基于小样本的知识图谱补全模型
2023-01-02肖亚新
肖亚新,韩 斌
(江苏科技大学计算机学院,江苏镇江 212003)
0 引言
知识图谱被定义为G={E,R,F},即{实体,关系,事实的集合}[1],是一种存在多种实体关系的结构化有向图,其节点与“头实体—关系—尾实体”三元组相对应。其中,三元组(h,r,t) ∈F表示事实,h表示头实体,t表示尾实体,r表示两者之间的关系。现阶段,Freebase[2]、Dbpedia[3]等知识图谱已被广泛应用,最新研究集中在知识图谱嵌入领域,旨在将实体和关系映射到低维向量,并捕捉其中的语义关系[4-5]。
目前,知识图谱嵌入技术可分以下4 类:①基于深度学习的知识图谱嵌入技术;②基于图形特征的知识图谱嵌入技术;③基于翻译模型的知识图谱嵌入技术;④基于元学习的知识图谱嵌入技术[6]。基于以上方法,本文定义了一种新的元学习框架。通过特定关系的元信息观察实例,达到加速学习过程的目的,并将常见的关系信息从已有的三元组中转移至其它三元组。此外,在预测过程中通过关系元传递重要信息,利用梯度元提升模型的学习效率。
1 相关工作
1.1 知识图谱嵌入模型
在知识图谱补全中,通常通过链接预测和三元组分类方法评价两个任务模型的性能。肖阳华[7]提出的翻译模型在两个任务中均取得了较好的成绩。Border 等[8]提出的原始模型TransE 是目前具有代表性的方法,将实体和关系嵌入低维空间,模型结构简单,具有以下优势:在数据集中表现出色且容易扩展;能够训练大规模数据。TransE 的目的是使实体向量和关系向量靠近于一种向量运算关系h+r=t,其中h为头实体向量,r为关系向量,t为尾实体向量,但该模型在处理一对多、多对一、多对多等复杂关系时效果并不理想。
为此,不少学者对TransE 模型进行了改进,衍生了TransH[9]、TransR[10]、TransD[11]等模型,此类模型均将实体与关系映射到不同的空间。其中,TransH 运用空间投影建立超平面的思想,将实体与关系映射到同一个向量空间的不同向量平面,但导致该方法计算较为复杂;TransR 通过变换矩阵的思想,将实体与关系映射到另一个向量空间进行投影,方法精度较高,但参数设置较为复杂;TransD 模型则为头、尾实体分别设置了两个不同的矩阵投影,每个矩阵均由实体和关系决定。上述方法虽在一定程度上解决了TransE 的局限性,但根本上均利用头实体和关系向量预测尾实体向量。
此外,Borders 等[12]提出了一种结构化嵌入模型,该模型为每个关系设置了两个独立的矩阵Mrh和Mrt投影头实体和尾实体。Borders 等[13-14]提出的语义匹配能量(Sematic Matching Energy,SME)模型将每个命名的实体和关系编码为一个向量,通过矩阵运算捕捉实体和关系间的相关性。Sutskever 等[15-16]提出的潜在因素模型(Latent Factor Model,LFM)将每个实体编码为一个向量,并为每个关系设置唯一的矩阵。Nickel 等[17]提出的基于张量分解的语义匹配模型RESCAL,旨在学习具有双线性评分函数的多关系数据的潜在语义。
1.2 元学习概念
由于知识图谱中存在长尾现象,并且现实世界中知识是动态变化的,为保证三元组未被使用,提出元学习框架通过少量的样本预测新的关系事实。Xiong[18]提出了一种基于度量小样本的学习方法,该方法先利用R-GCN 为单跳邻居进行编码,捕捉局部图结构信息,然后在长短时记忆网络的指导下将结构实体嵌入模型进行多步匹配,计算相似度得分。Lyu[19]等提出了一种基于优化的元学习方法Meta-KGR,该方法采用模型无关元学习进行快速自适应与强化学习,并应用于实体搜索和路径推理领域。Zhang等[20]提出了异构图编码器、递归自动编码器和匹配网络联合模块,能够在小样本中补全新的关系事实。Qin 等[21]利用生成式对抗网络(Generative Adversarial Networks,GAN)在零样本学习下为未知关系进行合理嵌入。Baek[22]提出了一种转导元学习框架,用于在知识图谱中预测小样本外图的链接。
基于上述方法,本文通过相同关系获得元信息,将信息从支持集传输至查询集,并利用梯度元加速学习关系元信息,通过梯度下降方法使函数损失达到最小。实验结果表明,所提出的模型在实体和关系预测方面性能更优。
2 基于小样本的知识图谱补全模型
2.1 元学习方法
元学习是对多种学习任务进行系统性观察的研究,并从中学习新任务,目标是概括任务的分布,对成批的任务进行优化。每个任务都有相应的学习问题,表现良好的任务能够提升学习效率,并在未过度拟合的情况下概括小样本问题。由表1 可知,在元学习中共划分了3 种数据集,分别为支持集S、查询集Q及辅助集A,并且根据N-way,Kshot方法对每个集合进行任务取样,构成训练集合T。

