基于敏感路径的精确行为依赖图跟踪检测恶意代码
2023-07-15唐成华高庆泽强保华
唐成华,高庆泽,杜 征,强保华
1(桂林电子科技大学 广西可信软件重点实验室,广西 桂林 541004) 2(广西密码学与信息安全重点实验室,广西 桂林 541004) 3(广西云计算与大数据协同创新中心,广西 桂林 541004)
1 引 言
Web应用程序在给我们带来便利的同时,其暴露出漏洞的数量呈线性增长趋势,已成为网络攻击的主要目标,而导致安全风险的产生也正是因为漏洞和威胁的存在[1].尽管更广泛的Web应用程序风险Top10很有意义,但在如今由应用程序驱动的信息化世界中,作为研发创新的基本要素,应用程序编程接口(API)是Web应用程序、SaaS和移动服务的关键,由于涉及代码逻辑和敏感数据,快速创新的过程必须有安全API的保证,所以重点关注常见的API安全问题是非常重要的[2].作为一种资源交换方式,API越来越成为攻击者的目标,对敏感数据的恶意访问以及对代码行为的逻辑混淆也正是许多恶意代码的基本特征.
行为依赖分析对提取恶意代码的特征具有极大的作用,通过对指令层污点传播与行为层语义进行分析,获得系统调用和指令信息,并构建行为依赖关系图,从而提取恶意代码的行为特征,是识别恶意代码及其变种的有效方法[3].目前,污点分析是软件安全分析与推理中的重要研究课题,亦是可信软件研究的热点和难点.尽管在污点分析领域已有多方向的探索,但普遍的问题是,静态污点分析具有路径覆盖率高的优势但资源消耗过大,误报率较高,尤其是对分析恶意代码时会遇到代码混淆技术的阻碍,所以主要用于重点代码静态属性的辅助性评估和验证[4];动态污点分析则是实时监控污点数据的流动,检测数据能否从污点源传播到污点汇聚点,执行效率高但每次只能遍历一条路径,覆盖率较低.因此,往往采用静态分析与动态验证相结合的方法,形式化定义污点传播操作语义,以有效跟踪跨文件和跨页面的污点传播[5].
程序中的数据流、控制流,以及依赖关系等是软件代码的应用特征,通过挖掘这些特征信息,获取程序依赖、数据依赖、行为依赖、API调用关系及实例化等方面的特征和语义信息,从而得到软件中恶意代码的正确理解.
在程序依赖方面,依赖性分析是许多程序分析的基础,其中,程序依赖通常综合安全敏感API、系统调用、控制流结构和信息流等,为应用程序的行为提供一个独特的语义视图,能够在依赖关系图(如每个基本块、方法和类等)中量化它执行恶意活动的程度[6].当然,程序依赖分析要减少对程序执行中的扰动.Crussell等人[7]生成软件的程序依赖图,在不考虑代码混淆的情况下,基于语义信息检测相似APP的克隆性及恶意代码的注入性.
在数据依赖方面,基于依赖图的分析方法通常需要提取函数调用间的数据依赖,这种数据依赖关系能够清晰地描述程序的行为逻辑.应用于语义分析中的函数依赖发现,其本质体现的是数据属性之间的关系[8].Li等人[9]提出了一种快速数据依赖分析技术,允许跳过循环中重复执行的内存操作,可以降低部分时间开销,但此方法构建的数据依赖图包含大量与脆弱性分析无关的变量,降低了变量回溯的效率.吴礼发等人[10]同时分析了Java层和原生代码层的语义信息,通过提取原生方法函数调用路径、数据操作和敏感字符串等,进行数据流分析,判断是否存在敏感数据依赖关系,从而理解软件中的语义异常行为,以保护应用的良性,不过如果将数据流与控制流结合分析,可以更精准地理解Java层语义.Abbas[11]等人通过自适应的方式生成数据依赖图,为了避免由于代码插桩方式导致运行损失过高的问题,但这种自适应方式会损失一部分精度.实际上,在分析数据依赖时,由于语义可执行路径分支众多,极易产生路径空间的组合爆炸,使得代码检测的覆盖率充满挑战性,往往需要从路径分支选择与搜索算法上考虑[12].Lindner[13]等人均引入符号执行方法,对代码指令形式化语义描述后,通过控制依赖关系追溯路径的调用过程,针对存在敏感调用的路径进行约束求解路径条件,从而缓解路径爆炸问题.
