面向方面的自适应跨度特征的细粒度意见元组提取
2023-05-24陈林颖刘建华孙水华郑智雄林鸿辉
陈林颖,刘建华*,孙水华,郑智雄,林鸿辉,林 杰
(1.福建工程学院 计算机科学与数学学院,福州 350118;2.福建省大数据挖掘与应用技术重点实验室(福建工程学院),福州 350118)
0 引言
面向方面的细粒度意见提取(Aspect-oriented Finegrained Opinion Extraction,AFOE)[1]是细粒度情感分析[2-3]的一项重要任务,提取给定句子的意见对(方面词,意见词)或意见三元组(方面词,意见词,情感极性)。其中,方面词和意见词是两个重要因素:方面词也被称为意见目标,通常指句子中讨论的实体单词或短语;意见词是一个表达主观态度的词或短语。例如,“这家酒店的环境很好,但服务太差”,“环境”和“服务”是两个方面词,“很好”和“太差”是两个意见词。
意见二元组(意见对)提取(Opinion Pair Extraction,OPE)是以(方面词,意见词)的形式从一个句子中提取所有的意见对。这个任务需要提取三个意见因素,即方面词、意见词以及它们之间的配对关系。在上个例子中包含的两个意见对分别是(环境,很好)和(服务,太差),前者表示方面词,后者表示相应的意见词。与OPE 相比,意见三元组提取(Opinion Triplet Extraction,OTE)增加了预测意见对的情感极性,两个意见三元组分别为(环境,很好,积极),(服务,太差,消极)。OPE 或OTE 任务的主要挑战在于一个句子中经常会出现一个方面词对应多个意见词,或一个意见词对应多个方面词。
在传统的意见对提取任务中,大多研究工作致力于在一个联合框架中同时提取方面词和意见词,Wang 等[4]将递归神经网络和条件随机场集成到一个统一的框架中,用于显式方面词和意见词的联合提取;Yu 等[5]提出一种全局推理方法,通过显式的方式对方面词和意见词之间的几个句法约束建模揭示它们之间的关系;Dai 等[6]提出了一种基于依赖解析结果的算法,从现有训练样本中自动挖掘提取规则,解决了训练数据缺乏的问题。然而,这些方法抽取出的方面词和意见词相互独立,忽略了方面词和意见词之间的配对关系。为了解决这一问题,Wu 等[1]提出了网格标记方案(Grid Tagging Scheme,GTS),该方案预测了所有可能的词对之间的情感关系,并通过特定的解码策略生成三元组;Li 等[7]提出了基于位置感知的 BERT(Bidirectional Encode Representation from Transformers)框架(Position aware BERTbased Framework,PBF)[8],以管道方式相继提取方面词、对应的意见词并预测该意见对的情感极性;Mukherjee 等[9]基于指针网络,在每个时间步生成完整的意见三元组。夏鸿斌等[10]提出了GTS 的词对关系标注方案(Word-Pair Relation Tagging Scheme,WPRTS),通过改进GTS 的词对关系标注构建词对关系网络,能提高三元组提取性能。但是,以上方法都未考虑意见对局部上下文重要性。如图1 所示,句中有两对意见三元 组,分别为(hot dogs,top notch,positive)和(coffee,average,neutral)。观察图1 可知,远距离的意见词average 可能影响到方面词hot dogs 的情感极性;反之,意见词top notch 可能影响到方面词coffee 的情感极性。由此可知,方面词与接近其自身的意见词更相关,但远距离的意见词可能会产生负面影响,降低对情感极性预测的准确率。
