无人车典型场景构建及车速预测
2022-07-22宋传杰高建平谢诏玺郗建国
宋传杰,高建平,谢诏玺,郗建国
(河南科技大学 车辆与交通工程学院, 河南 洛阳 471003)
0 引言
随着汽车智能化、网联化的深度发展,智能驾驶汽车的安全问题成为关注的焦点。构建合理的自动驾驶汽车测试与评价系统,需对真实环境中的危险场景进行分析与构建。当前,自动驾驶汽车的测试评价对象已从传统的人-车系统转变为人-车-环境交互耦合系统,而测试场景已成为不可或缺的环节[1-2]。目前,国内外对测试场景及场景要素的形式还存在争议,标准中也未进行明确阐述。场景生成方法可分为基于演绎的方法和基于归纳的方法。郭景华等[3]、徐向阳等[4]基于归纳的方法,通过采集的真实交通数据构建测试场景,且处于仿真阶段。Xia等[5]利用层次分析法衡量场景要素的重要度,通过独立组合测试方法将离散的测试用例聚类成连续场景,确保了场景覆盖的全面性,但生成的场景不具有典型性。基于当前自动驾驶汽车测试现状,测试场景应具有代表性强、数量少等特点。
目前,科学理论技术提升了自动驾驶汽车的预测能力。熊晓夏等[6]基于支持向量机和混合高斯的隐马尔可夫链模型对道路事故进行预测,但对我国交通环境下网联车辆的前车状态考虑较少。张金辉等[7]采用贝叶斯网络对前车车速进行预测,将得到的跟车数据分为训练集和测试集,通过测试集检测前车车速预测效果,但预测精度有待提高。倪捷[8]在构建预测模型时,仅考虑了车辆的运行特征,而忽略了交通环境对行车风险的影响,不能全面反映行车状态。综上所述,由于我国交通环境复杂度较高,车辆未来状态受驾驶员等多种因素影响,自动驾驶车辆对前车运行状态难以进行精确预判。
