基于自然语言处理的漏洞检测方法综述
2022-12-15杨伊李滢陈恺,3
杨 伊 李 滢 陈 恺,3
1(信息安全国家重点实验室(中国科学院信息工程研究所) 北京 100093)2(中国科学院大学网络空间安全学院 北京 100049)3(北京智源人工智能研究院 北京 100084)(yangyi@iie.ac.cn)
截至2021年5月,CVE(common vulnerability and exposures)上收录的漏洞数量已达到154 504个,如图1所示.近10年来,漏洞数量呈现指数增长态势.据2021年CVE漏洞趋势安全分析报告显示[1],2020年漏洞数量是2010年漏洞数量的5倍之多.当前漏洞类型占比最大的5类分别是代码执行(code execution)、拒绝服务(denial of services, DoS)、溢出(overflow)、跨站脚本攻击(cross-site scripting, XSS)以及信息获取(gain information)[2].报告显示[1],漏洞“CVE-2018-1303”已影响资产数量达到459万台,成为目前影响最广的一个漏洞.因此,漏洞检测成为当前一大热门研究领域.
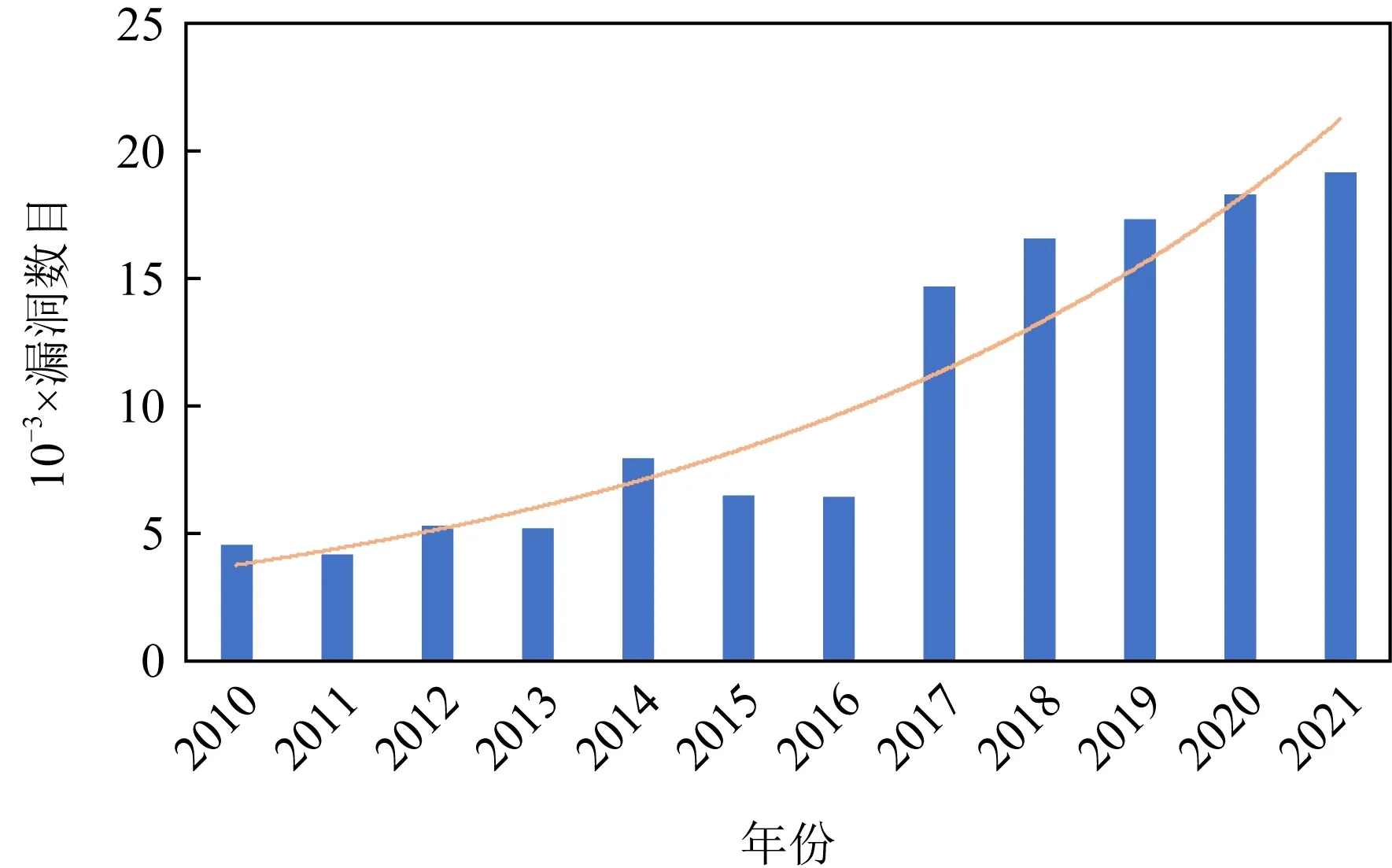
Fig. 1 The numbers of vulnerabilities between 2010 and 2021图1 2010-2021年漏洞数目
随着自然语言处理(natural language processing, NLP)技术的发展,研究人员发现利用这一技术处理分析文本内容或代码能够辅助进行漏洞检测研究.传统漏洞检测方法大多是基于对代码的分析,而NLP技术以分析处理自然语言为主.基于这一前提,通过对当前基于NLP技术实现漏洞检测的研究工作按照数据类型的不同进行分类,可分为官方文档、代码、代码注释以及漏洞相关信息4部分研究内容.
以文本为基础的漏洞检测研究工作可按照数据源的不同划分为基于官方文档[3]、代码注释[4]以及漏洞相关信息[5-6]的漏洞检测研究.有研究表明[7],使用开源软件时存在不遵守使用规范会出现安全问题.例如,setuid函数通常暂时性拥有最高权限,当任务完成时,该函数权限应该被释放,而这一操作需要通过在程序中检查返回值.libstdc库文档中针对这一函数进行了强调“It is a grave security error to omit to check for a failure return from setuid().”通过对文档进行分析,提取文档强调的操作限制,我们发现PulseAudio 0.9.8并没有依照文档的说明进行检查返回值操作,从而导致本地权限逃逸漏洞CVE-2008-0008.这一漏洞出现的原因是开发人员没有遵守文档中强调的安全相关操作导致的.
以代码为基础的漏洞检测研究主要为借鉴NLP技术思想辅助进行漏洞检测研究.由于NLP技术的初期以处理文本内容为主,在处理代码时,通常将代码视为一种特殊的文本[8],需要将NLP技术中的模型或方法加以修改,才能为漏洞检测所用.
本文对从4类数据出发,对利用NLP技术进行漏洞检测的研究进行了详细的成果阐述与讨论.通过对2005-2021年期间在信息安全高水平会议USENIX Security,IEEE S&P,ACM CCS,NDSS以及顶级软件工程期刊会议的相关文献进行梳理,总结并归纳了基于NLP的漏洞检测研究成果,针对当前研究中出现的问题进行梳理,并对未来研究方向进行了讨论与展望.
本文工作的主要贡献有3个方面:
1) 广泛收集并调研了基于NLP的漏洞检测研究领域的现有相关文献,并对该领域成果进行了梳理.
2) 从不同数据源出发,对基于NLP的漏洞检测各研究成果进行横向对比,并分析各成果局限性.
3) 分析当前基于NLP的漏洞检测研究存在的问题,并讨论未来研究方向.
1 相关工作
1.1 自然语言处理(NLP)技术
在利用NLP技术辅助漏洞检测研究的时候,通常是NLP解析器使用标准NLP技术对预处理文本中的每一条语句进行分解,依次利用依存句法解析、词嵌入、命名实体识别、词性标注、语义消歧等操作对语句进行处理,每一步操作解释如下:
依存句法解析(dependency parser)[9]主要是通过分析单词等语言单位之间的语法关系来揭示句子的句法结构,包括主谓关系、动宾关系[10]等.依存句法解析的结果通常表示为有根解析树[11].在树结构中,以动词为中心,所有其他的词汇与动词直接或者间接相连,即对动词起到直接或者间接的修饰作用.
词嵌入(word embedding)[12]是一种语言建模和特征学习的技术[13],可以将文本(单词或短语)从词汇表映射到实数的高维向量,把一个维数为所有词的数量的高维空间映射到一个低维度连续向量空间中,从而消除维数灾难的问题[14],每个单词或词组被映射为实数域上的向量.
