融合语义解析的知识图谱表示方法
2022-12-15胡旭阳王治政孙媛媛林鸿飞
胡旭阳 王治政 孙媛媛 徐 博 林鸿飞
(大连理工大学计算机科学与技术学院 辽宁大连 116024)(huxy912@163.com)
伴随进入“大数据”时代,网络中的数据呈指数增长[1].互联网的信息结构多样,多数以HTML格式承载,使用者只能从网页中搜寻自己需要的内容信息,但计算机无法有效地从网页中识别语义信息,数据难被高效利用.于是,“互联网之父”Berners等人[2]提出语义网(semantic Web)的概念,即将万维网中HTML格式链接的网页转化为可被计算机处理的数据链接,将现实世界中的万物联系起来.其中信息以资源描述框架RDF[3](主体-谓词-客体的三元组形式)描述,统一的格式便于计算机处理.随之谷歌提出知识图谱(knowledge graph, KG),其本质是语义网络的知识库,将其用于网页搜索,可从语义层次理解需求,使搜索准确率提高[4].
图谱以图模型可视化地描述了现实世界中信息的关联,继提出概念后,构建和应用知识图谱得到了高速的发展.涌现出大量的开放知识图谱,如WordNet[5],DBpedia[6],NELL[7],YAGO[8],Freebase[9]等.知识图谱揭示了知识的发展规律,并应用于实际任务,如在语义解析[10]、实体消歧[11]、信息提取[12]和问题回答[13]等多个领域均发挥出越来越重要的作用.
尽管知识图谱在结构化表示数据方面很有效,但是这种表示方法由于RDF或类似标准的符号特性需要针对不同的符号设计不同的模型,复杂度高,通用性差、计算效率低.并且知识图谱包含信息极大,符号的表示方法无法缓解数据稀疏性,占用空间大.
近年来,深度学习[14]的迅速发展引起人们广泛的关注,通过表示学习建模在许多方面表现出优越的性能.为解决由知识图谱符号表示所带来的问题,研究人员提出一个新的研究领域——知识表示学习[15],针对知识图谱建模的表示学习也称知识图谱嵌入[16].其核心是在向量空间中建模知识图谱,将符号形式的三元组表示为低维的向量形式,同时保留知识图谱原有的结构.嵌入向量可进一步应用于各种下游任务,如知识图谱补全[17]、关系提取[18]、实体分类[19]和实体解析[20].这种方法具有以下优点[15]:1)便于计算分析;2)融合异质信息[20];3)解决数据稀疏[15,20].
目前,知识图谱表示学习方法大多是仅根据三元组来进行的.即,在向量空间中表示三元组中的实体和关系,并对每个三元组定义一个评分函数衡量其存在的合理性.实体和关系的表示(嵌入)通过最大化三元组的合理性来获得.但这种方法得到的向量表示仅与每个三元组结构有关,而不相连实体之间的隐含关系.因此,得到的向量表示不够准确,对下游任务的预测精度有限[21].为此,研究人员提出融合多源信息进行知识图谱表示学习,如实体类别[22]、关系路径[23]、文本描述[24]、逻辑规则[25]信息等.
由于在给定数据时,不同类型的实体和关系通常均带有文本描述,即一段描述实体或者关系的文字,其文本描述中可能含有复杂的隐藏路径关系.比如给定三元组(中国,首都,北京)、(中国,城市,上海)以及北京的一段描述“北京是中国一座城市,也是中国的首都”,通过这段关于北京的文本描述可以推断出(中国,城市,北京)这样隐含的关系路径.为挖掘更深层次的信息,建模利用的信息更加丰富,更好地学习嵌入,本文旨在将带有复杂语义信息的知识图谱嵌入到低维向量中,以达到知识表示学习的目的,并在具体的下游任务中取得显著效果.
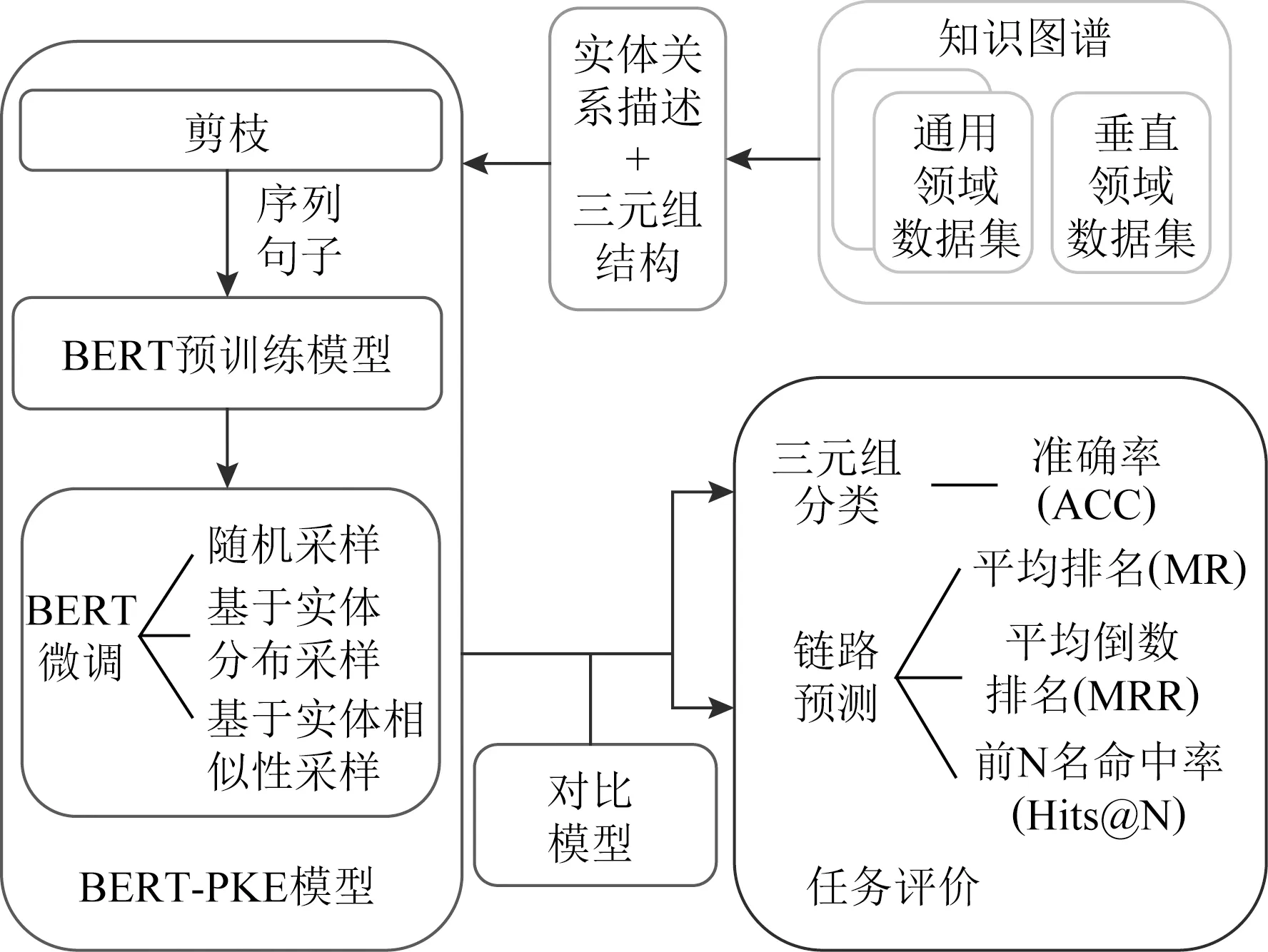
Fig. 1 The research framework图1 研究内容框架
