基于差分进化邻域自适应的大规模多目标算法
2022-06-25闫世瑛颜克斐陆恒杨
闫世瑛, 颜克斐, 方 伟, 陆恒杨
(江南大学人工智能与计算机学院, 江苏 无锡 214122)
0 引 言
大规模多目标优化问题(large-scale multi-objective optimization problems,LSMOPs)是指有两个或三个目标的带有多于100个决策变量的问题。对于多目标问题的求解已经有很多研究成果,例如带精英选择策略的非支配排序多目标遗传算法、基于参考点的非支配排序的进化多目标优化算法、基于分解的多目标优化算法(multi-objective evolutionary algorithm based on decomposition,MOEA/D)等。对于单目标大规模优化问题,以协同进化(coo-perative coevolution)为框架将问题采用分治策略来处理是可行手段之一。但对LSMOPs使用传统的多目标优化算法或者大规模优化算法往往都得不到好的效果。原因是随着维数增加,其搜索空间会呈指数式增长,导致算法无法收敛或者陷入局部最优,不但计算成本很高,而且复杂性也会成倍增加。差分进化算法相比遗传算法在高维上收敛速度更快且不容易陷入局部最优,易与其他算法相结合构造混合算法,被广泛应用于LSMOPs的求解中,改进的差分进化算法主要提升算法的收敛速度,克服早熟收敛和搜索停滞的问题,LSMOPs与之结合能显著提升算法性能。目前,针对LSMOPs的求解方法大致可以分为3种类型。
第一类是基于决策变量分解的思想,采用分治思想将决策变量分为若干小组并单独优化,从而解决LSMOPs搜索空间过大的问题,但在分组决策变量时需耗费较多计算资源。Iorio等提出基于非支配排序的合作协同进化算法,首先将各决策变量分派到不同的子种群中,再通过带精英选择策略的非支配排序算法优化各个子种群。Ma等提出基于决策变量分析的大规模多目标优化算法(large-scale multi-objective evolutionary algorithm based on decision variable analysis, MOEA/DVA),利用决策变量分析策略将所有变量分为距离变量、位置变量和混合变量三类,然后根据各个距离变量间的相互作用关系划分出多个子多目标优化问题,在种群进化阶段先优化距离变量从而提升种群的收敛性,然后优化所有变量从而获得种群多样性性能的提升。MOEA/DVA将决策变量分析应用到LSMOPs的求解中,但是对混合变量的处理不够有针对性,仅考虑其对多样性进化的影响,将混合变量与位置变量合并,共同优化种群的多样性。此外,种群的进化过程分为前期收敛性进化阶段和后期多样性进化阶段,但是区分进化前期的结束时间与后期的开始时间在实际问题上较为困难。Zhang等提出基于变量聚类的大规模多目标进化算法(evolutionary algorithm for large-scale multi-objective optimization,LMEA),首先用均值聚类法将决策变量划分分为收敛性变量和多样性变量两类,然后进行交替迭代,使用不同方法来优化不同类型的变量。
第二类是基于决策空间缩减的思想,利用问题转化思想将LSMOPs转化为小规模优化问题,并使用传统进化算法进行优化求解,从而减小决策空间,降低搜索最优解集的难度,但问题转化策略在不连续的搜索空间易陷入局部最优。Zille等提出基于问题转化的求解LSMOPs的框架,用一组权重来改变决策向量,然后将权重作为要优化的变量来建立小规模的多目标优化问题。He等提出问题重构加速大规模多目标优化的通用框架,在搜索空间上定义多个参考方向,在进化过程中通过扰动参考方向的解来探索更优解。Liu等提出基于聚类和降维的多目标进化算法,首先通过聚类方法将决策变量划分为收敛变量和多样性变量,然后通过主成分分析减少收敛性相关变量,并用差分分组进一步划分收敛性相关变量。
最后一类通过提出新的搜索策略直接解决LSMOPs,主要包括新的复制算子和概率模型,无需借助决策变量分组或决策空间缩减,但其对问题的求解效率随决策变量数的增长而降低。Zhang等提出基于信息反馈模型的大规模多目标优化算法,设计6个信息反馈模型并集成到MOEA/D中,通过根据历史信息更新产生子代。Cheng等提出基于概率模型的多目标优化算法,构建基于高斯过程的逆模型,将解从目标空间映射到决策空间,并使用逆模型对目标空间进行采样来生成后代。