命名实体识别(named entity recognition)[15]指的是识别文本中具有特定意义的实体以及可以用名称标识的事物,主要包括人名、地名、机构名以及专有名词等.在计算机领域,一系列的单词或短语是具有特定含义的,如“Google maps”“Twitter”等表示应用名称的词语,而使用语法、句法解析这些短语是不必要的,所以通过命名实体识别操作能够进一步辅助文本分析.
词性标注(part-of-speech tagging, POS)[16]是基于上下文将文本中的单词标记为对应于特定词性如名词、动词、形容词等的过程.
词义消歧(word sense disambiguation, WSD)[17]是NLP中的核心与难点.在词义、句义、篇章含义层次都会出现语言根据不同上下文产生不同语义的现象,消歧即指根据上下文确定对象语义的过程[18].
以上各步骤构成了NLP的预训练内容.而当前预训练模型被划分为词嵌入模型如Word2Vec,GloVe,ELMo和多用途的NLP模型如Transformer和BERT.词嵌入模型Word2Vec[19]通过随机值初始化词表示[20],并通过应用连续词袋或跳过词将词上下文的联合概率分布用作其输入模型[21];然后在神经网络的训练过程中利用这种分布,其中单词向量会不断更新以使联合概率最大化.训练的结果确保相关词被赋予其相似上下文的近似向量,不相关的词被映射到不同的向量中,而词与词之间的语义差异通常通过向量之间的余弦距离进行测量[22].2014年,Pennington等人[23]提出了GloVe模型,将语料库的全局统计和局部的上下文特征结合.2018年,Peters等人[24]提出了ELMo模型,解决了Word2Vec模型和GloVe模型无法解决的多义词的情况.将一句话或一段话输入模型后,ELMo模型能够依据上下文推断每个词对应的词向量,能够很好的完成词义消歧任务.
注意力机制(attention mechanism)最早被用来解决图像识别领域的技术问题.2014年,在Google Mind[25]团队利用注意力机制进行图像分类后逐渐进入其他领域.同年,Bahdanau等人[26]将注意力机制引入机器翻译任务中.NLP领域使用较广的预训练模型Transformer[27]的核心就是注意力机制.该模型完全依靠注意力机制绘制输入和输出之间的全局依赖关系,其本质上是一种Encoder-Decoder的结构,以3种不同的方式使用多头注意力机制.在Transformer模型的基础上,Google研究人员于2018年提出了一种基于Transformer模型Encoder结构的模型BERT[28].该模型的预训练部分与Word2Vec和ELMo相似.由于计算机无法直接识别文本,需要对文本进行编码.词向量模型提取词的语义特征,向量之间的距离代表其语义相似性,BERT预训练模型可以使一个词在不同的语境下生成不同的词向量[29],为文本分类和词性标注等后续下游任务提供支持.
1.2 漏洞检测与分析
漏洞是网络和安全的根源,是信息系统的硬件、软件、操作系统、网络协议、数据库等在设计上、实现上出现的可以被攻击者利用的错误、缺陷和疏漏[30].漏洞攻击通常包含漏洞发现、漏洞分析和漏洞利用这3个步骤.而漏洞检测指的是对信息系统所用软硬件进行研究,找出存在的可能威胁信息系统安全的薄弱环节.目前常见的漏洞检测技术包括静态和动态2类方法.静态检测技术指的是在不执行应用程序源代码的情况下[31],从语法和语义上理解程序的行为,直接分析被检测程序的特征,寻找可能导致错误的异常,包括潜在的安全违规、运行时错误以及逻辑不一致[32]等情况.基于源代码的静态分析方法主要有数据流分析、抽象解释和符号分析3种方法[33].
Gosain等人[34]分析了主流的静态分析技术和工具,并按照静态分析工具的功能对其进行了分类,分为静态检查、漏洞发现、软件验证以及类型限定符推理4类.其中静态检查即为查找普通的编程错误,包括可疑赋值、未使用的变量、无法访问的代码等;漏洞发现表示发现安全编码引起的缺陷(例如缓冲区溢出)、导致程序崩溃的缺陷(例如空指针引用)、不正确的程序行为(例如未初始化变量)等;软件验证即通过静态分析进一步证明程序是否符合规范;属性推断则是捕获类型限定符之间的关系.结合当前研究成果的分析,我们对当前的静态分析工具进行归类梳理,如表1所示:

Table 1 Comparison of Static Analysis Tools表1 静态分析工具对比
数据流分析的目的是分析变量沿着程序执行路径的流动过程[52],即获取有关程序运行时行为的信息的过程,不会使用语义运算符[53].在基于数据流的源代码漏洞分析中,通常包含代码建模、程序代码模型、根据规则进行漏洞分析以及检测结果的分析.在数据流分析时,根据程序路径的分析精度分为流不敏感分析、流敏感分析和路径敏感分析;根据程序路径的深度进行分类时,分为过程内分析(只考虑函数内的代码进行分析)和过程间分析(考虑函数之间的数据流).而在一般情况下,程序漏洞的特征恰好可以表现为特定程序变量在特定的程序点上的性质、状态、或者取值不满足程序安全的规定,所以应用数据流分析恰好可以检测这些漏洞[53].
抽象解释是一种数学结构的近似理论,它涉及语义模型的数学结构[54],是对计算机程序的部分进行执行,然后获取关于它的语义信息的理论,其目的是找出程序在运行时的语义错误,比如除以0或者变量溢出.而抽象解释在计算资源上可能比较昂贵,所以必须选择适当的值域和适当的启发式循环终止来确保可行性.抽象解释的优点在于具有良好的扩展性[55],可以对许多有价值的属性构造格,其缺点在于只能针对简单的属性,如“状态”“值”以及对时序性质支持较弱.
符号分析指的是使用符号值而不是实际数据作为输入,将实际变量的值表示为符号表达式,得到每个路径抽象的输出结果[56].
总的来说,静态检测有以下特点:不局限于特定的代码执行路径,能够实现程序的全面分析,并且由于静态分析不需要运行源代码,可以在程序代码执行前验证其安全性.目前常见的静态分析工具如表1所示,其他常用的静态分析工具还包括Dex2jar[57],IDA[58],GDA[59],Jeb[60]等.
模糊测试(fuzzing)是一种半自动化动态漏洞检测的方法.其本质是向程序中插入异常的、随机的输入来触发程序中不可预见的代码执行路径或漏洞.Manès等人[61]调研了当前Fuzzer的相关文献以及成果创新,对列举的模糊测试工具进行了全面的功能概述和比较.然而,综述中欠缺了对未来模糊测试工具研究方向的思考.模糊测试的方法通常根据目的分为2种类型:基于路径覆盖率的模糊测试方法(coverage-based fuzzing)和导向型模糊测试方法(directed fuzzing)[62].
基于覆盖率的模糊测试方法是发现漏洞、错误或者崩溃最有效的技术之一[63].它的目的在于生成输入以遍历应用程序的不同路径,从而在一些路径上触发错误[64-69],即最大化覆盖路径从而触发可能包含错误的路径.当前主流基于路径覆盖率的漏洞检测工具包括AFL[64],libFuzzer[65],honggfuzz[66],AFLFast[67],VUzzer[68],CollAFL[69]等.
导向型模糊测试指的是在潜在漏洞位置已知的情况下,寻找可以触发漏洞的PoC(proof of concept),即有针对性地生成一组输入[70].目前常见的导向型模糊测试方法包括AFLGo[71],SemFuzz[5],Hawkeye[72]等.
2 基于NLP技术的漏洞检测研究
随着NLP技术的发展,提供丰富知识的文本信息,例如,官方文档、技术博客、论坛以及代码注释等能够被用来进行漏洞检测的文本信息.除此之外,代码也成为利用NLP技术进行漏洞检测的主流数据源之一.这些信息为开发人员提供了额外的知识,从一定程度上填补了开发人员的知识空白.通过对文献的调研,分别从官方文档、代码、代码注释以及漏洞相关信息4部分内容出发,总结利用NLP技术从文本和代码等信息中提取相关知识,从而实现漏洞检测的相关研究成果并对其进行讨论与分析.基于各类数据源的文献数量占比如图2所示.
我们将当前各部分基于NLP的漏洞检测研究按照时间顺序进行了整理,如图3所示.从图3可以看出,研究初期主要是针对不同类型文本数据进行漏洞检测研究探索,后期在利用NLP技术广泛拓展文本数据的基础上,提出利用NLP技术思想对代码进行漏洞检测的探索研究工作.

