基于关键点预测的装配机器人工件视觉定位技术
2022-08-05张泮虹李文航赵亚辉张红彦翟海阳
倪 涛 张泮虹 李文航 赵亚辉 张红彦 翟海阳
(1.燕山大学车辆与能源学院,秦皇岛 066004;2.吉林大学机械与航空航天学院,长春 130022)
0 引言
装配作为产品生产的关键工序,实现其自动化能够提高生产效率,节约人力成本。机器视觉以及机器学习的发展为装配机器人的智能化发展指明了方向。装配机器人工件的定位技术大致分为基于图像特征、点云位姿以及深度学习3类。尚洋等[1]针对不同工况提出了一套完整的解决方案,在目标物体模型已知的情况下,提出了基于直线间积分距离度量的位姿测量方法,而对于模型不确定或未知的物体,结合光束平差法的思想,根据序列图像对物体模型进行修正或重建,求解物体位姿。发那科公司开发的iRvision[2]机器人视觉系统通过多个相机获取工件在不同维度的位置坐标,融合成工件的整体位姿,指导机器人进行作业并补偿偏差。以上基于手工特征方法的缺点是对环境和光照的要求较高,检测精度极易受到物体纹理、光照等因素的影响,算法稳定性差。方贤根[3]采用点云特征提取的方法获取工件的精确位姿。姜德涛等[4]将位姿估计过程分为粗配准和精配准两部分,并提出了四叉树逼近算法对ICP点云配准过程进行了优化,并最终得到了工件位姿。DROST等[5]在2010年提出了点对特征(Point pair feature,PPF)算法,将物体点云的点对特征作为描述子,在已知点云模型的情况下,用点对特征作为匹配基准来识别物体。HINTERSTOISSER等[6]在其基础上进行优化和改进,取得了较好的效果。张少杰等[7]针对匹配过程中的错误匹配提出了双阈值剔除算法。LI等[8]针对点云模型中的不必要描述特征导致的匹配性能降低,提出了稳定观察点对,通过构建全局模型特征描述子来实现速度匹配和精度平衡。点云匹配的方法虽然能够获得较高的检测精度,但要求预先建立高精度的物体点云模型,并无法解决物体遮挡问题。
相较于图像特征和点云匹配,近年来的深度学习给研究人员带来了新的思路和方向,文献[9]提出了一种位姿估计算法评估基准,并对15种不同方法进行评估,结果显示深度学习算法在精度和计算效率上均优于其他方法。在众多深度学习算法中,有以LINEMOD[10]为代表的模板匹配方法,该方法的缺点是当目标物体在场景中存在遮挡时无法完成匹配,BB8[11]和SSD-6D[12]则采用端到端的方式,将输入的图像分割识别出目标物体的二维包围盒,并使用经过训练的卷积神经网络预测物体的三维姿态,该方法将位姿估计视为一个整体,以图像作为输入而直接输出位姿,不能保证网络的泛化性。PVNet[13]将基于向量场投票的思想应用到关键点的预测上,通过投票得到物体关键点的坐标,再使用PnP算法计算物体位姿,有效解决了目标物体被遮挡的问题。PoseCNN[14]则是先提取出不同分辨率下图像的特征,分割出图像中物体的像素,再依次得到物体的平移和旋转向量。CHEN等[15]提出了一种实时估计目标物体位姿的网络框架G2L-Net。HE等[16]提出了PVN3D位姿估计网络框架,同样以深度图像作为输入,由特征提取模块融合外观特征和几何信息,将特征输入三维关键点检测模块,通过训练预测每个点的偏移量,并最终使用最小二乘拟合算法应用于预测关键点,估计出位姿参数,这些学习框架都是基于开源的数据集,无法保证经过训练之后能够学习到足够的特征,对最终工件的检测精度造成一定的影响。
本文采用深度学习的方式,对基于关键点预测的工件视觉定位技术展开研究。采集工件各个角度的彩色图像和深度图像的信息,计算得到工件的位姿信息,选取工件表面的关键点作为数据集。然后构建关键点的向量场,实现前景点指向关键点的向量场预测,将其与数据集一同输入深度网络中进行训练,得到输入工件图像的关键点预测结果,以此为基础实现工件的位姿估计,并对位姿结果进行可视化。
1 六自由度位姿估计数据集构建
构建的数据集用于网络模型的训练,直接决定了预测结果的准确率,本文针对构建位姿估计数据集时位姿数据难以测得的问题,使用ArUco位姿检测标识和ICP点云配准技术构建了一组用于训练位姿估计网络模型的数据集。
1.1 ArUco标识位姿解算
采用相机对标识进行图像采集,并进行阈值化处理进而增强图像主体,如图1所示。但是,由于图像中标识或大或小(图2)都会影响标识的检测结果,因此在进行位姿检测时需设定标识角点到图像边缘的最小距离,在获取位姿时舍弃掉角点超出图像边缘或离边缘较接近的标识,以获得准确的结果。检测图像中所有轮廓,通过轮廓滤波,剔除掉一些标识可能较小的轮廓,丢弃掉错误的候选,减少候选目标,以降低下一阶段的计算消耗。过滤得到候选结果后,通过比特位提取对其进行解码,确定图形是否为标识。最后,针对每个图形提取出的比特位序列进行错误检测,判断是否属于标识字典。对于边界宽度为1的标识来说,边界所对应的比特位一定为黑色,可以直接剔除不符合条件的结果。以比特位为索引,在字典内查找标识,若匹配成功,则返回标识ID。

