一种嵌入式轻量化卷积神经网络计算加速方法
2023-07-15谢媛媛刘一睿陈迟晓康晓洋张立华
谢媛媛,刘一睿,陈迟晓,康晓洋,张立华
1(复旦大学 工程与应用技术研究院,上海 200433) 2(复旦大学 信息科学与工程学院,上海 200433) 3(复旦大学 芯片与系统前沿技术研究院,上海 200433)
1 引 言
近年来,随着以卷积神经网络(Convolutional Neural Network,CNN)为代表的人工智能算法的深入研究与普及,智能电子设备与相关应用场景已随处可见,例如目标检测[1]、人脸识别[2]、智慧医疗[3]等.CNN通过增大网络结构,以高的计算量为代价实现模型预测的高准确率.一些对实时性要求比较高的应用场景不仅对网络的准确率有较高的要求,而且要求网络有较高的处理速度.目前最常用的加速卷积运算的平台有图形处理器(Graphics Processing Unit,GPU),体积大,功耗高,且难于集成,很难在小型化的硬件设备上进行部署[4].专用集成电路(Application Specific Integrated Circuit,ASIC)具有性能高和功耗低的特点,且可以方便地部署在小型化的硬件设备上,但是灵活性和迁移性低,设计周期长,开发难度大、成本高.现场可编程门阵列(Field-Programmable Gate Array,FPGA)性能高、功耗低,且灵活性较好,但是需要开发者具备一定的硬件专业知识背景,对不是专门从事硬件工作的人来说开发难度较大[5].基于ARM处理器(Advanced RISC Machines)的嵌入式平台体积小,功耗低,灵活性高,方便部署和迁移,对硬件相关知识要求相对较低,为CNN部署提供了一种有效的解决方案.但是传统ARM处理器算力低,在一些应用场景中不能满足实时运算的要求[4].
在卷积网络加速的方法中,其中一种有效的解决方案就是使用低位宽的定点数来表示原来的32位浮点数进行卷积运算[6-13];另一种方法就是使用单指令多数据(Single Instruction Multiple Data,SIMD)的方法并行计算[14];此外,由于卷积运算中有大量的数据复用,且计算具有规则性,可以用数据流架构减少内存访问,从而提升速度[15-18].
本文提出一种卷积神经网络加速的方法,通过可学习步长量化的方法得到低位宽的网络参数,提高推理的运算速度,降低功耗,采用数据流架构的SIMD卷积加速器在ARM上进行加速运算.将本文方法用于处理脑电信号(Electroencephalogram,EEG)来进行手术过程中麻醉深度监测,实验结果表明,该方法在几乎不影响网络预测准确率的情况下,显著提高了EEG信号处理的速度,降低功耗.
2 相关工作
2.1 神经网络低位宽量化
在进行神经网络的乘累加运算时,使用低位宽可以减少存储容量和内存访问、加速运算、降低功耗,此外,把浮点数量化为整数之后,具有更好的硬件兼容性.有研究显示,降低位宽能够显著减少加法和乘法运算的功耗和芯片占用空间[6].只要精度不降低太多,在能够满足计算目的的前提下,本文尽量采用低位宽量化来减少存储空间和内存访问,从而提升速度,降低功耗[6-13].
权重聚类[19]是一种典型的轻量化算法,比如应用k-means聚类来减少表示权重的值的数量[20].使用权重共享方法对权重进行量化,然后对量化后的权重应用Huffman编码以获得更高的压缩率[7].然而,权重聚类方法需要特殊的数据索引,这种方法既耗时又不利于硬件实现.为了获得更高的压缩率,出现了二值化或三值化的方法,但是这种方法实现高压缩率的同时也会带来显著的准确率损失[10,11,21].
2019 年有学者提出可学习步长量化算法,用训练过程学习到的步长对网络参数进行低位宽量化,将轻量化网络参数用于推理.将该算法用于ImageNet数据集的几种不同规模的ResNet网络和VGG-16网络的低位宽量化,将网络量化为2bit,3bit和4bit时,该方法能够得到目前已有量化算法中最高的网络准确率[22].
2.2 基于ARM处理器的SIMD指令集
SIMD是一种最常用的加速神经网络运算的并行架构[14].SIMD架构每次从指令存储器读取一条指令,从数据存储器读取多个数,运算完把多个结果都存起来.这种结构非常适用于神经网络,因为在神经网络中,有大量的突触,存在大量并行运算,意味着需要加载很多组权重和输入,然后进行乘累加,对于这种非常高度并行的架构,SIMD有很大优势.
