基于卷积神经网络的睡眠呼吸暂停综合征严重程度4分类预测
2022-08-25邹汉荣何汉武
邹汉荣,何汉武
(广东工业大学 机电工程学院,广东 广州 510006)
睡眠呼吸暂停综合征(sleep apnea syndrome,SAS)是指在睡眠状态下反复出现口与鼻的气流中断停止10 s 以上现象的睡眠障碍疾病[1]。SAS 的主要影响在于睡眠过程中的慢性间歇性低氧和反复微觉醒。严重影响睡眠质量、白天精神状态。SAS 在未得到及时治疗的情况下,还会引发高血压、冠心病、脑卒中等并发症[2]。
在传统医学诊断中,使用多导睡眠仪(polysomnography,PSG)对睡眠进行监测是检测SAS 的“金标准”[3]。PSG 可以记录被试者夜晚睡眠状态下的脑电、眼电、肌电、呼吸、血氧等生理信号,但是需要其在医院进行睡眠监测。身上粘贴的电极片会对被试者睡眠产生干扰,影响被试者的睡眠质量,从而导致测量偏差。监测记录完成后,需要医生阅读PSG 图,并进行人工判断,判断的过程耗费大量的时间和精力。
SAS 在我国的患病率在4%左右,是一种常见病,然而SAS 的诊断需要PSG。多导睡眠仪价格昂贵,目前只有大、中城市三级医院或部分二级医院才有条件对该病进行规范的诊断和治疗,致使大量患者得不到及时的诊断和治疗,目前该疾病的确诊率不到10%[2],给人民的健康造成了极大的危害。
查阅文献发现,近年已经开发了许多替代的传统SAS 的检测方法。这些方法基于呼吸、血氧饱和度信号[4]、鼾声[5]、心电[6]等生理信号。但这些方法都涉及对生理信号的数据预处理、特征提取、特征选择。虽然特征工程非常重要,但这个过程需要相当多的领域专业知识,特别是高维数据。
呼吸暂停低通气指数(apnea hypopnea index,AHI)是衡量被试睡眠呼吸暂停综合征的一个重要指标[2]。现有技术大都是先获取睡眠监测的生理信号数据,对信号进行降噪滤波,然后将信号分段,人工提取信号特征,再训练一个神经网络预测信号片段是属于正常片段还是发生了睡眠呼吸事件,根据发生的睡眠呼吸事件计算AHI 值,最后根据AHI 值判断被试者SAS 的病情程度。这些方法需要对信号进行降噪和滤波,对于信号的抗干扰能力弱。除此以外,由于要对信号进行分段,所以还需要事件的标注数据。然而实际上事件的标注数据并不那么容易获取,而且这种分段的方法并不能直接做出睡眠呼吸暂停综合征严重程度的诊断。