Fig. 2 The percentage of quantities of literatures based on vulnerability detection type图2 各类漏洞检测研究文献数量占比
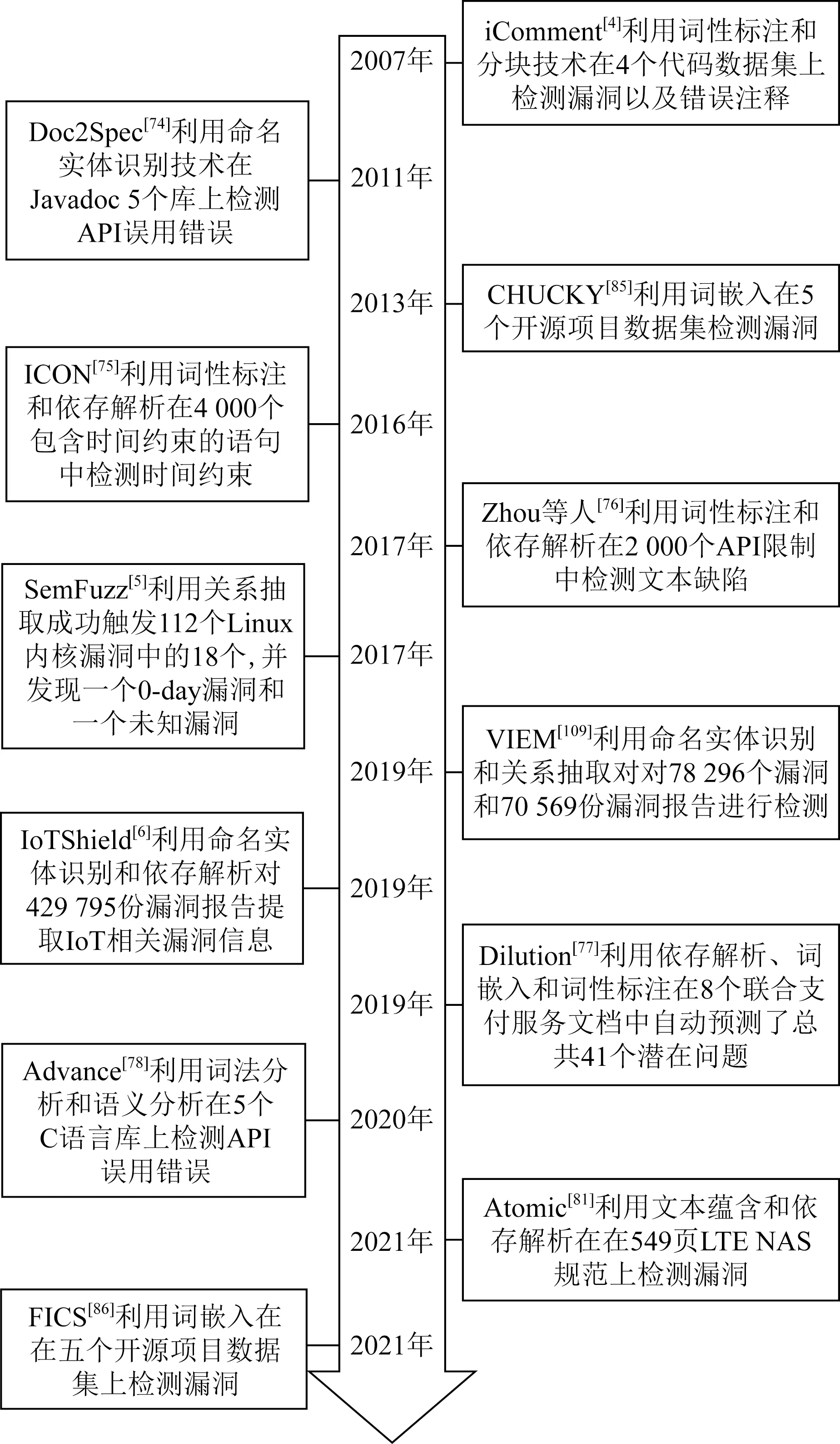
Fig. 3 The development of the vulnerability detection researches based on NLP图3 基于NLP的漏洞检测研究发展历程
2.1 基于官方文档的漏洞检测研究
应用程序或源代码中的漏洞发现通常依赖于程序分析,而直接利用程序分析或软件测试技术检测漏洞存在一定的局限性:1)通过人工分析一系列的代码来推断正确的函数调用规则.这一过程需要大量专家知识辅助完成,主观性较强,会引入大量的误报[73].2)代码集的覆盖范围可能导致遗漏许多漏洞,产生漏报.
软件开发过程中,开发人员通常需要阅读官方文档来合理使用文档中的应用程序接口(application programming interface, API)或函数(function),从而实现软件的开发任务.文档通常描述了函数或API的使用限制及格式.然而,文档撰写人员和开发人员之间存在一种信息不对称:当开发人员错误理解文档内容或错误使用了API时,将产生API误用错误,这一错误可能会在特定情况下引发多种漏洞,包括内存泄漏和拒绝服务等,从而导致程序的崩溃.因此,针对这一类漏洞的检测研究显得极为重要.这一部分研究包括利用NLP技术对文档进行信息提取和分析检测文档中的错误以及代码中的漏洞.
因此近年来,有不少利用NLP技术对官方文档进行分析,从而实现漏洞检测或者辅助漏洞检测的研究,包括检查文档声明与实现的不一致性、以及文档中的逻辑缺陷等.Zhong等人[74]提出了Doc2Spec的方法,利用NLP技术分析API文档,自动从文档中推断资源规范,他们将命名实体识别技术用来分析文档,基于隐马尔可夫模型(hidden Markov model, HMM)使用命名实体识别技术,在HMM的五元组中融入词性特征.该方法在JavaDoc的5个库上进行了评估,结果表明该方法推断的规范具有相当高的精确度、召回率和F1分数,并且对API文档和源代码之间的不一致检测是有效的.但是与传统的静态分析相比,该方法可能导致更高的误报.Pandita等人[75]提出了ICON,利用NLP技术解析API文档,通过词性标注、短语和从句解析以及类型依赖从文档中提取API的调用序列,从而检测代码中的不一致性.实验结果表明ICON可以有效地识别时间约束语句,平均准确率达到70%.Zhou等人[76]利用NLP技术分析文档中与参数约束和异常抛出声明相关的指令,利用了词性标注和依存句法解析从文档中自动提取约束,从而检测API误用的缺陷,在2 000种API的使用限制条件下,可以检测到1 158个缺陷,准确率为82.6%、召回率为82.0%.Chen等人[77]提出了Dilution,根据付款服务的付款模型和安全要求,自动检查联合支付文档.他们利用词性标注和依存句法解析分析官方支付文档的句子、识别句子的句法元素并且明确它们的语义、利用词嵌入模型并计算余弦相似度识别文档中的同义词,最终在8个主流的联合服务共1 456 KB文档中(包括Ping++,Paymax,BeeCloud等),自动预测了总共41个潜在问题.Lv等人[78]提出了自动化利用NLP技术分析C语言库文档的工具Advance.首先利用情感分析提取文档中的API使用指导和限制条件,然后利用频繁子树挖掘并识别常用的代码描述,最后利用词法分析和语义分析进行参数的解析,从文档中提取这些约束并且在5个库(OpenSSL,SQLite,libpcap,libdbus,libxml2)和39个应用上进行了评估,发现了193个API误用错误,其中139个为未知错误,达到了88%的平均准确率,高于APEx[79]和APISAN[80]的21.6%和12%,在API误用错误检出率上,Advance也有了较大提升.然而,由于一些限制条件在文档中并不常见,将会在检测中引起漏报.Chen等人[81]提出了Atomic,从蜂窝移动网络的大量技术文档中自动发现蜂窝移动网络中的漏洞,利用NLP技术中的文本蕴含和依存句法解析,从大量的LTE文档中自动发现某个事件发生在某个状态时描述危险操作的语句,从而恢复状态和事件信息生成测试用例,进一步检测LTE设计和实施中的漏洞,并且在549页的LTE NAS规范上运行Atomic后发现了42个漏洞,其中包含10个从未被报告的漏洞.
以上研究均借助了官方文档,主要利用NLP技术中的命名实体识别、词性标注、依存句法解析、语法分析、语义消歧等对自然语言文档进行分析,从文档中提取规则和约束等,从而辅助代码中漏洞的发现.
除了针对代码的漏洞检测,研究人员同样对文档本身的漏洞和错误展开研究.计算机软件包括程序和文档,所以文档的正确性对于软件项目的成功也至关重要,而在检测源代码的漏洞之前,文档中可能也存在错误,直接检测文档中的错误有助于加速代码审核的速度.因此,Zhong等人[82]结合代码分析技术和NLP技术来自动化检测API文档中的错误并且以相对较高的精度和召回率检测了1 000多个JavaDoc中以前未知的错误.以上研究主要利用依存句法解析来分析文档,从而检测其他文档中的缺陷.在整个漏洞检测的过程中,NLP主要对文本内容分析起到了辅助的作用,自动化分析文档并且提取文本中的信息,从而辅助源代码或应用程序文档中的漏洞分析.