在行为依赖方面,恶意代码体现某些或某种行为意图,通过对命令和行为的语义分析,提取关键行为并建立行为依赖或行为关联,这类基于行为特征的提取与检测是有效识别恶意代码的方法.行为序列可以看作一系列内在关联的函数调用,而恶意代码的行为是为达到某种获利目的的执行逻辑,表现为一系列敏感函数调用或代码段的执行[14].通过建立恶意代码行为依赖关系图是近年来检测恶意代码的有益尝试,不管是为恶意软件家族建立一个共同的行为依赖图[15],还是从恶意代码家族行为依赖图中挖掘出代表家族显著共性特征的最大频繁子图[16],均是基于污点跟踪的API系统调用行为间依赖关系的实现,用行为依赖图的匹配来判别恶意行为.当然,这些方法有一定的局限性,比如只观察可执行文件的部分行为,如果恶意软件在受监视的环境中运行时可以隐藏其恶意行为,则该方法无效.
在API方面,API被用来访问内、外部资源,其中恶意API调用频繁序列可被模式挖掘技术用来识别恶意软件行为的经验,从而建立恶意行为的基础.Jerbi等人[17]通过遗传算法进化出大量API调用序列,根据一组定义良好的进化规则来发现新的恶意软件行为,该检测方法的性能取决于恶意软件实例的基础多样化,因此需要人工加入一些恶意行为来丰富实例基础,以最大限度地提高检测率.Eiter等人[18]引入IO依赖关系的语义信息优化了API访问检查,直观地将调用外部源的结果中出现的值与提供给该调用的输入中出现的值联系起来,能更精确地近似真实的依赖关系,虽然在检查和优化依赖关系的属性时有一定的局限性,但在评估具有外部源访问的程序恶意代码时能显著降低成本.
总之,代码之间具有某种行为关联,即使是恶意代码及其变种结合了混淆和代码更改技术使其具有不同的语法结构,但在行为上仍具有相似性、序列性或某种依赖关系[19-21].在面对一些建模方法无法描述和分析的应用程序行为(如递归),也往往结合属性语法和数据流分析来捕获程序的行为并构建行为数据依赖图[22].本文借鉴于此通过动态污点传播分析提取恶意代码在进行API函数调用时的行为依赖关系,并结合自定义污点传播规则生成精确行为依赖图(Precise Behavior Dependency Graph,简称PBDG),特别的,将基于依赖关系的语义行为过滤,以及对程序代码的语义分析和动态污点分析紧密结合,以达成软件语义缺陷检测精度的有效性,从而挖掘Web应用程序中的潜在漏洞.通过污点分析技术深入研究程序的行为踪迹与执行路径,根据语义的数据依赖关系和控制依赖关系实现精确行为依赖关系和静动态结合的污点分析.
2 基本概念
定义1.函数调用可以用一个三元组sys_call={ret,arginput,argoutput}来描述.其中,ret表示函数调用的返回值,arginput表示函数调用的入口参数,argoutput表示函数调用的出口参数.
定义2.在污点传播分析中每个污点的状态可以用一个五元组Taint= {add,len,sta,type,p_info}表示.其中,add表示污点的起始地址,len表示污点长度,sta表示污点状态,type表示污点类型,p_info表示数据的上下文访问路径.
