胖树拓扑中高效实用的定制多播路由算法
2022-12-15陈淑平何王全漆锋滨
陈淑平 李 祎 何王全 漆锋滨
(江南计算技术研究所 江苏无锡 214083)(chenshuping_hit@163.com)
在高性能计算领域,多播路由算法对硬件支持的集合操作性能具有至关重要的影响.例如,集合通信中的Bcast,Barrier,AllReduce,AllGather等操作均可通过多播进行加速.多播路由算法通过构建多播树实现.过去主要研究如何降低树高、如何提升路由负载均衡程度.目前高性能计算已经迈入E级计算时代,系统中多播组的个数急剧增加,可能会超过硬件支持的多播表条目数,而现有的多播路由算法要么没有给出解决方案,要么存在时间开销大、多播路由经常变化等问题.为此,本文提出一种用于胖树的高效实用的定制多播路由算法(customized multicast routing for limited multicast forwarding table size, C-MR4LMS),可用于包括Infiniband在内的高速互连网络.本文主要贡献包括:
1) 对胖树结构中可使用的无冲突多播生成树个数进行了量化研究,根据系统中的最大多播组个数确定多播表的大小,为设计互连网络系统提供了理论依据.
2) 提出了一种用于胖树拓扑的高效实用的定制多播路由算法C-MR4LMS,可根据MGID(multicast global identification)静态地将多播组映射到1棵生成树中,快速完成多播树的构建;当需要合并多播组时,仅需合并那些使用同一生成树的多播组,且仅需添加部分链路即可完成多播组的合并,不会改变被合并多播组的路由,因此不会影响这些多播组的正常使用.
3) 提出了分层的MGID分配策略,当同一终端节点同时加入多个多播组时,每个多播组都使用不同层内的MGID,避免出现同一终端节点使用同一颜色加入多个多播组的情况.
4) 提出了相互无干扰的作业节点分配策略,使得2个作业不共用任何通信链路,保证2个作业的多播组互不干扰.
5) 在多种典型拓扑结构及典型通信模式下对C-MR4LMS的链路EFI、TFI、运行时间及应用程序性能等进行了测试,验证了其有效性.
1 研究背景及相关工作
集合通信[1-4]为实现一组进程间的通信提供了非常方便的抽象,被广泛应用于高性能计算领域.它包括同步、广播、规约、全规约、分散、收集、全收集等类型及其变体,可实现多个进程间的同步、数据分发与收集等功能.传统的集合通信一般是由软件利用点到点消息实现的.但随着系统规模的不断扩大,超级计算机对集合通信的性能及可扩展性都提出了更高的要求,而软件集合通信难以满足E级系统的需求.硬件集合通信可将集合操作卸载到网络设备中进行,具有良好的性能及可扩展性,已成为高速互连网络领域的研究热点.近几年出现了很多硬件集合通信技术,如Mellanox的SHARP技术[5],神威互连网络的硬件集合通信等[6].
硬件支持的集合操作中,多播技术是重要的支撑.集合通信中的Bcast,Barrier,AllReduce,AllGather等操作需要将相同的数据分发给参与集合通信的不同进程,它们均可利用硬件多播进行加速.因此多播路由的性能对这些集合操作具有重要影响.
目前的多播路由算法[7-12]均是为每个多播组构建1棵多播树.用户每创建1个多播组,就需要构建1棵对应的多播树,并占用多播路由表的1个条目号.而多播表大小是有限的,随着系统规模的不断扩大,多播组的个数会急剧增加,可能会超过硬件支持的多播表条目数.而现有的多播路由算法要么默认多播表条目数是够用的,因此没有给出多播表条目数不足时构建多播表的方案;要么针对拓扑未知的网络,存在时间开销大、多播路由经常变化等问题.本文在胖树结构下研究面向有限多播表条目数的多播路由算法.
1.1 基本概念
定义1.互连网络.互连网络定义为一个有向图I=G(N,L),其中N为网络节点集合,L为通信链路集合,网络节点又分为终端(一般是网卡设备,用于收发数据)及交换机(用于转发数据).
定义2.多播组.多播组(multicast group, MCG)是网络节点集N的一个子集,其成员一般是终端节点.
多播组对应MPI中的1个通信域,用全局唯一的MGID标识.它不仅用于多播操作,还可用于包括同步、全局规约等在内的其他集合操作.例如,神威互连网络中,硬件全局规约可通过多播组将规约结果广播给所有成员.
定义3.多播路由.从单个交换机的角度看,多播路由可定义为如下映射R:L×M→2L,其中M为MGID集合.该映射的输入参数为输入链路lij及多播组MGID,返回值为输出链路列表{ljk}.
该定义允许交换机根据不同输入链路选择不同的输出链路.这要求交换机每个端口都有独立的多播路由表.而从全局角度看,多播路由R将多播组MGID映射为I的1棵子树,该子树包含该多播组的所有成员.我们称该子树为多播树(multicast tree, MCT).图1所示的多播组中,阴影所示节点发送多播包时,每到达1个交换机的1个端口,就查询该多播组对应的多播表条目,从而确定将多播包复制到哪些端口进行转发.1个多播组对应1棵多播树,但1棵多播树可供多个多播组使用.
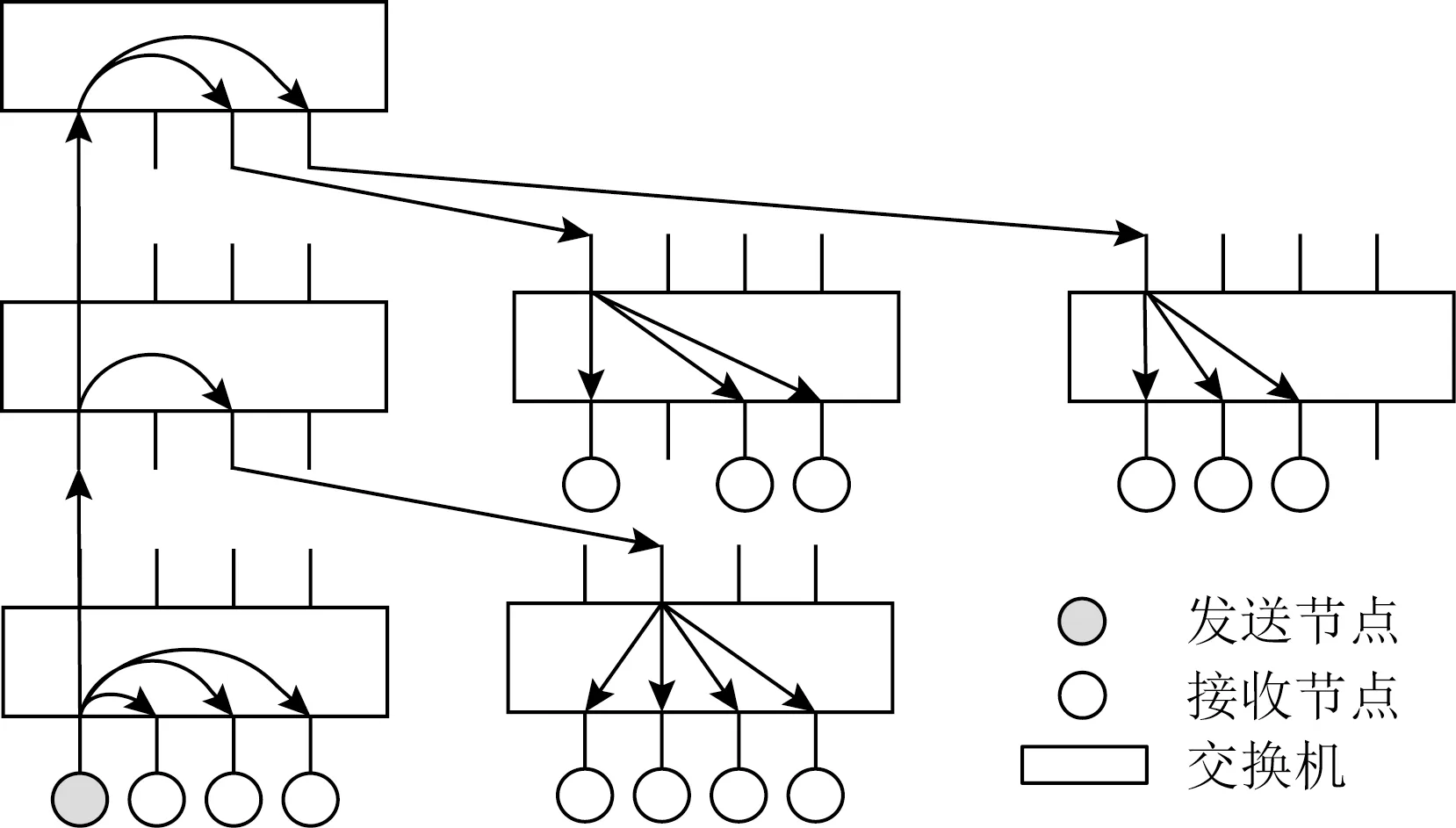
Fig. 1 Illustration for multicast tree图1 多播树示意图
定义4.多播表条目号.交换机多播表有多个条目,以支持不同的多播组,其编号称为多播表条目号.每个条目都是1个位图,指定了需要将数据包复制到哪些输出端口.多播路由除了为每个多播组确定多播树之外,还需要确定该多播树使用的多播表条目号.
在发送多播消息时,MGID及多播表条目号具有不同的作用.用户需同时指定目的MGID及多播表条目号.交换机收到多播包时,根据多播表条目号查找对应的多播表条目,并将多播包通过该多播表条目指定的输出端口转发出去.而终端节点收到多播包后,则根据MGID决定将该包拷贝到哪些通信队列中.
不同厂商支持的多播表条目数不同,例如Mellanox交换机最多可支持16 384个多播表条目,而神威互连网络仅支持32个多播表条目.在不考虑多播表大小的情况下,可以为每个多播组都分配1个不同的多播表条目号;Infiniband即采用该策略,其多播表条目号称为MLID(multicast local identification).而在考虑到多播表有大小限制时,则没有必要为每个多播组都分配1个单独的多播表条目号,2个多播组只要不使用同一条链路,就可以共用同一个多播表条目号,从而大大降低对多播表条目数的需求;神威互连网络即采用该策略,其多播表条目号称为多播链号.