为得到准确的知识图谱表示,本文提出一种融合语义解析的知识图谱表示学习模型.如图1所示,将BERT用于图谱表示学习中的语义解析,提出表示模型BERT-PKE.将事实三元组的实体和关系的结构和文本描述信息以序列形式输入BERT,通过训练解析语法,将嵌入转化为序列分类问题,通过对下游任务的微调,得到三元组的向量表示并预测三元组和链路的合理性.在多数现有算法的训练中,采用随机负采样方法,生成的负样本是明显的错误样本,很容易通过实体类型区分.因此,本文提出尽量“替换同类实体”的负采样方法——基于实体分布和实体相似度进行采样,生成高质量的负样本用于模型的训练,使模型的训练效果更好.此外,由于BERT计算成本过高,在训练和测试中,解析文本描述微调更新词表花费的时间过长.因此本文提出一种改进策略,将文本描述进行剪枝处理,生成实体和关系的精简文本描述集合,缩短训练时间且性能与原模型基本相同.在构建模型后,将BERT-PKE模型与先进的知识图谱嵌入模型进行调试比较,测试并分析三元组分类和链路预测中的评价结果.经过实验验证,BERT-PKE模型和提出的改进策略在三元组分类和链路预测任务中提升效果显著.
1 相关工作
近年来,知识图谱表示学习研究蓬勃发展,根据研究者利用的信息结构,可分为使用事实三元组建模和融合其他信息建模[26]的知识图谱表示学习模型.
1.1 基于事实三元组的知识图谱表示学习
基于事实三元组的知识图谱表示学习仅根据观察到的事实三元组来执行嵌入任务,将其进行向量表示,向量可用于其他下游任务.模型有3个要点:1)表示形式,实体通常表示为目标空间中的向量,而关系通常表示为目标空间中的操作,如向量、矩阵和高斯分布等;2)得分函数,衡量三元组存在的可能性,其得分越高,三元组在图谱中出现的概率越高;3)优化方法,通常使用梯度下降的方法优化求解.基于事实三元组得分函数定义不同,又可分为基于距离的模型、基于语义匹配的模型[16]等.
1.1.1 距离模型
距离模型学习实体和关系表示,将三元组存在的合理性建模为三元组内部隐含的距离[27].给定一个知识图谱,实体首先被投影至低维向量,然后将关系投影为实体之间的平移或旋转算符,通常表示为向量或矩阵.继而,每个三元组通过2个实体之间的距离评价函数来衡量三元组存在的合理性.合理的三元组往往具有较低的距离值.如TransE[17],TransH[28],TransR[29],TransD[30],RotatE[31].
1.1.2 语义匹配模型
语义匹配模型通过相似性得分函数来学习向量表示的三元组特征,通过张量分解的形式,计算潜在语义相似度并衡量三元组存在的合理性.如RESCAL[21],DistMult[32],HolE[33],ComplEx[34-35],ANALOGY[36],SimplE[37].
1.2 融合多源信息的表示学习
融合多源信息的表示学习除了三元组结构信息外,还通过利用外部资源学习知识图谱的嵌入表示,如实体类别、文本描述、关系路径等.为融合实体类别的信息,语义平滑嵌入模型SSE[22]利用嵌入限制、强正则化约束实体和关系,提出平滑性假设并分别使用2种流形学习算法构建模型.为融合实体和关系的语义信息,融合实体描述的知识表示模型,DKRL[38]利用连续词袋和卷积神经网络学习实体和关系中的语义信息,将语义信息和三元组的结构信息一起进行TransE训练,用改进后的TransE模型学习更深层次的嵌入表示.为融合关系路径的信息,基于关系路径的翻译模型PTransE[39],为特定头实体向量到特定尾实体向量之间途径的所有的实体和关系定义关系路径向量,从而可以利用多个关系中包含的语义信息,建模利用的信息更加丰富,能更好地学习嵌入.
2 融合语义解析的知识图谱表示模型
知识图谱是一种复杂图结构,除三元组之外,还有其他可利用的信息,如上下文、句法和语义信息,这些信息可从更深层次刻画实体和关系的关系,却被以往仅仅依据事实知识的嵌入方法所忽视.其中,实体和关系的文本描述就是一个值得解析利用的信息.
将知识图谱中的三元组视为文本序列,提出了一种融合语义解析的知识图谱表示框架——基于BERT[40]模型的剪枝图谱表示模型BERT-PKE.给定知识图谱,首先将实体和关系的文本描述进行剪枝处理.然后,将三元组和文本描述转化成序列结构输入BERT模型中.最后,利用预训练语言模型BERT对三元组以及实体和关系的描述进行语义解析,得到嵌入模型.在训练过程中,负样本的构造可影响模型的学习.因此,提出2种改进经典方法生成负样本的方法,改变负样本的采集方法来增强模型学习的能力.
