结合分层深度网络与双向五元组损失的跨模态异常检测
2022-12-15彭淑娟王楠楠
范 烨 彭淑娟 柳 欣 崔 振 王楠楠
1(华侨大学计算机科学与技术学院 福建厦门 361021)2(厦门市计算机视觉与模式识别重点实验室(华侨大学) 福建厦门 361021)3(南京理工大学计算机科学与工程学院 南京 210094)4(综合业务网理论及关键技术国家重点实验室(西安电子科技大学) 西安 710071)(fanye@stu.hqu.edu.cn)
异常检测是开放场景中机器学习和数据分析的一项重要技术,旨在挖掘出数据集中与大多数其他数据具有显著区别的对象,已广泛应用于如网络垃圾邮件检测[1]、信息差异管理[2]、网络入侵与故障检测[3]、信息窃取[4]、图像/视频监控[5]等实际应用领域中.近年来,国内外研究学者针对异常检测已经提出了许多有效的解决方法,包括基于数据分布的方法[6]、基于距离的方法[7-10]、基于密度的方法[11]和基于聚类的方法[12-14].然而,这些异常检测的方法主要针对的是单一视图数据.在众多的实际场景中,数据往往来源多样,并且具有多种表现形式.近年来,研究人员发现对单个视图数据进行异常检测时常常存在着漏检问题,究其原因在于当查看某个实例每个单独视图中的大部分数据时,它们通常不是异常的,但当联合考虑多个视图时,它们就可能会呈现异常状态.然而,由于多视图数据复杂的组织结构和分布差异性,传统的异常检测方法常常无法满足对多视图数据进行异常样本检测的需求.
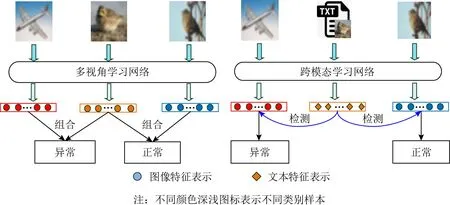
Fig. 1 Difference between multi-view anomaly detection and cross-modal anomaly detection图1 多视角异常检测与跨模态异常检测的区别
据文献研究[5],在实际场景中多视图数据常常包括了2类数据:一类是来自同一实例的不同视角数据,如来自同一人脸的左侧部分与右侧部分;另一类是源自同一实例的不同模态数据,如反映同一语义信息的图片与文本等.针对多视图样本点的异常检测问题,近年来研究人员提出并尝试了一些多视图异常检测的方法,然而这些方法主要专注于检测多视图数据中属于同一实例的不同视角异常样本信息,鲜有相关研究专注于检测多视图数据中属于同一实例的不同模态异常信息.在实际场景中,多视角异常检测可能难以完成不同模态的检测问题.例如,自闭症患者的行为在平时与常人无异,但在一些表述中会表现出与常人不同的行为.因此,可以利用这些表述对患者所对应的行为进行检测.为有效检测来源多样的多视图异常数据,研究人员提出了基于多模态数据的跨模态异常检测概念,如图1所示,多视角异常检测旨在通过结合不同视角的数据进行检测,而跨模态异常检测旨在利用一个模态数据样本去检测属于同一实例的其他模态样本异常信息.尽管属于同一实例的不同模态数据具有较高的语义关联性,然而不同模态数据样本呈现分布复杂、特征异构并且具有明显的语义鸿沟,因此从不同模态数据中进行有效的异常检测仍是一个极其挑战性的课题.
据文献[15]可知,目前多视图数据中的样本异常主要可以分为3类:1)类别异常;2)属性-类别异常;3)属性异常.这3类异常的形式化定义如1)~3):
1) 类别异常.在不同视图中表现出不一致特征的异常值,即该数据样本在不同的视图中表现出不同的类别特征,如图2空心圆形所示.
2) 属性-类别异常.在某些视图中表现出正常的特征值,而在其他视图中表现出不一致的异常值,即该数据样本在某些视图中没有表现出异常,而在其余视图中表现出异常,如图2空心三角形所示.
3) 属性异常.在每个视图中都表现出不一致的异常值,即该数据样本在不同的视图中都表现出异常,如图2五边形所示.