Table 1 Examples of meta-training set and meta-testing set data表1 元训练集和元测试集数据示例
关系是支持集和查询集中共有的部分,实验目的是将支持集和查询集中共有的关系信息迁移到缺失尾实体的三元组中,通过迁移关系特定的元信息实现小样本知识补全,使模型利用关系元和梯度元信息快速学习重要知识。其中,关系元表示支持集和查询集中连接头实体和尾实体的关系;梯度元为支持集中关系元的梯度,通过梯度元改变关系元达到最小损失并加速学习过程。此外,特定关系的元信息一方面将共同信息从三元组转移至不完整的三元组中;另一方面通过观察少量实例加速任务内的学习过程。
元学习模型主张跨任务学习并适应新任务,目的在关系任务上学习任务未知的模型,而并非只针对含有特定任务模型。该模型通过元训练和测试阶段处理小样本的学习问题,先将现有完备的实体关系三元组定义为补全任务的元训练集Dtrn,再将待补全的知识图谱三元组定义为补全任务的元测试集Dtst,最后对Dtrn和Dtst中所有的三元组进行初始化处理,得到向量表示的三元组(h,r,t) ∈G,G为三元组样本集,h,t∈E,E为实体集,r∈R,R为关系集。
在Dtrn中将具有同一关系的三元组归为同一集合,则该集合为关系对应的关系任务Tr,Tr∈T,T~p(T),p(T)为所有关系任务构成的任务集合。在任务集合p(T)中随机抽取一项任务,取N个三元组样本作为该任务的支持集Sr,剩余样本作为任务的查询集Qr,并且支持集的样本数小于查询集中的样本数。元学习模型具体算法如下:
输入:关系任务训练集Ttrn。
输出:嵌入层参数emb、元学习器的参数φ、新的关系元R'。
1.当训练集Ttrn为空。
2.在训练集Ttrn中定义一个任务Tr={Sr,Qr}。
3.从支持集Sr中取关系元R。
4.计算当前任务Sr的损失函数和得分函数。
5.从关系元R中获取梯度元G。
6.根据梯度元G更新关系元R。
7.计算当前任务查询集Qr的损失函数。
8.根据任务查询集Qr的损失函数更新学习器的参数φ和嵌入层参数emb。
9.结束学习过程。
10.输出新的关系元R'。
通过L层全连接神经网络提取实体的特定关系元:
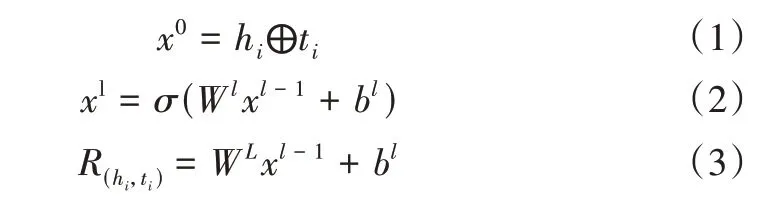
其中,hi∈Rd为头部实体hi维数为d的嵌入,ti∈Rd为尾部实体ti维数为d的嵌入,L为神经网络的层数l∈{1,…,L-1},Wl、bl为l层神经元的权重和偏置,使用LeakyReLU 计算激活σ,x⊕y表示向量x和y的拼接,R(hi,ti)表示特定实体hi和ti的关系元。
对于多个实体对(hi,ti)的特定关系元,通过当前任务中所有实体对的特定关系元生成最终关系元:

其中,K表示关系元个数。
2.2 评估方法
为了评估梯度元对关系元的更新效果,需要构造得分函数评估特定关系下实体对的有效排名,并计算当前任务的损失函数。为此,将嵌入方法的核心思想应用于嵌入学习器中,证实知识图谱中三元组的真实排名的有效性。
在任务τr中,计算支持集Sr中每个实体对(hi,ti)的得分:

其中,||x||表示向量x的L2 范数。假设头实体、关系和尾实体构成的三元组(h,r,t)满足h+r=t,可利用得分函数比较h+r和t之间的距离,使其最小。可将此思想应用于小样本链接预测任务中,但由于任务中并无直接的关系嵌入,因此将关系嵌入r替换为关系元Rτr。
对于每个三元组的得分函数,设置以下损失函数:
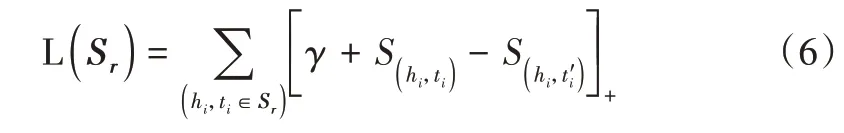
其中,[x]+表示x的正例三元组,γ表示边缘超参数,S(hi,t'i)为当前支持集中实体对(hi,ti) ∈Sr的得分,S(hi,t'i)为支持集中负样本的得分,两者满足(hi,r,t'i) ∉G。
由于任务Tr表示模型能够正确编码正确的三元组,L(Sr)的值较小,因此将基于L(Sr)的R(Tr)梯度视为梯度元G(Tr):

根据梯度更新规则,对关系元进行快速更新:
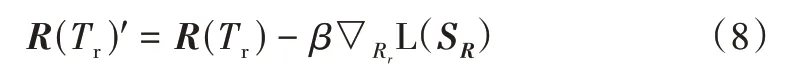
其中,β表示关系元操作时梯度元的步长。
当通过编码学习器对查询集进行评分时,在得到更新后的关系元R(Tr)'后,将其转移至查询集Qr={(hj,tj)}的样本中,计算在查询集中的得分和损失。同理,对支持集进行操作:

其中,L(Qr)为最小化的训练目标,可利用其损失对模型进行更新。
训练的目标是最小化损失函数,一个小批量中样本所有任务的损失之和可表示为:

3 实验结果与分析
3.1 数据集
本文提出的模型将在Wordnet 数据集、Freebase 数据集下的子集FB15K 及小样本数据集NELL-995 进行实验,并且采用链接预测和三元组分类两个评价指标对模型进行评价。表2为数据集的统计信息。

