KNMC:基于近内存计算的k-NN和k-means加速器设计
2023-07-15刘博生吴亚兰武继刚
连 铎,刘博生,吴亚兰,武继刚
(广东工业大学 计算机学院,广州 510006)
1 引 言
k近邻(k-Nearest Neighbor,k-NN)算法和k-均值(k-means)算法为机器学习中的经典算法.在大数据时代,k-NN和k-means在数据挖掘[1,2],医学成像[3,4],3D点云[5],文本分类[6],人脸识别[7]等领域广泛应用.k-NN是一种简单常用的分类算法,通过比较出待测样本与训练集样本距离最近的k个样本,得出待测样本的分类.k-means是一种无监督学习聚类算法,实现将距离相近的样本聚集进行分类.
尽管k-NN和k-means应用广泛,但是,在大数据处理过程中,k-NN和k-means在计算和数据传输过程需要消耗巨量的能耗开销.这源于k-NN和k-means需要对不同数据进行反复距离计算.例如,文献[8]在Intel Xeon E5-4620 CPU上使用UCI Gas数据集测试k-NN和k-means.结果显示k-NN的距离计算过程占其总运行时间的84.44%,而k-means的距离计算过程占总运行时间的89.83%.在反复的距离计算中,处理单元(Process Element,PE)需要不断的对片外动态随机存取存储器(Dynamic Random-Access Memory,DRAM)设备进行读写,产生巨大的能耗开销.
前人已针对k-NN和k-means展开硬件加速方面的研究.PuDianNao[8]提出一个基于专用集成电路(Application Specific Integrated Circuit,ASIC)的k-NN和 k-means加速器硬件架构.然而,由于该加速器的存储系统与计算部件是分离的,输入必须从片外DRAM设备通过内存层次结构传输到用于计算的PE部件中,存在严重的 “内存墙(memory wall)”[9]问题,导致加速器的计算性能和能效不佳.
近内存计算(near-memory computing)[10]是缓解“内存墙” 的一项重要技术.近内存计算通过将数据处理单元设计于数据中心附近,使数据传输拥有更高的带宽,最大限度地减少数据移动所带来的能耗开销[11-13].近内存架构虽然减少了加速器对片外DRAM的读写能耗,但是由于k-NN和k-means算法在计算和传输过程会频繁地读写片外DRAM,依旧会导致加速器巨量的能耗开销.简单地将加速器直接设于近内存部件中仍会导致加速器效率低下,需要灵活的调度流来减少加速器对片外DRAM的读写频率.另一方面,近内存计算技术减少了加速器片外DRAM读写能耗,片上缓存和PE元件的能耗占比变高,这使得对加速器的设计空间探索变得更有意义.
本项工作提出一种基于近内存计算的k-NN和k-means加速器(简称KNMC)设计.与传统基于ASIC的加速器相比,KNMC通过近内存处理数据减少数据传输能耗.为灵活支持k-NN 和 k-means 加速计算,本项工作设计可配置的灵活近内存加速器架构,有效减少硬件资源开销.同时,本文发现加速器在PE规模大小和片上缓存(on-chip buffer)容量大小对其整体性能和能耗都有很大影响.本项工作通过设计不同的加速器配置方案,探索在这些权衡因素下,加速器达到最优能效的方案.
本文的主要贡献包括3个方面:
1)提出一种基于近内存计算的k-NN和k-means硬件加速器硬件架构(KNMC).所设计的加速器能通过硬件重配置,灵活支持k-NN和k-means硬件加速.
2)在近内存架构前提下,本文通过评估不同设计方案,权衡不同片上缓存大小和PE大小下的能效分析,探索最佳能效下的片上缓存容量和PE规模配置.
3)综合实验结果表明,所提出的设计与前人最先进的基准加速器PuDianNao相比,对k-NN实现1.5倍的性能提高和2.1倍的能效提升; 对k-means实现1.2倍的性能提高和1.5倍的能效提升.
2 相关工作
本节主要介绍k-NN 和k-means相关研究,以及本项工作与前人工作的不同之处.
