基于位置依赖的密集融合的6D位姿估计方法
2020-06-24黄榕彬


摘 要:基于RGBD的6D位姿估计方法的一个关键问题是如何进行彩色特征信息和深度特征信息的融合。先前的工作采用密集融合的方法,主要关注的是局部特征和全连接层提取的全局特征,忽略了远距离像素间的位置依赖关系。文章提出通过捕获像素间的位置关系,并将其与彩色特征图和几何特征图进行密集融合,最后逐像素预测物体的6D位姿。实验结果表明,该文的方法相比其他方法在YCB-Video数据集上获得更优的结果。
关键词:6D位姿估计;弱纹理;RGB-D;密集融合
中图分类号:TP751 文献标识码:A 文章编号:2096-4706(2020)22-0016-04
6D Pose Estimation Method Based on Position Dependent Dense Fusion
HUANG Rongbin
(Guangdong University of Technology,Guangzhou 510006,China)
Abstract:One of the key problems of the 6D pose estimation method based on RGBD is how to fuse the color feature information and depth feature information. Previous work used dense fusion method,mainly focused on local features and global features extracted from fully connected layer,ignoring the position dependence between remote pixels. The article proposes that by capturing the positional relationship between pixels and intensively fusing it with the color feature map and geometric feature map,the 6D pose of the object is predicted pixel by pixel. Experimental results show that the proposed method achieves better results than other methods on YCB-Video dataset.
Keywords:6D pose estimation;weak texture;RGB-D;dense fusion
0 引 言
物體的6D姿态估计可以广泛应用于机器人抓取、虚拟现实、自动驾驶等领域。笔者实验室致力于研究机器人的工业应用,为将物体6D位姿估计应用到机器人抓取或者工业焊接领域,需进一步提高6D位姿估计算法的精度和鲁棒性。为此,笔者提出将一种新的RGBD融合方法,以提高6D位姿估计的精度。
目前6D位姿估计的主要方法大致可以分为基于RGB的方法和基于RGBD的方法。基于RGB的方法主要有:传统方法[1,2]、基于关键点的方法[3]和直接回归[4]的方法。其中,基于关键点的方法主要通过获取图像的关键点,再利用PnP计算目标物体位姿。直接回归的方法是通过CNN直接回归得到物体的位姿,由于缺乏深度信息,导致这类方法在使用时存在较大的困难[5]。
基于RGBD的主流方法有通过RGB获取粗略的位姿,再利用深度信息细化位姿和通过融合RGB特征和深度特征获取位姿。第一种方法实时性较低,第二种方法的典型代表是PointFusion[6]和DenseFusion[5]。PointFusion采用全局融合RGB特征和深度特征,进而回归得到物体的位姿。由于是基于全局特征回归得到位姿,当物体存在遮挡时,被遮挡部分将直接影响识别精度。DenseFusion采用逐像素密集融合的方法,通过每个融合的像素特征分别回归得到位姿,再通过投票得到置信度最高的位姿。然而DenseFusion主要关注的是局部特征和通过多全连接层获取的全局特征,忽略了像素之间的位置关系。受Non-local[7]的启发,本文提出逐像素融合物体像素之间的位置关系,进一步丰富每个像素特征的信息,以提高每个像素的识别精度。
1 算法介绍
基于RGBD的6D位姿估计问题是指给定目标物体所在场景的彩色图像和深度图像,计算物体的旋转矩阵R∈SO(3)和平移向量t∈3,为方便计算,通常统一为:
其中,T为齐次变换矩阵,SO(3)为特殊正交群,SE(3)为特殊欧式群。
1.1 总体概述
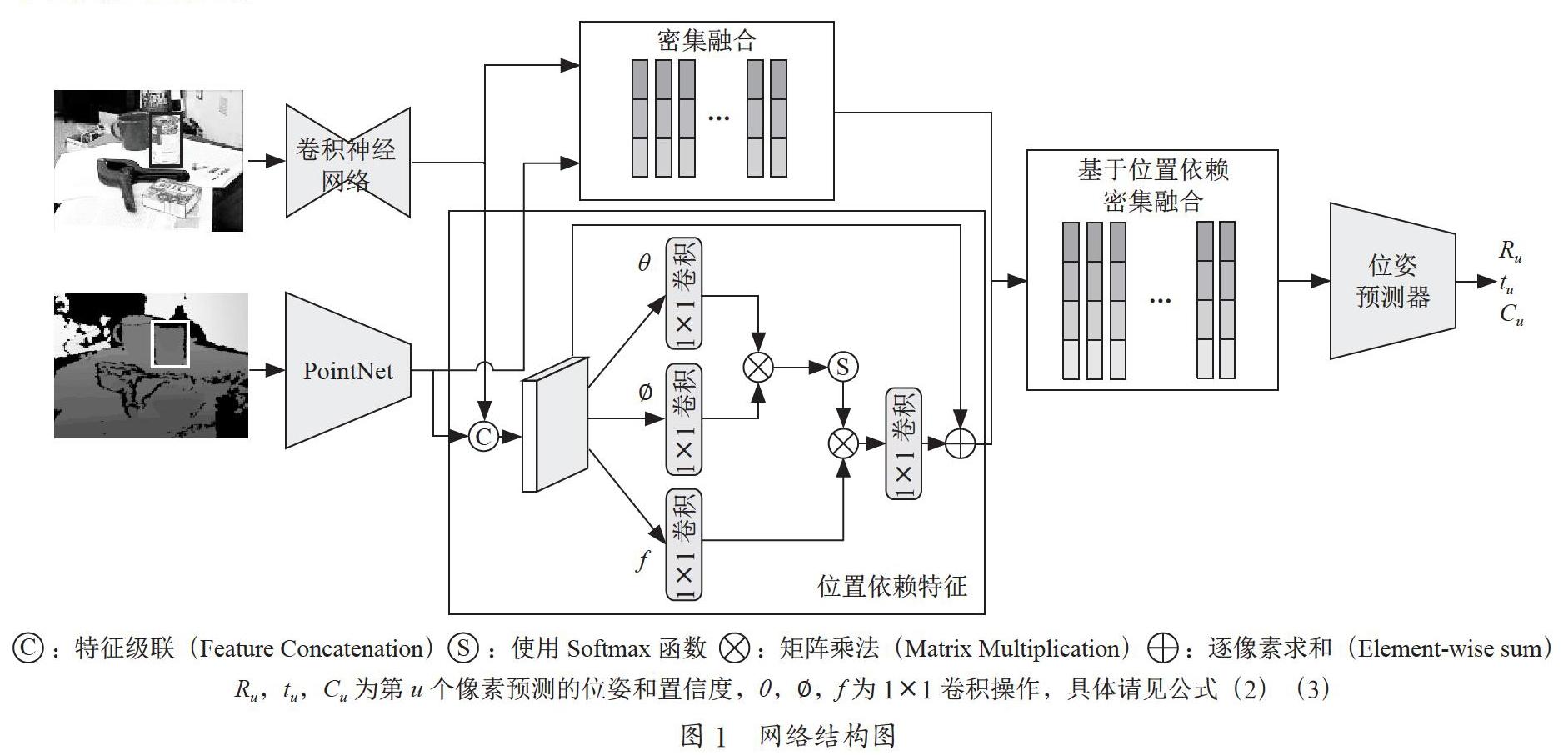
受Non-local的启发,本文介绍了一种新的RGB数据和深度数据融合方法,主要应用于物体的6D位姿估计。该方法是在DenseFusion的基础上,通过自注意力机制获取像素间的位置依赖,进一步融合像素之间的位置依赖,以丰富每个像素的特征信息,提高位姿估计的精度。本文提出的方法的网络结构如图1所示,主要包含三个步骤,语义分割、位置依赖特征提取与逐像素融合,最后通过改进的位姿细化网络优化得到的位姿。
1.2 语义分割
第一步,采用语义分割网络获取彩色图像中目标对象的掩摸,然后利用掩摸从彩色图像和深度数据中获取只包含目标对象的图像块和目标对象的深度数据,并将深度数据转换为点云数据。在此为了更好的与已有的工作进行对比,采用了PoseCNN[8]的语义分割结果。
1.3 位置依赖特征提取与逐像素融合
第二步,从目标对象的图像块和点云数据中分别提取彩色嵌入特征、几何嵌入特征和位置依赖特征。在此,采用了DenseFusion中的Encoder-Decoder结构的卷积神经网路从图像块中提取彩色嵌入特征,采用PointNet[9]从点云数据中提取几何嵌入特征。基于Non-local网络提取位置依赖特征。
DenseFusion采用全连接层获取全局特征。全连接层可定义为:
其中,i为输入的位置索引,j为输出的索引,x为输入信号,w为权重,f为激活函数,y为输出信号。
全连接层的输出仅考虑每个位置的响应对于输出的影响,而忽略了每个位置之间的依赖关系对于输出的影响。受Non-local的啟发,本文提出进行逐像素融合时,考虑像素间的依赖关系,将像素间的依赖关系作为位置依赖特征与彩色嵌入特征和几何嵌入特征进行融合。位置依赖特征的定义为:
其中,g为计算i,j两个位置间的依赖关系的函数,C为归一化因子。若函数g采用嵌入空间下的高斯函数或者点积相似函数,那么可以采用矩阵乘法进行替代计算[7]。在此选用嵌入空间下的高斯函数[7]:
因此,将式(3)转成矩阵相乘,转换成了图1中位置依赖特征的提取模块。通过该模块获取位置依赖特征图,将彩色嵌入特征图、几何嵌入特征图、位置依赖特征图进行逐像素融合。最后将融合的结果输入位姿预测器中回归得到每个像素的预测结果和对应的置信度,将置信度最高的位姿作为最终的预测结果。
1.4 位姿细化改进模块
由于采用ICP算法细化位姿的实时性较差,DenseFusion[5]提出了一个细化迭代网络,主要思想是采用预测的初始位姿渲染模型获取点云数据,并将其输入PointNet[9]中获取几何嵌入特征,将得到的几何嵌入特征和彩色嵌入特征图融合获取全局特征,并用于预测位姿残差,生成新的位姿,再进行下一次迭代。该网络也没有考虑像素间的位置关系。因此,本文提出通过提取像素间位置关系,与全局特征图进行融合,进一步丰富特征信息,以提高精度。改进后的位姿细化网络结构图如图2所示。
1.5 损失函数
损失函数采用ADD和ADD-S[8]。ADD是指计算真实位姿下的对象模型上的采样点与预测位姿下的对象模型上的对应点的距离。给定真实的旋转矩阵R和平移向量t以及预测的旋转矩阵 和平移向量 的情况下,损失函数Lu定义为:
其中,Lu为第u个像素预测的位姿的损失值,M为从三维点云模型任意选择的点的数量,xv为M个点中的第v个点。
ADD对于非对称性物体表现良好,ADD-S则是针对对称物体,具体是指计算估计位姿下的对象模型的采样点与真实位姿下的对象模型上最近点的距离,定义为:
其中,k为真实位姿下的对象模型上点的索引。
本文采用每个像素均预测一个位姿和置信度的方法,为使得网络学习平衡每个像素的误差和置信度,将整体的误差定义为[5]:
其中,N为特征图像素特征的数量,ω为平衡超参数,cu为第u个像素预测的位姿对应的置信度。
2 实验结果
本文采用YCB-Video数据集[8]评估本文提出的方法,并和其他方法进行对比。评价指标采用Yu Xiang等人[8]提出的ADD和ADD-S。
表1展示了本文提出的方法与其他方法的对比,可以看出进行位姿细化的结果比其他方法更优,整体的平均AUC提升了1%,其中picher_base和wood_block两个类别均提升了4%,extra_large_clamp更是提高了19%。当然,也存在部分物体的精度下降了,其中scissors下降了17%,目前的判断是因为该物体较小,当使用图像块预测位姿时,物体所占的像素比例较小,导致像素之间的位置关系引进了更多的噪声,进而导致识别精度较低,本文提出的方法对于体积较大的物体精度较高。但整体而言,如图3所示,本文提出的方法在YCB-Video数据集上表现优于目前的主流方法。