针对以上问题,本文提出了一种基于整段血氧饱和度信号,利用卷积神经网络(CNN)实现直接诊断SAS 严重程度的方法。基于传统的医学诊断方法,根据AHI 值将SAS 划分不同的严重程度患者,即正常、轻度、中度和重度4 种[7]。通过卷积神经网络自动提取不同严重程度患者血氧饱和度的特征,将卷积神经网络提取到的特征结合被试的体征数据再通过全连接层进行分类,从而实现SAS 严重程度的直接预测。该方法使用的是整段的血氧饱和度信号,不再需要分割,也不需要专家标注各个信号片段的标签。血氧饱和度信号可以通过采用指套式光电传感器,只需将传感器套在被试手指上即可方便获取[8],而且对被试睡眠影响较小。该方法的数据易获取且不需要专家领域知识,有更好的通用性。
1 数据集和预处理
1.1 数据集
本研究中使用的数据,是广州某医院提供的实际临床数据。这些数据是从PSG 或者便携式PSG 设备采集到的。数据一共由1 684 个记录组成,每个记录都包括被试者的夜晚睡眠监测的血氧饱和度信号和一份医学的诊断报告,在诊断报告中有由医生做出睡眠呼吸暂停综合征严重程度诊断结果。
在训练过程中,将数据按照3∶1∶1 的比例划分为训练集、验证集和测试集。每份数据集的数量分别为1 008,338 和338。
1.2 数据处理
医院提供两份数据,即睡眠监测数据和医学诊断报告。
睡眠监测数据包含了被试者夜晚睡眠的生理信号监测数据。根据采集的PSG 设备不同,数据的通道个数和采样频率也各不相同。本研究将单一的血氧信号作为判断信号,所以首先从睡眠监测数据中提取血氧饱和度的数据,下采样频率为1 Hz。因为睡眠监测的初始阶段被试者尚未进入睡眠状态,同时在睡眠监测结束阶段,被试者已经醒来,但没有取下设备。所以在监测数据的初始和末尾阶段,被试者是清醒的。但是,医院没有提供睡眠阶段的标记,所以本研究根据传统诊断依据[7]只选择了睡眠监测过程中最中间的7 h 的数据。
从医院提供的医学诊断报告中提取被试者的基本体征数据和由医生作出的诊断结果。基本体征数据包括被试者的年龄、性别、身高、体重和体质量指数(BMI)。诊断报告中有被试者的AHI值,根据医学标准,将患者分成了正常、轻度、中度和重度4 种严重程度。被试者的SAS 严重程度作为训练标签。
从睡眠监测数据中提取被试者夜晚7 h 的血氧饱和度信号,结合从医学诊断报告中提取的体征数据作为训练模型的原始数据。对于模型训练,每一个样本的训练数据表示了被试者的体征数据和血氧饱和度,而每一个样本的标签则是其SAS严重程度。最后,根据原始数据训练卷积神经网络。数据的完整处理流程见图1。
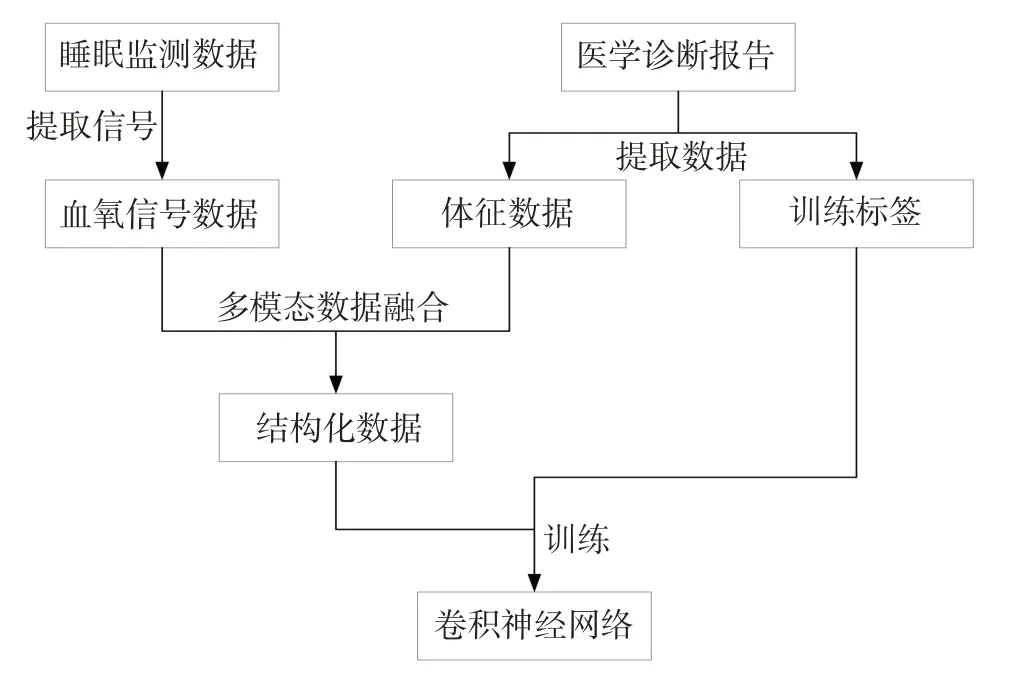
图1 数据处理流程
1.3 数据标准化和归一化
1.3.1 标准化 标准化更好地保持了样本间距,保留了数据中的异常点信息。当被试者发生睡眠呼吸暂停或低通气时,在被试者的血氧饱和度信号上会表现为血氧下降。为更好地保留血氧饱和度信号中的变化信息,所以对血氧饱和度信号进行了标准化。μ表示该样本血氧饱和度的期望,σ表示该样本的血氧饱和度的标准差,如公式(1)所示。