基于以上问题,本文以自动驾驶车辆为研究对象,对典型场景下自动驾驶车辆前车车速进行预测,选取对事故类型影响较大的特征要素。采用Prescan、Matlab/Simulink等工具和优化算法,构建基于马尔科夫链和循环神经网络的前车车速预测模型,通过模拟状态与原始状态的对比,验证了预测模型的有效性。最后,将车速模型参数导入整车控制器中,并进行试验验证。
1 测试场景要素分析
1.1 数据来源
本文数据来源于国家车辆事故深度调查系统(national automobile accident indepth investigation system,NAIS),由多所高校和研究机构共同建立。该数据围绕事故相关的人-车-路-环境信息进行深入采集,涵盖全国具有代表性的区域,且与我国道路事故统计特征基本吻合[9]。结合NAIS数据库和自动驾驶测试场景要求,考虑到测试过程中,测试车辆本身与周围场景的相互作用,因此,将场景要素分为交通环境要素和测试车辆基础信息要素两大类,如图1所示。

图1 场景要素分类
1.2 场景要素编码
为了构建场景要素指标体系,需要对各场景要素进行编码。根据实际驾驶经验,本文以交通环境要素中的事故时间、天气、道路状况、道路流量、路面材质、道路类型为自变量,事故类型为因变量,使用SPSS软件进行多元线性回归分析,探究各要素对事故类型的影响程度。多元线性回归模型能较好地兼顾各个要素的权值。此外,为避免个别要素取值过于离散,在编码过程中将相近的属性进行合并。要素编码情况如表1所示。
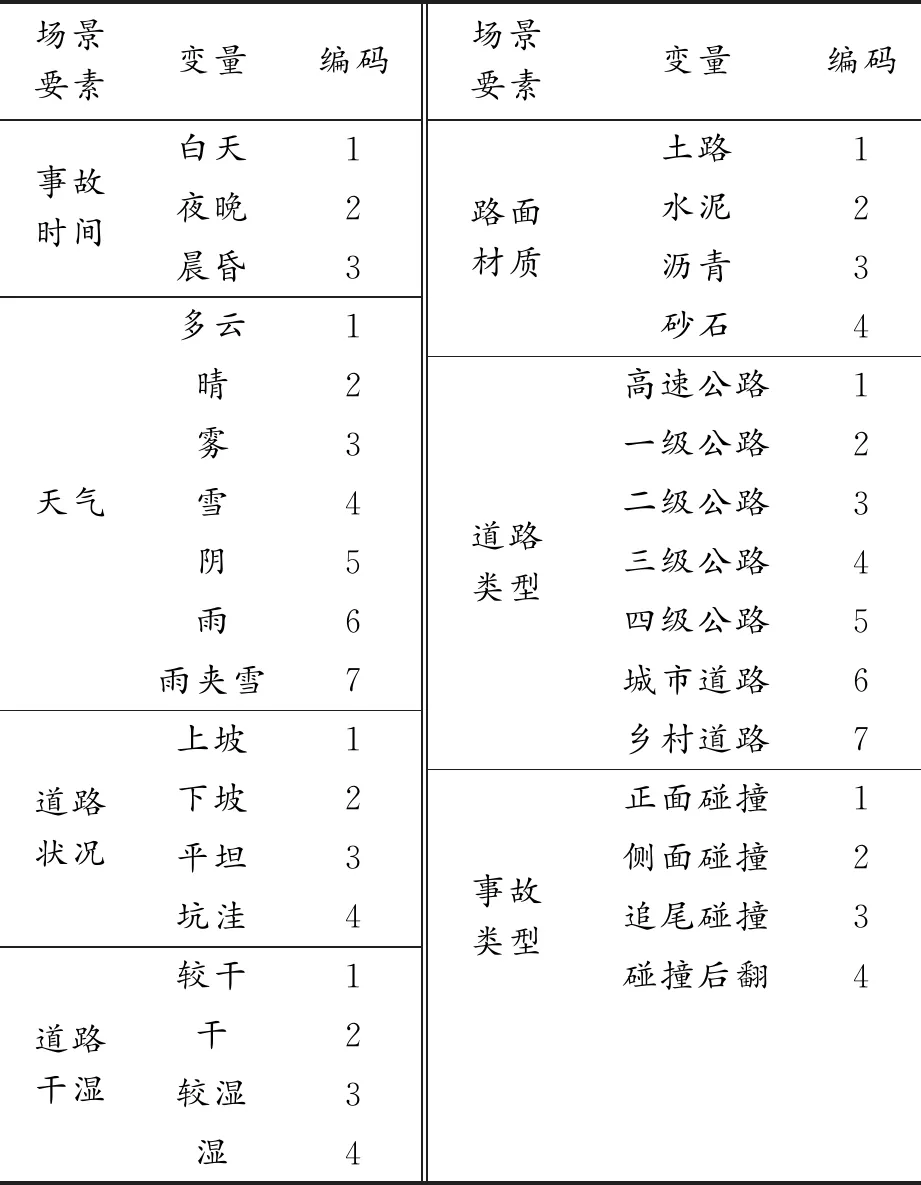
表1 要素编码
1.3 多元线性回归模型构建
事故类型的线性回归模型为:
(1)
式中:Y为事故类型;x为对事故类型有显著影响的自变量;p为自变量个数;n为样本总数;βp为第p个变量的回归系数,εi为第i个样本的随机误差[10]。由式(1)可得n个样本的矩阵随机表达式:
Y=xβ+ε
(2)
假设x的列满秩,则回归系数的最小二乘估计量为:
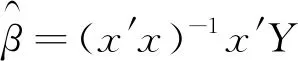
(3)
多元线性回归过程中还需对样本回归函数进行检验,以判断预测的可靠程度,包括拟合优度、显著性水平、德宾-沃森值等。
拟合优度检验即通过样本回归对观测值进行拟合,记

(4)
为总离差平方和,
(5)
为回归平方和,
(6)
为残差平方和,则:
(7)
式中,R2为可决系数,其大小可表示自变量对因变量的贡献程度,其值越接近1,表明拟合优度越高。
在原假设成立的前提下,显著性检验的统计量由
(8)
公式确定,查表可得临界值Fα,通过比较F和Fα的大小来判断原假设H是否成立,一般情况下显著性水平取0.05或0.1。
1.4 多元线性回归结果
本文多元线性回归分析中,置信区间设为95%,模型信息如表2所示,回归分析结果如表3所示。根据R2,表明各要素预测事故类型的准确性较强。
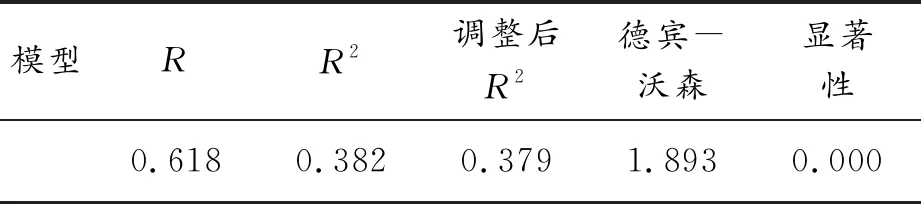
表2 模型信息

表3 回归分析结果
结合表2和表3数据,根据德宾-沃森值和VIF值,可说明样本数据随机性较强且多重共线性呈弱相关,显著性水平<0.001,表明模型预测效果较好。取显著性水平为0.05,根据分析结果,路面材质、道路类型和道路干湿对事故类型影响较大,而天气、道路状况对事故类型影响较小。
基于以上分析,将路面材质、道路类型和道路干湿确定为特征要素,特征要素即对事故类型影响较大的要素。由于自动驾驶车辆感知系统容易受能见度的影响,因此,将能见度作为测试场景的特征要素[11]。
2 测试场景K-均值聚类挖掘
2.1 K-均值聚类算法