3 结 论
本文提出了一种基于位置依赖的逐像素融合的6D位姿估计网络。在我们的方法中,通过提取像素间的位置依赖关系获取位置依赖特征图,将位置依赖特征图逐像素融合进位姿估计网络中和位姿细化网络中,以丰富每个像素的特征信息。在YCB-Video数据集中的实验表明,与DenseFusion相比,我们的方法的性能得到了提升。
参考文献:
[1] LUCA V,VINCENT L,PASCAL F. Stable real-time 3D tracking using online and offline information [J].IEEE transactions on pattern analysis and machine intelligence,2004,26(10):1385-1391.
[2] LOWE D G. Object recognition from local scale-invariant features [C]//Proceedings of the Seventh IEEE International Conference on Computer Vision.Kerkyra:IEEE,1999:1150-1157.
[3] PENG S D,LIU Y,HUANG Q X,et al. PVNet:Pixel-wise Voting Network for 6DoF Object Pose Estimation [C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR).Long Beach:IEEE,2019:4556-4565.
[4] KEHL W,MANHARDT F,TOMBARI F,et al. SSD-6D:Making RGB-Based 3D Detection and 6D Pose Estimation Great Again [C]//2017 IEEE International Conference on Computer Vision (ICCV).Venice:IEEE,2017:1530-1538.
[5] WANG C,XU D F,ZHU Y K,et al. DenseFusion:6D Object Pose Estimation by Iterative Dense Fusion [C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Long Beach:IEEE,2019:3338-3347.
[6] XU D F,ANGUELOV D,JAIN A. PointFusion:Deep Sensor Fusion for 3D Bounding Box Estimation [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:244-253.
[7] WANG X L,GIRSHICK R,GUPTA A,et al. Non-local Neural Networks [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:7794-7803.
[8] XIANG Y,SCHMIDT T,NARAYANAN V,et al. PoseCNN:A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes [J/OL].arXiv:1711.00199 [cs.CV].(2017-11-01).https://arxiv.org/abs/1711.00199.
[9] QI C R,SU H,MO K C,et al. PointNet:Deep Learning on Point Sets for 3D Classification and Segmentation [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Honolulu:IEEE,2017:77-85.
作者簡介:黄榕彬(1995—),男,汉族,广东揭阳人,硕士研究生在读,研究方向:6D位姿估计。