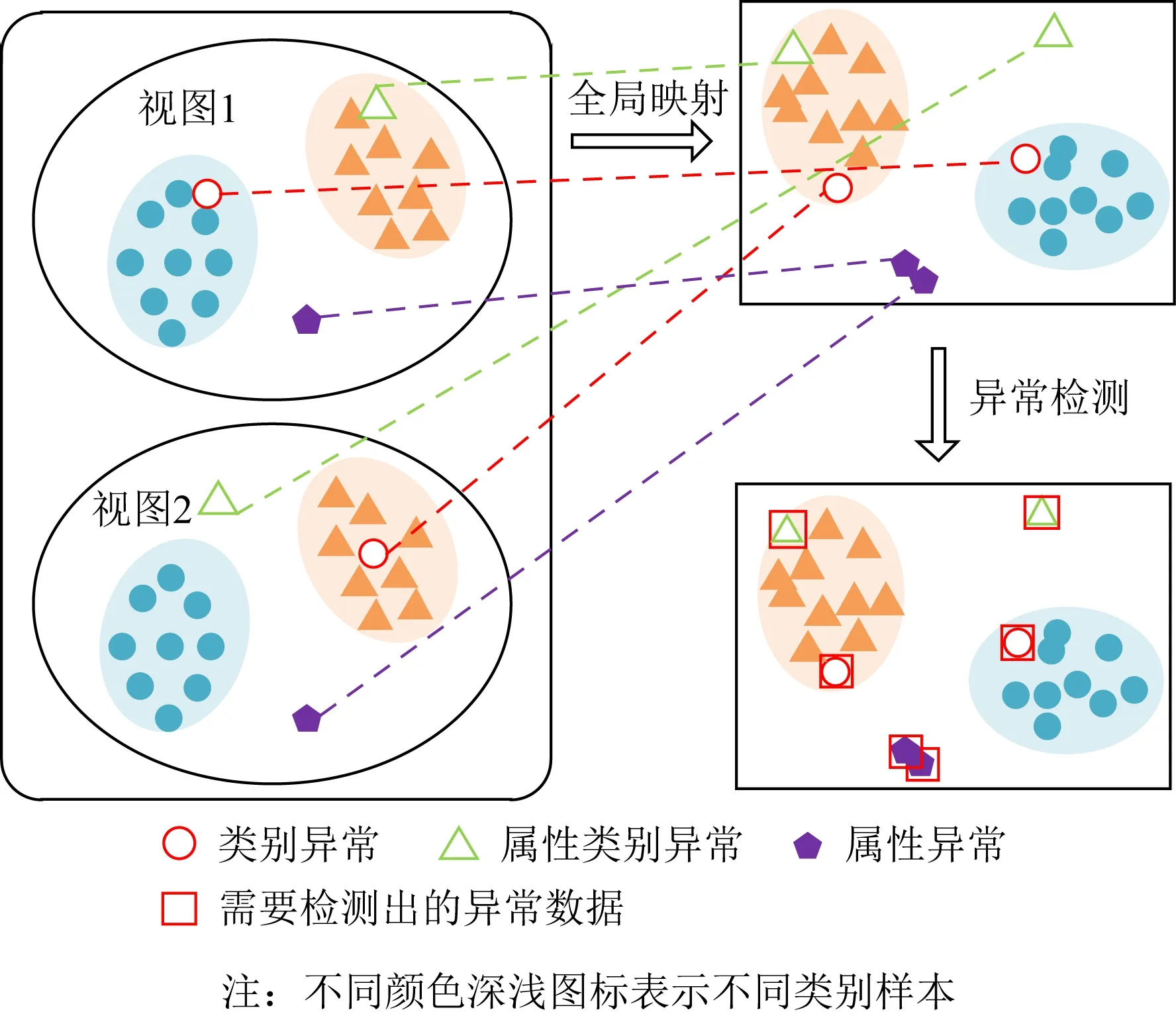
Fig. 2 Classfication and detection of three types of outliers图2 3类异常样本的分类及检测
有效的多视图异常检测方法需要对上述3类异常样本进行检测.然而,由于同一实例不同模态的数据也属于多视图数据,传统的多视图异常检测无法有效处理此类问题.为有效检测来源多样的多模态异常数据,近年来提出的跨模态异常检测方法仍然需要对以上述3类异常进行检测.据文献[14],现有的跨模态异常检测框架主要采用双分支模型将不同模态中的数据投影到共同语义嵌入空间进行差异化分析.然而,若一个实例中的多个模态数据同时出现异常且数据结构特征相似时,该框架会将该组数据投影到相似的位置,从而常常存在漏检现象.因此,现有的跨模态异常检测方法不能同时有效满足对3类不同类型异常值进行全面检测,并且有益于训练的样本没有实际参与模型训练,数据利用不够充分.针对上述问题,本文提出了一种结合分层深度网络与相似度双向五元组的跨模态异常检测方法,旨在全面检测出不同模态中所有的异常类型样本点.具体地,以图片和文本为例,本文将图片与文本数据输入到框架之中,使用单视图异常检测层对其中一个模态进行检测,判断检测数据样本中是否存在属性异常与部分属性-类别异常点.若检测出该数据没有此类异常,则该数据进入跨模态检测层,对该数据的图片以及文本描述进行进一步检测,该部分采用相似度双向五元组损失的双分支深度网络用于检测数据中的类别异常与其余部分的属性-类别异常.该损失让不同属性之间的数据正交化,相同属性之间的数据线性相关,从而不同属性数据的特征相关性降低,相同属性数据的特征相关性提高,并且通过模态间双向约束和模态内的邻域约束,极大提高了数据利用率,进而获得更好的训练效果.本文工作的主要贡献主要包括3个方面:
1) 提出一种新的跨模态异常检测框架.该框架结合分层深度网络进行跨模态异常检测,使得该框架可以完整检测出3类不同类型异常值,为跨模态异常检测提供一种新的研究思路.
2) 提出一种相似度双向五元组损失的异常检测方案,该损失使得不同属性数据正交化,相同属性数据线性相关,有效加大了不同属性数据间的特征差异性;增加了相同属性数据之间的特征相关性,并通过双向约束极大提高了模型的泛化能力.
3) 提出的学习框架可以有效检测不同模态中的异常样本点,相比于现有的跨模态异常检测的方法,本文所提出的框架几乎取得了全面的提升.
1 背景和相关工作
随着多视角数据在实际应用中的普及,研究者针对多视图数据的异常检测进行了诸多实验与探究,并提出了一些代表性的多视角异常检测方法.例如,Gao等人[16]提出的水平异常检测(horizontal anomaly detection, HOAD)是第1个解决多视图异常检测的有效方法,该算法首先构造一个相似矩阵并进行谱嵌入,然后利用不同嵌入之间的相似度来对每个实例的异常得分进行异常检测计算.Marcos等人[17]提出了一种基于亲和矩阵(affinity propagation, AP)的异常检测方法,该方法通过分析不同视图中每个实例的邻域来检测异常样本点.Alexander等人[18]提出了一种基于共识聚类(consensus clusters, CC)的多视图异常检测方法,旨在通过多个视图聚类结果的不一致性来检测异常样本点.然而,这些方法都仅用于检测类别异常,并未考虑其他异常类别.针对这个问题,Zhao等人[19]首先提出了多视图数据中样本属性异常与类别异常的概念,接着使用低秩子空间与K-means聚类方法(dual-regularized multi-view outlier detection, DMOD)对2类不同异常值进行同时检测.然而,基于聚类的检测方法对数据集中的异常样本点比较敏感,常常导致聚类中心的偏差高,从而导致低检测率.Li等人[20]将数据投影到低秩子空间进行学习(multi-view low-rank analysis, MLRA),然而该方法要求不同视图有着相同的维度,因此在许多多模态应用场景中受到限制.