部分研究人员针对k-NN或k-means展开了加速研究.针对k-NN加速计算器的研究中,Mokhles Aamel.Mohsin等人提出一个由微处理器和定制k-NN加速器组成的异构系统[14].该系统能实现数据预处理阶段,进行计算优化以提高分类精度.Reid Pinkham等人设计一个基于k-d树的k-NN加速器QuickNN[15],通过利用k-d树对输入的数据集进行分层,从而减少k-NN距离计算的计算量,相比于CPU基准,能提升19倍性能.
针对k-means加速器的研究中,Winterstein等人提出基于树结构的k-means加速器[16].该加速器使用二叉k-d树结构存储数据,实现减少计算量以提升性能.最近Li Du等人提出一种适用于高维度数据计算的k-means加速器设计[17],通过设计二级移位位数比较器实现减少数据比较的能耗.
部分研究人员还设计同时支持加速k-NN和k-means的加速器.Daofu Liu等人提出PuDianNao,一个基于ASIC的能够同时支持k-NN和k-means加速的加速器.该加速器通过对算法的共同点进行分析,能够充分利用硬件资源进行加速计算,相比于NVIDIA K20M GPU,能提升1.2倍性能,并减少128.41倍能耗.
上述的加速器,都需要与片外DRAM设备频繁进行数据交互,而在与片外DRAM设备进行数据传输时,会产生巨大的能耗开销.本项研究针对上述问题设计一种适用于k-NN和k-means的近内存可配置加速器.同时,本项工作通过设计空间探索,探索最优片上缓存容量和PE规模配置,实现最优能效.
3 研究动机
本节主要介绍研究动机,包括研究来源和研究出发点.
本项工作提出基于近内存计算的k-NN和k-means加速器.近内存计算将加速器的架构耦合于片外DRAM附近,这样大大减少了数据传输时数据移动的硬件资源消耗,极大程度地减少读写片外DRAM设备所需要的能耗.尽管如此,简单将加速器搬运到近内存部件仍会导致加速器部件效率低下.本项工作提出通过灵活的k-NN和k-means调度使得加速器能够充分利用计算资源.
在其距离计算中,由于片上缓存资源有限,需要和片外DRAM设备进行交互,减少片外访存效率是提高能效的关键.尽管前人加速器早有通过设计空间探索片上缓存在加速器中的效率影响[18],但是很少有工作关注片上缓存和PE规模同时对近内存加速器的效率影响.其中,片上缓存的容量大小影响加速器读写操作的延迟和能耗.PE规模决定同时进行处理的数据量.近内存计算减少加速器读写片外DRAM的能耗开销,使得片上缓存容量和PE规模对加速器读写操作的能耗影响变得更大.加速器不仅需要选择合适的PE数量,更是需要选择适当容量的片上缓存部件避免不必要的能耗开销.为探索得出加速器的最优能效,本项工作先量化加速器能效和片上缓存、 PE规模的最优化问题,然后通过求解最优化问题,得出在能效达到最优时的加速器片上缓存容量和PE规模配置.
4 预备知识
本节主要介绍本加速器所涉及到的近内存计算技术,k-NN算法和k-means算法.
4.1 近内存计算
近内存计算的主要目标,是让数据处理在数据所在的位置附近进行,即将计算处理单元耦合在数据附近,从而最大限度地减少数据移动的资源消耗.而3D集成和堆叠技术的发展,有效支撑近内存技术的实现[19].
图1展示了近内存加速器与传统加速器的区别.图1(a)是传统加速器概念架构.该类型加速器与片外DRAM设备进行读写数据时,需要经过内存层次结构的长数据通道,才能将数据传输至处理单元模块以进行计算.片外DRAM的读写能耗限制加速器的能效瓶颈.图1(b)为基于双列直插式内存模块(Dual In-line Memory Module,DIMM)的近内存计算加速器概念架构.加速器直接设计在片外DRAM附近,将数据处理传输过程缩减,减少数据的移动开销,降低读写DRAM能耗,从而提高加速器能效.

