学习型数据库索引推荐技术综述
2022-07-22杨国平乔少杰屈露露魏盛杰元昌安
杨国平,乔少杰,屈露露,韩 楠,魏盛杰,元昌安
(1.成都信息工程大学 软件工程学院, 成都 610225; 2.成都信息工程大学 管理学院, 成都 610103;3.四川音乐学院 数字媒体艺术四川省重点实验室, 成都 610021;4.广西教育学院, 南宁 530023)
0 引言
人工智能(artificial intelligence,AI)和数据库(database,DB)在过去的50年中得到了广泛的研究[1-3]。首先,数据库系统在许多应用中得到了广泛的应用,因为数据库通过提供用户友好的声明式查询范例和封装复杂的查询优化函数而易于使用。其次,人工智能最近取得突破得益于三大驱动力:大规模数据、新算法和高计算能力。此外,人工智能和数据库可以相互受益[4-5]。
传统的数据库技术往往依赖于人工算法或人工干预,如数据库参数调整、故障诊断、索引推荐等[6]。但在大数据时代,数据库实例较多,脚本更复杂,数据量更大,传统的数据库索引技术很难满足大数据的需求,比如云数据库中有数以百万计的数据库实例,DBA(database administrator)不可能完全控制百万计的数据库实例,一旦DBA对管理疏忽,后果不堪设想,而且不同实例的应用和用户使用水平也有很大差异。传统的算法很难泛化,人工干预难以处理更多的案例。
机器学习可以通过学习历史数据中的关系,辅助DBA做决策。机器学习技术在许多科学研究领域得到了广泛的应用[7-9],机器学习也为数据库索引优化技术提供了新的可能性,比如传统的机器学习模型:线性传回归[10]、随机森林[11]、支持向量机[12]和集成学习[13]等,从历史数据中积累“经验”,可以提高解决复杂问题的能力。但是传统的机器学习模型只能描述一个层次的学习过程,而且相对简单,例如简单的线性回归模型难以求解高阶参数和连续参数空间[14],于是深度学习(deep learning,DL)与强化学习(reinforcement learning,RL)被提出,有学者将DL与RL结合,变成深度强化学习(deep reinforcement learning,DRL),使用DRL模型可以解决NP-hard问题,因为它可以搜索庞大的解空间。人工智能可以使数据库更加智能化(AI4DB),使用人工智能去优化数据库(如代价估计、连接顺序选择、节点调整、索引和视图推荐等)是目前以及未来的研究热点。
基于索引推荐的不同阶段,本文将其分为索引生成与索引选择两部分。索引生成是为了生成满足数据库的索引数据结构,而索引选择是选择建立索引的方案。本文对索引生成技术和索引选择技术进行综述。索引对于提高复杂数据集的搜索和查询任务效率非常重要,特别是在处理事务负载时,将索引嵌入适当的列可以很大程度上提高处理效率[15]。
传统数据库采用通用的索引结构(如:B-Tree),这种索引结构只能让搜索数据时的速度有保障,但它没有利用数据之间的分布以及数据库中其他信息。此外,数据集越大,索引也就越大,很容易造成空间浪费。因此,需要一种高效的索引技术来支持数据库的应用。