近年来,Li等人[15]深入总结多视角异常样本的各种情况,并提出了第3类属性-类别异常概念.为了检测3类不同的异常,Sheng等人[21]提出了使用KNN(K-nearest neighbor)对不同视图进行检测的方法MUVAD(multi-view anomaly detection),该方法通过单个视图对应的其余视图数据近邻关系进行相似度异常检测,取得了在低维数据中很好的效果.然而该方法在高维数据样本中的异常检测效果欠佳.随着神经网络的发展,Ji等人[22]首次使用神经网络对多视图进行异常检测(multi-view outlier detection in deep intact space, MODDIS),该方法利用神经网络将各自视图与融合视图的特征进行提取叠加,取得了较好的多视角异常检测效果.然而,在多模态数据中,不同模态数据样本分布复杂、特征异构并且具有明显的语义鸿沟,因此,该方法不适用于特征异构的多模态数据异常检测.据文献查证,针对多视图数据中跨模态数据的异常检测是一项较为崭新的课题,有关此类问题的方法较少.Li等人[23]针对跨模态异常检测问题,提出了基于深度网络的跨模态异常检测方法(cross-modal anomaly detection, CMAD),该方法首先使用单向三元组对跨模态数据进行训练,然后通过相似度度量判断不同模态之间的异常,可以有效地突破不同模态的语义鸿沟,进行跨模态异常检测.然而,该方法仅仅只关注不同模态之间的相似性,从而会对具有相似性的不同模态异常样本进行漏检.同时,由于该方法使用单向的三元组损失函数,该损失函数忽略了许多其他有益于训练的样本,其训练效果还有所欠缺.
2 研究方法
针对来源不同的多视图异构数据,本文以图像和文本为例介绍跨模态异常检测学习框架.同时,针对现有跨模态异常检测框架对3类异常值检测不够全面的问题,如图3所示,本文提出的异常检测框架采用了分层深度网络结构.具体地,学习框架首先引入一个单视图异常检测网络层,通过深层特征和模态内近邻样本相似度判断来检测数据样本中是否存在属性异常与属性-类别异常点.若检测出该数据没有此类异常,进一步采用相似度双向五元组损失的双分支深度网络用于检测跨模态数据中的类别异常与属性-类别异常,该损失使得不同属性数据正交化、相同属性数据线性相关,加大了不同属性之间的特征的差异性,并同时提高了相同属性之间的特征相关性.此外,学习框架通过模态间双向约束和邻域约束来提高样本数据的利用率和增强模型的泛化能力.
2.1 形式化定义
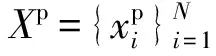
2.2 结合深层特征与近邻样本的单视图异常检测

(1)
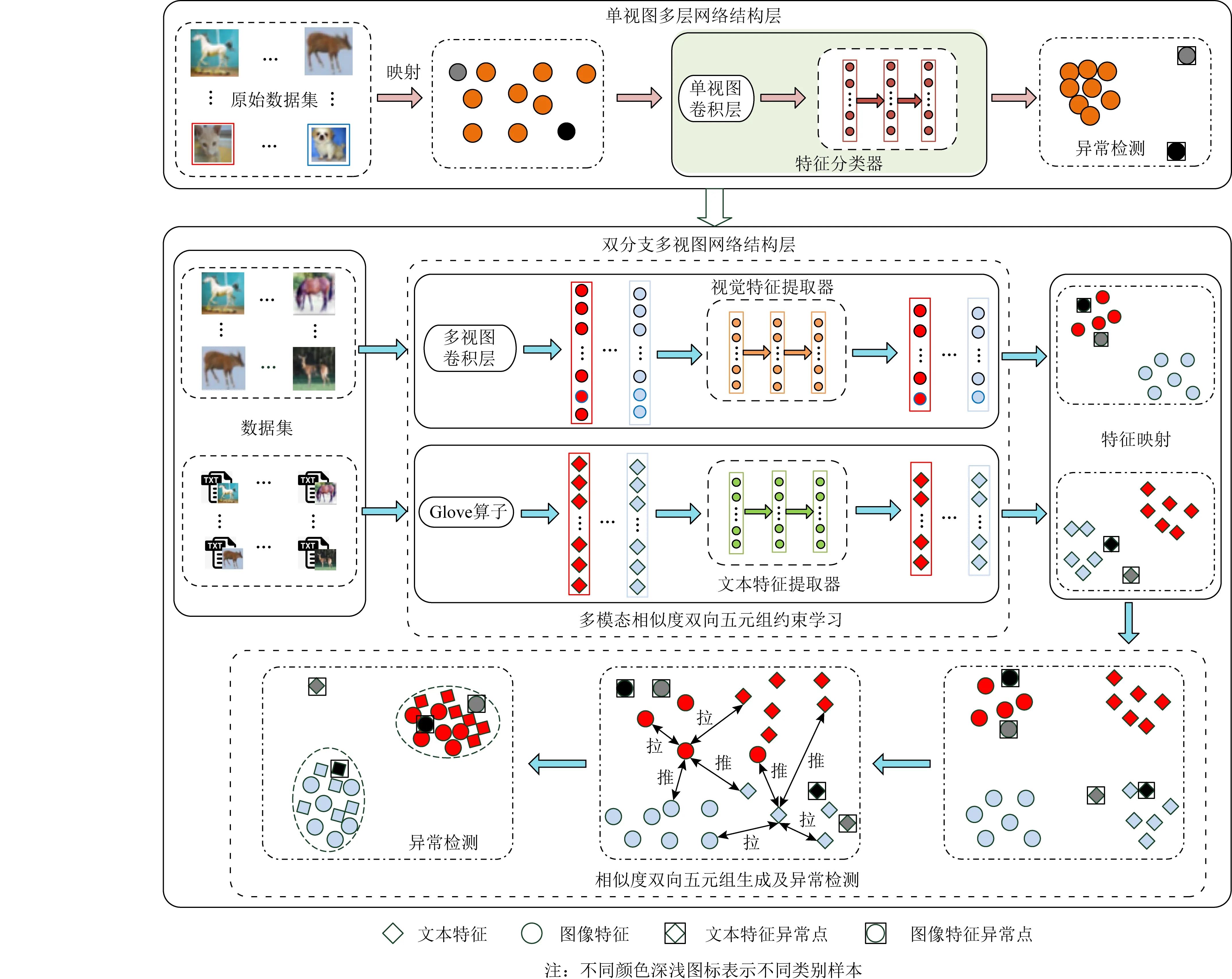
Fig. 3 The proposed cross-modal anomaly detection framework图3 本文提出的跨模态异常检测框架
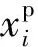