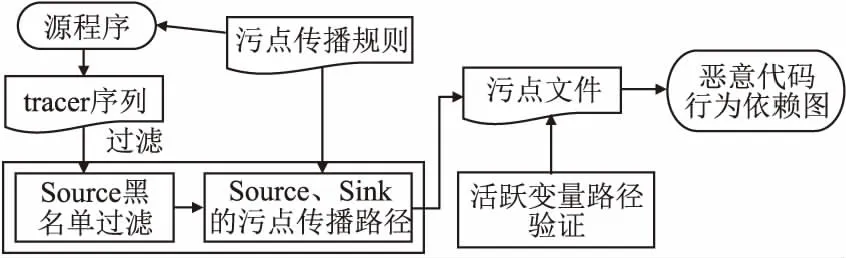
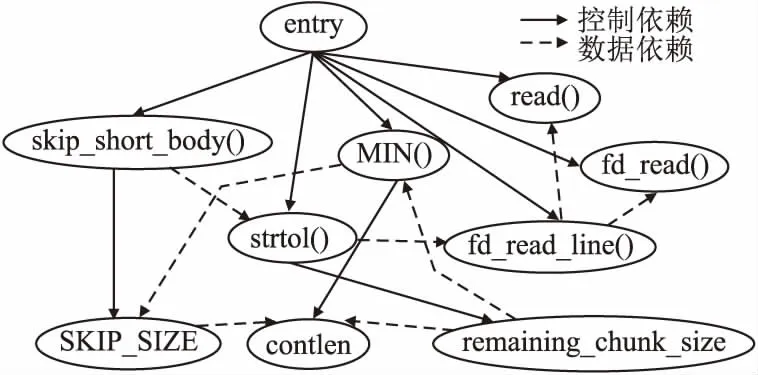
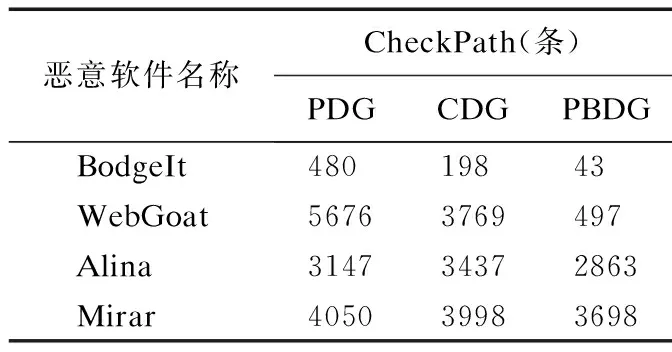
污点状态sta包括untaint(清洁)、taint(被污染)和malicious(恶意代码)3种,它们在受污染程度上满足untaint 定义3.ChTaint(a,status)表示为对污点变量a变换污点的状态.如果a的原先污点状态为untaint,则该操作称为被污染过程,表示为: 定义4.∃清洁变量a和上下文路径p,a位于p上,且α∉x.对于Tainta,存在a被标记或误报成疑似污点,如果经过算法1验证未被污染,则对起始地址为adda的污点数据进行污点净化,表示为: (ChTaint(α,taint))→(ChTaint(α,untaint)) 定义5.污点传播是将污点变量右值Rv的污点信息传递给左值Lv,表示为:τ(Lv)=τ(Rv). 为了提取恶意代码中的行为特征,本文通过污点文件,并结合恶意代码执行路径的验证实现精确行为依赖图的生成,应用于恶意代码的跟踪检测,其总体模型如图1所示. 图1 污点文件生成与验证模型Fig.1 Generation and verification of tainted file 首先,对恶意代码源程序进行动态污点传播分析,根据自定义的污点传播规则获取程序执行的相关信息,包括系统调用、函数调用及其参数的数据依赖关系和控制依赖关系,使用操作序列文件tracer来记录恶意代码函数调用间的关键数据.为了节省tracer文件占用的存储资源,与传统记录的方式不同,采用仅对新增指令引用的值进行记录的增量式文件存储方式.然后,对tracer文件进行过滤,对Source集合进行黑名单过滤,排除不属于外部恶意输入的Source,确保Source获取的值是真实的外部恶意输入,通过污点分析得到从Source到Sink的污点传播路径,对生成可配置的污点文件再利用活跃变量路径验证算法进行逆向的路径遍历来验证Sink→Source路径的准确性.经过验证后,对source到sink的不可达路径进行剪枝处理,在降低路径爆炸风险的同时,能节省计算资源,并提高路径验证的准确率. 通过污点传播分析可以分析相应的攻击行为,能够提取攻击信息.通过自定义的污点传播分析规则对函数调用中的敏感数据进行污点跟踪,得到行为之间的依赖关系,用于活跃变量路径验证. 首先定义一个taint集合用来动态存储污点变量信息,将经过黑名单过滤的Source集合中的污点变量加入taint集合中.其次进行污点传播分析,对污点数据进行跟踪,根据自定义的污点传播规则记录污点的传递过程,对一些具有特殊功能的函数增加控制依赖性分析,例如拷贝函数strcpy、strcat,内存分配函数mallco、calloc,以及调用过程会间接影响其它函数的调用从而导致隐式流产生的函数setjmp、longjmp等.基于定义5,设定污点对相应变量进行赋值与调用等操作的规则,这些规则针对形如“Lv=Rv”的变量表示,获得污点变量左值Lv的状态. 规则1.赋值规则 ① 若右值Rv为常量,通过以下赋值可以消除Lv的污点状态. τ(Lv)=untaint ② 若右值Rv形如Lv= arr[i](数组元素),Rv的污点状态为对所有数组元素污点状态求并集. τ(Rv)=untaint τ(Rv)=τ(Rv)∪τ(i) τ(Lv)=τ(Rv) fori=1,…,n ③ 若右值Rv形如Lv=b.v(对象实例的成员变量)/Lv=class.v(全局静态变量),Rv的污点状态为对所有使用变量污点状态求并集. τ(Rv)=untaint τ(Rv)=τ(Rv)∪τ(vi) τ(Lv)=τ(Rv) fori=1,…,n 规则2.方法调用规则 ① 对于形如x=invoke a.f(arg1,arg2)的方法调用首先判断是否有参数,若无参数,则按下式直接返回对象属性a.x的值. τ(Lv)=τ(a.x) ② 若有参数,且实例对象a或任意参数污点状态为taint或malicious,则对所有参数污点状态求并集. τ(Rv)=τ(a) τ(Rv)=τ(Rv)∪τ(argi) τ(Lv)=τ(Rv) fori=1,…,n 在Java中存在许多后门(敏感)函数,它们是针对不同的漏洞而存在.