面向高效边缘计算的可分类数据压缩传输机制
2023-01-02刘晓燕许志伟李文越刘利民
刘晓燕,许志伟,李文越,翟 娜,刘利民
(内蒙古工业大学数据科学与应用学院,内蒙古呼和浩特 010080)
0 引言
新型互联网应用形式的出现使网络终端节点逐渐从数据使用者转变为兼具数据发表者的角色。网络产生的数据量日益增加,且对数据的分析需求更加多样。现有的以云平台为代表的集中式数据平台无法保证在正常响应时延的基础上完成对全网数据的收集、处理和分析,边缘计算应运而生[1]。边缘计算作为5G 网络等新型通信技术的重要支撑,是通过接近用户边缘提供数据存储和计算服务的一种新型计算体系,在物联网中得到了广泛的应用。相关研究证明,将所有计算任务放在云上是一种有效的数据处理方式,但网络带宽往往无法满足快速发展的数据处理要求[2]。同时,随着边缘数据量的爆炸式增长,数据传输速度逐渐成为云计算的瓶颈,在这种岌岌可危的状态下,人们进入了边缘计算时代[3]。
边缘计算要求计算应尽可能靠近数据源并在边缘处理请求,这解决了网络边缘产生的海量数据无法及时处理的问题。在早期无线网络中,受部署传感器节点能量、处理能力、存储容量以及通信带宽等若干方面的资源限制,边缘计算发展受限。数据融合技术是解决资源限制的有效方法,其思想是融合来自不同数据源的信息[4]。它通过去除冗余信息来减少传输数据量,从而达到优化资源消耗、缩短网络传输时延的目的。但与此同时存在以牺牲准确度和鲁棒性为代价换取数据传输效率的弊端,且不够灵活也不能融合先验知识。目前已有相当关于边缘网络中基于离散小波的数据压缩技术研究[5],但现有数据压缩技术虽易行、简单,但却缺乏兼容性。数据压缩完成后传输编码到相关节点无法实时地完成相关数据处理操作。另一方面,引入以精度换取效率的数据压缩机制后,仍需在此基础上进一步改善。
本文主要为如何对边缘网络中传输的大量数据进行压缩处理,从而降低节点的功耗,提高数据传输效率。针对现状,本文提出一种面向高效边缘计算的可分类数据压缩机制。首先,在传感器的接收端分别进行数据收集,构建基于数据特征重构的压缩编码摘要机制,通过优化组合各输入数据的特征,重构数据特征。其次,应用目前的数据压缩表示技术CAE 算法搭建基于输入数据的压缩编码机制,通过编码对重构后的特征进行压缩,减少移动边缘网络节点的资源消耗,最终达到可分类的目的。
1 相关工作
1.1 现有互联网数据压缩传输机制
