基于高阶一致性学习的聚类集成算法
2023-09-27甘舰文
甘舰文,陈 艳,周 芃,杜 亮,4*
(1.山西大学 计算机与信息技术学院,太原 030006;2.四川大学 计算机学院,成都 610065;3.安徽大学 计算机科学与技术学院,合肥 230601;4.山西大学 大数据科学与产业研究院,太原 030006)
0 引言
聚类是一种重要的无监督分类技术,在统计、模式识别、机器学习、数据挖掘等不同领域都得到了广泛的研究。根据几种聚类准则和不同的相似性度量方法,可以揭示一个数据集的底层结构。在无监督学习中,由于训练数据集没有标签,聚类算法很难验证聚类结果的有效性,给设计聚类算法带来很大的挑战。每种聚类算法都有自己的优缺点,传统的聚类算法同时还面临其他问题[1],例如同一种聚类算法,由于目标函数的不同,在相同的数据集上也会得到不同的聚类结果。K-均值(K-Means)算法高度依赖初始化和数据分布。为了提高单个聚类算法结果的鲁棒性、一致性、新颖性和稳定性,聚类集成(聚类融合或共识聚类)利用多个聚类结果的共识并将它们组合成最优解。聚类集成提供了一种框架,可以将多个基聚类器的结果组合在一起,生成一致聚类[1]。
现有的聚类算法可以被分为三类:
1)基于相似性矩阵的算法。将基聚类结果转化为相似性矩阵,通过不同的聚类集成方法生成一致性矩阵。
2)图方法。将输入的基聚类结果转化为无向图,通过图划分得到最终的聚类结果。
3)基于重标记的方法。将基聚类结果转化为新的标签向量,然后通过标签对齐找到集合聚类。
基于相似性矩阵的方法和图方法近年来有着广泛的应用。相似性矩阵反映样本对之间的关系,在聚类集成算法中使用广泛。不同的相似度度量方式会得到不同的结果。但这两种方法的输入数据易受离群点影响而破坏簇的边界,从而影响到最终聚类结果[2]。本文通过基聚类器生成相似性矩阵,从不同的角度度量样本对之间的相似性。
1 相关工作
聚类集成融合多种输入结果试图得到一个更好的结果,至今已经发展出一大批聚类集成方法。在聚类集成方法发展早期,一些以信息论为基础的方法被提出,如Strehl 等[3]以信息共享为基础,将聚类集成问题转化为组合优化问题。近年来,更多的方法被应用到聚类集成中,如利用对齐的方法结合多个K-Means 的聚类结果[4]。一些工作利用非负矩阵分解将关联矩阵分解为两个指示矩阵[5]。除了以K-Means 作为基聚类输入,谱聚类也有聚类集成的工作。一些方法引入了概率理论将图模型转化为聚类集合,如Wang 等[6]使用了贝叶斯模型聚类集成学习了一个带有因子图的共识聚类结果。
由于聚类的多样性和质量在集成学习中至关重要,许多方法都充分利用多样性和质量来组合基聚类。如Abbasi等[7]提出了一种新的稳定性测度——归一化互信息(Normalized Mutual Information,NMI),并将它用于集合基聚类;Bagherinia 等[8]考虑基聚类结果的多样性和质量提出了一种模糊聚类集合。除了使用所有基聚类器的结果作为输入进行聚类集成,还有一些工作试图选择一些具有高质量信息且无冗余的基聚类结果进行集成。Azimi 等[9]提出了一种自适应聚类集合选择方法来选择基聚类结果;Hong 等[10]采用重采样方法选择基聚类;Parvin 等[11]提出了一种加权局部自适应聚类集合选择算法;Yu 等[12]将聚类选择转化为特征选择,设计了一种混合策略来选择基聚类结果;Zhao 等[13]提出了用于聚类集合选择的内部有效性指标;Shi 等[14]将迁移学习扩展到聚类集成,提出了迁移聚类集成选择方法。