2.3 数据复用
卷积运算中存在大量的数据复用,而且计算具有规则性,在用硬件实现卷积运算时,可以用数据流架构减少内存访问,从而提升速度、降低功耗[15-17].基于数据流架构的数据复用方法包括Weight Stationary[16,17],Input Stationary[16],Row Stationary[15,16],Tunnel Stationary[16]和Pointwise Group Convolution[18],实际使用时,卷积网络可以使用这几种数据流模型之一或混合模型来减少输入或权重的访存,来提升性能.
2.4 EEG用于麻醉深度监测
手术中对患者进行麻醉深度监测对保障患者安全舒适意义重大.脑电双频指数(bispect ral index,BIS)是临床上比较常用的评估麻醉深度的方法[23-28].BIS是在功率谱、频谱分析的基础上复合脑电相关函数谱分析技术,将成人的多个不同脑电变量综合而成的一个单一的无量纲指数,用 0~100 表示[23],BIS值高代表大脑皮层功能完整性良好,处于清醒状态,而BIS值低则代表大脑皮层功能完整性下降,处于麻醉状态.传统的BIS指数评估麻醉深度的方法有一定的缺点:由于连续EEG采集的时长及采集环境的影响,EEG信号必然存在干扰,例如肌肉活动及外来的电流或机械干扰,这些干扰会影响BIS的可靠性,从而影响麻醉深度的监测[29-31];由于BIS指数需要进行内部运算,所以BIS值与对应的EEG之间有20~30s的滞后,即BIS显示的数据至少是20秒以前的数据,而并非实时监测[29].
有学者将人工智能(Artificial Intelligence,AI)的方法应用于麻醉深度监测[29-32],海量的脑电数据通过AI学习,不仅节省了人力,还可以减少由于脑电信号存在干扰造成的误差[29].采用AI的方法进行麻醉深度的监测,由于卷积神经网络中涉及到大量乘累加运算,想要实现EEG信号的实时处理,需要优化算法,提升性能.
3 实验方法
3.1 面向EEG的网络结构
因为EEG信号时序较长,需要比较大的感受野,所以采用比较大的卷积核.通过训练和调整,得到精度较高的网络结构如图1所示.网络的输入为每秒对应的EEG信号,每条数据的宽度为100.网络包含4层卷积层,3层池化层和两层全连接层.其中,第0层卷积核的大小是15,输入输出通道分别是1和32,第2层卷积核大小是11,输入和输出通道分别为32和64,第4层卷积核的大小是7,输入和输出通道分别是64和128,第6层卷积核的大小是5,输入和输出通道分别为128和256.整个网络的输出为根据EEG信号预测得出的BIS值.网络采用均方误差损失函数(Mean Squared Error,MSE).这个网络在结构上相对简单,但是已经包含了卷积神经网络最主要的结构.如果后期想对网络进行修改,只需要将加速部分的代码进行修改,就可以继续调用已经设计好的加速模块.