针对基于决策变量分解思想的求解方法,由于LSMOPs包含多个互相冲突的目标,在这些目标上决策变量之间的相互作用可能不同,优化每组变量时应同时考虑种群的收敛性和多样性。因此,在LSMOPs上分组决策变量需要更精细的算法。基于问题转化的方法通过优化当前解的最佳权重来减少决策空间,虽然可以快速找到一些局部最优解,但是转化后的问题可能会丢失全局最优解。此外,虽然机器学习中已经有大量降维技术,但是由于其缩短的向量不可恢复,所以大多数都不能用来解决LSMOPs。为了解决上述问题,本文提出了一种基于差分进化邻域自适应策略的大规模多目标优化算法(large-scale multi-objective optimization based on differential evolution with neighborhood adaptive strategy, NAS-MOEA)。首先,对决策变量进行分析,扰动决策变量生成一系列被扰动解,根据被扰动解间的支配关系将决策变量分为两类,即多样性变量和收敛性变量,使变量分类更加准确,提升了进化过程的效率。其中,对收敛性变量进行主成分分析降噪,在保留原始数据主要信息的前提下使主成分间没有关联,从而减少计算成本并获得更好的结果。然后对种群交替进化,采用优化策略交替处理收敛性变量和多样性变量,平衡了进化种群收敛性变量与多样性变量之间的关系,避免算法陷入局部最优。在使用差分进化算法优化收敛性变量时,设计了邻域自适应更新操作,进而加快了种群在进化过程中的收敛速度。
1 问题描述
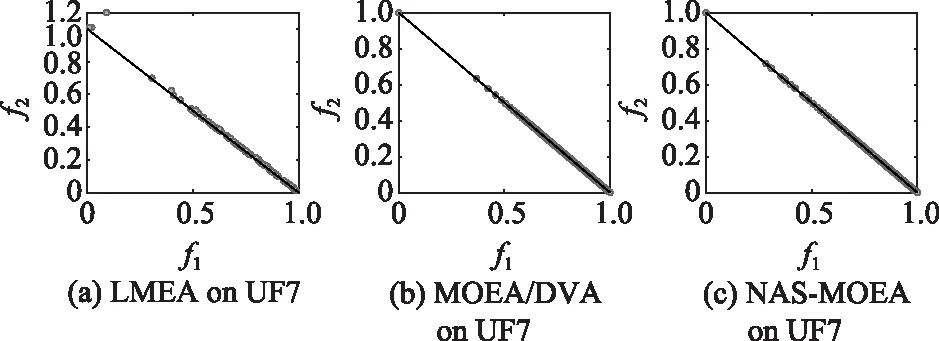
一个具有维决策变量,个目标函数的LSMOPs可以描述为
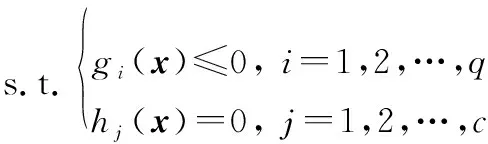
(1)
式中:=(,,…,)∈为决策变量;()为目标向量,由个目标函数()共同组成;()(=1,2,…,)表示目标函数需满足个不等式约束;()(=1,2,…,)表示目标函数需满足个等式约束。在此基础上,给出以下几个重要定义。
帕累托占优:假设可行解集中存在两个可行解、,当且仅当
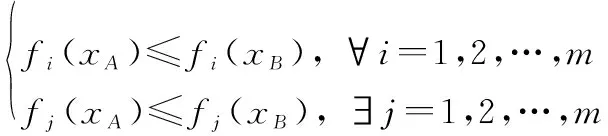
(2)
则称与相比是帕累托占优的,记作p,称为支配。

(3)
帕累托最优前沿:PS中的所有帕累托最优解对应的目标矢量组成的曲面称为帕累托最优前沿(Pareto front,PF):
PF≜{()|∈PS}
(4)
帕累托真正的前沿记为PF。
2 NAS-MOEA
2.1 决策变量分析
在LSMOPs中,既要保证解集的收敛性,也要保证解集的多样性,相对应的,一部分决策变量主要控制着解集生成的收敛性,而另一部分则主要控制着解集生成的多样性。因此,优化算法可以根据变量的不同控制类型来对其进行分类。Ma等提出的决策变量分类策略基于扰动解的支配关系将决策变量分为位置变量、距离变量和混合变量。当扰动解间均为支配关系时为距离变量,控制种群的收敛性,当扰动解间都处于同一PF时称为位置变量,控制种群的多样性,其余称为混合变量。由于混合变量与位置变量都对种群的分布有影响,因此将这两类变量都用作控制种群的多样性。但是有些混合变量生成的扰动解间大多数为支配关系,只有少数不是,那么这种变量在实际进化中更趋向于控制种群的收敛性,若用这种更适合进化种群收敛性的混合变量来进化种群的多样性不但会造成资源浪费,而且也没有达到种群多样性进化的目的。
因此,本文改进了决策变量的分类方式,对于距离变量和位置变量依旧根据其对种群收敛性和多样性的影响划分为收敛性变量和多样性变量。对混合变量则根据其对收敛性和多样性的偏好进行分类,若该混合变量趋向于控制解的收敛性,则将其划分为收敛性变量,反之则划分为多样性变量。这样提升了分类的准确性,能够在后续优化过程中对不同种类的变量进行更精确的处理,进而提升算法的整体性能。
图1举例说明了混合变量分析的过程,在图1中使用的多目标优化问题是

(5)
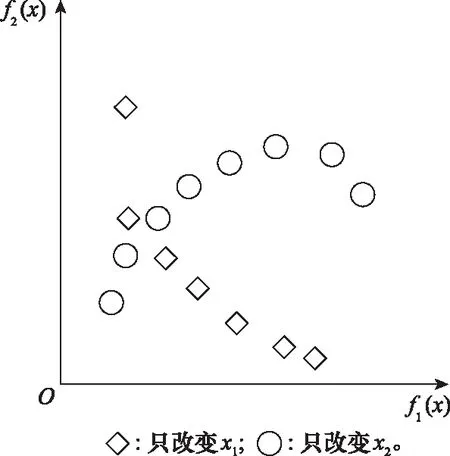
图1 混合变量分析示意图Fig.1 Schematic diagram of mixed variable analysis