图1 标识阈值化Fig.1 Signals thresholds

图2 标识过小(左)过大(右)Fig.2 Signs too small (left) and too large (right)
在成功匹配标识的情况下,对标识的位姿进行求解,即计算从标识坐标系到相机坐标系的刚体变换矩阵。假设世界坐标系{O}在标识坐标系所在平面{m}上,即Z=0,并且已知标识4个角点在世界坐标系下的位置,可以通过文献[17]中的DLT算法计算标识图形由世界坐标系到图像坐标系的单应矩阵,即标识的齐次变换矩阵,并且这种方法能够将由于角点在图像中的像素信息误差导致的定位误差最小化。最终得到的标识位姿结果如图3所示。

图3 ArUco标识位姿识别结果Fig.3 ArUco signals pose recognition results
1.2 工件位姿解算
通过ArUco标识已经计算出标识位姿,建立起标识坐标系相对相机坐标系的位姿变换关系,能够求得每帧间标识坐标系的位姿变换矩阵。由于标识和工件在同一水平面,且相对位置保持不变,则每帧图像间工件坐标系的刚体变换矩阵与标识坐标系变换矩阵相等。之后,只需要确定初始状态的工件位置,再根据坐标系的刚体变换,即可求得每帧图像中工件的位姿。
本节利用ICP点云配准技术[18],对实验场景进行三维重构,如图4所示;获取工件点云模型,如图5所示;再次使用ICP点云配准技术,将工件模型与初始状态下的点云图像进行配准,得到图像中工件点云相对于相机坐标系原点的刚体变换矩阵,即工件在初始化状态下的位姿。

图4 场景三维点云配准结果Fig.4 Scene 3D point cloud registration results

图5 工件点云模型Fig.5 Workpiece point cloud model
2 基于深度学习的关键点向量场预测
由于直接预测关键点会带来误差,对结果的准确度影响很大。而采用间接方式先预测图像中工件区域各像素点指向关键点的方向向量,构建向量场,再获取关键点坐标,这样能够获得更好的鲁棒性,能够最大程度降低局部误差对整体结果产生的影响。并且通过这种方式还能够在物体受到一定程度遮挡或截断的情况下,即使有些关键点无法被看到,利用刚体的特性,仍然能够根据可见部分像素的向量场来预测出被遮挡关键点的位置,进而估计出工件的位姿。
2.1 关键点选取
为保证求解位姿时具有更高的准确度,关键点需尽量分散。本文使用最远点采样(Farest point sampling,FPS)[19]在工件表面选取8个点,但是对于某些作为装配基准面的零件表面则需要更高的定位精度,因此也选定了若干点作为基准关键点,使系统在位姿计算时考虑到局部信息。FPS在选取关键点时,需计算{b1,b2,…,bn-k+1}与{a1,a2,…,ak-1}间的距离,每次选取计算(n-k+1)(k-1)个距离,占用大量的计算消耗,在选取过程中包含许多重复计算,本文对计算过程进行了优化。