根据算法思想和原理这些聚类集成方法可归类为:基于关系矩阵的方法、直接融合法和基于图的方法。Li 等[15]提出了规范化边的概念用来度量样本的相似度,用层次聚类来融合最终的结果;Huang 等[16]使用概率轨迹的概念重新构造样本相似度。直接融合法首先匹配基聚类器中的类簇,然后通过投票机制融合结果。图方法在基聚类器上构建图表示,利用图分割技术发现群组结构。常用的图划分技术包括归一化切割(Normalized CUT,N-CUT)[17]和层次化的分割算法METIS[18]。聚类方法的设计和输入的基聚类结果都会显著影响聚类集成的性能。基聚类结果应该尽可能地体现差异性,而不是追求数量。获得差异性的基聚类结果主要有以下几种方式:1)使用不同的聚类方法对同一数据集进行聚类;2)使用不同的初始化值和有差异性的参数值;3)对进行聚类的数据集使用不同的办法抽样,获得有区别的数据片段。
本文方法基于相似性矩阵,一方面利用高阶信息有效地发掘数据样本之间的联系,另一方面不同角度的信息使得参与融合的基聚类信息具有较大的差异性。同时,利用多种信息源也会带来处理高阶数据耗时长、计算量大的问题。针对以上问题本文提出一种新的高阶信息融合算法——基于高阶一致性学习的聚类集成(Clustering Ensemble with Highorder Consensus Learning,HCLCE)算法。首先将每种高阶信息融合成一个新的结构化的一致性矩阵;然后再对得到的多个一致性矩阵进行融合。算法通过双随机约束,使得一致性矩阵行列求和的值都为1,因此样本对之间的相似度,同时也表示了该样本与其他样本属于同一个类的概率。
2 基于高阶一致性学习的聚类集成
本章首先介绍高阶信息的表示方法,然后描述HCLCE算法的具体细节,最后对目标函数进行求解优化。
X={X1,X2,…,Xi,…,Xm}为d维空间中未标记的n个样本,通过K-Means 算法进行m次聚类,生成基聚类结果H={H1,H2,…,Hi,…,Hm},其中:Hi表示第i次聚类的结果;c表示簇的个数,假设所有基聚类器结果簇的个数一样。基于Hi,相似性矩阵Si可以表示为:,同时定义1 表示大小为n× 1 的列向量。
2.1 高阶矩阵信息定义
单个基聚类器相似性矩阵是一次聚类的结果,为了挖掘样本之间进一步的联系,利用多次聚类的结果,获取更具有代表性和差异性的高阶信息。本文通过以下几种方式,从不同的角度获得聚类信息增益。
2.1.1 一阶一致性
单次聚类结果的相似性矩阵结果Si之间差异性较小。以表示把单个相似性矩阵作为第一种输入信息。
加权结构化的过程可以分为两步,由于一阶信息是由m个聚类共识结果组成,每个聚类结果之间具有一定差异性,因此第一步对集合A1中的每个相似性矩阵赋予权重,融合成一个相似性矩阵,表示为:
其中:k是集合A1中元素的数量,在一阶情况下k的大小等于输入的相似性矩阵的个数;是k个相似性矩阵加权融合的结果为矩阵中的元素;wi是权重向量w的第i个元素。通过对结构化使簇的结构更清楚,同时满足相似性矩阵性质的约束。
其中:L是拉普拉斯矩阵;λ是自适应参数。
求得的M11 对称且满足双随机约束,是一阶信息加权结构化后的一致性矩阵。
2.1.2 二阶簇级一致性
