双收敛因子策略下的改进灰狼优化算法
2023-09-27周恺卿尹鹏飞刘雪薇
欧 云,周恺卿,尹鹏飞,刘雪薇
(1.吉首大学 通信与电子工程学院,湖南 吉首 416000;2.吉首大学 教务处,湖南 吉首 416000;3.吉首大学 计算机科学与工程学院,湖南 吉首 416000)
0 引言
群智能算法是一种模仿生物群体智慧的概率搜索算法,具有强鲁棒性、易扩充、易实现等特点,已被广泛应用于研究领域和实际场景[1]。灰狼优化(Grey Wolf Optimizer,GWO)[2]算法作为近几年新起的群智能算法之一,因具有参数少、易实现、稳定性强等特点,在解决特征选择、神经网络优化、路径规划等优化问题时表现出了良好的性能;但该算法也存在求解精度不高、收敛速度慢、易陷入局部最优等缺陷。
针对以上不足,研究者从初始化种群、收敛因子、位置更新方法、设置跳出局部机制等方面改进GWO。王振东等[3]针对入侵检测存在的初始值不确定性及早熟的问题,利用混沌映射初始化种群、设计非线性收敛因子以及动态权重策略等手段优化GWO,并将它用于解决反向传播(Back Propagation,BP)神经网络因初始化权值和阈值的随机性而导致的陷入局部最优问题;李长安等[4]针对GWO 收敛速度慢、寻优精度不高等问题,采用sin 映射初始化种群,引入合作竞争机制及修正自适应权重等策略改进算法,提高了算法收敛速度和精度;Joshi 等[5]针对GWO 在探索和开发之间的不平衡问题,将每次迭代中适应度值最优解作为头狼,提出了一种增强型灰狼优化(Enhanced Grey Wolf Optimizer,EGWO)算法来提升前期探索阶段的收敛速度;Heidari 等[6]针对GWO 在某些问题求解中因种群的多样性不足而易陷入局部最优等问题,提出了一种基于α 和β 双狼引领、莱维(Levy)飞行随机更新、贪婪选择等策略的灰狼算法LGWO(Levy-embedded Grey Wolf Optimizer)来提升算法全局寻优能力。王敏等[7]针对灰狼优化算法存在的寻优精度不高和易早熟等缺点,提出了一种新型灰狼优化(Novel Grey Wolf Optimizer,NGWO)算法,采用了如下策略:首先,在初始化种群时采用反向学习策略和随机均匀分布进行优化;其次,通过调整收敛因子平衡全局勘探和局部开发能力;最后,利用变异算子避免算法陷入局部最优。张文胜等[2]提出了一种采用Sigmoid 函数作为收敛因子,以粒子群优化(Particle Swarm Optimization,PSO)算法的惯性权重因子作为位置更新权重的灰狼算法TGWO(Transformed Grey Wolf Optimizer);Yu 等[8]提出一种基于对立学习的灰狼优化器(Oppositionbased learning Grey Wolf Optimizer,OGWO),在不增加计算复杂度情况下,以跳跃率方式将对立学习与GWO 相结合,提升了算法在求解复杂多模态函数方面的性能。针对灰狼算法在竞选三头领导狼期间,其他落选狼必须等待竞选完成后才能更新所导致的收敛慢等问题,Zhang 等[9]提出一种改进的动态灰狼优化(improved Dynamic Grey Wolf Optimizer,DGWO)算法,当前搜索狼在完成自身或前一个搜索狼与领先狼的比较后,就更新它的位置,这种在竞选期间动态更新搜索狼的位置策略,提高了算法收敛速度。