对于索引选择,首先定义索引选择问题如下:假设存在表集合T,令C表示T中所含表的列集合,其中,某一列c上的索引大小为Size(c),c∈C。给定一个查询集合Q,给某一查询q在列c上建索引的奖励定义为Reward(q,c),其中q∈Q,c∈C,再给定一个空间限制S,索引选择的目的就是找到一个列子集C*去构建索引,要使奖励Reward达到最大且索引总大小不得超过S,形式化表示如下:Maximize ∑ Reward(q∈Q,c∈C*),且∑ Size(c∈C*)≤S。这里有几个挑战。一是如何估计奖励Reward(q,c),一个常规的方法是使用一个假设的索引,它将索引信息添加到数据库管理系统(DBMS)的数据字典中,而不是创建实际的索引,从而使DBMS中的查询优化器能够识别索引的存在并估计查询执行的代价,而不必建立真正的索引。一个索引的估计奖励是在有或没有假设索引的情况下,查询执行的估计代价之差。二是解决优化问题,有2个主要的解决方案来解决这些问题:静态索引选择和动态索引选择。静态索引选择方法要求DBA提供一个通用的查询负载,并通过分析这个工作负载来选择索引方案。动态索引选择方法对数据库进行监控,根据工作负载的变化选择索引方案。静态方法和动态方法的主要区别在于静态方法只选择和物化一个索引计划,而动态方法则根据工作负载的变化动态地创建或删除一些索引。
1 索引生成技术
传统的数据库是由数据库架构师根据自己的经验设计的,但数据库架构师只能探索有限的设计空间。传统或非人工智能索引方法,如位图索引,基于树的索引等,这些方法是可以满足用户的基本需求的,但它们无法对用户行为或者大数据进行预测,而且通用的传统索引结构无法对特定的业务有极好的表现,因为它们无法学习数据的分布以及其他数据库内部信息,因此,有一些索引生成技术被提出。数据库社区和机器学习社区研究基于学习的结构,例如基于学习的B树,使用基于学习的模型代替传统索引以减小索引大小并提高性能。下面对索引生成技术展开综述(见表1),分别为基于学习的范围索引、基于学习的哈希索引、基于学习的布隆过滤器等6个方面进行综述。

表1 索引生成技术相关工作总结
1.1 基于学习的范围索引
Kraska等[16]认为“索引即模型”,其中B+树索引可以看作是将每个查询键映射到其页面的模型,如图1所示。B树是一个模型,或者在机器学习术语中是一个回归树:它将键映射到一个具有最小和最大误差的区域,并保证如果该键存在,则可以在该区域中找到它。其中最小误差(min_err)为0,最大误差(max_err)为页面大小(page_size)。对于有序数组,较大的位置下标意味着较大的键值,并且范围索引需要与累积分布函数相近。

图1 “索引即模型”概念图
基于上述观察,Kraska等[16]提出了一种递归模型索引,它使用基于学习的模型来估计一个键的页面编号。该方法在内存环境下的性能优于B+树,但不支持数据更新,对二级索引支持较差。为了支持二级索引,Wu等[17]提出了一种基于学习的二级索引机制,它利用分层回归搜索树(TRS)来捕获列相关性和异常值,每个叶节点包含线性回归模型,该模型将目标值映射到相关值,每个内部节点维护固定数量的指向子节点的指针。该模型有3个步骤来响应查询:(1) 搜索TRS树以将目标列映射到现有索引,(2) 利用现有索引获取候选元组,(3) 最后验证元组。该方法在内存和基于磁盘的DBMS中都有效。“最后一英里搜索”是基于学习的模型替换B树的一个最大挑战,比如,从误差的数量级上来看,使用单个模型将预测误差从100 M数量级降到数百数量级往往很困难。然而,将误差从100 M数量级减到10 K数量级却简单得多。针对这个问题,Kraska等[16]还提出了层次模型,在每个阶段,输入的变量都是模型,并基于输入选择另一个模型,直到最后阶段,模型的输出为记录的位置。这样,每个模型负责一块区域,可以更好地降低预测误差。另外,递归模型[16]也可以根据场景,实现混合模型使用。给定一个索引配置,它将阶段数和每个阶段的模型数指定为大小数组,算法1展示了混合模型端到端的训练算法流程。