例如eval()、system()等代码执行函数;又如ServletFileUpload()、FileItemStream()、MultipartFile()等文件上传函数; 还有getRuntime()、exec()、cmd()、shell()等命令注入函数; 以及Delete()、deleteFile()、fileName()、filePath()等任意文件删除函数;另有SAXBuilder()、DocumentBuilder()、XMLStreamReader()等XML注入函数,这样一些具有特殊功能的函数经常被作为攻击的调用.因此,对于这些危险的或关键的函数类建立一个可配置的动态黑名单文件写入Source集合中.随着新的恶意函数被发现,黑名单信息量将不断扩充. 将外部恶意输入的数据标记为污点起源Source,而将可能破坏数据完整性、机密性的方法标记为污点汇聚点Sink.在web应用程序中,Source多数来自GET变量、表单POST、数据库、会话变量等. 在检查恶意代码时,本文首先通过动态污点传播分析,对其运行一系列的自动测试.测试会生成tracer序列,将tracer序列中的敏感函数引入到污点起源Source中,当然,其中并非所有函数都具有恶意行为.例如,引入的Source信息可能是用于操作系统登录过程的按键,也可能是Web表单中的用户输入.因此对污点起源Source进行预处理来排除非恶意行为的输入.通过在污点分析过程中添加Source黑名单,主要对黑名单中的方法进行记录,过滤黑名单以外的函数,将不属于恶意输入的Source过滤掉,节约存储空间的同时提高检测效率.对Source过滤之后建立一个污点索引文件,由于被标记污点的变量都包含add起始地址与len长度的标记,应用此索引文件可以快速定位到指定的指令,应用于后文的活跃变量路径验证算法中,提高验证效率. 对污点索引文件中生成的Source→Sink路径进行活跃变量路径验证,使用活跃变量路径验证算法逆向遍历,对所生成的污点路径进行验证.经验证后对不真实存在污点传播的路径进行污点净化,以进一步降低路径空间. 定义6.活跃变量分析计算:∃α,ξ,t(α表示变量,ξ表示程序点,t表示ξ的执行路径),若在t中发现α(记为〈α∝t〉)则说明α在程序点ξ是活跃的.其中,Input表示入口处活跃变量的集合,经过逆向数据流求解后,将α之后的活跃变量集合作为Output.存在下式: Input[a]=ηs(Output[a]) (1) 其中,ηs为传递函数,描述代码执行前后的数据流值在输入输出后变化的语义约束. 定义7.genB表示变量在基本块Bi中被定义的活跃敏感参数定值集合(从Sink集合中选出),killB表示在基本块Bi中不活跃的变量集合,succ(B)表示基本块B的所有后继基本块的集合.存在下式: Input[B]=genB∪(Output[B]-killB) (2) (3) 根据定义6,计算分析得到基本块中活跃变量的Input与Output集合,通过路径敏感的上下文分析以及对Input进行跟踪可以得到从程序控制流图终止点end到起始点start的逆向执行路径(即Sink→Source路径),便可以验证路径的准确性,从而提高分析的准确率. 活跃变量的OutputgenB上下文可以用{Funcall,SensiveP,Blockid,Valuecon,pathtrav}的形式表示,其中Funcall表示所调用的函数,SensiveP表示敏感参数(Sink集合),Blockid表示所在的基本块号码,Valuecon表示定值信息,pathtrav表示路径遍历信息.一段存在验证漏洞的java代码如图2所示,通过上述的表示形式可以很好地对路径进行验证. 图2 含有漏洞的java代码Fig.2 Section of java code with vulnerability 根据图2,分析后可以得到相应的控制依赖关系,如图3所示.