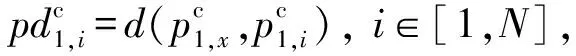
(2)
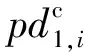
(3)
2.3 结合双分支深度网络与相似度双向五元组的跨模态异常检测
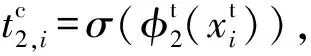
(4)
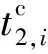
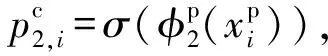
(5)
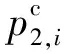
属于同一样本的多模态数据具有语义一致性.为刻画图片和文本的语义关联性,本文采取相似度双向五元组损失函数进行图片文本的语义关联性学习约束,该损失由多个相似度三元组损失构成,该损失函数使得不同属性数据得以正交化,相同属性数据线性相关,相似度三元组损失其形式化定义为
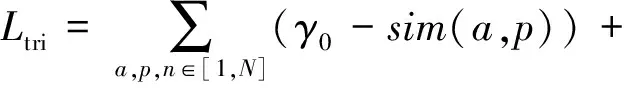
(6)
其中,a表示固定样本,p表示与a属于同一类别的正样本,n表示与a属于不同类别的负样本,sim(a,p)表示固定样本a与正样本p对应的特征表达式之间的相似度;sim(a,n)表示固定样本a与负样本n对应的特征表达式之间的相似度,当sim(a,n)=0时固定样本a与负样本n正交.为了使得该损失函数收敛效果更好,本文在该损失函数中增加了一个松弛γ,γ表示sim(a,n)之间的相似度松弛.针对每个三元组(a,p,n),三元组损失的优化目标是让sim(a,n)尽可能小于γ,sim(a,p)尽可能接近γ0,当sim(a,p)=1时,固定样本a与正样本p线性相关,并且该损失保证各个向量不为零向量,因此本文使用的γ0=1,且γ<γ0.
2.3.1 模态间的双向约束
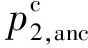
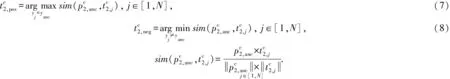
(9)
因此损失定义为
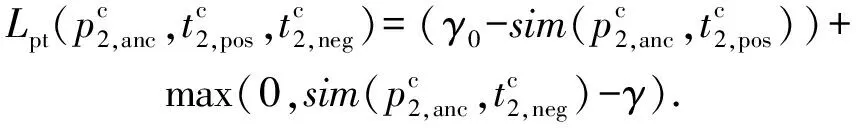
(10)
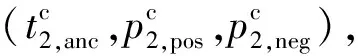
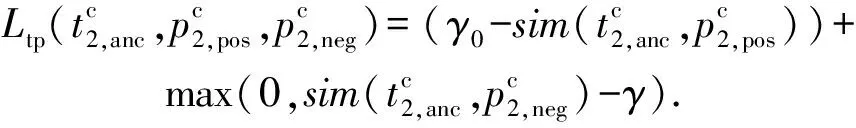
(11)
因此上述损失函数可以表示为
(12)
该损失函数对图像-文本和文本-图像数据进行了双向语义关联约束,使得不同模态间相同属性的特征相关性增大,不同属性的特征相关性减少.
2.3.2 模态内的邻域约束

(14)
因此文本模态内邻域损失定义为
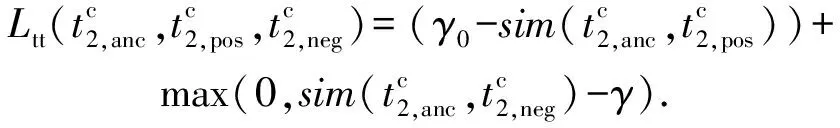
(15)
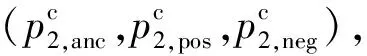
(16)
对相同模态之间进行邻域约束,可以使得在相同模态之间不同属性的数据特征相关性减少,相同属性的数据特征相关性增大,不仅增加了数据的使用率,而且可以增大不同属性数据的区分度.
