基于邻域交互和图神经网络的推荐模型
2023-07-15谢瑾奎曹磊亮
颜 祯,谢瑾奎,曹磊亮
(华东师范大学 计算机科学与技术学院,上海 200333)
1 引 言
近年来,推荐系统引起越来越多的关注,已经成为缓解信息过载和提升用户体验的重要工具.经典的推荐方法,例如协同过滤[1],利用用户-项目的互动记录来计算相似度.如今,已经发展到利用神经网络来处理复杂的异质数据,在提升推荐性能上展示出巨大的潜力.
现实世界的图大多都是异质的,图1展示了电影异质图,由多种类型的实体和关系组成.异质图能够建模复杂的网络结构,并融合节点和边的信息,已在推荐领域中得到广泛应用.为获取异质图中的丰富语义,现有的基于异质图的方法,大致分为以下两类.
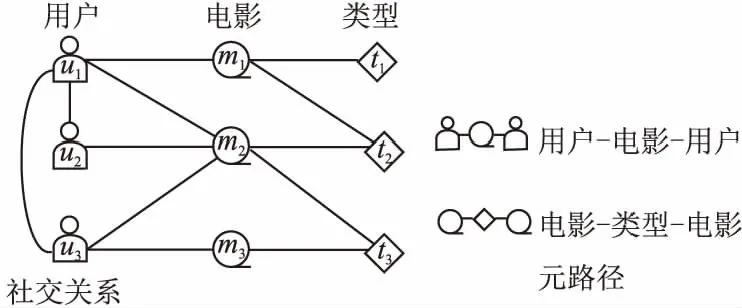
图1 电影异质图Fig.1 Movie heterogeneous graphs
第1类是基于图神经网络的方法,如HetGNN[2],通过随机游走对邻域采样,然后利用图卷积网络GCN[3]聚合节点信息.这类方法在预测前将节点及其邻域聚合为单一的嵌入,忽略了用户-项目间丰富的交互.第2类是基于元路径的方法,如MCRec[4],通过学习用户与项目间元路径的明确表示,获取丰富的交互信息来提升推荐的性能.元路径是连接两个实
体的不同语义路径.以图1的电影异质图为例,元路径用户-电影-用户(UMU)代表两个用户观看同一部电影,元路径电影-类型-电影(MGM)代表两部电影是同一种类型.这类方法将用户-项目间的元路径聚合为单一的嵌入用于预测,忽略了用户和项目节点本身丰富的邻域信息,且基于元路径的方法严重依赖于路径的可达性.
异质图推荐中存在数据稀疏性的问题导致性能不佳,研究人员考虑纳入社交信息[5]来缓解这些问题.社交关系理论一般假设具有社交关系的用户有相似的偏好,因此可以作为辅助信息缓解因数据稀疏性导致的性能问题.
为了解决上述问题,本文提出一种基于邻域交互和图神经网络的推荐模型(NGRec),本模型通过融合用户和项目及其交互信息用于推荐.本文的主要贡献如下:
1)融合用户和项目以及交互的元路径信息实现三向互动.引入注意力机制聚合用户和项目的一阶邻居得到节点信息,使用邻域交互算法学习用户-项目间的元路径信息.
2)引入新的社交边进行数据增强,使用图神经网络建模用户的社交关系,缓解数据稀疏性问题.
3)在3个异质数据集上进行大量实验,证明模型NGRec的有效性.
2 相关工作
经典的推荐算法主要分为基于内容[6]的方法、基于协同过滤[7]的方法和混合方法[8].由于存在冷启动问题,许多工作试图利用额外的信息来进行推荐,如社交信息[9],上下文信息[10]和异质信息[11].近年来,深度学习发展迅速,深度神经网络也被用来在用户项目交互数据中提取潜在特征[12].