讨论与分析1.本文列举了基于官方文档的漏洞检测研究中的6项代表性成果,如表2所示,分别从数据源、主要NLP技术、效果以及缺陷等部分进行横向对比.研究人员针对漏洞检测中的高误报和高漏报现象,提出将官方文档作为漏洞检测的重要数据来源.当前研究成果能够检测出Use-After-Free漏洞、内存泄漏、DoS拒绝服务漏洞、信息泄露等多种漏洞类型.由表2可知,当前基于官方文档信息进行漏洞检测的研究对象以Java和C++等高级程序语言为主,利用NLP技术,从官方文档中提取API使用约束并进行漏洞检测研究.大部分研究使用了词性标注和依存句法解析的方法,对文本中与API使用的相关限制信息进行提取和分析.随着研究的发展,研究中采用的NLP技术也从简单的提取关键信息,转变到对文本中信息进行理解再提取信息,在提取API限制信息的准确率上也有了提升.
同时,研究也存在一定的局限性:
问题1.提取文档中API使用限制的方法存在一定局限性:例如,Advance和Atomic难以处理描述模糊的语句,会产生一定的误报或漏报.
问题2.研究能够检测的漏洞类型相对单一:例如,Atomic仅能检测DoS相关的漏洞类型.
在未来的研究工作中,研究人员可探索的内容为:1)如何解决NLP技术难以处理文本信息中描述模糊的语句问题;2)如何解决利用官方文档进行漏洞检测时漏洞类型单一的问题.总体来说,基于官方文档的漏洞检测研究补充了一部分从代码中无法获取的知识,辅助更加全面的漏洞检测研究.自动化检测文档中的缺陷与错误,能够为程序分析(例如模糊测试)提供指导,从而更有效地检测漏洞.
2.2 基于代码的漏洞检测研究
NLP技术已在自然语言分析与理解领域广泛应用.然而,对于代码的理解,以及从代码中检测漏洞仍有较大的研究空间.调研发现当前以源代码作为输入数据来辅助漏洞检测的工作借鉴了NLP技术思想,下面将详细阐述这部分研究工作.
由于自然语言(natural language, NL)和编程语言(programming language, PL)本质上的区别,当前NLP技术难以直接应用到源代码中进行漏洞检测.因此,研究人员提出借鉴NLP技术的思想通过一些模型变体对源代码进行分析处理,从而实现漏洞检测任务.
由于源代码的数量巨大,人们很难仅从源代码中归纳并提取出编程规则的限定条件.因此,Engler等人[83]提出了一种自动化提取某段代码中的约束限定条件的方法.在不需要额外信息的情况下,仅从源代码中提取函数的使用限定.提出“以大多数代码的表现形式为基准,少数与这些形式不同的代码为潜在错误”,这一思想也被后续应用到各项研究中.这一方法应用广泛,为大量从源代码中检测漏洞的工作提供了新思路.
基于Engler的工作,Wang等人[84]提出“当一种模式没有以很高的频率出现时就不会形成规则,将会对漏洞产生漏报”.在代码集上出现频率较低的标记序列是不正常的,这些标记序列可能会导致错误和漏洞.研究提出了一个新工具Bugram,利用n-gram语言模型对程序的调用序列进行统计,并进行漏洞检测.该工作在14个Java项目上检测出21个真实漏洞.
另一些工作围绕Engler提出的思想,探索了直接在代码集中检测漏洞的可行性.由于无法实现对系统中的大部分漏洞的自动化检测,在大规模代码中进行漏洞检测长期依赖于对代码的人工审核,导致这一工作的效率变低.同时,研究人员发现,许多漏洞是由不充分的输入验证导致的,因此忘记检查输入或错误检查输入为漏洞检测提供了重要的信息.因此,Yamaguchi等人[85]提出了一项工作CHUCKY,通过对代码进行污点分析并识别出安全关键性对象的异常或缺失条件,加速人工代码审核的过程.研究人员以“大多数代码的表现形式为正确的”这一观察为基础,认为缺少检查或错误检查是罕见的事件、并且对软件项目中的安全关键性对象施加的大多数条件都是正确的.因此,CHUCKY通过对给定函数源码进行语法分析,在代码集上对具有相似的函数进行检测,确定与给定函数相关的安全检查,对给定函数和与它相似的函数进行分析,最终计算出一个模型对函数进行正态分析,并实现对缺失安全检查的检测.研究人员发现安全检查通常和代码上下文内容高度相关.在检测相似函数时,CHUCKY将使用相似API符号的函数称为相似函数,并借鉴NLP中的词袋模型(bag-of-words model),将代码集中的函数与向量空间匹配,维度是API符号在代码中出现的频率,使用相似API符号的函数在此向量空间中邻接出现,反之,距离越大函数的内容越不同.在对函数进行嵌入部分,同样借鉴了NLP中的词嵌入(word embedding)方法从上一阶段中的限制条件提取表达式,从而解决安全检查描述中的细微语法差异.基于函数的嵌入这一操作,CHUCKY能够在向量中根据距离检测缺失检查的操作,并辅助安全研究人员进行代码审计.实验表明,CHUCKY作为一项辅助工具,无需额外的数据和信息,能够一定程度辅助提高人工审计的效率.在5个开源项目(Firefox,Linux,LibPNG,LibTIFF,Pidgin)上进行检测,在其中2个项目上发现了12个未知漏洞.然而,这一工具也存在一些研究缺陷,例如,与缺失安全检查无关的一些漏洞是无法被检测出来的;尽管这一工具能够指出潜在的安全问题,但不能确认这一问题导致安全漏洞的必然性;同时,这一工具在成熟的代码项目中更加有效.
当前研究尝试了从已知漏洞学习规则来检测未知漏洞,这一方法已经形成了大范围的应用.但这一方法存在一定的缺陷:1)模型训练的过程需要输入大量已知漏洞的数据,才能在一定程度上降低模型的误报率;2)大多数模型只能实现针对特定类型漏洞的检测.
针对这一研究现状,Ahmadi等人[86]提出了一个工具FICS,无需已知漏洞数据集或额外信息进行模型训练,就能够检测出数据集中的已知漏洞和未知漏洞.同样延续了Engler等人[83]提出的理论,FICS以大多数代码的形式为基准,以偏离这些代码的表现形式作为检测漏洞的基础,实现了在5个现有开源项目数据集(QEMU,OpenSSL,wolfSSL,OpenSSH,LibTIFF)上检测功能相似但表现形式不同的潜在错误代码,称之为“不一致相关漏洞”.FICS从当前代码集上提取代码片段(construct),利用2步聚类方法来检测代码中功能相似的代码片段,最后检测这些片段中与大多数代码形式不一致的部分实现对不一致漏洞的检测.FICS利用了程序的数据依赖图(data dependency graph, DDG)来提取代码片段,该图通过保留程序依赖图(program dependency graph, PDG)中的数据依赖边、去掉控制依赖边生成.从根节点出发,遍历数据依赖图中的所有子节点,当遍历所有子节点或达到construct最大深度时,形成了最终的construct.根节点和最大深度能够唯一确定construct.在第1步进行相似construct聚类的过程中,Ahmadi等人[86]发现如果排除边,能够最大程度的不影响计算construct的相似性.因此,借鉴了NLP中词袋模型思想,提出了“bag of nodes”方法:只考虑construct中的节点,将每一个construct嵌入1个节点向量中,通过计算每一个节点向量的余弦相似性,这一方法能够有效的检测相似的construct.这一工作在5个开源软件上进行测试,发现了22个新漏洞.但这一工作也存在一定局限性,对于代码量过小和过大的工程检测效果并不是很好;对于细微漏洞来说,FICS的检测效果并不好,原因是FICS工具中的construct粒度仍然比一些漏洞要大.