为多播树分配多播表条目号时,必须遵循下列原则:1)同一棵多播树在其使用的所有交换机内使用相同的多播表条目号;2)若2棵多播树经过同一条链路,则这2棵多播树不能使用同一个多播表条目号.将每棵多播树看做图的顶点,只要2棵多播树共用同一条链路,则称这2棵多播树“相邻”,对应的2个顶点间添加1条边.我们将多播表条目号用颜色表示,为“相邻”的多播树指定不同的多播表条目号,也即用不同的颜色染色.后文将用术语“染色”表示为多播树分配多播表条目号.
定义5.EFI(edge forwarding index).文献[13-14]定义了单播路由中的EFI指数.我们对此进行扩展,将每条链路的EFI定义为经过该链路的多播组个数.
链路的最大EFI值反映了拥塞程度,值越大表示拥塞程度越高.最大EFI对多播操作性能具有重要影响,故需要尽量将多播路由均衡分布到不同的链路上,以降低EFI指数.
定义6.TFI(tree forwarding index).对多播树而言,使用该多播树的多播组个数称为该多播树的TFI.
若多个多播组共享1棵多播树,则1个多播组内的多播数据包会复制到其它多播组内,从而造成相互干扰,故TFI实际上反映了多播树中多播数据包的冗余程度.
1.2 现有多播路由算法存在的问题
Infiniband中现有的多播路由算法构建多播树的过程包括:1)选择1个交换机作为多播树的树根,使其到多播组内各成员的平均距离或最大距离最小;2)为多播组的每个成员分别找到1条到达树根的路径,从而完成多播树的构建.需要注意的是,在寻找到达树根的路径的过程中,不能形成环.
现有的路由算法未考虑多播表条目数不够用的问题,它们为每个MGID都分配1个不同的多播表条目号.随着应用规模的不断扩大,多播组的数量也随之快速增大,系统中可能同时存在成百上千甚至数万个多播组,可能会超过硬件支持的多播表条目数,导致多播表条目不够用.
对于多播表条目不够用的问题,一种简单的解决方案是建立1棵超级多播树(神威互连网络中称为全局广播链),使其包含所有终端节点,使所有多播组都使用该多播树进行广播.但该方案存在严重的性能问题:1个多播组发送的数据会复制到整个网络中,造成网络中存在大量无用的多播包;当很多个多播组同时使用该多播树发送消息时,会造成集合操作性能的严重下降.
为此,我们在前期工作中[15]提出了面向有限多播表条目数的多播路由算法(multicast routing for limited multicast forwarding table size, MR4LMS).MR4LMS工作原理为:只要多个多播组不经过同一条链路,就尽量共用同一个多播表条目号;而当n个相似的多播组无条目号可用时,就将它们合并到一起共用同一棵多播树.也即首先尝试让多个多播组共用同一个多播组条目号,如果失败,则尝试让多个多播组共用同一棵多播树.
具体来说,MR4LMS包括2个主要部分.一是采用2种方法来构造多播树,包括:1)在可用颜色数比较充足时,采用先构造后染色算法,以每个备选交换机为树根构造1棵多播树,然后尝试用不同的颜色染色;2)在颜色数不足时,采用先染色后构造算法,先找出可用的颜色,然后在该颜色下构造1棵多播树.二是当上述2种方法都不能构造出多播树时,采用合并算法,将多个多播组合并成1个多播组,从而降低对多播组颜色数的需求.
MR4LMS主要用于拓扑未知的网络,可以显著降低所需的多播表条目数,满足大部分应用创建多播组时的需求.但也存在一些实用性方面的问题,包括:
1) MR4LMS需要进行大量的图遍历操作,时间开销很大,特别是同时创建成百上千个多播组时,很可能出现颜色数不够用的情况,则需要尝试很多交换机做树根,或尝试很多种颜色,此时运行时间可能会超过数分钟.
2) MR4LMS根据系统中已存在的其他多播树情况为新多播组构建多播树,因此对于同一个多播组,在不同时刻构建的多播树很可能是不同的,也即创建出的多播树具有动态可变性.这在实际应用场景中会带来很多问题:①当网络拓扑发生变化而重新计算多播路由时,多播组使用的多播树即使没有使用故障链路,重新计算路由后也很可能会发生变化,从而造成多播路由的频繁变化,影响用户使用;②同一应用在不同时刻运行时,构建的多播树也可能不同,这会带来应用性能的差异,影响用户体验.
3) 当颜色不足而需要合并多播组时,也可能会重构已存在的多播树,从而影响已存在的多播组的使用.另外,不同时刻进行合并,产生的多播组也可能不同,带来2)中所述的影响.
4) 未考虑容错问题.当多播树的1条链路发生故障后,MR4LMS会重构所有的多播路由,由此带来下列问题:一是需要为所有多播组都重算路由,导致整机范围的路由重构,影响范围广;二是经过故障链路的多播包会丢失,即使有端到端的传输层控制协议可以重传该包,但由于重构多播路由需要相对较长的时间,因此会对应用性能带来较大影响.
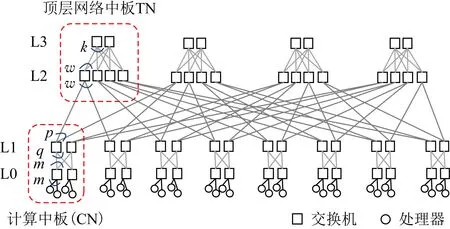
Fig. 2 Illustration of fat tree structure图2 胖树结构示意图
实际上,针对特定的拓扑结构,可以采用更高效的解决方案.胖树是目前高性能计算中最流行的拓扑结构,Top500排名中很多计算机均采用胖树或裁剪胖树.本文将针对胖树结构研究硬件仅支持少量多播组条目数时的多播路由算法.
1.3 本研究使用的胖树结构
目前Top500超级计算机中使用较多的是3层或4层胖树[16-19].本文研究图2所示的4层胖树.L0与L1层交换机被分成多个计算网络中板(computing network midplane, CN),每个CN包含q个L0层交换机以及m个L1层交换机.L2层与L3层交换机也被分成多个顶层网络中板(top network midplane, TN),每个TN包含k个L2层交换机以及w个L3层交换机.每个L1层交换机共有p个端口用于连接TN,故每个CN共有m×p个端口用于连接TN,TN的个数为m×p.每个TN有k×w个端口用于连接CN,因而CN的个数为k×w.
2 高效实用地定制多播路由算法
为了快速创建多播路由,可以预先构建好一些多播树,但这些多播树并没有真正写到多播表中.当为多播组创建多播树时,直接从这些预分配的多播树中选择1棵使用即可.每棵这样的多播树都应该包含所有L0层交换机,以支持整机规模的多播组.为与1.1节所述的多播树加以区别,称这些预先创建的多播树为生成树(spanning tree, SPT).一般情况下,多播组仅会使用该生成树的部分枝叶.当为多播组创建多播树时,仅将所使用的那部分枝叶写进多播表中即可.
在胖树结构中,多播组使用的多播树的树根应该是多播组内各成员的最近公共祖先.由于任一L0层交换机到给定树根有且只有1条路径,对每个多播组而言,只要确定了树根及颜色就确定了多播树.因此,要预先建立生成树,只需确定哪些交换机可以作为树根即可.选择交换机时,需要考虑以该交换机为树根建立的生成树,跟那些已建立的生成树是否存在冲突.2棵生成树若使用同一种颜色,则不能共用同一条链路;只有使用不同颜色时才可以共用同一条链路.
2.1 无冲突的生成树个数
首先要回答的问题是:给定颜色数C,可以建立多少棵不冲突的生成树?首先分析仅有一种颜色时生成树的个数.暂不考虑L0层交换机与终端节点间的链路是否会存在冲突.
定理1.胖树结构中,一种颜色能且仅能创建m棵不冲突的生成树,其中m是每个CN内L1层交换机的个数.
证明.首先,按下述方式构造m棵生成树.先将TN按从左到右的顺序编号并分组,每p个分为1组,共m组.按该分组方法,每个L1层交换机所连接的p个TN位于同一组内.然后从每组中任意选择1个TN,共选出m个.再在每个选出的TN中任选1个L3层交换机,共选出m个交换机.以这m个交换机为根,以所有L0层交换机为叶节点,可产生m棵生成树.图3单实线部分显示了一棵以第1个TN为树根的生成树.