此段代码中存在两个注入点name和pwd(记为Source点),但是最终赋值给了变量login(记为Sink点),所以将login标记为敏感参数,并将login加入genB集合中. 图3 代码的控制依赖图Fig.3 Control dependency graph of a piece of code 图3中显示的是将敏感参数login作为活跃变量来进行路径验证.根据公式(2),显然可以得出Input[B]={logingen}∪(Output[B]-loginkill).利用控制依赖关系可以得出InputB1={02,03,04,05}.继续迭代循环基本块B2,B3,B4,B5.得到InputB5={05,07,09,10,11}.经过分析得到B5的输出流来源于定值05,通过查找定值表(如表1所示),定值05所在的变量得知,05定值来自变量name.所以name在Source点是活跃的,即Sink→Source路径验证真实可达.Outputlogin={print,login,B5,11,(11→10→09→07→05→04→02)}.其中print是所调用的函数Funcall,login为敏感参数SensiveP,逆向追踪遍历路径pathtrav为(11→10→09→07→05→04→02).路径验证算法用于逆向遍历从敏感参数到程序开始的路径(即从sink到source).图3控制依赖图中的变量名与定值对应关系如表1所示. 表1 变量名与定值关系表Table 1 Relationship between variable name and value 算法1.活跃变量路径验证算法. Input:控制流图CFG中已求出的每个基本块的活跃敏感参数定值集合genB、不活跃变量集合killB; Output:验证后的逆向遍历路径信息pathtrav. Begin { 1.Input[end]=φ; /*end节点为程序的出口*/ 2.for eachBin CFG do /*遍历控制流图*/ 3. Input[B]=φ; /*对基本块初始化*/ 4.end for 5.change=true; /*用change记录Input变化*/ 6.while(change) do 7. change=false; 8. for eachBin CFG do 10. old=Input[B]; 11. Input[B]=genB∪(Output[B]-killB); /*过滤掉即将重新赋值的killB*/ 12. if(old!=Input[B]) then change=true; 13. end for 14.end while 15.for eachBendin CFG do 16. pathtrav=Output[Bend]; /*遍历最后基本块并取Output首元素*/ 17. print pathtrav; /*输出逆向遍历路径*/ 18.end for }End 算法1采用活跃变量计算分析逆向传播定值,直到此定值被过滤掉,算法才停止.因为对于每个基本块B,Input[B]被初始化为φ,迭代过程中Input[B]不会减小,所以当有定值加入到Input中不会存在丢失的情况.如果一个定值能够到达程序点,则它必须经过一条路径.使用迭代的方法求解,在while的每次迭代过程中,每个定值至少沿着相应的路径前进一个点.由于定值的集合是有限的,所以算法终止的标志为while循环执行后没有再向Input中添加内容,算法结束时输出此时的遍历路径. 基于污点文件生成精确行为依赖图,考虑了路径敏感的污点分析方法.为了避免控制依赖干扰数据依赖的情况发生,所分析的依赖关系既包括数据依赖关系也包括控制依赖关系. 定义8.精确行为依赖图可以用一个四元组G=(Entry,P,DE,CE)来表示.其中,Entry表示图的入口节点,P表示节点,DE(满足DE∈P×P)表示数据依赖边,CE(满足CE∈P×P)表示控制依赖边. 数据依赖边DE的添加要通过活跃变量路径验证算法反向验证产生污点的函数调用与其相关联的节点,并在两个节点之间添加一条数据依赖边.