算法1:混合端到端训练法
输入:阈值(threshold),阶段数组(stages[]),复杂神经网络(NN_complexity),记录数据(record),索引模型(Model index[][])
输出:索引(trained index)
1:M←stages.size; tmp_record[][]← all_data;#初始化
2: fori←1 toMdo
3: forj←1 to stages[i] do
4: index[i][j]←new NN trained on tmp_records[i][j];
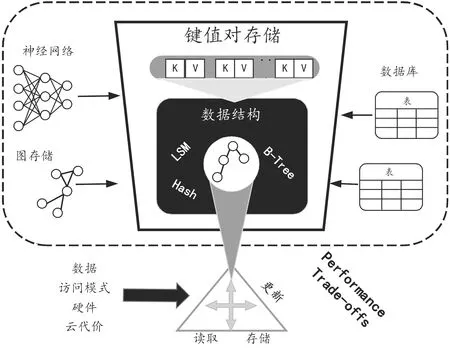
5: ifi 6: forr∈tmp_records[i][j] do 7:p←index[i][j](r.key)/stages[i+1]; 8: tmp_records[i+1][p].add(r); 9: forj←1 to index[M].size do 10: index[M][j].calc_err(tmp_records[M][j]); 11: if index[M][j].max_abs_err > threshold then 12: index[M][j]= new B-Tree on tmp_records[M][j]; 13:return index; 对于算法1,从整个数据集初始化(第1行)开始,它首先训练顶层节点模型(第2~4行)。基于对这个顶层节点模型的预测,它从下一阶段(第5~8行)选择模型,并添加属于该模型的所有键(第8行)。最后,在混合索引的情况下,如果绝对值的最小/最大误差高于预定义的阈值(第9~12行),则通过用B树替换神经网络模型来优化索引。 Galakatos等[18]提出的另一个基于学习的索引Fitting-tree,提供了严格的误差界限和可预测的性能,它支持2种数据插入策略。对于原地插入策略,Fitting-tree在页面的每一端保留额外的插入空间,以使原地插入不会超过页面误差。然而,插入大的片段代价可能很高。对于增量插入策略,在每个段中保持一个固定大小的缓冲区,并且这些键将被插入缓冲区并进行排序。一旦缓冲区溢出,它就必须拆分和合并这些段。与Fitting-tree类似,Alex索引[19]也为插入的键保留空间。不同的是,Alex索引中的保留空间是分散的,插入的键直接放在模型预测的位置。如果该位置被占用,则会插入更多的间隙(对于有间隙的数组)或扩展自身(对于压缩内存数组)。Alex索引可以更灵活地在空间和效率之间做出权衡。 Tang等[20]提出了一个称为Doraemon的工作负载感知索引。Doraemon可以通过在训练数据中复制多个频繁访问的查询来合并读模式,并且频繁查询比其他查询对误差的影响更大,优化程度更高。Doraemon重复使用预训练模型,这些模型所用的数据具有相似的分布,相似的数据分布需要相似的模型结构。 针对并行数据库,并行B树进行范围分区的数据迁移是一种解决方案,范围分区和链式非聚集副本的结合提供了高可用性,同时保持了可扩展性。Luo等[21]提出了一种利用并行B树(简称Fat-Btree)实现可扩展性的方法,单个Fat-Btree提供了所有处理器单元中主数据和备份数据的访问路径,大大减少了故障切换时间。此外,它支持动态负载平衡从而无需进行物理数据迁移,并提高了处理索引的内存空间利用率。 