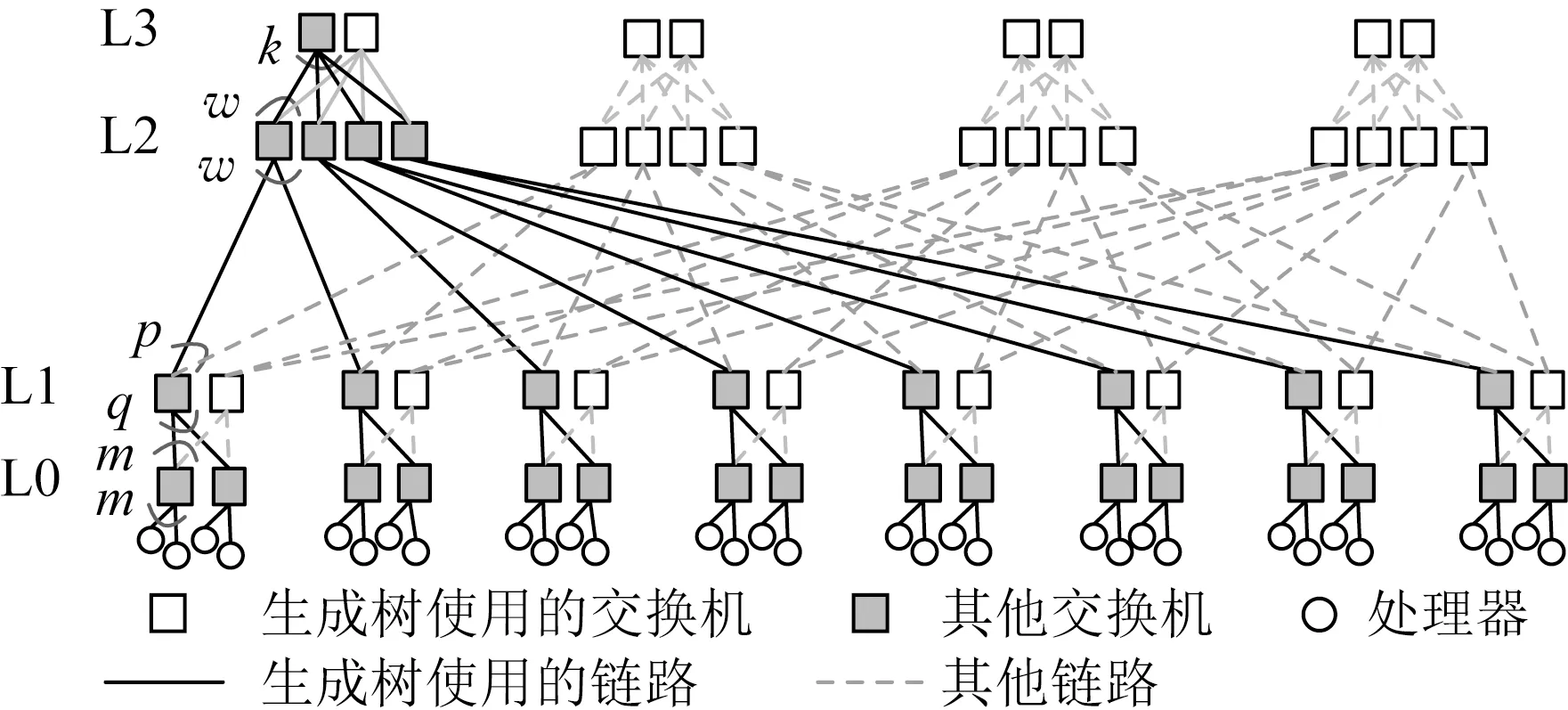
Fig. 3 Illustration of spanning tree图3 生成树示意图
其次,证明这m棵生成树不共用任何一条链路.很明显,这m棵生成树没有共用任何L2↔L3以及L1↔L2间链路,因为每个树根都位于不同的TN内.而每个L1层交换机连接的p个TN位于同一组内,这p个TN仅有1个被选为树根.也就是说,按上述方式构建的2棵生成树,不可能经过同一个L1交换机,也就不可能共用L0↔L1间链路.因此,上面构造的m棵多播树不共用任何1条链路,可使用同一种颜色.
最后,很容易就可看出,CN内的每条链路都已被上述m棵生成树中的1棵使用,因此不可能再创建出新的生成树了.
综上所述,仅有一种颜色时,能且仅能创建m棵不冲突的生成树.
证毕.
需要指出的是,仅使用一种颜色时,1个TN唯一确定了1棵生成树,而不用关心该生成树使用了该TN内的哪个L3层交换机做根.因此,如果2个多播组选择同一个TN内的不同交换机做树根,仍认为这2个多播组使用了同一棵生成树.更进一步,如果2个多播组选择使用位于同一组内的2个不同TN做树根,由于它们可能共用L0↔L1间链路,仍认为这2个多播组使用了同一棵生成树.如果2个多播组选择同一个TN内的交换机做树根,但使用了不同的颜色,则认为这2个多播组使用了不同的生成树.概括而言,TN及颜色唯一确定了1棵生成树.
根据定理1,可以很容易得到下面的2个推论.
推论1.胖树结构中,C种颜色能且仅能创建C×m棵不冲突的生成树.其中每个L1交换机承担C棵生成树,可以把这C棵生成树分布到跟该L1交换机连接的p个TN中.
在构造网络系统时,上述定理及推论为确定多播表大小提供了理论依据.例如,若用40端口交换机构造网络系统,则m=20;在每个交换机端口仅支持256个多播表条目时,可支持不少于5 120个多播组.
需要说明的是,系统中实际可创建的多播组个数一般大于C×m.这是因为很多情况下2个多播组可以共用同一棵生成树而不冲突,只要它们不共用该生成树的同一条链路即可.例如,如果使用该生成树的多播组的所有成员都位于同一个CN内,则该多播组仅使用了该生成树位于该CN内的那部分枝叶,剩余部分仍可供其他多播组使用.
即使多播组的成员分散在不同CN内,从而需要将根建在L2或L3层交换机上,该多播组仍然可以跟其他多播组共用同一棵生成树.图4显示了一个这样的例子.灰色阴影所示多播组和斜条纹填充所示多播组可以使用同一个L3层交换机做树根.2个使用同一棵生成树的多播组,只要它们没有共用同一个L2交换机,就可以共同一个L3交换机做树根,因为这样产生的多播树没有共用任何相同的链路.
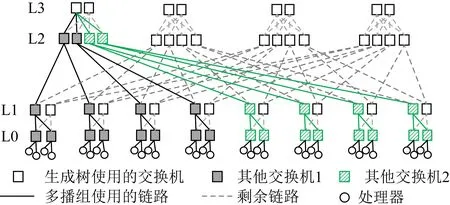
Fig. 4 Example for 2 MCGs using the same spanning tree图4 2个多播组共用1棵生成树的例子
系统中共有C×m棵不冲突的生成树,对编号为spt_no的生成树,根据式(1)确定其颜色color及树根所在的顶层网络中板tnid.另外,总是选择该顶层网络中板的第1个L3交换机做树根,因此确定了tnid及color,就确定了树根.由式(1)可以看出,我们将不同颜色的生成树树根分散到同一组内的不同TN内,来达到负载均衡的目的.
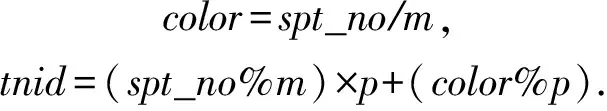
(1)
2.2 为多播组选择生成树
为多播组创建多播树时,首先需要确定该多播组应该使用哪棵生成树.对每一个多播组,根据其MGID将其映射到上述C×m棵生成树中的1棵.具体来说,假设多播组的MGID为mgid,根据式(2)确定该多播组使用的生成树.
spt_no=mgid%(C×m).
(2)
根据式(1)(2)我们可以得出根据MGID直接计算颜色编号及树根所在TN编号:

(3)
采用该方式创建多播树时,无需考虑系统中各链路的负载及颜色使用情况,仅由MGID即可确定使用哪棵生成树.如果多播组的个数多于C×m,则可能出现多个多播组共同一棵生成树的情况,此时需要将几个多播组合并成1个多播组.式(1)及式(3)保证使用同一棵生成树的2个多播组在合并时,仅需在原来的多播树上添加部分链路即可,被合并的那些多播组使用的多播树并不受影响,从而不会影响这些多播组的正常使用.
1个终端加入多个多播组时,每个多播组需要使用不同的颜色,否则在终端节点与L0交换机间的链路上就会产生冲突.本文将在3.1节研究该问题的解决方案.
2.3 为多播组构造多播树
确定树根所在的顶层网络中板及颜色后,就可以构造多播树了,步骤如算法1所示.该算法根据多播组成员的分布情况,从生成树中选择合适的交换机做为该多播组的树根,它们可能位于L0,L1,L2,L3中的某一层.
算法1.多播树构造算法.
输入:互连网络I=G(N,L)、多播组mcg;
输出:多播树mct.
① 根据式(3)计算该多播组使用的颜色color以及树根所在的顶层网络中板tnid;
② 对多播组的每个成员,检查其连接到L0交换机的那条链路上颜色color是否已被使用,若是则返回NULL;
③ 根据多播组各成员的物理位置,确定该多播组内各成员的最近公共祖先所在的位置;
④ 若最近公共祖先位于L0或L1或L2层,则该公共祖先有且只有1个,记为root;
⑤ 若最近公共祖先位于L3层,则选择顶层网络中板tnid内的第1个L3交换机做树根root;
⑥ 以root为树根,为mcg的每个成员都找出该成员到root的路径,从而构建出多播树mct;
⑦ 检查mct的每条链路中颜色color是否可用,若均为可用,则返回mct;
⑧ 否则,返回NULL./*需进行合并操作*/
算法1步骤②用于检查终端节点使用同一种颜色加入多个多播组的情况;若该颜色已被使用,则不能利用该颜色创建新的多播组,因此返回NULL,表示需要进行合并操作.
算法1步骤③~⑤用于确定树根,规则为:
1) 若多播组的成员都位于同一个L0交换机内,则树根即为该L0交换机;
2) 若多播组的成员均位于同一个CN内,则树根为生成树在该CN内的那个L1交换机;
3) 若多播组的成员位于不同CN内(CN编号记为cnid),且所有cnid/w相等,则树根为生成树中用于连接这些CN的那个L2交换机;
4) 其他情况下,选择该生成树中的第1个L3交换做树根.
算法1步骤⑥⑦尝试使用颜色color构建多播树.在胖树结构中,确定了树根后,多播组的每个成员到树根仅有1条链路,因此也就确定了多播树.2个多播组使用同一棵生成树时,有可能会共用同一条链路,从而会产生冲突,此时需要进行合并操作,方法见2.4节.
将多播组中成员个数记为S,则算法1的时间复杂度为O(S).
2.4 合并多播组
在算法1中,如果发现新构造的多播树与某个已经创建的多播组使用了同一条链路,则需要进行合并操作.方法如下:将算法1中构建的多播树记为tmpMct,检查tmpMct的每条链路,若该链路中颜色color已被其他多播组使用,则根据式(3)这些多播组必定与新创建的多播组使用同一棵生成树;将这些多播组的所有成员,连同新创建的多播组的成员一起,利用算法2构建一个新的多播组,记为vmcg;然后利用算法1为vmcg创建多播树.
算法2.合并算法.
输入:互连网络I=G(N,L)、多播组mcg;
输出:虚拟多播组vmcg.
① 根据式(3)计算该多播组使用的颜色color、树根所在的顶层网络中板tnid;
② 采用算法1找到树根root,并以root为树根构造多播树tmpMct;
③ 检查tmpMct的每条链路,将使用该链路且颜色为color的所有多播组,连同mcg合并在一起,形成虚拟多播组vmcg;
④ 返回vmcg.
算法2在寻找需要合并哪些多播组时,仅检查了tmpMct使用的链路,而tmpMct的树根可能是非L3层的交换机.也就是说,算法2仅检查了所用生成树的一部分链路的使用情况.那么,算法2是否已经合并了所有必须合并的多播组,从而保证一定能够成功为vmcg构建出多播树呢?答案是肯定的,下面我们进行证明.