作为一个新兴方向,异质图可以自然地建模推荐系统中不同类型的实体以及丰富的关系.异质图在处理各种辅助数据时所展现出的灵活性,对数据挖掘具有重大意义,已广泛应用到推荐系统领域中.其中,大多数基于异质图的方法依赖于路径的相似性[13].Yu等人[14]引入元路径的潜在特征来表示用户和项目间路径的连接性.Shi等人[15]利用元路径的用户相似性预测用户对项目的评分.Hu等人[4]利用基于元路径的上下文进行Top-N推荐.Li等人[16]提出基于路径的深度网络,通过聚合用户和项目间两跳路径的相关信息,预测用户兴趣.Tai等人[17]提出一个以用户为中心的路径网络,根据用户需求搜索路径,实现可解释的推荐.然而,这些方法忽略了所要预测的用户和项目本身丰富的信息.
另一方面,异质图神经网络的目标是学习每个图顶点的低维潜在表示,以用于下游的分析任务,如分类、聚类和推荐.图卷积神经网络GCN[3]采用局部图卷积提取节点特征,图注意力网络GAT[18]引入多头注意力机制进行信息传播,两者都是图神经网络的通用流行框架.Dong等人[19]基于随机游走得到的邻域学习异质图的节点表示.Fu等人[11]考虑路径的语义性来学习节点信息.Wang等人[20]使用节点级和语义级注意力聚合邻域特征以生成节点表示.Jin等人[21]利用元路径引导的邻域获取节点之间的交互.Song等人[22]整合显性和隐性的社交影响,通过GCN网络来学习用户和项目的社交嵌入.Chen等人[23]提出一个多关系模型,探索节点的高跳邻域,学习用户和项目以及关系的表示,来进行多关系的预测.
3 预备知识
本文是针对隐性反馈的推荐任务.考虑n个用户U={u1,u2,…,un}和m个项目I={i1,i2,…,im},用户隐性反馈矩阵R∈Rn×m中的每个元素ru,i定义如下:当观察到用户项目
3.1 元路径
给定一个异质图G=(V,E),A和R表示节点和关系的集合,构成异质图中的顶点V和边ε,其中|A|+|R|>2.在异质图中,两个节点由不同的关系连接,这些路径被称为元路径.元路径可以揭示用户项目互动的语义背景.

3.2 基于元路径的邻域
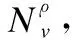
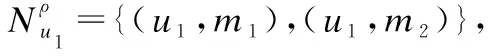
4 模型设计
4.1 模型概述
本文设计了一个基于邻域交互和图神经网络的推荐模型NGRec.与现有的基于异质图推荐模型不同,NGRec不仅学习用户和项目的表示,同时将元路径作为用户和项目互动的语义背景,学习元路径的明确表示.模型的目标是学习用户、元路径、项目的三向互动,三者相互增强,而不是只对用户和项目的双向互动进行建模.图2展示了模型的整体架构,可以看到模型包括学习用户嵌入和项目嵌入的组件,以及学习元路径嵌入的组件.用户模块通过注意力机制聚合用户周围的项目以及社交用户得到用户的最终表示,项目模块通过聚合项目周围的用户得到项目的最终表示.元路径嵌入模块通过对用户和项目的邻域元路径进行交互运算,并使用双层注意力机制获得元路径的表示.
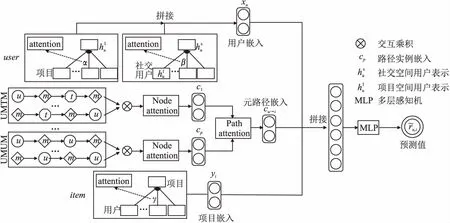
图2 模型框架图Fig.2 Model framework
4.2 用户模块
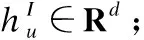
节点具有异质性,为了方便模型可以处理任何类型的节点.对于不同类型的节点,如类型为φt的节点,本文设计特定的转换矩阵Qφt,将不同类型的节点投影到统一的特征空间中,转换过程如下:
(1)
其中et和e′t分别是节点t的原始特征和投影特征.
