基于集成模型的污水处理厂出水总氮预测方法
2023-09-25姚怡帆荆玉姝王丽艳刘长青
姚怡帆,荆玉姝,王丽艳,刘长青
(1.青岛理工大学环境与市政工程学院,山东青岛 266520;2.青岛张村河水务有限公司,山东青岛 266100)
在社会经济发展、人们生产及生活水平不断提高的背景下,日益严格的污水处理标准与不断创新的污水处理技术驱动着污水处理厂的提标改造。数字化的水务行业发展趋势为污水处理厂的进一步发展提供了全新的思路〔1〕,其中水质预测作为污水处理厂数字化和智慧化的重要一环,可以为解决水质超低排放、节省能耗药耗等问题提供潜藏的有价值信息,有助于污水处理厂后期发展向“碳中和”目标迈进〔2〕。
由于传感器的普及和信息技术的发展,污水处理厂大多应用自动化的方式对大量业务数据进行采集和管理,在此背景下,研究人员借助由污水处理系统配套的检测探头所产生的水量、水质与运行数据,尝试对污水处理的复杂反应过程进行描述。Ying ZHAO等〔3〕利用人工神经网络(Artificial neural network,ANN)模型为中国哈尔滨某污水处理厂建立了原水水质、能耗和出水水质之间的关系,体现了ANN在模拟和预测出水水质方面的可行性。柴伟等〔4〕利用径向基函数神经网络的逼近能力建立污水处理系统出水BOD模型,结果表明该方法能有效预测出水BOD的上下限。
除上述单一模型,混合模型亦能对水处理方面数据进行有效的分析学习。Xin WAN等〔5〕融合深度学习算法和高斯回归挖掘造纸废水处理中数据的信息,实现了对出水化学需氧量和悬浮物的点预测和区间预测。Kang LI等〔6〕在预测污水处理厂出水氨氮浓度方面将灰色关联分析(Grey relation analysis,GRA)和时间卷积网络相结合,与4种单一模型相比,混合模型更稳健。因为混合模型能利用不同方式融合多种算法,弥补单一模型的不足、发挥各算法的优势、提供更可靠的预测结果〔7〕,所以逐渐成为水处理过程建模的研究热点。
以青岛某污水处理厂日常数据为基础,通过GRA选取影响出水总氮浓度变化的建模关键指标,采用目前在水环境领域预测性能较好的多种算法——长短期记忆神经网络(Long short-term memory networks,LSTM)、误差反向传播神经网络(Back propagation neural networks,BPNN)、支持向量机回归(Support vector regression,SVR)、极限梯度提升(Extrme gradient boosting,XGBoost)、K近邻(Knearest neighbor,KNN)对出水水质指标总氮(TN)进行预测,且通过Stacking集成方法对以上5种算法进行融合,探索该模型在污水处理厂出水总氮浓度预测中的可行性。
1 模型构建
1.1 数据集构建
本研究所用数据来源于青岛市某污水处理厂,因以预测出水总氮浓度为目标,故将出水总氮作为标签向量。不同于以往研究中仅利用进水各项指标建立出水预测模型〔8-9〕,考虑到污水处理过程复杂,最终出水水质情况是多因素共同作用的结果,因此在建模过程中将水质常规指标和运行操作情况均作为特征向量进行考量,不仅能保证模型的应用效果更加理想,也对污水处理厂具有一定的实践意义。
以每日平均值为数据统计的时间颗粒度,自2020年9月1日至2022年2月28日共累计数据546组,数据包含污水处理厂运行过程所监测的各项指标:进水的水质水量指标(COD、TN、NH4+-N、TP、SS、pH、水量)和各构筑物运行指标(ORP、DO、MLSS、曝气量、投药量、回流比)。由于该污水处理厂各构筑物水力停留时间合计约为24 h,因此设计模型时使用前一日的特征向量数据与当日的标签向量数据相对应。