图1中,()和()为两个目标函数,圆点和方点分别表示保持其他变量等于05而只改变和各8次产生的扰动解。需要注意的是,评价扰动解间的支配关系需要耗费的目标函数评价次数与扰动解的个数相同。由图1可以看出,大部分方点都处于同一个PF上,只有一个点与其他点间存在支配关系;对圆点而言,只有两个点在同一PF上,其他点间互为支配关系。因此,虽然这两个点均为混合变量,但是对于进化种群收敛性和多样性的影响是不同的,圆点对于进化种群收敛性更佳,方点则更适合进化种群多样性,这说明了分离混合变量,针对不同种类的混合变量进行针对性处理的必要性。算法1给出了决策变量分析的算法。

算法1 决策变量分析算法输入 决策变量数n,采样个数NCA。输出 多样性变量的索引向量DiverIndexes,收敛性变量的索引向量ConverIndexes。步骤 1 在可行域内生成随机向量X=(x1,x2,…,xi,…,xn),设置样本解集DiverIndexes=ConverIndexes=S=ø。步骤 2 按照x'i←xLi+j-1+randNCA·(xUi-xLi))对xi进行NCA次扰动,得到F(x1,x2,…,xi-1,x'i,xi+1,…,xn),将其加入到样本解集S中。其中,rand是分布在[0,1)上的均匀随机数。步骤 3 使用非支配排序方法对样本解集S进行排序,得到非支配解的数量。步骤 4 如果非支配解的数量小于NCA/2,那么xi被判定为收敛性变量,将i加入到收敛性索引向量ConverIndexes中;否则,xi被判定为多样性变量,将i加入到多样性索引向量DiverIndexes中。
2.2 主成分分析降噪策略
决策变量分为收敛性变量和多样性变量之后,本文对收敛性变量使用了主成分分析降噪策略,用于获得收敛性变量的降噪表示,它代表了数据集中的关键信息。算法2给出了主成分分析降噪的算法。

算法2 主成分分析降噪算法输入 种群pop,收敛性变量的索引向量ConverIndexes。输出 降噪后的种群pop。步骤 1 计算收敛性变量的协方差矩阵V。步骤 2 对协方差矩阵V进行特征分解,求得该矩阵所对应的特征值λi和特征向量wi,并对特征值λi进行降序排列。步骤 3 根据贡献率的大小,取前d个特征值Λ=diag[λ1,λ2,…,λd]和相应的特征向量Wd=[w1,w2,…,wd]作为子空间的基。步骤 4 由所提取的主成分重建原数据,得到降噪后的种群pop。
使用主成分分析进行降噪而非降维的原因是,降维操作会导致决策变量维数改变,随着参考坐标系的改变,计算适应度值时的映射关系也就发生了改变,这种改变是黑盒的,无法用公式来进行描述。先降维,将降维后的数据重建成原来的维度,一些对收敛性进化影响不大的值会被去除,在原始数据主要信息保留的前提下使主成分间没有关联,会使决策变量的特征更清晰,从而减少计算成本并获得更好的结果。
2.3 交替进化策略
在开始进化前,NAS-MOEA利用链接学习的思想将一个庞大的多目标优化问题分解为许多个比较简易的子多目标优化问题。其中,这些子多目标优化问题的多样性变量是均匀分布的,通过固定原始多目标优化问题的多样性变量生成,每一个子多目标优化问题的多样性变量都是不变的,只有全体收敛性变量需要被优化。
图2为种群结构示意图,共有个子多目标优化问题,每个问题有8个决策变量,,…,。其中,,是多样性变量,而,,…,是收敛性变量。
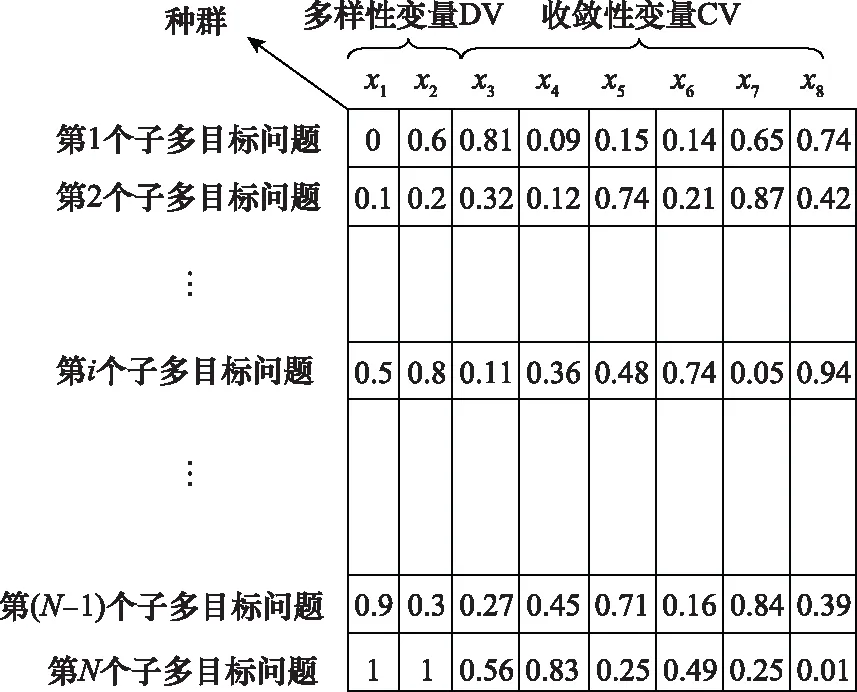
图2 NAS-MOEA的种群结构示意图Fig.2 Schematic diagram of population structure of NAS-MOEA
在进化阶段,NAS-MOEA采用不同的策略交替地优化收敛性变量与多样性变量直至算法结束。在种群收敛性进化阶段,固定种群多样性变量的值而只进化收敛性变量,在种群多样性进化阶段,固定种群收敛性变量的值而只进化多样性变量。图3为种群交替进化流程图。

图3 种群交替进化流程图Fig.3 Flow chart of population alternate evolution
在种群的收敛性进化阶段,NAS-MOEA使用差分进化算子。变异策略为DE/rand/1,其定义为
,=1,+·(2,-3,)
(6)