2.1 BERT-PKE模型结构
由于BERT[40]可解析深层次的语义信息,因此在融合语义解析的知识图谱表示方法中,本文采用BERT来进行语义解析,输入多层Transformer[41]结构,使用自注意力机制联合所有层的上下文来训练未标注文本,得到深度双向表示,实现图谱嵌入.由于BERT是处理自然语言的模型,只能处理序列结构的句子,图结构无法直接输入.因此BERT-PKE模型参考KG-BERT[42]模型中的输入方法,将三元组结构和文本描述作为文本序列输入预训练语言模型BERT,将描述实体和关系的词序列作为BERT模型的输入句进行微调,然后通过某种训练得到三元组的表示.
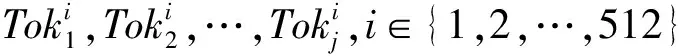

Fig. 2 The overall framework of BERT-PKE图2 BERT-PKE模型整体框架
输入词标记i对应的输入向量表示Ei输入到BERT模型架构中,该架构是基于Transformer的双向结构.在隐藏词字机制MLM任务中,特殊词标记[CLS]和第i个输入词标记中的隐藏向量记为C∈H和Ti∈H,其中H为预先训练BERT中的隐藏块大小.与[CLS]对应的最终隐藏块输出C被用于计算三元组的序列表示得分.微调过程中引入的唯一参数W∈2×H,表示输出层的权重.三元组(h,r,t)的得分函数为
sτ=fr(h,t)=sigmoid(CWT),
(1)
其中权重矩阵W与C相乘之后可获得三元组是正确的概率sτ,sτ∈2是2维实向量,且sτ0,sτ1∈[0,1]且sτ0+sτ1=1.
在给定正三元组集合D+和相应构造的负三元组集合D-,我们用sτ和三元组标记计算交叉熵损失:
(2)
其中yτ∈{0,1}是标记该三元组是正例还是负例的标签,即标记是正三元组还是负三元组,而正三元组表示的是正确的三元组,负三元组表示的是错误的三元组,负样本需要我们进行负采样构造.
负采样方法可影响模型的预测能力,在2.2节中我们将给出详细介绍.通过梯度下降的方法,可以更新预先训练好的参数权值和新的权值W.
2.2 负采样方法
负采样的目的是帮助模型进行特征学习训练,最终输出正样本.正样本在损失函数学习过程中保留,同时不断更新负样本.通过负采样,在更新隐藏层到输出层的权重时,只需更新负样本而不用更新全部样本,节省计算量.因此负样本的采集质量影响了模型的构建.本文通过负采样的方式降噪,对样本集的正三元组进行负采样,生成的负样本用于计算损失函数.
在现有的知识图谱表示模型中,负采样大多从实体集中随机抽取进行替换,采用这种负采样方法生成的负样本随机且质量较低.这样会带来产生伪标签和模型无法准确地学习训练2个问题.针对问题,提出2种改进的负采样方法,分别是基于实体分布的负采样方法和基于实体相似度的负采样方法.通过后续试验证明方法的效果.
2.2.1 随机抽样的负采样方法
虽然融合语义解析的知识图谱表示方法在实现知识图谱表示学习上有了进一步的突破,但是现有的嵌入模型中普遍存在一个问题,即模型在梯度下降训练中,负三元组集合D-仅仅由实体集合中随机抽取一个实体h′或t′,从正三元组(h,r,t)∈D+中替换相应的h或t得到的,即
D-={(h′,r,t)|(h′∈E)∧(h′≠h)∧
((h′,r,t)∉D+)}∪{(h,r,t′)|
(t′∈E)∧(t′≠t)∧((h,r,t′)∉D+)},
(3)
如果三元组已经在正集D+中,则不会被视为反例.
通过梯度下降的方法,负样本更新预先训练好的参数,因此采样的负三元组质量影响了模型的学习和向量的表示.例如,给定三元组(中国,首都,北京)经过随机负采样生成后的三元组可能为(中国,首都,足球),该三元组质量低,对训练过程中参数的更新没有显著帮助.这种采样方法被称为unif[17]采样,最初在TransE模型中被提出.由于知识图谱数据集中的信息是有限的,通过随机采样产生的负样本可能构造出正三元组,却被当作负样本本来处理,引入伪标签.图3是正、负三元组的举例说明.鉴于负采样的基本作用和现有方法的局限性,本文将重点放在负采样上,旨在提高负样本的质量.
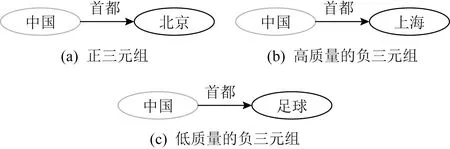
Fig. 3 Examples of positive and negative triples图3 正、负三元组举例
2.2.2 基于实体分布的负采样方法
根据TransH中提出的方法,以不同概率按照实体分布来选择替换三元组的头实体或尾实体,可依据伯努利分布提出bern[28]采样.本文针对1_to_N和N_to_1类型的三元组,如果是1_to_N三元组,则更大概率破坏头实体h;如果是N_to_1三元组,则更大概率破坏尾实体t,这样就减少了产生伪标签的机会.图4分别展示了不同关系类型下,基于实体分布的bern负样本生成过程.
