融合情感特征的在线学习成绩预测研究
2023-07-15李慧
李 慧
(首都师范大学 教育学院,北京 100048)
1 引 言
作为一种重要的开放型教育方式,基于信息技术的在线教育已经成为当代数字化教学的主流.MOOC、SPOC、Moodle等大型开放式在线学习平台及各高校自主建设的在线课程平台、在线学习管理系统,采集线上教学、学习活动的行为数据,记录学习者的学习行为、学习轨迹和学习环境,不仅为学习者提供在线学习的便捷途径,而且为教师及教学管理人员改进教学策略、完善教育管理机制提供科学的数据支持.基于在线学习者产生的大规模学习数据(如:学习行为轨迹、学习结果数据等),如何评估其在线学习效果、预测学习成绩、实现学业预警,进而为教学决策提供依据,是在线教育亟需解决的重要课题[1-7].
在线学习成绩预测研究主要采集在线学习者的客观统计数据、学习行为数据等.数据来源包括系统数据、日志文件、文本、音频、视频等,具有容量大、多样性、动态性等特点,能多角度地真实呈现学习者的在线学习状态.目前已提出的在线学习成绩预测方法主要分为3类:1)基于概率的在线学习成绩预测;2)基于传统机器学习(Machine learning)的在线成绩预测;3)基于深度学习(Deep learning)的在线成绩预测.
基于概率的在线学习成绩预测研究集中于知识追踪技术,主要采用学习者的既往学习行为数据,利用概率模型预测其学习成绩.知识追踪技术分为基于贝叶斯的知识追踪[8]、基于Logistic模型的知识追踪[9]和基于深度学习的知识追踪[10].其中,基于贝叶斯的知识追踪包括贝叶斯知识追踪(BKT)和扩展的BKT模型;基于Logistic模型的知识追踪包括项目反应理论(IRT)和因子分析模型;基于深度学习的知识追踪包括深度知识追踪(DKT)、改进的DKT模型等.传统的知识追踪技术采用概率模型,将学习者的知识掌握程度预测看作概率分布问题,使用的参数具备语义含义,具有强大的可解释性.
基于传统机器学习的在线学习成绩预测,利用关联分析、分类、图理论、矩阵分解、增量学习等技术预测学习者的学业成绩.Pardos等[11]研究了2786位学习者在3年内的81万条网络学习操作,构建学习状态与行为操作的关系模型,进而预测年终学习结果.Amrieh等[12]通过分析学习者在论坛中的讨论数、发贴数、资源访问数、阅读材料时长等在线学习行为,采用分类算法对学习成绩进行分类预测,发现在线学习行为与学习成绩之间存在密切关系.张琪等[13]采用回归算法和分类算法分析在线学习行为特征并预测学习者成绩,发现过程性评估成绩是最重要的预测变量.Qiu等[14]在统计学习者基本信息、分析过程性学习行为数据的基础上,基于动态图理论预测学习者的在线学习成绩,取得了良好效果.Gómez-Pulido等[15]利用矩阵分解和梯度下降算法构建学习者成绩预测模型,通过优化潜在因素、学习率和正则化因子等提高预测精度.罗杨洋等[16]使用增量学习的随机森林算法构建混合课程的学习者成绩预测模型,在样本数量较多的数据集中获取了理想的预测准确率.
近年来,基于深度学习的在线学习成绩预测已成为研究和应用的热点.Nabil等[17]探索深度学习在教育数据挖掘领域的效率,开发学习者的成绩预测模型,用于识别有学习失败风险的学习者.Liu等[18]充分利用学习者的行为特征和练习特征,融合注意力机制与深度知识追踪模型(DKT),提出学习者成绩预测框架,采用基于递归神经网络的注意力机制模拟学习者的学习过程并预测其学习表现,在真实数据集上的准确率高达98%.Feng等[19]提出一种上下文感知特征交互网络,使用上下文平滑技术对上下文特征进行平滑,融合注意力机制建模和预测MOOC中用户的退出行为.与前两类学习成绩预测模型相比,基于深度学习的预测模型在性能上具有显著优势,但可解释性较差,既难以清楚阐明隐藏状态的涵义,也难以从隐藏状态确定学习者的知识掌握程度.