图1 传统加速器与近内存加速器架构比较Fig.1 Comparison between conventional accelerators and near-memory accelerator
4.2 k-NN算法
k-NN[20]是一种基本的分类和回归算法,主要用于已知分类情况下,对未知类型的数据进行分类.
k-NN包括两个关键步骤.首先,每个待测样本都需要与整个训练集样本进行距离计算.如公式(1)所示:
dis(x-yi)
(1)
x表示待测样本,yi表示训练集样本,公式(1)求出待测样本x与训练集样本yi的欧式距离.其次,k-NN从距离的计算结果中比较找出与待测样本距离最近的k个训练集样本.
在整个k-NN计算过程中,数据之间的距离计算是最主要且最耗时的部分.距离计算的过程需要不断将数据输入到PE中进行处理.片上缓存的容量大小和PE规模在距离计算中至关重要.
4.3 k-means算法
k-means[21]是一种无监督的机器学习算法.k-means主要将数据样本划分为k个无相交的集合,每一个集合称之为一个 “群”(cluster).
k-means主要包括两个步骤.首先,k-means需要进行分群操作.k-means先随机选取k个样本点作为质心(centroid),再将样本数据与这k个质心进行距离计算,比较得出每一个样本数据所属最近质心,如公式(2)所示:
(2)
Ci表示第i个质心对应的群.x表示群集Ci中的样本,yi表示的是群集Ci的质心,dis(x-yi)求出样本x与质心yi间的欧式距离.公式最后将所属相同质心的样本数据归于一个群,得到k个群.
其次,k-means需要进行质心更新操作.k-means将所属同一个质心的数据进行累加平均,得出每一个群的新质心,如公式(3)所示:
(3)
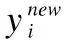
(4)

整个k-means过程中,最耗时的部分为数据与质心之间的距离计算.而且,k-means算法需要多次迭代计算,这意味着需要重复进行数据与质心的距离计算.
5 硬件架构
本节主要介绍所提出的加速器硬件架构,包括加速器的基本架构和调度流.
5.1 基本架构
图2(a)为所提出KNMC加速器的整体架构.KNMC位于DIMM中,DIMM桥接处理单元和标准的内存通道接口.内存控制器通过内存通道接口与内存中的加速器进行通信.由于该加速器靠近DRAM,该架构可以减少片外DRAM设备与加速器交互的数据移动所需要的能耗开销.
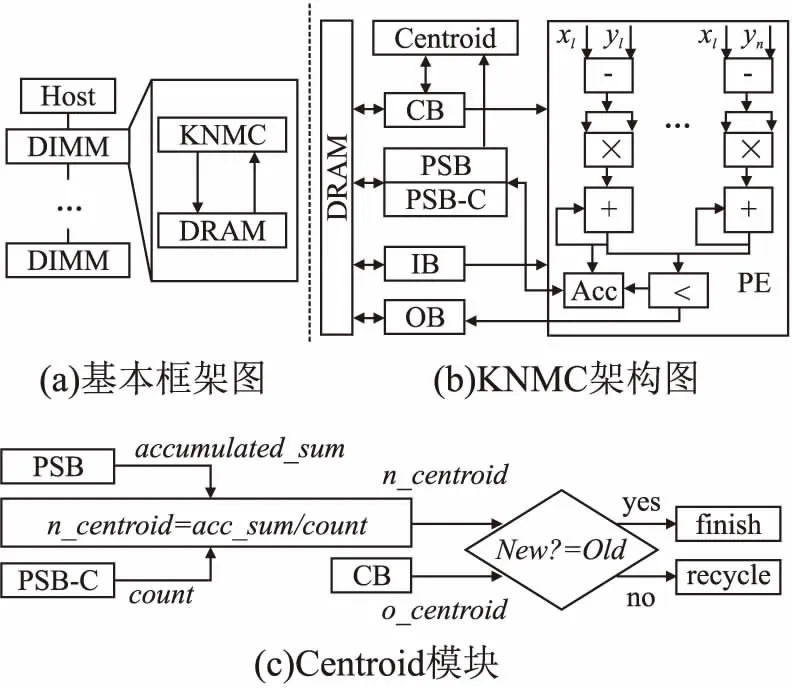
图2 KNMC加速器Fig.2 Proposed KNMC accelerator
图2(b)展示KNMC组件,主要包括PE计算部件,片上缓存和Centroid模块.PE模块主要用于对数据之间的距离计算和所产生的结果进行累加.KNMC包括5个片上缓存,分别是:用于存放质心的片上缓存CB; 用于存放输入数据的片上缓存IB和输出数据的片上缓存OB; 用于存放部分和的片上缓存PSB和存放部分和累加计数的片上缓存PSB-C.Centroid模块用于实现对质心的更新和新旧质心比较.