数据压缩主要指在信息存储过程中,去除掉那些占用额外比特位编码的冗余数据,以此达到缩减数据量的目的。现有互联网数据压缩传输机制多以数据融合方式实现[6]。融合信息系统为用户提供一个能够统一多源、异构信息的渠道,集成系统负责执行查询底层异构数据源、组合结果并将结果显示给用户等任务。许多数学理论也可用来融合数据,如Khaleghi 等[7]所述,数据融合方法可以分为基于概率的方法、证据推理方法和基于知识的方法。数据融合利用数据间的相关性按需融合数据,以此减少数据的表示量。例如,用于对海量数据特征估计的概要数据结构[8-12]和用于海量数据中关系查询的布鲁姆过滤器[13-14]是常用的数据压缩融合模型。雷萌等[15]提出的基于hash表的压缩算法则通过哈希映射将大量的数据压缩到一个紧凑且大小恒定的空间中,同时利用位置关系来融合不同的数据信息。但是,由于压缩融合模型是利用哈希运算来存储数据的,无法保存原始数据的任何信息,所以无法对数据进行分类处理。Ziv 等[16]提出了LZ77 数据压缩方法,LZ77方法通过利用数据的重复结构性质,达到数据压缩的目的,但存在耗时长的问题[17]。Burrows 等[18]提出了一种对矩阵进行排序和变换的数据压缩算法,但该方法的压缩性能较差。Bartus 等[19]提出了重复删除技术来实现数据压缩的目的,主要应用于重复性较高的共享资源压缩,例如音视频数据方面的压缩。但该技术需要建立繁琐的索引项进而导致消耗大量的计算时间。这些方法均存在兼容性较差、精度偏低的问题[20]。
1.2 边缘计算下的数据压缩传输机制
目前关于边缘网络中基于小波的数据压缩研究已有一些基础性的工作。针对单个传感器节点产生的时间序列信号RACE 给出了一种压缩位率自适应的Haar 小波压缩算法,通过阈值来选择重要的小波系数从而调整压缩位率[22]。该算法在单个节点内运行,通过挖掘时间相关性减少冗余数据的传输,但未考虑邻近节点间数据的空间相关性和冗余数据问题。Acimovic 等[21]给出了基于5/3 小波提升方案和Haar 小波的分布式压缩算法。这些算法在邻近节点间交换信息,在数据传送到汇聚节点前分布式挖掘网络中数据的空间相关性,极大地减少了冗余数据的传输。受限制的小波算法实现过程较容易,但不具实时性,且受限于固定的系数值,从而导致数据的缩减率相对不高。无限制的方法不受限于固定的系数值,能够实现更高的数据压缩率[23],同时部分算法具有实时性。这些工作采用的都是结构较为简单的小波算法,在边缘传输过程中,数据压缩完成后传输到相关节点。基于小波算法的压缩传输数据无法在传输路径上直接进行数据处理,因而难以满足边缘计算下不同应用系统对数据压缩后直接进行数据处理的要求。