上述研究主要考虑了学习行为数据而忽略了学习者在学习过程中的情感状态,如:学习体验文本、面部表情、肢体动作等所体现出来的情感信息或情绪体验.其中,学习体验文本中蕴含的情感信息对学习者成绩预测将产生重要影响,有效地利用情感特征能提升成绩预测的精度[20-22].但目前多数研究仍局限于定性分析情感因素的作用或文本数据的情感提取,结合学习者的情感特征定量预测学习成绩的研究亟需深入.本文首先采集学习者在学习过程中产生的文本数据,构建基于自注意力机制的BiLSTM文本情感分类模型,由词嵌入层、语义学习层、权重调整层和情感分类层组成,提取学习者的情感特征;然后融合情感特征、人口统计特征和学习行为特征,获取完备的学习者特征;最后采用LSTM循环神经网络构建学习状态模型,进而定量预测学习成绩.本文的主要贡献在于提出了融合情感信息的学习者特征提取方法,利用LSTM循环神经网络建模学习者在时间序列上的动态学习状态,实现在线学习成绩预测,并定量分析情感信息对学习者在线学习成绩预测的影响.
2 概念及问题描述
2.1 基本概念
设某在线课程包含K个知识点;L为在线学习者集合,|L|=N,其中N为在线学习者的总数.定义学习者Li在知识点k上的学习者特征向量xk(i)和学习状态向量yk(i).
定义1.学习者特征.令xk(i)=[xi,k,1,xi,k,2,…,xi,k,n]T表示学习者Li在知识点k上的学习者特征向量,由学习者的人口统计特征fpk(i)、学习行为特征fbk(i)和情感特征fek(i)融合而成,共n个维度;其中,人口统计特征fpk(i)由学习者的年龄、性别、教育层次、专业背景等特征构成;学习行为特征fbk(i)由学习者的登录次数、在线时长、下载文件数、提交作业数、观看视频时长、论坛发贴数、回复数、参与讨论数、课堂测验成绩等特征构成;情感特征fek(i)为学习者Li在知识点k上发表文本所体现的情感特征.因此,在线学习者特征向量可以表示为xk(i)=[fpk(i);fbk(i);fek(i)],实际应用中fpk(i)和fbk(i)通过系统数据和日志文件抽取获得,fek(i)由情感分类模型计算.
定义2.在线学习状态.令yk(i)=[yi,k,1,yi,k,2,…,yi,k,m]T表示学习者Li在知识点k上的学习状态向量,共m个维度;其中yi,k,j∈[0,1]为学习状态向量的第j个维度,代表学习者Li对课程知识点k相应能力维度j的掌握情况,数值越高代表掌握得越好.所有学习者的学习状态组成一个N×K×m维的向量.
定义3.在线学习成绩.令g(i)为学习者Li的在线学习成绩,g(i)∈[0,1].将学习者的在线课程成绩(如:百分制、等级制等)映射到区间[0,1].
2.2 问题描述
根据上述定义,基于深度学习的在线学习成绩预测问题,其输入为所有学习者的特征表征X,包括任一学习者Li在知识点k上的人口统计信息pk(i)、学习行为信息bk(i)和文本信息ek(i),进而抽取出学习者特征向量xk(i);输出为所有学习者的学习成绩g.本文基于深度学习理论,构建一种在线学习成绩预测框架,如图1所示.其主要工作包括:1)根据学习
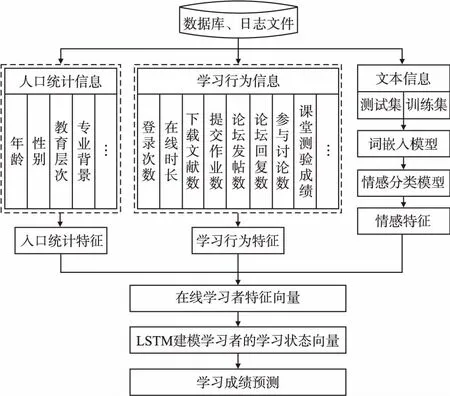
图1 在线学习成绩预测框架图Fig.1 Online achievement prediction framework
者的基础信息pk(i),抽取其人口统计特征fpk(i);2)挖掘学习者在网络学习过程中产生的学习行为数据bk(i),抽取其学习行为特征fbk(i);3)针对在线学习平台中学习者发布的文本,提出一种基于深度学习的文本情感分类模型,获取学习者的情感特征fek(i);4)融合人口统计特征fpk(i)、学习行为特征fbk(i)和情感特征fek(i),得到在线学习者特征向量X,能够全面展现学习者画像;5)将每个知识点k的在线学习者特征xk(i),作为LSTM模型的输入,获得学习者Li在不同知识点k上的学习状态yk(i),进而预测学习者的在线学习成绩g(i).