引理1.利用算法1构建多播树时,如果某多播组需要进行合并操作,则合并后产生的vmcg对应的多播树,其任意1条链路必定出现在某个被合并的多播组所对应的多播树内.

证毕.
定理2.利用算法1构建多播树时,如果某多播组需要进行合并操作,则合并后产生的vmcg对应的多播树,与使用同一生成树的其他多播组不共用任何链路.
证毕.
根据定理2,为vmcg构建多播树时,不会跟使用同一生成树的其他多播组冲突,也就是说算法2已经合并了所有必须合并的多播组.
由上述论述可知,合并多播组时,仅会在原来多播树的基础上添加部分链路,因而不会对原多播树带来影响.完整的C-MR4LMS路由算法见算法3.
算法3.C-MR4LMS.
输入:互连网络I=G(N,L)、多播组mcg;
输出:多播树mct.
① 利用算法1为mcg构建多播树mct;
② 若mct为NULL,则
③ 利用算法2进行合并操作,将几个多播组合并成1个虚拟的多播组vmcg;
④ 再次利用算法1为vmcg创建多播树mct;
⑤ 更新mct每条链路中相应颜色的使用情况;
⑥ 更新mct中每个交换机的多播路由表.
2.5 容错多播路由
本文采用图5所示的容错策略:为每个多播组构建多播路由时,选择2个树根并构建2棵多播树,两者互为备份,数据包同时通过这2棵多播树进行传输.终端节点收到2份重复的数据包时,仅需丢弃其中1个.当其中1棵多播树因链路故障而无法使用时,数据包可以通过另一棵多播树进行传输,从而做到对用户透明的容错.

Fig. 5 Illustration of multicast routing with fault tolerance图5 容错多播路由示意图
当开启容错功能后,利用式(4)计算多播组使用的颜色及2棵多播树树根所在TN编号.该方法实际上是将每种颜色下的m棵生成树分为2组,从每组分别选择1棵生成树使用.因此,系统支持的无冲突生成树的个数会减为原来的1/2.
(4)
2.6 另一种选择树根的方法
如果多播组内各成员的最近公共祖先位于L3层,则顶层网络中板tnid内每个L3交换机都可以做树根.从中选择哪个做树根实际上有2种策略:一是算法1所采用的固定选择第1个交换机的策略,由此产生的算法称为C-MR4LMS-fixed;二是将所有L3交换机都作为备选树根,从中选择1个合适的做树根(优先选择负载低的),由此产生的算法称为C-MR4LMS-dynamic.
这2种变体各有优缺点.
1) 某些情况下,C-MR4LMS-dynamic可以通过选择不同的L3交换机做树根,使C-MR4LMS-fixed算法下原本有冲突的2个多播组不再冲突.如图6所示,灰色阴影所示多播组与斜条纹所示多播组使用同一棵生成树.C-MR4LMS-fixed算法下这2个多播组共用同一个L3交换机做树根,因此在L2↔L3链路上会产生冲突.而C-MR4LMS-dynamic算法下这2个多播组可以使用不同的L3交换机做树根,从而避免产生冲突.
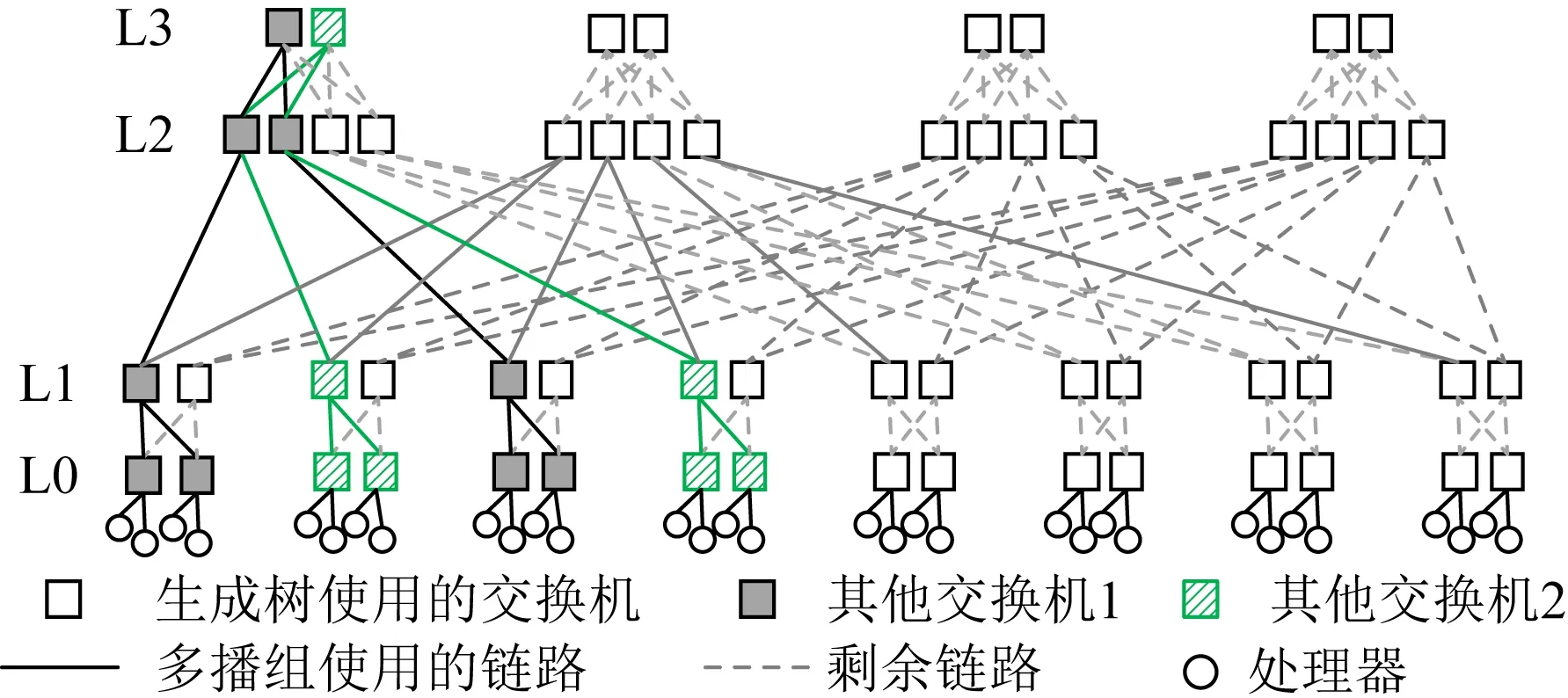
Fig. 6 Example for 2 MCGs using different L3 switches as root图6 2个多播组使用不同L3交换机做树根的例子
2) 需要进行合并操作时,C-MR4LMS-dynamic下同一棵生成树的几个多播组可能使用不同的L3交换机做树根,它们被合并到一起后,树根会发生变化,从而导致被合并的多播组其多播路由发生变化,而C-MR4LMS-fixed不存在该问题.
Fig. 7 Illustration for merge algorithm fails to construct MCTs with C-MR4LMS-dynamic图7 利用C-MR4LMS-dynamic算法构建多播树后合并算法失效的例子
3) C-MR4LMS-fixed算法下,利用算法2合并多播组时,已经合并了所有必须合并的多播组,从而保证一定能够成功为vmcg构建出多播树.而C-MR4LMS-dynamic算法下,利用算法2合并多播组时,可能会漏掉某些必须合并的多播组,从而导致为vmcg构建多播树失败.如图7所示(图中省略了L0,L1层交换机),假设新创建的多播组需要经过R2,R4这2个交换机,且无论选择R0还是R1做树根均跟已存在的多播组存在冲突,因此需要利用算法2进行合并操作.假设在合并时,选择R0做树根,且需要合并R1↔R4,R1↔R5间链路所示的多播组.在进行合并时,仅会检查R0↔R4,R0↔R2链路;而合并后的vmcg对应的多播树会用R0↔R5间链路,但该链路在检查需要合并哪些多播组时并未被考虑到,实际上该链路可能被另外的多播组使用,因而为vmcg构建多播树会因冲突而失败.出现该问题的原因是:R1↔R4,R1↔R5多播组使用了不同的L3交换机做树根,导致原本未被vmcg内任一多播组使用的链路R0↔R5出现在了vmcg经过的路径上,从而使得C-MR4LMS-dynamic算法下引理1不再成立.也就是说,C-MR4LMS-dynamic算法下,上述合并算法不能保证合并了所有必须合并的多播组.
基于上述原因,使用C-MR4LMS-dynamic时,为vmcg构建多播树可能失败,此时需要再进行1次合并方可成功.
4) 在多播组个数较多时,C-MR4LMS-dynamic需要尝试很多个L3交换机做树根,时间开销较大;而C-MR4LMS-fixed仅会尝试1个L3交换机做树根,时间开销较小.
具体使用哪种策略,可以根据实际情况进行选择.一般来说,多播组个数不多时,可以采用C-MR4LMS-dynamic策略;而多播组个数很多而需要频繁合并多播组时,比较适宜采用C-MR4LMS-fixed算法.
3 减少多播树冲突的2种方法
MGID分配策略及节点分配策略都会影响C-MR4LMS算法的性能.例如,为某个多播组选择不同的MGID,就会使用不同的生成树;将多播组所在的作业映射到不同节点上,也会影响多播树的分配.
本节将研究如何分配MGID及进行节点映射,以达到减少多播树冲突的目的.这些分配策略并不是C-MR4LMS的组成部分,目的是为了更好地发挥C-MR4LMS的性能.
3.1 分层的MGID分配策略
考虑每个终端节点可加入多个多播组的情况.1个终端加入多个多播组时,每个多播组需要使用不同的颜色,否则在终端节点与L0交换机间的链路上就会产生冲突.根据式(3),如果不对用户可用的MGID加以限制,就很容易出现1个终端加入的多个多播组时使用同一种颜色的情况.出现该情况后,需要将冲突的那些多播组合并.此时进行的合并跟2.2节介绍的合并有很大不同.当2个多播组因共用同一条交换机间链路而需要合并时,因为他们使用同一棵生成树,只需在原多播树的基础上添加部分链路即可,不会影响原多播组的正常使用.而当1个终端节点使用同一种颜色加入多个多播组时,这些多播组可能使用了不同的生成树,其树根位于不同TN内,合并后多播组的树根会发生变化,影响用户使用.