控制依赖边CE的添加则是分析具有污点属性的数据是否对标志寄存器EFlages改变,可以通过检查污点信息中的type字段是否为0来判断.若标志寄存器作为污点分析控制流转移的判别条件,计算新的函数调用在其后必经节点所在的范围内,则在两个顶点之间添加一条控制依赖边.若在某个函数调用中,既存在数据依赖又存在控制依赖,则在两个节点间添加两条依赖边. 定义9.通过对污点文件的分析,查看函数调用中的污点传播路径,给定两个已知的节点P1和P2,当且仅当P1和P2之间存在数据关联关系并且P1调用了P2,则在精确行为依赖图中记录P1与P2的数据依赖关系,记为DE(P1|→P2). 定义10.程序在运行的时候,会出现新的顶点P3被调用,这时需要考虑程序的跳转问题.通过分析带有污点属性的数据是否有通过控制转移指令进行直接或者间接的跳转.若路径t处于P3、P4两个节点之间,当仅存在一条执行路径从节点P3到程序结束且经过P4,则P4控制依赖于P3,记为:CE(P3|→P4). 算法2.精确行为依赖图构建算法. Input:污点文件(TF); Output:精确行为依赖图PBDG. Begin { 1.for each funcalin TF do /*遍历TF中的函数调用*/ 2. add funcal(pi); /*添加节点p*/ 3. for each controlrel in TF do /*遍历TF中的控制依赖*/ 4. add controlrel(Bi); /*添加基本块B*/ 5. end for 6.end for 7.for each Biin funcaldo 8. if(p1|→p2) then 9. PBDG.add-DE(p1,p2); /*添加数据依赖边*/ 10. end if 11. if(p3|→p4) then 12. PBDG.add-CE(p3,p4); /*添加控制依赖边*/ 13. end if 14.end for }End 算法2首先对TF文件进行分析,其中的函数调用关系用funcal表示,controlrel表示控制依赖,通过对污点文件中的控制流图进行遍历,若符合定义中的DE(P1|→P2),则在节点p间添加数据依赖边.若出现CE(P3|→P4),则在节点间添加控制依赖边.当对污点文件分析结束时,算法生成最终的PBDG. 精确行为依赖图PBDG提供了精准的行为依赖关系分析,能有效提高恶意代码的识别率.当前,出现溢出漏洞的主要原因是由于不安全函数的调用所引起,可以使用PBDG对溢出漏洞进行验证.以CVE-2017-13089栈溢出漏洞为例,2017年11月12日NVD公布了关于wget的漏洞情报,对wget缓冲区溢出漏洞进行分析.该漏洞主要是由于wget组件在处理401状态码的数据响应包时,没有对读取的包做正负检查,导致的整数栈溢出.wget在处理重定向时,会调用skip_short_body()函数,解析器在解析块时会使用strtol() 函数读取每个块的长度,但并没有去检查块长度是否为负数.解析器试图通过使用MIN()函数跳过块的前512个字节,最终传递参数到函数fd_read()中.由于fd_read()仅会接受一个int参数,当攻击者试图将一个负数作为参数时,块长度的高32位将会被丢弃,攻击者从而可以控制fd_read()中的长度参数,引发整形缓冲区溢出漏洞. 可以把skip_short_body()看做Source点,fd_read()看做Sink点,对skip_short_body()函数进行分析.首先该函数对于传入的第一个参数sock获取到http响应包的响应体指针line;然后调用strtol函数,将line变量指的值转为整型;接着通过MIN(remaining_chunk_size,SKIP_SIZE)得到响应体的长度contlen;之后调用fd_read函数,将响应体内容复制到栈中;fd_read函数封装了sock_read函数,sock_read函数调用了read函数,从这里出现了栈溢出漏洞.