3 在线学习成绩预测
3.1 基于自注意力机制的BiLSTM文本情感分类模型
本文构建了基于自注意力机制的BiLSTM文本情感分类模型,由词嵌入层、语义学习层、权重调整层和情感分类层组成,如图2所示.其中,词嵌入层将学习者发表的文本转换为词向量,输入到神经网络模型中;语义学习层由双向长短时记忆循环神经网络(BiLSTM)构成,对文本的上下文语义信息进行编码,获取语义特征;权重调整层采用自注意力机制(Self-Attention Mechanism)识别不同语义特征对情感分类的贡献,并获取加权的语义特征;情感分类层使用softmax函数获得文本属于不同情感类别的概率,进而确定其情感分类.下面具体描述该模型.

图2 基于自注意力机制的BiLSTM文本情感分类模型Fig.2 Text emotion classification model based on self-attention mechanism and BiLSTM
3.1.1 词嵌入层
词嵌入是将文本中的词汇转化成数值向量的方法,包括One-Hot编码、信息检索技术、分布式表示等.Word2vec是最常用的词嵌入模型之一,通过训练将文本中的每个词汇映射为一个n维实数向量,即将高维数据(维数为词数N)降为低维数据,最终生成词向量.Word2vec模型的效果一方面依赖于中文分词的准确率,另一方面依赖于大规模训练语料的长时间训练,因此可以使用开源的大规模数据集进行训练得到词向量,也可以使用预训练好的词向量.本文首先使用中国科学院计算技术研究所研发的汉语分词系统NLPIR进行中文分词,对分词后的数据建立字典;然后采用腾讯AI Lab公开的中文词向量数据,依据构建好的字典从中提取相应的词向量,最后建立词向量矩阵.
设学习者Li在知识点k上发表的文本为tk(i)={s1,s2,…,sp},其中sj={wj1,wj2,…,wjlj}表示文本中的第j个句子,wjk表示句子sj中第k个词汇,lj是句子sj的词数.采用Word2vec模型,将句子sj转化成词向量序列sj={vj1,vj2,…,vjq},其中vjk表示词向量,q是词向量的维度.