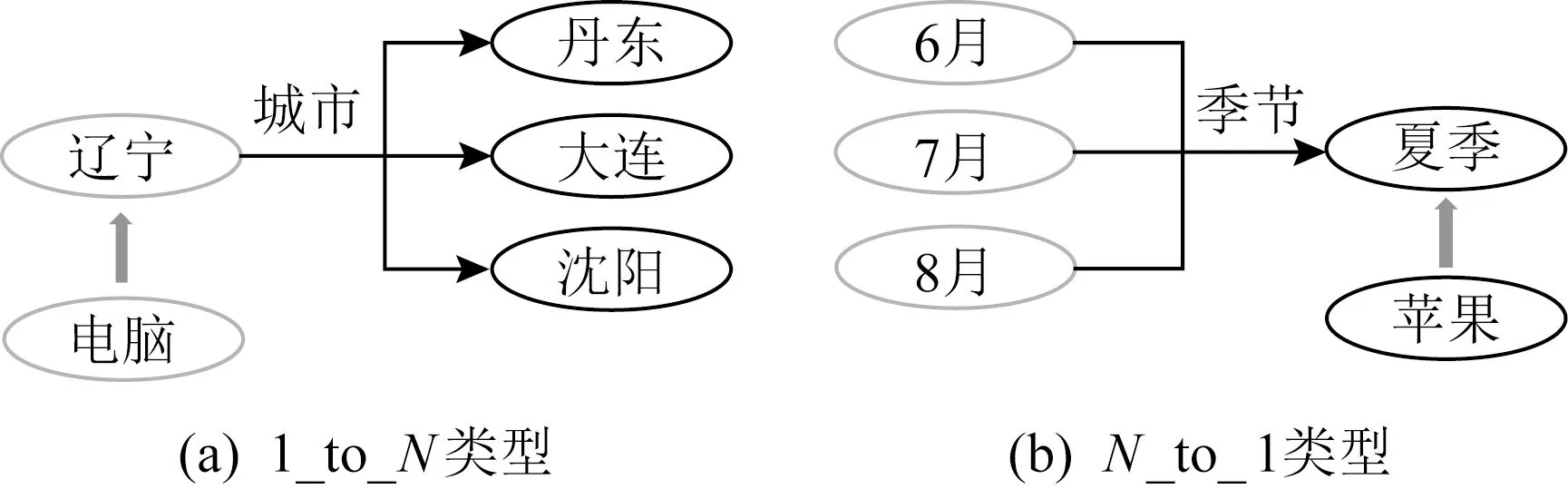
Fig. 4 Bern negative sampling图4 bern负采样
对于知识图谱中的每个关系r,首先得到以下2个统计量:1)头实体对应的平均尾实体的数,记为tph;2)尾实体对应的平均头实体数,记为hpt.然后为采样定义一个伯努利分布,其参数为
(4)
则替换头或尾实体,服从参数为p的伯努利分布,有

(5)
则X的分布律为
P(X=x)=px(1-p)1-x,x∈[0,1].
(6)
对于与关系r相关的正三元组(h,r,t),替换h构造负三元组的概率为p,替换t构造负三元组的概率为1-p.
2.2.3 基于实体相似性的负采样方法
基于实体分布的负采样方法虽然能够减少了产生伪标签的可能性,但替换实体仍需从整个实体集中选择,生成的三元组质量不佳,对训练过程中的特征学习帮助不大.本文希望替换的实体与原实体语义相似,因此提出一种基于实体相似性[43]的负采样方法,进一步改进2.2.2节中基于实体分布的负采样方法.该方法先使用TransE将实体表示成m维向量将相似性问题简化,然后用k-means[44]聚类将实体向量划分为k类.在负采样时,正三元组的实体用同类实体进行替换,通过这种负采样方法来提升知识图谱嵌入的质量.图5分别展示了1_to_N和N_to_1类型的k-means负样本生成.
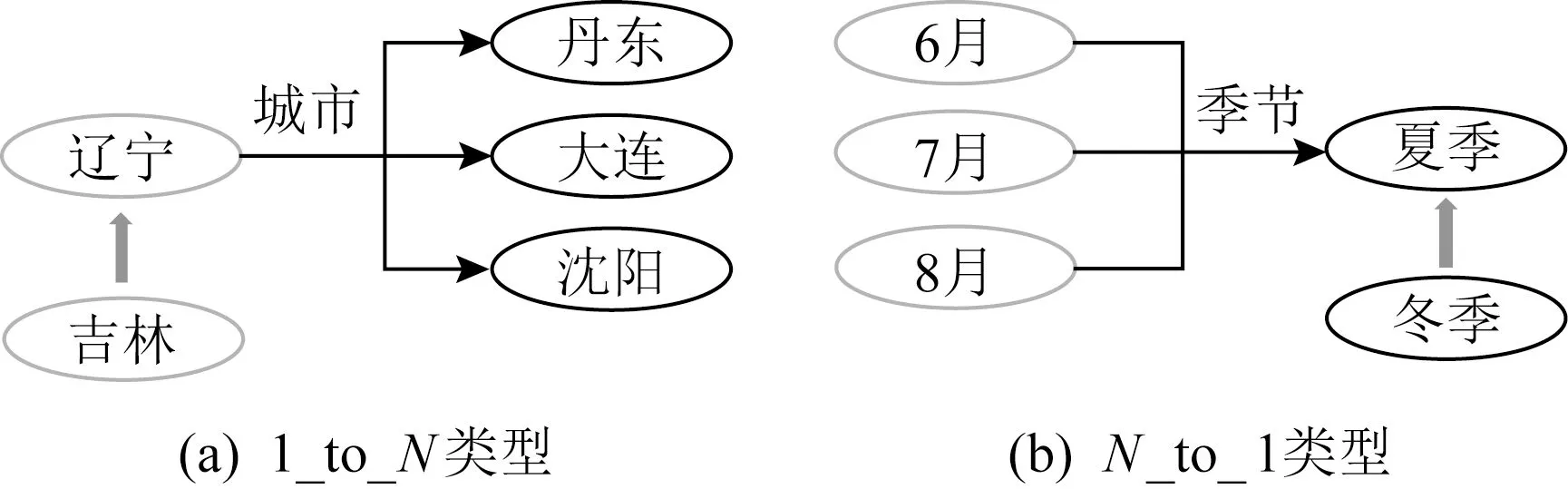
Fig. 5 k-means negative sampling图5 k-means负采样
首先,本文使用TransE将实体和关系表示成m维向量,将实体的语义结构相似问题简化为向量距离相近问题.给定三元组(h,r,t),TransE模型都有h+r≈t.因此在向量空间中,头实体h被t-r限制.同理,尾实体t和关系r分别有h+r和h-t限制.因此,不同三元组中同一个头实体在不同关系和尾实体的限制是相同的,即三元组(h1,r1,t1)和(h1,r2,t2)中有t1-r1=t2-r2.因此若2个实体相似,则其在空间中的限制也相似,表明在空间中2实体的向量坐标越相近,距离越小,则实体越相似.