从现场直接采集的数据受设备故障、操作失误等影响,部分数据可能存在异常和缺失。基于数据驱动的建模方式对数据有极强的依赖性,为保证模型具有良好的预测性能,对输入模型的数据进行如下处理:
1)异常数据处理。采用拉依达准则,各个特征向量将以均值μ为中心、3倍标准误差σ外的数据舍去,以消除数据集中的粗大不合理误差。
2)缺失数据处理。法定节假日期间,污水处理厂生化部分指标数据由于化验不及时存在缺失,则对该天整条样本进行删除。
3)数据标准化处理。在训练模型过程中,将所有特征数据的样本值映射到[0,1]范围内,可以消除不同指标的量纲不一致对模型产生的影响,标准化处理如式(1)所示。
式中:X、Xmax和Xmin——特征向量中各项指标的样本值、最大值和最小值;
Xscale——特征向量中各项指标的样本值进行标准化处理后所得数值。
546组数据经处理后保留493组有效数据。为了尽可能降低数据维度、节省模型运算时间,需选取与标签向量相关性较高的指标作为建模的特征向量。由于特征向量与标签向量之间的关系是不确定的,因此可将出水总氮的预测看作是一个灰色系统。而GRA是一种基于灰色系统理论、借助灰色关联度来反映因素间相关程度的一种方法〔10〕。因此利用GRA衡量各项指标与出水总氮之间的相关性,假设特征向量x共有m个,则特征向量x与标签向量y的灰色关联度ζ计算公式如式(2)所示。
式中:y(i)——标签向量的第i个值;
x(j,i)——第j个特征向量的第i个值。
灰色关联度越接近于1,指标间的相关度越大,经计算,筛选与出水总氮灰色关联度大于0.9的特征向量见表1。

表1 特征向量的灰色关联度Table 1 Grey correlation degree of the feature vectors
进水量和进水pH体现了污水的理化性质,进水TN、进水NH4+-N、生化池进水TN 3项水质指标可直接反映进入处理单元前污水中的氮元素浓度。生化缺氧池ORP代表生化处理阶段氧化还原反应的剧烈程度,生化MLSS平均值表示生化处理单元活性污泥的浓度,两者在一定程度上从活性污泥的角度反映了生化处理单元的脱氮潜力。乙酸钠投加量影响生化处理阶段的C/N、生化好氧池溶解氧浓度影响活性污泥中微生物的种类及活性〔11〕,均在运行控制角度反映了污水处理厂为脱氮过程所提供的条件。因此,表1通过灰色关联度筛选出相关性较高的指标可作为建模时所使用的特征向量。
1.2 算法选择
出水总磷预测模型的实质是建立一个数据驱动的回归模型,解决此类问题思路是通过寻找一个最优的算法模型f,构建t-1时刻的进水水质、t-1时刻的运行参数以及t时刻的出水总氮浓度之间的关系,假设经过GRA特征筛选后,特征向量x′共有k个,则特征向量x′k和标签向量y构建的关系如式(3)所示。现有非线性回归算法主要有传统机器学习、人工神经网络模型、时间序列分析等。
1.2.1 机器学习算法
在常见的机器学习中,选取了3种可用于构建非线性映射关系的回归算法,分别为KNN、SVR和XGBoost。KNN是通过计算欧式距离D,选取空间中与标签向量距离最接近k个的特征向量来逼近待测样本的真实结果,其理论成熟、训练高效且具有良好的实践应用效果。
式中:x′k(i)——经过GRA筛选后第k个特征向量的第i个值。
SVR可将高维数据通过核函数kernel在特征空间中表达,假设在一定误差容许ε范围内存在某一超平面离各类数据距离最近,超平面的表达式即为回归问题所逼近的非线性方程,则超平面满足式(5),其中b为截距向量。
XGBoost是引入正则项和二阶泰勒展开的一种精度高、运算快的树模型,是一种以最小化损失为目标,由弱学习器迭代而来的强学习器。其中,弱学习器数量n_estimators和提升树最大深度max_depth决定树模型所用学习器的个数与层次;学习率learning_rate决定在误差减小过程中迭代的步长;正则项参数reg_alpha与正则项参数reg_lambda互相影响,共同调整学习器正则项的大小。