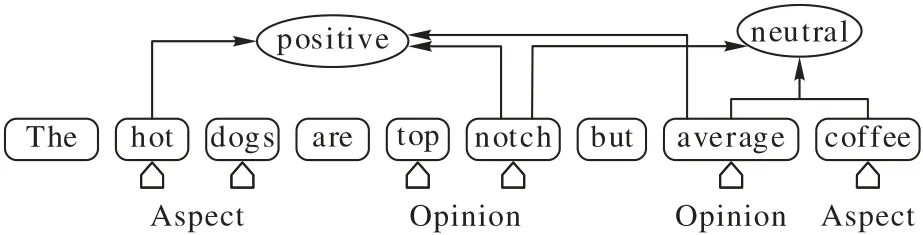
图1 意见对对情感极性预测的影响Fig.1 Influence of opinion pair on sentiment polarity prediction
2019 年,Zeng 等[11]认为方面词的情感极性与其局部上下文特征相关,越接近方面词的语义与方面词的情感极性关系越密切,而远距离的上下文可能造成负面影响,因此,他们提出了基于局部焦点(Local Context Focus,LCF)机制的两种方法,即上下文特征动态掩码(Context-feature Dynamic Mask,CDM)方法和上下文特征动态加权(Context-feature Dynamic Weighting,CDW)方法。Yang 等[12]采用两个独立的BERT 分别对句子和方面词建模,再通过特征交互学习(Feature Interactive Learning,FIL)层预测方面词的情感极性。但是这些都不适用于意见二元组或意见三元组任务。
针对以上问题,本文提出了自适应跨度特征的网格标记方案(Adaptive Span Feature-Grid Tagging Scheme,ASF-GTS)模型,采用BERT 提取句子上下文编码及特征,通过自适应跨度特征(Adaptive Span Feature,ASF)方法对意见对的跨度特征采样,再利用GTS 将意见对提取转化为统一的网格标记任务,并通过特定的解码策略生成对应的二元组或三元组。
本文的主要工作如下:
1)为加强意见对局部上下文的联系,消除远距离的负面影响,提出ASF 方法对意见对的局部上下文采样,并将该方法与GTS 模型结合提高OPE 或OTE 任务的F1 指标;
2)引入自适应跨度距离(Adaptive Span Distance,ASD)评估意见对跨度上下文的依赖关系,使ASD 内的语义特征得到保留,有效提高方面情感表达的性能;
3)在AFOE 数据集上对OPE 和OTE 进行大量实验,实验结果表明ASF-GTS 模型具有更好的情感特征保留能力,能更精确地提取意见对及其情感极性,在两个任务中都取得了更好的F1 值,验证了本文模型具有很好的泛化性。
1 相关工作
ASF-GTS 模型由ASF 方法与GTS 模型结合而成。大部分现有的研究工作在处理OPE 和OTE 任务时都采用了管道方式,但管道方式容易受到错误传播,降低实际应用的人机互动的速度,因此,本文采用GTS 模型通过统一标签方式解决管道问题,而ASF 方法则通过改进LCF 使之扩展到OPE 或OTE 任务中。
1.1 网格标记方案
GTS 由三部分组成,分别是标签标记、推理策略和解码算法。它通过标记所有词对之间的关系,成功地将句子的所有意见因素提取纳入一个统一的网格标记任务,然后通过特定的解码算法生成意见对或意见三元组。
1.1.1 标签标记