(1)
其中
式中 distance(b,a)——点b与点a间的距离运算函数

(2)
经过优化,选取第k个关键点时只需计算n-k+1个距离,有效降低了计算消耗。
2.2 基于改进的ResNet18向量场预测
向量场在PoseCNN[14]算法中首次被提出,PVNet将这种方法用于关键点的预测,本文使用改进后的ResNet18深度残差网络[20]模型作为PVNet神经网络框架的主体实现目标检测,其结构如图6所示。
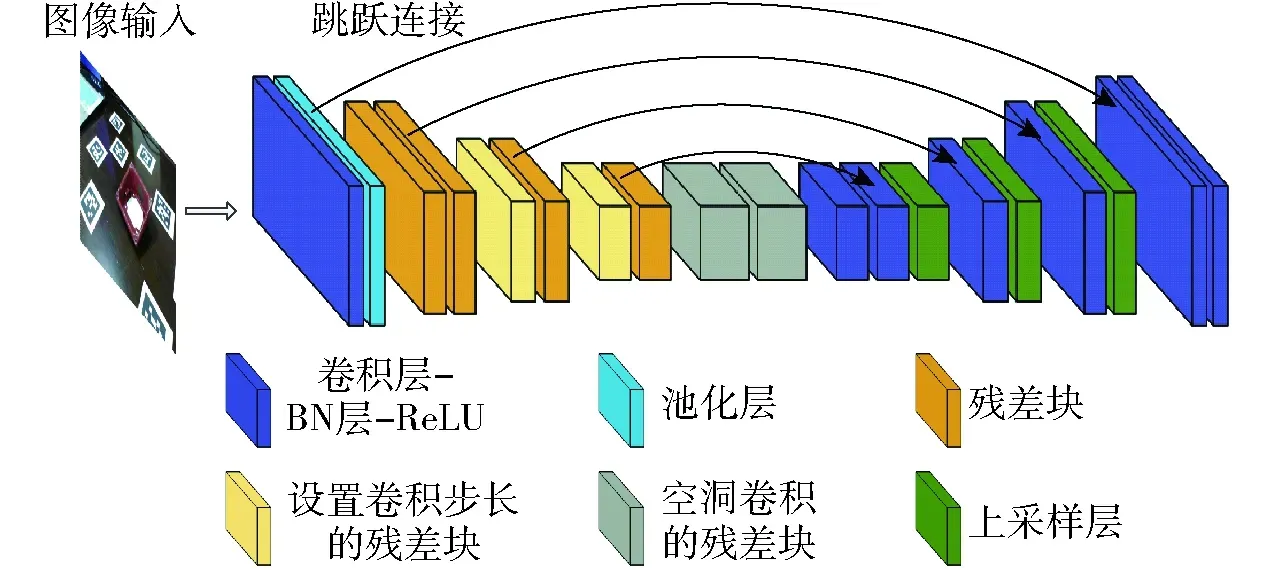
图6 PVNet神经网络结构图Fig.6 PVNet neural network structure diagram
PVNet的主要任务有:①对输入的图像进行语义分割,得到工件的图像掩码,即目标区域。②预测目标区域像素点对于每个关键点的向量场。
图像输入到网络模型后,首先进行一系列的池化操作提取出图像特征;然后对经过卷积提取出来的抽象特征进行上采样操作,一般是通过反卷积来实现[21];最终预测每个像素的类别标签并以图像掩码的方式输出,得到工件区域像素所对应的目标区域。
ResNet深度残差网络[22]是一种深度学习网络结构,和常规的深度网络最大的不同之处在于深度残差网络除了普通堆叠外还引入了捷径,将经过权值叠加后的输出和输入连接到一起组成并联网络,可使训练过程更加高效,如图7所示。