现有的数据压缩技术,不能在传输过程中直接处理,且压缩后的数据难以达到能够分类处理的目的。因此本文引入编码解码器,保留压缩数据的特性,处理后的压缩数据可以直接在传输过程中进行分类等分析工作,为构建面向边缘计算的、更为高效的数据传输机制提供基础。
2 面向高效边缘计算的可分类数据压缩机制构建
2.1 数据压缩编码模型
针对边缘网络节点间传输的海量数据导致的节点负荷超载、传输时延和能源消耗增大等问题,本文提出一种高效边缘网络数据压缩分类模型。该模型分别在传感器的接收端收集数据,应用压缩编码算法搭建基于输入数据的压缩编码机制,通过编码对数据进行压缩进而提升数据传输效率。
压缩编码方法最早是由Rumelhart 在1986 年提出的一种神经网络结构,其包括输入层、隐藏层和输出层三个部分[24],自适应编码器结构图如图1所示。
其中,从L1层到L2层是编码过程,从L2层到L3层是解码过程。设ƒ表示L1层到L2层的编码函数,g表示L1层到L2层的编码函数和L2层到L3层的解码函数,可得如下表达式。

Fig.1 Structure diagram of adaptive encoder图1 自适应编码器结构图
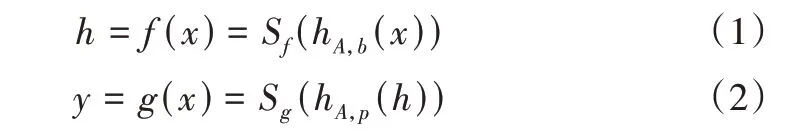
式(1)中,h为隐藏层表示;式(2)中,y为输出层的表示。L1 层到L2 层的映射权值矩阵为A,L2 层到L3 层的映射权值矩阵为Ã,Ã 为A 的转置矩阵,压缩编码器通过深度神经网络DNN 进行预训练,从而确定神经网络中权值矩阵A 的初始值。Sf(x)为编码器的激活函数,通常取Sigmod函数,即为解码器的激活函数,通常取Sigmod 函数或者恒等函数。自动编码器的参数有θ={A,b,b'},其中b和b'为偏置项,压缩自动编码器模型通过计算输出层输出数据y 和输入层输入数据x 的误差来训练这些参数,当输出数据和输入的相似程度大于阈值的时候则认为该编码器能保留输入数据的大部分特征信息。当激活函数Sg采用Sigmod 函数时,其重构误差如式(3)所示:

之后,设数据集为S={Xi}(i=1,2,3...n),根据式(4)计算训练样本的整体损失:

最后利用深度神经网络DNN 算法进行迭代训练,可得到使得损失函数J(θ) 最小的压缩自动编码器参数θ={w,b,b'},至此完成模型的训练。
2.2 基于数据特征重构的压缩编码机制
