基于改进LSTM的多源时序卷烟审计数据分析方法
2023-01-02王树明吴时清
王树明,吴时清,余 菁,陈 军,宋 伟
(1.中国烟草总公司湖北省公司;2.武汉楚烟信息技术有限公司,湖北武汉 430030;3.武汉大学计算机学院,湖北武汉 430070)
0 引言
对卷烟销售和经营活动进行严格的规范化管理是烟草行业专卖专营体制的内在要求。卷烟生产、销售网络非常庞大,面对纷繁复杂的卷烟业务系统和数据,如何挖掘和利用其中的信息和知识,从而准确、高效地识别潜在风险行为成为卷烟专卖专营管理的核心任务和需求。当前卷烟专营网络中拥有众多的独立运行子系统,数据纷杂,包括营销、物流、烟叶、专卖等十余个业务子领域。直接分析各个子系统数据并不能充分利用业务平台数据,充分发现卷烟业务平台中的潜在风险行为。卷烟专营网络平台中的审计子系统按照审计计划管理模块定义的审计任务和审计数据,对卷烟网络平台中的业务数据备份、审计。审计数据覆盖多个卷烟平台子系统,而且可以定义数据清理操作,提高多源审计数据的数据质量。因此,针对卷烟审计数据开展挖掘和分析,将会更加准确、高效地发现业务平台中的高风险行为。
1 相关研究
对审计数据进行建模分析和预测的前提是针对审计数据构建高质量数据特征。传统数据特征构建方法非常依赖用户对业务的理解,具有很大的局限性。卷烟业务平台非常庞大,各省业务也有很大差异,这些因素均限制了对平台业务数据的理解和分析。
近年来,随着以深度学习为代表的机器学习方法逐渐普及,利用神经网络卷积层提升数据特征维度可以尽可能地充分挖掘数据特征,筛选出对数据分析任务更有利的数据特征,不仅可以提高模型预测精度,而且可有效针对高维数据约束关键数据特征维度,提高模型训练效率。2015年,Yann 等[1]在Nature 杂志上发表论文介绍了深度学习的原理、优势和应用。循环神经网络(Recurrent Neural Network,RNN)[2-3]、长短期记忆(Long Short-Term Memory,LSTM)[4-5]和卷积神经网络(Convolutional Neural Networks,CNN)[6]等深度学习技术通过构建数据的序列层次可有效获取数据的时序依赖关系,在许多领域,尤其是自然语言处理、图像识别、语音合成等非结构化数据分析方面取得了令人瞩目的成果[7]。例如,Kanter 等[8]针对高维科学数据的自动特征提取问题提出了Deep Feature Synthesis方法,该方法针对科学数据中关系型或用户行为数据的特征提取问题,自动提取能够表达丰富特征空间的数据特征,但该方法并不能充分利用复杂的数据特征;Chong 等[9]从3 种无监督特征提取方法出发研究了基于深度学习的股票市场预测算法,研究结果表明深度神经网络可以从残差中提取更多额外信息,提高整个学习模型的预测准确率。