1.2.2 反向传播神经网络
BPNN能把获取的数据信息经过隐层神经元前向传递,同时将预测过程中产生的误差进行反向传播作为调整权重的依据,其强大的学习能力和拟合能力使其能以任意精度逼近任何非线性连续函数,适合求解污水处理过程这类内部机制复杂的问题。本研究设计的BPNN以平均绝对误差(Mean absolute error,MAE)作为纠正隐层神经元权重的评价指标,构建从特征向量x′k到标签向量y的映射,实现出水总氮的预测。
1.2.3 长短期记忆人工神经网络
S. HOCHREITER和J. SCHMIDHUBER于1997年在提出了LSTM这一深度学习算法〔12〕。不同于传统人工神经网络,LSTM在隐层神经元之间实现了连接,通过“门”的概念使得数据在时间序列(t时刻至t+1时刻)间也可完成信息传递。在气候、人口、经济等因素影响下,进水水质不规律波动会映射到出水水质上,同样,前一时刻污水处理厂所承受负荷冲击也必然会影响各构筑物的处理能力,继而导致后一时刻污水处理效果的变化。因此利用LSTM在建立输入与输出关系的同时,将历史水质信息进行记忆和传递,捕捉相关数据在时间序列上所产生的规律,从而多角度提升预测的效果。
1.3 Stacking集成模型
Stacking集成模型是一种多层学习模型〔13〕,该模型包含两层:第一层为基学习器层,由原理各异的多个算法组成;第二层为元学习器层,采用不易过拟合的算法将基学习层的预测结果进行整合。由于不同的算法具有不同的学习原理,因此预测的结果将表现出各算法独特的优势和弊端。Stacking集成模型通过集合多个算法、寻求多种意见、整合算法优势来进行决策,即使某个数据在某一个算法上预测的结果不理想,其他算法也可以将其修正,从而进一步提高模型的预测精度。因此,为发挥多算法的优势,获得一个更佳的预测模型,基、元学习器的选择至关重要。
1.4 性能评估
选取拟合优度R2评价上述回归算法的拟合度,均方根误差(Root mean squared error,RMSE)、MAE作为算法精度的评价指标。其中yi是实测值,y预测i是yi对应的预测值,yˉ是yi的平均值,计算公式如下:
1.5 主要参数的设置及模型搭建
Stacking模型是一种嵌套组合型的算法集成方法,具有强鲁棒性高泛化能力〔14〕,易产生模型训练与预测效果两极化的过拟合现象。为防止过拟合现象的发生,合理选取算法的参数至关重要。为获取单一算法的最佳参数组合,按照交叉验证的原理选取同时满足训练与验证在最小损失下的参数为该算法的最佳参数,最佳参数组合见表2。

表2 各算法的参数Table 2 The parameters of the algorithms
Stacking框架下建立多算法融合的污水处理厂出水总氮预测模型的流程见图1。
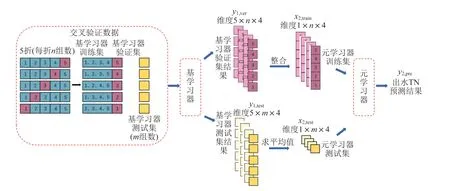
图1 Stacking流程Fig. 1 The flow chart of stacking
步骤1:在数据预处理的基础上将数据集分为三部分:训练集、验证集和测试集。其中,90%的数据利用K折交叉验证方法划分训练集和验证集,折数为5,即训练集与验证集比例为4∶1。剩余10%的数据用于构建测试集,共48组数据,其标签向量为目标出水总氮的实测值。
步骤2:利用训练集分别对LSTM、BP、SVR、XGBoost和KNN算法进行训练后,各算法使用测试集预测评估。依据评估结果选择4个算法为基学习器和1个算法为元学习器,初步建立Stacking的集成框架。
步骤3:在基学习器层,4个基学习器并行各交叉训练5次。训练完成后使用验证集进行验证,4个基学习器通过5次验证得到基学习层的验证结果,将其设为y1,ver。验证后利用测试集预测,其中测试结果由4个基学习器利用测试集数据在5次训练后测试得到,令其结果为y1,test。