由于引入压缩机制后将导致精确率下降的问题,所以本文提出了一种基于特征重构的数据压缩编码机制。压缩编码算法的输入要求为实数矩阵,特征重构指将原始数据转换成实数矩阵。特征重构是一种特征工程技术,它的目标为将原始数据转化成特征向量。首先在传感器的接收端分别进行数据收集;其次对输入数据进行特征重构;最后应用2.1 节中的压缩编码表示算法通过编码对特征进行压缩,降低资源消耗。基于特征重构的数据压缩编码结构如图2所示,具体步骤如下。
(1)收集传感器中原始数据。将原始输入数据依次记录在图2 的Array1中,定义h 个大小为4 的数组,每个数组中的比特位初始化为0。
(2)通过MOD 函数后将函数值依次存放于图2 中Array2数组中。构造MOD 函数并依次利用MOD 函数分别对记录在步骤(1)中的h 个数组中的每位数据逐个进行运算,依次将函数计算结果存放于比特数组中。
(3)组合步骤(2)中的比特数组表示结果作为新的特征向量,如图2 所示Vector。将新的特征向量作为压缩编码机制的输入数据。
(4)特征重构后采用压缩编码机制进行数据特征压缩。压缩编码机制中自编码器将输入的空间数据通过非线性变换映射到特征空间,在图2 中用Encoder 过程表示。解码器将特征空间的特征同样通过非线性变换还原到原始输入空间中。在还原过程中,利用最少的比特数来高度表达原来输入数据特征,其优化目标函数为最小化重建误差,在图2 中用Decoder 过程表示。压缩编码可以很好地捕捉能够代表输入数据的最重要因素,寻找到代表原数据的主要成分,进行特征压缩提取操作。
3 实验与结果分析
3.1 数据集
本文共进行了两组实验,其中每组实验中选用5 个数据集,每次实验数据集大小如表1所示。
实验1 数据集来源于科罗拉多州北部的罗斯福国家森林,这些地区是人类干扰程度最小的森林,包含四大荒野地区,共有12 个数据特征和7 种森林覆盖类型。四大荒野地区的背景信息如表2所示。
其中,Neota 在四个荒野地区中具有最高的平均海拔值,Rawah 和Comanche Peak 会有一个较低的平均高程值,而Cache la Poudre 的平均高程值最低。12 个数据特征包含Elevation、Aspect、Slope等因素。

Fig.2 Schematic diagram of data compression coding based on feature reconstruction图2 基于特征重构的数据压缩编码示意图