2.3.3 训练策略
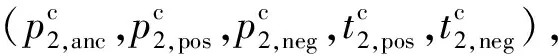
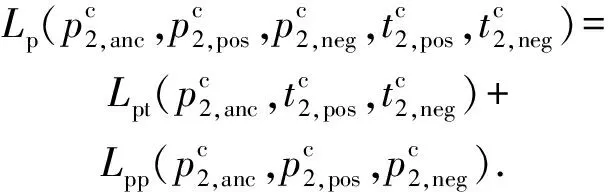
(17)
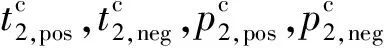

(18)
整个的相似度双向五元组损失函数为
(19)
本文采用结合权重衰减和动量技术的随机梯度下降方法(stochastic gradient descent, SGD)来优化模型.
3 实验与结果
为了充分评估本文所提出算法的有效性和鲁棒性,本节进行了大量实验来进行验证.
3.1 数据集
本文采用3个公开的MNIST,FashionMNIST,CIFAR10数据集进行异常检测算法性能评估,数据集的详细信息描述为:
MNIST[24]数据集由7万张原始图像来代表1×28×28像素的10个不同数字.整个MNIST数据集分为6万个训练集和1万个实例的测试集.
FashionMNIST[25]数据集是一个替代MNIST手写数字集的图像数据集,其涵盖了来自10种类别标签的共7万个不同商品图片.该数据集的大小以及训练集/测试集划分与MNIST数据集一致.
CIFAR10[26]数据集是一个用于普适物体识别的计算机视觉数据集,该数据集包含6万张3×32×32的RGB彩色图片,总共10个分类.其中,包括5万张用于训练集,1万张用于测试集.
3个数据集同时包含图片数据信息和类别标签信息,因此本文参照文献[23]的方法,根据类别标签信息自动为每张图像中添加文本标签语义描述信息,并通过GLOVE词嵌入方法将文本标签信息嵌入到100维向量中,使得数据集综合生成与图片语义相对应的文本描述信息.本文从3个数据集中的训练集分别取出5 000个实例作为验证集,并确保其训练集与验证集不相交.
针对多视角数据存在3类异常样本的问题,本文生成一定比例的跨模态3类异常数据.具体地,本文将一定比例的文本进行修改以及随机注入其他类型的文本数据来生成文本属性异常与属性-类别异常的数据;同时,本文将一定比例图片中的维度数据进行随机生成来构建图片属性异常数据与属性-类别异常,并选取一定比例文本和图片进行随机打乱来生成类别异常.
3.2 基线算法
本文采用了4种近3年来可用于跨模态异常检测的算法进行比较:基于双分支深度神经网络嵌入的学习框架[27](embedding network, EN),通过测量不同模态之间的欧氏距离来区分跨模态异常;基于特征融合的深度神经网络的学习框架(MODDIS);基于相似度的跨视图KNN框架(MUVAD);以及深度网络跨模态异常检测的方法(CMAD).在实验中,这些基线方法的参数设置与论文中描述一致.本文算法实验中对L与Linter损失函数进行了对比实验和分析,其损失函数中的超参数γ值设置为0.4.
3.3 评价指标
本文实验中,使用Accuracy,FPR,TPR,AUC作为评价指标.AUC为ROC曲线面积,AUC值越高,该方法的性能越好;TPR为真正例率;FPR为假正例率.TPR的值越高,FPR的值越低,该方法性能越好,FPR,TPR公式为