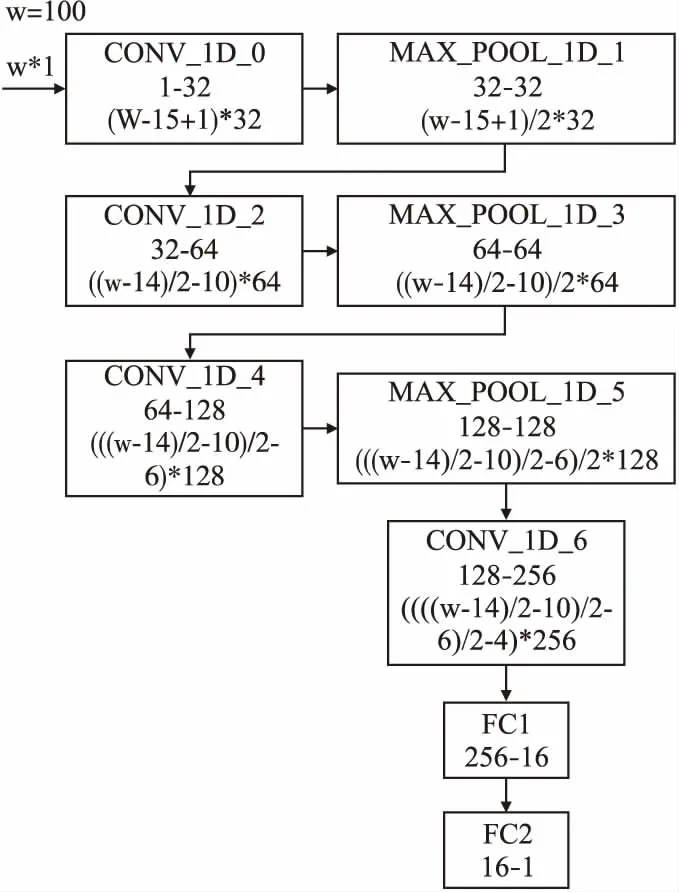
图1 处理面向麻醉深度监测的EEG信号的网络结构Fig.1 Network structurefor processing EEG signals which is used for monitoring the depth of anesthesia
3.2 网络轻量化
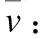
(1)
其中,函数clip(z,rmin,rmax)把z限定在rmin和rmax之间,当z小于rmin时返回rmin,当z大于rmax时返回rmax,当z∈[rmin,rmax]时返回z,取整函数[z]返回最接近z的整数.对于给定的量化位宽b,对于无符号数的量化(输入),QP=2b-1,QN=0,对于有符号数(权重)的量化,QP=2b-1-1,QN=2b-1.
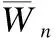
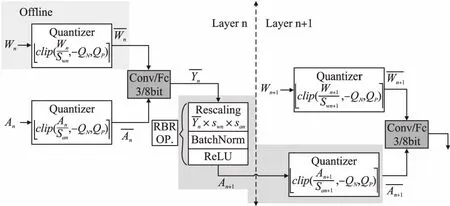
图2 量化算法每一层实现的步骤Fig.2 Steps to implement each layer of the quantization algorithm
把高位宽参数量化为低位宽参数,减小网络参数存储空间、提升速度的同时,由于参数的精度下降,从而导致网络预测的准确率下降.因此在量化时,对量化步长的选择至关重要,本文采用可学习步长的量化方案,采用随机梯度下降算法,使用直通估计器来推导取整函数的梯度,从而使用反向传播算法更新网络参数.更新参数时,对于损失函数L,使用直通估计器,按照:
(2)
来更新量化步长s,这样能够提高模型的准确率[22].其中∇是梯度算子,Nw表示权重W的数量.
3.3 基于ARM处理器的卷积网络SIMD计算加速方法
ARMv8 有32个128bit寄存器,本文基于ARMv8 用嵌入式汇编编程来实现SIMD卷积加速器设计,一条指令实现8组数据的乘累加运算.表1列出了几种常见的指令,分别是加法,减法,乘法,乘累加,数据加载和存储指令.

表1 几种常见的SIMD指令Table 1 Several common SIMD instructions
第0层卷积采用Input Stationary的数据流架构来减少访存次数,实现加速,第2层和第4层卷积采用类似于Row Stationary的数据流架构,第6层卷积由于卷积核通道数太大,受到寄存器数量的限制,只能采用Pointwise Group Convolution的架构来加速卷积运算.
4 实验结果与分析
本文网络训练是在计算机上,基于Windows10系统(版本号20H2),显卡为NVIDIA GeForce RTX 2080,环境为GPU版本的Pytorch1.3.1.推理阶段是在Ultra 96-V2开发板的ARM处理器上完成的.
4.1 实验数据集
实验数据集是昆士兰大学生命体征公开数据集[34],EEG信号为单通道数据,采样率为100Hz.把数据集中各个患者连续采样的数据截取为时长为1秒的数据,用每秒钟中间时刻的BIS指数当作标签,共得到57732条EEG信号数据和对应的BIS指数,4/5作为训练集,1/5作为测试集.