在得到实体和关系的嵌入向量后,使用k-means算法对实体向量进行无监督的分类.首先,在实体向量集合{x1,x2,…,xn}∈m中选择初始化的k个样本作为初始聚类中心{μ1,μ2,…,μk};然后,针对实体向量集中每个实体向量xi所属的聚类中的所有点到聚类中心的欧氏距离之和最小,对于每个向量xi,计算其应该属于的类:即
(7)
其中,ci表示样本xi与k个距离中心最近的类.arg是表明样本归于哪个类的运算符.然后,对于每个类中心μj,重新计算该聚类的中心
μj
(8)
不断重复划分类ci和更新聚类中心μj这2个操作,直到达到聚类的中心不变或者变化很小,其损失函数为
(9)
通过k-means聚类算法,本文认为属于同一个类别的实体相似度高,可相互替换生成负样本.基于实体相似性的方法在一定程度上提高了负样本的质量,使表示模型的性能得到了提升.
2.3 剪枝策略
BERT模型的一个主要局限性是代价太过于昂贵,在学习模型表示的过程中需要将句子的每个词输入多层Transformer结构中进行嵌入训练;在测试模型的过程中更是耗费大量时间;在链路预测评估需要遍历所有的实体替换头实体或尾实体,并且所有负三元组序列都被输入到12层Transformer模型中.由于序列中文本描述通常为一段话,在50词以上,过于冗长,包含一些无用信息,如标点、谓词、系动词等.
为尽可能正确嵌入训练样本,每个样本句子的词标记的学习过程将不断重复,有时词标记形成的分支过多,这时就有可能把训练集学习得太好,以至于把训练集的某一些特点当成所有数据都具有的性质,这时就发生了过拟合.因此,针对BERT模型的局限性,本文将实体和关系的文本描述进行剪枝处理,对冗余的文本描述进行修剪,从而避免嵌入不必要的操作和搜索,更快地获得更好的效果.
本文使用基于词频[45](term frequency)和k近邻[46](k-nearest neighbor)的技术.首先,TF表示的是某个词在文本中出现的次数,即词频,其公式为
(10)
对于词频统计的具体做法,本文采用N元语法模型(N-gram),N-gram是一种基于统计语言模型的算法.将描述文本中的单词按字节进行大小为N的滑动窗口操作,形成字节片段序列.每个片段称为gram,对所有gram的出现频度进行统计,并且按照阈值过滤,形成文本的向量特征空间.
在N-gram中,第N个词的出现只与前面N-1个词相关,与其他任何词都不相关,整句的概率就是各个词出现概率的乘积.这里只需要获得各个词出现的词频.本文取N=1,2,3.其中,当N=1时,称为一元语法模型(unigram model),即当前词的概率分布与给定的历史信息无关,它将文本描述分成单词,统计单词出现的词频;当N=2时,称为二元语法模型(bigram model),即当前词的概率分布只与距离最近的词有关,它将文本描述中所有2个词组成一个词组,统计词组出现的词频;当N=3时,称为三元语法模型(trigram model),即当前词的概率分布与距离最近的2个词有关,它将文本描述中的所有相邻3个词组成1个词组,统计词组出现的词频.
k近邻表示的是一个样本附近的k个最近,即特征空间中最邻近样本,文本是1维表示,则其最近邻的度量方式为曼哈顿距离,即
L(j,k)=|j-k|.
(11)
因此,本文在剪枝过程中抽取实体和关系名称的前后k跳词语,并抽取除名称、标点、量词、系动词以外出现词频较高出现的词或词组(可以为多个),然后组成一个由逗号分隔、由词语组成的实体和关系的文本描述集合.通常,剪枝后的模型精度稍微有所下降,但相比节省了大量的时间空间,精度基本与原来持平或稍稍下降的误差完全可以忽略.
3 实验设置及结果
本文选用垂直领域数据集UMLS[47],通用领域数据集FB14K-237和WN18R.其中FB14K-237由FB15K-237[48],WN18R由WN18RR[48]预处理得到,具体信息如表1所示:
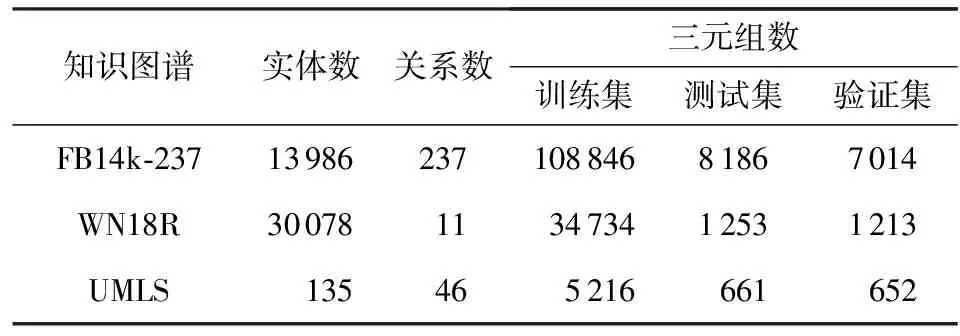
Table 1 The Information of Data Sets
在完成嵌入后,将嵌入的向量应用于不同的下游任务中,本文的下游任务为三元组分类和链路预测[49-52].并采用准确率(ACC)作为评价指标用于衡量三元组分类的效果,采用平均排名(MR)、平均倒数排名(MRR)和正确实体排在前N名的概率(Hits@N)作为评价指标用于衡量链路预测的效果.
三元组分类的目的是判断三元组(h,r,t)中实体和关系是否正确匹配,本文将各个模型运行3次并取其平均值,表2给出了FB14k-237,WN18R,UMLS在不同模型上的三元组分类任务的准确率.