为挖掘出具有代表性的测试用例,采用聚类算法对测试场景进行聚类挖掘,剔除重复或相似的测试用例,得到代表性较强的测试用例。K-均值聚类分析算法作为一种快速聚类算法,其对计算机的性能要求不高,且可应用于比系统聚类法大得多的数据组[12]。
K-均值算法流程为:首先,将所有样品分为K个初始类;然后,计算某样品到各类中心的欧几里得平方距离,将样品分配给最近的一类。对于有变动的类,重新计算其坐标,为下一步聚类做准备。无变动的类输出后成为一类[13]。聚类算法的流程如图2所示。
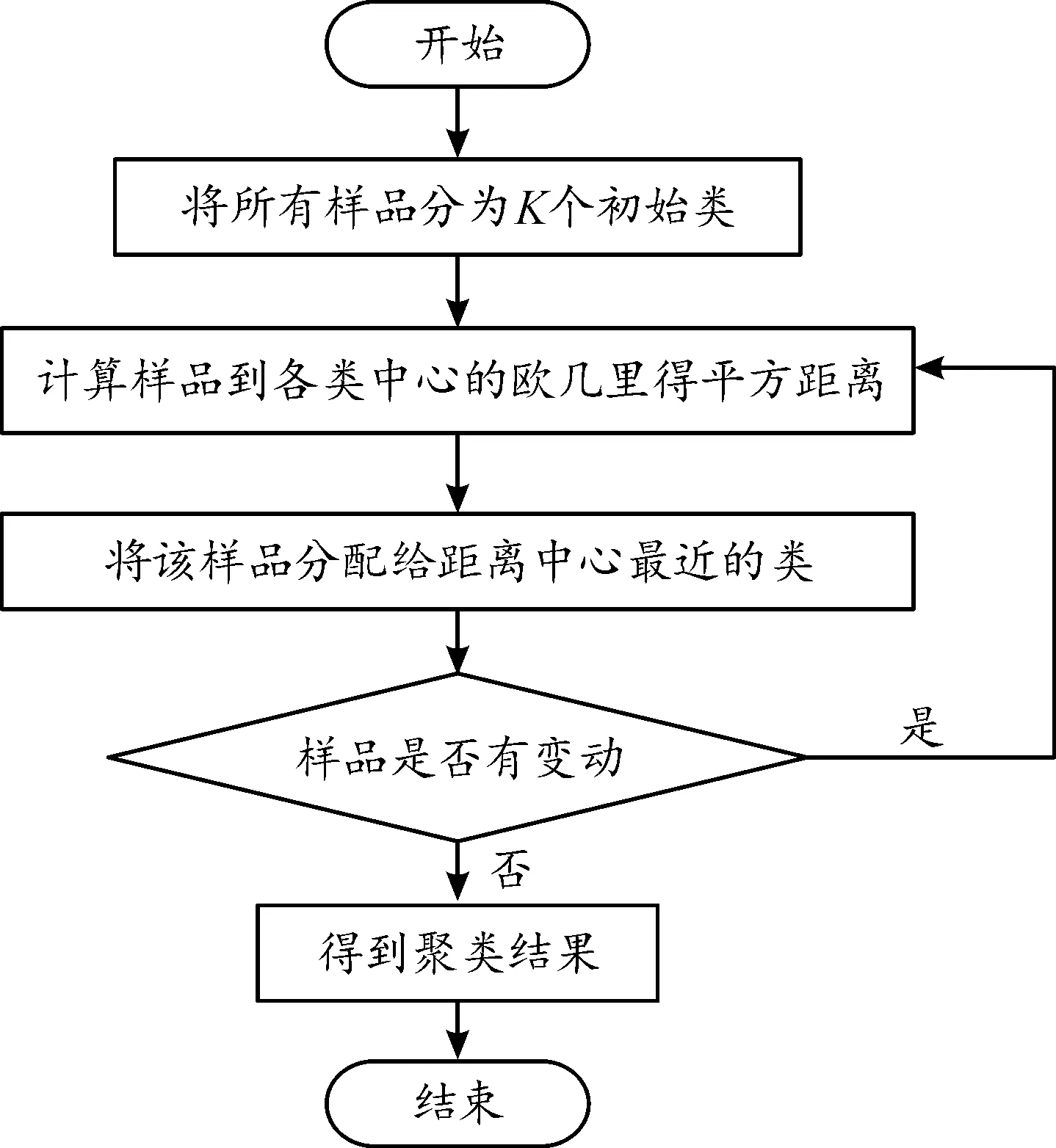
图2 K-均值聚类算法流程
其中欧式平方距离公式为:
(9)
式中:I=(xi1,xi2,…,xif)和J=(xj1,xj2,…,xjf)是2个f维的数据对象,f为变量个数,xik为第i个样本中第k个变量的度量值。此外,采用最长距离法定义类与类之间的距离,规定相同变量间距离为0,不同变量间距离为1。首先,将各样品自成一类;然后将距离最小的两类合并。其中,定义类Gi与类Gj之间的距离为最远样品的距离,公式为:
(10)
式中:dij为样品Xi与Xj之间的距离;Dpq表示类Gp与Gq之间的距离。将类Gp与Gq合并为Gr,则任一类Gm与Gr的类间距离为:

max{Dmp,Dmq}
(11)
2.2 测试场景聚类结果
选取第1节的4个特征要素为聚类分析的参数,在聚类分析中,需将参数进行赋值,以计算各测试用例之间的距离。考虑到本文只针对名义变量,规定相同变量间距离为0,不同变量间距离为1。其中,对于几乎静止的要素如天气等,可将其设置为较小的值。基于上述方法得到的聚类结果如表4、表5所示。
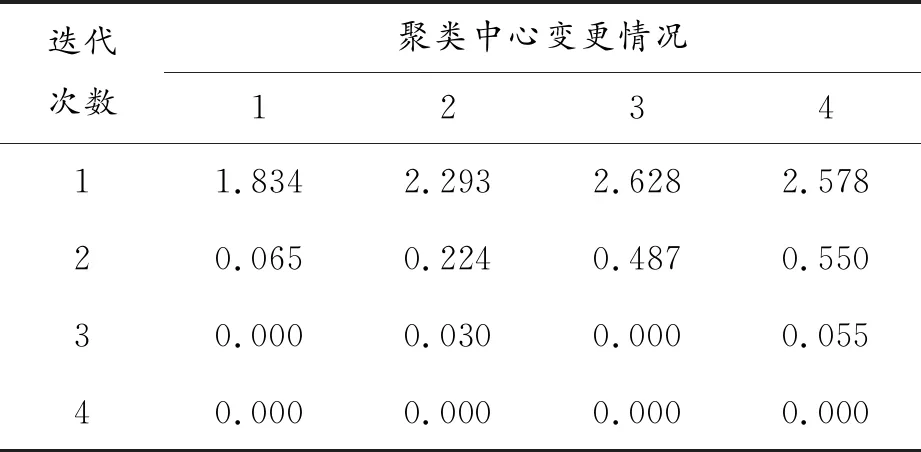
表4 迭代记录