4.2 结果与分析
表2分别是全精度网络和不同方案的量化网络在测试集上的结果,准确率表示预测值和真实值相差小于5,即能够准确预测出麻醉过程病人状态的概率,std表示预测值与真实值差值的标准差,它的大小能够反映网络预测的准确率.Quan 8表示整个网络都量化为8bit,Quan 3 表示整个网络都量化为3 bit,Quan 838表示网络的第0层卷积和最后一层全连接层量化为8 bit,其余各层均量化为3 bit,Quan 83表示网络的第0层卷积量化为8 bit,其余各层均量化为3 bit.表2中,Quan8的准确率最高,但是用汇编实现数据流架构的SIMD卷积加速器时,相比Quan 83,第2,4,6层卷积运算的位宽都要加倍,使SIMD并行计算的数据量减少,导致运算时间和调用加速模块时参数传递时间加倍,从而使网络总的处理时间加倍.选择量化方案时,也试过将整个网络量化为16bit,得到的量化网络标准差std为3.99,准确率为89.14%,但是实现这种网络的时间代价是8bit网络的几倍,无法实现实时处理.Quan 3 的std太大,不能满足预测要求.Quan 838与Quan 83 相比,虽然最后一层全连接层的量化位宽有所增加,但是网络准确率降低,原因可能是最后一层网络参数冗余,出现了过拟合,导致网络准确率降低.综合考虑速度和准确率,本文最终采取Quan 83的量化方案,即网络的第0层卷积量化为8 bit,其余各层均量化为3 bit.
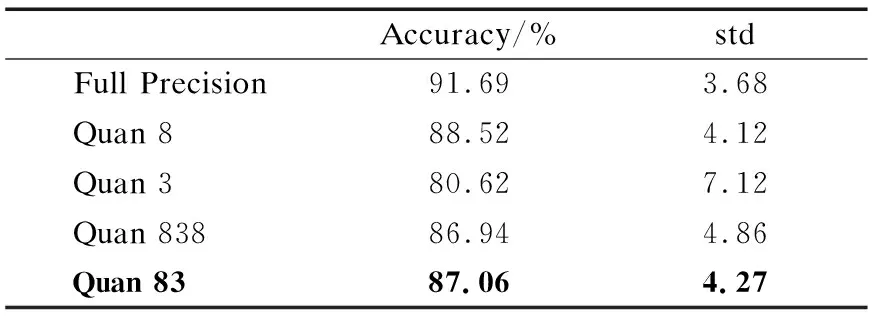
表2 全精度网络和量化网络精确度对比Table 2 Comparison of accuracy between full-precision network and quantized network
表3列出了轻量化网络各层参数,浮点数网络总参数量为993.216kB,而量化后网络总参数量为97.39kB,下降了90.19%,极大地降低了网络参数存储空间.表4列出了量化网络各卷积层乘累加的次数和卷积层间乘累加的次数.量化之前网络的卷积层是浮点数乘累加,需进行1.53M次;量化之后卷积层是整数乘累加,卷积层间是浮点数运算,只需要进行6.42k次浮点数的运算.所以量化之后浮点数乘累加的次数下降了99.58%,网络的运算速度得到很大提升.
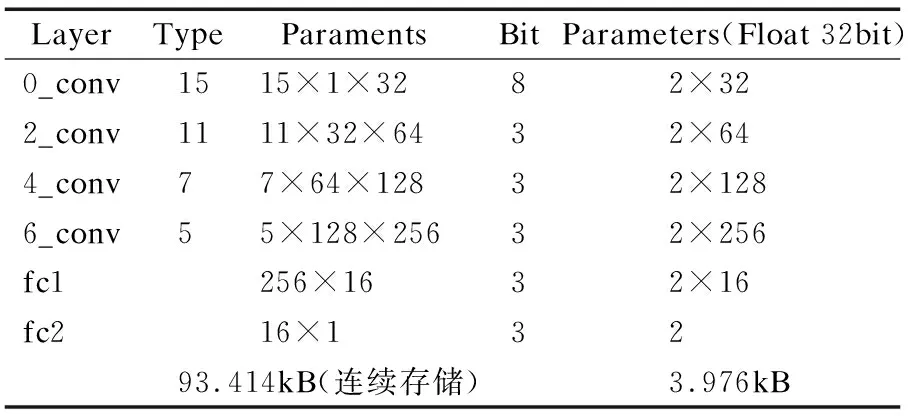
表3 量化网路各层参数Table 3 Layer parameters of the quantified network
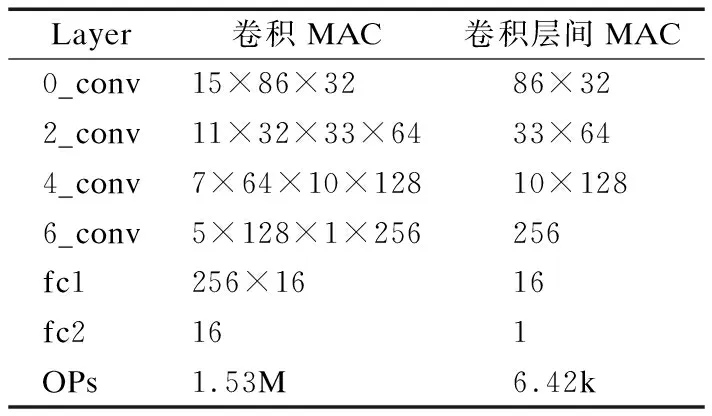
表4 量化网络各层乘累加次数Table 4 Multiply and accumulate times of the quantified network
Ultra 96-V2开发板上HDMI接口连接在FPGA部分,需要在FPGA上配置相应的IP核才能使用HDMI接口输出图像.由于本实验的输出结果BIS只是一个数字,比较简单,不需要输出视频图像,所以为了减少开发难度,使用串口与PC连接,把神经网络模型的运行结果通过串口输出到PC端进行显示.