1.3.2 归一化 本研究使用了被试者的体征数据,年龄、性别、身高、体重和BMI 指数。归一化能够让不同维度的特征在数值上有一定的比较性。所以对被试者的体征数据进行归一化。xmax表示该体征在样本集中的最大值,xmin表示该体征在样本集中的最小值,如公式(2)所示。
心肌细胞是心脏泵功能的主要承担者,但数量仅占心脏细胞总数的30%~40%,其余为非心肌细胞,主要是成纤维细胞,占90%以上,还有少量的内皮细胞、巨噬细胞、血管平滑肌细胞等[2]。成纤维细胞通过合成细胞外基质和胶原酶等维持心肌细胞基质网络的稳态,进而维持心脏正常的结构和功能。当心脏出现心肌梗死等病理变化时,成纤维细胞将异常增殖并转化为肌成纤维细胞,促进心肌的纤维化重塑[3]。

2 方法
2.1 SAS 严重程度4 分类预测
使用卷积神经网络自动提取不同严重程度SAS 被试者夜晚整段血氧饱和度特征和基本体征特征。通过CNN 自动提取特征的方式代替了传统的专家提取特征。首先将每一条记录的夜晚监测7 h 的血氧饱和度信号输入的模型的第一个输入,通过三层卷积层,提取到血氧饱和度特征。然后将每一条记录的体征数据输入到模型的第二个输入,通过一层卷积层,提取到体征特征。然后进行特征融合,结合被试者的血氧饱和度特征和体征特征进行分类预测。模型最终输出的就是预测的SAS 严重程度。完整的模型框架见图2。

图2 CNN 模型结构
2.2 模型结构
本研究使用一个原始CNN 模型从各个记录的血氧饱和度信号中自动提取特征。提出的CNN 模型结构见图2,各结构参数见表1。本文选择Relu非线性激活函数作为CNN 模型的激活函数,同时选择使用KaiMing 初始化方法初始化卷积层的参数,这种方法对于非线性激活函数的模型有更好的效果[9]。

表1 CNN 模型结构
本文的CNN 模型结构由4 个负责提取特征的一维卷积层组成,即一个池化层,一个DropOut层,两层负责特征分类的全连接层以及一个Softmax 层。
CNN 模型的输入有两个。一是7 h 的频率为1 Hz 的单通道血氧饱和度信号,所以模型的第一个输入维度为1×25 200;二是被试者的体征数据,所以模型的第二个输入的维度为1×5。
首先,模型第一个输入的血氧饱和度信号先通过一个一维的BatchNormal 批归一化层。批归一化层负责对每一批次的数据进行归一化,批归一化能够防止梯度消失问题,减少梯度对参数或权重初始值的依赖,能有更大的学习率,加速网络训练速度[10]。经过批归一化层后,数据将进入第一个卷积层。第一层卷积层的卷积核数量为16,每个卷积核的大小为1×32。最后再通过Relu 激活层。接下来使用3 个卷积层和1 个池化层提取信号更高维的特征。在每次使用卷积层处理前都要通过1 个批归一化层进行归一化。在每次使用卷积层处理后,都需要通过1 个Relu 激活层进行非线性激活。