基于上述原因,当1个终端需要加入多个多播组时,我们需要对其使用的MGID加以限制.也就是说,根据式(3)计算color及tnid时,要么每个多播组都使用不同的颜色,要么2个多播组可以使用同一种颜色,但计算出的tnid必须相同,从而保证这2个多播组可以不用切换TN做树根即可进行合并.
用户可以采用多种策略保证1个终端节点使用的多个MGID没有颜色上的冲突.一种可行的策略是:根据每个终端可加入的多播组的个数将颜色划分为不同的区间,每个区间称为1个层,从而也就将MGID空间划分成了多个互不重叠的层,称为MGID层.在每个MGID层内,1个终端节点最多可加入其中的1个多播组;加入多个多播组时,选择不同的MGID层即可保证他们使用不同的颜色.
每个终端可加入的多播组的个数一般不会太多,例如,以2维网格方式划分通信域时,假设每个终端上仅运行1个通信进程,则每个终端仅需加入3个多播组,包括1个全局通信域、1个用于行通信的子通信域以及1个用于列通信的子通信域.在此情况下,我们可以将MGID划分为3个层,使得每个MGID层均使用不同的颜色,为哪个维度的多播组分配多播组,就从该维度对应的MGID层中选择1个MGID使用.
当每个终端上可运行多个通信进程时,情况变得复杂,因为每个终端节点在每个维度方向上可能加入多个多播组.此时需要考虑通信域的划分方式,并将每个通信域映射到合适的MGID层.MPI集合通信中,主要有2种通信域划分方法[20-21]:一是划分成2维或3维网格,其每个维度中每行或每列都是1个通信域,对应1个多播组;二是划分成层次结构,例如树型结构,每层分成很多组,每个组构成1个通信域,每个组再选出1个leader,形成更高层次的组.以层次结构划分通信域时,将通信域映射到MGID层的方法比较简单,只需为每个通信域层指定1个MGID层.
下面考虑3维网格划分方式下将通信域映射到MGID层的方法,2维网格方式与此类似,不再赘述.如图8所示,假设每个终端节点上有P个通信进程,且它们在3维环网中的位置是连续的.例如,设3维环网x,y,z维长度分别为X,Y,Z,某终端节点上首进程的坐标为(a,b,c),则该终端节点上第n个进程的坐标为((a+n)%X,(b+(a+n)/X)%Y,c+(bX+a+n)/(XY)).
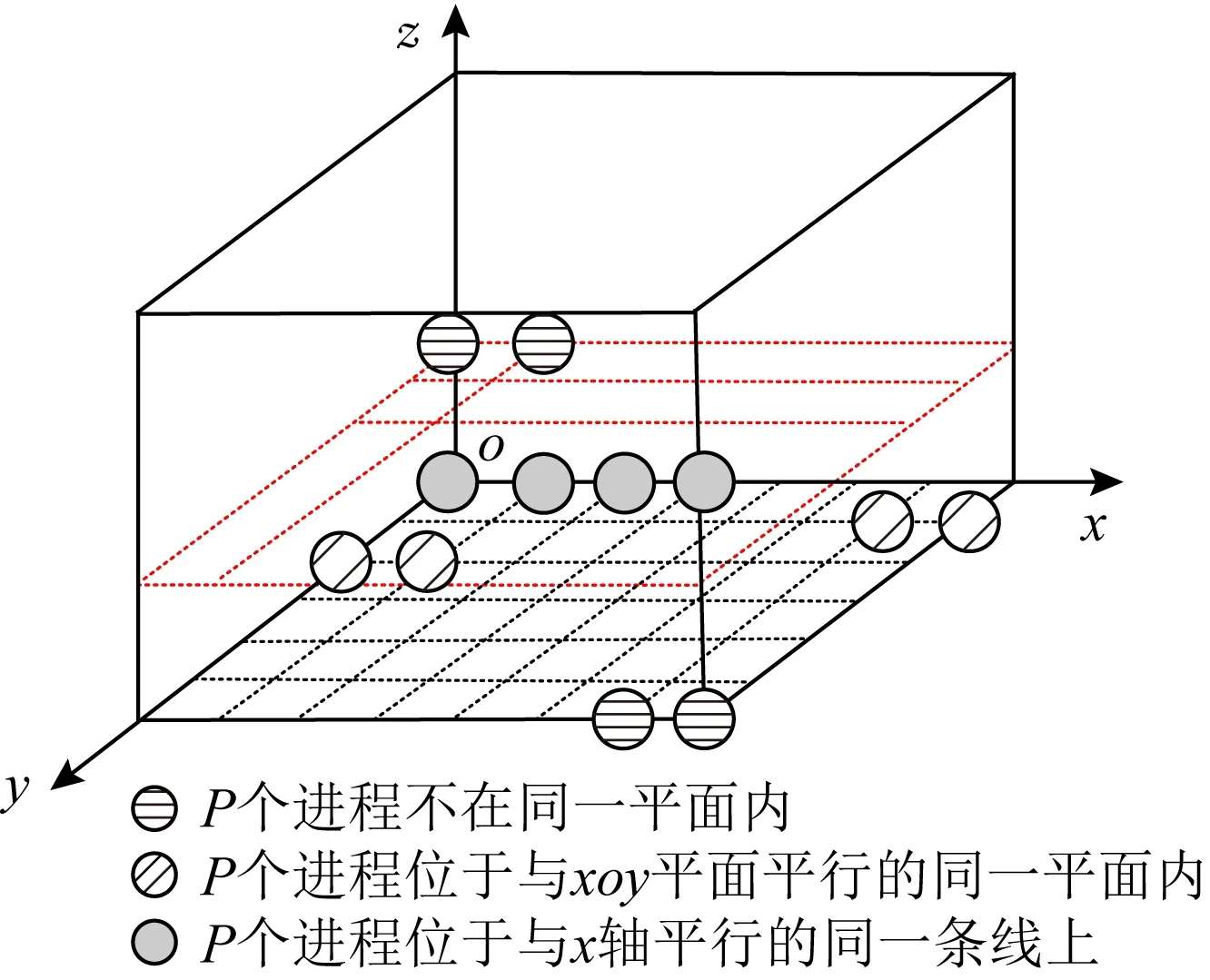
Fig. 8 Illustration for different process’s position on the same terminal node in 3D-torus图8 3维环网中同一终端节点上不同进程位置示意图
给定坐标为(a,b,c)的进程,我们根据式(5)分别计算该进程加入3个轴方向上的多播组时使用的MGID层号,其中layerx,layery,layerz分别对应x,y,z轴方向上的多播组.
(5)
定理3.以3维环网方式划分通信域时,若每个终端节点上有P个通信进程(P小于3维环网任一维的长度),且这些进程在3维环网中位置连续,则利用式(5)将每个进程的3个多播组放入某个MGID层时,对任一终端节点而言,每个多播组均位于不同的MGID层内.
证明.首先,很容易看出,不同方向上的多播组位于不同的MGID层内.其次,我们证明,同一终端节点上同一方向上的多播组也位于不同的MGID层内.我们先列出同一终端节点上各个进程的位置分布情况,包括:
1)P个进程位于与x轴平行的同一条线上(如灰色阴影进程所示);
2)P个进程不在同一条直线上,但位于与xoy平面平行的同一平面内(如斜纹填充进程所示);
3)P个进程不在同一平面内(如横纹填充进程所示).
先看x轴方向上的多播组.情况1)中,P个进程属于同一个多播组.情况2)中,P个进程属于多个多播组,但它们具有相同的z坐标,以及连续的y坐标,因此根据式(5)得到的MGID层号必不相等.情况3)中,P个进程属于多个多播组;若2个多播组具有相同的z坐标,则与情况2)一样,根据式(5)得到的MGID层号必不相等;若2个多播组具有不同的z坐标,则其中1个多播组的y坐标必小于P-1,另一个多播组的y坐标必大于等于P-1,根据式(5)得到的MGID层号也不相等.因此,上述3种情况下,根据式(5)得到的MGID层号都互不相等.
同理,y,z轴方向上的多播组根据式(5)得到的MGID层号也互不相等.
证毕.
利用式(5),可以将3维环网中的多播组映射到不同的MGID层内,保证每个终端节点在每个MGID层内最多加入1个多播组,从而保证该终端节点加入多个多播组时,每个多播组都使用不同的颜色,也就避免在终端节点与L0交换机间的链路上产生冲突.每层内的颜色数可以根据该层内的多播组个数进行分配.
3.2 相互无干扰的作业节点分配策略
根据定理1及2个推论,当系统中多播组的个数少于C×m时,无需合并多播组即可完成多播树的创建;而当多播组的个数多于C×m时,很可能出现2个多播组使用同一棵生成树的同一条链路的情况,从而导致冲突,此时需要将这2个多播组合并在一起.多播组合并会导致1个多播组发送的数据拷贝到另一个多播组内,从而使得链路EFI指数变大,影响集合操作的性能.因此需要尽量避免这种情况的出现.
通过优化节点分配来减少作业间的相互干扰是提升应用性能的重要手段[22-23].本文提出了一种作业分配策略,使不同作业使用的网络资源彼此隔离,从而使得不同作业可以共用同一棵生成树而没有任何冲突.这样每个作业都至少可以创建C×m个不冲突的多播组,从而使得系统中支持的多播组总数远远大于C×m.
首先根据作业使用的终端个数将作业分为下列类型:
1) T0作业,其终端个数小于等于m;
2) T1作业,其终端个数小于等于m2;
3) T2作业,其终端个数小于等于w×m2;
4) T3作业,其终端个数大于w×m2.
为作业分配终端节点时,必须遵循下列规则:
1) 1个节点仅能分配给1个作业使用;
2) T0作业使用的节点均位于同一L0交换机内;
3) T1作业使用的节点均位于同一CN内;
4) T2作业使用的节点,其计算网络中板号cnid/w应等于同一个值;
5) L0交换机可被多个T0作业共享,但最多只能被1个T1及以上规模的作业使用;
6) 1个计算网络中板可以被多个T1作业共享,但最多只能被1个T2及以上规模的作业使用;
7) 编号为i×w,i×w+1,…,(i+1)×w-1的w个中板可以被多个T2作业共享,但最多只能被1个T3作业使用.
定理4.按规则1)~7)为作业分配节点时,任何2个作业不共用同一条链路.