在基于非易失性内存(non-volatile memory,NVM)的索引设计中,基于哈希的结构是最有前途的候选结构之一,因为它可以充分利用NVM的字节可寻址特性来执行具有恒定时间复杂度的查询操作。哈希映射的索引尽可能避免冲突,因为冲突严重影响性能和存储需求,可以使用基于学习的方案以减少冲突的数量。Kraska等[16]建议将键的CDF(cumulative distribution function)近似为散列函数,以将所有键均匀地分布在每个散列桶中并减少冲突。基于哈希的连接算法通常包含2个阶段:分区阶段和分区连接阶段。Harris等[22]描述了使用最优多属性哈希(multi-attribute hash,MAH)索引来降低分区阶段(基于哈希连接算法)的平均代价的过程,通过完全消除最常见的连接查询的分区阶段来达到目的,并证明了该技术可以扩展到包括数据的多个副本,每个副本具有不同的MAH索引方案组织,并且这进一步降低了执行hash-join算法的分区阶段的平均成本。 Ma等[23]发现“再散列操作”可能会在NVM上产生大量的写活动,这对NVM的续航能力是有害的,并且会导致性能急剧下降。此外,无法对基于散列的索引有效地进行范围查询操作。于是,Ma等[23]提出了一种基于哈希的索引方案,对于NVM是友好的,称为“Bucket Hash”,用于基于 NVM的内存数据库。具体来说,为了减少再散列 操作的延迟,其使用多个小桶而不是更大的桶。为了最大限度地减少NVM写入的次数,Bucket Hash在进行再散列操作期间,会使大约一半的条目重新散列到新的存储桶中,并且将这些桶维护为一个排序的链表。由于链表存在搜索效率低下的问题,引入了一种辅助结构来提高查询操作的性能。此外,结合辅助结构和排序链表,该索引方案可以使范围查询操作易于管理。 布隆过滤器(bloom filter,BF)是一个常用的索引,用来判断一个值是否存在于给定的集合中。但是传统的BF可能会由于位数组和哈希函数而占用大量内存。BF可以加速对数结构合并(logarithmic structure merge,LSM)树中的点查找速率,主要通过减少对不包含所需键的层访问来实现。在 LSM树中,在查询树的每一层时都会使用BF,因此,随着数据大小(以及树的高度)的增长,CPU的代价也会增加。为了减小BF所占地内存,Kraska等[16]提出了一种基于学习的BF,训练一个二分类器来判断数据集中是否存在查询。新的查询需要首先通过分类器,未通过的应该进一步通过传统的BF,以保证不存在假负例。为了解决LSM树中BF不断增加的CPU代价,Zhu等[24]建议在BF内部和跨BF以及不同层之间积极地重复使用哈希计算,并且通过分析和实验,表明该方法可以保持接近理想的错误率,同时运行时间明显减少。然后,使用散列共享来降低查询的CPU代价,导致在LSM树中查找性能提高10%。 对于高维数据集,逐个搜索一组BF会耗费空间和时间。Macke等[25]提出一种用于多维数据的、高效的、基于学习的布隆过滤器。对于属性嵌入,通过字符级循环神经网络(RNN)表示高基数(high-cardinality)属性中的值,以减小模型大小。此外,他们选择最好的分类器去逼近阈值以最大化真正例率和假正例率之间的KL散度(Kullback-Leibler divergence)。为了减少噪声对索引数据的影响,为每个正例训练样本引入了一个移位参数。 Idreos等[26-27]表明键值存储(KV-store)中的数据结构可以从基本组件构建,基于学习的代价模型可以指导构建方向,如图2所示,从性能权衡到数据结构、键值存储丰富的应用程序。