4.2.1 项目聚合
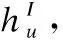
(2)
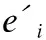
(3)
其中W1和W2表示注意力网络中的权重矩阵,b1和b2表示偏置向量.最终的注意力权重由softmax函数归一化注意力分数得到:
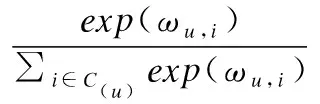
(4)
4.2.2 社交聚合
根据社交关系理论,一个用户的偏好会受其直接或间接联系的社交朋友影响.为了缓解数据稀疏性问题,模型通过增加新的社交边来进行数据增强.本文考虑两个用户互动的项目重合度越高,两个用户就越相似,为前N相似度的两个用户添加一条社交边,建立新的用户-用户社交图.
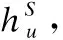
(5)
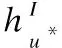
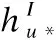
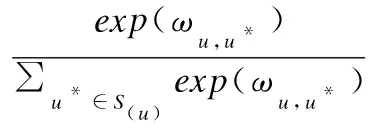
(6)
(7)
其中W1和W2表示两层神经网络中的权重矩阵,b1和b2为偏置向量.
4.2.3 用户嵌入
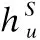
(8)
4.3 项目模块
在用户-项目图中,聚合项目周围的用户以得到项目的最终表示.聚合方式类似于用户模块中的项目聚合,对于项目i,采样与项目互动过的所有用户集合C(i),聚合集合中的用户得到项目的嵌入yi,公式如下:
yi=σ(W·{∑u∈C(i)γi,u·e′u}+b)
(9)
其中e′u表示与项目i互动的用户嵌入,W和b表示权重矩阵和偏置向量.模型采用两层神经网络学习项目-用户注意力权重γi,u,考虑互动的用户嵌入e′u和项目i的嵌入qi,注意力权重γi,u的学习过程如下:
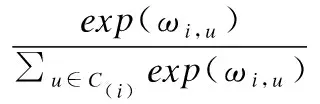
(10)
(11)
其中W1和W2表示项目注意力网络中的权重,b1和b2为偏置向量.ωi,u表示从交互用户集C(i)学习用户偏好时,用户u在表征项目i时的注意力分数.通过softmax函数对ωi,u进行归一化得到最终的注意力权重.
4.4 基于邻域交互的元路径嵌入
元路径中包含丰富的语义信息,捕捉这些丰富语义得到元路径的表示,用来增强用户和项目以实现用户、元路径、项目的三向互动.
4.4.1 邻域采样
一个元路径下有多个路径实例,为了生成高质量的路径实例,关键在于设计一种有效的随机游走策略.给定一个异质图G=(V,E)和一个元路径ρ(A1A2…Al+1),下一个节点的生成策略如下:
(12)
其中Nk为随机游走的第k个节点,Nρv(1)表示节点v在元路径ρ引导下的一阶邻域节点集合.采样将重复如上策略,直到其达到预定义的长度.根据3.2小节,不需要对源节点到目标节点进行显式可达的元路径采样.
4.4.2 元路径邻域交互
模型不依赖于路径的可达性,通过对源和目标节点的邻域进行交互,得到用户和项目间元路径的表示.考虑到与源和目标节点距离不同的邻域通常对表征元路径的贡献不同,本文将元路径引导的邻域划分成不同的距离组.如图3所示,对于源用户us和目标电影mt,给定元路径用户-电影-类型-电影(UMTM),分别得到元路径引导的源邻域us,m1,t2,m3和目标邻域mt,t4,m5,u6.组0中的us和mt分别为源节点和目标节点的0跳邻域,组1包含源和目标节点的0及1跳邻域,组3包含源和目标节点的0,1,2及3跳邻域,组6中的m3和u6分别为源节点和目标节点的3跳邻域.根据距离规则将元路径邻域划分成2l-1组,其中l表示路径长度.可以观察到,不同组的邻域与源节点和目标节点的距离不同.