通过对相关函数的调用分析,生成精确行为依赖图,如图4所示,描述了多个函数相互作用而构成的数据依赖关系与控制依赖关系.基于PBDG对代码进行分析,与传统的PDG方法等相比,能获得更加清晰的数据流,检测的路径更加精确. 图4 相关函数的精确行为依赖图Fig.4 Precise behavior dependence graph of correlation function 实验所用的机器配置为Intel i5-8500CPU系统为windows10操作系统,开发环境基于JDK 7,Soot-2.5.0,工具为Eclipse,编程语言为java.恶意代码行为依赖图的构建是基于模拟器SOOT平台实现的,通过在虚拟系统中对代码进行动态分析,对执行的代码进行审计.实验数据集选取的是两个Web漏洞网站WebGoat和BodgeIt以及另外两款用作对比参照的恶意软件Alina和Mirai. 4.2.1 实验过程 首先结合使用Selenium自动化测试工具分别对上述4种数据集构建恶意代码行为依赖图,作为对照,选取传统的行为依赖图PDG[3]和公共行为依赖图CDG[15]的构建方法,与所提出的精确行为依赖图PBDG在构建规模和时间上的情况,如表2所示.然后在依赖图的生成质量和对敏感路径的处理上进行比较验证. 表2 依赖图的构建时间与规模Table 2 Construction time and scale of dependency graph 从表2可以看出,由于PBDG方法过程通过上文提出的Source黑名单构建和过滤机制,以及受到自定义的污点传播规则的限制,所以检测到的函数调用数量远少于传统PDG方法,略优于CDG方法,构造出的依赖图边数与节点数有了明显的减少,避免路径爆炸,有效节约了空间开销.由于CDG采用从依赖图中提取行为图的方法,所以在依赖图的构建方面比传统依赖图PDG和PBDG方法要消耗更多的时间. 4.2.2 依赖图生成质量对比分析 通过对3种构建方法生成的行为依赖图进行Source→Sink静态分析,验证污点路径的准确性,进而降低漏洞的误报率.在对依赖图分析后获得的漏洞报告情况如表3所示. 表3 依赖图生成质量的表现(个)Table 3 Generation quality of dependency graph BodgeIt中实际共有15个漏洞,根据表3可以看出,通过算法2构建的精确行为依赖图分析,报告出共13个漏洞,对其进行活跃变量路径验证分析后,验证出其中12个漏洞报告准确,误报1个漏洞.WebGoat中实有30个潜在漏洞,报告出27个漏洞,经过验证其中有2个漏洞为误报.Alina中实有35个漏洞,分析出26个,其中有5个漏洞被验证为误报.Mirai中实有42个漏洞,经算法2分析出30个漏洞,其中有7个漏洞误报.由于本文方法主要应用于对Web应用中的漏洞分析,所以在BodgeIt和WebGoat中发现漏洞以及漏洞误报明显优于传统的PDG方法和CDG方法.但是在对恶意软件Alina和Mirai中发现的漏洞与漏洞误报比PDG方法略好,而CDG由于采用了基于最大权子图的图匹配算法用加权图来描述恶意软件家族的常见行为,通过牺牲时间来换取一定的恶意软件漏洞检测率. 测试网站WebGoat中有SQL注入漏洞代码如下: final String kid=(String) header.get("kid"); try(var connection=dataSource.getConnection()){ ResultSetrs=connection.createStatement().executeQuery ("SELECT key FROM jwt_keys WHERE id=′" + kid + "′"); while(rs.next()){ return TextCodec.BASE64.decode(rs.getString(1));} } 实验采用PDG传统方法构建行为依赖图未能发现该漏洞.