设计空间可以用所有基本设计组件(例如栅栏指针、链接和时间分区)来描述,而设计连续体是设计空间的一个子空间,它连接多个设计。为了设计数据结构,首先确定总代价的阈值以及可以调整哪个节点来缓解它,然后向一个具体的方面调整节点,直到达到其阈值或总代价达到最小值。这个过程类似于梯度下降,可以自动进行。 图2 从性能权衡到数据结构、键值存储丰富的应用示意图 许多现代关系型数据库(DBMS)架构需要从存储中转移之后再进行处理。鉴于数据量不断增加,数据传输速度成为可扩展性的限制因素。相邻数据处理(neighbor data process,NDP)和智能/计算存储成为有希望的解决方案,这些解决方案允许执行分离原地操作、减少数据传输和更好的带宽利用率。然而,并非每个操作都适合原地执行,需要仔细配置和优化。Christian等[28]提出了一种基于NDP的KV存储查询优化代价模型。他们为计算存储提供了NDP感知代价模型的案例,在这种设置中,DBMS操作具有主机和 NDP风格,并且需要自动选择。此外,他们提出了一个初始的NDP感知代价模型。只要给定基本工作量,代价模型估计代价基本正确,从而产生适当的执行计划选择。 传统的空间索引,例如R-tree、kd-tree、G-tree,无法捕捉底层数据的分布,可以通过基于学习的技术进一步优化查找时间和空间开销。例如,Wang等[29]提出了一种基于学习的ZM索引,该索引首先将多维地理空间点映射为具有Z排序的一维向量,然后构建神经网络索引以拟合分布并预测查询位置。 高维数据上的最近邻搜索(nearest neighbor search,NNS)问题旨在有效地找到查询中最近的k个点。解决近似NNS问题的传统方法可以分为三类,包括基于哈希的索引、基于分区的索引和基于图的索引。一些学者[30-32]通过使用机器学习技术改进了前2种方法。Schlemper等[31]提出了一种端到端的深度散列方法,该方法使用有监督的卷积神经网络,它结合了2种损失:相似性损失和比特率损失,因此它可以同时将数据离散化并最小化碰撞概率。Sablayrolles等[32]提出了一种类似的端到端深度学习架构,该架构学习催化剂功能以提高后续编码阶段的质量,引入了源自Kozachenko-Leonenko微分熵估计器的损失,以支持球形输出空间中的均匀性。Dong等[30]减少高维空间分区问题以权衡图分区和监督分类问题。首先使用图划分算法 KaHIP将KNN(K近邻)图划分为平衡的小分区,然后学习神经模型来预测查询的KKN落入分区的概率,并搜索概率较大的分区。 在DBMS中,建立索引的方案有若干种,每种方案带来的检索速度与时间/空间消耗都不一样,通过多方面考虑,权衡选择一个最佳索引是很困难的,可以证明索引选择问题是一个NP完全问题[33]。此外,许多开发者把索引应用到不同场景中,开发了原型系统,提出了很多优化的解法[33]。下面我们分别综述4类索引选择技术:1) 不需要DBA干预的在线方法[34-35];2) 有 DBA 参与的离线方法;3) 半自动化的索引选择;4) 基于机器学习的索引选择(见表2)。 表2 索引选择技术相关工作总结 在线方法的有3个步骤:工作负载分析、索引方案选择、索引方案实现,这3个步骤的循环进行,可以对工作负载的变化做自动调整。Lühring等[34]给出了一个基于“观察-预测-反应”循环的软索引自治管理方法,它可以在当前配置上自动根据环境实现索引结构,并在线自动调整框架本身的性能。 1) 工作负载分析:在线方法实时监控工作负载,并对单个查询分析。