表5分别是在计算机上和在Ultra 96-V2开发板的ARM处理器上各卷积层运行时间,Ops表示每层的乘累加次数,PC表示在计算机上用numpy 1.18.0计算,PS表示在ARM处理器上只用numpy 1.13.3计算,C表示在ARM处理器上直接使用C语言对卷积运算进行加速,ASM表示在ARM处理器上采用嵌入式汇编实现数据流架构的SIMD卷积加速器.由表5可以看出,第0层卷积运算,相对PS,ASM方法速度可提升12550倍,相对C,ASM方法速度可提升368倍,这是因为第0层卷积采用Input Stationary的数据流架构,极大地减少了访存次数,实现加速.由于参数量增加,寄存器数量有限,第2层和第4层卷积采用类似于Row Stationary的数据流架构,加速效果略差于第0层卷积,相对PS,第2层和第4层采用ASM方法速度可分别提升677倍和338倍,相对C,第2层和第4层采用ASM方法速度可分别提升403倍和251倍.第6层卷积由于卷积核通道数太大,寄存器数量严重制约数据流架构的加速效果,采用的是Pointwise Group Convolution的架构,相对PS,ASM方法速度可提升72倍,相对C,ASM方法速度可提升81倍.另外可以看出,在ARM处理器上ASM的方法比计算机的运算速度还要高很多倍.
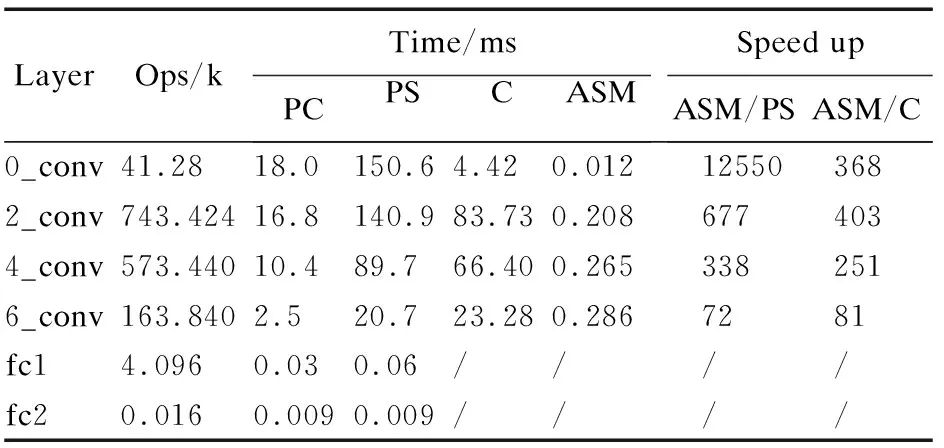
表5 各卷积层计算时间Table 5 Calculation time of each convolutional layer
由表5可知,在ARM处理器上采用嵌入式汇编实现数据流架构的SIMD卷积加速器,速度比直接使用C语言对卷积网络进行加速快很多,可能的原因是直接使用C语言进行编译,优化加速的时候并没有采用SIMD并行,也没有采用数据流架构来减少访存,所以运算速度不高.另外,本文中卷积运算的模式并不支持GPU加速,所以在ARM处理器上和在计算机上直接进行推理,速度都很低.