3.1.2 语义学习层
中文文本的上下文之间存在明显的语义关系.为了同时考虑文本的上下文语义,全面提取文本特征.在语义学习层,将原始文本经过词嵌入层获得词向量序列后,构建双向长短时记忆循环神经网络BiLSTM,对句子的语义信息进行编码.BiLSTM是长短时记忆循环神经网络LSTM的拓展,由正向LSTM和反向LSTM组成,采用双向LSTM机制对句子进行建模,提取出比LSTM更丰富的上下文语义特征,具有较强的长距离语义捕获能力.BiLSTM的输入为词向量,隐含层包含正向传播层和反向传播层,分别学习当前文本的上文语义和下文语义,把上层网络输出的向量作为本层的输入,通过双向传播层输出语义特征.BiLSTM分别通过隐含层的正向LSTM和反向LSTM得到t时刻的隐态输出向量,其矩阵表示为hr和hl,则BiLSTM在t时刻的隐态输出向量Bt可表示为连接正向LSTM和反向LSTM输出向量hr和hl,即:
Bt={hr,hl}
(1)
3.1.3 权重调整层
由于词向量及其语义特征并不能平等地反映学习者的情绪特征,即不同词向量及其语义特征对学习者情绪表达的重要性不同.因此,在权重调整层采用自注意力机制,调整BiLSTM模型输出语义特征的注意力权重,对关键的语义特征赋予更大的权重;采用自注意力机制,将BiLSTM模型产生的隐态输出向量再次编码,提取出更高层次的特征.自注意力机制是注意力机制的一种,传统的注意力机制依赖部分外部信息,而自注意力机制通常不使用额外信息,仅通过训练自身信息来学习参数、获取权重分布.语义特征的注意力权重αt计算如下:
(2)
vt=tanh(W1Bt+b1)
(3)
其中,vtA为得分函数,用于计算语义特征重要性得分;Bt为BiLSTM在t时刻的隐藏状态;A、W1均为权值矩阵,b1为偏置向量.

(4)
3.1.4 情感分类层
文本情感分析的本质是一个分类任务.因此,基于自注意力机制的BiLSTM文本情感分类模型的最后一层是情感分类层,其输入为加权后的语义特征向量.使用softmax作为激活函数,经过softmax函数获得文本属于不同情感类别的概率p,确定情感类别标签l,并定义其损失函数.
(5)
l=arg max(p)
(6)
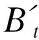
3.2 融合情感信息的学习者特征
为了获取完备的学习者特征,本文融合了学习者的人口统计特征fpk(i)、学习行为特征fbk(i)和情感特征fek(i),其中情感特征fek(i)为基于自注意力机制的BiLSTM文本情感分类模型的输出结果——文本在不同情感类别上的分布概率p.
由图1可知,学习者特征的有效表示是学习状态建模的前提.基于学习者的基础信息pk(i)和学习行为信息bk(i),分别抽取其人口统计特征fpk(i)和学习行为特征fbk(i);基于学习者发表的文本,采用基于自注意力机制的BiLSTM文本情感分类模型,获取情感特征向量,即学习者的情感特征fek(i);采用多源特征融合函数fuse,获得学习者特征xk(i).
xk(i)=fuse(fpk(i),fbk(i),fek(i))
(7)
本文采用向量拼接融合多源特征,即xk(i)=[fpk(i);fbk(i);fek(i)],其中“;”表示特征向量按行序拼接.
3.3 基于LSTM的在线学习状态建模和学习成绩预测
3.3.1 学习状态建模
学习具有时间上的持续性.学习过程中,学习者在第k个时间步的学习状态,既与当前时间步k的学习行为相关,也受第k-1个时间步学习状态的影响,因此需要动态地建模学习者在不同时间步的学习状态.本文采用LSTM构建学习者在时间序列上的学习状态模型.
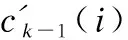

图3 LSTM网络模型结构图Fig.3 LSTM network model structure
(8)
其中,Wc是细胞状态的权值矩阵,bc是细胞状态的偏置向量.
考虑学习过程中学习者对已有知识的遗忘、记忆以及对新知识的吸收,分别通过遗忘门fk(i)和输入门ik(i)更新第k个时间步的隐含学习状态.
fk(i)=σ(Wf[yk-1(i);xk(i)]+bf)
(9)
ik(i)=σ(Wi[yk-1(i);xk(i)]+bi)
(10)
(11)
其中,Wf和Wi是遗忘门和输入门的权值矩阵,bf和bi是遗忘门和输入门的偏置向量;σ是sigmoid函数,⊙表示向量按位乘运算.
在学习过程中,学习者的情绪状态(如:紧张、困惑、挫败等)会影响其学习效果,隐含学习状态难以完全输出,因此通过输出门ok(i)将第k个时间步的隐含学习状态ck(i)转换为学习者的实际学习状态yk(i).
ok(i)=σ(Wo[yk-1(i);xk(i)]+bo)
(12)
yk(i)=ok(i)⊙tanh(ck(i))
(13)
其中,Wo和bo分别是输出门的权值矩阵和偏置向量.