对于单个查询,通过对其中的SELECT,WHERE,ORDER BY和GROUP BY子句进行分析,提取可索引列,然后采用与DB2 Advisor[35]相同的方法枚举候选索引方案,并对索引方案的空间大小进行估计,其使用这个索引带来的时间减少量为奖励,奖励越大越好。对于工作负载的分析,将对单个查询的分析结果合并即可。 2) 索引方案选择:Toumi等[36]使用静态方法和增量动态方法引入了位图连接索引选择问题 (bitmap join index selection problem,BJISP)的一种新的多目标公式。首先,提出了静态BJISP的多目标公式,称为SMBJISP,它创建了一个使用两个目标函数,并从头开始构建位图连接索引的解决方案集,这些目标函数将查询负载代价和受上限约束的存储大小降至最低。其次,引入了一种称为IMBJISP的BJISP增量动态多目标公式。此公式假设存在实际解决方案(即针对查询工作负载生成并实施最佳解决方案),并以增量动态方式考虑查询工作负载的更新。Schnaitte等提出COLT[37],它支持基于当前索引方案自动在线实现新索引。 它将索引选择问题建模为在离线索引选择中描述的背包问题,并应用动态规划来获得索引方案。一旦得出最终的指标方案,将立即对其进行物化。但是,传统的在线方法没有考虑DBA的经验。此外,索引方案的不断变化可能会影响DBMS的稳定性并导致高开销。 3) 索引方案实现:Lühring等[34]将索引实现过程延后进行,即在系统空闲时间执行。为了索引效果尽快体现,在反应期引入了两个操作IndexBuildScan和SwitchPlan。IndexBuildScan对通常的表扫描算法进行了扩展,将要生成的索引集合作为一个额外的输入,在扫描的同时建立索引。SwitchPlan允许在执行与创建索引的查询再次执行时,使用最新创建的索引。例如,对于嵌套循环连接,内层循环的表会被扫描多次,第二次扫描时,就可以利用先前建好的索引。 根据表2以及对上述典型在线方法实现的分析,优点是在线法可以根据负载变化及时调整索引,也能在一定程度上减轻DBA的负担。然而,也有明显的缺点,即没有充分利用DBA的经验,而且需要系统持续运行,会长时间占用系统资源。同时,连续调整也具有一定的盲目性。此类方法适应能力为中等。 此方法依赖DBA从查询日志中选择一些频繁的查询作为代表工作负载,并使用工作负载来选择索引。Chaudhuri等[38]为Microsoft SQL服务器提出了一个索引选择工具AutoAdmin,主要原理是为每个查询选择性能良好的索引方案,然后扩展到查询集合Q中的多个查询。首先,对于每个查询qi∈Q,AutoAdmin从SQL查询中提取可索引的列。其次,AutoAdmin使用一个原生的枚举算法使索引列集合作为候选,例如,I= {{i1,i2,i3,i4},{i3,i4,i5,i6},…}。然后AutoAdmin选择I中对该查询具有最高收益的索引方案。然后,对于每个查询,都有相应的最优索引策略,对于Q中的所有查询,AutoAdmin根据收益选择top-k方案。接下来,对于每个top-k方案,AutoAdmin使用贪心算法增量添加可索引列,直到大小等于阈值B。最后,将选择具有最高收益且在存储预算内的方案。 根据表2以及对上述典型离线方法实现的分析,优点是离线法能够充分利用DBA的反馈。但是,无法处理工作负载的动态变化,并且加重了DBA的负担。此类方法适应能力低。可以看到,离线方法与在线方法的优缺点相反。 