步骤4:整合基学习器的验证结果y1,ver和测试结果y1,test。将y1,ver的5次验证进行纵向拼接,y1,test的5次测试集的预测结果取平均值分别作为元学习层训练集x2,train与元学习层测试集x2,test。
步骤5:在元学习层,步骤2所选择的元学习器利用x2,train进行训练,训练完成后利用x2,test进行测试,输出的测试结果即目标出水总氮的预测结果y2,pre。将y2,pre与目标出水总氮的实测值进行比较评估,评判该集成模型的拟合效果。
本研究采用python语言进行编译,使用谷歌TensorFlow项目库实现LSTM、BPNN算法模型设计,利用D. COURNAPEAU开发的Scikit-learn项目库实现算法建模。
2 结果与分析
2.1 基学习器的选择
合理评判学习器的性能有助于获取最佳的Stacking集成预测模型,优先选用预测性能较好的算法作为基学习器。为了降低模型因随机梯度下降而产生的预测偏差,对BPNN与LSTM分别进行10次训练和预测,并对每次预测结果进行评估。BPNN和LSTM均取10次预测结果的平均值为单一算法的最终预测结果。LSTM、BPNN、SVR、XGBoost和KNN的预测结果评估见图2。
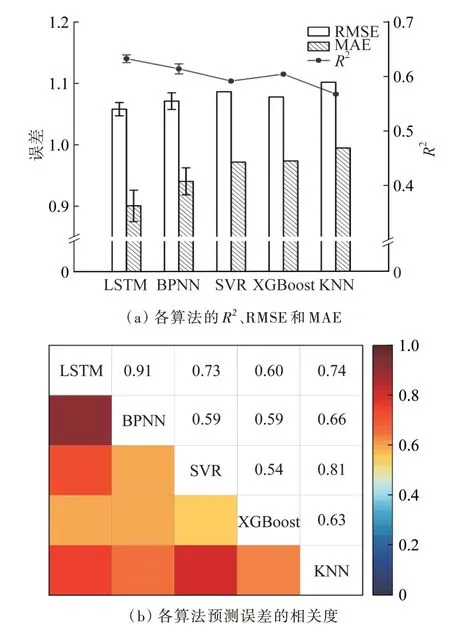
图2 LSTM、BPNN、SVR、XGBoost和KNN的预测结果评估Fig. 2 Evaluation of prediction results of LSTM,BPNN,SVR,XGBoost and KNN
图2(a)展示了单独使用LSTM、BPNN、SVR、XGBoost和KNN 5种算法的预测效果,且针对LSTM、BPNN的每次预测评估结果绘制3项评估指标的误差棒。可以看出,RMSE、MAE的变化趋势与R2相反。5种算法中,LSTM算法的预测效果最佳,RMSE、MAE和R2分别为1.06、0.900和0.633,同时从数据和时间两个角度构建关系展示了良好的预测性能。KNN算法的RMSE、MAE最大,R2最小,分别为1.10、0.995和0.567,与其他算法相比拟合程度偏低,可作为Stacking预测的元学习器。
从算法的差异角度考虑,通过各算法预测结果分析算法之间的相关性。令预测值与实测值之差为预测误差E(mg/L),通过计算得到E值且利用皮尔森相关系数反映各算法E值的相关强度。相关系数越接近1,表明算法的预测趋势越相近;相关系数越接近0,算法间E值的相关性越弱,体现算法的差异性。由图2(b)可知,各算法的E值存在差异且相关系数最低为0.54,最高为0.91,表明所选取算法学习训练能力较强,均达到了良好的预测效果。其中,LSTM算法和BPNN算法预测误差相关性最高为0.91,可能是因为激活函数相同且均为神经网络结构。同样,SVR算法与KNN算法均依靠将数据映射在高维空间进行预测,两类算法的预测误差相关性为0.81,显示两者在预测性能上具有一定的相关性。XGBoost算法在学习过程中基于树模型进行一阶和二阶导数迭代更新,与其他算法的训练方式不同,因此与其他4种算法的预测误差相关度较低。
综合考虑以上两方面,选择预测效果较好、预测误差相关性差异较大的算法作为基学习器,以保证集成模型的泛化能力,选择能避免集成模型过拟合的算法作为元学习器,完成Stacking集成模型的构建。因此,最终选取LSTM、BPNN、SVR、XGBoost 4种算法并列作为集成模型的基学习器,KNN算法作为集成模型的元学习器。
2.2 预测性能分析