3.3.2 学习成绩预测
采用在线学习状态模型,获得学习者Li在不同知识点k上的动态学习状态yk(i);当学习者完成某课程所有知识点的学习后,得到最终的学习状态向量y(i);采用一个单隐层的MLP(Multilayer Perceptron)神经网络,即可预测学习者Li的课程成绩g(i).
g(i)=sigmoid(W2c(i)+b2)
(14)
其中,W2和b2分别是线性变换的权值向量和偏置向量.
4 实验与分析
4.1 实验数据
为了验证本文所提模型的有效性,本文采集了国内某大学在线学习平台上2020年春季学期至2021年秋季学期中5门在线课程的人口统计学信息、学习行为数据、学习体验文本等.其中,人口统计学信息主要包括学习者的基本信息,如:年龄、性别、教育层次、专业、先修课成绩等;学习行为数据是指在线学习中的过程性数据,如:下载文献、提交作业、观看视频、在线练习、在线讨论、论坛发帖及回复等;学习体验文本主要来源于课程论坛中学习者针对知识点、课程内容、学习活动、学习交互等发布的文本.由于学习体验文本缺少情感标签,因此需要进行人工标注,本文将学习体验文本的情感标签确定为积极、消极和中性3类.综上,形成了本文模型所使用的学习者特征,见表1.

表1 模型使用的特征Table 1 Features used in the model
4.2 文本情感分类模型结果分析
4.2.1 实验设置
下载学习者发表在课程论坛中的文本数据,形成在线课程文本数据集,并按照6:2:2的比例将数据集划分为训练集、验证集和测试集.将准确率(Accuracy,ACC)作为情感分类模型的评价指标,采用均方根误差(Root mean square error,RMSE)衡量预测标签和真实标签之间的分离程度.计算公式如下:
Acc=T/N
(15)
(16)

文本情感分类模型使用的主要超参数如下:针对在线课程文本数据集,采用腾讯AI Lab的中文词向量数据训练词向量,建立200维的词向量矩阵;设置文本表示向量的维度为50,每条文本的长度不超过50个词语;设置BiLSTM模型中隐藏层的节点数为100;设置初始学习率(Learning rate)为0.005,并采用Adam方法优化模型参数.
4.2.2 结果分析
基于Stanford Sentiment Treebank(SST)[23]数据集和本文采集的在线课程文本数据集进行训练和测试,选择SSWE[24]、RNTN-RNN[23]、PVDMM[25]模型和本文模型进行对比,实验结果见表2.其中,SSWE模型的核心步骤为:首先进行文本中情绪特征的词向量表示,使用池化操作处理句子中单词的词向量并获取文本表示,进而训练SVM分类器实现情感分类.RNTN-RNN模型的核心步骤为:采用递归神经张量网络RNTN获得句子表示,将其输入递归神经网络RNN,对其每个时间步的隐向量进行平均并获取文本表示,进而训练情感分类模型.PVDMM模型的核心步骤为:采用段落向量的分布式存储模型PVDMM学习文本表示,进而使用隐藏层和softmax函数实现文本情感分类.
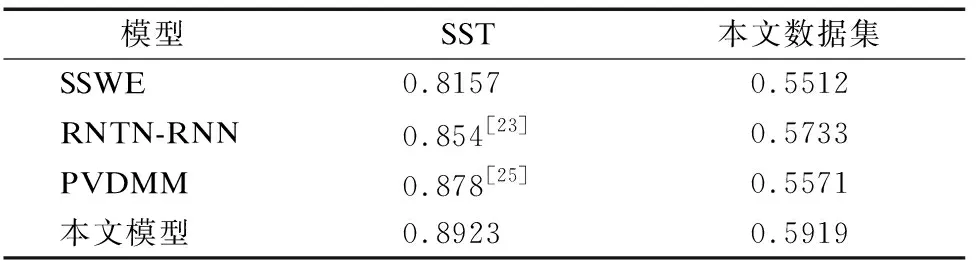
表2 不同情感分类模型的准确率Table 2 Accuracy of different sentiment classification models
实验结果表明:与SSWE、RNTN-RNN、PVDMM模型相比,本文提出的文本情感分类模型的效果最好,在2个数据集上的分类准确率最高(见表2),在课程文本数据集上的分类均方根误差最小(如图4所示).究其原因在于本文方法采用了基于自注意力机制的BiLSTM模型,对文本中情绪特征程度不同的词语赋予不同权重(即“注意力”),能有效发现蕴含情绪的词语,捕捉文本的情感特征,因此其情感分类效果更优.