PE模块用于计算不同数据间的距离,以及对所产生的结果进行累加.在k-NN的距离计算上,由公式(1)得知,PE模块以待测数据x和训练数据{y1,y2…yn}作为输入,得出x1与{y1,y2…yn}距离最近的k个训练数据,最后输出k个训练数据的索引.在k-means中,由公式(2)得知,PE模块以待测数据x和质心{y1,y2…yn}作为输入,计算数据x与每一个质心yi的距离,然后比较x与{y1,y2…yn}距离的大小,得出距离最小的一个,输出其对应的质心索引.PE模块同时进行对应质心群上的数据累加,输出对应的累加结果.
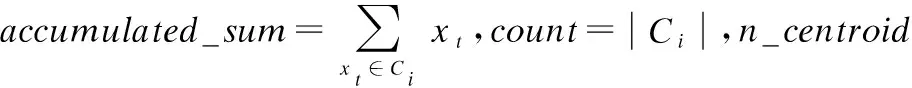
5.2 总调度流程
图3(a)、图3(b)、图3(c)介绍KNMC的总调度流程,包括输入流程,计算流程和输出流程.首先,KNMC进行输入流程.图3(a)介绍KNMC的输入流程.KNMC从片外DRAM读取相应的数据作为输入,写入片上缓存IB中,同时,若有需要,则读取另外的数据写入另一个片上缓存CB中.然后,KNMC进入计算流程.图3(b)介绍KNMC的计算流程.KNMC将输入数据从片上缓存输入到PE模块中进行距离计算等一系列操作.输出相应数据存储于片上缓存OB中.同时,若有需要,KNMC将另外的数据输出于片上缓存PSB和PSB-C中,再经由Centroid模块调度.最后,KNMC进行输出流程.图3(c)介绍KNMC的输出流程.KNMC将数据从片上缓存 OB写入片外DRAM中,待OB数据全部写出,结束调度.
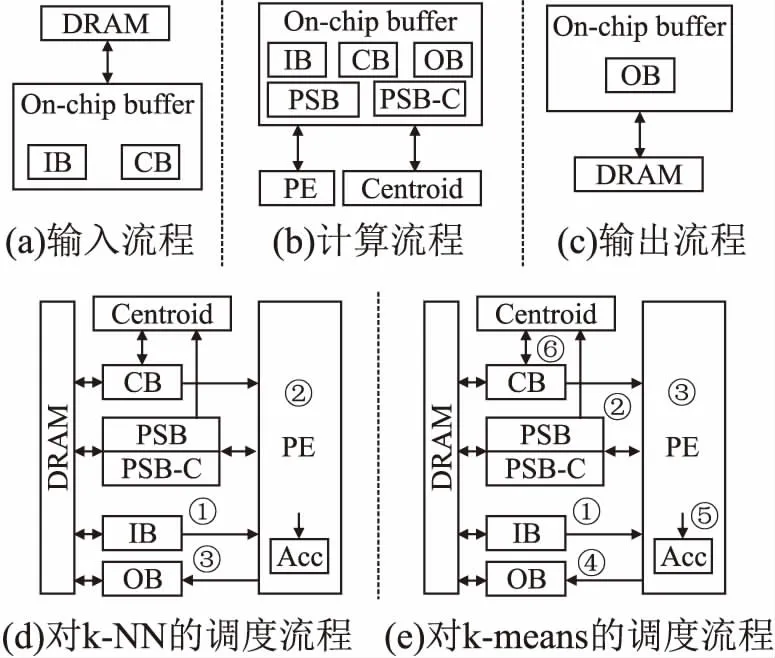
图3 KNMC总调度流程及对不同算法的调度流程举例Fig.3 KNMC overall scheduling process and illustration of KNMC for different algorithms
5.3 k-NN调度流程
图3(d)为KNMC加速计算k-NN算法的整个过程.图中灰色部分是未参与调度的模块.以下仔细介绍整个k-NN的调度过程:
1)KNMC从DRAM读取待测数据和训练数据写入片上缓存IB.然后KNMC从IB读取一个待测数据,广播到PE上,同时从IB读取多个训练数据,输入到PE;
2)待测数据与多个训练数据在PE中同时进行距离计算.KNMC将距离计算结果进行比较,最后得出k个待测试数据最近的距离数据;
3)KNMC将这k个待测数据写入片上缓存OB.待整个流程结束后,KNMC将OB中的结果写入DRAM中,完成加速器对k-NN算法的计算.