由于在线和离线方法都存在一定的不足,于是,Schnaitter等[39]提出了一种被称为工作负载反馈索引调整(workload feedback index tuning,WFIT)的方案,该方案基于半自动索引调整(semi-automatic index tuning),将在线方法和离线方法结合起来,充分利用二者各自的优点。既减轻了DBA选择典型工作负载的工作量,充分利用了调优器的计算能力,同时,还将DBA的专业知识应用在内,实现迭代的索引调整方法。它可以实时监控DBMS,动态分析工作负载并列举了一些候选方案来调整索引结构。但是在实施索引方案之前,WFIT需要 DBA 判断是否应该对列进行索引。然后在后续的索引选择过程中,WFIT会根据DBA的经验,从索引方案中剔除不应该被索引的列。同样,它也可以将应该被索引的列添加到索引方案中。 根据表2以及对上述典型半自动方法实现的分析,优点是半自动法可以减轻DBA的负担以及充分利用DBA的专业知识;缺点为没有考虑工作方案对整体的影响。此类方法适应能力为中等。 给定一个工作负载,索引选择的任务是决定创建索引的属性使处理工作负载的好处最大。通常,由于空间约束和索引维护成本,会给出要创建的索引数量的上限,因此简单地为所有列创建索引不是一个好的选项。当然,目标是在不需要管理员的情况下,以自动的方式提出适当的索引选择。 Sharma等[40]基于深度强化学习(deep reinforcement learning,DRL)进行数据库自动管理,总结了应用DRL来训练神经网络接管管理过程,本质上,必须定义一个所谓的问题环境,由以下4个组件组成:① 神经网络的输入。这通常是具有查询特征的当前工作负载,系统应该针对该工作负载以及配置的当前状态进行优化;② 可以采取的一系列行动。操作可以是在某个列上创建辅助索引或更改数据库缓冲区的大小。此类操作是从当前系统配置到新系统配置的转换;③ 奖励函数,评定所采取动作的影响。例如,可以将采取新配置(动作)后的运行时间与目前的最佳配置进行比较。改善越高,回报的正奖励越高。如果性能下降,则返回负奖励;④ 引导学习过程的超参数。这包括神经网络的属性(例如,隐藏层数、每层节点数)以及学习过程的属性,如迭代次数。 基于机器学习的索引选择方法会自动从历史数据而不是DBA的反馈中学习经验。Pedrozo等[33]提出了一种基于学习分类器系统(learning classifier system,LCS)和遗传算法的索引选择方法(index tuning with learning classifier system,ITLCS),并且ITLCS结合了强化学习算法。ITLCS使用LCS来创建和更新基于规则表示的知识,并生成覆盖数据库中绝大多数情况的索引。在经典的LCS中,基因算法将每个分类器当作一个单独的个体,并将低适应度的分类器替换为高适应度的分类器。每个分类器进行监督学习,输入是选择的索引,输出是性能分数。每个分类器对应一组判断规则表示,包含引导词(Condition)和结果(Action)两部分,遵循“IF ITLCS的工作流程大致分为4步:① 探测器从环境中探测信息,规则和信息处理系统将对探测到的信息进行处理,分类器试图将信息与引导词组合(此处信息对应于索引选择定义中的查询q);② 如果满足条件的分类器数量大于1,它们将在环境中相互竞争,算法将会选取指标最高的那个分类器;③ 被选择的分类器将会采取结果(动作,即索引选择定义中的c),然后从环境中接收反馈信息,并对所选分类器进行奖惩(即索引选择定义中的Reward),最后对所有分类器收取存活代价,降低其强度;④ 使用遗传算法产生新的后代分类器,并淘汰掉不合适的分类器。 