在当前代中,对于个体,,首先找到该子多目标问题的邻域,从邻域中随机选取两个个体2,和3,作为偏差向量,生成一个新个体,。其中,需关注变异算子,变异算子决定偏差向量的放大比例,过小造成算法早熟,过大导致算法的收敛性变差。因此,在NAS-MOEA中的变异算子使用0~1之间的随机值,在进化收敛性变量时,避免算法早熟以及收敛性变差。
在种群的多样性进化阶段,首先NAS-MOEA对每个子多目标优化问题都会随机产生一个新的子代解,需要注意的是,这些子代解只有全部多样性变量与父代解不同。然后,NAS-MOEA将父代种群和所有新生成的子代解相结合,并对其进行非支配排序,最终得到许多个非支配前沿。在此过程中,NAS-MOEA会选出位于前个非支配前沿位置的解,其中是满足|PF∪PF∪…∪PF|≤||的最大值。若=0,NAS-MOEA则寻找至少在一个目标方向上具有最大目标值的解,将其放入选择之后的新种群中。之后,NAS-MOEA每次从第+1个非支配前沿中选出一个解直到所有选出解的数量与种群的大小相同,其中,NAS-MOEA在第+1个非支配前沿中每次选择的单个解必须保证与所有已经被选中的解有最远的距离。
2.4 差分进化的邻域自适应更新策略
自适应更新邻域策略指每个子多目标优化问题优化完成后,自适应地更新该子多目标优化问题的邻域,这样每次使用邻域时都能保证此邻域是该子多目标优化问题当前的邻域,使算法更容易找到PF,从而提升算法的收敛速度。
邻域的自适应更新策略在收敛性变量的进化过程中执行,在使用差分进化算子进化收敛性变量时,首先要找到每个子多目标问题的邻域。通过比较当前子多目标优化问题与其他子多目标优化问题间多样性变量的欧几里得距离获取当前子多目标优化问题的邻域。
但是随着迭代次数的增加,该子多目标优化问题与其他子多目标优化问题间的欧式距离可能会发生改变,可能靠近也可能远离。这时,以最初找到的邻域作为固定邻域则不够准确,不利于进化种群的收敛性。
图4为一次邻域更新过程示意图,初始邻域中有,,,4个子多目标问题,邻域中有,,3个子多目标问题,随着一次收敛性变量的进化,的位置由变为′,自适应更新邻域划分,将′从邻域更新到邻域中,再进行下一次收敛性变量的进化。
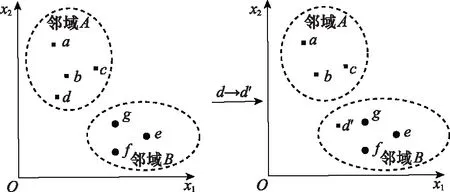
图4 邻域更新过程示意图Fig.4 Schematic diagram of neighborhood update process
算法3给出了收敛性变量优化及差分进化的邻域自适应更新过程。

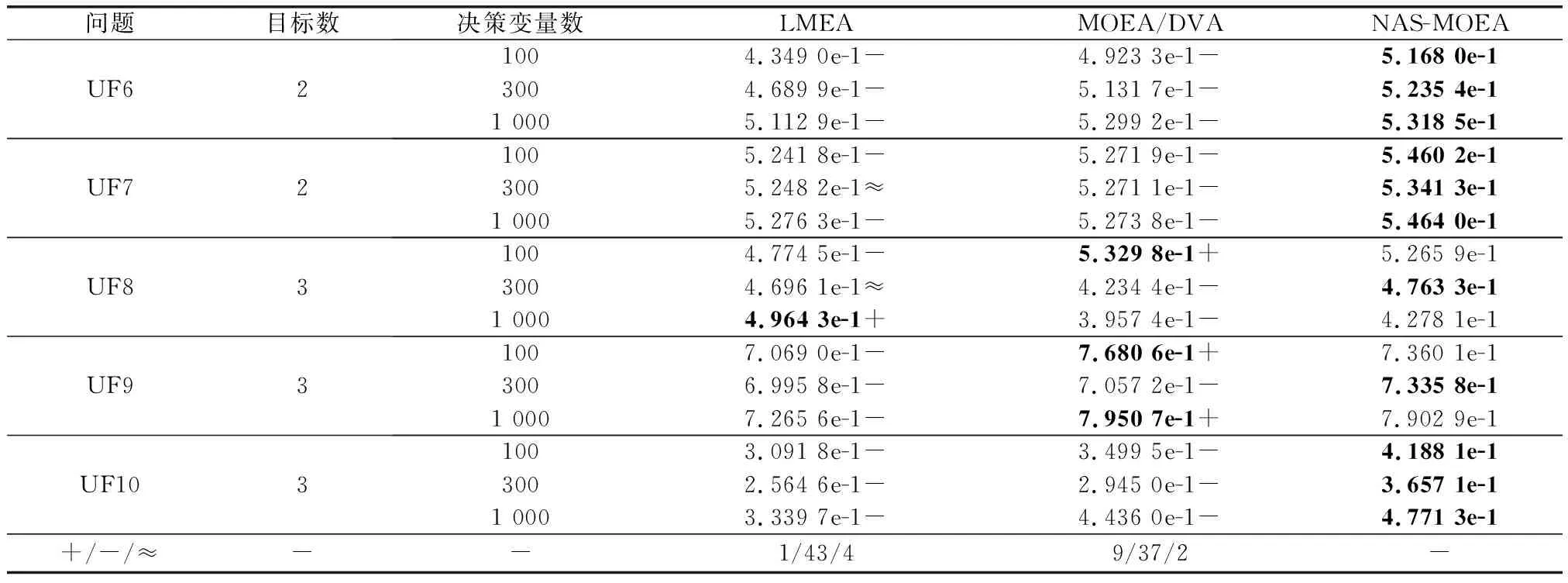
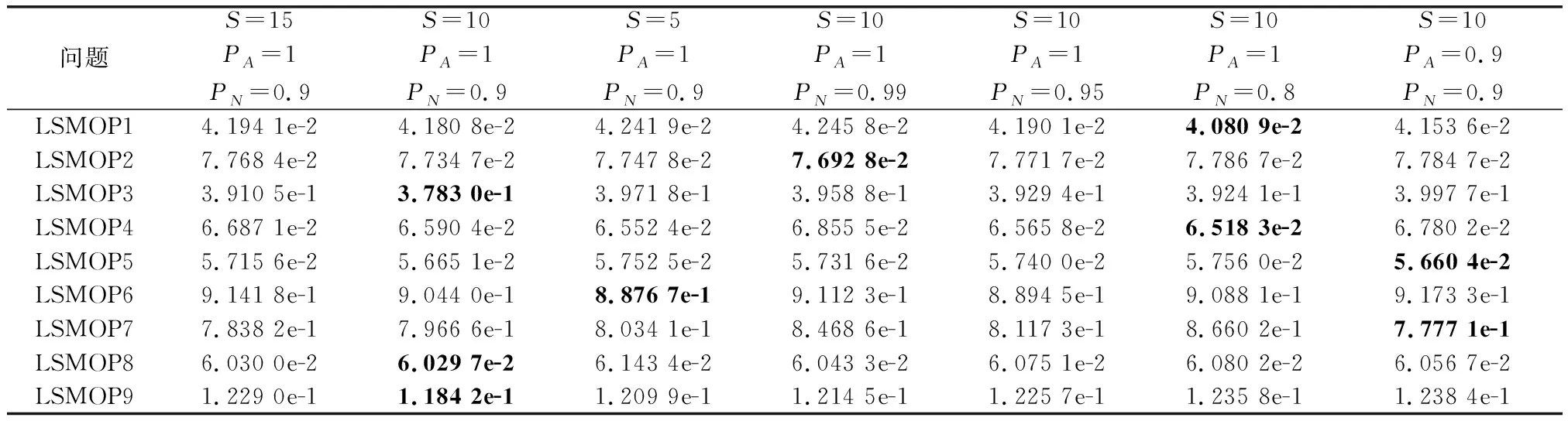
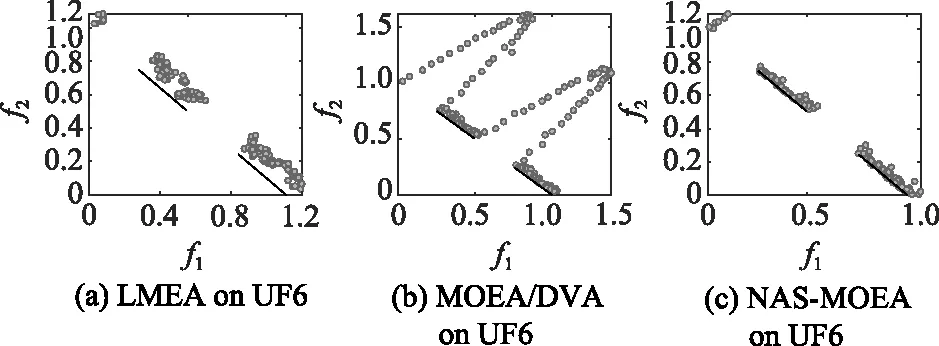
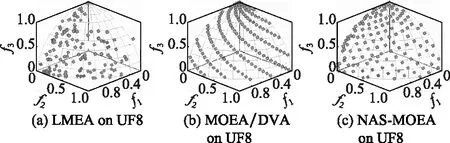
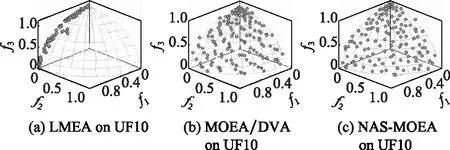
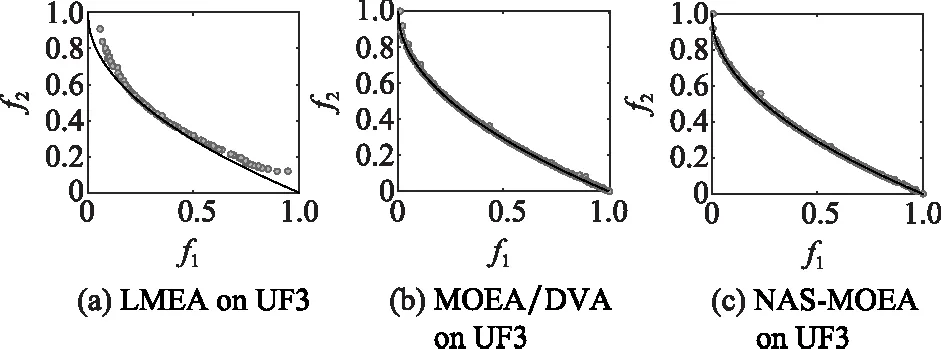
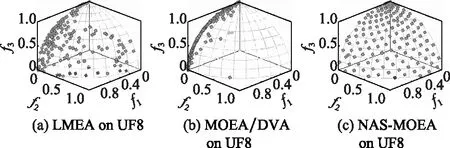
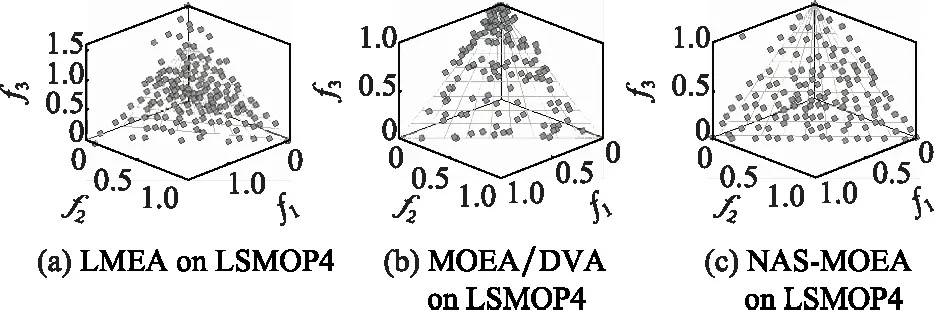
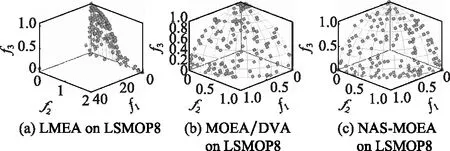
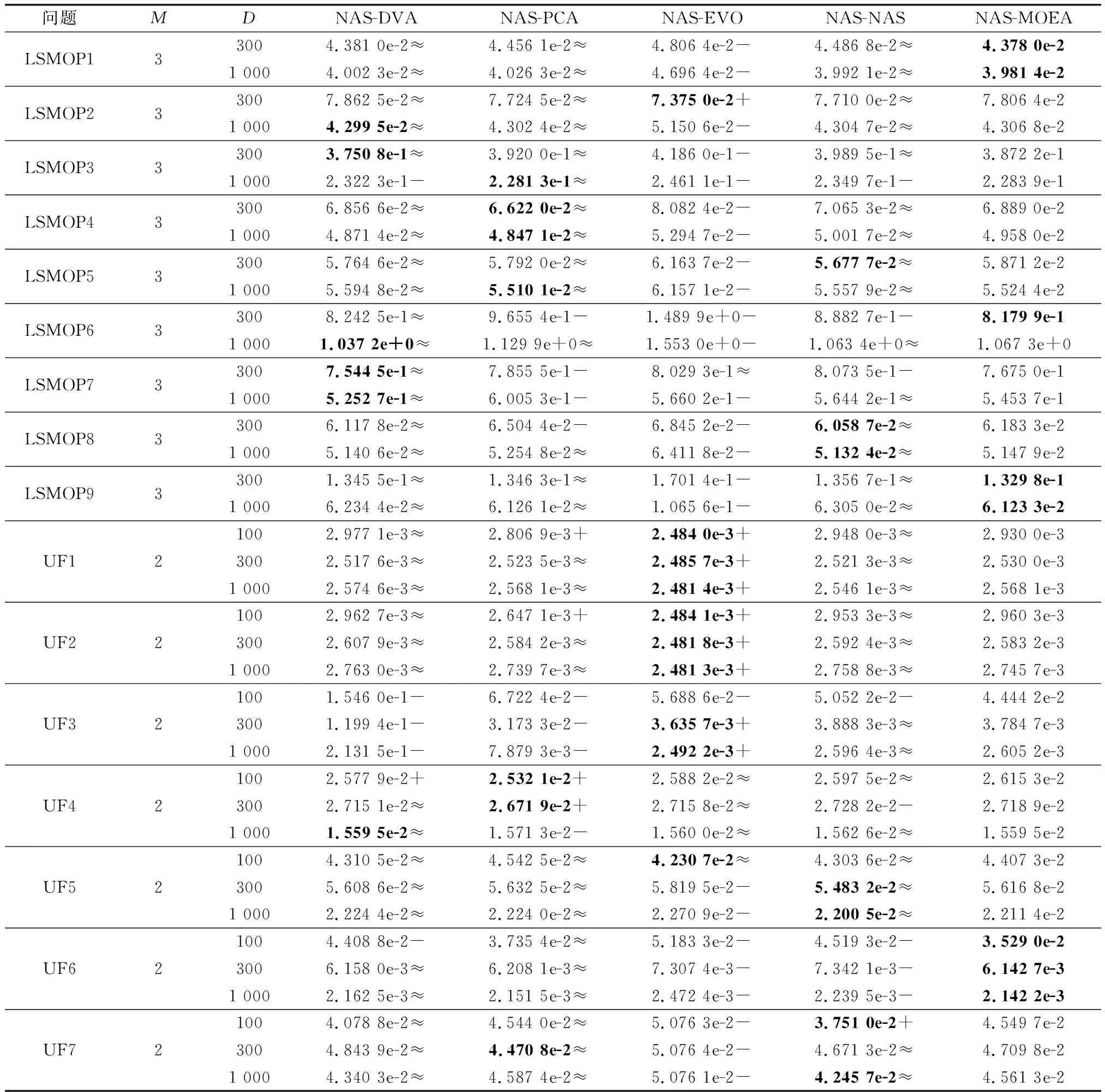
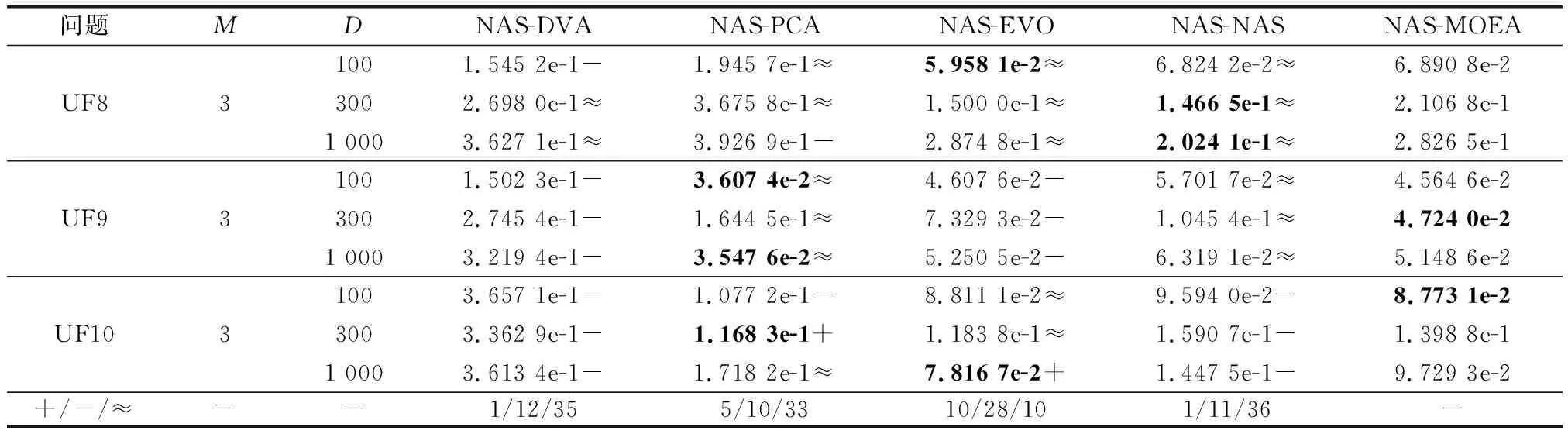
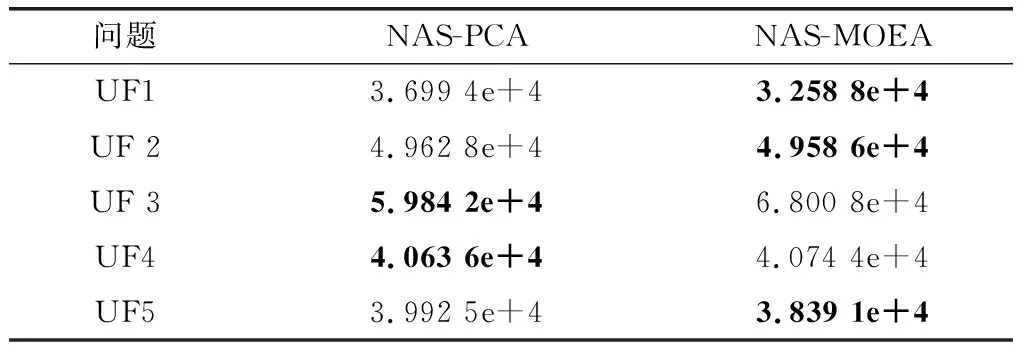
算法3 收敛性变量优化流程输入 进化种群当前解pop及其目标值Obj,收敛性变量的索引向量indices,子多目标优化问题的个数N。输出 优化后的进化种群pop及其目标值Obj。步骤 1 令i=1。步骤 2 从第i个子多目标优化问题的邻域中随机选择两个子多目标优化问题pop(k,indices)和pop(1,indices)。使用差分进化算子生成一个新个体y'←pop(i,indices)+F·(pop(k,indices)-pop(1,indices))。其中,差分进化算子的缩放因子F为0~1之间的随机值。步骤 3 对新个体y'实行多项式变异操作。