经过第一个卷积层处理后,通过平均池化层,池化层的作用是减小数据维度,提高训练效率。模型采用的是平均池化的方法,对于输入的血氧饱和度信号的所有采样计算一个平均值,可以更好的将卷积层的特征与预测类别对应起来,池化可以降低参数量,整合了全局的空间信息,对于输入的特征有更好的鲁棒性[11]。第二层卷积层的卷积核数量为12,每个卷积核的大小为1×16。第三层卷积层的卷积核数量为6,每个卷积核的大小为1×3。模型的第一个输出经过以上三层模型处理后,从输入的维度1×25 200 处理成了维度6×12 567,最后再将数据展平成一个1×75 402 的向量,最后通过一个全连接层,最终模型第一个输入的输出维度为1×48。
模型的第二个输入是被试者的体征数据,维度为1×5。处理的过程与模型第一个输入类似,考虑到输入的维度较小,所以只使用了一个卷积层。第二个输入先通过一个BN 层,进行归一化,再通过一个卷积层。卷积核的数量为12,卷积核大小为1×3,再经过Relu 激活层激活后进行展平,展平成一个1×48 的向量。
本研究的模型有两个输入,一个是被试者的夜晚睡眠监测的血氧饱和度信号,另一个是被试者的基本体征数据。分别经过3 层卷积层和1 层卷积层处理后,将处理结果进行拼接。再经过一个全连接层进行4 分类。最终再经过一个Softmax层将结果映射到0~1 范围。模型最终预测结果即为被试者预测SAS 严重程度。
3 实验
3.1 实验设备
本文训练模型使用的硬件是一台GPU 工作站,具体配备的CPU 是Intel E5-2678@2.50GHz,显卡是Nvidia GeForce RTX 3090,内存为64 G。软件使用的CUDA 版本是11.4,Python 是3.8。选择Pytorch 作为深度学习框架。
3.2 模型性能评估指标
本文研究的是一个四分类任务,属于多分类任务。本文使用准确率Accuracy 作为评估模型总体性能的指标。准确率表示总体中被正确预测SAS 严重程度的样本数占总体的比例。但准确率只能给出总体的预测情况,并不能全面评估各个类别的准确率。所以本文还使用了查准率(Precision)、敏感性(Sensitivity)、特异性(Specificity)和(F1-Score)作为模型的各个类别的评价指标。混淆矩阵定义如表2 所示。

表2 分类混淆矩阵定义
查准率表示在被预测为某一类的样本中,实际为该类的样本的占比,即对于各个类别,被正确预测的比例,也被称为精确率查准率计算公式:

敏感性表示对于某一类样本,被正确预测的样本占比,也被称为查全率(Recall)、召回率和真阳性率,敏感性计算公式:
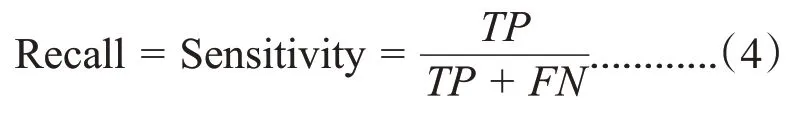