由于WebGoat使用了预编译方法PrepareStatement调用函数,将数据代码分离,且通过BASE64.decode()函数进行BASE64解码,使得传统方法无法识别;而采用PBDG方法通过黑名单构建和过滤机制成功检测出预编译PrepareStatement调用函数,以及BASE64.decode()函数,再通过路径验证算法遍历路径,可以成功建立路径Sink(key)→Source(kid),最终发现SQL注入点kid. 更直观的,给定准确率用∂表示,按下式计算: ∂=n/N (4) 其中,n表示确定为漏洞的数量,即发现漏洞的数量减去误报的数量,N表示实际存在的漏洞个数. 误报率用μ表示,按下式计算: μ=e/E (5) 其中,e表示漏洞误报的数量,E表示实际存在的漏洞个数. 不同方法对目标漏洞检测的准确率和误报率如图5和图6所示. 图5 对数据集的检测准确率Fig.5 Detection accuracy of four data sets 由图5和图6可以看出,本文方法在发现漏洞的准确率与误报率均好于传统方法PDG,但是由于本文方法主要面向Web应用漏洞,所以在针对后两款恶意软件检测时,采用了共性行为依赖预处理的CDG方法的准确率与误报率优于其他两种,但此时PBDG与PDG相比仍有较好的表现. 4.2.3 路径验证对比分析 经过活跃变量路径验证算法验证后,能够有效地对Source→Sink的不可达路径进行剪枝.通过与其他两种方法对比检查Source→Sink的路径数量如表4所示,通过本文活跃变量路径验证后需要遍历的路径有明显的减少,最高减少了91.2%,最低减少了8.7%.由于Source的黑名单后门函数是针对Web应用的,所以对于两款恶意软件的Source没有进行有效的过滤,在后两款恶意软件中需要验证的路径数与其他两种相比没有得到明显的减少. 表4 路径检验条数Table 4 Number of check paths 总体来说,本文提出的PBDG构建方法,可以有效提高漏洞发现的准确率,降低误报率.经过分析后,需要验证的路径明显少于其他两种方法,但在图构建时间方面还有待提高. 4.2.4ACCmin对依赖图生成质量的影响 ACCmin为最小精确值,定义如式(6)所示. (6) 随着PBDG依赖图的构建的扩大,活跃变量路径验证算法中定值Valuecon和InputBend(其中下标Bend表示最后一个基本块)也不断变化,准确率∂和误报率μ也会随着发生变化.在Web应用中,通过调整ACCmin的值,发现准确率∂和误报率μ发生如图7变化. 图7 准确率与误报率随ACCmin的变化情况Fig.7 Changes of accuracy and false rate with ACCmin 从图7准确率与误报率随ACCmin的变化情况中可以看出,当ACCmin=0.4时,准确率达到最高83%;当ACCmin> 0.4时,准确率开始出现明显下降趋势.当0.4≤ACCmin≤0.5时,误报率最低为7%;ACCmin> 0.5时,误报率出现了小幅的上涨.因此,综合分析准确率∂和误报率μ的情况,将最小精确值ACCmin设置为0.45,误报率与准确率效果达到最佳. 提出了精确行为依赖图PBDG的构建方法,并基于该方法实现了恶意代码行为依赖图的构建,与传统的行为依赖图构建相比,其相关数据的控制依赖关系与数据依赖关系更加清晰,活跃变量路径的引入,优化了路径分析过程.实验结果表明该方法在多种实验数据集中的有效性,尤其在对Web应用程序进行检测时效果更好,能有效地提高漏洞发现的准确率,降低了漏洞的误报率.由于本文使用污点分析与活跃变量路径验证,所以要分析更多的指令,在指令分析的优化方面需得到有效提高.下一步工作将符号化污点分析与代码混淆技术结合进来,对包括Web漏洞和恶意软件等具有变种的恶意代码进行更好的检测.在不影响准确率的情况下,进一步缩短依赖图构建时间和遍历时间.
3 基于污点文件的依赖图生成与验证
3.1 自定义污点传播规则
3.2 Source黑名单构建
3.3 Source黑名单过滤
3.4 活跃变量路径验证算法




3.5 生成恶意代码精确行为依赖图
3.6 应用PBDG分析漏洞
4 实验过程与分析
4.1 实验环境与数据
4.2 实验结果及分析




5 结 论