表6是ARM处理器处理每组EEG信号所需总时间和功耗,其中C和ASM的方法是通过Python调用加速模块实现的,整个流程除了卷积之外,还有对浮点数的量化、最大池化、 RBR运算和全连接层的运算,这些都是直接用numpy 1.13.3来实现的.由表6可知,本文提出的方法能够加速EEG信号的处理,降低功耗,仅需39.64ms就可以处理时间跨度为1s的EEG单通道信号,且功耗仅为0.1J.对于多通道的EEG信号,只要通道数不超过25,就能够实现实时处理.

表6 处理每组EEG信号所需总时间和功耗Table 6 Total time and power consumption required to process each group of EEG signals
另外,测得在ARM处理器上用numpy 1.13.3进行浮点数量化、最大池化、RBR运算和全连接层运算的总时间为9.1ms,所以由表5和表6对比计算可得,用本文提出的ASM方法,四层卷积层所用总时间为0.771ms,所以调用加速模块时参数传递需要的时间为29.8ms.
测试集中BIS最小值为17,最大值为93,这里从中随机抽取BIS值不同大小的6组数据,给出表2中所示几种不同的网络对应的EEG波形图,如图3所示,图中标注了对应的BIS的真实值Label和不同网络得到的预测值.由图3可知,总体来说,全精度网络预测的结果最接近真实值,Quan 8 是预测结果最接近真实值的量化网络,Quan 83次之.但也有特殊情况,例如,Label为27的数据,Quan 8 和Quan 3网络预测值和真实值都相差很大,用这两个网络训练过程学习到的参数来处理这组数据,结果不太理想.而Label为90的数据,Quan 83 网络预测值最接近真实值,甚至优于全精度网络的预测值.综合考虑准确率和处理速度,本文方法能够很好地预测不同麻醉深度的BIS值.