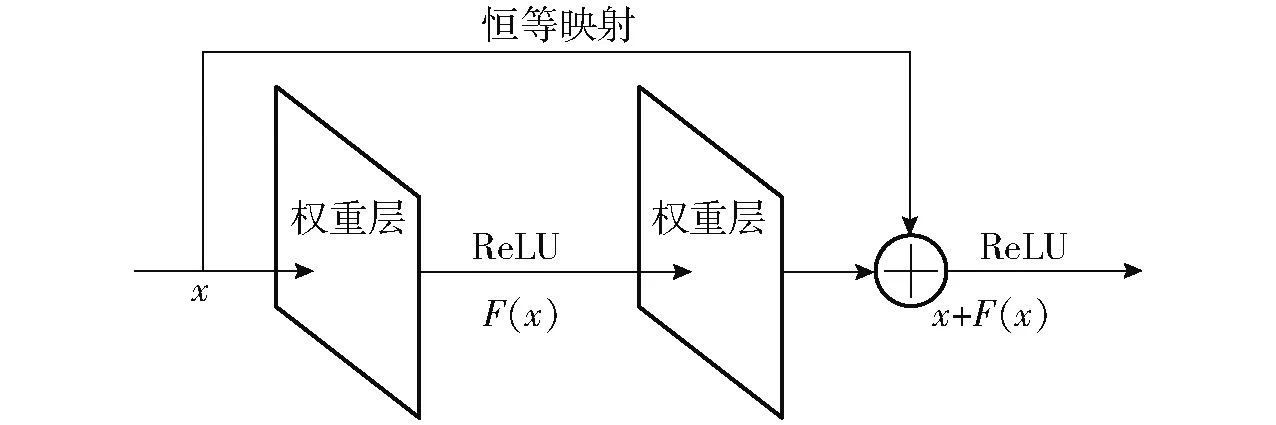
图7 残差网络基本单元Fig.7 Basic unit of residual network
2.3 模型训练
由于位姿估计数据集属于小样本数据集,随机初始化从头开始训练容易出现过拟合现象,且模型的特征提取泛化能力不强,本文使用经过ImageNet预训练的ResNet网络模型,ImageNet数据集作为图像识别最大的数据库,是按照WordNet架构组织的大规模带标签图像数据集,约包含1.5×107幅图像,2.2×104类,每幅图像都经过了严格的人工筛选和标记。ImageNet作为执行过大量数据特定分类任务的模型,其浅层网络对于图像特征的提取能力以及网络泛化能力都有较好的提升,能够获得一组较优的权重。
模型训练采用Adam[23]优化器以及反向传播算法[24]对参数进行优化,将参数β1和β2分别设置为0.9、0.99。初始学习率设置为0.001,权值衰减系数为0.85,每5个训练期衰减一次,直到0.000 01,批量设置为8,α初始值为1,每个训练期放大1.1倍。
3 基于关键点生成假设的位姿计算
3.1 生成关键点假设
根据随机抽样一致(Random sample consensus,RANSAC)[25-26]的思想,从样本中选取初始值,作为局内点估计出模型参数。对于关键点预测问题,首先生成关键点的所有假设,确定各个关键点可能存在的所有位置。