对于OPE 任务,GTS 使用标签集{A,O,P,N}标记句子中所有词对(wi,wj)。标签A 表示词对都为相同方面词;标签O表示词对都为相同意见词;标签P 表示词对中的一个单词为方面词,另一个单词为意见词且可以形成意见对;其他词对标签用N 表示。这里的词对是无序的,(wi,wj)和(wj,wi)的关系相同,因此,使用上三角网格标记。
对于OTE 任务,将之前的标签P 改为代表词对情绪的标签{POS,NEG,NEU},三个标签分别对应词对(wi,wj)的情感极性为积极、消极及中立。此时OTE 任务的标签集为{A,O,POS,NEG,NEU,N}。
1.1.2 推理策略
为利用每个词对之间的潜在关系促进AFOE,Wu 等[1]设计了推理策略。推理策略主要依赖于两点:第一,方面词与意见词不相容,例如,词对(wi,wj)中有一个单词为方面词,则这个词对标记就不可能是表示相同意见词的O 标签,反之亦然;第二,先前的词对标签预测可以推断当前回合(wi,wj)的标签。因此,GTS 推理策略可以通过迭代预测和推理得出词对标签。
初始回合,从下一层得到(wi,wj)的特征表示,将它拼接为rij,并通过线性变换得到初始标签预测的概率分布,同时将rij作为初始特征表示上述推理过程如式(1)~(8):
1.1.3 解码算法
在GTS 中获得句子预测标记结果后,大量的标签标记造成召回率降低。因此,GTS 设计了简单有效的方法解码意见对或意见三元组。首先,根据预测标记,在主对角线上找出所有的方面词和意见词,然后将连续的A 标签视为一个方面词,连续的O 标签视为一个意见词。提取到的方面词A 和意见词O 至少能形成一个意见词对(a,o),其中,a表示方面词,o表示意见词,并将这个词对标记为P。
对于OTE 任务,判断提取到的词对(a,o)的情感极性c是否属于三类情绪标签{POS,NEG,NEU}。若不属于,则认为a和o不能形成三元组;若属于,则得到意见三元组(a,o,c)。
1.2 局部上下文特征
LCF 机制通过语义相对距离(Semantic-Relative Distance,SRD)确定上下文,并学习上下文和方面之间的交互关系,增强方面词及其上下文权重。
1.2.1 语义相对距离
Zeng 等[11]在LCF 机制中提出了SRD 用于确定了上下文词是否属于特定词的局部上下文,以帮助模型获取局部上下文特征。具体操作如式(9):
其中:SRDi表示第i个单词与特定词的相对距离;i是上下文词的标记位置;pb是特定词汇的中心位置,b为范围阈值,若SRDi<b,则认为第i个单词属于特定词汇的局部上下文;m为方面词长度,n是句子的长度。
1.2.2 上下文特征动态掩码方法
CDM 方法通过遮掩矩阵M掩盖不属于特定词的局部上下文特征。具体地,将所有的SRD 超出阈值b的特征置为0,不参与特征学习,阈值范围之内的特征保持不变,从而保留方面词的局部上下文特征,遮掩局部上下文之外的权重。计算过程如式(10)~(12)所示:
其中:O为零向量;E为单位向量;EBERT是通过BERT 获得的初始上下文特征。
2 ASF-GTS模型
针对OPE 和OTE 任务,本文提出ASF-GTS 模型。该模型将ASF 方法和GTS 模型相结合:GTS 模型可以消除错误传播的影响,比管道方式更精确地提取意见对及其情感极性;ASF 方法则能够加强与意见对有关的局部上下文联系,消除远距离的负面影响,提高ASF-GTS 模型的准确率。如图2 所示,ASF-GTS 模型主要由嵌入层、特征提取层以及GTS 层三部分组成:嵌入层使用预训练模型BERT 为编码器,获取上下文信息,有助于模型更好地学习特征;然后通过ASF 方法学习意见对的上下文特征;最后由GTS 层对获得的特征表示标记意见对,再利用推理策略促进意见对或意见三元组提取,并通过特定的解码策略解码出意见对或意见三元组。