针对灰狼算法易早熟等缺陷,张佳琦等[10]提出一种改进的灰狼优化算法(Improved Grey Wolf Optimizer,IGWO),首先利用混沌Tent 映射策略初始化种群,提升种群的多样性和分布均匀性,然后采用非线性收敛因子、差分进化更新迭代等手段平衡算法的全局勘探和局部开发能力,并降低出现局部最优概率;刘继忠等[11]为避免全局搜索时陷入局部最优,提出了动态双子群策略改进的灰狼优化(improved Grey Wolf Optimizer based on Dynamic Double-subgroup strategy,DDGWO)算法。其他类似改进思路可参阅文献[12-15]。上述研究表明,对GWO 的改进思路可以归纳为以下几点:
1)优化初始化种群,确保种群的均匀分布性和多样性。
2)调整收敛因子,平衡算法全局勘探和局部开发能力。
3)改进更新方法,提升算法收敛速度和精度,避免陷入局部最优。
受以上研究启发,本文提出了基于双头狼引领的改进灰狼优化(Grey Wolf Optimization with Two Headed Wolves guide,GWO-THW)算法。首先引入混沌Cubic 映射初始化种群用以提升种群分布的均匀性和多样性;然后根据平均适应度值将狼群分为适应度值较优的捕猎狼和适应度值较差的侦察狼,并设立双头狼分别带领捕猎狼和侦察狼以不同的非线性收敛因子进行狩猎;最后设计一种自适应权重因子更新位置,提高收敛速度和精度。实验部分通过常用的基准测试函数测试了算法改进的可行性。
1 灰狼算法
灰狼优化算法是2014 年Mirjalili 等[16]受灰狼群狩猎行为启发而提出的一种群智能算法。GWO 首先将灰狼群当成初始解种群,按灰狼社会等级制度,将当前最优解当作α 狼,次优解为β 狼,第三优解为δ 狼,其余所有解为ω 狼,算法求解过程就是狼群的狩猎过程,具体模型如下。
1.1 包围猎物过程
灰狼为了完成对猎物的包围,需要根据猎物的大概位置计算出到猎物的距离,然后向猎物移动,计算公式如式(1)、(2)所示。
其中:t表示当前迭代次数;X(t)表示第t次迭代灰狼个体位置向量;XP(t)表示第t次迭代猎物的位置向量;X(t+1)表示更新后灰狼个体位置向量;D表示灰狼个体与猎物之间的距离;A和C是参数控制向量,A用于调节灰狼个体移动的方向,C用于修正猎物位置,分别用式(3)和式(4)计算。
其中:r1、r2为(0,1)内的随机向量;a为迭代收敛因子,它的值由2 线性递减到0,由式(5)确定。
其中:t表示当前迭代次数;T表示总迭代次数。
1.2 捕获猎物过程
在整个狩猎过程中,α 狼确定猎物位置,并一直向着猎物移动,β 狼和δ 狼跟随α 狼追捕猎物并引导其他狼包围猎物,其他狼向α 狼、β 狼、δ 狼移动,完成对猎物的包围。移动公式如式(6)~(12)所示。
其中:A1、A2、A3由式(3)计算;C1、C2、C3由式(4)计算;Xα、Xβ、Xδ分别表示α 狼、β 狼、δ 狼的位置向量;式(12)为灰狼个体位置更新公式。
2 灰狼算法的改进
GWO-THW 在标准GWO 的基础上,从种群分布、收敛因子、位置更新权重、跳出局部最优等方面进行改进。
2.1 初始化种群
在标准GWO 中,狼群位置分布越均匀,算法越易求得最优解。相较于GWO 的随机生成狼群初始位置策略,混沌映射由于它的随机性、均匀性和多样性等特点被广泛应用于智能算法中初始群体的生成。本文引用映射效果相对稳定的改进Cubic 混沌映射[17]实现狼群位置分布的初始化操作,映射函数如式(13)所示:
其中:xn的初始值设为x0,x0∈(0,1);ρ为控制参数,关系着Cubic 映射的混沌性。本文参照文献[17-18]中经过验证后相对较优的取值,x0取0.3,ρ取2.595。
2.2 改进收敛因子
GWO 的全局勘探和局部开发能力由 |A|决定,当 |A|≤1时,狼群跟随头狼围捕猎物;当 |A|>1 时,狼群扩散搜索猎物。
A值受收敛因子a影响,从式(5)可知,a成线性变化,控制前一半迭代次数用于全局搜索,后一半迭代次数用于局部寻优,不利于全局勘探和局部开发的平衡。而GWO-THW 根据平均适应度值将狼群分为适应度值较优的捕猎狼和适应度值较差的侦察狼,并提出相应的非线性双收敛因子。捕猎狼收敛因子如式(14)所示:
式(14)保证了该收敛因子在前期和后期递减缓慢,中期递减较快,这样就平衡了算法的全局勘探和局部开发能力并确保了算法收敛速度。
侦察狼收敛因子如式(15)所示:
式(15)使收敛因子从2 非线性递减到0,加强了侦察狼的全局勘探能力。
双收敛因子与原收敛因子的变化曲线如图1 所示。

图1 双收敛因子与原收敛因子曲线Fig.1 Curves of dual convergence factors and original convergence factor
2.3 增加自适应权重系数和引入Levy飞行策略
GWO-THW 设立γ 狼和α 狼双头狼机制,分别引领捕猎狼和侦察狼进行狩猎。但二者侧重点不同,捕猎狼的任务是围杀猎物,侦察狼的任务是搜寻猎物。所以,针对捕猎狼和侦察狼目标不同,GWO-THW 采用不同的位置更新策略。
捕猎狼由α 狼、β 狼、δ 狼带领围捕猎物,但从式(12)可知,标准GWO 采用平均权重作为灰狼个体的位置更新系数,不利于快速围杀猎物。为此,本文提出了一种自适应调整权重因子策略,以单位欧氏距离内适应度值递减速度快慢作为捕猎狼向α 狼、β 狼、δ 狼的移动权重,比值越大,表示梯度下降越快,该领导狼附近存在猎物的可能性也越大,捕猎狼向它偏移幅度就相应变大。
通过此策略,既提升收敛速度,又加强β 狼和δ 狼的影响力,避免所有个体都向α 狼聚集,增强算法勘探能力。权重公式如式(16)~(21)。
其中:f(X(t))表示第t次灰狼个体的适应度值;f(Xα(t))、f(Xβ(t))、f(Xδ(t))表示第t次α 狼、β 狼、δ 狼的适应度值;Dα、Dβ、Dδ为当前捕猎狼与第t次α 狼、β 狼、δ 狼之间的欧氏距离;ε为一个较小的正常数,本文取值为10-6。bα(t)、bβ(t)、bδ(t)为当前搜索狼与α 狼、β 狼、δ 狼间的单位距离内适应度值降低值。因此,捕猎狼个体位置更新公式如下:
为加强算法的全局探索能力,本文将迭代历史过程中的全局最优值设置为全局头狼γ,它的位置为Pbest。γ 狼一方面积极与α 狼交流,以便及时更新全局最优解;另一方面指导侦察狼以Levy 飞行策略反向搜索猎物。更新公式如下:
其中:θ是步长的缩放因子,取(0,1)内的随机数;a2由式(15)确定;Xz为随机个体。Levy(λ)为服从式(24)Levy 飞行分布的随机步长,u服从N(0,η2)分布,v服从N(0,1)分布,η由式(25)确定,λ取值1.5。
其中,Γ()为伽马函数。
为了提升侦察狼的搜寻效果,算法为侦察狼提供一次择优机会,若进行Levy 飞行更新的位置不佳,则保持原位置不变。侦察狼位置更新公式如下:
2.4 增加跳出机制