为了进一步验证按2.1节所述方法进行学习器搭配的合理性,基、元学习器不同组合方式下Stacking集成模型的预测性能见表3。考虑到LSTM和BPNN预测结果需运行10次稳定,算法训练耗时且复杂程度高易出现过拟合现象,不适宜作为元学习器,故LSTM和BPNN算法仍为基学习器。依次选取KNN、SVR、XGBoost算法作为元学习器,分别形成了3种组合方式的Stacking集成模型。根据1.5所述流程对目标出水总氮进行预测,经计算,3种组合方式均在一定程度上缩小了预测误差,获得了更好的精准性。
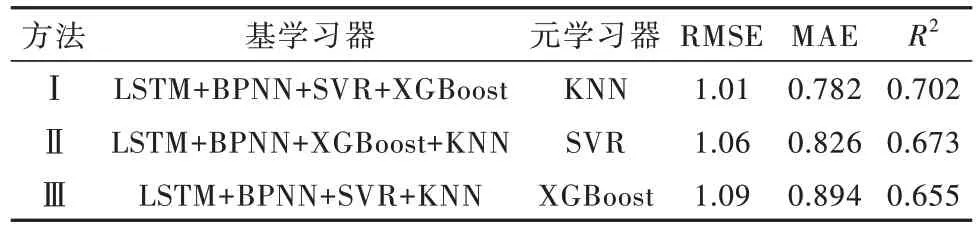
表3 基于不同基、元学习器的Stacking组合模型的预测效果Table 3 Prediction effect of Stacking models based on different base learners and meta learner
不同方法下出水总氮的预测结果对比见图3。图3(a)的点线图分别对应目标出水总氮的实测值和表3所示3种方法的预测值,柱状图通过预测误差E展示了实测值与各方法预测结果的差异。可以看出,柱状图中方法Ⅱ和方法Ⅲ所对应的E值是三者中较高的,表明两类方法存在较大的预测误差。相比单一算法中预测性能最好的LSTM算法,方法Ⅲ所形成的集成模型各项评估指标提升效果不明显(表3),由2.1节可知,XGBoost与其他算法的预测误差相关性最小,因此,当XGBoost作为元学习器时,Stacking集成不同原理算法的优势将被削弱。方法Ⅰ的MAE为0.782,在柱状图中预测误差普遍较小,其中,E值最小为0.008 mg/L,可以较准确、可靠地表达出水总氮的水质情况。观察图3(b)可知,方法Ⅰ与LSTM算法两者的预测趋势相似,但方法Ⅰ的预测结果比LSTM的预测结果更加逼近出水总氮的实测值,方法Ⅰ中有41 d的E值低于LSTM,占总预测天数的85.4%,展示了方法Ⅰ所使用的集成方法对LSTM预测结果的修正能力,体现了Stacking集成方式在融合算法的基础上实现预测效果的进一步优化。与2.1节所计算的LSTM算法评估结果相比,方法Ⅰ的RMSE、MAE分别降低了4.77%、15.1%,R2提升了10.9%,泛化性能更强,预测效果更优,因此进行Stacking集成时可利用方法Ⅰ优化出水总氮的预测效果。
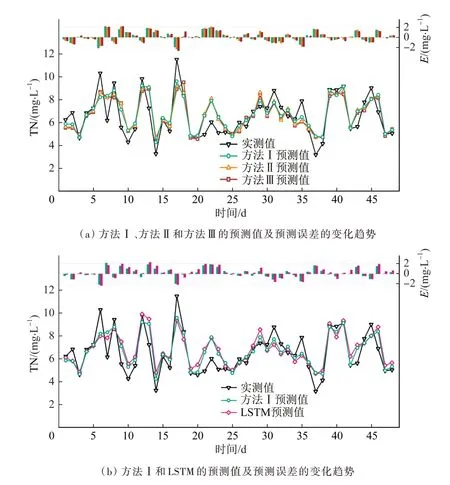
图3 不同方法下出水总氮的预测结果对比Fig. 3 Comparison of prediction results of total nitrogen in effluent with different methods
3 结论
本研究基于Stacking集成模型的思想,融合了机器学习和神经网络多种算法,提出了一种用于污水处理厂出水总氮预测的方法。从单一算法的预测性能和预测误差相关性两个角度出发,合理对基学习器和元学习器进行组合,最终选择以LSTM、BPNN、SVR、XGBoost作为基学习器、KNN作为元学习器的Stacking集成模型。经对比分析发现,该方法可将各算法优势结合在一起,在保证各算法学习能力的前提下泛化能力良好。从预测结果看,预测值与实测值趋势较为一致且拟合度高,证明通过该方法所建立的集成模型可对出水总氮情况做出合理的预测。除此之外,利用GRA对建模所使用的特征向量进行筛选,能依据污水处理厂的实际情况进行分析,具有一定的实践意义。因此,Stacking集成模型的优越性与可行性为污水处理过程中快速、准确地预先判断出水水质情况提供了途径。在未来工作中,可尝试将更多性能良好的预测算法进行融合,发挥算法的独特优势提升预测的精确度。在预测效果高精度的条件下,通过该集成模型可进一步探究由GRA所筛选出的特征向量与出水总氮的关系,为污水处理厂精准控制、提标改造等工程应用提供数据支撑。