根据表4可得,当进行第4次迭代时,各个聚类中心的绝对坐标不再改变。因此,本文最终的聚类个数为4。根据SPSS得到的结果,查阅要素编码表,最终得到4种危险典型场景,如表5所示。

表5 4种危险典型场景
3 前车车速预测模型
本文基于采集的实车数据作为样本,利用马尔科夫模型和循环神经网络分别对平稳工况和快变工况下前车车速进行预测。
3.1 前车状态数据采集
本文以某公司生产的自动驾驶巴士为测试车辆,车上装载多线激光雷达和毫米波雷达,底盘采用CAN总线进行通讯,对实际道路工况进行采集。由于实际道路采集的数据受周围环境、道路结构、驾驶风格等因素影响,因此需要对数据进行处理。其中采集的数据集包括前车速度、前车加速度等数据。为建立符合我国交通特征的跟车工况,根据以下准则筛选出相应数据[7]。
1) 考虑到换道、超车情况,前后两车距离应满足|Δdi|<8 m,其中Δdi为主车与前车之间的距离,单位为m。
2) 为确保跟车安全,两车速度差应满足|Δvi|<5 km/h,其中Δvi为主车与前车速度之差。
3) 连续跟车大于10 s时,不考虑起步、停车过程。
根据上述准则筛选出车辆跟车数据,其中前车速度、加速度概率分布情况如图3、图4所示。

图3 前车速度概率分布
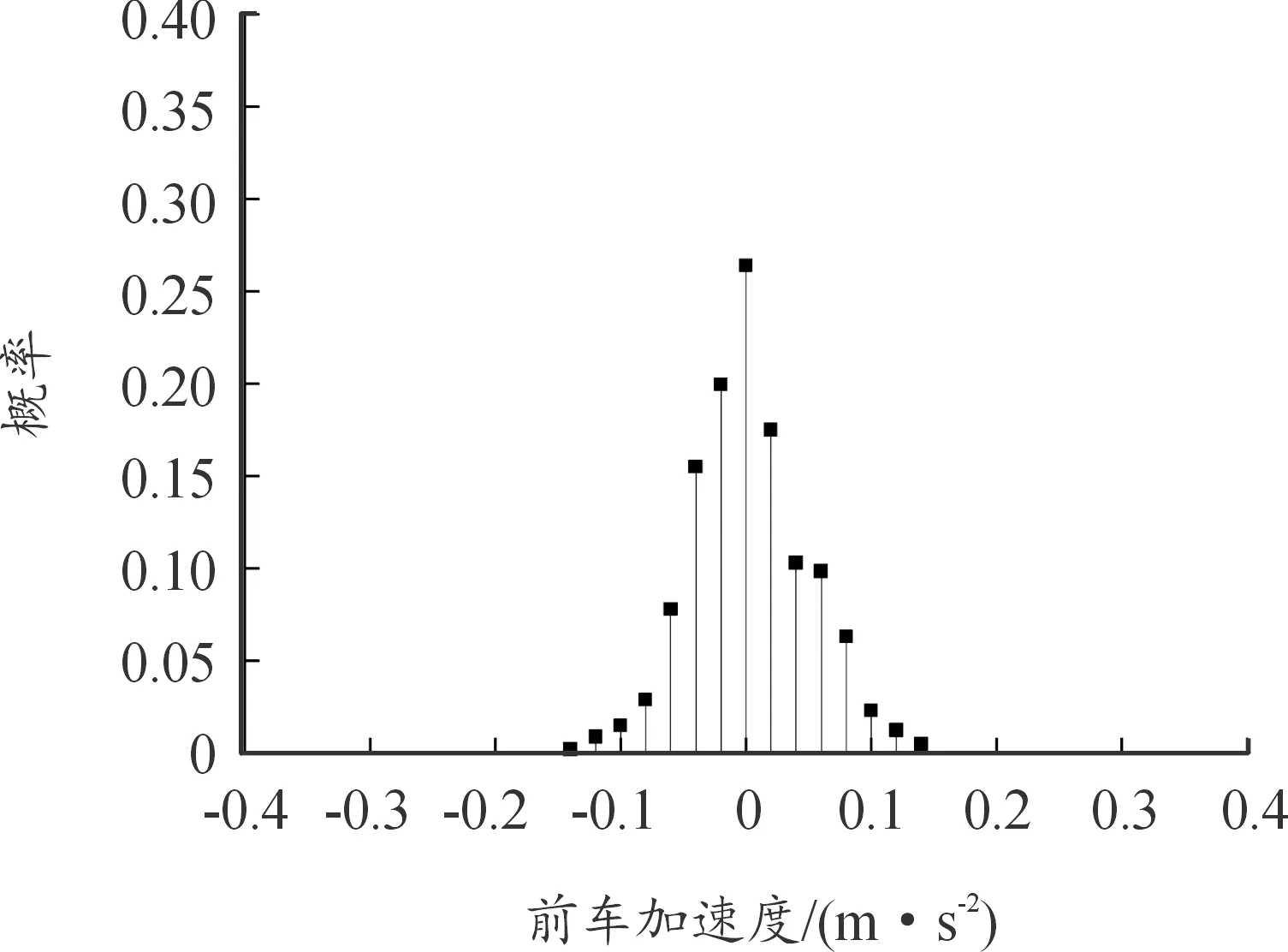
图4 前车加速度概率分布
3.2 平稳工况下预测模型构建
为准确预测前车运动状态,参照文献[14]的工况判断方法,将筛选出的工况分为平稳工况和快变工况。以采集的数据为基础,在平稳工况下构建基于马尔科夫的前车状态预测模型。假设车辆未来的状态与历史状态无关,则当前车辆的状态变化可视为一种马尔科夫过程。假设驾驶过程为随机过程ω,ω(m)为m时刻前车的状态,其中ω(m)可以表示速度、加速度等参数的随机组合。根据条件概率定义,由状态sm转移到sn的转移概率可定义为:
Tmn={X(t+1)=sm|X(t)=sn}
(12)
式中:Tmn为t时刻的转移概率,即从t时刻sm转移到t+1时刻sn的概率。将历史数据划分为若干片段,随机组成不同状态并依次编码。车辆运行时,状态间随机进行转换,可根据这一属性和历史数据得到状态转移矩阵,公式如下:
(13)

(14)
式中:vm为下一时刻车速;vn为当前车速;aj(m)为下一时刻加速度。根据单次试验时的数据,可得到马尔科夫链转移概率矩阵元素,如图5所示。

图5 马尔科夫模型转移矩阵元素
3.3 快变工况下预测模型构建
考虑到马尔科夫预测模型在前车工况波动较大时预测鲁棒性较弱,不能实时为主车提供准确的前车运行状态。因此,本文采用循环神经网络(recurrent neural network,RNN)对前车多变工况进行预测,通过对驾驶行为序列的自学习预测前车状态[16]。
循环神经网络具有深度神经网络的输入、输出和隐藏层,且隐藏层具有传统神经网络的前馈连接,并且每个神经元都具有自反馈功能,RNN模型如图6所示。
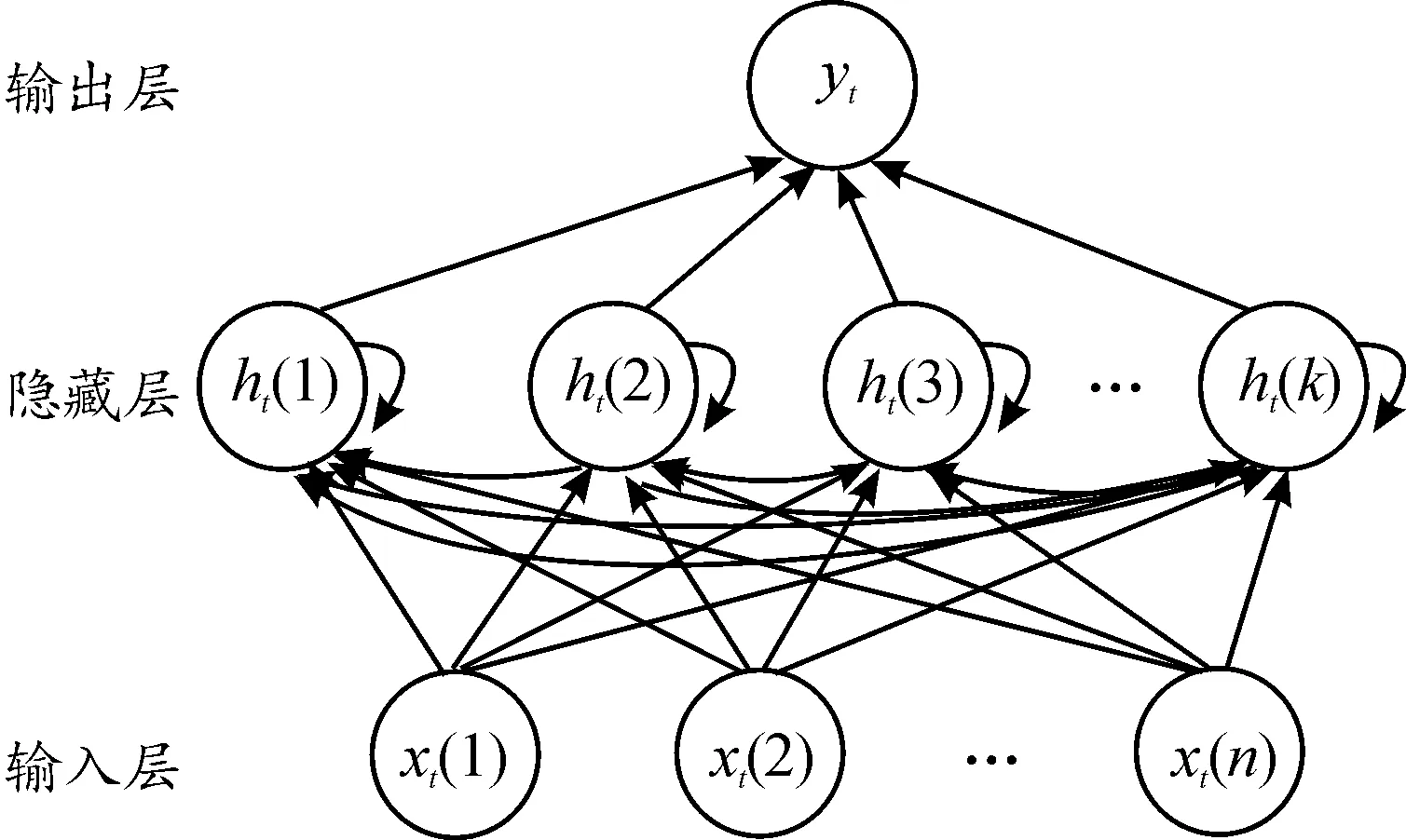
图6 RNN模型示意图
其中,定义RNN模型的输入层xt(n)为历史车速和加速度信息,输出层yt为前车未来车速和及加速度,隐藏层采用具有自反馈功能的偏执向量。

(15)
式中:W为权重系数矩阵(Wxh表示输入层到隐藏层的权重系数);b为偏置向量(bh表示隐藏层的偏置向量);fa为激活函数,t为当前时刻。其中损失函数为:
(16)
式中:pi和yi分别为前车车速预测值和真实值;(m-l,l)为输出结果的维度。设定损失函数最小为优化目标。RNN模型根据输入的历史车速和加速度信息预测未来车速,根据相应的误差项和权重梯度实现循环神经网络在线学习。