二阶簇级一致性表示两个基聚类器对同一个簇的一致性进行投票。得分越大,说明不同基聚类器之间同一个样本所在的两个簇之间交集越大,越具有相似性。簇的一致性的投票计算过程如图1 所示,可以表示为

图1 相似性矩阵Si和Sj簇间交集大小的计算Fig.1 Calculation of intersection size between clusters of similarity matrix Si and Sj
二阶簇级一致性是基聚类器两两运算,基聚类器之间不进行运算,所以m个输入会产生m2-m个结果,而相似性矩阵本身对称,因此只需要计算(m2-m)/2 次,对A2加权得:
求得M2对称且满足双随机约束,表示二阶的簇级信息加权结构化后的一致性矩阵。
2.1.3 二阶样本对一致性
相似性矩阵的每一个元素的值代表着不同样本对两两之间一致性的大小。通过相似性矩阵两两之间进行点乘运算,只有在两种样本对取值都为1 的情况下,样本对是否属于一个类才能达成一致,否则认为不属于同一类,这说明点乘运算只会保留达成一致的样本对,不一致的样本将会舍去,计算过程如图2 所示,相似性矩阵对同一个样本对相似性进行乘法运算,显然只有达成一致的样本对相似性为1,否则为0。所以这种情况下的高阶信息同时增强了样本对之间的确定性和不确定性,表示为对 于m个 相似性矩阵哈达玛积也会产生(m2-m)/2个结果。

图2 相似性矩阵Si和Sj样本对的一致性计算Fig.2 Consistency calculation of similarity matrix Si and Sj sample pair
对A3加权得:
求得M3对称且满足双随机约束,是二阶样本对之间信息加权结构化的一致性矩阵。
2.1.4m阶样本对一致性
在此基础上,可以提出一种更加严格的样本对一致性信息挖掘方式,表示为,这种运算表示对所有单次聚类结果进行连乘点积运算,只有所有结果达成一致的样本对才会被保留,任何一个相似性矩阵的不一致结果,都会使该样本对结果为0,计算过程如图3。可以看到,对不同相似性矩阵中的样本对相似度相乘,只有所有相似性矩阵在该样本对上的值为1 时,得到的最终矩阵才会保留该样本对相似度为1。因此,保留下的样本对具有最大的确定性,同时该矩阵也最稀疏。A4最后结果只有一个矩阵,因此不需要赋予权重。定义S4=A4,对结构化的过程为:

图3 所有相似性矩阵样本对一致性计算Fig.3 Consistency calculation for all similarity matrix sample pairs
求得M4对称且满足双随机约束,是m阶样本对级别的信息加权结构化后的一致性矩阵。
2.1.5 高阶信息融合
聚类集成将多个共识结果组合为一个最优解,由于对高阶信息的发掘,特别是相似性矩阵两两之间的关联,使得需要融合的共识结果迅速增多,一次性融合这些信息需要耗费巨大的时间和计算量,为此本文提出一种分阶段融合的框架。对每种高阶信息进行计算,先融合成一种加权结构化后的高阶信息,将它作为输入,最终融合为一个一致性矩阵。用M表示满足约束条件,是最终学习的一致性矩阵。整体算法流程如图4 所示。

图4 分阶段融合算法流程Fig.4 Flowchart of phased fusion algorithm
由于每种高阶信息携带的信息和侧重点不同,为了放大信息间差异性的作用,仍需要对每种信息赋予权重,如式(8)所示:
其中:L是拉普拉斯矩阵,LM=DM-M,DM为矩阵M的度矩阵,DM∈Rn×n定义为一个对角矩阵,第i个元素为,通过增加秩约束,使得rank(LM)=n-c,学得的一致性矩阵有c个连通片,从而获得更加清晰的簇结构[19];d是需要融合信息的个数;λ是自适应参数,随着rank(LM)的大小自动调整;Mi是第i种加权结构化后的高阶信息输入。下面介绍如何求解所提出的目标函数。
2.2 模型优化
本节主要介绍优化问题的求解方法和算法流程。
2.2.1 加权优化
优化问题式(1)、(3)、(5)为同一种问题,区别在于权重个数不同。以式(1)为例,迭代更新w和A1。
2.2.2 结构化算法
优化问题式(2)、(4)、(6)、(7)为同一类问题。以式(2)为例:
1)固定F,更新M1。
根据Von Neumann 交替投影定理[20]。本文使用的这种相互投影策略将收敛于由问题(14)和(15)形成的两个子空间的交叉。对式(14)[21]求解可得:
将得到M1作为B代入式(14),如此迭代直至M1收敛。
2)固定M1,更新F。
优化问题(2)可化简为:
根据Ky Fan’s theorem 理论[22],F为L前c个最小的特征向量。
2.2.3 融合算法
求解式(8),可以迭代地更新M、W、F,详细过程如下:
1)固定M,更新w。
固定M,式(8)可化简为:
其中,F为L前c个最小的特征向量。
下面对目标函数求解过程进行总结。
求解式(1)、(3)、(5)的算法流程算法1 所示。
算法1 加权优化。
3 实验与结果分析
3.1 数据集
本文使用以下8 种不同类型的数据集进行聚类集成实验:1)CSTR(http://www.ncdc.ac.cn/portal/metadata/1a0e7fc8-8dc1-4c74-a6b2-e6a20d7b6ee4);2)GLIOMA(https://sites.google.com/site/feipingnie/file/);3)Prostate(https://cdas.cancer.gov/datasets/plco/20/);4)ORL(http://www.uk.research.att.com/facedatabase.html);5)YALE(http://cvc.yale.edu/projects/yalefaces/yalefaces.html);6)Tr41(http://www.cs.umn.edu/~karypis/cluto/files/datasets.tar.gz);7)Jaffe(http://www.kasrl.org/jaffe.html);8)AR(http://www2.ece.ohio-state.edu/~aleix/ARdatabase.html)。使用不同类型的数据集可以更好地评估算法性能,数据集的详细信息如表1所示。

表1 数据集详细信息Tab.1 Detailed information of datasets
3.2 对比方法
实验对比了以下9 种算法:
1)K-Means(简写为KM):表示K均值聚类的结果。聚类集成通常使用该算法作为基线。
2)CSPA(Cluster-based Similarity Partitioning Algorithm)[3]:表示了同一个簇种样本的关系,用于度量样本对之间的相似度。