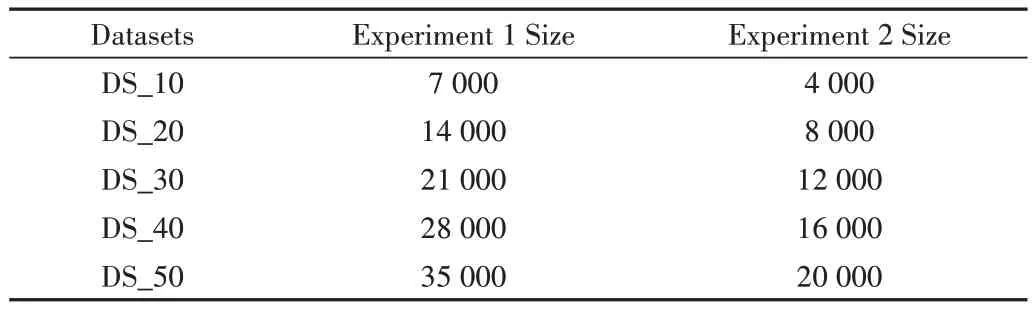
Table 1 Information of datasets表1 实验数据集信息

Table 2 Information of four wilderness areas表2 四大荒野区域信息
实验2 数据集来源于4 名年龄在66-86 岁之间的健康老年人的运动数据。在他们穿戴的外衣上安装传感器记录日常活动的数据变化内容。数据集包含接收信号强度指示器(RSSI)、相和频率等8个属性。
根据采集部署在传感器上的数据信息,利用基于特征重构的压缩编码机制对数据特征进行压缩归类。然后搭建预测模型,比较数据分类精度以及模型运行效率。
3.2 实验方法
对于两个数据集,分别进行以下操作:首先收集边缘网络传输路径节点中数据,对输入数据的不同属性进行特征重构;然后通过编码对这些特征进行压缩;最后利用基于支持向量机算法搭建数据分类模型。
首先,定义4 个存储容量大小为4bit 的数组,选用的MOD 函数为H(2),对输入的数据集中的数据进行特征重构。通过函数运算,最后组合4 个数组中存储的16 个bit值,作为数据特征向量。其次,对于数据集一,传感器接收的原始数据总共12 个特性,重构特征后输入大小为16*12,将重构特征作为压缩编码算法的输入,对特征进行编码压缩后输出大小为1*6。对于数据集二,传感器接收的原始数据总共8 个特性,重构特征后输入大小为16*8,将重构特征作为压缩编码算法的输入,对特征进行编码压缩后输出大小为1*6。最后,将压缩编码通过相关节点传输到边缘设备,在微型设备上搭建SVM 分类模型。
本文采用常用的准确率作为分类评估指标,其计算公式如下。
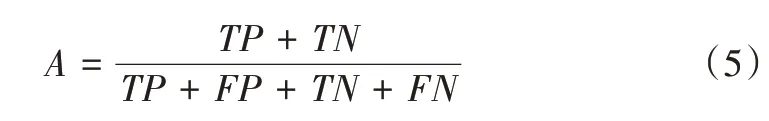
其中,TP表示正确分类数据个数,FP表示错误分类的数据个数,FN表示属于该数据类型但被错分的数据个数,TN表示属于其他数据类型被分到其他类别的数据个数。
3.3 实验结果分析
对传感器收集到的数据不做任何处理,直接使用SVM算法构建分类模型,用SbaVM 标识。对数据进行压缩编码后构建分类模型,用Saboc 标识。对传感器接收的数据首先进行特征重构,然后进行压缩编码后再构建分类模型,用DccAbofe 标识。实验1 运行准确率如图3 所示,运行时间如图4 所示。实验1 准确率和运行时间比较如表3 所示。实验2准确率和运行时间比较如表4所示。
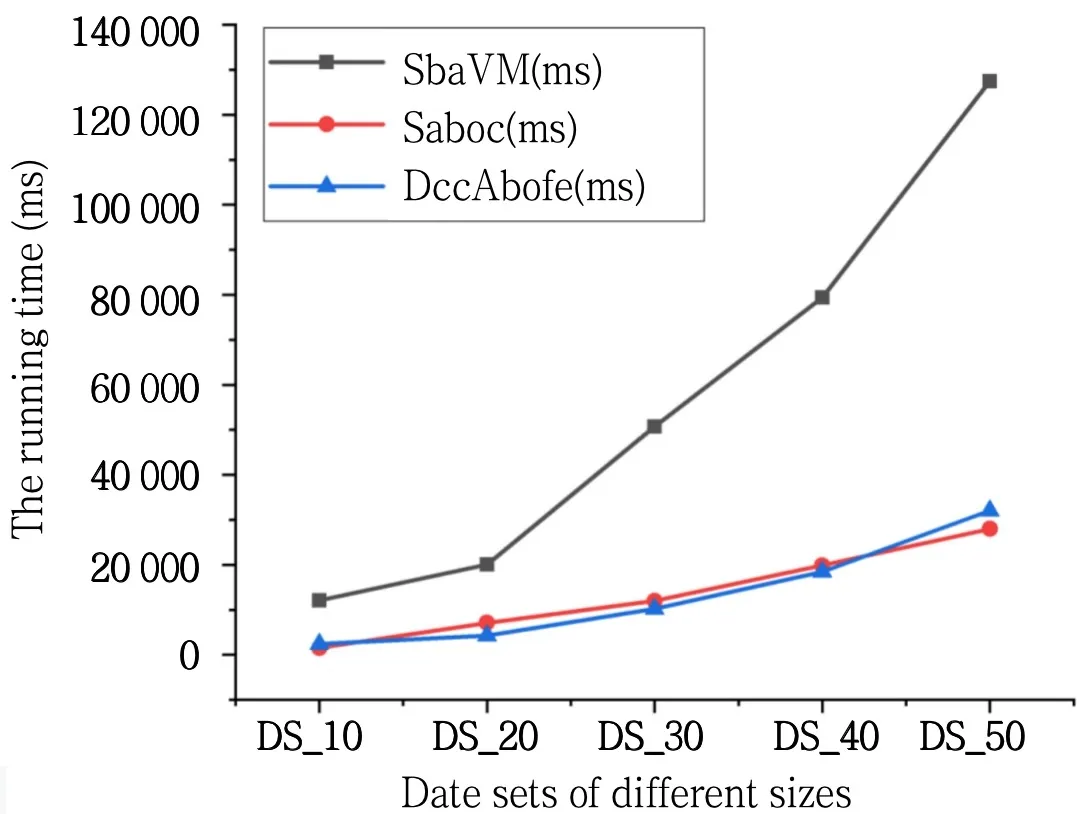