4 仿真验证与分析
为验证前文中车速预测模型和测试场景生成方法的有效性,在Prescan和Matlab/Simulink中搭建联合仿真平台。车辆模型选用Prescan自带车型,在Prescan界面中对车辆、场景参数、输入输出进行配置,通过界面可实时观察仿真结果。图7为部分三维仿真场景。定位系统和传感器融合策略在Matlab/Simulink中搭建,设置采样时间间隔为0.1 s。考虑到自车车速的危险工况多在20~40 km/h,将测试车辆采集的数据作为样本数据,统计可得目标车加速度呈近似正态分布。

图7 部分三维仿真场景
将聚类的4种场景中自车车速作为历史数据,可得城市场景、二级公路场景、三级公路场景的速度,如图8所示。3种场景中的速度误差集中在 2 km/h范围内,考虑到原始工况下车辆随机性及环境随机性较大,通过对采集数据的学习得到预测模型,结果存在一定的差异,其中体现了车辆状态的随机性。城市场景车辆频繁启停,速度误差波动较大,二级公路、三级公路波动较小。
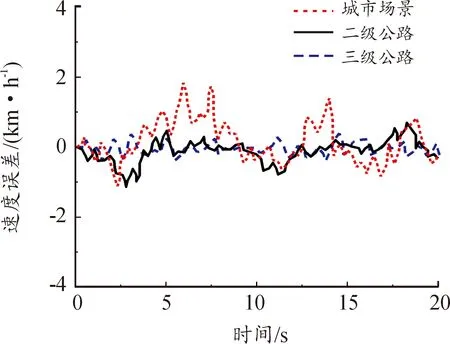
图8 3种场景预测速度误差
5 试验验证与分析
为进一步验证前文提出的前车车速预测模型的准确性,利用某公司生产的自动驾驶套件标定系统将模型参数导入至整车控制器中,进行实验验证。试验小车如图9所示。

图9 试验小车
5.1 试验小车通讯方式
全车采用基于CAN卡的通讯方式,协议采用主从通讯模式,主设备是测量标定系统,从设备是整车控制器。当主从设备建立联系后,主设备控制所有通讯数据,从设备接受数据并反馈代码信息和报文。
5.2 试验