图8 生成关键点假设Fig.8 Generating key point hypothesis

3.2 关键点投票策略及优化
在成功得到由向量场生成的关键点假设后,对于每一关键点的所有假设,使用投票的方式计算各个关键点假设的置信度。
从关键点假设的集合中按顺序每次取出一点作为待测试模型。然后计算前景层内像素点的数量,若数量大于n则从中随机抽选n个点作为测试点,若小于n则全部取出。之后,计算测试点指向关键点假设的矢量,并与测试点对应的方向向量进行比较,若两者间误差低于阈值,则视为该测试点适应此模型,将其扩充进内点集Pinlier,并为该关键点假设累计1投票得分,否则将该测试点归为局外点,如图9所示。
投票分数ωk,i计算式为[27]
(3)


(4)
式中θ——模型阈值,用于判断数据点是否适应此模型,取0.99
在经过一系列迭代后,根据投票分数ω,得到最优的关键点假设hwin,并对模型进行更新。由于在上一步生成关键点假设时,有些像素点对应的方向向量误差较大,由这样的点生成的假设也一并纳入,会对估计结果产生影响,现在在将局外点剔除的情况下重新估计模型。首先选取扩充后的内点集Pinlier,使用2.1节的方法令各点方向向量两两相交生成关键点假设,再由内点集中的各点对重新得到的关键点假设投票,得到最终关键点的预测结果。
n点透视投影(Perspective n point,PnP)[28]是一种被广泛应用于根据输入点对来计算位姿变化矩阵的方法。选取其中最有效的有效n点透视投影(Efficient perspective n point,EPnP)方法对工件的位姿进行求解,如图10所示。最后采用基于主成分分析法[13]的有向包围盒进行位姿求解,结果如图11所示。
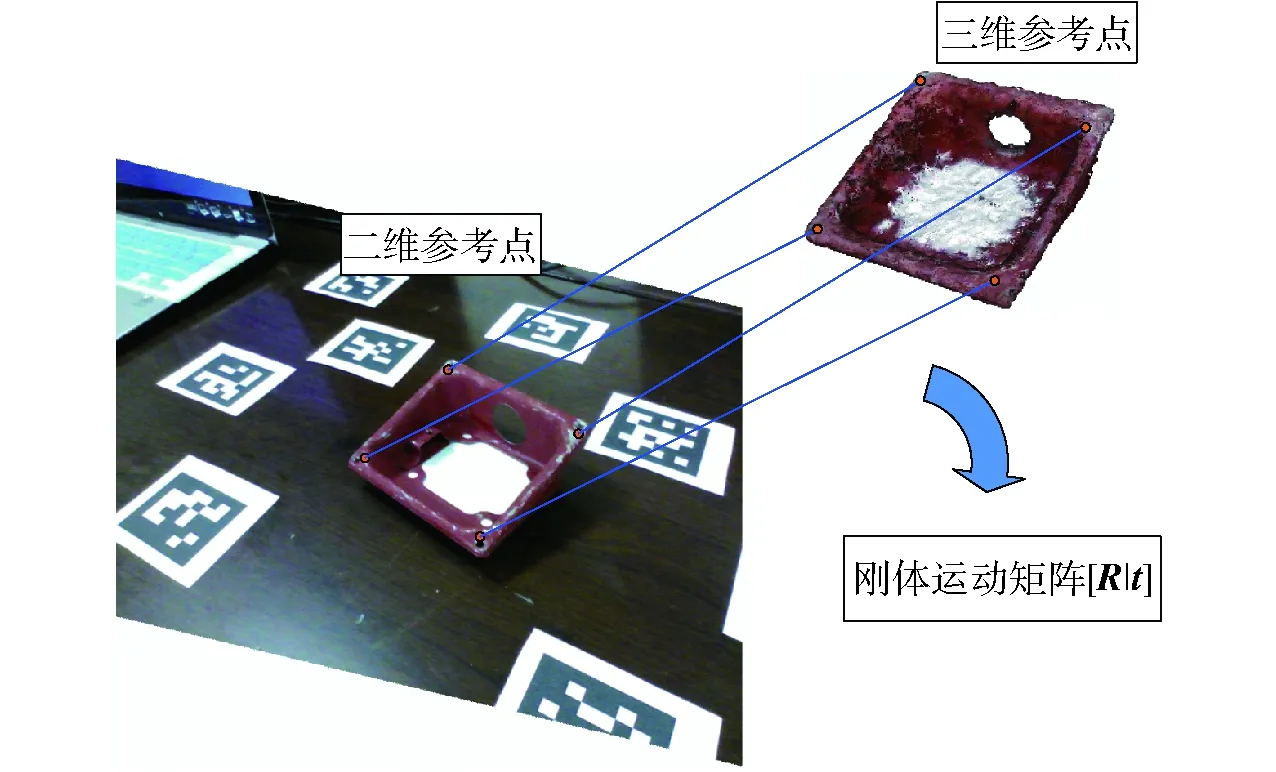
图10 EPnP求解Fig.10 EPnP solving

图11 有向包围盒的生成Fig.11 Generation of directed bounding boxes
4 实验及分析
在Ubuntu 16.04 LTS操作系统下进行各部分的实验。硬件设备使用Intel i7-8700K处理器,16 GB运行内存,显卡为NVIDIA GTX 1080,显存为6 GB,在GTX1080ti的GPU下,以速度0.025帧/ms进行处理。
4.1 向量场预测实验
将测试集中的图像输入神经网络模型进行预测,本次实验根据FPS算法选取了8个关键点,包括工件的中心点在内共9个关键点,最终网络输出的各个关键点的像素点向量场示意图如图12所示。