图4 不同情感分类模型的均方根误差Fig.4 RMSE of different sentiment classification models
4.3 在线学习成绩预测结果分析
4.3.1 实验设置
在数据预处理时,选择课程讨论过程中发贴数量处于前85%的学习者的数据,组成在线学习成绩预测模型的有效数据集.学习状态向量的维度m=20.在5门在线课程上进行了学习成绩预测实验,按照8:2的比例将数据集划分为训练集和测试集.将准确率Accg和均方根误差RMSEg作为在线学习成绩预测模型的评价指标,计算公式如下:
Accg=T[a,b]/N
(17)
(18)
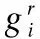
4.3.2 结果分析
基于在线学习成绩预测数据集进行训练和测试,选择MR、MLP、XGBoost、FM模型和本文模型进行对比.其中,MR为多变量回归模型,MLP为包含一个隐含层的多层感知器,XGBoost为一个基于Boosting框架的集成模型,FM[26]是一种基于矩阵分解(Matrix Factorization,MF)的方法.


表3 课程成绩预测结果Table 3 Achievement prediction results of courses
实验结果表明:与其他方法相比,本文提出的成绩预测方法的效果更好.究其原因在于:1)本文方法不仅采用了学习者的人口统计特征和学习行为特征等客观特征,而且使用了在线课程文本的情感特征,能充分体现学习者的主观性,进而全面刻画学习者在线学习状态;2)本文方法考虑了学习者的整体动态学习过程,采用LSTM构建其在时间序列上的学习状态模型,针对不同知识点获取学习者的在线学习状态变化,在一定程度上提升了成绩预测效果.FM方法仅考虑了学习者的课程成绩数据,难以有效刻画学习者的学习行为.MR-、MLP-和XGBoost-仅采用人口统计特征和不同知识点k上学习行为特征的平均值,难以充分反映学习者在学习过程中学习状态的变化.与MR-、MLP-和XGBoost-相比,MR+、MLP+和XGBoost+分别增加了在线课程文本的情感特征,成绩预测效果有不同程度的提升,表明情感特征是成绩预测中不可忽视的重要因素.
本文模型使用了人口统计特征、学习行为特征和情感特征.为了探讨这3类特征对在线课程成绩预测结果的影响,进一步设置以下对比实验:分别删除3类特征,并比较特征删除前后的在线课程成绩预测结果,如图5所示.实验结果表明:
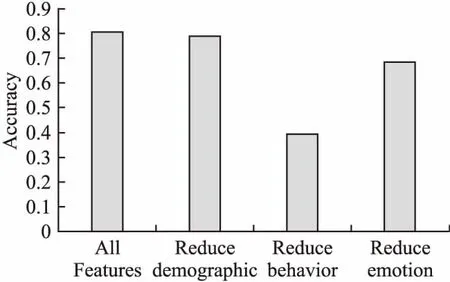
图5 不同特征对在线课程成绩预测的影响Fig.5 Influence of different features for online course performance prediction
仅减少人口统计特征时,对成绩预测效果的影响最小,成绩预测结果降低了约2%,原因在于在线学习过程中人口统计特征通常不会发生变化,难以充分体现学习者的个体差异;仅减少学习行为特征时,对成绩预测效果的影响最大,成绩预测结果降低了约51%,原因在于学习行为特征能充分反映学习者的学习状态,进而明显地影响其课程成绩;仅删除情感特征时,成绩预测结果降低了约16%,原因在于情感特征反映了学习者在学习过程中的情绪状态,对学习者的在线课程成绩具有不可忽视的重要作用.