步骤 4 若f1(y)+f2(y)+…+fm(y) NAS-MOEA算法的具体流程如算法4所示。 算法4 NAS-MOEA算法流程输入 LSMOPs,目标数M,决策变量数n,种群大小N,采样个数NCA,变量链接判定的最大试验次数NIA,变异系数f,邻域大小S。输出 经过优化后的种群pop,目标值Obj。步骤 1 使用算法1进行决策变量分析。步骤 2 使用随机采样方法初始化种群的收敛性变量,得到pop(:,CV),使用均匀分布采样点技术初始化种群的多样性变量,得到pop(:,DV)。步骤 3 使用算法2和链接分析技术将收敛性变量分组。步骤 4 计算多样性变量之间的欧氏距离,按照距离从小到大排列,取最小的S个变量作为该变量的邻域。步骤 5 进化种群。步骤 5.1 令f的初始值为0.5。步骤 5.2 按照算法3优化收敛性变量。步骤 5.3 优化多样性变量:使用遗传算法对种群中的每个解产生一个子代解,将所有子代解与种群结合,并对合并后的种群进行非支配排序;接着,采用拥挤度距离为次环境选择策略来选出大小为N的种群作为子种群。步骤 5.4 停止准则。如果终止条件满足,则输出种群N;否则,返回步骤5.2。 本文主要的运算量是变量链接分析、非支配排序和拥挤度距离计算。变量链接分析的复杂度为(),其中是决策变量数。非支配排序的复杂度为(()),其中是种群数量,是目标数。拥挤度距离计算的复杂度为(log())。因此,本算法整体时间复杂度为max((),(()))。LMEA和MOEA/DVA作为本文的对比算法,其时间复杂度分别是(())和max((),())。由此可见,本文提出的算法在复杂度方面与对比算法相似。 本文针对两目标和三目标的LSMOPs进行测试,分别采用测试函数集为UF和LSMOP系列测试函数。 UF是由IEEE Congress on Evolutionary Computation所提出的针对LSMOPs的测试集,UF测试集有共包括10个连续且不带约束的多目标优化问题。UF测试集求解难度较高,主要是决策变量间的关联度很高,这给决策变量分类算法带来了很大的挑战。因此,UF测试集中一些求解难度较高的多目标优化问题仍然需要探索更有效的算法去求解。 LSMOP是针对LSMOPs提出的第一个大规模多目标优化测试集,含有9个测试函数。LSMOP测试集不但具有复杂的决策变量关联性,还有决策变量分组的不均匀性以及适应度函数地形的复杂性,这些都增加了其求解难度。 为了评估算法的性能,在实验中使用反向世代距离(inverted generational distance,IGD)指标和超体积(hypervolume,HV)指标,二者都能标量化地反映算法的性能。针对某一个测试问题,IGD指标越小,表明该算法获得的PF越能够代表该问题的PF,而HV指标反之。IGD的计算公式如下: (7) 式中:是在PF上均匀分布的一系列解;是PF的近似解;(,)是中的个体到中所有个体的最小欧氏距离。 HV定义为种群中的点与参考点集中的点所围成的区域的超体积,但HV中的参考点集R是远离PF的一个或多个参考点,而不是处于PF上的一个或多个随机采样点,计算公式如下: HV(,)=((,)) (8) 式中:表示勒贝格测度,即 (9) 实验的参数设置如下:种群大小设置为100,最大目标函数评价次数在决策维数为100、300、1 000时分别设为1 000 000、3 000 000、30 000 000,经过20次独立运行比较算法的IGD结果。本文对比的算法有LMEA和MOEA/DVA,对于NAS-MOEA,在进化收敛性种群阶段,设置差分进化时的变异算子的初始值为05,交叉算子为1。邻域的大小设置为01,每个解被子代解替换的概率为001,从邻域中选择父代解的概率设置为09。为了方便比较,决策变量分析的相关参数设置与LMEA一致。在NAS-MOEA和MOEA/DVA中的决策变量相关性分析次数设为6,决策变量分析中解的选择数量设为20,LMEA中的决策变量聚类中解的选择数量设为2,每个解的扰动次数NCA设为4,决策变量相关性分析次数设为6。 表1给出了NAS-MOEA和MOEA/DVA,LMEA在UF和LSMOP上20次运行后得到的IGD和平均运行时间统计结果。表2给出了NAS-MOEA、MOEA/DVA和LMEA在UF和LSMOP上20次运行后得到的HV统计结果。