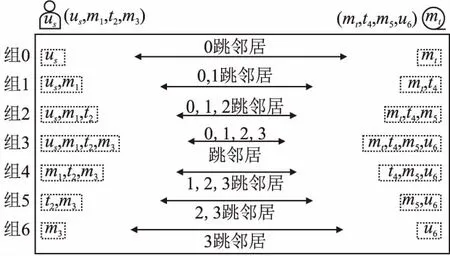
图3 路径实例的邻域划分Fig.3 Neighborhood division of path instance
交互操作只发生在同组邻域中,用元素积运算来衡量组内的同/异质节点间的相似度.受到卷积神经网络CNN的启发,粗略地看,卷积包含移位、乘积、求和3种运算.为了实现元路径邻域的交互,对邻域进行划分,得到不同的距离组,组内进行交互.源和目标邻域的整个交互过程也可以理解为一种卷积运算,即移位、元素乘、求和3种运算重复进行,直到达到路径的长度.如图4所示,为了实现源邻域us,m1,t2,m3和目标邻域mt,t4,m5,u6的交互,即完成从组0~组6的不同距离组的组内交互,首先对目标邻域逆序操作得到u6,m5,t4,mt,然后依次向右移动,观察移动过程中重合的节点.第1次重合发生在源节点us和目标节点mt间,即组0,通过如下公式实现交互:
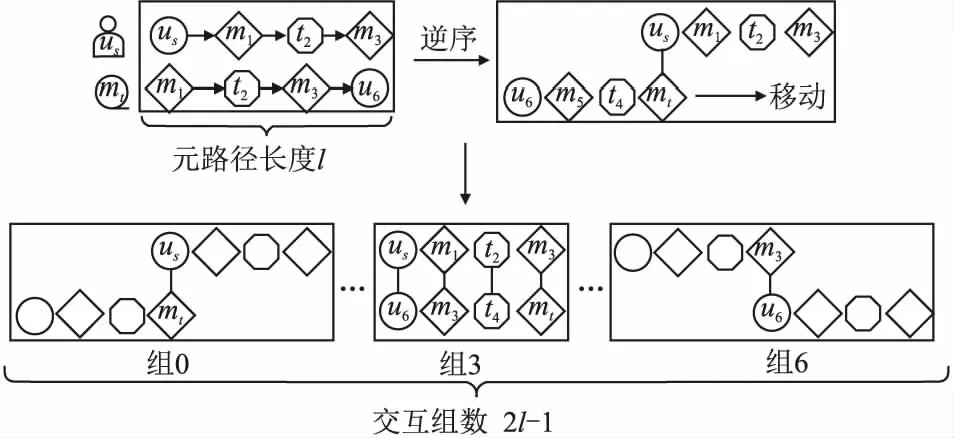
图4 路径实例的交互操作Fig.4 Path instance interaction operation
s(us,mt)=us⊙mt
(13)
其中⊙为元素积.后续移动过程中,包含多跳邻域时,先通过乘积计算相似度,再求和汇总.继续移动直到所有节点都重合时(组3),通过s(us,u6)+s(m1,m5)+s(t2,t4)+s(m3,mt)
来表示距离组3中的整个交互过程.最后的交互发生在源和目标节点的3跳邻居之间s(m3,u6).通过上述卷积过程得到路径实例p下不同距离组的交互嵌入:
(14)
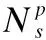
4.4.3 路径实例嵌入
由于距离源和目标节点不同的邻域对表征元路径的贡献不同,本文引入自注意力机制学习不同距离组交互嵌入的注意力分数:
(15)
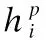
(16)
Np表示路径实例p下所有的距离组.为所有交互加权求和得到最终的路径实例嵌入:
(17)
其中K为注意力头数,将注意力机制扩展到多个头,有助于更加稳定地学习路径表示.