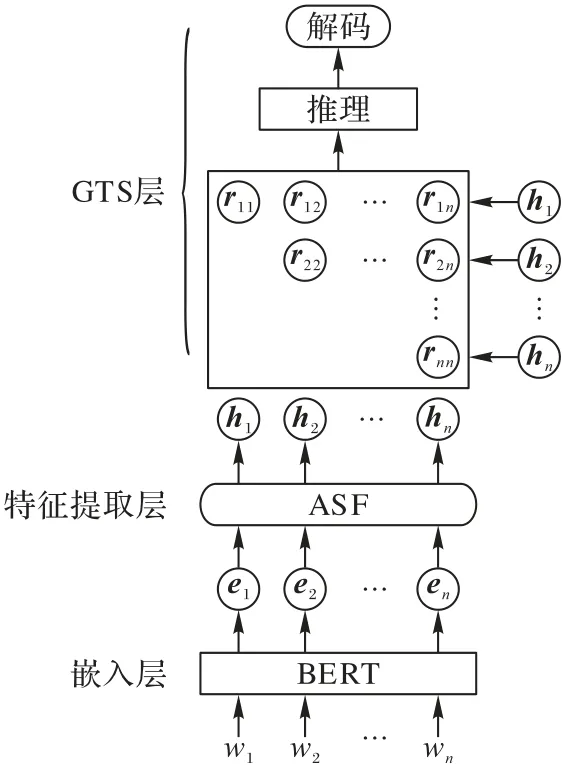
图2 ASF-GTS模型结构Fig.2 Structure of ASF-GTS model
2.1 任务定义
2.2 嵌入层
传统生成词向量方法word2vec[13]和GloVe[14]无法体现在不同语境下的不同语义。BERT 模型针对这一点优化,采用词嵌入、位置嵌入和段嵌入作为词向量表示,并通过多层的双向Transformer[15]对句子建模获取句子上下文表示,将句子s={w1,w2,…,wn}映射为向量EBERT={e1,e2,…,en},wi表示输入句子的第i个单词,EBERT∈Rn×d,其中n表示输入句子长度,d表示词嵌入维度。
2.3 特征提取层
本文提出的ASF 方法是基于LCF 机制中CDM 方法的改进,将CDM 扩展到意见三元组提取任务中。CDM 方法借由SRD 确定方面词的局部上下文词,掩盖非局部上下文词,目的是保留与方面词有关的情感信息。意见词是最能体现方面词情感信息的词语,但是SRD 方法可能导致意见词被掩盖,因此,本文提出ASD 方法代替SRD 方法,自适应地保留方面词与意见词跨度间的特征,以保留情感信息量最多的词语,消除跨度外的词特征,使语义较少的特征不参与学习。
2.3.1 自适应跨度距离
如图3 所示,其中Aspect 箭头指向方面词,Opinion 箭头指向意见词,Mask 大括号内的位置特征将被屏蔽,其余位置特征将得到保留。一个句子中的意见对情况分为三种:图3(a)表示一个方面词对应一个意见词;图3(b)表示一个方面词对应多个意见词;图3(c)表示一个意见词对应多个方面词。针对这三种情况,提出了ASD 自适应调整方面词和意见词之间的跨度。在第一种情况中,“hot dogs”为方面词,“top notch”为对应的意见词,此时ASD 应为方面词的第一个词“hot”的位置到意见词的最后一个词“notch”的位置;反之,若方面词比意见词位置靠后,则ASD 应为意见词的第一个词位置到方面词最后一个词位置。在第二种情况中,方面词为“food”,对应的两个意见词“authentic Italian”和“delicious”,此时ASD 为方面词第一个位置“food”到所有意见词的最后一个单词“delicious”的位置,反之亦然;在第三种情况中,方面词为“service”和“food”,对应的意见词为“excellent”,此时ASD 为所有方面词的第一个单词“service”位置到意见词的最后一个单词“excellent”位置,反之亦然。ASD 方法适用于这三种情况。ASD 的公式如下:
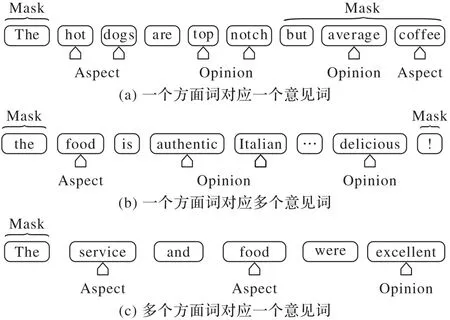
图3 自适应跨度焦点图的三种情况Fig.3 Three cases of adaptive span focus map
其中:ASDt表示句子的第t个意见对的跨度距离;startt和endt分别表示第t个意见对跨度的起始位置和终止位置。