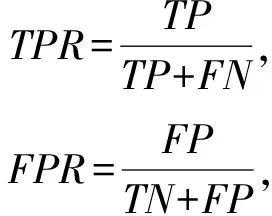
(20)
其中TP,FN,TN,FP分别代表真阳性、假阴性、真阴性和假阳性的数量.Accuracy为检测准确率,公式为

(21)
3.4 性能对比
表1~3显示了3种不同数据集异常检测的Accuracy,FPR,TPR,AUC的平均值.
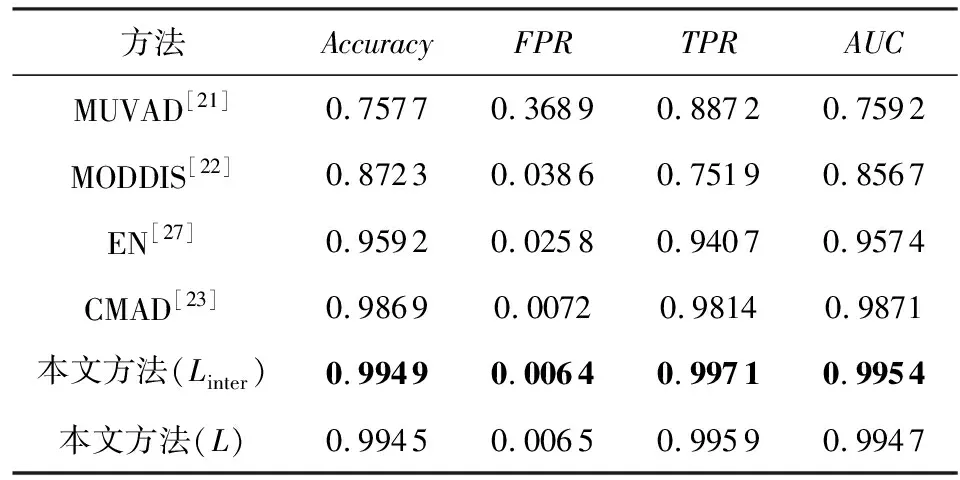
Table 1 Results on MNIST Anomaly Detected by Each Framework
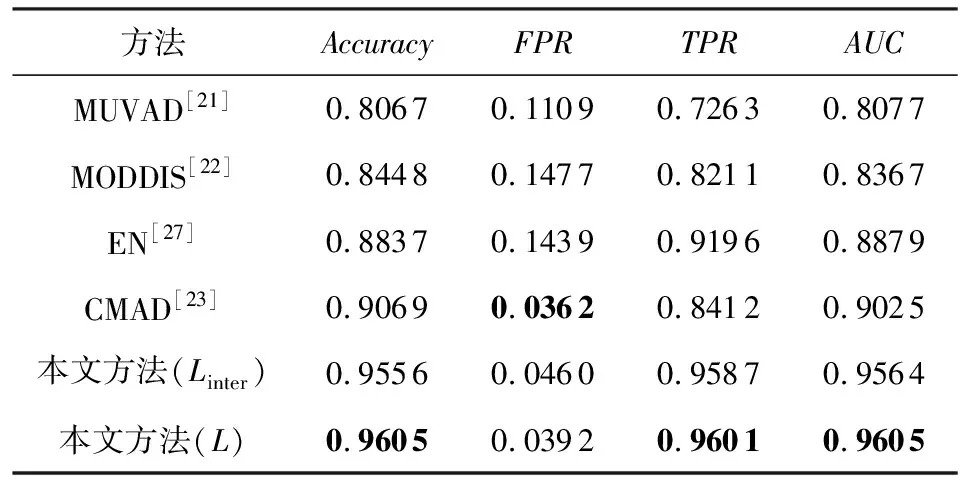
Table 2 Results on FashionMNIST Anomaly Detected by Each Framework
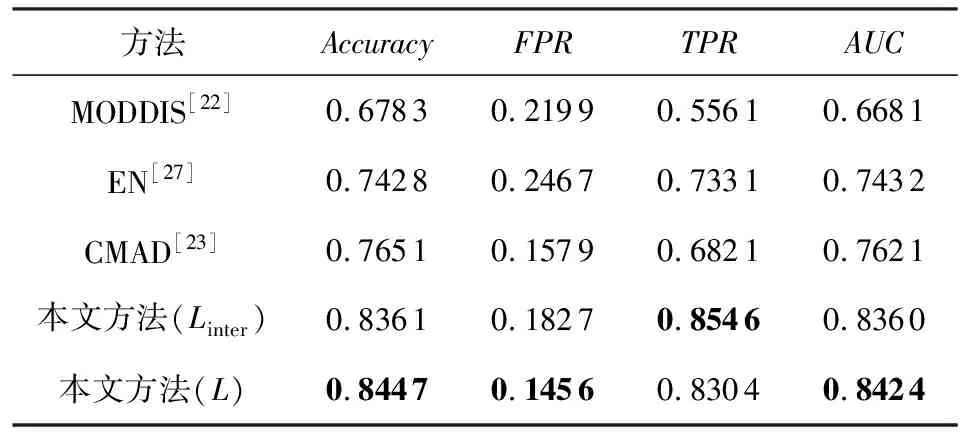
Table 3 Results on CIFAR10 Anomaly Detected by Each Framework
可以看出,本文所提出的方法优于所有的基线方法,相较于多视角异常检测的方法,本文的方法有着很大的优势.由于本文使用的数据集维度相较于文献[21]中所使用的维度更大,MUVAD算法中所使用的KNN算法存在维度灾难,因此,该算法在低维数据中性能较好,而在本文所使用的数据集中的准确率较低.由于不同模态的数据维度差距较大,基于特征融合的MODDIS算法在融合过程中会出现图片数据起主要作用的情况.由于CIFAR10数据集中的图片数据维度的占比相比于其他数据集更高,因此,该算法在CIFAR10数据集中的准确率相比与其余数据集更低.CMAD算法在较为简单的MNIST数据集上可以达到与本文方法相当的性能,但在相对语义多样的FashionMNIST与CIFAR10数据集中表现出低于本文提出的方法的性能.在表1与表4中可以看出在MNIST数据集中,Linter损失相比于L损失时的表现更好,其原因在于使用Linter损失函数时,该损失关注不同模态间的学习,L损失关注不同模态间学习的同时也进行模态内的学习,增加了学习复杂度,而MNIST数据集相对于其他数据集模态内的区分度较高,即模态内不同属性的数据区分明显,导致L损失相对于Linter损失没有优势,因此L损失在MNIST数据集中的表现比Linter损失差.图4显示了不同方法在相同指标下的对比曲线图,可以看出本文提出的方法在相同指标下始终优于其余基线方法,实验证明了本文方法的有效性.
此外,实验同样在FshionMNIST与CIFAR10数据集上进行验证和测试.从表5和表6实验结果可以看出准确率在不同异常比情况下属性异常数据/属性-类别异常数据的变化情况.特别地,在MNIST数据集中表现良好的CMAD学习框架,在FshionMNIST与CIFAR10数据集异常比例上升中异常检测效果表现出整体下降的趋势比较显著.