在标准GWO 中,狩猎都是α 狼引领。一旦α 狼判断错误,算法就很难找到全局最优解。针对这种情况,本文设定一种跳出机制,当α 狼位置连续迭代n次无变化(本文中,n=10),则记录当前α 狼位置及适应度值,然后种群按式(27)进行一次Levy 飞行,继续寻找其他最优解,直到算法终止。λ取值1.5,Xz、Xk为随机个体。
2.5 算法步骤
综合上述改进思想,GWO-THW 算法步骤如下。
步骤1 设定种群的大小N,维度M,初始化各参数。
步骤2 利用Cubic 混沌映射初始化灰狼种群。
步骤3 计算灰狼个体适应度值并求出适应度平均值,根据个体适应度值确定α 狼、β 狼、δ 狼,取全局最优解作为γ狼,计数α 狼出现在当前位置次数n,然后根据式(14)、(15)计算收敛因子a1、a2。
步骤4 判断灰狼适应度值是否小于平均值,若是,则根据式(22)进行位置更新;否则,保存当前位置并根据式(23)更新位置,然后根据式(26)择优确定最终更新位置。
步骤5 判断n次是否达到阈值,若是,则记录当前α 狼位置及适应度值,并与γ 狼比较,取优者为γ 狼,然后将种群通过式(27)进行位置更新;否则,转入步骤6。
步骤6 判断是否达到终止条件,若是,则将输出最优值;否则,返回步骤3。
3 实验与结果分析
为了验证本文算法的有效性,选取了通用的10 个基准测试函数进行性能测试。运行环境为Intel Corei5-10500 CPU,主频3.10 GHz,内存8 GB,Windows10 64 位操作系统,集成开发环境为 Python 3.7。为保证实验数据与其他算法的无差异性,算法的种群数设置为30,迭代次数设定为500,算法独立运行30 次,取平均值和标准差为性能对比度量。
3.1 基准测试函数
仿真所用基准测试函数的相关参数如表1 所示,其中包含7 个单峰测试函数(F1~F7)和3 个多峰测试函数(F8~F10)。

表1 10个基准测试函数Tab.1 Ten benchmark functions
3.2 改进策略分析
为验证本文改进策略的有效性,将改进算法在表1 所列的10 个基准测试函数上进行消融实验。对比算法包括GWO和本文的GWO-THW 去掉各改进策略后的算法(GWO1 代表去掉初始化种群策略;GWO2 代表去掉改进的收敛因子策略;GWO3 代表去掉自适应权重系数和Levy 飞行策略;GWO4 代表去掉跳出机制)。实验结果如表2 所示。
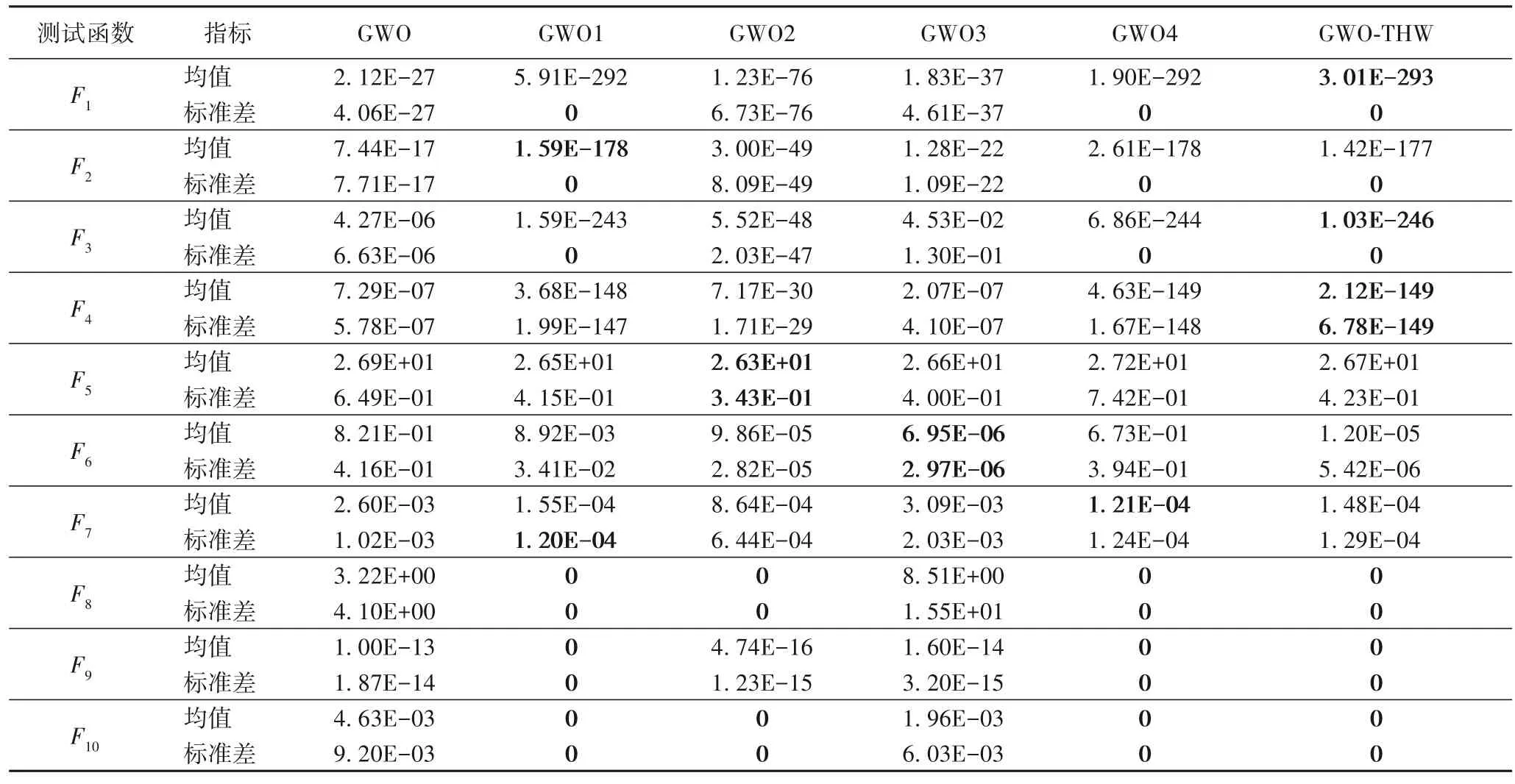
表2 消融实验结果Tab.2 Ablation experiment results
从表2 可知,去掉初始化种群策略(GWO1)和跳出机制策略(GWO4)对寻优精度的影响较小。初始化种群策略能改进初始种群的分布,影响算法的前期寻优速度和寻优结果的稳定性;跳出机制策略是跳出局部最优机制,在算法寻优趋势较好时发挥的作用较小。对于改进收敛因子策略、自适应权重系数和Levy 飞行策略,单一情况下对算法有一定改进,但效果一般,二者结合后,对算法的寻优精度提升较大。
3.3 与其他群智能算法比较分析
为验证本文算法在寻优性能上的优势,将GWO-THW 与其他群智能算法(包括差分进化(Differential Evolution,DE)、萤火虫算法(Firefly Algorithm,FA)、粒子群优化(Particle Swarm Optimization,PSO)算法)在10 个基准函数上进行仿真实验,实验结果如表3 所示。