Table 2 Statistics of different data sets表2 不同数据集的统计信息
3.2 链接预测
链接预测是指预测一个三元组中缺失的实体或关系。在任务中,基于所有正确实体的平均排名(Mean Rank)和排名前10 的正确实体的比例(Hits@10)作为评价指标。在Wordnet、FB15K 和NELL-995 数据集上与RESCAL、TransE、DistMult、ComplE 及小样本进行比较。
超参数的范围设定为:实体、关系和词的向量维数k∈{50,80,100,150};随机梯度上升算法学习率λ∈{0.001,0.005,0.01};负采样参数n∈{10,15,20,30};偏置量α∈{6.0,8.0,10.0},β∈{6.0,8.0,10.0};相同关系下实体的结构字段中的实体数阈值τ2∈{5,10,20};SGA 中的batch 大小b∈{20,120,480,600,960,1 440,4 800}。
实验采用随机梯度下降法,使用初始学习率为0.001的Adam 优化器对参数进行更新。设定初始参数γ=β=1,在查询集中正三元组和负三元组的数量分别为3 和10,训练后的模型每1 000 个epoch 对应一个验证任务,并记录当前的模型参数和性能,以便于后期进行比较。各模型具体性能参数见表3。
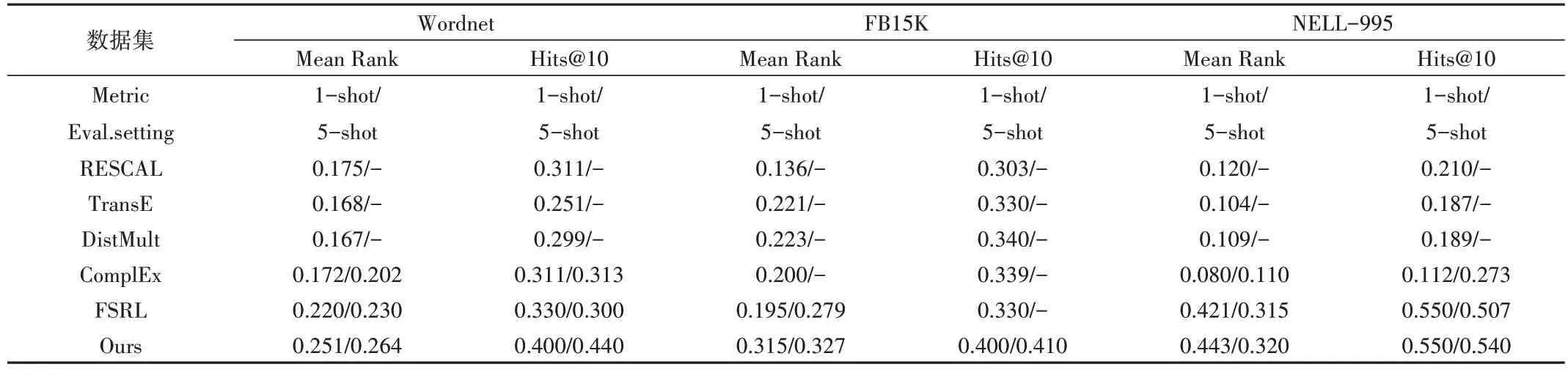
Table 3 Prediction results of different models表3 不同模型的预测结果
由表3 可见,在单次链路预测(1-shot)方面,相较于基准模型,本文模型在3 个数据集的Mean Rank 分别平均提升了32%、27.9%、7%,Hits@10 平均改善率分别为41%、19%、13%;在5 次链路预测(5-shot)方面,本文模型在3个数据集的Mean Rank 分别平均提升了30%、40%、22%。由此可见,所提出的模型预测能力小样本链路的能力更强。
然而,Freebase 与Wordnet 数据集的最佳结果出现在不同的数据集。尤其在Freebase 上,两个数据集的差异更为明显。在3 个数据集中,小样本数据集NELL-995 表现更为出色,可能是由于FB15K 数据较为稀疏,连接相同关系的实体较少,每个实体对应的相似实体较少,导致实体嵌入偏差较大。
3.3 三元组分类
为了判断三元组分类给定的(h,r,t)是否正确,在数据集Wordnet、FB13、NELL-955 上进行实验,对模型进行评估。表4为不同数据集上三元组分类的结果。

Table 4 Triple classification results表4 三元组分类结果
由表4 可知,本文提出的模型的分类性能均优于基准模型,特别是在数据集NELL-995中,性能最佳。
4 结语
本文提出了一种基于元学习框架预测知识图谱中的少量链接,并设计了将特定关系的元信息从支持集传递至查询集的模型。
通过在Wordnet 数据集、Freebase 数据集下的子集FB15K 及小样本数据集NELL-995 的大量实验表明,本文提出的模型性能均优于现阶段的常用模型。
此外,本文还分析了训练任务的数量和实体稀疏性对模型性能造成的影响,为后期模型优化奠定基础。接下来,将思考如何在知识图谱小样本知识补全的链接预测中,获取有关稀疏实体的信息。