LSTM 可以有效克服传统RNN 的梯度爆炸问题,例如Jin 等[5]基于LSTM 模型提出了LSTM-DE 模型,将检测序列数据作为附加输入连接到药物处方预测序列中,提高了处方预测效果,然而LSTM-DE 模型受到RNN 网络遗忘性的限制,当测试数据的时间序列变大时,预测效率有较明显的下降;Ma 等[10]基于双向神经网络(BRNN)提出了Dipole 模型,利用历史和未来时序数据作为输入进行联合训练,提高了针对长序列时序数据的学习精度,然而Dipole模型没有考虑到多模态数据对于预测结果的影响;Zhang等[11-12]基于CNN 提出面向时空数据分析的时空残差网络模型,该模型对时空数据的时间特性、空间特性和关联关系进行建模,学习时空数据的时空关联特征,很好地解决了时空数据特征分析,但对多模态数据的特征分析代价较大;王晓飞等[13]设计了一种基于Prophet-LSTM 模型的PM2.5 浓度预测方法,利用Prophet 模型可分解方法,将PM2.5日值浓度序列分解成趋势、周期和随机波动分量,对随机波动分量建立LSTM 模型进行分析;覃智威等[14]构建了一种基于粒子群优化算法的LSTM 模型,并用于医院门诊量的时序关系预测;谢贵才等[15]提出一种基于深度学习的多尺度时序卷积网络MSCNN,实现了人流量时序数据中短时依赖、长时周期模式的获取和多尺度时序模式特征的重标定,可对任意时段人流量进行预测。
现有研究方法缺乏针对多源审计数据的时序特征、多模态特性开展高效深度学习方法的研究。卷烟审计数据来源多、维度大,卷烟业务平台中用户行为也往往具有时空差异性,用户行为模式也都具有极大的不确定性,这给卷烟审计数据分析带来了巨大挑战,目前仍然缺乏针对卷烟审计数据的有效分析方法[16-18]。为此,本文基于卷烟审计数据的两个内在特征,即多源异构性和时序关联性,发挥深度学习在深层次数据特征分析和多维数据时序关联分析两方面的优势,提出一种改进LSTM 的RNN,并对LSTM 门函数结构进行优化,提高针对多源数据卷烟审计数据的特征提取能力,准确高效地发现卷烟业务网络中的潜在高风险行为,为我国省级卷烟业务网络平台提供面向多源卷烟审计数据的深度学习分析解决方案。
2 基于改进LSTM 的多源时序卷烟审计数据分析机制
2.1 LSTM
RNN 能够有效处理大数据量数据,也可以对序列数据进行有效处理,但RNN 需要逐层传递状态信息,这种模型训练方式导致随着序列长度的增加,参数传递的层数也会越多,导致梯度爆炸等问题,同时神经网络对于长序列数据也会产生长时间间隔的消息失忆问题。