证明. 首先考虑L0层交换机.根据规则1),L0交换机的下行链路只能被1个作业使用.根据规则2),T0作业不会使用L0交换机的上行链路;而根据规则5),L0交换机最多被1个T1及以上规模的作业使用,因此L0交换机的上行链路最多被1个作业使用.
再考虑L1层交换机.同样根据规则5),其每条下行链路最多被1个作业使用;根据规则3),T1作业不会使用L1交换机的上行链路;而根据规则6),L1交换机最多被1个T2及以上规模的作业使用,因此L1交换机的上行链路最多被1个作业使用.
再考虑L2层交换机.同样根据规则6),其每条下行链路最多被1个作业使用;根据规则4),T2作业不会使用L2交换机的上行链路;而根据规则7),L2交换机最多被1个T3作业使用,因此L2交换机的上行链路最多被1个作业使用.
最后考虑L3层交换机.同样根据规则7),其每条下行链路最多被1个作业使用.
证毕.
由此可知,按规则1)~7)为作业分配节点时,来自不同作业的2个多播组使用同一棵生成树创建多播树时,不会产生冲突.因此,只要每个作业使用的多播组个数不超过C×m,就可以保证系统中所有的多播组不用合并就可成功创建多播树.
4 ibsim下的性能评估
我们在OpenSM 3.3.22[24]中实现了C-MR4LMS,共有约2 000行代码.对OpenSM源码进行了修改,使得每个交换机端口都有一份单独的路由表.另外,还对加入、离开多播组的机制进行了简单的修改,以解决频繁重算路由的问题.
4.1 实验环境
本文使用ibsim-0.7[24]模拟了图2所示的一棵4层胖树,参数如下:交换机端口数为40,m=w=16,q=k=32,p=6.理论上,该网络最大支持512个CN,96个TN,262 144个终端节点.但由于OpenSM及ibsim最多支持49 152个节点(包括交换机及终端),因此仅使用了64个CN、96个TN;网络中节点总数为40 448,其中交换机个数为7 680,终端节点数为32 768.
本文使用测试程序模拟发起加入或离开多播组的请求.OpenSM运行在一台48核Intel Xeon Silver 4214服务器上,频率为2.20 GHz.需要指出的是,在ibsim下的测试结果跟在真实网络环境下的测试结果是一样的,因为EFI及运行时间等性能数据跟是否使用ibsim模拟拓扑结构无关.
MPI中将进程划分为子通信域时,可以采用层次结构进行划分,也可以采用2维或3维网格方式进行划分.采用2维或3维网格方式划分通信域时,会产生大量多播组,对多播表条目数的需求量更大.后面实验中,采用2维及3维网格划分进程,以测试存在大量多播组时多播路由算法的性能.除此之外,还测试了进程随机加入某个多播组的通信模式.另外,既测试了每个终端运行1个通信进程的情况,也测试了每个终端运行多个通信进程的情况.
后面将要测试的2维或3维网格模式中,有些是按拓扑结构进行划分的,模拟拓扑感知的通信模式;有些划分成正方形或立方体形状,模拟拓扑无感的通信模式.以每个终端节点上运行1个通信进程为例, 512×64通信模式下,第1维有64个多播组,每个组都位于同一个CN内,因此通信模式与拓扑结构匹配;而181×181通信模式下,存在很多跨计算中板的多播组,因此通信模式与拓扑结构不匹配.
神威互连网络中每个交换机端口最多支持32个多播表条目,因此后面测试中,将最大颜色数设为32,不冲突的生成树的个数为512.设为其他值时,测试结果会有差异,但测试结论与颜色数为32时基本一致,因此不再赘述其测试数据.另外,为了与MR4LMS对比,关闭了C-MR4LMS的容错功能.
本文测试了原始MR4LMS算法及本文提出的2种多播路由算法(C-MR4LMS-fixed,C-MR4LMS-dynamic)在各种通信模式下的性能,其中每个终端节点上运行1个通信进程时的测试结果如图9所示,每个终端节点上运行4个通信进程时的测试结果如图10所示.
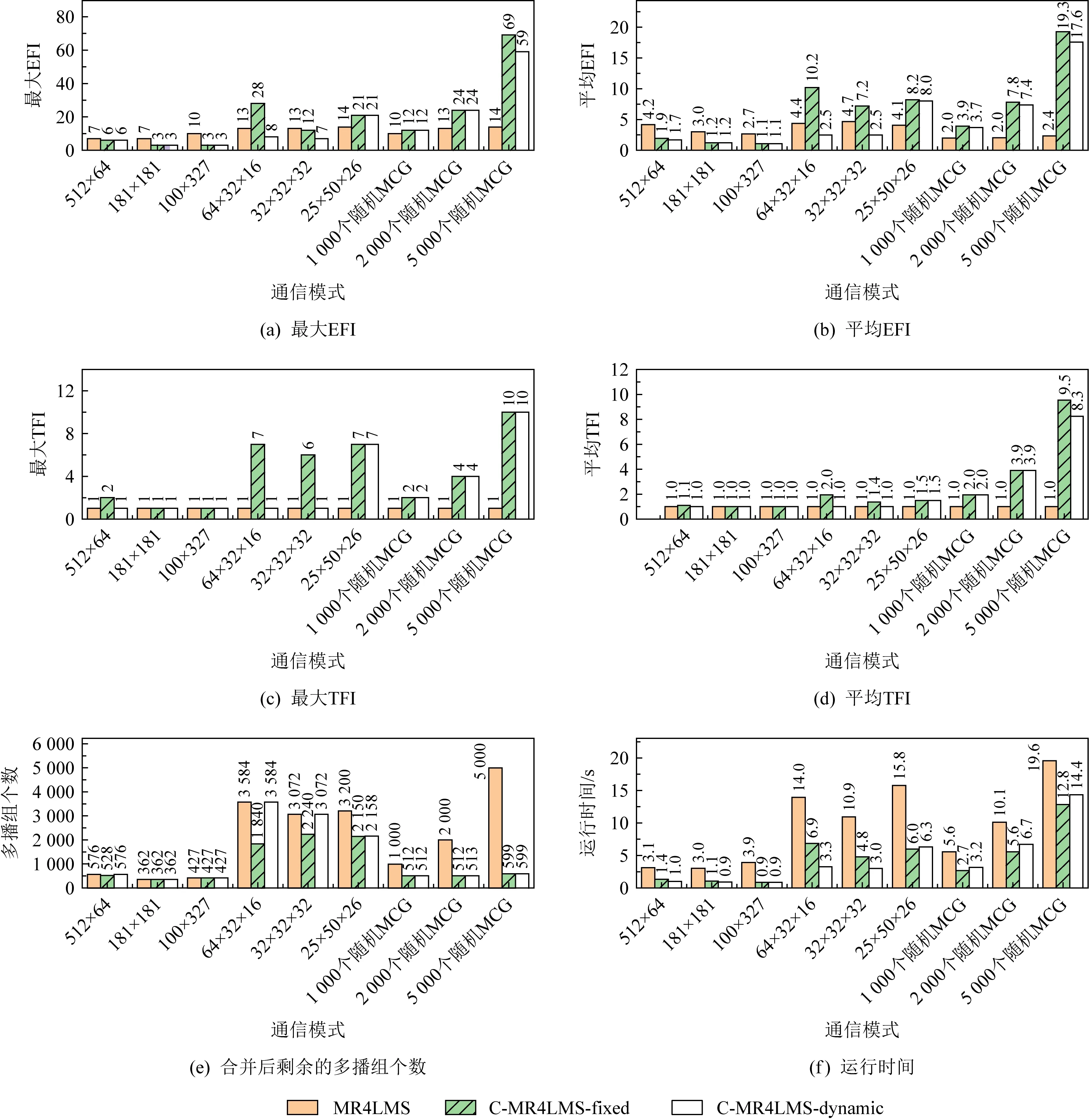
Fig. 9 The performance of three algorithms with only one communication process on each terminal node图9 每个终端节点上仅有1个通信进程时3种算法的性能

Fig. 10 The performance of three algorithms with 4 communication process on each terminal node图10 每个终端节点上4个通信进程时3种算法的性能
4.2 不同通信模式下的链路EFI
最大EFI及平均EFI反映了各链路上多播树的数量,一定程度上代表了多播路由算法的均衡程度.
4.2.1 每个终端上仅1个通信进程
先分析每个终端节点上运行1个通信进程时的情况,结果如图9(a)(b)所示.
1) 2维环网模式下,2种C-MR4LMS算法的最大EFI及平均EFI均低于MR4LMS算法.出现该现象的原因是:MR4LMS算法在选择树根时根据负载情况从很多备选树根中选择1个;而在胖树结构中,所有的L3交换机均可作为备选树根,因此会被轮流作为树根使用.而2维环网下多播组的个数较少,因此MR4LMS仅用到了那些位置靠前的L3交换机,而那些位置靠后的L3交换机未被使用.这就导致MR4LMS算法仅使用了部分顶层网络中板,进而导致连接L1交换机与L2交换机的那些链路上EFI指数偏大.而C-MR4LMS算法会轮流使用不同顶层网络中板做树根,因此可以将多播组分散到不同顶层网络中板内.随着多播组个数的增多,C-MR4LMS算法会重用顶层网络中板,此时C-MR4LMS的优势将会消失.另外,由于创建的多播组不多,2种C-MR4LMS算法的EFI差别不大,C-MR4LMS-dynamic略优于C-MR4LMS-fixed.
2) 3维环网模式下,2种C-MR4LMS算法的表现有时比MR4LMS好,有时比MR4LMS差,这是因为随着多播组个数的增大,MR4LMS算法会使用全部的顶层网络中板,故3种算法均会将多播组分散到不同顶层网络中板内;而MR4LMS算法会根据负载情况选择不同的交换机做树根,因此大部分情况下MR4LMS算法具有更好的负载均衡性.2种C-MR4LMS算法比较,C-MR4LMS-dynamic略优于C-MR4LMS-fixed.