ASD 的算法流程如下:
算法1 ASD 算法。
2.3.2 自适应跨度特征提取
ASF 层保留由ASD 计算得到的跨度特征,跨度之外的特征将被屏蔽。具体地,本文通过计算得到遮掩矩阵A来屏蔽跨度外的词特征,将跨度外的特征置为0,不参与学习,将跨度内的特征置为1 以保留原特征。ASF 计算过程如式(14)~(16):
其中:pi表示第i个单词位置;n表示句子长度;M由n个mi向量组成,mi是第i个单词的遮掩向量。通过ASD 判断pi是否在跨度内:若第i个位置在跨度内,则mi取全为1 的向量E∈Rd;若不在跨度内,mi取全为0 的向量O∈Rd。最后将遮掩矩阵M与嵌入层学习到的语义特征EBERT点乘,以保留跨度内的特征。
2.4 模型训练
本文采用交叉熵损失函数训练所有词对的真实值标记与预测值标记,如式(17):
其中:yij是单词对(wi,wj)的真实值标记表示单词对(wi,wj)的预测值标记,L表示推理回合;C代表标签集,在OPE 任务中C∈{A,O,P,N},在OTE 任务中C∈{A,O,POS,NEG,NEU,N};I(·)指示函数用于验证yij是否属于C。
3 实验与结果分析
3.1 数据集与评价指标
原始的SemEval Challenge 数据集[16]由4 个基准数据集组成,分别是14Res、14Lap、15Res 和16Res,但这些数据集只标注了方面词和对应的情感极性,缺乏对应的意见词注释。面向目标的意见词抽取(Target-oriented Opinion Words Extraction,TOWE)数据集[17]是基于14Res、14Lap、15Res 和16Res 数据集标注对应的意见词,但缺乏方面词和对应的情感极性的注释。因此,Wu 等[1]将原始的SemEval Challenge数据集和TOWE 数据集相结合组成AFOE 数据集。
本文在AFOE 数据集上验证模型的准确性。表1 显示了AFOE 数据集的统计数据,其中:Sen 表示句子总量,Asp 表示方面词总量,Opi 表示意见词总量,Pai 表示意见对总量,Tri表示意见三元组总量。可以观察到一个句子可能包含多个方面词或意见词。此外,一个方面词可能对应多个意见词,反之亦然。

表1 AFOE数据集Tab.1 AFOE datasets
为评估本文模型的性能,使用召回率R(Recall)、精确度P(Precision)、F1 值F1(F1-score)作为评估指标。只有当预测和基本真值完全匹配时,提取的意见对或意见三元组才被视为正确的。三种指标的计算方法如下:
其中:TP表示预测样本和真实值都为正的数量;FN表示预测样本为负真实值为正的数量;FP表示预测样本为正真实值为负的数量。
3.2 实验参数设置
模型采用BERT 生成词向量,词向量维度为768,模型设置学习率5 × 10-5,每个batch 中含有8 个样本数据,每个样本的最大长度为100,训练次数epochs 为100。采用Adam 优化器优化网络,并使用Dropout 函数防止过拟合,参数设置为0.1。主要采用pytorch 深度学习框架实现模型的训练和预测。
3.3 对比实验
3.3.1 OPE实验结果与分析