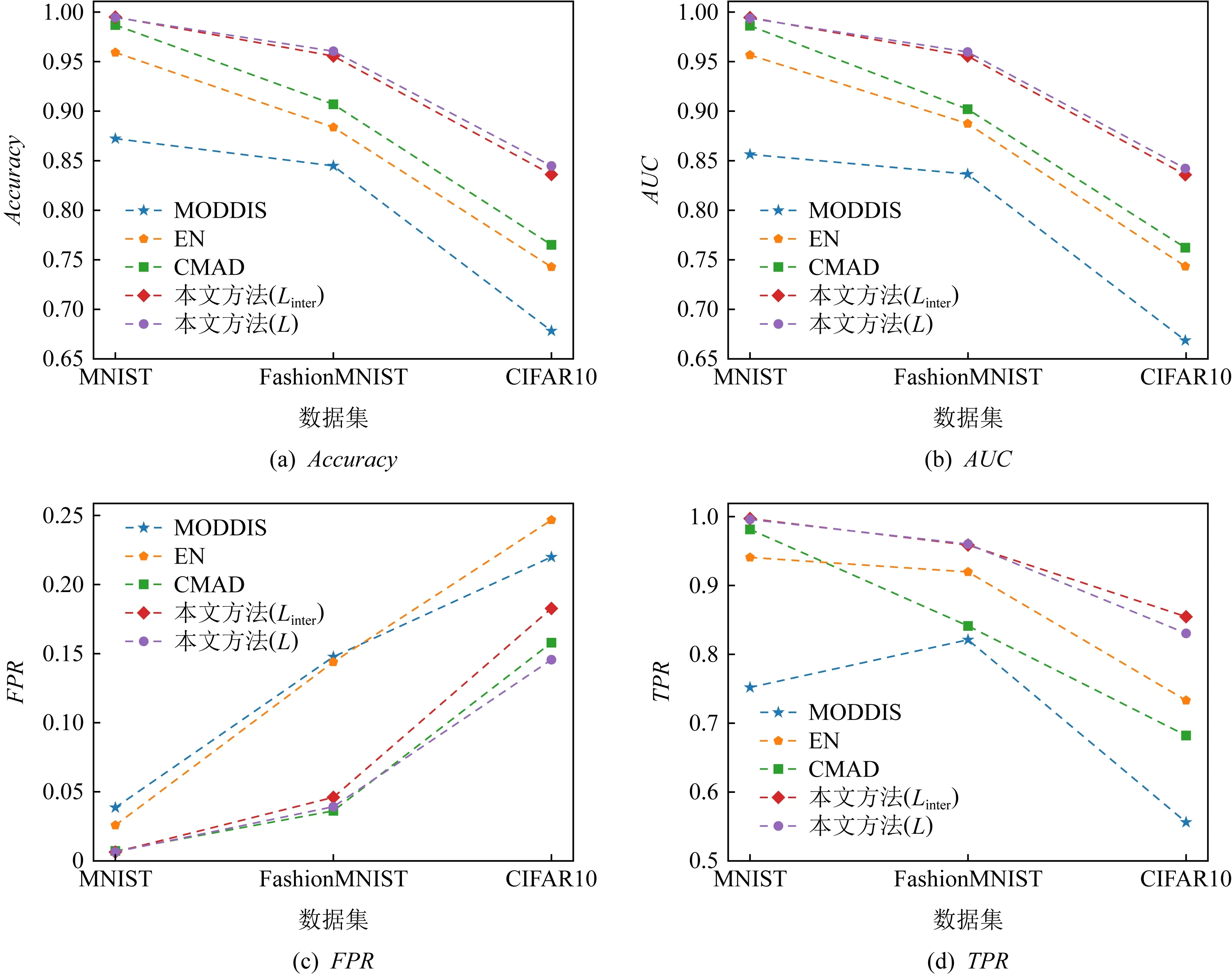
Fig. 4 Performance comparison of each method on different datasets图4 各个方法在不同数据集中性能比较
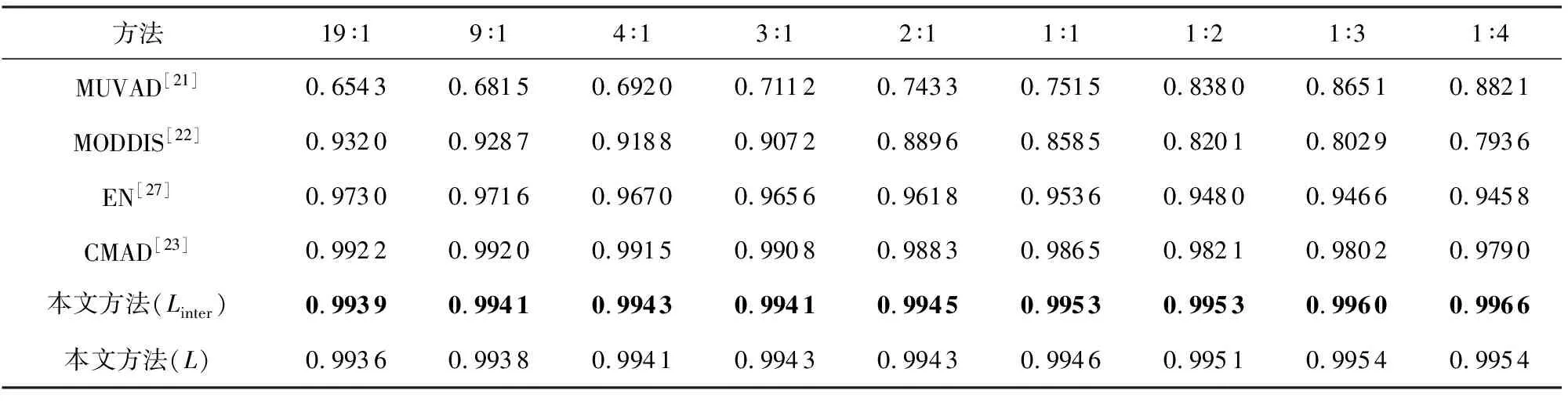
Table 4 Accuracies Obtained by Different Frameworks with Diverse Abnormal Proportions (MNIST)表4 各框架对比不同异常比例的准确率(MNIST)
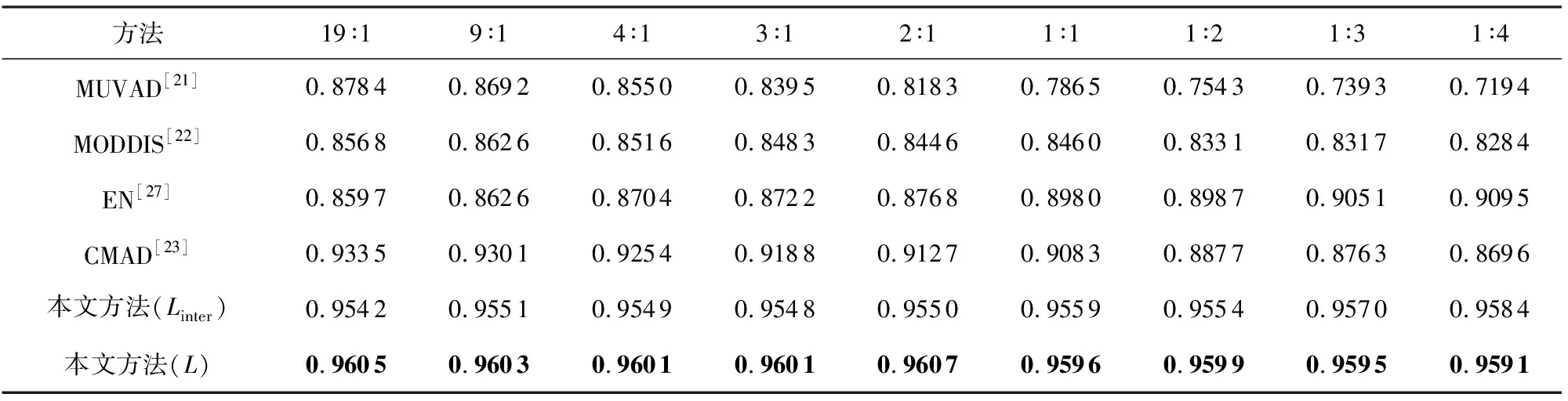
Table 5 Accuracies Obtained by Different Frameworks with Diverse Abnormal Proportions (FashionMNIST)表5 各框架对比不同异常比例的准确率(FashionMNIST)
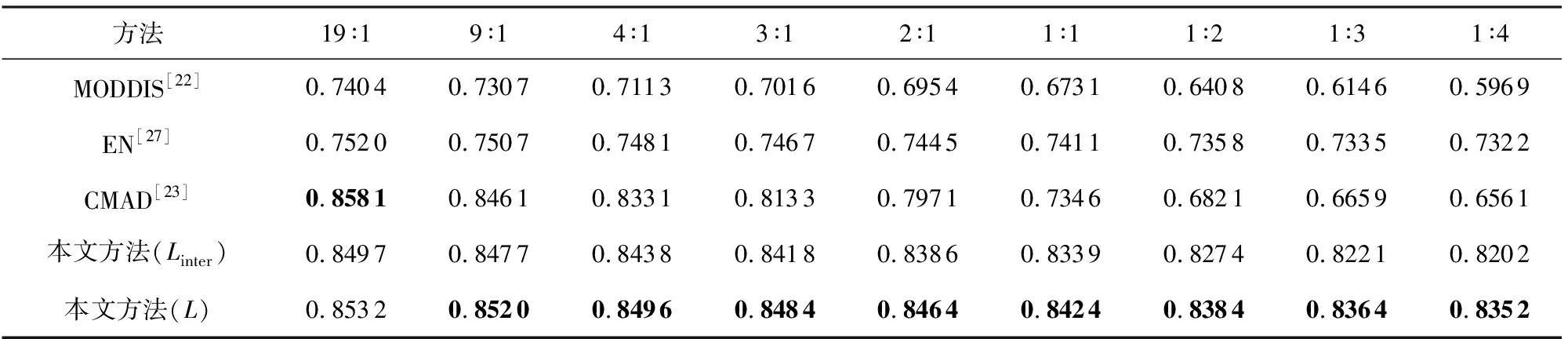
Table 6 Accuracies Obtained by Different Frameworks with Diverse Abnormal Proportions (CIFAR10)表6 各框架对比不同异常比例的准确率(CIFAR10)