3)HGPA(HyperGraph Partitioning Algorithm)[3]:一种基于超图划分邻域的方法,将超图的超边以及顶点所有的权重设为统一值。设置分区大小以避免出现大量碎片分区。
4)MCLA(Meta-CLustering Algorithm)[3]:该算法将聚类集成问题转化为簇一致性问题。
5)LWEA(Locally Weighted Evidence Accumulation)[23]:层次聚类方法,基于集成不确定估计和局部加权策略。
6)LWGP(Locally Weighted Graph Partitioning)[23]:一种基于局部加权策略的图划分算法;此外,通过熵的准则判断簇的可靠性。
7)RSEC(Robust Spectral Ensemble Clustering)[24]:一种具有鲁棒性的谱聚类方法。
8)DREC(Dense Representation Ensemble Clustering)[2]:该算法利用密集表示模型构造样本相似性矩阵。
9)SPEC(Self-Paced Clustering Ensemble)[25]:该方法从易到难进行学习,并将难度评估和集成学习融合在统一的框架中。
3.3 评价指标
本文实验采用聚类准确率(ACCuracy,ACC)和归一化互信息(Normalized Mutual Information,NMI)两种常见的聚类有效性外部评价指标评估算法性能。
ACC 用于比较获得的标签和数据提供的真实标签,用VACC表示,取值范围是[0,1],值越大说明获得的标签准确性越高,将样本正确划分的效果越好。
其中:pi是聚类后的标签;qi是真实标签;n为样本总数。δ表示指示函数,具体如下:
NMI 度量聚类结果的相似性程度,取值范围为[0,1],值越大,说明变量之间的关系越密切,聚类结果越相近:
其中:H(A)、H(B)是A、B的熵;I(A,B)是互信息,表示一个变量包含另一个变量的信息量;A是真实数据的标签集合,B是聚类算法划分的类集合。互信息I(A,B)表示为:
其中:p(ai)为从数据集中任意选定一个样本点属于A类的概率;p(ai,bi)为任选的数据点同时属于A类和B类的概率。
3.4 实验结果与分析
本文将通过实验验证高阶信息以及高阶信息融合的有效性。不同算法在8 个数据集上的结果对比如表2~4 所示,其中:最优结果加粗表示;次优结果用下划线表示;括号中的数据为方差。
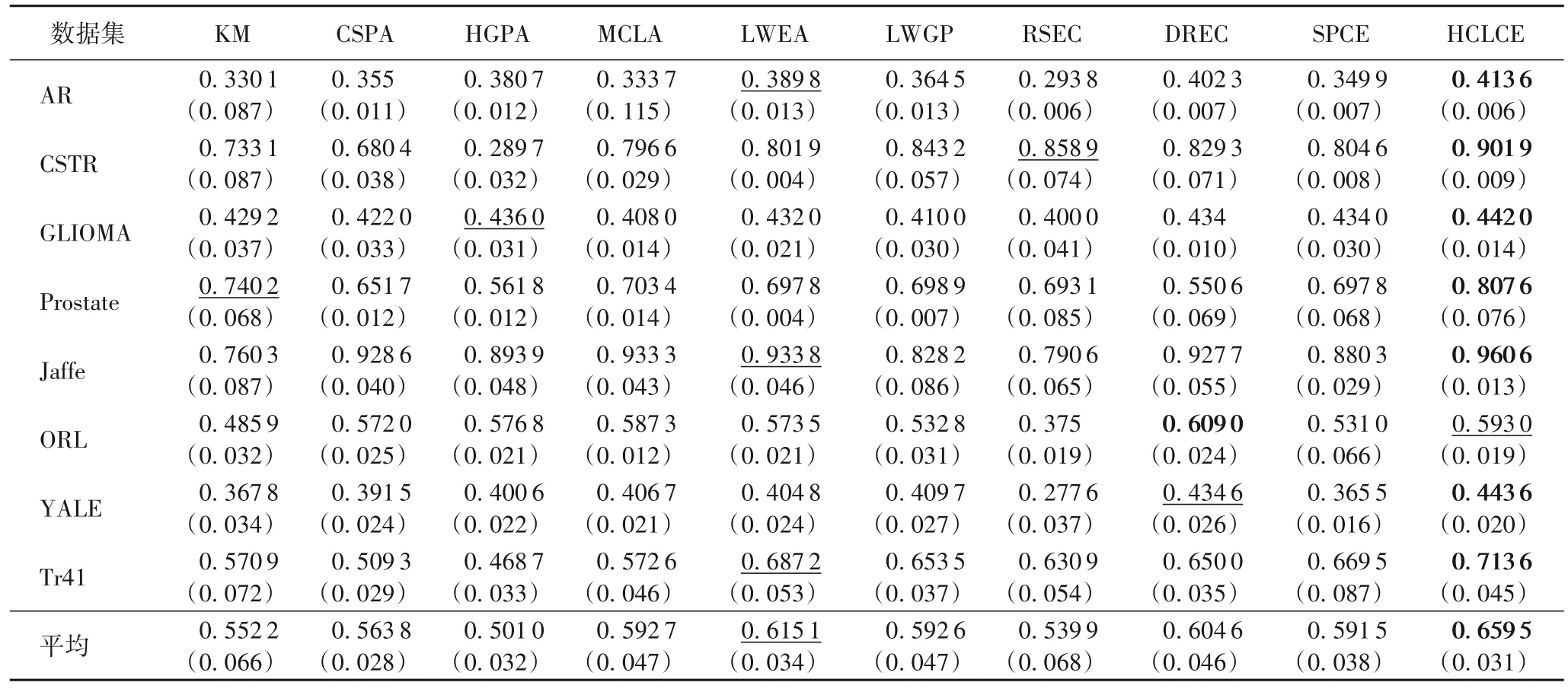
表2 ACC实验结果对比Tab.2 Comparison of ACC experimental results
表2 为不同算法的ACC 结果,可以看出:HCLCE 算法在一定程度上提高了聚类集成的聚类效果,在不同数据集上的实验结果大部分高于对比算法;并且HCLCE 算法相比其他对比算法,具有较小的方差,说明HCLCE 算法的稳定性更好。对比鲁棒性方法RSEC,HCLCE 算法具有更好的表现。
表3 为不同算法的NMI 结果对比。从表2~3 可以看出,HCLCE 算法的ACC 和NMI 在所有数据集上的均值均好于对比算法。与次优的LWEA 相比,ACC 平均提升了7.22%,NMI 平均提升了9.19%。

表3 NMI实验结果对比Tab.3 Comparison of NMI experimental result