4.4.4 元路径嵌入
为了学习元路径的嵌入,模型使用非线性函数来转换路径实例的嵌入,并将转换后的嵌入进行平均来说明路径实例对表征元路径的贡献:
(18)
其中P表示所有的路径实例集合,W1和W2是注意力网络中可训练的权重,b1是偏置.最后使用路径级的注意力机制聚合所有的路径实例得到元路径嵌入:
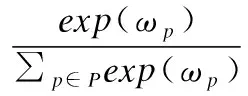
(19)
cu→i=∑p∈P(βp·cp)
(20)
4.5 融合预测层
给定源用户u和目标项目i,模型已经学习到用户嵌入xu和项目嵌入yi以及元路径嵌入cu→i,三者相互增强.融合层将3个嵌入拼接起来得到一个统一的表示:
(21)
其中⊕表示向量拼接操作.最后使用一个MLP组件,通过非线性函数来模拟复杂的交互行为:
(22)
其中MLP组件由两个隐藏层实现,激活函数为ReLU,输出层使用sigmoid函数.
4.6 模型训练
模型采用对数损失函数,并使用负采样法学习模型的参数:
(23)
Y+和Y-分别为正负样本集,y为样本标签.
5 实验设置与结果分析
本文提出的NGRec模型使用Pytorch框架实现,所有的实验都在一台CPU为Intel i7-9700,显卡为NVIDIA GTX 1650,内存为32G的机器上运行.
5.1 数据集
本文采用3个广泛使用的数据集,它们来自于不同的领域,分别是Amazon电子商务数据集,Movielens电影数据集,Yelp商业数据集.数据集中的评分表示用户和项目的互动记录.3个数据集的详细信息见表1,每个数据集的第一行表示用户和项目及互动的数量,其他行则是对其他关系的统计.
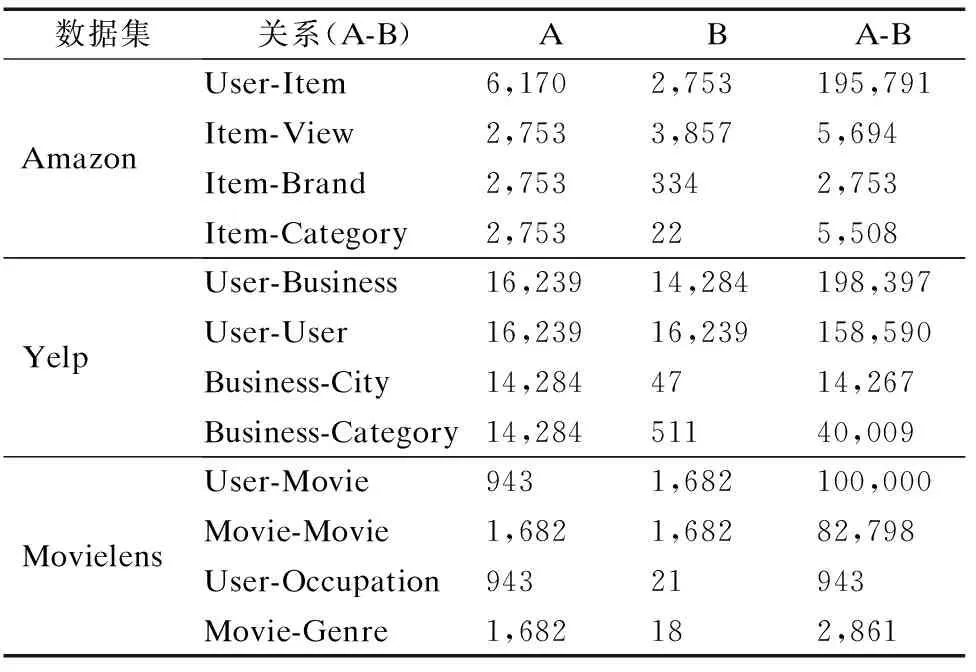
表1 3个数据集统计信息Table 1 Statistical information on the three datasets
5.2 评价标准和指标
为了评估推荐性能,本文对数据集进行随机划分,60%的数据为训练集,20%的数据为验证集,20%的数据为测试集.文中采用两种任务来评估模型,分别是点击率预测和Top-N推荐.在点击率预测任务中,采用准确率Acc和F1分数来评估每个数据点的性能.在Top-N推荐任务中,采用平均精确率均值MAP@k,以及归一化折损累计增益NDCG@k作为评价指标.最终结果是对一个用户的所有测试项目进行平均,再对所有用户进行平均.为了保证稳定性,本文使用随机划分的训练/验证/测试集运行5次实验,统计平均结果.