LSTM 是RNN 针对长序列数据依赖关系的改进实现,LSTM 单元结构如图1 所示,其通过在RNN 中增加遗忘门和更新门,从而有选择地对状态信息进行记忆增强和遗忘,使得特定信息可以有效记忆并传递。LSTM 单元中遗忘门和更新门采用Sigmoid 函数,Sigmoid 函数取值接近于0 则门处于关闭状态,接近于1 则门处于开启状态,可对信息进行有选择的采纳。LSTM 的前向传播计算函数表示为:
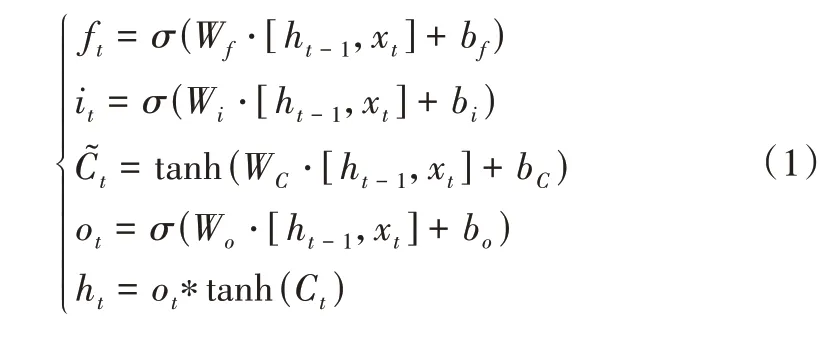

Fig.1 Unit structure of LSTM neural network图1 LSTM 神经网络单元结构
式中,ft、it、ot分别为遗忘门、更新门和输出门的t时刻状态值;Ct-1和Ct分别为LSTM单元在t-1和t时刻的状态值;ht-1和ht分别为LSTM单元在t-1和t时刻的输出值;为LSTM 单元在t时刻的候选状态值。遗忘门可以选择LSTM 单元状态中哪些分量继续传递,哪些分量丢弃;更新门决定了LSTM 状态中哪些分量更加重要;输出门则决定了哪些分量作为当前状态传递到下一个时刻。
对于卷烟审计数据分析任务来说,审计记录、交易行为按照固定的时间间隔记录,LSTM 可以针对审计数据的时间关联特性,将用户行为数据按照时间顺序依次输入到LSTM 中,利用LSTM 对高维审计数据进行筛选和处理。虽然LSTM 可以更好地利用时序关联数据特征,但是卷烟交易行为往往具有长时间关联特性(如明显的季节性和政策导向性),这些服务特点导致LSTM 应用于卷烟审计数据分析时训练模型时间较长,模型精确性有限。为此,本文引入总体经验模态分解(Complementary Ensemble Empirical Mode Decomposition,CEEMD)方法对审计数据特性进行增强,以提高模型训练效率,使得针对多源时序卷烟业务审计数据的分析效果更好。
2.2 CEEMD
卷烟业务审计系统是一个非线性、非平稳的复杂动态系统,与单业务系统不同,卷烟审计数据来源于多个业务系统,数据特征复杂,同时审计数据的时序特征是一个重要的数据特征。经验模态分解(Empirical Mode Decomposition,EMD)方法由Huang 等[19]提出,是用于处理非线性、非平稳时间序列的有效方法。EMD 可将任意的复杂信号分解成为有限规模的本征模态函数(Intrinsic Mode Function,IMF),且每个IMF 表征原始信号不同特征尺度的时间序列。