融合自举与语义角色标注的威胁情报实体关系抽取方法
2023-05-24程顺航李志华
程顺航,李志华,魏 涛
(江南大学 人工智能与计算机学院,江苏 无锡 214122)
0 引言
网络安全威胁情报能够从多个角度剖析采用不同技术、战术、方法的网络攻击行为,并对网络攻击进行预警、对网络威胁的发展态势进行有效研判,从而高效地化解网络安全风险[1]。本文面向互联网开源异构大数据,针对大量隐藏在各类型网络安全文件中的攻击指示器(Indicators of Compromise,IoC)挖掘问题,从构建“实体-关系-实体”三元组的角度展开研究。
信息抽取(Information Extraction,IE)作为特征抽取的一个演变升华形式,在自然语言实体抽取领域得到了广泛的应用。实体抽取旨在从目标文件中抽取事实信息和事实描述。实体抽取主要包括命名实体识别(Named Entity Recognition,NER)、关系抽取(Relation Extraction,RE)和事件抽取(Event Extraction,EE)三个部分[2],其中实体识别和关系抽取是自然语言处理的基础,能够有效地从半结构化、无结构化文本中挖掘特定的实体及其关系。
语义角色标注(Semantic Role Labeling,SRL)是以谓词为核心的一种浅层语义分析技术,能够在谓词所表达的事件短语中对谓词相关的语义成分进行标注,如施事者、受事者、时间和地点等。通过SRL 技术能够有效地分析句中各成分与谓词之间的关系,是实体抽取任务的重要中间步骤之一。
目前信息抽取技术已经在自然语言处理领域得到了广泛应用[3-9],并取得了较好的效果。但是具体针对网络安全威胁情报挖掘而言,信息抽取技术在此领域的应用当前还面临着以下不足:1)互联网开源大数据中存在着海量的IoC,这些IoC 是构建网络安全威胁情报的重要基础和来源。而这些开源大数据通常表现为结构复杂多样的半结构化或无结构化的长文本,并且语句结构与日常用语差异性较大,词汇专业性强、复杂度相对较高。2)互联网开源网络安全威胁情报具有实体更新频繁、形式多样、格式不统一的特性。当前,从作者可涉及的研究资源角度来看,缺少一个统一、标准的网络安全威胁情报标准数据样本集。这一情况不利于网络安全威胁情报挖掘同数据挖掘、机器学习等前沿学科进行交叉研究,更无法满足大数据挖掘训练的要求。
针对上述不足,本文提出了一种面向少样本的网络安全威胁情报实体关系抽取(Threat Intelligence Entity Relation Extraction,TIERE)方法。TIERE 方法包含:一种提高文本可分析性的数据预处理方法、基于改进自举法的命名实体识别(Improved BootStrapping-based Named Entity Recognition,NER-IBS)算法和基于语义角色标注的关系抽取(Semantic Role Labeling-based Relation Extraction,RE-SRL)算法。实验结果表明TIERE 方法能高效地挖掘互联网开源异构大数据中有关网络安全威胁情报的实体和关系。
1 相关工作
信息抽取技术的研究相对比较成熟。早期的信息抽取采用基于规则的方法[3],由领域专家根据实体特点构建相应的规则模板,再通过模式匹配的方法进行信息抽取。这类方法虽然高效、准确度高,但存在成本高、召回率低、泛化能力差的缺点。随着机器学习的发展,基于数学统计的信息抽取技术逐渐流行,主要通过提取各类实体的特征,然后借助大规模语料进行训练,这类机器学习模型如支持向量机(Support Vector Machine,SVM)[4]、隐马尔可夫模型(Hidden Markov Mode,HMM)[5]等,在信息抽取方面都有不少的应用,实验取得了较好的效果,但是存在特征构建复杂、适应性较差的不足。