5.3 参数设置
模型使用正态分布来随机初始化参数,使用自适应矩估计Adam进行优化.模型的批处理大小设置为128,正则化参数设置为0.0001,学习率λ为0.001,丢失率dropout设置为0.3,用户和项目以及其他异质节点的嵌入维度均设置为128,注意力头数为3.表2展示了每个数据集选取的元路径,采样路径实例的数量为16,其中元路径的长度为4.

表2 不同数据集的元路径Table 2 Selected meta-paths for each dataset
5.4 比较方法
本文使用了4种基线方法,包含异质图嵌入模型HAN和TAHIN,以及推荐模型MCRec和NIRec.
HAN[20]:提出双层注意力的异质图神经网络,考虑节点级和语义级重要性,聚合邻域信息以生成节点表示.
TAHIN[24]:在源域和目标域设计一个跨域模型,使用三层注意力聚合来获得用户和保险产品的表示.
MCRec[4]:学习丰富的元路径上下文信息,提出共同注意力机制来提升HIN的推荐性能.
NIRec[21]:提出一种端到端的基于邻域的交互推荐模型,利用元路径引导的邻域获取节点对之间的交互.
5.5 实验结果及分析
5.5.1 NGRec模型与其他基线比较
点击率预测任务的结果如表3所示,不同数据集下的Top-N推荐任务的结果如表4~表6所示.根据实验结果可知,本文提出的模型NGRec在3个数据集上始终优于所有基线,表明了用户、项目、元路径三者互相增强的意义,验证了模型NGRec的有效性.因为NGRec不仅考虑到用户项目信息,还考虑到元路径丰富的交互信息,提高了模型在CTR预测和Top-N推荐方面的性能.
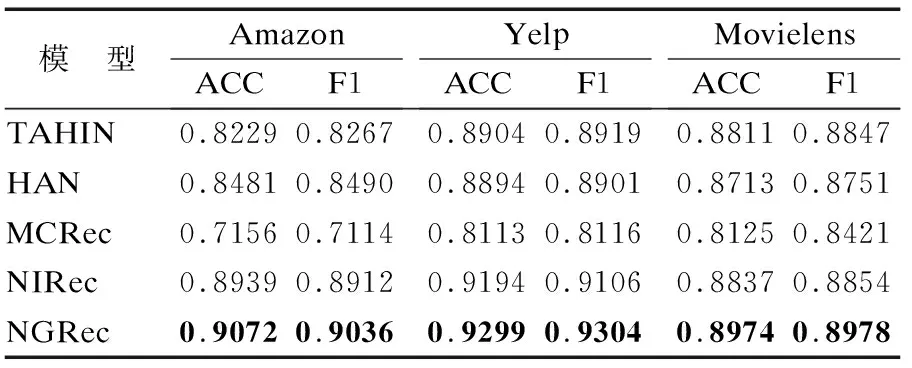
表3 点击率预测Table 3 CTR prediction