在LSMOP测试集的9个测试函数上的实验结果由两行数据构成,分别代表目标数为3时,维数为300,1 000维下的优化结果。在UF测试集上,其中UF1-7测试函数的目标数均设置为2,在UF8-10上设置为3,3行数据分别表示维数为100,300,1 000维下的优化结果。 表1 3种算法在UF和LSMOP上的IGD和平均运行时间结果 续表1 表2 3种算法在UF和LSMOP上的HV结果 续表2 实验记录IGD和HV指标的平均值,其中,加粗项为同一测试函数中获得的最优值。还采用了显著性水平为0.05的Wilcoxon秩和检验对结果进行分析,符号“+”“-”和“≈”分别表示对比算法的性能显著优于、显著差于或统计意义上相似于所提出的算法。 3.4.1 参数敏感性分析 NAS-MOEA算法主要用到了3个参数,邻域的大小、每个解被子代解替换的概率,和从邻域中选择父代解的概率。为了分析上述3个参数对算法性能的敏感性,本文对每个参数使用多个实验数据,的3个实验值分别是5,10和15,的两个实验值为1和09,的4个实验值分别是08,09,095和099。以3目标300个决策变量的LSMOP1~LSMOP9作为测试问题,每个问题两个参数的配置都独立运行3 000 000次。 表3给出了NAS-MOEA在不同参数的3目标300个决策变量的LSMOP上20次运行的IGD结果。从表3中可以看出,NAS-MOEA提出的基于差分进化邻域自适应的算法对参数,和的不同组合具有很强的鲁棒性,在=10,=1,=09下得到的结果最优,在9个测试函数中有3个结果最优,有3个次优。故将=10,=1,=0.作为NAS-MOEA的首选参数设置。 表3 NAS-MOEA在不同参数的3目标300个决策变量的LSMOP上的IGD结果 3.4.2 100维问题上的实验结果 在这一部分,将NAS-MOEA算法用于具有100维决策变量的测试函数上,使用UF1~UF10问题。实验结果表明,NAS-MOEA在UF3~UF7、UF10等问题上取得了较好的效果,而MOEA/DVA在UF1、UF2、UF8问题上优化效果最好,对于UF9来说,LMEA的优化效果优于NAS-MOEA算法。从算法总体运行时间上看,NAS-MOEA要稍高于LMEA和MOEA/DVA。 图5~图14展示了NAS-MOEA、LMEA和MOEA/DVA在100个变量的UF1~UF10上运行20次获得的平均最终种群,其最大迭代次数为1 000 000。其中,黑色曲线/点代表理想的PF,灰色圆圈代表各算法运行得到的真实个体,形成了PF。可以看到,NAS-MOEA在UF2~UF3,UF6,UF8~UF10问题上获得的解集在多样性和收敛性上要比对比方法更好。在UF1,UF4,UF5,UF7上MOEA/DVA找到的解集与NAS-MOEA相似,均比LMEA在多样性和收敛性上更好。实验结果表明,NAS-MOEA在保证收敛的情况下对于解集分布更加均匀,之所以NAS-MOEA在被选问题上成功,主要原因是将决策变量根据其本身性质划分为收敛性变量和多样性变量,对每种变量进行针对性处理,并利用其特性进行收敛性和多样性的交替进化操作,这说明NAS-MOEA在大规模决策变量测试问题上的优越性。 图5 100个变量的UF1上的解集Fig.5 Solution set on UF1 with 100 variables 图6 100个变量的UF2上的解集Fig.6 Solution set on UF2 with 100 variables 图7 100个变量的UF3上的解集Fig.7 Solution set on UF3 with 100 variables 图8 100个变量的UF4上的解集Fig.8 Solution set on UF4 with 100 variables 图9 100个变量的UF5上的解集Fig.9 Solution set on UF5 with 100 variables 图10 100个变量的UF6上的解集Fig.10 Solution set on UF6 with 100 variables 图11 100个变量的UF7上的解集Fig.11 Solution set on UF7 with 100 variables 图12 100个变量的UF8上的解集Fig.12 