ITLCS将DBA与索引选择进行了解耦,使强化学习对分类器做决策,可以解决NP-hard问题。ICLCS能够适应工作负载的变化,推荐策略根据环境进行动态变化,提高了效率。然而,ITLCS的选择过程主要依赖于遗传算法,强化学习只是为其提供了能在更大的搜索空间S求解的方案,并未将基于学习的方法深入应用到问题的求解过程中。其次,ITLCS使用遗传算法来消除LCS规则并生成复合规则作为最终的索引策略。但是,很难生成规则。针对规则生成难的问题,Sadri等[40]提出了一种基于强化学习的索引选择方法。首先,在没有专家规则的情况下,将工作量特征表示为查询的到达率,将列特征表示为每列的访问频率和选择性。其次,使用马尔可夫决策过程模型从查询、列和输出一组动作的特征中学习,这些动作表示创建/删除索引。 然而,计算机系统的配置空间对于传统和自动调整策略具有挑战性。Welborn等[42]探讨了如何使用特定任务的归纳偏置来增强基于学习的索引选择,特别是通过将这些归纳偏置编码为更好的动作结构。当问题根据排列学习重新表述时,就会出现索引选择特定的动作表示,并且依靠最近的动作来学习关于排列的强化学习(reinforcement learning,RL)策略。通过这种方法,构建了一个索引代理,它能够实现改进的索引并使用特定于任务的统计数据验证其行为。与其他方法相比,该代理可以找到在相同延迟水平下最多减少40%的配置,并表示出更直观的索引行为。 对于NoSQL数据库,Yao等[43]提出了一种新的索引选择方法。针对不同的工作负载,选择不同的索引及其不同的参数来优化数据库性能。该方法构建深度强化学习模型,为给定的固定工作负载选择最佳索引并适应不断变化的工作负载。实验结果表明,深度强化学习索引选择方法(deep reinforcement learning index selection approach,DRLISA)比传统的单索引结构在不同程度上提高了性能。该方法选择索引配置比手动选择索引更合理,并且可以应对NoSQL数据库智能索引选择问题。与单一索引结构不同,DRLISA支持在动态工作负载下选择索引结构及其参数。此外,该方法显示出其强大的可扩展性,体现在可以将其他索引添加到索引集中,将动作添加到动作集中或修改不同情况下的奖励评估函数作为扩展。强大的可扩展性DRLISA符合NoSQL数据库的概念。DRLISA可以为NoSQL索引选择问题带来新的启发。 根据表2以及对上述典型基于学习的方法实现分析,基于学习的方法能够适应工作负载的变化,并且推荐策略能够动态变化。然而,基于DRL的索引选择法通常需要结合其他算法(如遗传算法),并且强依赖于奖励函数。 综述了索引推荐相关技术,包含2个阶段,第一阶段是索引生成技术,第二阶段是索引选择。索引生成技术叙述了范围索引、哈希模型索引、基于学习的布隆过滤,索引选择技术分别叙述了离线、在线、半自动化和基于学习的方法。目前已有大量的机器学习算法,可以尝试将不同的模型运用到索引推荐中。下一步的研究方向是考虑多维索引,并且从理论上证明学习型索引的正确性。对于动态变化的工作负载,要求基于学习的模型具有很强的泛化能力;DBA工作经验是很有价值的知识,如何学习这些知识并进行应用也是一个需要解决的问题。1.2 基于学习的哈希索引
1.3 基于学习的布隆过滤器
1.4 基于学习的键值对存储
1.5 基于学习的空间索引
1.6 基于学习的高维数据索引
2 索引选择技术
2.1 在线方法
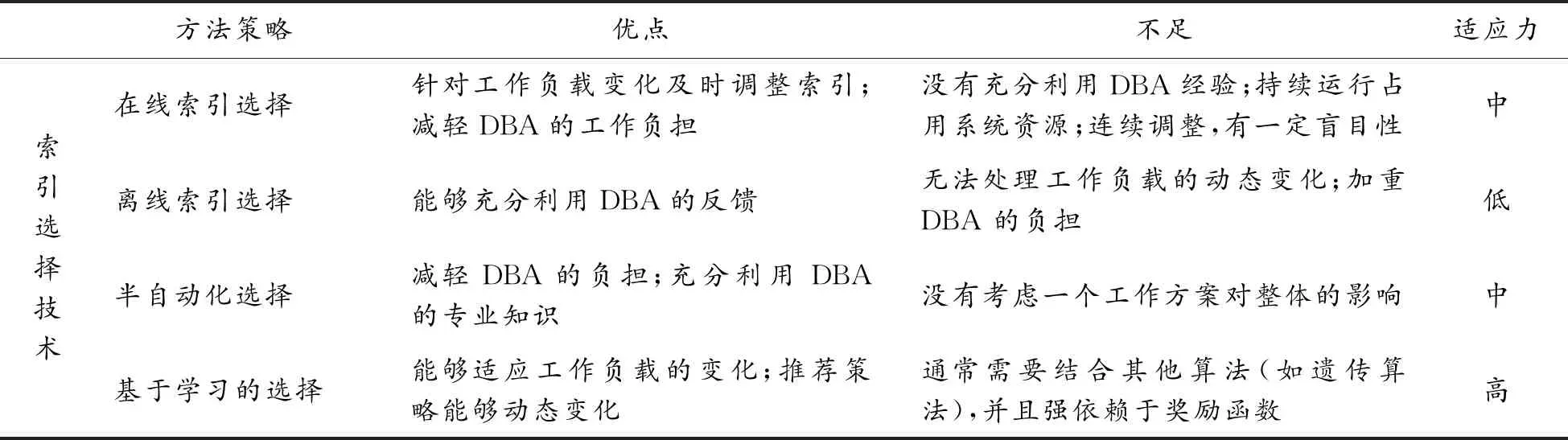
2.2 离线方法
2.3 半自动方法
2.4 基于学习的方法
3 结论