EMD 方法与Hilbert 频谱结合是一种自适应的时间频域分析方法。当信号中存在间歇性信号时,EMD 分解方法会产生所谓的频率混叠现象,即一个IMF 分量中会包含多个不同特征尺度的成分,或者相似尺度的数据特征在不同的IMF 分量中存在。为解决由于间歇性数据信号导致的模态混叠现象,Yeh 等[20]基于EMD 分解方法提出了CEEMD。
针对审计数据的复杂时序特征,本文采用CEEMD 方法对审计业务系统数据进行处理,分解得到一系列相对平稳的时序分量,处理流程为:
(1)针对一组序列审计数据输入X={x1,x2,…,xn},对xi加入第i组高斯白噪声,得到两个信号序列mi+和mi-,表示为:
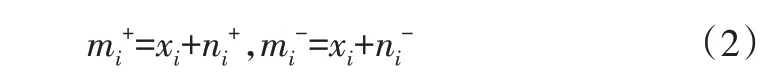
式中,ni+和ni-为正负成对的高斯白噪声。
(2)对mi+和mi-进行EMD 分解,得到两组集成的IMF分量,分别为加入正噪声组的IMF+和加入负噪声组的IMF-。
(3)针对时序审计数据x(i1≤i≤n),得到两组IMF 向量IMFi+和IMFi-。
2.3 卷烟业务审计数据
省级卷烟业务平台中审计管理业务主要分为审计资源管理、审计计划管理、经责与专项审计、工程审计、采购审计等五大业务环节。业务涉及的源端系统主要包括营销、物流、专卖、烟叶、财务、人力资源、内管等业务系统。数据中心采集源端业务系统业务数据后,进入数据中心进行数据采集、数据清洗、数据转换、数据加工汇聚后形成数据服务目录,对外提供数据服务,为支撑数据应用服务及源端业务系统的统计分析、审计数据中心提供基于CEEMD 的LSTM 审计数据分析引擎,提供针对多源时序卷烟审计数据的高效分析服务。卷烟审计数据中心框架如图2所示。
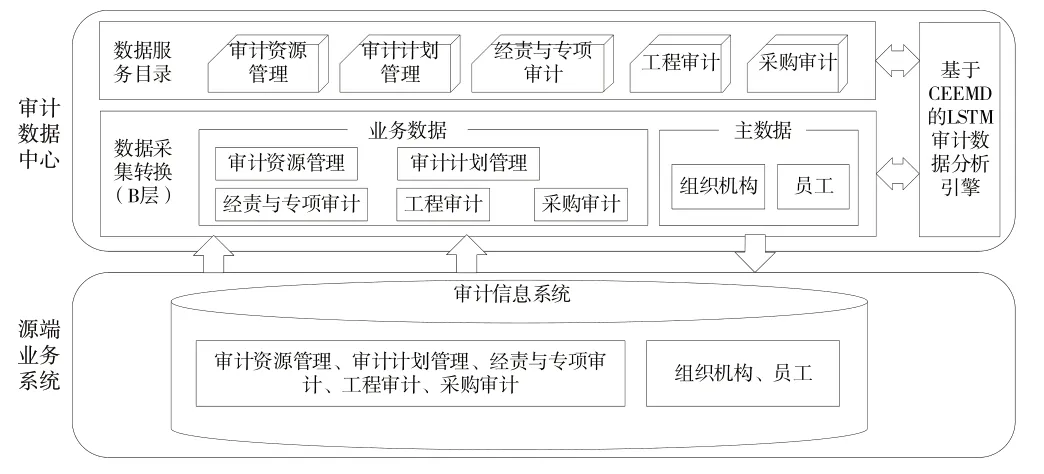
Fig.2 Framework of cigarette audit data center图2 卷烟审计数据中心框架
2.4 基于CEEMD 的LSTM 多源时序卷烟审计数据分析方法
卷烟业务平台审计数据来自多个综合业务平台,为实现对多源时序审计数据的精准分析,结合审计数据具有的不规则时序特征,本文设计的基于CEEMD 的LSTM 多源时序卷烟审计数据分析框架如图3所示。
针对多源审计数据,首先采用CEEMD 方法对审计源数据进行模态分解,得到多组IMF 分解向量IMFi+和IMFi-。基于CEEMD 的特性,分解后的向量组IMFi+和IMFi-仍然保持原业务系统的时序特征,并且使得数据的时序变化相对更加平稳,有利于后续基于LSTM 对审计数据分析的精确性。