5.4 k-means调度流程
图3(e)为KNMC加速计算k-means算法的整个过程.以下仔细介绍整个k-means的调度过程:
1)KNMC从DRAM读取待分群数据,写入片上缓存IB.同时,KNMC从IB读取一个待分群数据广播到PE;
2)KNMC从DRAM读取初始化好的质心写入片上缓存CB.同时,KNMC从CB读取多个质心,输入到PE;
3)KNMC将待分群数据与多个质心同时进行距离计算并比较,得出待分群数据距离最近的质心索引,即该数据所属的群索引;
4)KNMC将所得出的群索引输出并写入OB.若OB已被写满,则KNMC对OB进行刷新,将OB中的数据写入DRAM中,再将索引写入OB;
5)KNMC将片上缓存PSB对应索引的部分和与当前数据进行累加,并根据该索引从片上缓存PSB-C读出对应的计数进行累加,累加后的部分和与计数分别写入PSB和PSB-C中;
6)KNMC将存储于PSB中的部分和与PSB-C中的计数输入到Centroid模块中进行相除,得出新的质心,并将新的质心与旧的质心进行比较.若新质心与旧质心相同,则循环停止,算法结束; 若新质心与旧质心不相等,则KNMC重新跳转到①继续执行上述步骤.
6 设计空间探索
本节针对加速器PE规模和片上缓存容量进行设计空间探索.本节首先通过PE规模和片上缓存容量作为变量建立最优化问题.其次,求解最优化问题,得出最优加速器片上缓存容量和PE规模配置.
6.1 最优化问题的确立
本次工作所要优化的参数是片上缓存容量大小和PE数.片上缓存参数为5个片上缓存IB,OB,CB,PSB和PSB-C的容量大小:wIB,wOB,wCB,wPSB和wPSB-C.处理单元PE的参数为PE数量NPE.为求得加速器的最优能效,本项工作需要对wIB,wOB,wCB,wPSB,wPSB-C和NPE尽可能进行组合,通过不同组合求出最优能效.因为加速器是针对k-NN和k-means两种算法进行加速,为求得对k-NN和k-means两种算法的最优能效值,这里本项工作将加速器最优能效表示为:
max(fk-NN(BS,NPE)×fk-means(BS,NPE))
(5)
该公式由以下条件约束:
BS=C(wIB,wOB,wCB,wPSB,wPSB-C)
(6)
NPE∈{1,2,4,8,16,32,64}
(7)
wIB,wOB,wCB,wPSB,wPSB-C∈{1,2,4,8,16,32,64}kB
(8)
在式(5)中,fk-NN(BS,NPE)表示加速器调度k-NN的能效,fk-means(BS,NPE)表示加速器调度k-means的能效.约束(6)中,BS表示加速器中wIB,wOB,wCB,wPSB和wPSB-C的组合.约束(7)确定NPE的数量选择范围.约束(8)确定wIB,wOB,wCB,wPSB和wPSB-C的容量选择范围.fk-means(BS,NPE)和fk-NN(BS,NPE)都表示对算法加速的总能效,该能效等效于:
(9)
其中fenergy efficiency代表加速器的总能效,fenergy代表加速器的总能耗,该能耗由片上缓存,KNMC和片外DRAM设备所消耗的能耗组成.fperformance表示加速器的总性能.通过式(5)~式(9),求得该加速器wIB,wOB,wCB,wPSB,wPSB-C和NPE的最优配置,以得到最优能效.