同样在其他研究工作中,也借鉴了NLP技术中“词嵌入”思想.当传统基于控制流程图的检测工具无法在大规模的IoT设备上实现漏洞检测时,Geniu[87]能够很好地解决这一问题,将控制流程图转换到高阶数字特征向量中.这一工作对8 126个Firmware Images中的420 558 702个函数进行实验,在最终结果中发现了5个厂商的38个潜在脆弱的Firmware Images.同时,另一项工作也借鉴了这一思想.因为代码中变量和函数的名称在一定程度上能够为检测代码中某些种类漏洞提供语义信息.然而当前研究往往忽略了这一信息,导致漏洞检测工具可能会对某些漏洞产生漏报.因此,Pradel等人[88]提出了一项新技术“DeepBugs”,能够从代码名称中将语义相似的标识符识别出来.借鉴NLP的“词嵌入”思想,将标识符进行嵌入操作,辅助识别具有相似语义的标识符.该工作在12万个JavaScript文件中检测出102个程序误用,达到了至少89%的准确率.针对抄袭检测、恶意软件检测以及漏洞检测等任务,跨平台二进制代码的相似性检测极为重要.现有研究使用相似图匹配的方法进行相似性检测,这一方法在一定程度上非常耗时且容易出错,普适性差.Xu等人[89]提出了一项工具Gemini,对每一个二进制函数生成其控制流程图,对他们进行嵌入向量的操作,通过计算向量间的距离来检测相似性.这一思想同样也借鉴了NLP技术中的“词嵌入”思想.实验表明,Gemini能够将模型训练速度从1周的时间降至30 min到10 h.同样地,与Genius相比,Gemini能够检测出更多有潜在漏洞的Firmware Images.Saccente等人[90]提出了Project Achilles,利用词嵌入对源代码进行表征,然后利用长短期记忆循环神经网络(LSTM RNN)来检测源代码中的漏洞.在使用44 495个测试用例检测后发现,可以对29种不同类型的CWE漏洞中的24种达到高于90%的检测准确率,但其对于其他漏洞类型的检测仍有不足.Wang等人[91]提出了FUNDED,这是一种用于漏洞检测的模型框架.它利用词嵌入对代码的语法信息进行学习,从而进行初始化节点嵌入.FUNDED利用图神经网络(GNN)来捕获程序的控制、数据和调用依赖.利用该框架评估在大型真实世界数据集上C,Java,Swift,Php编写的程序,表明其性能优于其他替代方法.尝试在5个开源项目的不同版本中进行漏洞检测,在56个漏洞中共检测出了53个漏洞,达到了95%的准确率.但该方法同样对不同漏洞类型的覆盖度不足.
讨论与分析2.本文选择4项具有代表性的基于代码的漏洞检测研究进行横向对比,如表3所示.由于NLP技术最初被用来处理文本信息,因此,当前针对代码的漏洞检测研究仅借鉴了NLP技术中“词嵌入”的思想,但数据源大多为Github中的开源代码项目,通过对代码进行降维处理从而达到后续漏洞检测的目的.当前基于代码的漏洞检测研究成果既可以以较高准确率对已知漏洞进行检测,还可以检测出未知漏洞.由于基于代码的漏洞检测研究覆盖率依赖于代码规模,在代码量一定的前提下,研究人员提出了借鉴NLP技术思想,将代码转换为低阶向量,这一操作能够一定程度降低通过进行图比较产生的损耗.
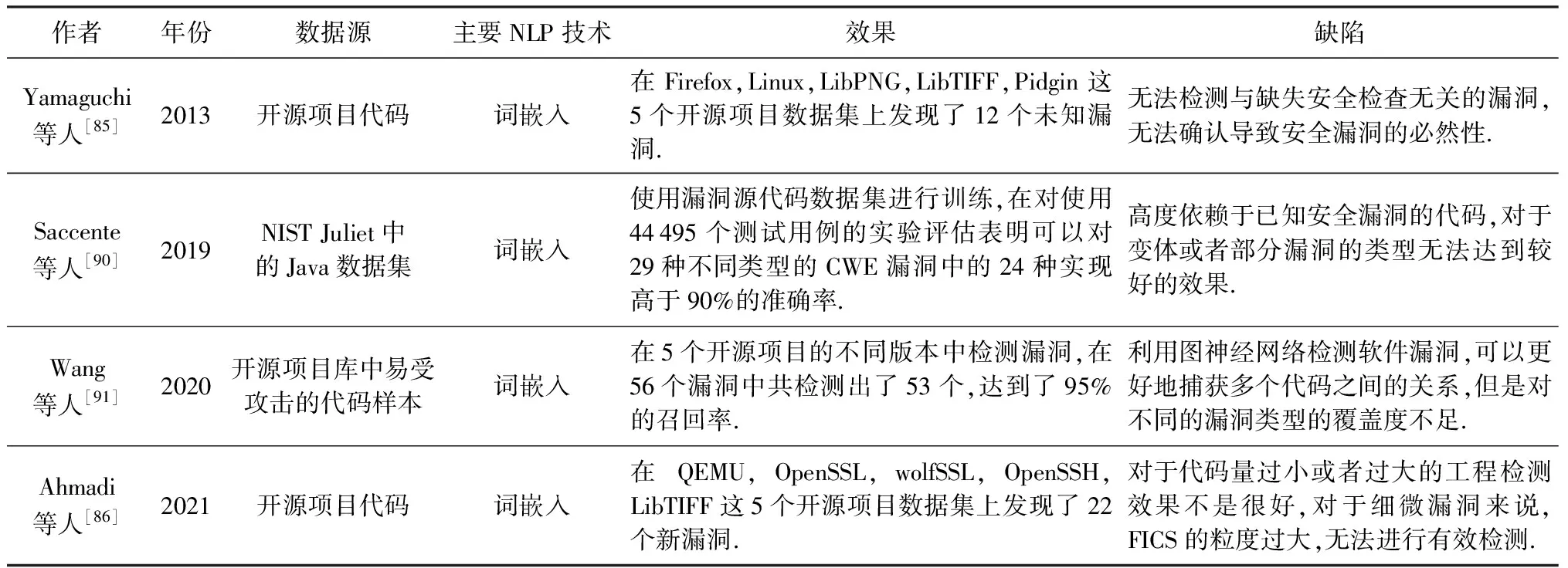
Table 3 Comparison of Vulnerability Detection Based on Code表3 基于代码的漏洞检测对比
然而,现有研究成果也存在一定的局限性:
问题3.研究针对代码量规模有一定要求:例如,FICS针对代码量过大或者过小的工程检测效果一般.
问题4.部分研究存在漏洞检测的单一性:例如,CHUKCY难以检测与missing-check漏洞无关的其他漏洞类型.
因此,未来研究工作中潜在的研究方向可归纳为:1)如何解决代码量级对漏洞检测效果的影响问题;2)如何在单一数据源上实现检测多种漏洞类型的问题.总体来说,基于代码的漏洞检测研究从另一方面为研究人员提供了研究思路.从开发人员的角度出发,借鉴NLP技术思想辅助漏洞检测效率的提升,在无需额外文本信息的辅助下实现相对高效的漏洞检测,但如何实现针对多种类型的漏洞检测仍是未来需要探索的方向.
2.3 基于代码注释的漏洞检测研究
相对于程序代码,代码中的注释更加直接,描述清晰且易于理解[92].Woodfield等人[93]对48名资深程序员进行了一个问卷调查,结果表明对于程序员来说,带有注释的代码更容易被理解.因此,开发人员会把代码实现的功能以及对代码操作的限制条件写在注释中.这些注释语言为漏洞检测研究提供了极大的帮助.例如,微软开发的源代码注释语言(source-code annotation language, SAL)可以用来注释函数的参数和返回值[94].这一注释语言不仅可以帮助用户清晰地表达代码含义,还能够辅助静态分析工具以低误报率和低漏报率自动化且准确地分析代码.SAL注释[95]帮助检测了Windows代码中的1 000多个潜在安全漏洞[96].看到SAL的成功,微软最近提出了新的注解,包括与并发相关的注释.此外,其他几种注释语言,包括来自Linux内核社区的Sparse[97],Sun的Lock_Lint[98]和SharC[99],研究了与并发相关的问题.代码注释包含了程序开发中需要注意的限定条件,然而由于自然语言表述不够直接且规模巨大,使得从代码注释中提取程序编写的限定条件,并利用这些信息进行漏洞检测的工作难以自动化[100].因此,Tan等人[4]提出了利用NLP技术对代码注释进行自动化分析,并将其语义和代码进行比较,检测他们之间的不一致,检测潜在安全漏洞及恶意代码注释的工具iComment.这一工具在Linux,Mozilla,Wine,Apache这4个代码集上提取了1 832条锁相关和调用相关的限定规则,准确率达到90.8%~100%,并检测出33个新漏洞和27条错误注释.然而,这一工具在检测其他类型错误时有一定的局限性:iComment在处理“中断相关(interrupt-related)”的注释时,准确率会降低.因此,Tan等人[101]提出了新的工具aComment,从注释和代码中提取“中断相关”的前置和后置条件,再利用这些信息检测程序中和中断相关的并发缺陷.