近年来,深度学习的发展对自然语言处理产生了比较大的影响,随着GPT(Generative Pre-Training)[6]、BERT(Bidirectional Encoder Representations from Transformers)[7]等语言预训练模型的发布,进一步提高了信息抽取的性能,预训练模型与双向长短时记忆(Bidirectional Long Short-Term Memory,BiLSTM)网络和条件随机场(Conditional Random Field,CRF)相结合成了当前信息抽取的主流方法[8-9]。但是,目前大多数基于深度学习的模型和算法都需要依赖大规模的标注样本集进行学习训练,当面对如网络安全威胁情报这样的特定专业领域,受限于有限的、可信赖的有监督学习的训练样本集,在少样本集可供学习训练的情况下,导致上述模型和算法的性能必然受到影响,信息抽取的精准度大幅下降[10]。
当前,针对网络安全威胁情报的信息抽取主要聚焦于IoC 的挖掘,如IP、HASH 值等有规则的实体。Liao 等[11]提出的iACE(IoC Automatic Extractor)框架,借助模式匹配的方法通过提取文本中包含关键字的语句,再使用图挖掘技术分析上下文的语义关系来抽取IoC;Long 等[12]使用基于神经网络的序列标注模型对IoC 进行分类挖掘。以上研究均取得了比较好的效果。通常网络安全文本如APT(Advanced Persistent Threat)报告中不仅仅包含IoC,还有其他有意义的实体,如威胁组织名、恶意软件名等,它们同样是构建威胁情报的重要组成部分之一。为了加强对此类实体的识别,Dionísio 等[13]使用BiLSTM-CRF 模型完成了对网络安全推文的实体识别实验,取得了不错的效果;Qin 等[14]提出了CNNBiLSTM-CRF 模型,通过添加卷积神经网络(Convolutional Neural Network,CNN)增强了模型的特征提取能力;Gao 等[15]将神经网络通过注意力机制与外部字典相结合,使模型能充分学习到威胁情报相关的专业词汇。
虽然基于深度学习的有监督实体识别模型在威胁情报挖掘领域取得了不错的成果,但这类模型需要专业人员构建庞大的数据集,在少样本集情况下难以普及。为此,McNeil等[16]提出了一种半监督学习算法PACE(Pattern Accurate Computationally Efficient Bootstrapping)。PACE 算法结 合Bootstrapping 和规则匹配完成了对网络安全概念的抽取;Georgescu 等[17]提出了手动标注与自动标注相结合的方法构建威胁情报样本集;Yi 等[18]提出一种正则表达式、已知实体字典和CRF 结合的安全命名实体识别算法RDF-CRF(Regular expression and Dictionary combined with Feature templates as well as CRF)。但是上述方法只是单纯地提取实体,忽略了实体与实体之间的关系。“实体-关系-实体”是自动生成、构建威胁情报的关键。
本文针对威胁情报挖掘领域少样本集导致信息抽取准确度不高这一问题,提出了TIERE 方法,TIERE 方法能够在无样本标注的情况下完成对半结构化、无结构化文本的“实体”、“实体-关系-实体”挖掘。实验结果表明TIERE 方法是有效且高效的。
2 TIERE方法