在实车试验前,启动Dreamview平台,并在Cyber monitor里查看小车定位、感知、预测等通道的信号是否正常。试验时小车安全车速为20~30 km/h,最大加速度为5 m/s2。实车测试表明:在试验条件下,预测模型能平均提前4.86 s预测前车车速,且单程误差率小于0.1%,误差较小且实用价值较高。分别对试验后速度指标和加速度指标进行分析,试验与仿真场景如图10—12所示。通过观察3种场景下前车速度和加速度的试验与仿真对比图,其变化趋势基本一致。部分片段偏差过大,这种现象是由试验环境及测量误差造成的,均在合理范围之内。
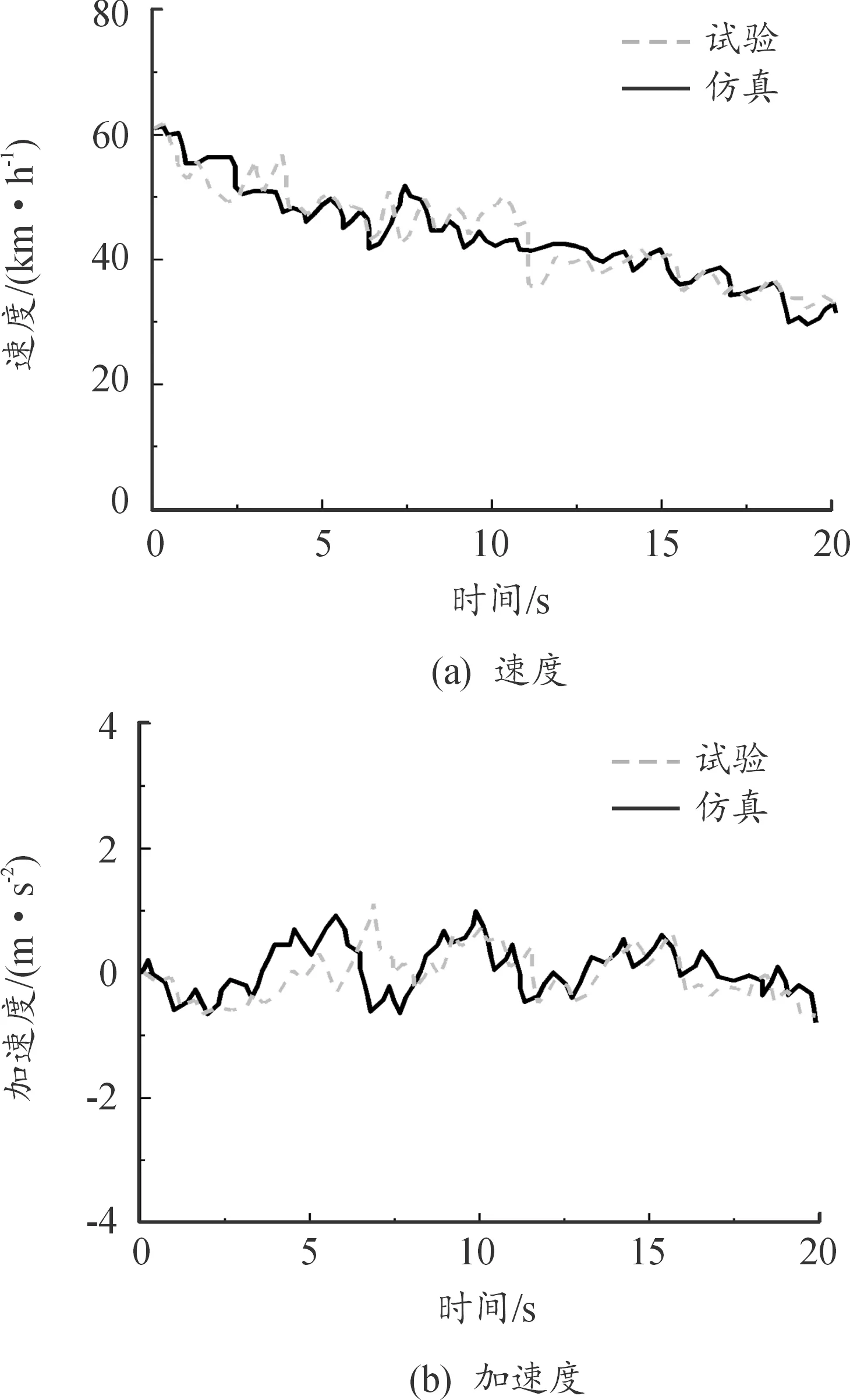
图10 城市场景试验与仿真

图11 二级公路场景试验与仿真
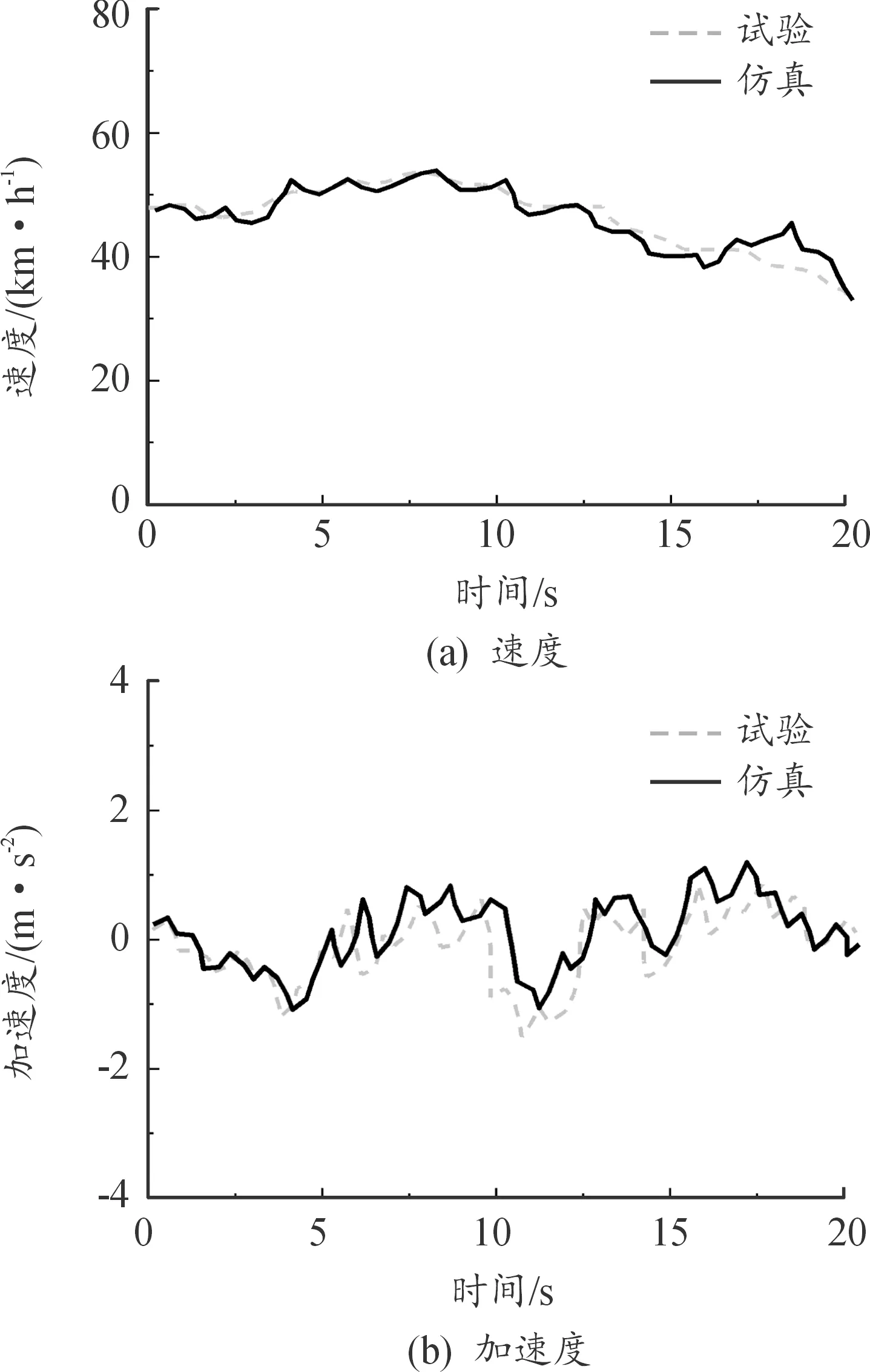
图12 三级公路场景仿真与试验
根据表6可以看出,城市场景和二级公路场景误差车速较小,三级公路场景误差车速较大,这是因为试验条件和测试误差造成的。由此可以看出,所构建的车速预测模型能较好地预测前车车速,实车试验验证了预测模型仿真系统的有效性。
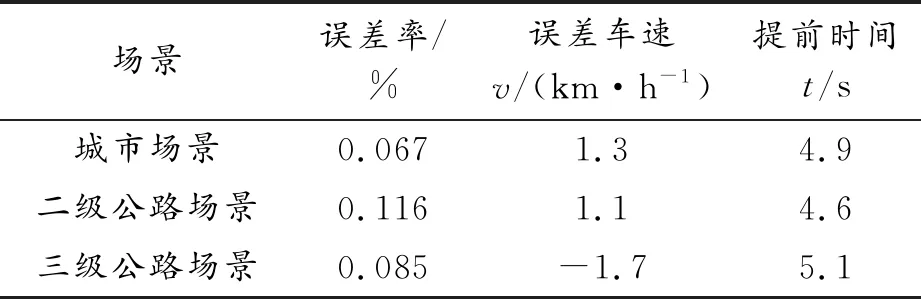
表6 预测试验结果
6 结论
1) 基于NAIS数据库,在置信区间为95%时,在构建的多元线性回归模型中提取得到4个特征要素,对特征要素使用K均值聚类算法,挖掘出4种危险典型场景。
2) 基于实际跟车数据,分别对平稳工况和快变工况建立马尔科夫和循环神经网络车速预测模型。基于Prescan、Simulink联合仿真平台,对典型场景下车速预测模型进行验证,仿真结果表明:所提出模型的车速预测误差小于2 km/h,在合理范围内。
3) 基于马尔科夫模型和循环神经网络模型平均能提前4.86 s预测前车车速,且单程误差小于0.1%,实用性较高。未来的工作是探究如何快速生成典型测试场景。