特异性表示在真实值为阴性的样本中,有多少样本被预测为阴性,也被称为真阴性率,特异性计算公式:
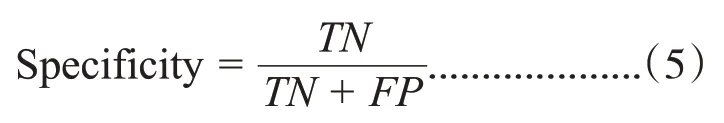
一般来说,查全率和查准率是互斥的,而F1-Score 是衡量两者的一个指标,F1-Score 越接近1表示查全率和查准率越好,计算公式为
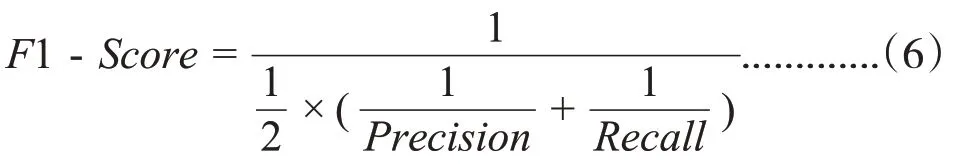
3.3 性能测试结果
如图3 所示,测试集中一共有338 例样本,总体准确率Accuracy 为86.39%。正常样本一共有98 例,其中有89 例样本被预测为正常,9 例被预测为轻度。轻度样本一共有85 例,其中有9 例被预测为正常,74 例被预测为轻度,2 例被预测为中度。中度样本一共有55 例,其中有14 例被预测轻度,40 例被预测为中度,1 例被预测为重度。重度样本一共有100 例,其中有11 例被预测为中度,89 例被预测为重度。

图3 CNN 预测结果
实验的总体准确率达到了86.39%,由图4、图5、表3 可以看出正常类别的准确率为90.82%,轻度类型的准确率为76.29%,中度类型的准确率为75.47%,重度类型的准确率为98.89%。实验的结果说明在缺少分段标签的条件下,使用7 h 整段的血氧饱和度信号,并结合基本的体征数据预测SAS 是可行的。
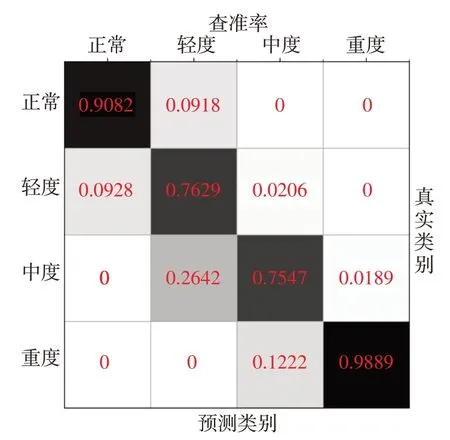
图4 各类别查准率
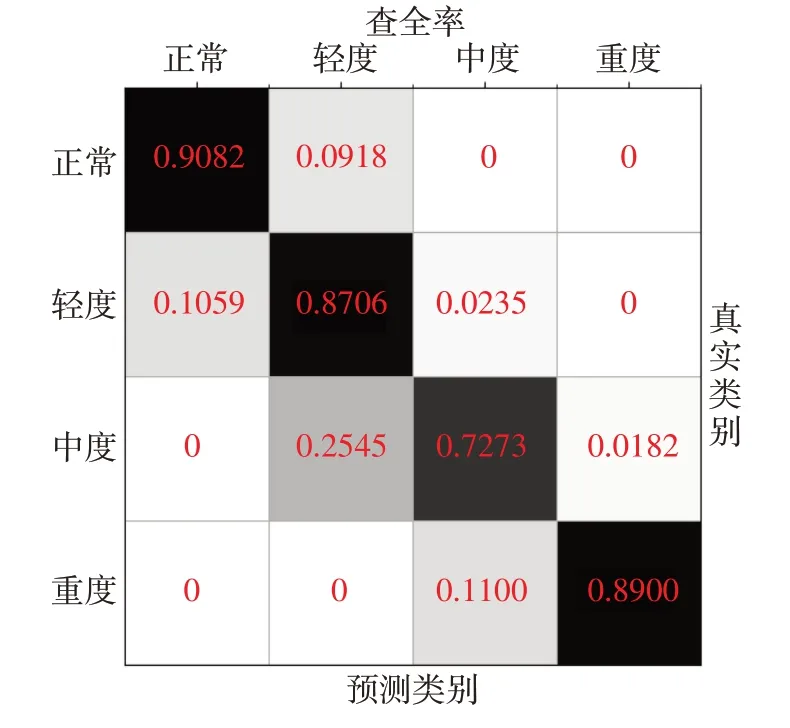
图5 各类别查全率

表3 各类别评估(%)
4 总结和展望
在本文研究中,在缺少分段标签的条件下,提出了一种使用CNN 提取血氧饱和度特征和体征特征的方法预测SAS 严重程度。从原始的夜晚睡眠监测中提取睡眠状态下7 h 的血氧饱和度信号,作为模型的第一个输入。从医生的诊断报告中提取被试者基本体征,作为模型的第二个输入。使用3 层卷积层提取血氧饱和度信号的特征,使用1层卷积层提取体征特征,然后进行特征融合,最后通过全连接层和Softmax 层,进行分类和模型输出。模型最终输出的结果就是被试者SAS 的严重程度。
实验结果表明,实验总体准确率达到了86.39%,其中正常类型的准确率达到了90.82%,重度类型的准确率更是达到了98.89%。实验证明了本文研究的方法,在缺少分段标签,使用整段信号的条件下,结合被试者的基本体征数据,能够良好预测SAS 的严重程度。为更多的二三线医院提供了许多患有SAS 未能得到及时诊断的解决方案。
在未来的工作中,由于本研究使用的轻度和中度样本数量有限,可以采集更多的样本数据提高轻度和中度类型的预测准确率。同时若能准确获取睡眠状态下的血氧饱和度信号,也能够提升模型的准确率。