TIERE 方法的主要目的是从半结构化、无结构化的异构文本中自动抽取“实体-关系-实体”三元组。TIERE 方法主要包括三个部分:将待处理的目标文本通过数据预处理流程进行清洗和转换,生成易于理解、结构标准的语句;通过NER-IBS 算法,依赖少量的初始学习样本和抽取规则,挖掘句子中的威胁实体;通过RE-SRL 算法,对文本语义信息进行分析,挖掘威胁实体之间的关系,并对关系进行分类。以下对各个部分进行详细讨论。
2.1 数据预处理
以安全厂商对某次攻击行为分析后所发布的报告为例,报告中包含有网络威胁情报,这些报告形式上以自然语言描述,以PDF 文本、HTML 文本的形式存在,通常包含有大量的无关信息,严重影响信息抽取的效果。在此,概括分析诸如上述安全厂商报告给威胁情报挖掘带来的挑战如下:
1)开源威胁情报多数是半结构或无结构化的文本数据,如HTML 格式的安全博客和PDF 格式的APT 报告等,异构数据会对信息的抽取造成困难。
2)安全领域文本存在较多无语义的字符数据,与其他领域文本不同,安全领域文本包含大量的URL、IP、HASH 等词汇,会严重影响实体识别模型对文本语义的理解,在模型训练过程中产生大量的噪声。
3)安全领域文本专业性更强、复杂度更高。具体表现为:存在大量的代词,这些代词通常用来替代重复出现的威胁实体,从而导致实体之间的跨度增加,影响了关系抽取模型的回归率;英文文本中动词词形多样,又增加了相似度计算的复杂性,影响了关系分类的性能。
针对上述问题,本文研究并提出了一种数据预处理方法,具体流程如图1 所示。
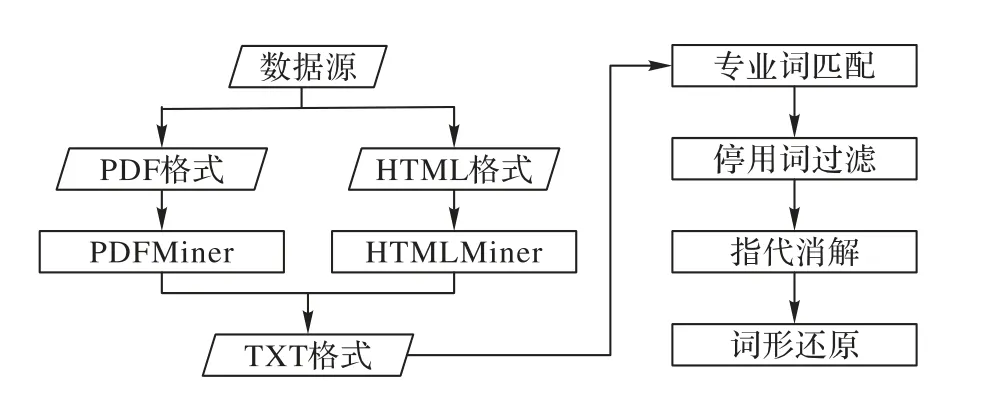
图1 数据预处理方法Fig.1 Data preprocessing method
首先,对开源的威胁情报文本进行格式归一化处理。考虑到绝 大多数 格式为PDF 和HTML,采 用PDFMiner[19]、HTMLParser[20]分别对PDF 格式、HTML 格式文本进行解析,并过滤其中的非ASCII 字符,生成TXT 格式文本;然后,对它们进行数据清洗,考虑到文本中可能包含URL、IP、HASH 等无语义的专业词汇,采用正则表达式进行匹配和替换,并在此过程中过滤掉停用词;最后,对清洗后的文本进行标准化处理,借助HanLP[21]提供的指代消解模型消除文本中的代词,通过WordNet[22]提取英文动词的词干。专业词汇的正则表达式构造方法如表1 所示,其中,对URL 词汇中ftp、ftps、sftp、http、https 五种网络传输协议进行解析;并对IP、URL 中常见的混淆技术进行识别,如网络安全中IP、URL 通常指向恶意链接,为防止误点使用锚点进行混淆。对HASH 函数中MD5、SHA1、SHA256 三种加密算法进行识别,它们分别由32 b、40 b、64 b 字母或数字组成。

表1 专业词汇的正则表达式Tab.1 Regular expressions of specialized vocabulary
2.2 改进自举法的实体识别算法
针对传统的Bootstrapping 算法[16]中随着迭代次数的增加容易导致语义漂移问题,在此对Bootstrapping 算法进行改进。Bootstrapping 算法的改进策略如图2 所示,主要分为三个阶段:1)模式匹配,通过规则库与半结构、无结构化文本进行匹配,构造带标注的样本数据集,利用少量样本和正则表达式作为初始种子构建规则库;2)实体识别,使用实体识别模型训练样本集并挖掘新实体;3)实体评估,通过实体识别模型训练后可能产生大量伪实体,这将严重影响规则库和数据样本集的质量,为了克服这一不足,通过加入实体评估模型对新的实体数据集进行评估,过滤其中的伪实体。上述三个阶段重复迭代,以此来不断完善规则库、扩大实体数据样本集,有助于提高实体识别的性能。