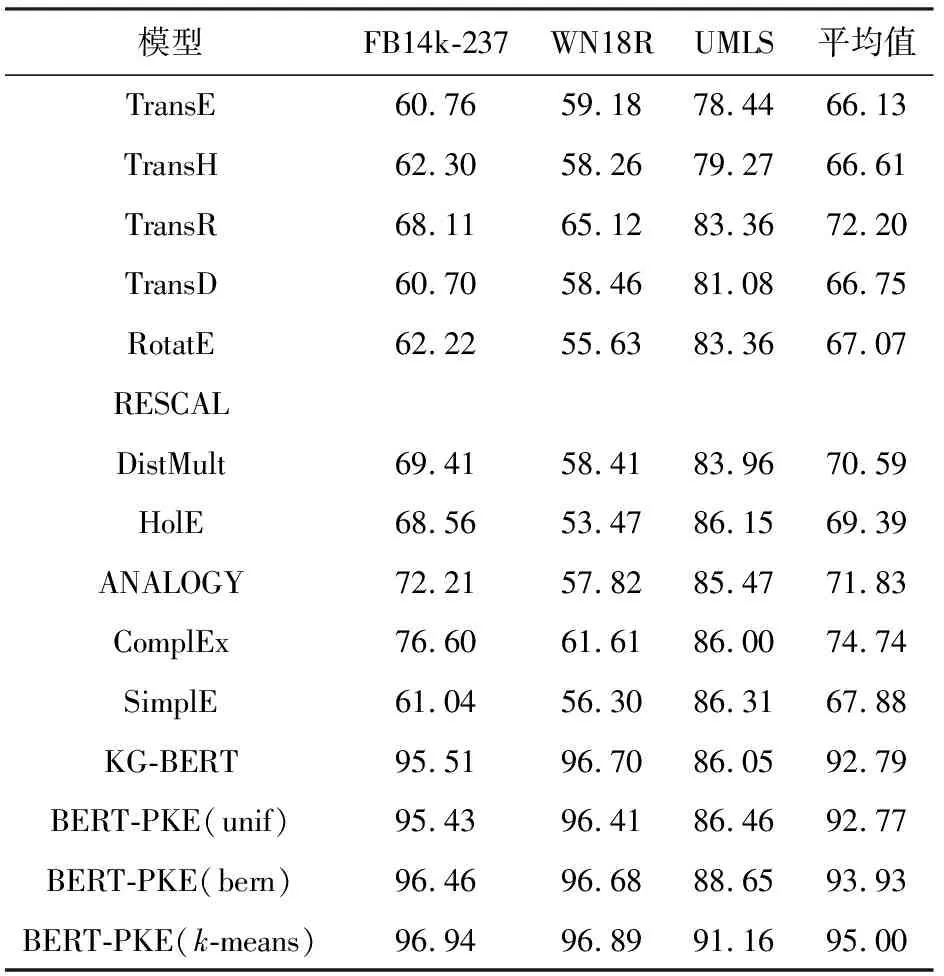
Table 2 ACC of Triplet Classification
如表2可得,所提出BERT-PKE模型在三元组分类任务上的准确性显著高于所有基准模型,和KG-BERT原型基本相同,证明了本文提出方法的有效性.所提出的剪枝策略改进的BERT-PKE模型与原模型KG-BERT的准确率相差不多,但训练时间却大大缩短.以FB14k-237数据集为例,KG-BERT算法中词标记有4 920 563个,迭代1次需要25 h,而BERT-PKE算法中词标记只有20 409个,迭代1次只需要1.5 h,而在模型学习过程中需要多次迭代,时间代价成倍数增长.在通用领域数据集WN18R、FB14k-237上,其准确率均高于95%,且采用剪枝策略相差不超过0.3%,在垂直领域数据集UMLS上准确率甚至高于KG-BERT模型.因此可以看出,剪枝策略可显著节省模型训练的时间和空间.同时,提出基于实体分布负采样和基于实体相似性负采样负采样改进方法,在3个数据集上,这2种负采样都能使得BERT-PKE模型的性能得到提升.并且基于实体相似性(k-means)的负采样方法在基于实体分布(bern)的方法基础上提出,其准确率也更高.通过实验,证明负采样在模型训练中的重要影响,也证明本文改进采样方法的成效.
链路预测的目的是判断三元组(h,r,t)在已知其中关系和其中一个实体的情况下预测的另一实体是否正确.表3~5中给出不同数据集下不同模型的链路预测结果.