这一工作从Linux内核中提取96 821条中断相关的注释,并检测到9个操作系统的并发缺陷,这些错误可能会导致并发攻击,使得攻击者攻击系统的机密性、完整性和可用性[102].2012年,Tan等人[103]基于先前的研究继续提出了tComment工具.由于Javadoc文档的规范性,无需利用NLP技术对注释进行处理.工具检测出28个不一致错误,其中12个已经被确认.以上研究工作将关注点聚焦在C/C++编写的系统代码上和锁协议(locking protocol)、函数调用以及中断错误上.因此,在检测其他类型漏洞时具有一定的局限性.然而,这些研究为基于文本的漏洞检测研究提供了新的数据源方向.检测代码注释与函数实现之间的不一致也帮助研究人员发现了大量未知的漏洞.Wong等人[104]提出了DASE来改进自动化的测试生成以及错误检测.DASE利用自然语言处理中的语法关系来分析程序的文档(手册和代码注释)自动提取输入约束.DASE在对在5个广泛使用的软件套件(GNU COREUTILS,GNU FINDUTILS,GNU GREP,GNU BINUTILS,ELFTOOLCHAIN)的88个程序上进行评估,发现了12个未知的错误.但该方法专注于几种错误类型,对更多的错误类型的可行性未知.Rabbi等人[105]使用Siamese recurrent network解决了代码和代码注释序列的不一致问题.利用词嵌入思想对代码和代码注释进行向量化表示,利用2个单独的RNN-LSTM模型分别输入代码和注释,从而检测代码与注释的相似度来发现不一致的问题.实验表明,在对300个代码注释对进行评估后,召回率达到91.7%,精确度63.2%.代码注释有助于提高代码的可读性,而开发人员通常会忽略更改代码后的注释更新,从而导致代码与注释的不一致.因此,Zhai等人[106]提出了CPC,即利用程序分析来传播注释.CPC将词嵌入思想用于注释分类器的分类,利用依存句法解析提取注释中词汇之间的依赖类型从而完成对注释的特征提取.CPC同时使用程序分析来传播注释,派生的注释用于检测5个实际项目的代码,并检测出37个新的错误代码,其中30个已由开发人员确认并修复.此外,CPC还发现现有注释中存在304个缺陷,其中包括12条不完整的注释以及292条错误注释.但是该方法不是上下文敏感的,无法识别传递触发函数返回null或-1的参数的情况.
讨论与分析3.本文将4项具有代表性的基于代码注释的漏洞检测研究成果列举出来,如表4所示.研究人员利用NLP技术对代码注释进行语义提取,并将其与代码进行比较,检测两者间不一致导致的漏洞成为近年来的一个新兴研究方向.当前研究成果中,大多数采取词嵌入以及依存句法解析的方法对代码注释进行关键信息提取,辅助实现对开源代码的漏洞检测.当前研究不仅能够实现对未知漏洞或错误的检测,还可以对代码注释中的错误或不一致情况进行检测.
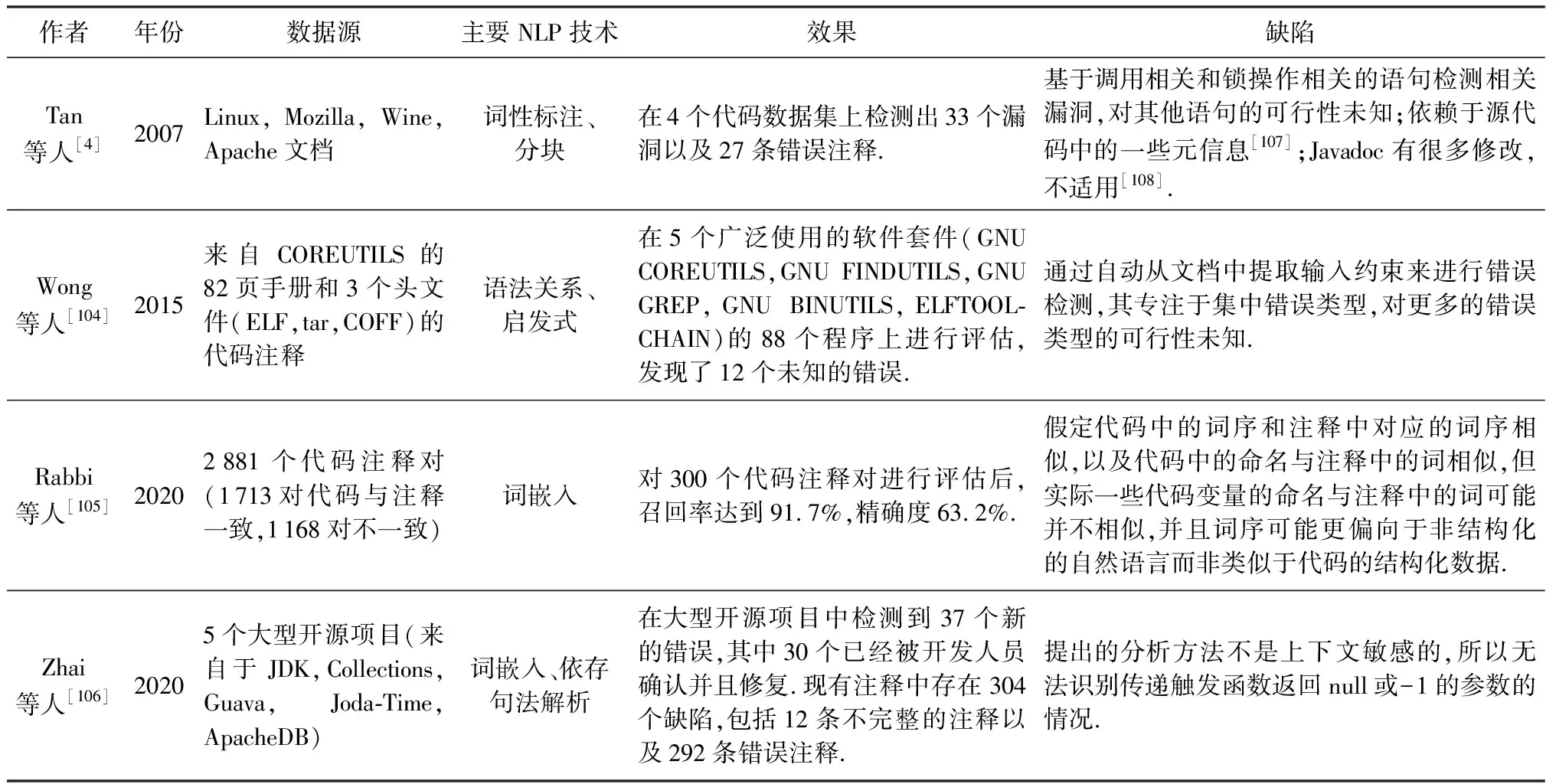
Table 4 Comparison of Vulnerability Detection Based on Code Comment表4 基于代码注释的漏洞检测对比
代码注释能够帮助其他开发人员更好地理解代码,同时也帮助研究人员从注释中找出代码实现上的问题.然而这一研究方向的成果也存在一定的局限性:
问题5.研究工具的普适性还有一定的提升空间.例如,iComment将研究重心放在了锁相关和调用相关的限定规则中,aComment将研究点落在中断相关的限定规则中,这2个工具在单一领域的运用效果不错,但是难以提取其他领域的规则并进行漏洞检测.
问题6.研究在跨语言平台不够友好.例如,当前研究仅针对C/C++编程语言的代码注释进行分析,在检测一致性时仅能够对单一开发语言进行处理分析,对于多种开发语言的适用性未知.
因此,在未来的研究工作中,研究人员可尝试探索如何保证利用代码注释进行漏洞检测时形成的工具具备更好的普适性,使得工具能够在跨语言平台的检测效果更好.
2.4 基于漏洞相关信息辅助漏洞检测研究
本文将漏洞相关信息分为官方给出的漏洞信息(CVE[109]和NVD)以及第三方漏洞描述信息(如漏洞报告,漏洞利用数据库).接下来,将分别从这2部分内容出发,对基于漏洞相关信息辅助漏洞检测的研究成果进行梳理与总结,并对成果中存在的问题进行分析并给出潜在未来研究方向.
CVE[109]是由US-CERT发起的针对公众已知的信息安全漏洞和披露的参考系统.截至2021年6月,CVE中已包含153 821个漏洞的描述信息.种类包括代码执行、DoS、溢出以及XSS等.