表3 本文算法与其他群智能算法的比较结果Tab.3 Comparison results of the proposed algorithm and other swarm intelligence algorithms
从表3 可以看出,GWO-THW 除了在F5函数上与PSO 算法寻优精度相近外,其他数值都明显优于对比的群智能算法,特别是在F1~F3和F8~F10函数上,寻优精度更佳。这也验证了本文的GWO-THW 相比其他的标准群智能算法具有较大的精度优势。
3.4 与其他灰狼算法的对比分析
为进一步验证本文的改进策略的有效性,将GWO-THW与GWO 及相关改进GWO 进行比较。对比算法如下:
GWO[14]:标准灰狼算法。
EGWO[5]:基于当前迭代最优解为头狼的改进算法。
LGWO[6]:基于双狼引领、Levy 飞行的改进算法。
NGWO[7]:基于反向学习和变异算子的改进算法。
TGWO[2]:基于Sigmoid 及权重因子的改进算法。
OGWO[8]:基于反向学习的改进灰狼优化算法。
DGWO2[9]:改进的动态灰狼优化算法。
实验结果如表4 所示。表4 中10 个基准测试函数上的测试数据,除GWO、OGWO、DGWO2 和GWO-THW 算法外,其他算法的数据都来源于原文献。

表4 GWO及其各种变体的实验结果Tab.4 Experimental results of GWO and its variants
从表4 来看,GWO-THW 在20 个指标数据中占据16 项最佳结果。在复杂单峰函数F5~F6上,因最优值所在区域中,函数值变化不大,随机算法容易在此区域内发生扭摆现象,因此GWO-THW 与其他算法性能接近;但在其他8 个基准测试函数上,GWO-THW 都取得了较高的寻优精度,尤其在多峰函数上更是取得了理想最优值,说明算法在多峰函数和简单单峰函数上寻优能力良好,验证了GWO-THW 的有效性。
从算法改进策略分析,在收敛精度方面,NGWO、TGWO、GWO-THW 在多峰函数方面表现较好,而这几种算法都改进了收敛因子,说明收敛因子调整有助GWO 算法在多峰函数上的寻优;TGWO、OGWO、GWO-THW 在函数F1~F4上性能较佳,这些算法在进行位置更新时都引入了自适应动态权重因子,说明位置更新权重系数能提高GWO 在简单单峰函数上的性能;在复杂单峰函数方面,对比的各算法都有待进一步改进。
为验证算法在收敛速度方面的性能,选取GWO、OGWO、DGWO2 和GWO-THW 这4 种算法进行实验,算法的种群数设置为30,迭代次数设定为500。算法独立运行30次,取其中寻优精度最佳的实验数据作迭代图,具体收敛曲线如图2 所示。
从图2 可以看出:除函数F5、F6外,在迭代相同次数的情况下,相比其他算法,本文的GWO-THW 能得到更高的精度,尤其在多峰函数上,200 次迭代内就能收敛到理想最优值0。说明改进算法在收敛速度方面优于其他算法,进一步验证了GWO-THW 算法的有效性,且在多峰函数上具备非常明显的优势。
4 结语
针对标准GWO 算法的收敛精度不高、易早熟等问题,本文提出了一种的改进灰狼算法。首先,利用混沌映射初始化种群机制,提升算法的鲁棒性;设计了双非线性收敛因子和双头狼引领狩猎策略,平衡算法的全局勘探和局部开发性能;引入Levy 飞行策略和调整自适应位置更新权重机制,提升算法寻优精度和收敛速度,同时加强算法跳出局部最优能力;最后通过10 组基准测试函数验证了改进策略的有效性。