Fig.3 Comparison of the accuracy of different mechanisms under different data sets图3 不同数据集下运行准确率比较
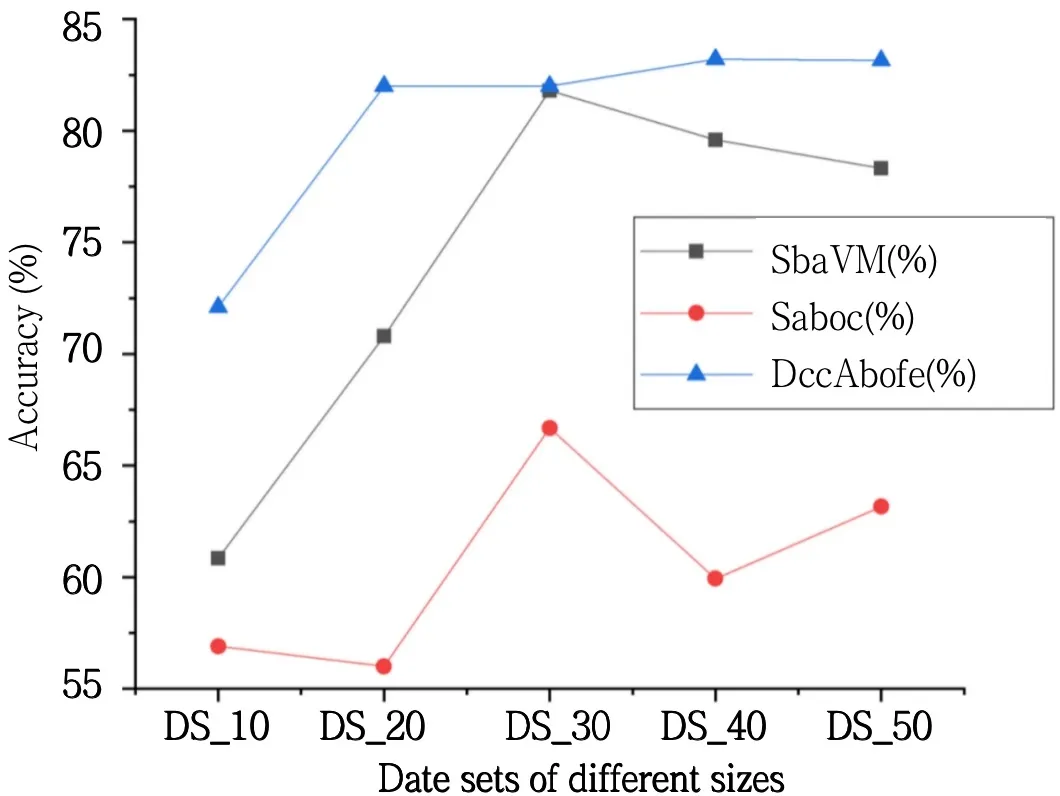
Fig.4 Comparison of running time under different data sets图4 不同数据集下运行时间比较
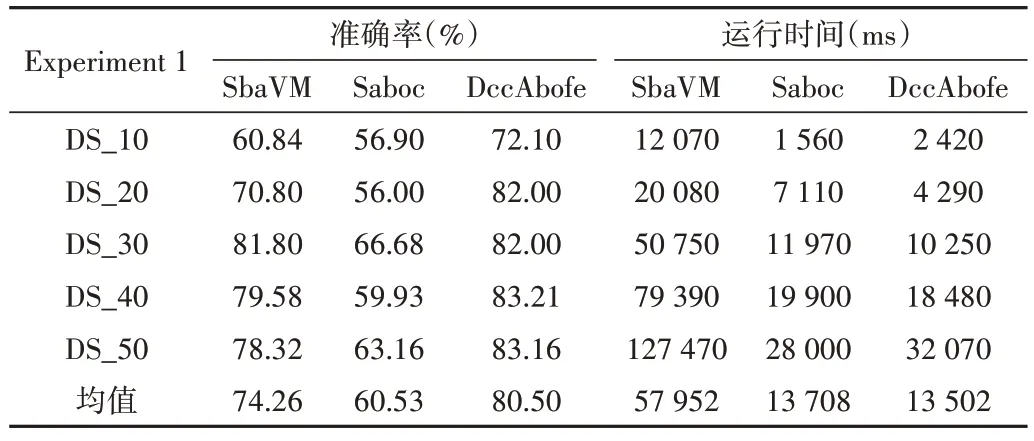
Table 3 Comparison of accuracy and running time in experiment 1表3 实验1准确率和运行时间比较
通过观察图3-4、表1 和表2,在选取的两组实验中,压缩编码分类机制(Saboc)比传统支持向量机模型(SbaVM)的运行时间至少降低6 070ms,当数据量达到35 000 时,准确率降低了15.12%;基于特征重构的压缩编码分类模型(DccAbofe)比传统支持向量机模型(SbaVM)运行时间至少降低6 240ms,与此同时当数据量达到16 000 时,准确率提升了3%。
压缩编码算法在编码过程中进行数据压缩后会损失一定的准确率,出现比传统的SVM 算法偏低的准确率;采用了基于特征重构的压缩编码分类处理后,准确率比传统SVM 算法有所提升,且运行时间大幅度下降。
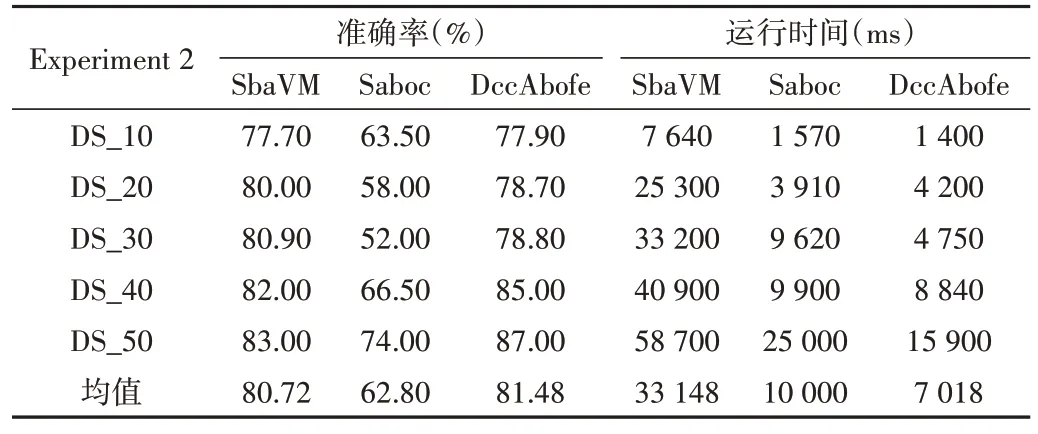
Table 4 Comparison of accuracy and running time in experiment 2表4 实验2准确率和运行时间比较
4 结语
在边缘网络节点收集和传输数据的过程中,为减小数据传输的开销并优化传输效率,同时针对引入压缩机制后导致精确率下降的问题,提出了基于特征重构的数据压缩分类机制。通过传感器接收数据,构建感知数据特征压缩机制,最后应用基于支撑向量机的数据处理模型对传感器采集数据进行归类整理。实验证明,通过对数据进行以上处理,减小了数据传输时延,同时精确率得到提升,使得边缘网络设备的性能利用率提高。
由于时间、精力和实验条件的限制,本研究尚有许多问题和不足,后期可以从以下几个方面展开更深入的研究:
(1)在验证数据压缩分类时,采用的方法不够前沿,未来需要进一步优化算法和程序代码。
(2)数据重构过程中,采用的哈希方法,可逆计算效率低,需进一步优化。