图2 Bootstrapping算法的改进策略Fig.2 Improved strategy of Bootstrapping algorithm
2.2.1 模式匹配
对不同的实体类型结合相应的实例词典与正则表达式构成初始化规则库,与半结构化、无结构化文本进行匹配,生成初始化的实例样本集,每次迭代后更新规则库,并生成新的样本集。受STIX(Structured Threat Information eXpression)[23]中定义的STIX 域对象(STIX Domain Object,SDO)启发,本文选取6 种实体类型。实体类型及其模式匹配方法如表2 所示,其中Attacker 表示某攻击行为的主体,通常指黑客、间谍或威胁组织,部分常见的威胁组织使用APT、TA 作为前缀规则进行命名,如APT34、TA459 等,可选取ATT&CK[24]知识库中常见攻击组织词典以及其命名规则作为初始化模式与原始文本进行匹配;Malware 表示攻击行为中使用的工具或恶意代码,通常以.exe、.sh 等后缀规则命名,可选取ATT&CK 知识库中的常用恶意软件词典以及Malware 命名规则作为其初始化模式;Cve 表示攻击行为中利用的漏洞,部分已公开的漏洞使用CVE 作为前缀进行编号,如路由器漏洞CVE-2021-34730,使用编号规则作为其初始化模式;Location 表示攻击的目标位置或攻击主体所在位置,对此使用国家名作为词典构造初始化模式;Type 表示攻击主体或恶意软件的类型,本文总结出病毒、键盘记录器、蠕虫、木马、勒索软件、后门6 种攻击类型构成词典作为初始化模式;IoC 表示攻击行为中涉及的攻击指示器,如IP、HASH 值等,使用表1 中对应的正则表达式作为初始化模式。
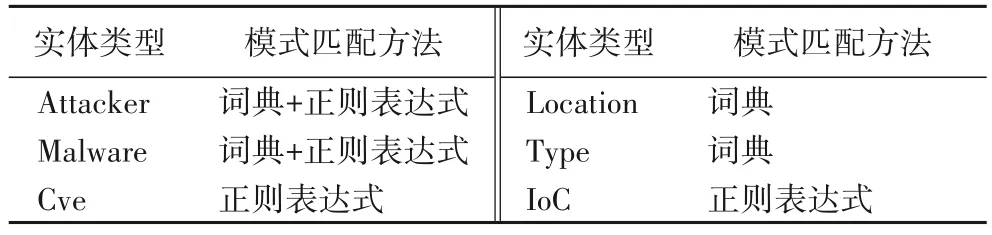
表2 实体类型及模式匹配方法Tab.2 Entity types and pattern matching methods
2.2.2 实体识别模型
针对威胁情报实体专业性强的特点,为了更好地学习它的语义特征,使用基于深度神经网络(Deep Neural Network,DNN)[25]的实体识别模型。实体识别模型主要分为词嵌入层、上下文编码层、解码层。词嵌入层主要将文本中的词表示成向量的形式,使相似意义的词在向量空间上具有相似的表示,为了更好地提取词与上下文间的语义特征,使用了BERT[7]预训练模型作为词嵌入层,将词特征、句特征、位置特征三种特征融合作为模型的输入用于计算词向量,并通过迁移学习的方式运用到下游任务中;使用BiLSTM 作为模型的上下文编码层,LSTM 是一种循环神经网络(Recurrent Neural Network,RNN)结构,能很好地处理序列数据,学习上下文信息。对比传统的RNN,LSTM 在长序列数据上有更好的表现,解决了RNN 模型训练过程中梯度消失的问题。LSTM 主要由多个神经单元构成,每个单元通过遗忘门(forget gate)、输入门(input gate)和输出门(output gate)控制信息的记忆。在第t时刻,遗忘门、输入门、输出门如式(1)~(3)所示:
其中:Wf、Wi、Wo分别为遗忘门、输入门和输出门的神经网络参数;bf、bi、bo分别为遗忘门、输入门和输出门的神经网络偏置值;ht-1表示在t-1 时刻的隐藏状态。
在t时刻单元状态Ct由前一时刻单元状态Ct-1和现时刻的初始状态决定,按式(4)~(5)计算:
通过遗忘门过滤前一时刻单元的不重要信息,通过输入门提取当前时刻重要信息。最后通过输出门按式(6)计算当前时刻隐藏状态ht:
BiLSTM 将正向和反向两个方向的LSTM 隐藏状态结合作为新的隐藏状态,如式(7)所示:
经过BiLSTM 编码层后可以得到向量序列,需要解码器对它进行解析,使用CRF 作为模型的解码层,计算所有标签序列的概率分布,按式(8)~(9)计算:
其中:U和b为神经网络参数和偏置值表示从前一个标签yi到后一个标签yi+1的转移概率表示第i个元素输出为yi标签的概率。
2.2.3 实体评估模型
为了防止过多的伪实体对样本集训练结果产生影响,对经过实体识别后的实体集进行评估,提取质量较高的实体用于补充规则库。通过分析发现伪实体一般由以下原因产生:1)威胁实体通常以词组的形式存在,如“海莲花组织”中“海莲花”为一个整体,而在日常的语言中,“海”和“莲花”分别为不同的实体,因此可能出现实体边界判定错误;2)不同类型的实体出现在相同的语境可能产生不同语义,如“一种Linux恶意软件”与“一种Mirai 恶意软件”两句话中“Linux”与“Mirai”有相同的语境,但却表达不同的含义。针对上述问题,本文提出了一种实体评估模型,如图3 所示。
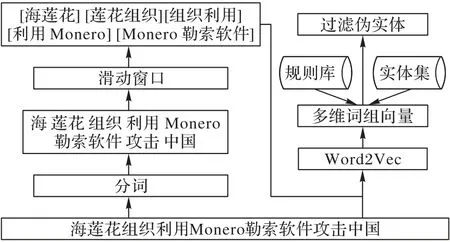
图3 实体评估模型示例Fig.3 Entity evaluation model example
首先,为了验证实体边界,使用Jieba 库[26]对半结构化、无结构化文本进行分词,通过滑动窗口构建多元词组;其次,将词组与文本作为输入通过Word2Vec 模型[27]进行预训练,得到多元词组向量集合V;最后,为区分相同语境下不同类型的实体,计算实体集中实体E=(e1,e2,…,eq)与规则库中实体G=(g1,g2,…,gp)的余弦夹角,即相似度,并过滤相似度较低的实体。相似度计算如式(10)所示:
其中:Sk表示实体集中第k个实体与规则库所有实体的相似度之和;表示实体ek的第i维词组向量。
2.2.4 NER-IBS算法
NER-IBS 算法如算法1 所示。输入文本集L=(l1,l2,…,ln),规则库U,迭代次数N,输出实体集E。首先,通过模式匹配模型生成样本集W,通过BERT 预训练模型生成词嵌入矩阵X,通过滑动窗口生成多元词组M,通过Word2Vec 预训练模型生成词组向量V;然后,进行N次迭代,依次按照式(1)~(7)计算BiLSTM 层隐藏状态h,按照式(8)~(9)计算CRF 层概率分布S;接着反向传播更新模型参数,通过多次迭代训练后,得到标签序列y,并更新实体集;最后,依次将实体集与规则库实体进行相似度计算,过滤规则库中相似度小于阈值的实体。
算法1 NER-IBS 算法。
NER-IBS 算法的时间复杂度可表示实体识别的效率。设隐藏层维度为n,BERT 词向量维度为m,则计算遗忘门、输入门和输出门的时间复杂度为O(m(n+m)),计算单元状态和隐藏状态的时间复杂度为O(n)。由此可得,LSTM 模型一个时刻的时间复杂度为O(3m(n+m)+2n),即O(n2)。由于训练次数epoch为常量,设时间步长为T,则实体识别模型时间复杂度为O(n2T),即O(n3)。设Word2Vec 词组向量维度为w,实体集总数为e,则计算相似度的时间复杂度为O(w),实体评估模型的时间复杂度为O(we)。由于迭代次数N为常量,则总时间复杂度为O(n3+we),即O(n3)。
2.3 基于SRL的关系抽取算法
SRL 是一种以谓词为中心的浅层语义分析技术,主要描述如“谁对谁”“何时何地”“做了什么事”等。SRL 技术能有效地挖掘实体间的潜在关系,但无法判断关系的类别。本文在SRL 技术的基础上提出了RE-SRL 算法。RE-SRL 算法的逻辑架构如图4 所示,通过关系抽取模型挖掘实体间的关系,通过关系分类模型识别关系的类别。

图4 RE-SRL算法的逻辑架构Fig.4 Logic architecture of RE-SEL algorithm
2.3.1 关系抽取