6.2 求解最优问题
由约束式(7)、式(8)可知,变量wIB,wOB,wCB,wPSB,wPSB-C和NPE值个数非常有限.本项工作通过穷举法对这些变量进行组合,结合式(5)~式(9)求解该最优问题.本项工作将每一种组合的情况一一列出,从这些组合中找出最高能效的片上缓存容量和PE规模配置.为使加速器获得最佳能效,提高加速器对不同数据集的适应能力,本项工作采用多个数据集进行计算空间探索.通过计算出加速器调度每一个数据集的能效,再对所有数据集的能效求几何平均,本方法将得出用于空间探索的评估计算的能效参考值.
7 实验方法
本节介绍实验的具体方法,包括部分参数选取,实验所选用的工具和实验步骤.

本项工作主要通过两个步骤对加速器进行评估.第1步是通过设计空间探索,求得加速器的最优能效配置.由于本项工作的参数较多,本项工作先通过不同PE规模的能效影响确定PE数量,再在该PE规模下进一步确定最优片上缓存容量组合.在本项工作中,每一个PE包含16个乘法器,32个加法器,14个比较器和1个累加器.第2步是将本项工作提出的加速器与前人最先进的加速器基准,PuDianNao[8],进行比较.PuDianNao能够对k-NN和k-means进行加速.
8 实验结果
本节主要介绍实验结果并对实验结果进行分析.
8.1 设计空间探索结果
本项工作通过PE数量和片上缓存的容量进行设计空间探索,PE的数量取值从1个~64个(每个PE有16个乘法器,32个加法器,14个比较器和1个累加器),而每一个片上缓存的容量取值从1kB~64kB.片外DRAM的容量取值为1GB.
图4为取不同PE规模时,该加速器的最高归一化能效值.加速器由公式(9)求出能效值,加速器的归一化能效值由最低能效值点作为基准点求出.可以看出,当PE数量为8时(NPE= 8),加速器能够得到最高的能效值.在图4中,随着PE数量的增加,加速器的最高能效值先增长,然后再减少.这是由于随着PE数量的增加,每一次并行计算的数据增加,计算所需要的周期数就会随之减少,即性能得到提升,能效随之提升.但同时,PE规模的增大造成加速器的功耗增加,而且需要将片外DRAM设备和片上缓存的I/O位宽增加保证计算过程的连续性.这导致加速器的能耗增加.当能耗的增加程度高于性能的提升程度时,加速器的能效也会随之下降.经过本项工作的实验得知,该加速器在PE数量等于8时能够得到最佳能效.