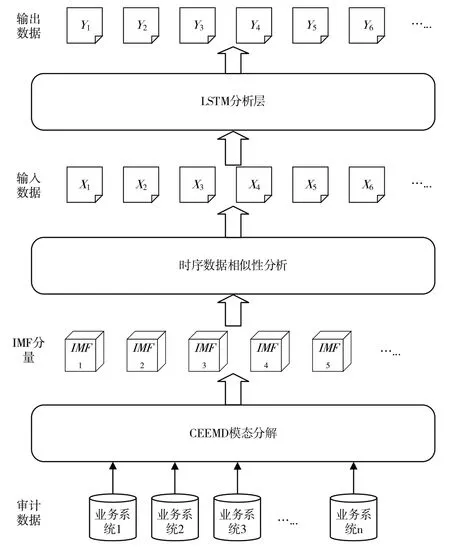
Fig.3 LSTM analysis framework over multi-sources audit data based on CEEMD图3 基于CEEMD的多源时序审计数据LSTM 分析框架
得到IMF 分量后,为分析多源时序数据之间的时序关联关系,对IMF 分量采用相似性分析方法扩展构建时序数据序列X={X1,X2,…,Xn}。对于给定IMF 分量IMFi={x1,x2,…,x}l和IMFj={y1,y2,…,y}l,利用公式(3)评价其相似度,表示为:
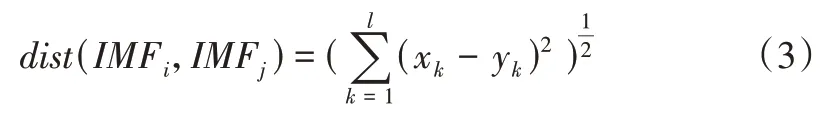
针对各IMF 分量选择top-k的时序相似序列后,扩展得到时序数据序列X={X1,X2,…,Xn},作为后续LSTM 网络的输入数据。例如卷烟审计平台数据来自卷烟平台合同、营销、专卖、财务、物流等业务系统,针对单业务系统数据难以充分体现卷烟审计数据的时序关联数据特征。营销数据仅记录了卷烟销售商户的订单信息,目前卷烟物流配送存在一定滞后性,因此单纯从营销数据和卷烟数据方面不能充分体现卷烟经营户的经营时间特性。本文利用CEEMD 抽取跨营销域与物流域的综合IMF 分量可以更好地体现经营时间特性,例如抽取营销数据和异步物流配送数据的阶段时间窗口方差和平均值来体现卷烟经营户的时序经营特征。
传统RNN 中同样的权重参数矩阵在不同循环层之间共享,最终的输出层梯度为各层梯度之和。RNN 网络中总的梯度并不会消失,但远距离的梯度仍然会被近距离的数据梯度所主导并覆盖,导致RNN 模型很难对远距离的依赖关系进行学习。卷烟平台行为数据具有明显的季节性和周期性,而这种时间关联性的时效特征往往非常长,因此针对烟草审计数据的学习模型必须能够适应数据长效时间关联特征。
LSTM 是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。如图1 所示,LSTM中梯度的传播有多条途径,在以公式(4)为代表的路径上,逐个元素直接叠加,梯度流最稳定,但是其他路径上梯度流传播与普通RNN 相似,仍然有权重矩阵反复连乘,会存在梯度消失和梯度爆炸的问题。LSTM 通过保证公式(4)路径上的梯度传递保证远距离梯度的传递。
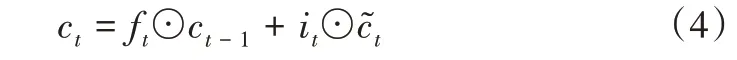
LSTM 单元中遗忘门可以将时序关系有选择地传递给后续LSTM 单元。为了更好适应卷烟审计数据的长时间关联特征,对LSTM 单元进行改进。首先,为保证时间梯度流稳定传播,将公式(4)主路径的ft设置为1(即不经过遗忘门直接传递给下一个状态),利用公式(5)保证远距离梯度的流畅传递不会遗失。