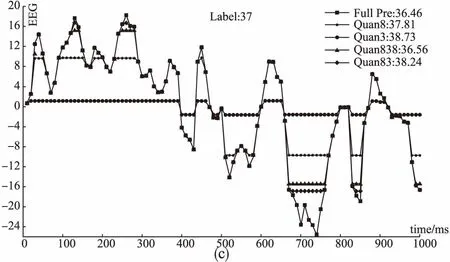
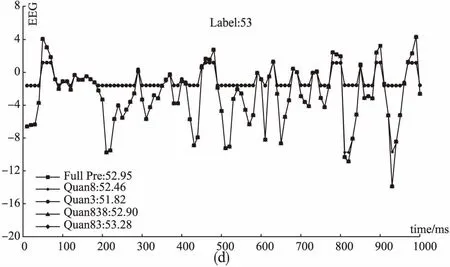
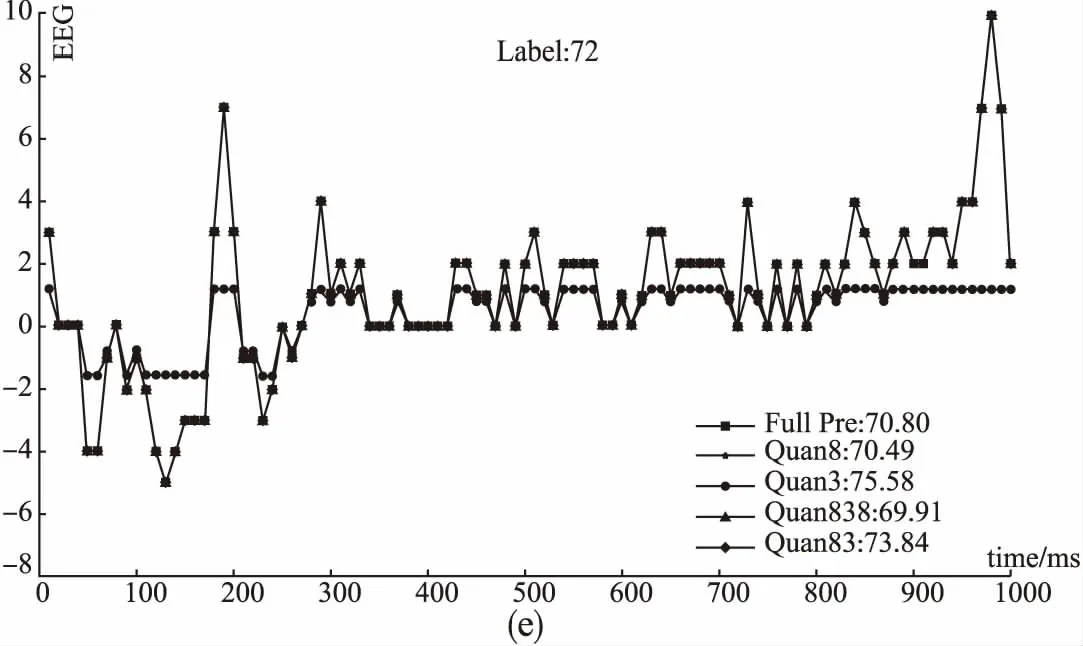
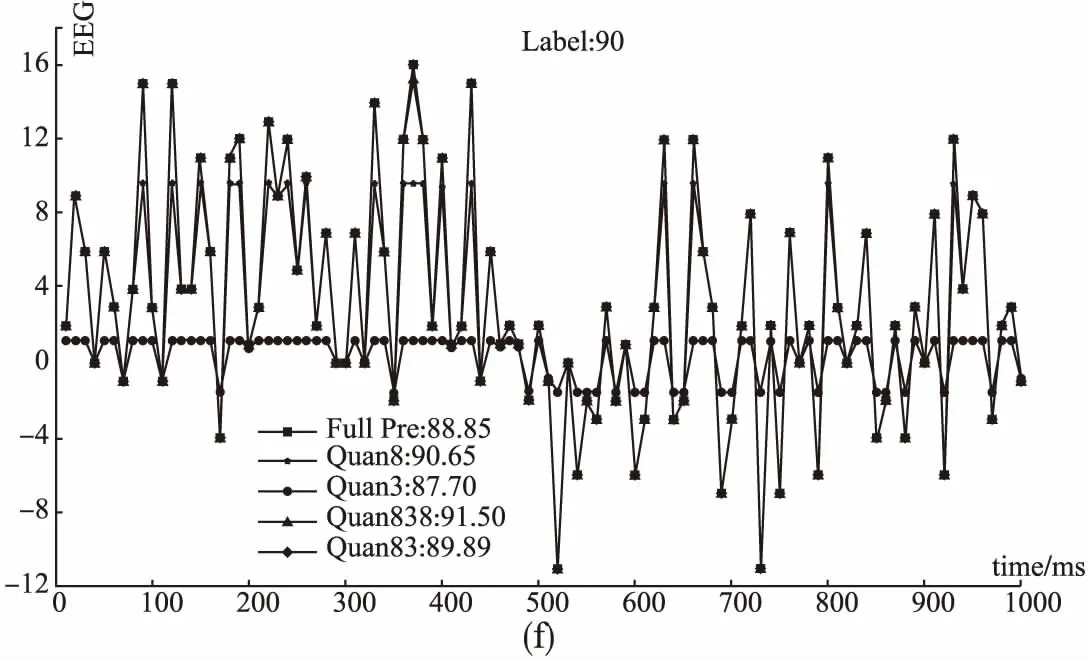
图3 测试集中代表性的EEG波形图和计算得到的BIS值Fig.3 Representative EEG waveform and calculated BIS value from test set
5 结 论
本文提出了一种基于SIMD指令集的卷积神经网络计算加速方法,旨在解决传统ARM处理器算力低,不适用于实时性需求比较高的应用场景的问题.并将该方法用于处理EEG信号来进行手术过程中麻醉深度监测.本文通过可学习步长量化的方法得到低位宽的网络参数,网络参数量由993.216kB下降到 97.39kB,下降了90.19%,极大地降低了网络参数存储空间;浮点数的乘累加次数由1.53M次下降到6.42k次,下降了99.58%,网络的运算速度得到很大提升.采用数据流架构的SIMD卷积加速器,各卷积层可分别加速几十倍、几百倍,甚至一万多倍,在Ultra 96-V2开发板的ARM处理器上用Python调用加速模块实现整个网络的运算,仅需39.64ms就可以处理时间跨度为1s的EEG单通道信号,速度提高到原来的10.5倍,且功耗仅为0.1J.极大地提高了处理速度,在ARM处理器上能够实现最多25通道EEG信号的实时处理.采用可学习步长的量化方法,在提升速度、降低功耗的同时,基本保持网络预测的准确率,能够很好地预测出麻醉深度.同时本文中用Python调用加速模块,参数传递比较耗时,优化调用部分的设计,进一步提高整个网络的速度,仍是未来有待研究的问题.