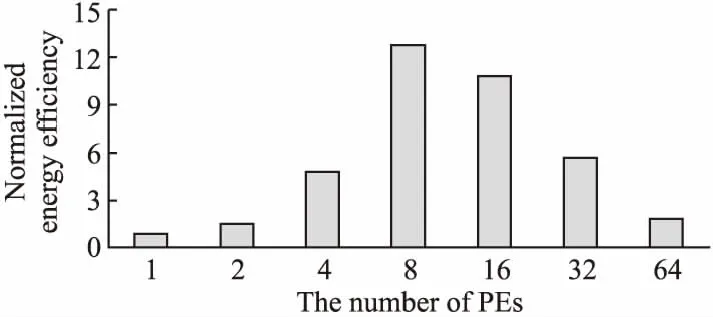
图4 不同PE规模的归一化能效比较Fig.4 Normalized energy efficiency comparison of different PE scales
图5(a)为PE数量等于8时,加速器采用不同容量的片上缓存时的归一化能效变化图.本项工作通过对比加速器不同片上缓存大小配置下的能效值,选取能效最高值作为加速器的能效最优点.当wIB=16kB,wOB= 16kB,wCB= 4kB,wPSB= 4kB和wPSB-C= 1kB(总片上缓存大小为41kB)时加速器能达到能效最优点.可以发现,加速器在片上缓存容量较小时,所取得的能效很低.因为对于CB,PSB这些片上缓存,CB所存储的是质心值,PSB所存储的是各个数据中间累加的部分和.它们所需存储的值相对较少,但却需要频繁地读取所存储的全部数据.当容量取值太小导致无法将数据全部存储时,加速器需要频繁地对片外DRAM进行读写以暂存无法存储的数据,这造成大量的能耗开销.当片上缓存容量取值较小时,加速器需要反复刷新片上缓存,读写片外DRAM导致延时增加,导致性能降低.当片上缓存容量取值较大时,加速器能效也会降低.因为随着片上缓存容量的增加,其访问延时和访问能耗也增加.经过实验得知,wIB= 16kB,wOB= 16kB,wCB= 4kB,wPSB= 4kB和wPSB-C= 1kB时能够得到加速器的最优能效.
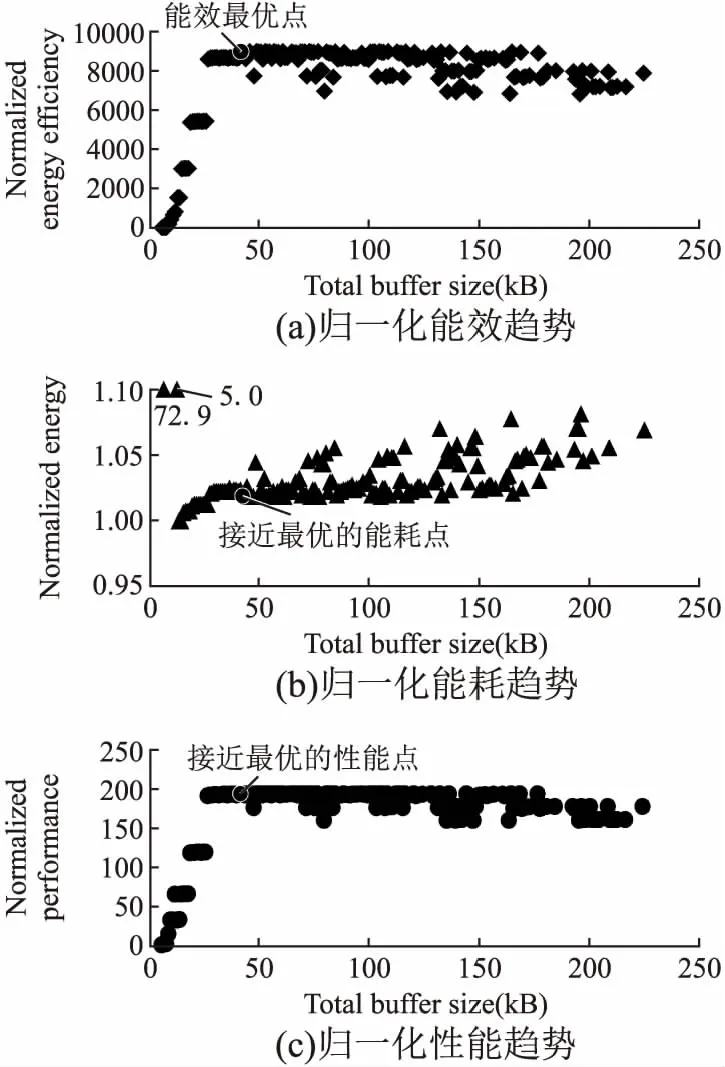
图5 NPE=8时不同片上缓存大小下的归一化能效,能耗,性能趋势Fig.5 Normalized energy efficiency,energy and performance trend under different on-chip buffer sizes when NPE=8
图5(b)为该加速器在PE数量等于8时,采用不同容量的片上缓存时的归一化能耗图.图5(b)中接近最优的能耗点,是指在能效最优的加速器配置下,加速器的相对能耗值.另外,由图可见在片上缓存较小时有两个能耗值相对较大(72.9和5.0).这是由于当CB,PSB两个片上缓存容量都较小时,无法将数据全部存储,加速器需要频繁对片外DRAM设备读写.当CB片上缓存的容量能够容纳整个质心数据时(wCB= 4kB),加速器对片外DRAM设备的读写会极大程度的减少,加速器的相对能耗值会从72.9下降至5.0.当PSB片上缓存容量能够容纳整个中间部分和的数据时(wPSB= 4kB),加速器与片外DRAM设备的数据传输也会减少,从而减少能耗,加速器的相对能耗值从5.0降至1.0.之后加速器的相对能耗值随着片上缓存容量的增大而增加.