图12 输出各关键点向量场示意图Fig.12 Output vector field schematic of each key point
4.2 位姿估计实验
在向量场已知的情况下,利用向量交叉法得到所有的关键点假设,并由投票点对假设点进行投票,根据投票结果计算参考点并传入PnP求解器,求得位姿结果由有向包围盒显示,并与数据集中的位姿进行对比,如图13所示。图中绿色包围盒为数据集中真实位姿结果,蓝色包围盒为系统输出的位姿估计结果。根据文献[28]中的ADD度量对本次实验中810帧图像的预测结果进行评估,得到正确结果百分数为86.05%。

图13 位姿估计实验结果Fig.13 Pose estimation experimental results
为了进一步对工件位姿估计结果进行评估,使用Steward六自由度并联机器人搭建实验平台进行实验,如图14所示。将工件连接在并联机器人的上平台表面,控制并联机器人运动,并使用视觉定位系统估计工件位姿。在实验过程中,由电动缸传感器计算并联机器人上平台坐标系的位姿,进一步计算工件位姿,并与视觉定位系统位姿估计结果进行对比。结果表明,通过传感器检测的位姿结果精度较高,上平台位姿定位误差小于1 mm,上述方式能够评估视觉定位系统的性能。

图14 实验平台Fig.14 Experimental platform
并联平台位姿采样间隔为5 ms,视觉系统每帧图像的检测周期为40 ms,工件x、y、z3轴转角对比曲线如图15所示。工件在稳定状态下转角估计结果较为平稳,沿某一方向开始运动时,3轴转角的估计结果均发生抖动,其中,在x、y轴方向上检测误差均值分别为2.61、3.02 mm,平台沿z轴方向进行升沉运动时,检测结果容易发生抖动,误差均值为4.2 mm,但是总体来看,视觉识别系统能够在误差允许范围内估计出运动工件的位姿。

图15 转角曲线Fig.15 Angle curves
4.3 遮挡物实验
由于位姿估计过程中,通过工件的所有像素点投票得到关键点位置,所以即使物体局部受到遮挡,被遮挡的关键点也能由未被遮挡部分的像素点预测得出,使得系统在工件被部分遮挡的情况下依然有效。为了验证视觉定位系统对于物体被截断或遮挡情况下的识别能力,采集特定图像作为输入进行了实验,图16为先对图像进行随机旋转和裁剪操作再输入系统得到的结果,图 17为采集图像时对工件主体施加人为的遮挡得到的结果。由实验结果可见,本系统在物体被截断及遮挡的情况下仍具有一定的识别能力。

图16 被截断工件位姿估计Fig.16 Pose estimation of truncated workpiece

图17 被遮挡工件位姿估计Fig.17 Pose estimation of occluded workpiece
4.4 鲁棒性实验
为了验证视觉定位系统的鲁棒性,对位姿识别的场景施加了扰动,测试了在复杂背景、干扰物多以及人为施加干扰情况下的实验情况,如图18所示。实验结果验证了视觉定位系统有一定鲁棒性,能够在一定程度上在工作场景发生变化的情况下识别出目标物体。

图18 施加扰动的工件位姿估计Fig.18 Pose estimation of workpiece with perturbation
4.5 定位精度对比实验
目前较为成熟的基于特征匹配方法和本文所述的基于关键点预测方法的检测误差对比,实验所用检查样本是第1节所建的数据集,如图19、20所示,从实验结果可以看出,除去部分采集图像,本文所述的基于关键点预测的工件定位精度得到了一定程度的提高,尤其在容易发生抖动的z轴方向效果更为显著。因为检测的工件是放置在平面上,故x、y轴方向的旋转误差没有考虑。

图19 工件误差曲线Fig.19 Error curves of workpiece

图20 工件绕z轴旋转误差曲线Fig.20 Error curves of workpiece rotation about z axis
5 结论
(1)输出的由FPS算法选出的关键点向量场表明了所搭建的PVNet深度模型框架的有效性。
(2)通过ADD位姿估计标准对定位系统进行评价,对810帧图像的预测结果进行评估,得到正确结果的百分数为86.05%。
(3)针对主体被截断、遮挡以及画面中存在干扰的情况,实验结果表明所述系统具有一定的鲁棒性。