然而这样的方式会导致多余的状态信息被大量传递到后续LSTM 单元,进而导致潜在的状态爆炸问题。为解决这个问题,保障对烟草审计数据的学习效果和效率,对其他路径的参数传递进行控制。如图4 所示,遗忘门负责压缩之前的状态信息,并过滤前一个状态的无效参数;更新门的输入数据受遗忘门控制,部分无效或低关联度数据被过滤掉而不进入更新门,以控制参数爆炸的规模;输出门控制有多少信息进入到下一个LSTM 单元。这种结构可有效控制LSTM 的信息传递,同时可以更好地体现周期性的时序关联数据特征,非常适用于卷烟业务平台中时序审计数据的分析任务。
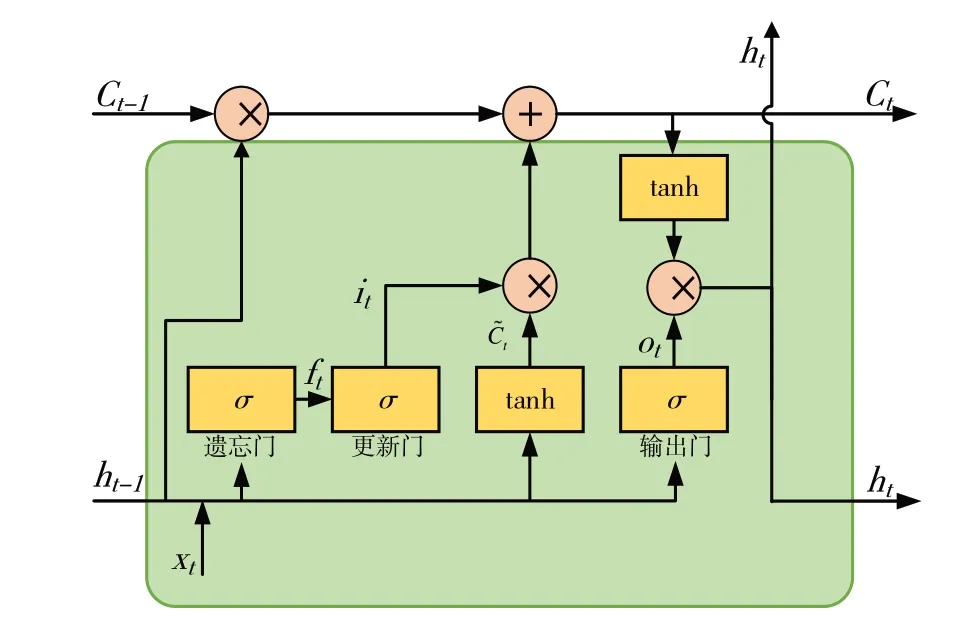
Fig.4 Improved LSTM unit structure for time series cigarette audit data图4 面向时序卷烟审计数据的改进LSTM 单元结构
3 实验方法与结果分析
3.1 实验设置
将面向多源时序卷烟审计数据分析算法用于湖北省卷烟业务平台中的审计数据分析,实验明确定义多源数据审计过程中的数据不一致性、数据不合规以及数据异常现象为风险行为,以发现其中的潜在交易风险行为。设计实验分析比较本文算法与LSTM、ATTAIN[5]、LSTM-DE 模型[6]针对多源时序烟草审计数据的分析性能,统计在不同模型参数及数据情况下的风险行为发现查全率和查准率,并对查询结果进行分析。
训练数据选用卷烟审计平台中覆盖5 个子业务系统(合同、营销、专卖、财务、物流)的审计数据,数据记载2019年1-12 月的各个子业务系统业务数据,每个子系统业务数据规模控制在2 万条,训练数据规模为10 万条。测试数据选用2020 年6 月-2021 年6 月的卷烟审计数据(2020 年卷烟营销数据由于疫情原因缺失,因此实验忽略2020 年数据)共计200 万规模,标注风险行为主要包括跨区配送(即不合理异常配送)和异常营销风险行为(即卷烟品类采购与销售异常)两类。实验运行环境为CPU AMD 5900X,ASUS RTX-3090,32GB 内存的服务器。训练过程按照时序特征对原始训练数据进行分片,分片规模保持与训练层层数一致(10~50),各数据分片采用“2.4”节介绍方法提取数据特征作为输入数据输入学习单元。
3.2 查全率预测