图5(c)为该加速器在PE数量等于8时采用不同容量片上缓存时的归一化性能图.图5(c)中接近最优的性能点是指能效最优时加速器的相对性能值.片上缓存的读写延时随片上缓存容量的增大而增大.片上缓存总容量在小于26kB时,相对性能取值很小,这是由于片上缓存所能存储的数据量少,导致片上缓存刷新频率高,对片外DRAM的读写频率高,导致加速器性能下降.此时相对性能随着片上缓存容量的增加而增加,因为片上缓存容量的增加能够极大程度减少片外DRAM的读写频率.当片上缓存容量大于26kB,片上缓存容量的增大对片外DRAM读写频率影响减少,访问片上缓存的时延成为影响性能的主要因素,导致相对性能开始随片上缓存容量的增大而减小.
8.2 性能对比结果
本项工作加速器的PE规模和片上缓存与基准加速器PuDianNao规模不同.为进行公平的性能比较,本项工作将KNMC的PE规模重置为与基准加速器相同(NPE=16).图6(a)显示本项工作与基准加速器对k-NN加速的归一化性能比较.图6(b)显示本项工作与基准加速器对k-means加速的归一化性能比较.结果表明,KNMC对k-NN加速的平均性能是基准加速器的1.5倍,对k-means加速的平均性能是基准加速器的1.2倍.性能的提升归于加速器灵活的调度流使加速器充分利用硬件资源,提升了加速器的PE利用率.加速器对k-NN加速的PE利用率提升1.5倍,对k-means加速的PE利用率提升1.3倍.
8.3 能效对比结果
该能效比较基于加速器的原始配置.KNMC的配置是通过空间探索得出的最佳配置(PE数量NPE= 8,片上缓存wIB= 16kB,wOB= 16kB,wCB= 4kB,wPSB= 4kB,wPSB-C= 1kB,总片上缓存容量为41kB).KNMC的频率是800MHz.KNMC硬件架构中,PE的功耗为50.6mW,总面积为0.6mm2,Centroid模块的功耗为1.1mW,总面积为0.05mm2,计算延迟时间占比是总时间的1.39%.基准加速器的频率是1GHz,片上缓存总大小为32kB.基准加速器的PE规模是KNMC的2倍.图6(c)和图6(d)分别为KNMC与基准加速器对k-NN和k-means加速的归一化能效比较.结果表明,KNMC对k-NN加速的平均能效是基准加速器的2.1倍,对k-means加速的平均能效是基准加速器的1.5倍.KNMC获得更高的能效主要归于近内存计算减少对片外DRAM读写所需的能耗,以及合理的片上缓存容量和PE规模配置.
9 总 结
本项工作提出一个基于近内存计算的k-NN和k-means加速器.该加速器通过灵活的调度流,让加速器充分利用硬件资源对k-NN和k-means进行加速计算.同时,本项工作通过设计空间探索,寻求最优的片上缓存容量大小和PE规模,实现加速器的最优能效.实验结果表明,与前人最先进的基准加速器相比,本项工作对k-NN实现1.5倍的性能提高和2.1倍的能效提升,对k-means实现1.2倍的性能提高和1.5倍的能效提升.