在模糊测试这一过程中,有研究人员发现漏洞相关信息能够辅助进行漏洞检测工作.结合CVE中的漏洞描述,You等人[5]提出了一个新的模糊测试工具SemFuzz,该工具利用NLP技术对漏洞描述和Linux git logs进行分析,提取漏洞相关的信息,例如,受影响的版本、漏洞类型、有漏洞的函数,以及系统调用等.利用这些信息,SemFuzz能够生成针对Linux内核的模糊测试用例.该工具成功触发了112个已知Linux内核漏洞中的18个,并发现了一个0-day漏洞和一个未被披露的漏洞.当前大部分基于文本分析的漏洞检测研究集中在对官方文档的分析上,SemFuzz提出了一个新思路,利用漏洞描述信息来辅助进行漏洞检测工作,这一工作也为后续利用官方文档以外的文本信息进行漏洞检测提供了新的方向.
同样,CVE和NVD(national vulnerability data-base)上有关漏洞的描述促进了威胁情报的共享,为漏洞检测的上游任务提供了依据.Gartner认为威胁情报(threat intelligence)是一种基于证据的知识,包括了情境、机制、指标、影响和操作建议.它描述了现存的、或者是即将出现针对资产的威胁或危险,并可以用于通知主体针对相关威胁或危险采取某种响应[110].然而,对于平台上大量的漏洞信息,有研究人员发现第三方漏洞描述与NVD之间存在不一致的情况.Dong等人[111]提出了一项大规模不一致信息分析的工具VIEM.该工具从CVE中使用自然语言描述的漏洞信息以及NVD中结构化的漏洞相关数据来检测相关漏洞技术博客中与这2个平台漏洞数据不一致的情况,从不规则文本中提取软件中有潜在安全问题的软件名称和版本信息.在近20年中的78 296个漏洞以及70 569个漏洞报告中进行不一致检测,发现仅有59.82%的报告与NVD中的信息完全一致.不同程度的不一致信息可能会导致在漏洞检测和漏洞修复过程中的安全问题.这一工作以NVD中对于漏洞信息的描述为基准,实现了大规模针对漏洞报告中有漏洞的软件名称以及版本不一致的检测.漏洞报告通常作为为漏洞打补丁或生成威胁情报指标的重要依据.而漏洞报告中漏洞相关信息的错误可能导致漏洞被延迟或漏打补丁.这一结果将导致更加严重的漏洞出现.
漏洞在公开后,研究人员通常会对漏洞进行评估,并以报告的形式对漏洞评估结果进行公开,而报告对于解决任何未发现的问题至关重要.如果没有清晰且结构良好的报告,项目和组织负责人可能无法了解他们面临的威胁规模以及他们应该采取哪些措施来缓解威胁.漏洞报告首先清楚地总结评估和关于资产、安全缺陷和整体风险的关键发现.然后,更详细地介绍了与程序所有者最相关的漏洞以及它们如何影响组织的各个方面.评估和后续报告的主要目的都是修复漏洞,因此报告应特别注意提供指导和建议措施以解决当前问题,同时防止未来出现问题.因此,研究人员发现漏洞报告中提供了漏洞代码本身或官方漏洞数据未提供的信息,基于漏洞报告内容的漏洞检测研究也是有意义的.研究人员发现,只有当漏洞被漏洞数据库公开或已经被修复后才会被大众所知.当一些漏洞被公开后,与它相关的错误,称之为HIB(hidden impact bug)[112],这些错误并不会被及时修复或给出安全评级.研究人员[113]针对这些漏洞,利用NLP技术从公开的漏洞报告中提取信息并分析,生成分类器对提交给漏洞数据库的漏洞进行分类,区分出HIB和普通错误.在同时期对Bugzilla[114]和CVE上的漏洞数据上进行了实验验证,表明NLP能够准确区分出88%的HIB.基于漏洞报告的文档分析同样也适用于针对IoT设备的漏洞检测与防御.Feng等人[6]提出对从漏洞技术博客和论坛中抓取的过去20年里的43万份报告中提取的与IoT设备安全相关的7 500个漏洞报告进行分析.通过提取IoT设备安全相关的实体名称,生成恶意行为签名来辅助入侵检测系统和防火墙降低对IoT设备的攻击.Sun等人[115]进行了实证研究,主要研究ExploitDB的帖子和CVE之间的关系.为了减少为ExploitDB帖子记录CVE的延迟和缺失,他们从详细的漏洞利用帖子中生成CVE描述,利用基于BERT的命名实体识别技术和问答技术从漏洞利用的帖子中提取版本、漏洞类型、攻击向量等9个关键点然后对所提取的内容进行组合,在实体识别阶段准确率高于97%,确保了ExploitDB帖子内和跨异构漏洞的数据一致性.此外,这项研究明确了ExploitDB帖子对于CVE发现和分析的重要性.
讨论与分析4.CVE作为官方给出的漏洞信息数据库,为研究人员提供了认证的漏洞信息,而第三方漏洞描述是开源可获取的新兴研究数据信息.这2类数据构成了漏洞相关数据的集合.本文将该方向具有代表性的4项研究进行汇总,如表5所示.当前利用漏洞相关信息的研究工作,大部分利用了命名实体识别的方法,对文本中与漏洞相关的关键信息进行提取.在漏洞检测阶段,尝试利用漏洞信息对模糊测试进行辅助,尝试对漏洞信息之间的不一致性进行检测从而达到漏洞检测的目的.
基于官方漏洞信息的漏洞检测研究,通过利用NLP技术从漏洞信息中提取漏洞类型、存在漏洞的函数以及系统调用等标准化信息,辅助漏洞检测的研究.而第三方漏洞描述为官方漏洞信息补充了丰富的专家知识,多方位辅助漏洞检测研究的工作.
同样地,这部分研究也存在一些问题:
问题7.漏洞检测类型上比较单一,例如,Semfuzz在检测逻辑漏洞上的效果未知,对于需要特殊工具才能触发的漏洞检测效果未知.官方漏洞信息CVE和NVD不仅为检测未知漏洞提供了新思路,还为漏洞打补丁的过程提供了帮助.以上研究表明,基于漏洞相关信息不但可以辅助进行漏洞检测,还可以生成威胁情报辅助提高入侵检测系统的准确率.
问题8.NLP技术在处理漏洞相关语句上的局限性,对于长难句以及描述不够完整的语句分析效果未知.因此,在未来的研究工作中,研究人员可将以下2点内容作为研究方向:1)探索如何在单一数据源上实现检测多种漏洞类型的问题;2)探索如何解决当前NLP技术难以处理漏洞相关长难句的问题.
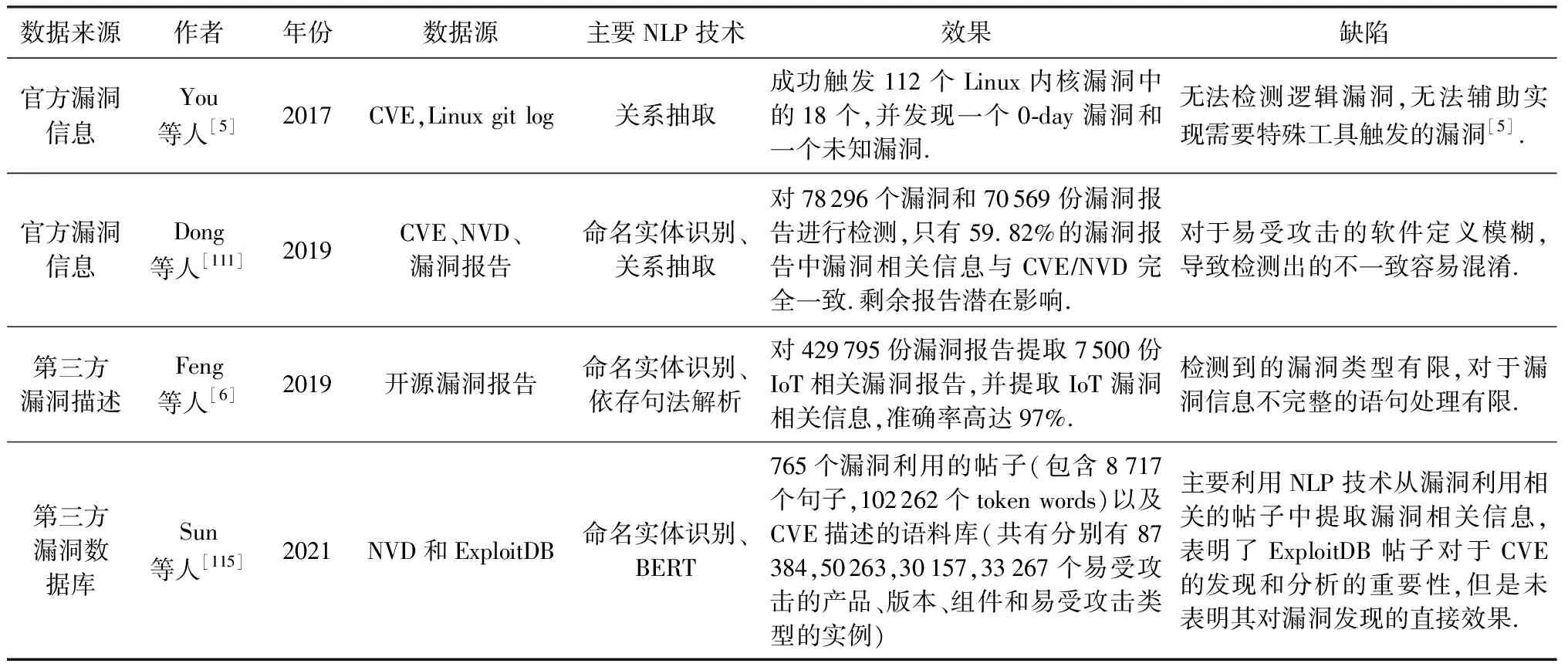
Table 5 Comparison of Vulnerability Detection Based on Vulnerability-related Information表5 基于漏洞相关信息的漏洞检测研究对比
3 延伸研究领域成果
研究人员围绕漏洞进行的研究工作除了漏洞检测与发现,还有漏洞的复现、漏洞的修复以及漏洞的利用.本节将简要介绍利用NLP技术实现漏洞复现、漏洞修复以及漏洞利用的当前研究成果.