Table 3 Link Prediction Results of UMLS
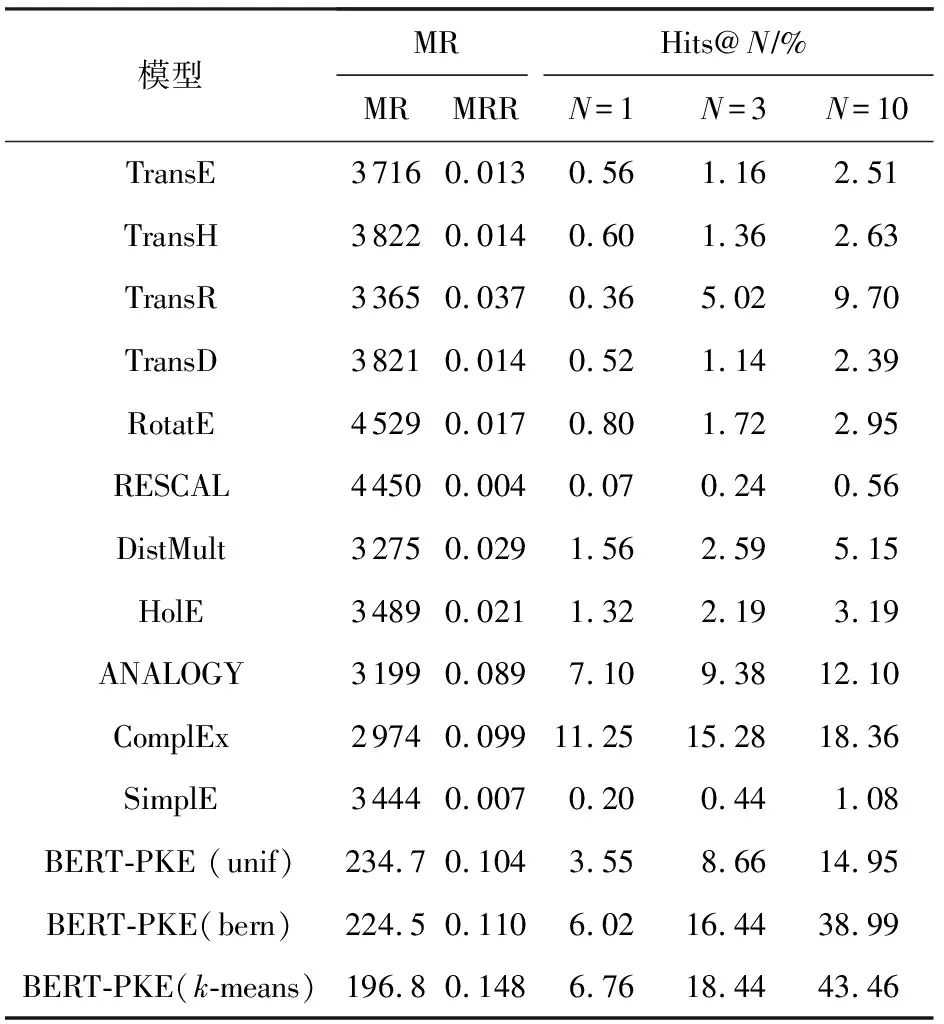
Table 4 Link Prediction Results of WN18R

Table 5 Link Prediction Results of FB14k-237
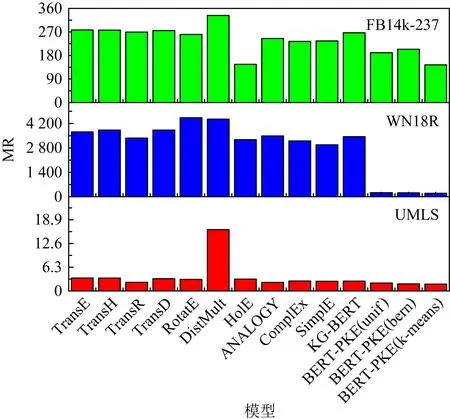
Fig. 6 MR of link prediction图6 链路预测的MR
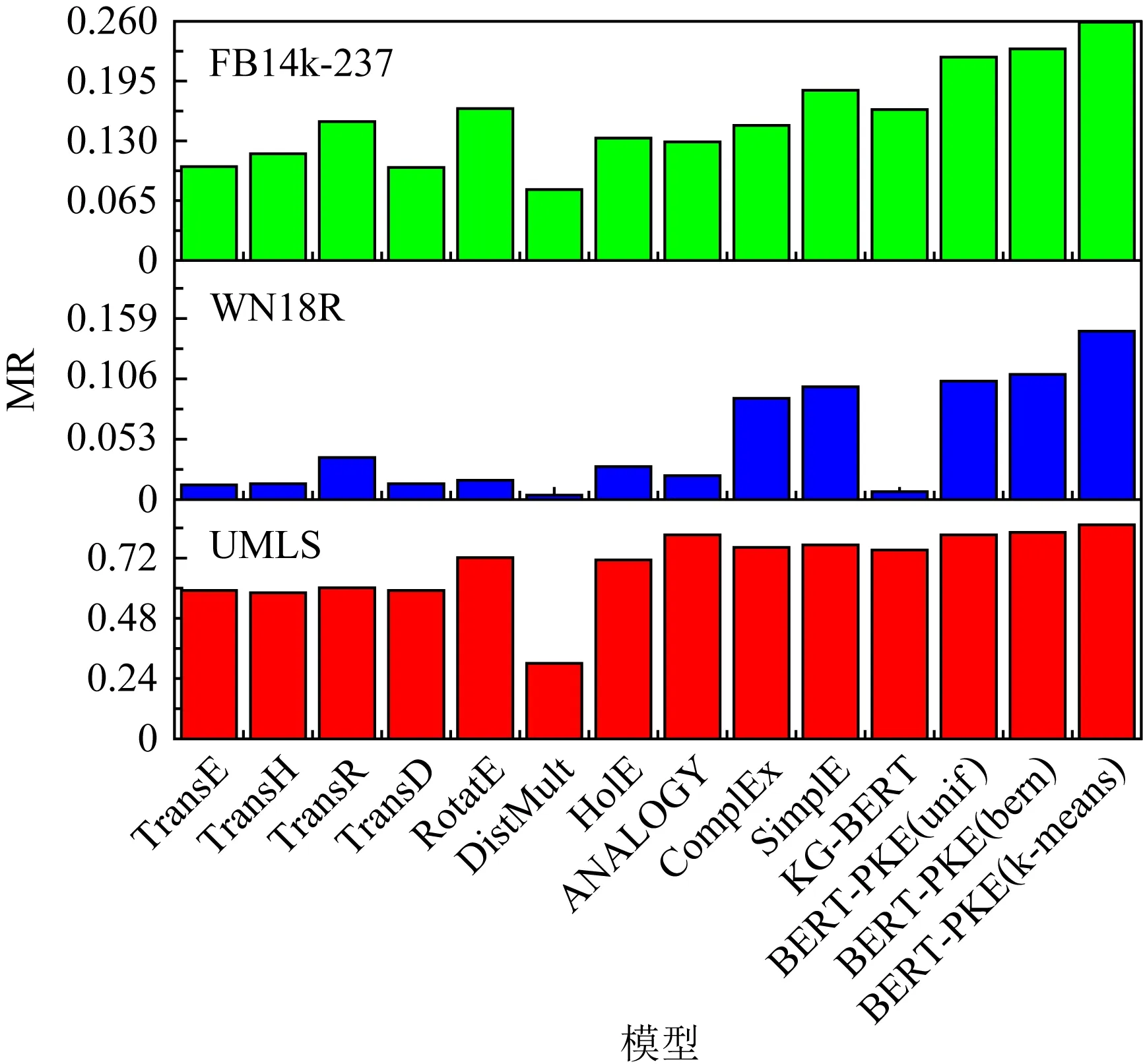
Fig. 7 MRR of link prediction图7 链路预测的MRR
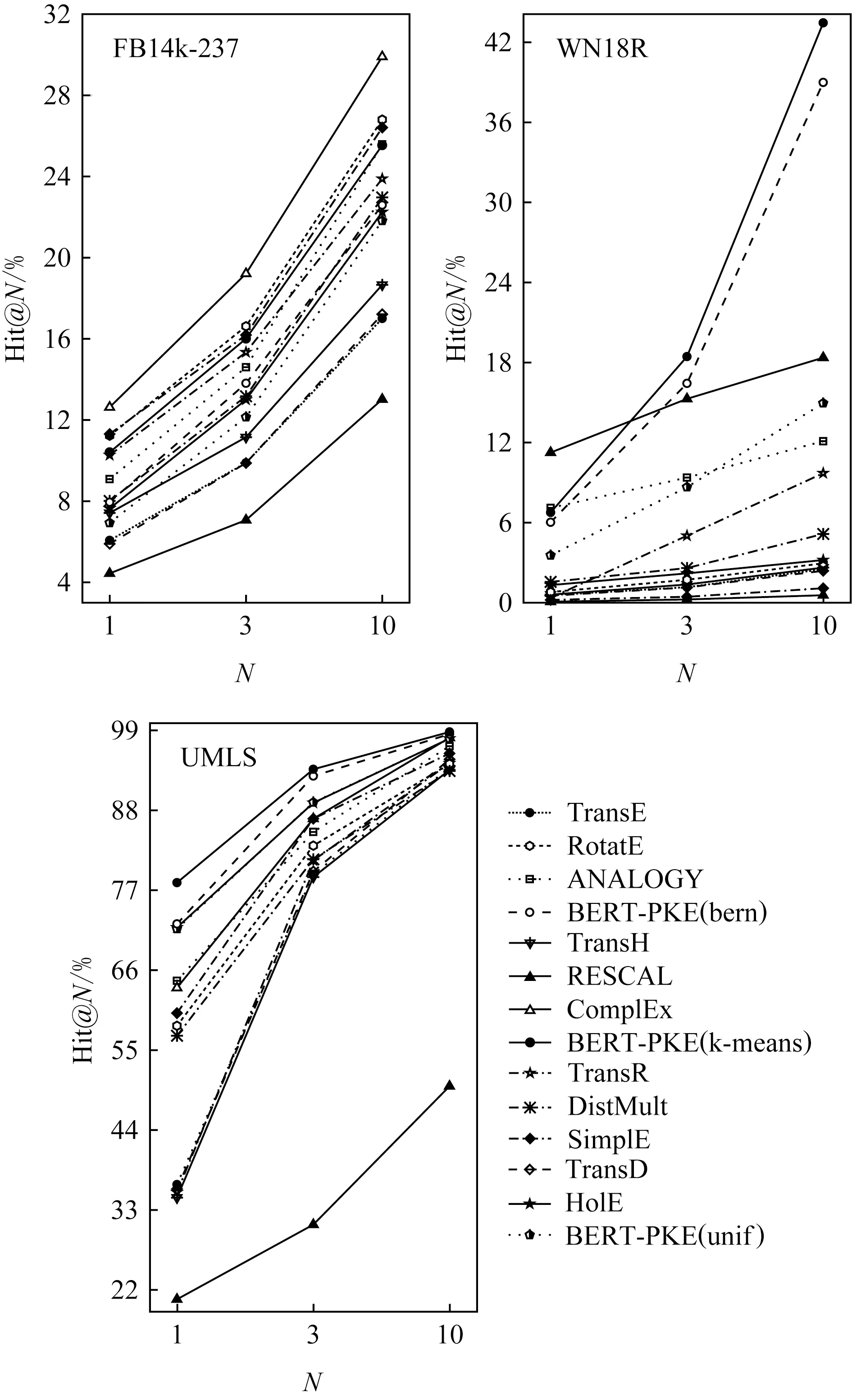
Fig. 8 Hits@N for top 1,3,10 of link prediction图8 链路预测的前1,3,10名命中率
通过表3~5以及可视化图6~8上的结果,可以总结出:1)3种BERT-PKE模型的MR值均比基准模型的MR值更低,MRR值更接近于1,并且提升较为明显.且采用基于实体相似性和实体分布的负采样策略也有明显的提升效果.2)3种BERT-PKE模型中有一小部分负采样方法中的Hits@N值低于一些最先进的方法,如ANALOGY,ComplEx;但采用改进负采样策略的BERT-PKE模型的Hits@N值较随机负采样方法相比有明显提升.