本文模型与以管道方式提取意见对的模型:BiLSTMATT+IOG(Bi-directional Long Short-Time Memory-ATTention and IO-LSTM and Global context)[17]、DE-CNN+IOG(Dual Embeddings-Convolutional Neural Network and IOG)[19]、RINANTE+IOG(Rule Incorporated Neural Aspect and opinion Term Extraction and IOG)[6]以及未加入ASF 方法的GTSBERT[1]模型作对比。其 中,BiLSTM-ATT+IOG 模型是 把BiLSTM[18]和Attention 机制与IOG[17]结合的模型,BiLSTMATT 用于方面词提取,IOG 用于面向方面的意见词提取;DECNN+IOG 采用2 个嵌入层和4 个CNN 层的堆栈对句子编码,然后对方面词进行提取,再通过IOG 提取意见词;RINANTE+IOG 模型通过句子中单词的依赖关系挖掘方面和意见词;GTS-BERT 采用BERT 生成词向量并将意见二元组抽取形式化为一个统一的词对标注任务,然后通过特定的解码策略生成对应的二元组。
实验结果如表2 所示,可以看出GTS 模型的性能明显优于以管道方式提取意见对的对比模型,说明管道方法中的错误传播限制了OPE 的性能。与GTS-BERT 相比,ASF-GTS 模型性能得到了进一步的提升,ASF-GTS 在14Res、14Lap、15Res、16Res 数据集上的F1分别提高了7.30%、5.10%、4.41%、2.42%,验证了ASF-GTS 模型的有效性。

表2 OPE任务提取结果 单位:%Tab.2 Extraction results of OPE tasks unit:%
3.3.2 OTE实验结果与分析
将本文模型与Peng-unified-R+IOG 模型和IMN+IOG(Interactive Multi-task learning Network and IOG)模型作对比。其中,Peng-unified-R+IOG 是将Peng-unified-R[20]与IOG 相结合的模型。Peng-unified-R 是一个具有两阶段框架的模型:第一阶段利用通用模型框架预测方面词、相关方面词的情感极性以及意见词;第二阶段利用第一阶段抽取到的信息对方面词和意见词配对。IMN+IOG 模型通过交互式多任务学习网络(Interactive Multi-task learning Network,IMN)[21]与IOG结合作为强基线。IMN 是交互式多任务学习网络,它将不同任务的有用信息发送回共享的潜在表示,然后将这些信息与共享的潜在表示相结合,并提供给所有任务进一步处理,从而提高基于方面的情感分析(Aspect Based Sentiment Analysis,ABSA)任务的整体性能。GTS-BERT 采用BERT 生成词向量,并将意见三元组抽取形式化为一个统一的词对标注任务,然后通过特定的解码策略生成对应的三元组。
由表3 可 知,IMN+IOG 在数据集14Res 和15Res 上 明显优于Peng-unified-R+IOG,因为IMN 使用多域文档级情感分类数据作为辅助任务。相比之下,无须额外文档级情感数据的GTS-BERT 模型在F1上比IMN+IOG 表现更优,说明了GTS统一标记的优越性。而本文模型ASF-GTS 与GTS-BERT 相比,在14Res、14Lap、15Res、16Res 数据集上的F1分别提高了4.17%、4.27%、6.61%、2.62%。OTE 任务的整体实验结果再次验证了本文模型的有效性。