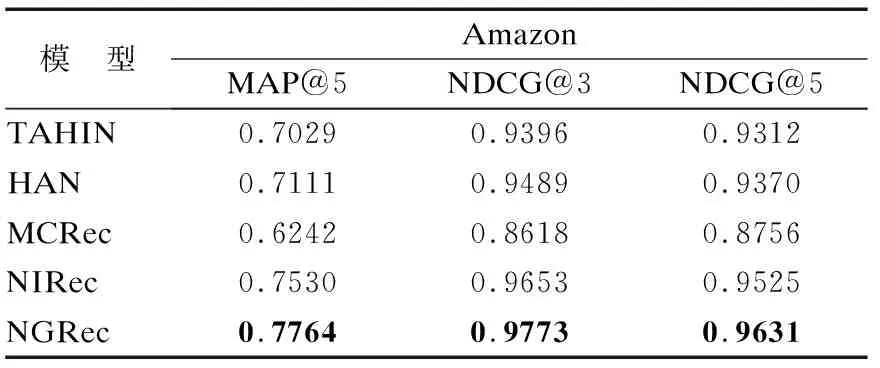
表4 Top-N推荐任务(Amazon)Table 4 Top-N recommended tasks(Amazon)

表5 Top-N推荐任务(Yelp)Table 5 Top-N recommended tasks(Yelp)
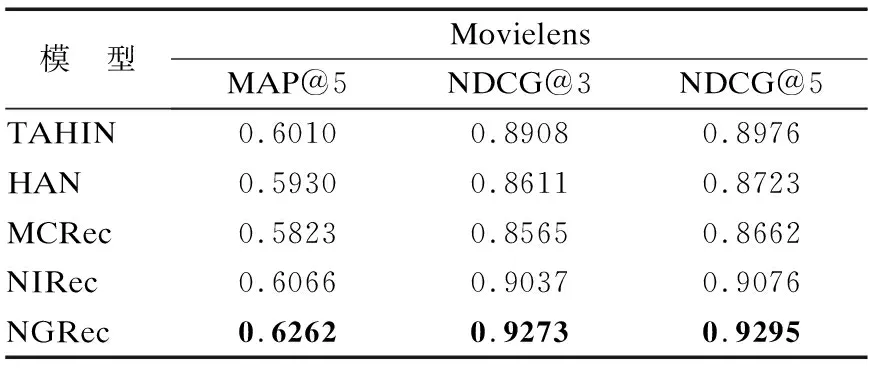
表6 Top-N推荐任务(Movielens)Table 6 Top-N recommended tasks(Movielens)
在4种基线中,基于元路径邻域的方法TAHIN,HAN以及NIRec明显优于MCRec,一个直观的解释是,MCRec的性能依赖于用户项目间可达的高质量元路径,并且MCRec忽略了用户和项目周边丰富的低阶邻域信息.本文的模型NGRec联合考虑低阶和高阶信息,通过聚合低阶邻域来获取用户和项目的表示,利用高阶邻域交互来获取元路径的表示.
在基于元路径邻域的3种方法中,NIRec明显优于HAN和TAHIN,模型NIRec对用户和项目的邻域进行交互得到元路径的信息,一个可能的解释是NIRec利用交互模块可以挖掘出元路径中更多有用的隐藏信息.此外,模型HAN略逊于TAHIN,原因可能是HAN只利用元路径的两个末端节点,忽略了中间节点,导致了部分信息损失.
在所有数据集中,模型NGRec的表现始终最优.具体分析如下,NIRec和MCRec只考虑了用户和项目之间的元路径信息,忽略了用户和项目节点本身的邻域信息.HAN和TAHIN则相反,考虑了用户和项目的高阶邻域,但忽略了用户和项目之间丰富的元路径信息.本文的模型NGRec聚合用户和项目的低阶邻域得到节点表示,通过对用户和项目之间的元路径邻域进行交互得到元路径信息,与之前的方法相比,NGRec可以充分挖掘有用的隐藏关系.