这是由于BERT-PKE模型没有对知识图谱的整体图结构信息进行准确建模,从而无法使得实体和关系描述的语义相关度很高,因此不能将给定实体的某些邻居实体排在前10位.通过基于实体分布和实体相似度的负采样改进方法可提高Hits@N值、判断实体关系的种类、并通过TransE预先得到实体相似度分布、然后进行归类,该方法都对图结构有一些整体把握,因此可提升模型的性能.由此可得,负采样策略可提升知识图谱表示学习的能力,并且通过剪枝策略,可大大缩短模型训练和测试的时间,如FB14k-237数据集,剪枝前迭代一次需要25 h,剪枝后只需要1.5 h;剪枝前测试匹配一个实体需要8 min,而剪枝后只需要50 s.
4 结 论
本文提出一种融合语义解析的知识图谱表示模型——BERT-PKE,该模型将BERT用于语义解析,提出基于词频和k近邻的剪枝策略以缩短训练时间.此外,提出2种负采样策略,基于实体分布的负采样方法可减少伪标签产生;基于实体相似性的负采样可通过同簇实体的替换提高负三元组质量,帮助特征训练.本文填补了已有表示模型中挖掘文本描述深度关联的空白.此外,本文还将BERT模型应用于知识图谱补全任务.未来的研究方向包括通过图结构联合建模等.将BERT-PKE模型作为一种知识增强语言模型应用于语言理解任务是我们未来要探索的一项工作.
作者贡献声明:胡旭阳设计了算法思路和实验方案,完成了所有实验以及文章撰写;王治政参与设计了算法实验、论文架构并完成了实验分析;孙媛媛指导了论文思路,对实验提出指导意见并修改论文;徐博参与了论文想法的讨论,对于实验方案提出指导意见并完善论文内容;林鸿飞负责提出选题并确定论文框架.