为了阐明情感特征与学习状态之间的关系,本文随机选取某门课程中两个相邻的知识点ki和ki+1,获取积极情感隶属不同概率区间的学习者集合,分析各集合中学习者的学习状态变化.由于本文使用的学习状态向量的维度m=20,不失一般性,仅分析与在线课程成绩相关度最高的m5、m7和m16,如图6所示.
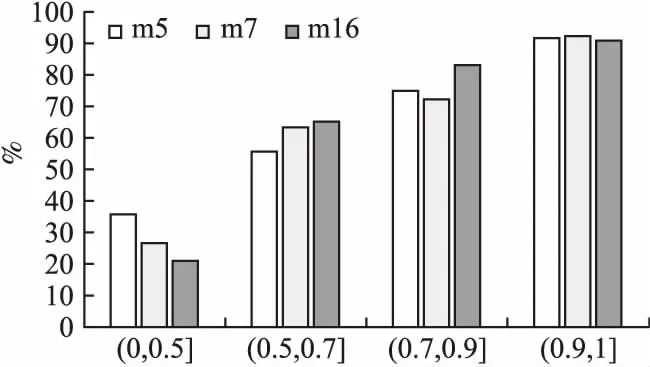
图6 学习状态呈正向变化的学习者的占比(积极情感)Fig.6 Ratio of learners with a positive change of learning status(positive emotions)
根据ki+1时刻学习者在积极情感上的预测概率,将其划分到(0,0.5]、(0.5,0.7]、(0.7,0.9]和(0.9,1]4个区间,分别统计各区间内在m5、m7和m16维度上学习状态呈正向变化的学习者的占比,其中正向变化是指学习状态维度上ki+1时刻的数值大于ki时刻的数值.由图6可知,当学习者在积极情感上的预测概率位于[0.5,1]区间时,大部分学习者的积极情感占主导地位、学习状态呈正向变化;表明学习者的学习态度积极、学习主动性强,能比较顺利地学习知识点,并踊跃参与在线学习活动(如:在线讨论、观看视频、完成课堂练习及课后作业等).但是,仍有少数学习者虽然表现出较高的积极情绪,其学习状态却呈负向变化(即学习状态维度上ki+1时刻的数值小于ki时刻的数值),究其原因可能在于其在人口统计特征或学习行为特征上表现不佳,如先修课成绩较差或课堂测验成绩较低等.当学习者在积极情感上的预测概率位于[0,0.5]区间时,多数学习者的消极或中性情绪占主导地位、学习状态呈负向变化;表明学习者的学习态度不够积极、学习主动性较差,学习知识点时存在一定困难.此时,有部分学习者的学习状态却仍然呈正向变化,究其原因可能在于他们习惯表达消极情绪或通过提问/求助等方式学习知识点,并在学习过程中投入较多时间和较大精力.
5 结 论
本文提出一种融合情感特征的在线学习成绩预测方法,定量分析了情感信息对学习者在线学习成绩预测的影响.首先,下载在线课程论坛数据,形成在线课程文本数据集;构建基于自注意力机制的BiLSTM文本情感分类模型,获取文本情感特征(即文本在不同情感类别上的概率分布向量).其次,融合学习者的人口统计特征、学习行为特征和文本情感特征,采用LSTM构建学习者在时间序列上的学习状态模型,获得其动态学习状态.最后,基于学习者的学习状态向量预测其在线学习成绩.实验结果表明:本文提出的文本情感分类模型对在线课程论坛文本的分类效果更好,能够很好地提取学习者的情感信息;融合文本情感特征的学习状态模型能有效提升在线学习成绩预测的精度.
下一步工作将继续探索更优的文本情感分类模型,进一步提升在线学习成绩预测的效果;本文方法本质上是基于深度学习的在线学习成绩预测方法,其可解释性较差,拟结合基于概率的成绩预测方法(如:知识追踪技术),增强在线学习成绩预测的可解释性.