Solution set on UF8 with 100 variables 图13 100个变量的UF9上的解集Fig.13 Solution set on UF9 with 100 variables 图14 100个变量的UF10上的解集Fig.14 Solution set on UF10 with 100 variables 3.4.3 300维问题上的实验结果 统计结果表明,NAS-MOEA在LSMOP1~LSMOP9、UF3~UF7、UF9和UF10等绝大多数问题上的性能都优于MOEA/DVA和LMEA,MOEA/DVA在UF1和UF2上依旧以微弱的差距优于NAS-MOEA,在UF8上LMEA优于MOEA/DVA和NAS-MOEA。总体来看,NAS-MOEA对于三目标问题的求解优势更为显著,在给出的所有三目标测试函数上的IGD和HV结果均优于对比算法。原因是NAS-MOEA采用了分治策略,将一个复杂的LSMOPs转化为了多个简单的子多目标优化问题,减小了问题的规模,加快了算法的执行速度,并对其进行交替优化,通过交替进化收敛性变量和多样性变量,平衡了算法的收敛性和多样性。 图15~图20选取了对比算法在300变量的部分LSMOP和UF测试函数上运行20次得到的平均最终种群,最大迭代次数为3 000 000。其中,黑色曲线和三维网状图代表PF,灰色圆圈代表各算法运行得到的真实个体,形成了PF。 图15 300个变量的UF3上的解集Fig.15 Solution set on UF3 with 300 variables 图16 300个变量的UF6上的解集Fig.16 Solution set on UF6 with 300 variables 图17 300个变量的UF8上的解集Fig.17 Solution set on UF8 with 300 variables 图18 300个变量的LSMOP4上的解集Fig.18 Solution set on LSMOP4 with 300 variables 图19 300个变量的LSMOP8上的解集Fig.19 Solution set on LSMOP8 with 300 variables 图20 300个变量的LSMOP9上的解集Fig.20 Solution set on LSMOP9 with 300 variables NAS-MOEA获得的PF优于其他算法的结果,对UF3和LSMOP4而言,MOEA/DVA得到的解集较为均匀,这是因为其能正确地将决策变量分组,故在此问题上性能较好。NAS-MOEA也可以正确地将这些问题中的决策变量分组,故也能在这些问题上得到最好或与MOEA/DVA相当的结果。NAS-MOEA在UF8上的性能与LMEA相当,但是在解集的分布性上优于LMEA,这是因为NAS-MOEA采用交替进化策略,平衡了进化种群的收敛性和多样性的冲突。NAS-MOEA在UF6、LSMOP8、LSMOP9上性能要优于LMEA和MOEA/DVA,原因是NAS-MOEA采用主成分分析降噪和差分进化的邻域自适应更新策略,两种策略相结合使NAS-MOEA在进化过程中更高效的进化种群,这对种群收敛性有积极作用。因此本实验可以验证NAS-MOEA在大规模决策变量问题上的有效性,其收敛能力和多样性能力更优。 3.4.4 1 000维问题上的实验结果 在1 000维的测试函数上,在LSMOP系列和UF系列共19个测试函数上进行实验,IGD结果表明,NAS-MOEA在其中的17个测试函数上的性能都优于MOEA/DVA和LMEA,在UF8上NAS-MOEA表现虽不如LMEA,但与MOEA/DVA相比仍有优势,MOEA/DVA在UF9上表现更优。HV结果表明,NAS-MOEA在其中的14个测试函数上的性能都优于对比算法,NAS-MOEA和MOEA/DVA在UF1~UF3上表现相似,MOEA/DVA略优于NAS-MOEA,两算法均优于LMEA。从算法总体运行时间上看,NAS-MOEA在LSMOP7上运行时间小于MOEA/DVA,在全部测试函数上总体运行时间均小于LMEA。 可以看出,随着决策变量的增加,NAS-MOEA的优势逐渐显现出来,这主要是因为差分进化的邻域自适应更新策略随着决策变量的增加显示出了其优越性。