在此,借助LTP(Language Technology Platform)[28]模型获取威胁情报文本中的语义标记信息,其中A0 表示事件的主体即实施者、A1 表示事件的受事者、V 表示事件的谓语。如“海莲花组织利用Monero 勒索软件攻击中国”中“海莲花组织”为实施者,“利用”和“攻击”分别为描述受事者“Monero勒索软件”和“中国”的谓语。对语义标记信息进行剪枝,剔除不含威胁实体的信息,并以谓词为核心对其进行划分,上述语句可得到两组三元组:(A0:海莲花,V1:利用,A1:Monero)、(A0:海莲花,V2:攻击,A1:中国)。
2.3.2 关系分类
借助SRL 技术,并使用无监督语义相似度模型对语义角色中的关系谓词进行分类,针对网络安全领域实体,选取了如表3 所示的关系类别。由于不同语境下的谓词表达的含义可能不同,将整个三元组作为相似度的评价标准,使用表3 中的关系集替换原始三元组中的谓词构建多个不同的三元组,并与原始三元组计算相似度,相似度计算如式(11)所示:
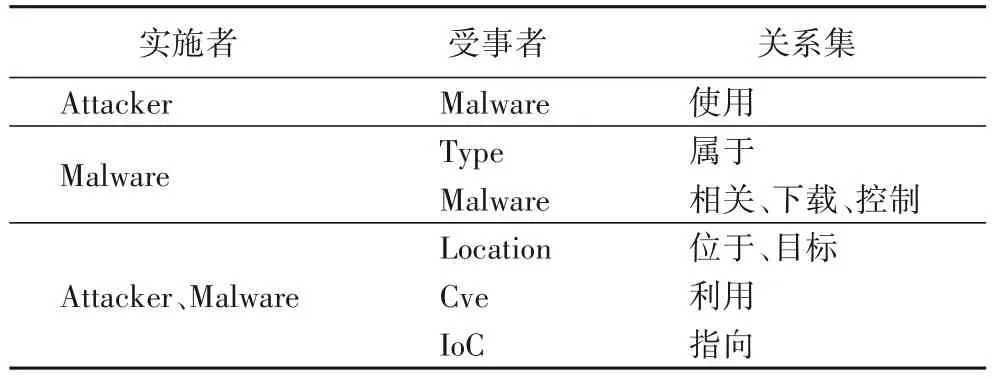
表3 关系类别Tab.3 Relation category
其中:r为关系集R的一种关系;t为原始三元组,tr表示使用关系r替换谓词后的三元组;Vt,i表示三元组t的第i维句向量,句向量使用BERT 模型[7]计算。选取相似度最高的三元组作为关系抽取的结果。
2.3.3 RE-SRL算法
RE-SRL 算法如算法2 所示,其中:L为文本输入,E为实体集输入,R为关系类别输入,tuples为最终输出的“实体-关系-实体”三元组集合。使用LTP[28]模型计算文本的语义标记信息SRL,对于SRL中的每行信息srl逐一进行计算。首先遍历实体集,匹配与实施者srlA0和受事者srlA1对应的实体ei、ej,并与谓语srlv结合生成三元组t;然后,将使用关系集替换谓词后的新三元组tr与原始三元组计算相似度sr;最后,取相似度最高的三元组tmax存入三元组集合中。
算法2 RE-SRL 算法。
RE-SRL 算法的时间复杂度可表示关系抽取的效率。设文本总长度为n,实体集数量为e,则关系抽取模型时间复杂度为O(ne)。设BERT 句向量维度为v,计算三元组相似度的时间复杂度为O(v),由于关系类别数为常量,则关系分类模型的时间复杂度为O(v)。算法总时间复杂度为O(nev),即O(n3)。
2.4 TIERE方法
本文提出的TIERE 方法包含:数据预处理、NER-IBS 算法和RE-SRL 算法,具体步骤如方法1 所示。
方法1 TIERE 方法。
参见TIERE 方法,输入网络安全文本texts、规则库U、迭代次数N、关系类别R,输出“实体-关系-实体”三元组tuples。首先,对安全文本格式进行判断,分别对PDF 格式、HTML 格式的文本进行解析,依次通过数据清洗、指代消解、词形还原操作生成标准化文本集L;然后,使用NER-IBS 算法生成实体集E,使用RE-SRL 算法生成“实体-关系-实体”三元组。
3 实验与结果分析
3.1 实验数据集
为了验证面向少样本的威胁情报信息抽取方法的有效性和高效性,本文从各安全厂商发布的博客和报告中收集了71 篇安全类文章,包含1 757 条语句,其中各类实体标签数量如表4 所示,各类关系数量如表5 所示。

表4 各实体标签数量Tab.4 Number of labels per entity
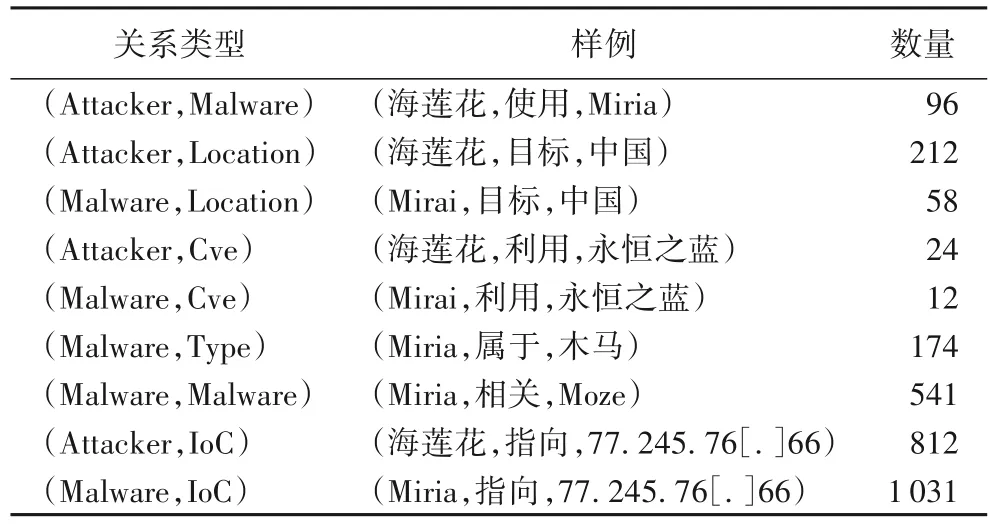
表5 各类关系数量Tab.5 Number of relations
3.2 评估指标
实验中使用的评估指标为精确率Pre、召回率Rec和F1值(F1),具体计算方式如式(12)~(14)所示:
其中:TP表示真实值为阳性样本中预测正确的数量;FP表示真实值为阴性的样本中预测错误的数量;FN表示真实值为阳性中预测错误的数量。
3.3 实验环境和实验参数设置
本文实验使用的软硬件配置如表6 所示,实验中模型的参数设置如表7 所示。

表6 实验环境配置Tab.6 Experimental environment configuration
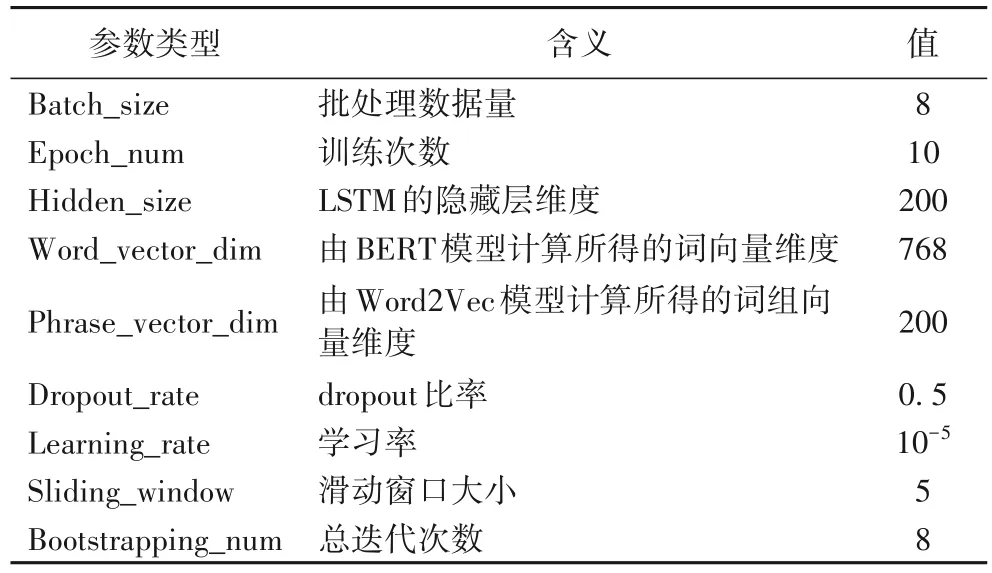
表7 模型参数设置Tab.7 Model parameter setting
3.4 实体识别实验
为验证NER-IBS 算法的有效性和高效性,设置了对比分析实验、Bootstrapping 迭代次数分析实验和消融实验。
3.4.1 对比分析实验
为验证本文实体识别方法的高效性,将其与其他半监督学习算法和有监督学习算法在本文语料上进行对比实验,实验结果如表8 所示。由表8 可知,本文提出的实体识别算法在F1 值上均优于其他少样本学习算法,并且接近使用大规模样本的有监督学习算法的效果。与文献[16]中的算法相比,本文NER-IBS 算法的召回率提升了33 个百分点,F1 值提升了23 个百分点,主要原因在于深度学习模型融入了词嵌入特征,能更有效地分析实体词汇在文中的具体语义,解决了传统的模式匹配方法挖掘力度不足的问题;与文献[17]中的算法相比,NER-IBS 算法在召回率和精确率上都有提升,F1 值提升了16 个百分点;与RDF-CRF 算法相比,NER-IBS 算法在召回率上提升了3 个百分点,在F1 值上提高了2 个百分点,主要原因在于NER-IBS 算法通过自举法不断迭代,能有效地利用多次统计推理的结果;对比文献[13]与文献[15]中的算法可知,融入专业词典可有效地提高实体识别效果。
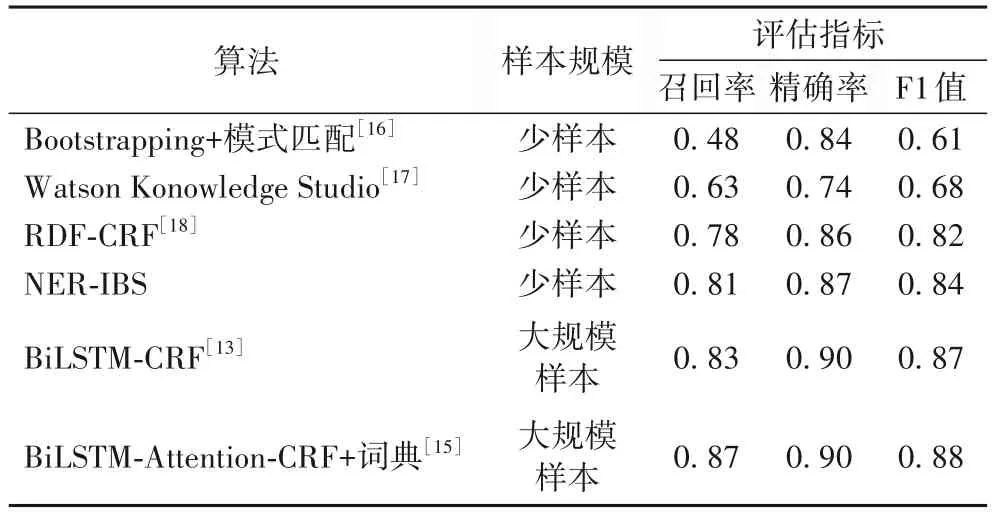
表8 不同算法实验结果的对比Tab.8 Comparison of experimental results of different algorithms
3.4.2 Bootstrapping迭代次数分析实验
为验证使用Bootstrapping 算法进行迭代对各类别实体抽取效果的影响,选取了三种不同复杂度的实体进行分析实验,如图5 所示为各实体在不同迭代次数下的准确度。由图5 可得出以下结论:
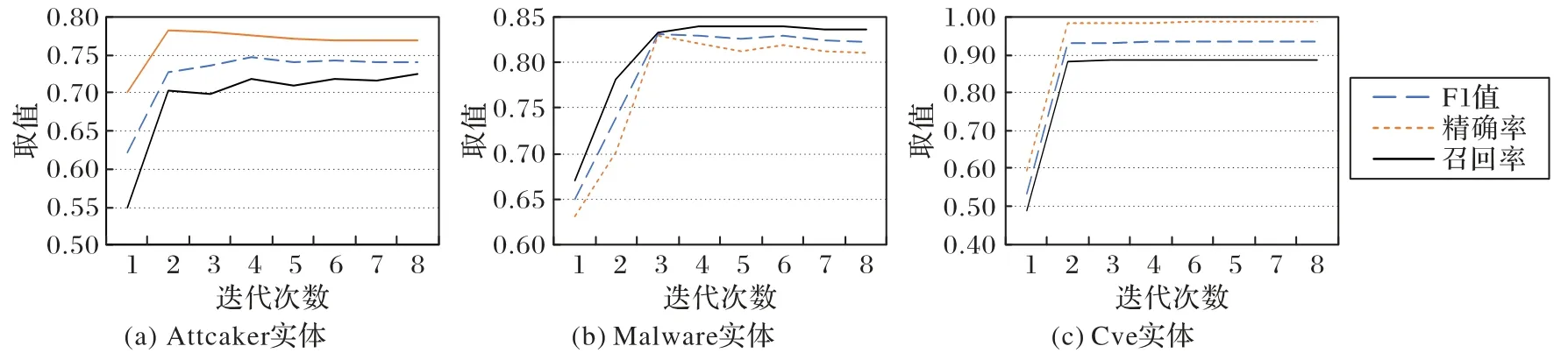
图5 各实体不同迭代次数下的实验结果Fig.5 Experimental results of each entity under different iteration numbers
1)分析实体抽取效果的整体变化趋势,发现前几次迭代中实体抽取的各项评价指标都有大幅度提升,可以得出Bootstrapping 算法对实体抽取效果起作用。
2)分别比较迭代次数对不同实体抽取效果的影响,发现Attacker、Malware、Cve 实体分别在第4 次、第3 次、第2 次迭代时F1 值达到稳定状态,由于Attacker 实体具有更复杂多样的结构,而Cve 实体相对简单且多数为有规则的编号,可以得出更复杂的实体需要迭代更多的次数。
3)分析实体抽取效果在不同评价指标下的变化趋势,发现对于Attacker 和Malware 相对复杂的实体,在F1 值达到稳定后随着迭代次数的增加会导致精确率下降的情况,较复杂的实体随着迭代次数的增加可能会导致语义漂移,从而影响样本集的质量。
3.4.3 消融实验
针对迭代过度导致的语义漂移问题,本文在传统的Bootstrapping 算法中加入了实体评估模型,为验证实体评估模型的有效性进行了消融对比实验,实验结果如表9 所示。由表9 可知,加入实体评估模型后虽然召回率有所下降,但精确率和F1 值都有明显提升。