5.5.2 元路径对NGRec模型的影响
这一小节主要研究不同的元路径加入对推荐性能的影响.为了便于分析,本文在数据集Amazon和Yelp上进行实验,描述准确率ACC和F1分数随着元路径加入的变化趋势,如图5、图6所示.随着不同元路径的加入,模型NGRec的性能不断提升.特别是,在没有元路径交互到第一个元路径加入时,性能有了明显的提升,说明了模型纳入元路径信息的意义.同时,根据指标的上升趋势发现,不同的元路径似乎对推荐性能有不同的影响.在Amazon数据集中,加入元路径UIUI和UIVI时,性能都有明显的提升.类似的情况也发生在数据集Yelp中,加入元路径UBUB时,模型有明显的性能提升,加入元路径UBCiB和UUUB时,性能也有较大的提升.这些发现表明,不同的元路径对最终结果的贡献是不同的.
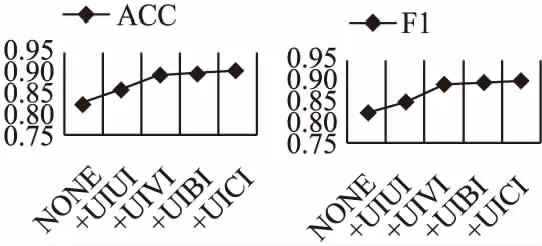
图5 不同元路径对ACC和F1的影响(Amazon)Fig.5 Impact of different meta-paths on ACC and F1(Amazon)
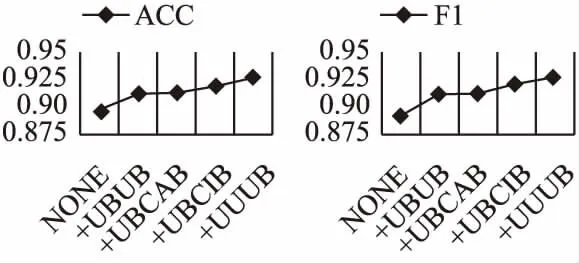
图6 不同元路径对ACC和F1的影响(Yelp)Fig.6 Impact of different meta-paths on ACC and F1(Yelp)
5.5.3 消融实验
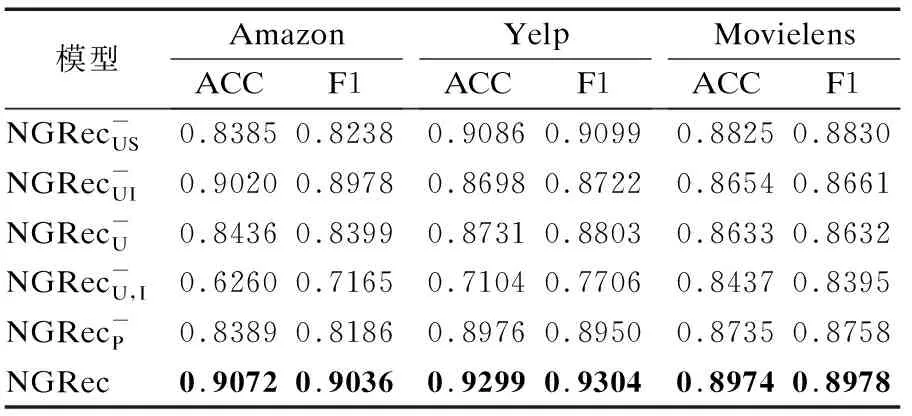
表7 消融实验Table 7 Ablation experiments
6 结 语
本文提出了一个基于邻域交互和图神经网络的推荐模型NGRec,并且引入新的社交边用于数据增强.本文模型为用户,项目,元路径学习有效的表示,实现三向互动,共同增强.首先引入用户模块的项目聚合和社交聚合学习用户的表示,引入项目模块的用户聚合学习项目的表示,然后通过端到端的元路径邻域交互学习元路径的表示,最后融合三者信息来增强推荐的效果.为了更好地获取元路径中的丰富语义,本文设计一种双层注意力机制,学习节点交互和路径实例的重要性.通过在3个数据集上的实验表明,本文提出的模型在推荐性能上具有优势.下一步的工作将考虑纳入知识图谱,在学习节点的基础上,学习节点间丰富的关系,设计关系感知的模型,增强推荐过程中的可解释性.