3) 进程随机加入某个多播组的模式下,MR4LMS算法明显优于2种C-MR4LMS算法.原因如下:C-MR4LMS算法下,多播组的个数已经超过了不冲突的生成树的个数,因而需要合并多播组,导致EFI偏大,而MR4LMS算法由于可以尝试不同的交换机做树根,不需要合并多播组,因而EFI指数小.后面将会看到,随着多播组个数的进一步增大,MR4LMS算法也会产生合并,此时其EFI指数也会明显增加.需要指出的是,虽然2种C-MR4LMS算法的EFI明显高于MR4LMS,但最大EFI为69,尚在可接受的范围内.
4.2.2 每个终端上4个通信进程
再分析每个终端节点上运行4个通信进程时的情况,结果如图10(a)(b)所示.
1) 2维环网模式下,2种C-MR4LMS算法的最大EFI及平均EFI略高于MR4LMS算法.这与每个终端上仅1个通信进程时3维环网通信模式下的情况类似,原因是进程数增多后,多播组的个数也随之增大,因而MR4LMS算法会使用全部的顶层网络中板,故其表现优于2种C-MR4LMS算法.
2) 3维环网模式下,2种C-MR4LMS算法的表现有时比MR4LMS好,有时比MR4LMS差.MR4LMS比2种C-MR4LMS算法差的原因是:随着多播组个数的增大,3种算法需要进行合并,但2种C-MR4LMS算法仅会合并使用同一生成树的多播组,合并的多播组较少;而MR4LMS算法在选择树根时是根据负载情况动态选择的,因此大量多播树交错在一起,合并时极端情况下可能需要合并很多个多播组.
3) 进程随机加入某个多播组的模式下,2种C-MR4LMS算法的表现优于MR4LMS,原因与2)一样.
4.2.3 结论
综合上面分析,在EFI方面,有4点结论:
1) 当多播组个数少于不冲突的生成树个数时,2种C-MR4LMS算法一般情况下略优于MR4LMS.
2) 当多播组个数增大时,2种C-MR4LMS算法需要合并多播组,而MR4LMS算法不需要进行合并操作,此时MR4LMS算法一般优于2种C-MR4LMS算法.
3) 随着多播组个数的继续增大,从而使得3种算法都需要合并多播组时,2种C-MR4LMS算法一般情况下又会优于MR4LMS算法.
4) 2种C-MR4LMS算法比较,C-MR4LMS-dynamic略优于C-MR4LMS-fixed;但大部分情况下,C-MR4LMS-fixed接近于C-MR4LMS-dynamic.
概括而言,依据图9(a)、图10(a),当多播组个数较少时,C-MR4LMS算法的最大EFI略高于MR4LMS算法,最多增大88;而当多播组个数较多时,C-MR4LMS算法的最大EFI明显低于MR4LMS算法,最多减少594.
4.3 不同通信模式下的TFI
多播树的TFI表示有多少个多播组使用该多播树.最大TFI及平均TFI反映了多播组的合并程度.
4.3.1 每个终端上仅1个通信进程
先分析每个终端节点上运行1个通信进程时的情况,结果如图9(c)~(e)所示.
1) MR4LMS算法下,所有通信模式下均未发生合并,因此TFI均为1.
2) 2种C-MR4LMS算法下,当多播组个数小于生成树个数时(如181×181,100×327),因不需要合并,TFI均为1.随着多播组个数的增多,需要合并多播组,TFI大于1.有几个有趣的现象需要注意:
① 64×32×16以及32×32×32这2种通信模式下,C-MR4LMS-fixed的最大TFI分别为7和6;而C-MR4LMS-dynamic的最大TFI均为1,这表明通过选择同一TN内的不同L3交换机做树根可以避免一些不必要的合并操作.
② 25×50×26以及3种随机加入多播组的通信模式下,2种C-MR4LMS算法的最大TFI均大于1且相等,但从平均TFI方面看C-MR4LMS-dynamic略优于C-MR4LMS-fixed.
③ 2种C-MR4LMS算法下,多播组发生合并后,剩余多播组的个数均不少于512(即系统中互不冲突的生成树个数).
④ 随机加入多播组的3种模式下,平均TFI接近于最大TFI,表明多播树合并比较均匀.而3种3维环网通信模式下,平均TFI明显低于最大TFI,原因是:采用分层的MGID分配策略后,有些层的多播组与拓扑结构匹配,因而不需要合并多播组,其TFI为1;而有些层的多播组与拓扑结构不匹配,需要合并多播组,其TFI较大,因此就出现了平均TFI与最大TFI差异较大的现象.
4.3.2 每个终端上4个通信进程
分析每个终端节点上运行4个通信进程时的情况,结果如图10(c)~(e)所示.有下列现象:
1) 3种2维环网模式,以及3维环网模式(256×32×16,128×32×32),MR4LMS算法的最大TFI均为1,而2种C-MR4LMS算法的最大TFI均大于1.这是因为每个终端节点上运行4个通信进程时,这几种2维环网通信模式中的多播组个数均超过了512,因而需要共用同一棵生成树,导致2种C-MR4LMS均需合并多播组.
2) 100×50×26以及3种随机加入多播组的模式下,3种算法(C-MR4LMS,C-MR4LMS-dynamic,C-MR4LMS-fixed)的最大TFI均大于1,但MR4LMS算法的最大TFI明显高于2种C-MR4LMS算法,即MR4LMS算法在选择树根时是根据负载动态选择的,因此大量多播树交错在一起,合并时极端情况下可能需要合并很多个多播组.以100×50×26通信模式为例,MR4LMS算法的最大TFI为168,而平均TFI仅为1.1,这表明大部分的多播组未被合并,而有168个多播组被合并到了一起.这也说明MR4LMS算法在需要合并多播组时,TFI波动较大.反观2种C-MR4LMS算法,其最大TFI与平均TFI相比差别没有这么明显,特别是3种随机加入多播组的模式下,平均TFI几乎等于最大TFI,这是因为2种C-MR4LMS算法轮流使用不同的生成树.
3) 从合并后剩余的多播组个数上看,某些通信模式下MR4LMS算法仅剩下少量多播组,例如1 000个随机多播组模式下仅剩下32个多播组,这进一步表明MR4LMS算法极端情况下会合并大量多播组.而2种C-MR4LMS算法下,剩余多播组的个数均不少于512,这是因为2种C-MR4LMS算法在合并时仅合并那些使用同一生成树的多播组.
4.3.3 结论
综合上面分析,在TFI方面,有下列结论:
1) 当多播组个数较少时,MR4LMS 算法不需要合并多播组,其TFI为1,而2种C-MR4LMS算法的TFI可能大于1.
2) 随着多播组个数的继续增大,3种算法(C-MR4LMS,C-MR4LMS-dynamic,C-MR4LMS-fixed)都需要合并多播组时,2种C-MR4LMS算法一般情况下会优于MR4LMS算法,且剩余多播组的个数均不少于512;而MR4LMS算法在极端情况下会剩余很少的多播组.
3) 2种C-MR4LMS算法比较,C-MR4LMS-dynamic略优于C-MR4LMS-fixed.
概括而言,依据图9(c)、图10(c),当多播组个数较少时,C-MR4LMS算法的最大TFI略高于MR4LMS算法,最多增大25;而当多播组个数较多时,C-MR4LMS算法的最大TFI明显低于MR4LMS算法,最多减少148.
4.4 不同通信模式下的算法运行时间
图9(f)、图10(f)分别显示了每个终端节点上运行不同数量的通信进程时3种算法(C-MR4LMS,C-MR4LMS-dynamic,C-MR4LMS-fixed)的运行时间.该时间仅包括计算路由的时间(选择树根、构建多播树、为多播树染色等步骤的时间),不包括发送加入多播组请求、分发路由等其他步骤的时间.
可以发现,2种C-MR4LMS算法的运行时间明显低于MR4LMS算法,最多下降94%.当创建大量多播组而需要进行合并的时候,两者间的差异更加明显.例如,图10(f)所示100×50×26通信模式下,MR4LMS算法运行时间超过575 s,而2种C-MR4LMS算法运行时间均低于35 s,显示出2种C-MR4LMS算法在减少运行时间方面的巨大优势.MR4LMS算法需要尝试大量的树根及颜色,故其运行时间较长,且受多播组大小、网络中颜色使用情况等因素的影响;而2种C-MR4LMS算法直接根据MGID确定树根及颜色,故其运行时间固定,且时间较少.
另外,C-MR4LMS-dynamic运行时间一般略高于C-MR4LMS-fixed,这是因为C-MR4LMS-dynamic需要尝试同一TN内的不同T3交换机做树根.
5 基准测试程序性能
本文在神威E级原型机上对C-MR4LMS算法的集合消息性能进行了测试.神威E级原型机采用神威互连网络,以硬件方式支持同步、规约、广播等集合消息类型,相比点对点消息实现的集合操作具有更低的延时,其拓扑结构为4层胖树.使用了600个终端节点进行测试,这些终端节点分布在4个CN内,每个节点上运行6个通信进程.共测试了4种集合通信类型,包括MPI_Barrier、8 B粒度的MPI_Allreduce、8 B及2 KB粒度的MPI_Bcast.通信模式如下:将所有进程划分为2维网格,为每行及每列均创建1个通信域;每个进程先与同一行的所有进程进行1次集合通信,再与同一列的所有进程进行1次集合通信;所有进程同时进行通信,因此同一时刻有大量多播组在通信;共进行5 000遍测试,由0号进程记录每遍测试中2次集合通信的总时间,2遍测试间不加同步;对每种进程划分方式、每种集合通信类型,本文均测试了4种路由算法的性能,包括全局广播链、MR4LMS、C-MR4LMS-fixed及MR4LMS-dynamic.