图5(彩图扫OSID 码可见,下同)统计了模型参数对学习预测查全率的影响。图5(a)为当审计数据来源3 个业务系统(K=3)时,查全率随着隐藏层数的变化规律。如图5(a)所示,本文方法的查全率优于其他对比方法,当隐藏层为50 时,本文方法的查全率R=88.5%,可以很好地满足卷烟业务系统对审计数据分析的应用需求。
卷烟业务平台包含了多个业务系统,来源于不同审计数据具有不同的数据模态,本文设计实验验证设计方法是否可以更好地适应多源时序审计数据的分析需求。图5(b)为当固定LSTM 隐藏层数为50 时查全率与数据源规模之间的关系。如图5(b)所示,针对多源审计数据之间的关联关系引入CEEMD 方法对时序审计数据进行模态分解,分解后的输入数据在时序特征上更加平滑,可以更好地适应多源业务系统之间数据模态的差异,而随着数据来源业务系统的增加,其他没有对数据进行预处理的方法查全率均出现了不同程度的下降。由图5(b)可知,本文方法可有效提高多源审计数据的分析效果。
3.3 查准率预测
设计实验统计分析模型参数对学习查准率的影响。图6(a)记为当审计数据来源3 个业务系统(K=3)时,查准率随着隐藏层数的变化情况,可以看出本文方法的查准率优于其他方法,在不同隐藏层数情况下,本文方法的查准率维持在90%以上,当隐藏层为50 时,本文方法的查准率R=92.3%。卷烟业务数据具有长时间特征,导致LSTM 和LSTM-DE 方法的查准率不足,而ATTAIN 方法运用了注意力机制,本文方法设计了LSTM 单元利用遗忘门控制更新,均可以很好地利用长期数据的关联特征。
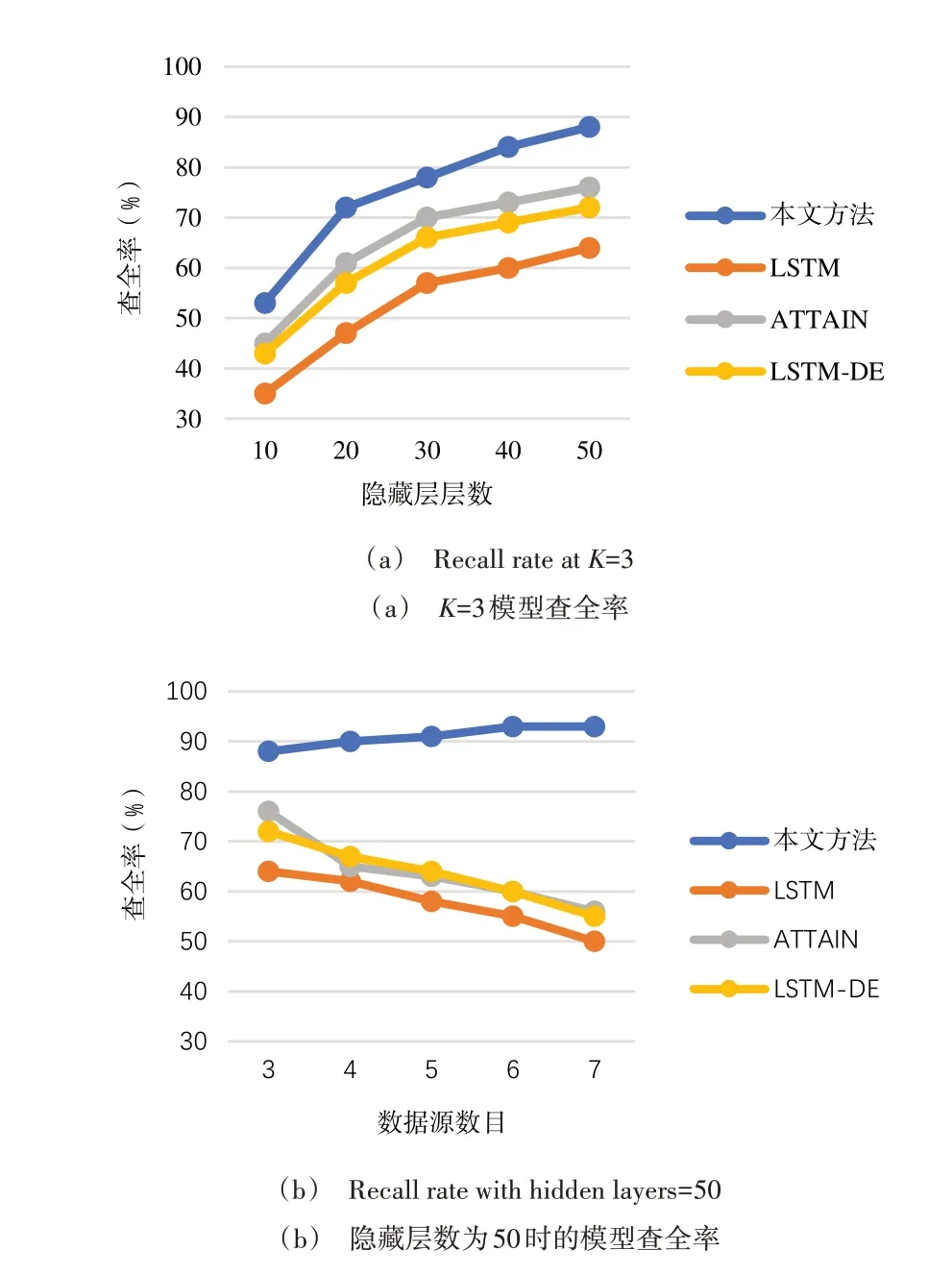
Fig.5 experiments of recall rate图5 查全率实验结果

Fig.6 Precision experiments图6 查准率实验结果
如图6(b)所示,当审计数据来源于多个业务系统时,由于数据模态的差异,对比方法的查准率均随着数据模态的差异加大而有明显下降,而本文方法采用CEEMD 进行模态分解,可以更好地使用多源业务系统的数据模态差异,其在数据源增加的前提下,分析查准率并不会出现显著下降,仍然维持在90%以上,说明该方法针对多源卷烟审计数据具有很好的查准效率。
4 结语
本文设计并实现了一种面向多源时序卷烟审计数据的深度学习分析算法,针对卷烟审计数据具有的多模态、时序关联特性,设计了一种改进LSTM 网络,从而更好地适应卷烟审计数据的长时间关联特征。将本文方法应用于湖北省卷烟业务平台,实现了面向卷烟审计数据的高效、准确分析,为大型省级卷烟业务平台提供了跨业务系统的高效审计业务数据分析解决方案。后续将继续关注稀疏审计数据集的分析问题,设计适用于稀疏审计数据的高效数据挖掘分析方法。