利用文本进行漏洞复现工作的前提是漏洞报告内容的详细和准确.为了使漏洞报告能够为研究人员所用,报告应该清晰地描述观察到的行为、复现步骤以及预期行为来辅助研究人员理解和复现潜在的错误.Chaparro等人[116]通过词性标记和启发式的方法将句子和段落与话语模式相匹配,从而进一步识别漏洞报告的描述中是否具备复现步骤和预期行为.Zhao等人[117]提出了ReCDroid,利用NLP技术中的词性标注和依存句法解析来分析漏洞报告的文本,采用22条语法规则从报告中提取复现错误相关的事件表示,从而进一步实现自动化地漏洞复现.在对33个安卓应用的51个原始漏洞报告评估后,显示ReCDroid对漏洞的复现成功率达到了63.5%.另一方面,有研究人员开展了利用文本内容辅助漏洞修复的研究.Nappa等人[118]对漏洞补丁进行了研究,并且利用NLP技术从文本描述中提取易受攻击的范围,从而自动化比较文本漏洞描述中的易受攻击范围和NVD XML转储中的易受攻击版本.
当前利用NLP技术辅助漏洞复现和漏洞修复的研究还有很多难题未解,未来研究的发展空间很大.利用NLP技术辅助漏洞检测研究领域中的成果可以迁移到下游任务中,辅助实现漏洞的复现和修复工作.
4 总结展望
当前利用NLP技术展开的漏洞检测研究根据数据源不同可划分为4类:官方文档、代码、代码注释以及漏洞相关信息.当前领域已经探索了大部分开源可用的数据,技术上相比传统漏洞检测工具在准确率上已有较大的提升.然而,我们发现当前研究成果多存在一些局限性,即成果在漏洞检测类型上的单一.分析其原因,我们发现当前研究在选取数据集以及NLP技术上存在一定的局限性,从而导致漏洞检测类型不尽如人意.通过对当前研究存在的问题进行总结归纳,将问题类型划分为数据、技术以及效果3类,如表6所示:
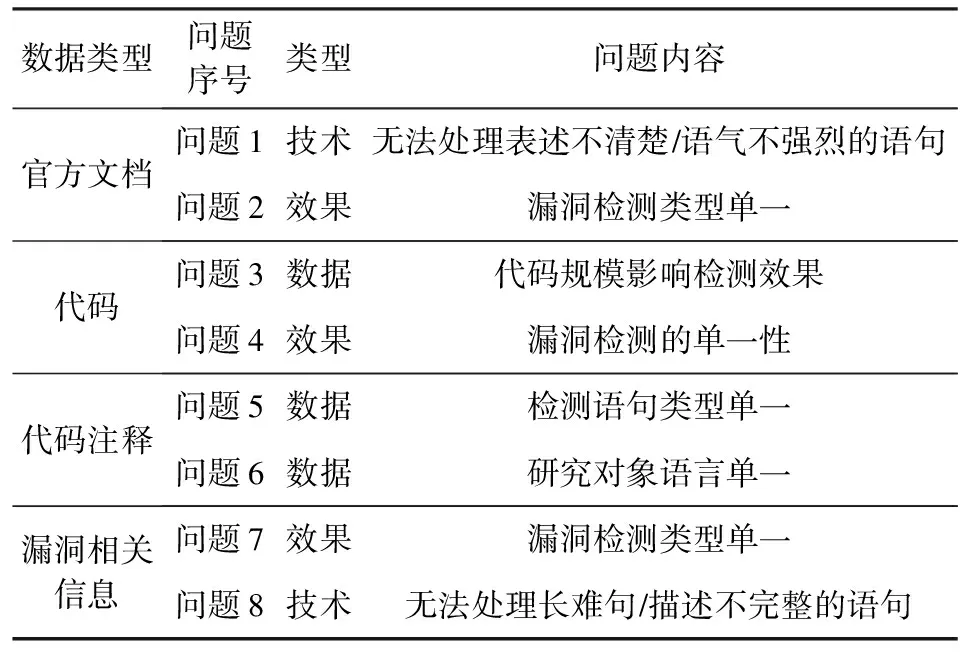
Table 6 Problems of Vulnerability Detection Based on NLP
除此之外,还将对未来研究工作与方向进行讨论.
1) 数据
在基于代码和代码注释的漏洞检测研究中,我们发现多个研究均出现数据源过于单一的情况.通过分析问题3、问题5和问题6,我们发现:数据结构单一、数据来源单一、以及数据类型单一均包含在数据单一的范畴中.而本文提到的当前研究成果中出现数据源单一问题的集中在基于代码的研究部分.因此,结合文本信息辅助进行漏洞检测研究可能会增加后续检测出的漏洞类型.对于基于文本的漏洞检测研究,我们发现丰富文本类型可能会增加后续检测出的漏洞类型,能够最大程度地降低后期研究成果的局限性.未来方向将探索多元数据在漏洞检测领域的作用.通过文献调研,我们发现官方文档在开发过程中起到了教科书的作用,而第三方技术论坛和博客则扮演了教辅的角色,即通过补充文档信息,给出错误的应用场景以及相应的解决方案等给研究人员提供额外的知识.当前,基于第三方漏洞描述以及技术知识辅助进行漏洞检测工作主要集中在完成漏洞检测的上游任务中,而利用第三方漏洞描述直接进行漏洞检测的研究非常有限,这表明从大量无序文本中提取有助于漏洞检测研究的信息非常具有挑战性.未来可以将研究探索重心放在如何利用第三方技术知识实现漏洞检测上.同时,通过分析问题1和问题8,我们发现从数据角度也可以通过结合不同数据源的信息,补充上下文将模糊语句清晰化,从而达到漏洞检测的目的.
2) 技术
在调研文献的过程中,我们发现在处理文档信息的时候,工具对特定语句的处理能力未知,例如问题1和问题8,相关研究成果在表述不清或不完整、语气不够强烈的语句以及长难句上的提取分析能力未知.这部分问题的主要原因是传统NLP技术对于处理多元文本数据的局限性.未来方向将探索NLP技术处理多样数据的潜能.针对同一类型下的多元数据,尝试突破现有技术在处理特定类型语句,例如长难句、描述不完整的语句以及情感不强烈的描述性语句等上的局限性.未来可以将研究重点集中到如何利用传统NLP技术解决多元数据的方向上.
3) 效果
在多个研究成果中,我们发现问题2、问题4和问题7提出的研究在漏洞检测类型上的单一性、数据范围过窄,数据处理技术无法突破,从而导致检测到的漏洞类型过于单一,直接影响成果的影响范围.未来方向将探索漏洞检测方法的泛化潜能.当前大部分研究成果大多具有针对性,即在某一领域下针对特定数据源或特定类型的漏洞进行研究.研究产出的工具在一定程度上难以达到大规模、跨平台以及跨领域的漏洞检测能力.未来可以对如何构建高质量大规模数据集进行深度探索.同时,尝试在多语言数据集上应用工具,使漏洞检测方法具有泛化能力.
作者贡献声明:杨伊是主要撰写人和构思者,完成相关文献资料的收集和分析及论文的写作;李滢参与文献资料的部分整理工作以及图表的制作;陈恺负责指导论文的构思和写作工作.