表9 消融实验结果Tab.9 Ablation experimental results
3.5 关系抽取实验
对RE-SRL 算法进行验证,分别分析算法无类别抽取和有类别抽取的性能,验证关系分类模型的有效性和RE-SRL算法的高效性,实验结果如表10 所示。由表10 可知,本文提出的关系抽取方法在不考虑关系类别的情况下F1 值达到了0.94,而进行关系分类后F1 值为0.71。

表10 关系抽取和分类实验结果Tab.10 Experimental results of relation extraction and classification
3.6 TIERE方法的实用性验证
本节借助TIERE 方法抽取网络安全威胁情报验证方法的实用性。使用TIERE 方法对一篇有关“海莲花组织攻击活动”的APT 报告[29]进行实体和关系抽取实验。其“实体-关系-实体”三元组抽取结果如下所示:
段落1:海莲花是高度组织化的、专业化的境外国家级黑客组织。其活动迹象最早可追溯到2012 年。攻击目标包括中国政府、海事机构、海域建设部门、科研院所和航运企业等。
三元组1:(海莲花,目标,中国)。
段落2:其样本执行的宏代码将通过regsvr32.exe 注册调用~$doc-ad9b812a-88b2-454c-989f-7bb5fe98717e.ole 程序,该程序为dll 文件。并解密出最终的payload 进行执行。最终的复杂木马也是海莲花使用的远控载荷之一,如“WinWord.exe”SFX 样本,(md5:d87e12458839514f1425243075cfc078)。
三元组2:(海莲花,使用,WinWord.exe)(海莲花,使用,regsvr32.exe)(海莲花,指向,d87e12458839514f1425243075 cfc078)(regsvr32.exe,相关,WinWord.exe)。
威胁情报表示成STIX2[27]格式的结果如下所示:
此攻击活动的攻击主体(Attacker)为海莲花,攻击地点(Location)为中国,包含恶意软件(Malware)有regsvr32.exe 和WinWord.exe,涉及了3 种攻击指示器,包括77.245.76[.]66、5.104.110[.]170、d87e12458839514f1425243075cfc078。各实体之间存在4 种关系,共生成了5 组“实体-关系-实体”三元组,包括:(海莲花,使用,regsvr32.exe)、(海莲花,使用,WinWord.exe)、(海莲花,目标,中国)、(海莲花,指向,d87e12458839514f1425243075cfc078)、(regsvr32.exe,相关,WinWord.exe)。这充分说明了TIERE 方法在挖掘无结构化文本中的威胁情报实体和关系的有效性。
4 结语
信息抽取是自然语言处理的重要分支,针对网络安全报告中IoC 挖掘的具体需求,可以提出新的信息抽取模型和算法,或改进已有的模型和方法,以挖掘非结构文本中的威胁情报信息。对此,本文提出了一种威胁情报实体关系抽取(TIERE)方法,通过预处理降低文本的复杂度,使用基于自举法的实体识别(NER-IBS)算法挖掘威胁实体,使用基于语义角色标注的关系抽取(RE-SRL)算法挖掘实体间的关系,解决了威胁情报信息抽取任务中样本稀缺、文本复杂的问题,并取得了较好的实验效果。
本文研究只针对中文文本,在后续的研究中,将进一步研究多语种威胁情报的信息抽取技术,提高方法的泛化能力,并增加更多的实体类型和关系类型,开发更全面的威胁情报信息体系。