5.1 关闭容错时的集合消息性能
首先,测试关闭容错时的性能.表1显示了不同路由算法下的集合消息延迟中位值.另外,图11以小提琴图的形式显示了60×60通信模式下的集合消息延迟分布和概率密度.小提琴图的两侧反映了密度信息,越宽表示出现在该区间的测试数据越多.小提琴图的中间部分以箱线图方式显示了延迟的中位数及上下四分位数,其中上四分位数记为Q3,下四分位数记为Q1,Q3与Q1之间的差值称为四分位数差(interquartile range, IQR),记为IQR.大于Q3+1.5×IQR或者小于Q1-1.5×IQR的值为异常值.IQR越小,表示数据越密集,波动性越小.为便于显示,图11去掉了部分异常值.限于篇幅,未显示其他通信模式下的小提琴图.可以发现下列现象:

Table 1 Median Values of Collective Message Latencies Under Different Routing Algorithms
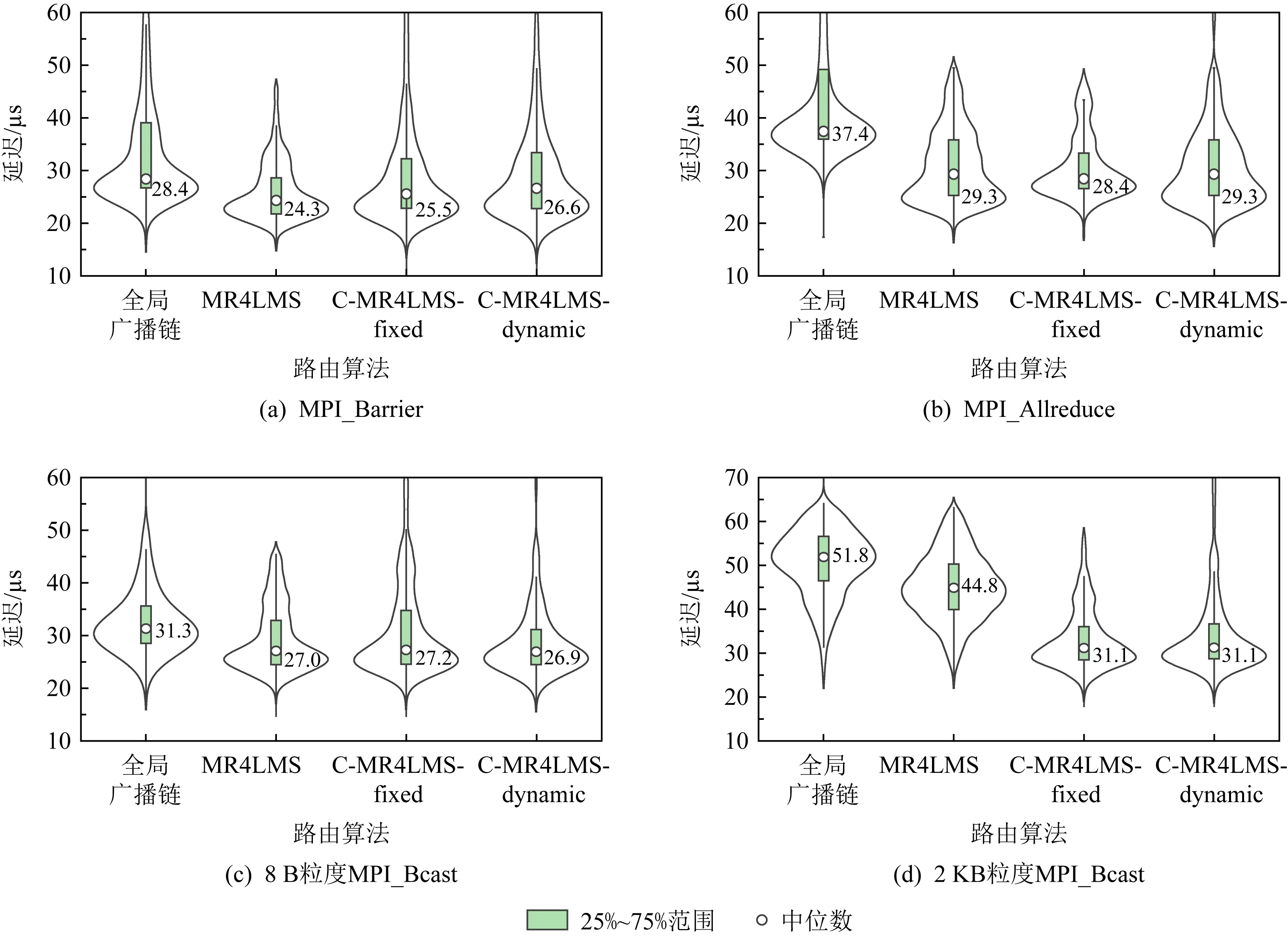
Fig. 11 Collective message latencies under different routing algorithms for 60×60 communication pattern图11 60×60通信模式下不同路由算法的集合消息延迟
1) MR4LMS及2种C-MR4LMS-算法下的延迟明显低于全局广播链.以60×60通信模式下平均延迟为例,C-MR4LMS-fixed与全局广播链相比,MPI_Barrier延迟降低10%,MPI_Allreduce延迟下降24%,8 B粒度MPI_Bcast延迟降低13%,2 KB粒度MPI_Bcast延迟降低40%.另外,全局广播链下,对同一种集合操作来说,不同通信模式下其延迟差异较大,这是因为不同通信模式下的多播组个数不同,而每个多播组都使用同一棵多播树,导致不同通信模式下的链路EFI差异较大,测出的延迟差异也较大.相比而言,MR4LMS及2种C-MR4LMS-算法在不同通信模式下的延迟差异没有这么明显,这是因为这几种算法可以将多播组分布到不同链路上.
2) 2种C-MR4LMS-算法的消息延迟与MR4LMS算法基本相当,2 KB粒度的MPI_Bcast延迟甚至明显低于MR4LMS.这与ibsim中的测试结果一致,即当多播组个数较少时,C-MR4LMS算法的链路EFI低于MR4LMS算法,而2 KB粒度的集合消息对EFI较敏感.
3) C-MR4LMS-fixed与MR4LMS-dynamic算法的消息延迟差异不大,可以认为是测试误差及网络噪音导致了这些差异.
4) 从图11可以看出,4种路由算法在延迟数据的稳定性方面差异不大.
本文也测试了3维环网及随机加入多播组的情况,测试结果与表1及图11类似,不再赘述.
综上所述,当大量多播组同时通信时,2种C-MR4LMS算法下集合消息的延迟明显低于全局广播链,而与MR4LMS算法相当.
5.2 开启容错时的集合消息性能
首先测试容错功能的有效性.通过手工断开某条链路制造故障,然后运行上述基准测试程序,发现全局广播链、MR4LMS均存在收不到消息的情况,而2种C-MR4LMS算法下测试课题均能正常运行.这表明开启容错功能后可以对网络故障进行透明容错.
由于开启容错功能后,原来的1个多播数据包会被复制2份,可能会影响消息延迟.下面以C-MR4LMS-fixed为例分别测试关闭及打开容错功能时的消息延迟,观察容错功能对消息性能的影响.图12显示了60×60通信模式下的测试结果.其中C-MR4LMS-fixed表示关闭容错,C-MR4LMS-fixed-ft表示开启容错.可以发现:1)从延迟中位值的角度看,开启容错功能后MPI_Barrier,MPI_Allreduce的延迟略有下降,而MPI_Bcast的延迟略有上升.2)从分布范围看,开启容错后延迟波动范围略有降低,可以认为有更低的尾延迟.

Fig. 12 Collective message latencies under C-MR4LMS-fixed with and without fault tolerance图12 开启及关闭容错功能C-MR4LMS-fixed算法下的集合消息延迟
上述测试结果表明,多复制一份数据包并不会对消息延迟带来显著影响,反而会缓解因多个多播组相互干扰而带来的性能波动.出现该现象的原因是:终端节点收到第1个数据包后就可做后续处理,因而可以忽略延后到达的多播包,一定程度上抵消网络噪音对多播消息带来的影响.
6 结 论
本文针对胖树拓扑提出一种高效实用的定制多播路由算法C-MR4LMS,在硬件仅支持很小的多播表时,能够快速地为数千甚至数万个多播组构建多播路由.C-MR4LMS在构建多播树时,根据多播组的MGID静态地将多播组映射到1棵生成树中,这带来了下列好处:1)可以快速选择出树根及颜色,从而快速完成多播树的构建;2)构建出的多播树是恒定不变的,重算多播路由不会改变多播树;3)合并多播树时,仅需合并使用同一生成树的多播组,且仅需添加某些链路即可完成多播树的合并,不会改变被合并的多播组的路由.而MR4LMS算法根据各多播链号的使用情况,动态创建多播树,因而多播路由具有动态可变性,即在不同时刻、不同网络状态下为同一多播组构建的多播树可能不同.
实验结果表明,当多播组个数少于不冲突的生成树个数时,C-MR4LMS算法在EFI,TFI方面与MR4LMS算法相当,某些情况下甚至略优于MR4LMS算法.随着多播组个数的增多,C-MR4LMS算法需要进行合并操作,而MR4LMS算法由于可以尝试不同的树根及颜色,不需要进行大量合并操作,在EFI,TFI方面优于C-MR4LMS算法.随着多播组个数的进一步增多,MR4LMS算法也需要进行很多合并操作,此时C-MR4LMS算法大部分情况下又会优于MR4LMS算法.可以认为,很多情况下,C-MR4LMS算法在EFI,TFI方面优于MR4LMS算法;而部分情况下,C-MR4LMS算法在EFI,TFI方面比MR4LMS算法差,但仍在可接受的范围内.基准测试程序也表明,在各种通信模式下,C-MR4LMS算法下的集合消息性能不比MR4LMS算法差,很多情况下还优于MR4LMS算法;而在运行时间方面,C-MR4LMS算法具有明显的优势.
综上所述,在胖树中C-MR4LMS算法的性能可以匹敌MR4LMS算法,而其运行时间相比MR4LMS算法有了显著下降,能够更好地满足大规模并行应用的需求.
另外,C-MR4LMS算法还有需要完善的地方:1)C-MR4LMS采用由用户指定MGID的策略,因此需要用户巧妙地选取MGID,这对用户提出了很高的要求.未来,我们将提供工具帮助用户完成该工作.2)目前C-MR4LMS面向拓扑已知的胖树,影响了其适用性.未来我们将做下列改进:①自动感知网络拓扑结构,动态调整相关的网络参数;②识别故障链路,并将使用该链路的生成树标记为不可用,从而在构建多播路由时避开这些故障链路.但这会导致C-MR4LMS遇到与MR4LMS一样的难题:多播路由受网络状态的影响,具有动态多变性,需要在多播路由的稳定性与适用性这两者间进行适当的平衡.
作者贡献声明:陈淑平提出研究思路,设计并实现算法,进行试验并对实验数据进行分析,撰写并修改论文;李祎参与算法实现、实验验证和数据分析;何王全参与实验数据分析,论文审阅与修订;漆锋滨对课题进行监管与指导,并审阅与修订论文.