表3 OTE任务提取结果 单位:%Tab.3 OTE task extraction results unit:%
3.4 适应性实验
为了研究ASF 方法对OPE 任务的适应性,本文在OPE 任务上进行局部上下文特征对比实验。在GTS-BERT 上加入LCF 机制的CDM 方法形成的新模型GTS-BERT+CDM 与本文的模型对比,其中,CDM 方法的阈值a设置为5。实验结果如表4 所示,可以看出GTS-BERT+CDM 的整体性能比GTSBERT 略有下降,而融入了ASF 方法的ASF-GTS 模型比GTSBERT 模型F1表现更优,说明本文ASF 方法比CDM 方法更适应于OPE 任务,也同样适应于OTE 任务。

表4 OPE任务适应性结果 单位:%Tab.4 OPE task adaptability results unit:%
3.5 案例研究
从14Res 数据集中选取3 个样本进行案例分析,如表5所示:样本1 仅包含一对意见对,样本2 包含3 对不重叠的意见对,样本3 包含2 对方面词重叠的意见对。
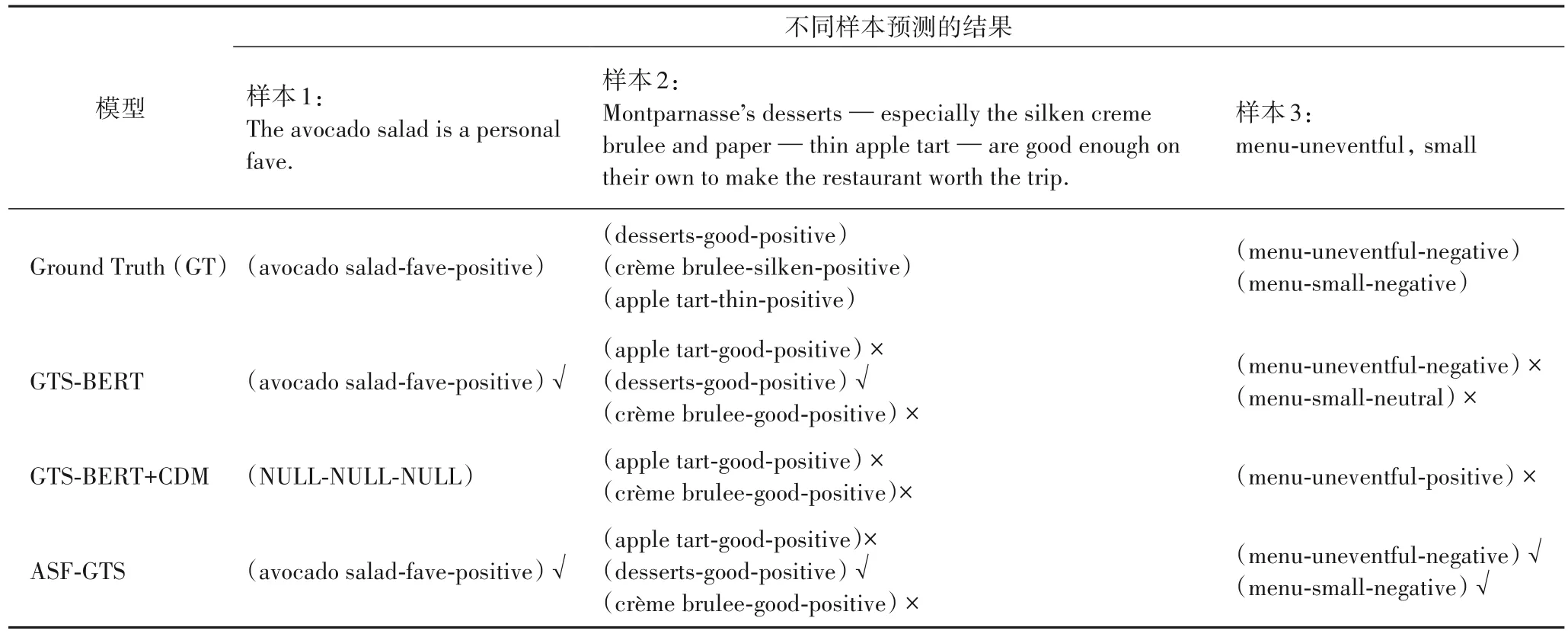
表5 三个样本的预测结果Tab.5 Prediction results of three examples
观察表5 可知ASF-GTS 模型预测表现最好。对于样本1,ASF-GTS 能够准确地预测出样本的意见三元组,然而GTSBERT+CDM 无法预测意见对,故无法输出意见三元组。对于样本2,GTS-BERT+CDM 受到固定阈值的影响无法识别超出阈值外的意见词,故无法输出(desserts-good-positive)的意见三元组,而GTS-BERT 和ASF-GTS 不受距离约束,因此可以准确地预测(desserts-good-positive)三元组。此外,表中模型都面临方面词和意见词匹配错乱的问题,在多个意见词的干扰下,不能很好地捕捉与方面词相对应的意见词。对于样本3,GTS-BERT+CDM 仅预测了一对错误的三元组;GTSBERT 虽然正确地预测出了所有的意见对,但是这些意见对的情感极性预测错误;而ASF-GTS 预测出所有正确的三元组,表明ASF-GTS 模型在一个方面词对应多个意见词的情况下,有更好的预测能力。该实验结果表明,融入ASF 方法的GTS 模型具有跨度语义焦点机制,可以通过ASD 保留情感信息量最多的词,更好地预测意见三元组。
4 结语
本文针对OPE 和OTE 任务提出了ASF-GTS 模型,该模型通过ASF 方法使模型充分学习ASD 内的特征,最大化地保留了情感信息特征,消除跨度外的词特征,使语义较少的特征不参与学习,并通过标记所有词对间的关系,成功地将句子的所有意见因素提取纳入一个统一的网格标记任务,然后通过特定的解码算法解码意见对或意见三元组。对比实验结果表明,本文模型比原来的GTS-BERT 模型效果更好,并且在适应性实验中验证了ASF 方法在OPE 或OTE 任务中的适应性与有效性。不过本文并未考虑反讽情况,未来将针对这一方面进行研究。