HCLCE 算法融合多种高阶信息,在多数情况下好于仅使用一种信息的聚类结果。使用不同高阶信息矩阵A作为输入,进行加权结构化后得到新的关联矩阵M。表4 为不同的M在融合前的聚类效果和融合后整体的聚类效果。其中Ai的定义已在前面介绍,不同的集合代表着不同的高阶信息计算方式,集合从大小到所表示信息具有很大差异性。M1是加权结构化后的一阶信息关联矩阵,以M1为基础进行聚类,效果比对比方法有一定提升,说明对不同输入加权起到了让质量好的输入权重大、质量差的输入权重小的作用,从而提高聚类结果。并且结构化和秩约束使样本对关系表达得更加清楚,簇的结构更加清晰。融合的过程再次对不同阶信息分配权重,使各种信息再次组合。

表4 信息融合前后不同阶的ACC对比Tab.4 ACC Comparison at different leves before and after information fusion
每种高阶信息从不同的角度表示样本对相似性,因此有不同的特点。以CSTR 数据集为例,不同阶信息表示的关联矩阵经过加权结构化后的直观展示如图5 所示:颜色越深,样本相似性越小;颜色越浅,样本相似性越大。

图5 不同阶数信息的结构化关联矩阵Fig.5 Structured correlation matrices of different order information
从图5 可以看出:1)使用原始输入的聚类结果得到的结构化相似性矩阵M1中,大量样本对之间相似性处于0.5~0.6,很难判断两个样本是否属于同一类。2)对于矩阵叉乘M2,得到的相似性矩阵区分度不高,大量样本对同时具有高相似度,这种信息过于冗余,基聚类输入两两之间在簇上的产生交集的概率很大,特别是在基聚类器之间差异性不大的情况下,同样不具有区分性。3)矩阵样本对之间的一致性介于原始输入和簇级一致性之间,说明基聚类器两两之间在样本对一致性判断上不能统一,有的簇中样本对一致性较大,有些簇中样本对一致性趋于二分,不容易判断。4)单独使用所有关联矩阵点积连乘运算获得的m阶信息的聚类效果明显下降。这是因为m阶信息虽然可靠但非常稀疏,只保留了所有输入达成共识的样本对,没有保留一致性较大的样本对,关联不好的簇作为输入会影响整体聚类的效果。
HCLCE 算法对融合的每种信息赋予权重:与目标差异越大的信息获得的权重越小,减轻了不好的基聚类器带来的影响;质量高的基聚类器占据主导地位,提高了最后的聚类结果。经过高阶信息融合后得到的关联矩阵簇结构更清晰,去除了很多冗余样本对信息,更加满足关联矩阵的性质。
4 结语
本文提出了一种新的数据高阶信息挖掘方法,利用高阶一致性共识的信息,从不同角度刻画样本之间的联系,验证了不同层面的共识信息的差异性。HCLCE 算法通过加权减少信息之间的质量差异性带来的影响,引入对关联矩阵双随机约束和秩约束,使得最终融合的关联矩阵更加符合其内在特性。通过对多种高阶信息的融合,得到了比聚类集成算法和单独使用一种信息更好的聚类结果。实验结果表明,差异性大的输入对于聚类结果的提升具有帮助。其次,通过实验验证了每一种信息的特点和有效性,以及融合算法要好于单独使用某一种信息。此外观察到m阶信息虽代表了可信度最高的一致性样本对信息,但是在融合过程中没有起到明显的提升效果或者是约束样本对一致性的监督作用。在后续工作中,应探索在聚类过程中如何充分利用可靠信息,从可靠信息中发掘样本潜在的一致性信息,从而更大程度地减少低质量信息对聚类结果产生的负面影响。