相比较而言,本文提出的跨模态异常学习框架同样保持着在不同异常比例下较高情况下较好的准确率,并在不同占比的异常数据中保持着稳定的检测精度.
综上所述,本文所提出的方法相较于基线算法有着更好的鲁棒性以及更高的准确率,究其原因在于:1)本文算法首先使用单视图网络检测结构可以有效检测出数据中的属性异常,以降低属性-类别异常的漏检性,初步增加了检测的准确率;2)本文算法使用相似度双向五元组损失,加大了不同属性数据之间的特征差异性,同时增加了相同属性之间的特征相关性;3)提出的双向约束框架在相同数量的数据集下可以得到充分的训练,数据利用率高,从而使得训练的模型泛化能力较强,可适用于不同类型的异常样本检测.实验结果表明了提出方法的有效性.
4 总结与展望
针对极具挑战性的多源异构数据的跨模态异常检测问题,本文提出了一种结合分层深度网络与相似度双向五元组的跨模态异常检测方法,该方法充分考虑模态内和模态间的各种异常差异,并采用单视图网络和双分支网络相结合的方法,可以有效适用于不同类型的跨模态异常检测,在不同数据集中均获得了显著的效果,并且在3类不同类型的跨模态异常检测情况下的表现几乎全面超过了现有的方法,有效地提高了检测的准确率,相关实验验证了本文提出方法的有效性.在下一阶段的研究工作中,本学习框架将进一步探究不同参数的搭配对不同多模态数据集运行结果的影响,尽可能挖掘一种自适应参数的选择方法用来适配形式各异的多模态异常数据集.
作者贡献声明:范烨负责算法设计与论文撰写;彭淑娟负责模型优化和论文撰写;柳欣负责模型可行性分析;崔振负责算法优化;王楠楠负责实验的多样性分析.