收敛性变量的邻域自适应更新是收敛性变量的优化是进化过程中最重要的环节之一,在收敛性变量差分进化的过程中,从合适的邻域中选取父代有助于更快地找到非支配前沿,在进化过程中不断更新邻域,会加快种群收敛性进化的速度,从而更快更好地找到PF。 3.4.5 算子有效性的实验验证 为了进一步探究NAS-MOEA中各个算子的贡献度和鲁棒性,本节针对每一个算子设计了消融实验,通过与算法中的一部分进行对比,在保证其余部分一直可控的情况下,单独探究每个算子的有效性。为此,设计了4种NAS-MOEA变体,分别命名为去除决策变量分析的NAS-MOEA(NAS-MOEA without decision variable analysis,NAS-DVA)、去除决策变量分析的NAS-MOEA(NAS-MOEA without principal component analysis,NAS-PCA)、去除交替进化策略的NAS-MOEA(NAS-MOEA without alternate evolution strategy,NAS-EVO)、去除邻域自适应策略的NAS-MOEA(NAS-MOEA without neighborhood adaptive strategy,NAS-NAS)。 在NAS-DVA中,去除了决策变量分析算子,对于混合变量没有进一步划分,将混合变量默认为多样性变量。NAS-PCA去除了收敛性变量的降噪算子,直接对收敛性变量进行链接分析。在NAS-EVO中,放弃了种群的交替进化策略,取而代之的是将整个进化过程分为两阶段,第一阶段进化种群的收敛性,第二阶段进化种群的多样性。NAS-NAS去除了收敛性进化过程中的邻域自适应更新算子,只在开始进化前计算邻域组成,在进化收敛性过程中不改变邻域。NAS-MOEA和其4个变体在LSMOP和UF测试集上的IGD结果表4所示。表5给出了NAS-PCA和NAS-MOEA在2目标3 000个决策变量的5个UF问题上20次运行的平均运行时间统计结果。 表4 5种算法在UF和LSMOP上算子有效性验证的IGD结果 续表4 表5 NAS-MOEA和NAS-PCA在3目标3 000个决策变量的LSMOP上的运行时间结果 从表4可以看出,在1 000维以下的NAS-MOEA在LSMOP6~LSMOP10、UF3~UF8的性能均优于NAS-PCA,这表明主成分分析降噪策略对算法性能提升有效果。在与NAS-PCA算子的比较中,从表5可以看出在UF1,UF2和UF5测试函数上,缺少降噪算子会导致算法的总体运行时间变长,这说明在高维情况下降噪算子在保留原始数据主要信息的前提下能有效减少计算成本,效果会随着维数的增加而更加明显。 在与NAS-DVA算子的比较中可以验证决策变量分析算子的有效性,通过对混合变量的准确划分,使算法在后续进化过程中对不同种类变量采用不同进化方式的策略得以实现。在与NAS-EVO的比较中,交替进化策略的去除导致算法的寻优效率减慢,导致NAS-EVO在大多数测试函数上表现都比较差。因此可以看出,交替进化策略对进化种群收敛能力和多样性寻优能力有影响。在与NAS-NAS的对比可以看出,差分进化的邻域的自适应更新策略避免了邻域变化对种群的收敛性进化的不利影响,加快了收敛性进化的速度。 本文针对LSMOPs提出了NAS-MOEA。在NAS-MOEA中,设计了一种新的决策变量分类方法,根据决策变量分别对收敛性和多样性的贡献,将决策变量分为两组,即收敛性变量和多样性变量。使用主成分分析策略对收敛性变量进行降噪处理,根据分组结果,分别对两组变量进行交替优化,在优化收敛性变量的过程中又加入差分进化的邻域自适应更新策略。多种机制相结合,有助于提升算法的收敛能力。在具有多达1 000个决策变量的19个复杂测试函数上开展实验,并将实验结果与经典大规模多目标优化算法以及最新的大规模优化算法进行对比。实验结果表明,本文提出的算法能在一定的计算时间内具有更快的收敛速度和更高的寻优精度,表现出良好的性能。下一步将探索新的决策变量分类方法,减少变量分组阶段的计算资源消耗,以进一步提高算法性能,加快问题求解。2.5 NAS-MOEA算法流程

2.6 算法复杂度分析
3 算法性能测试及分析
3.1 测试函数
3.2 性能指标
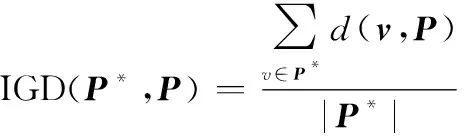

3.3 参数设置
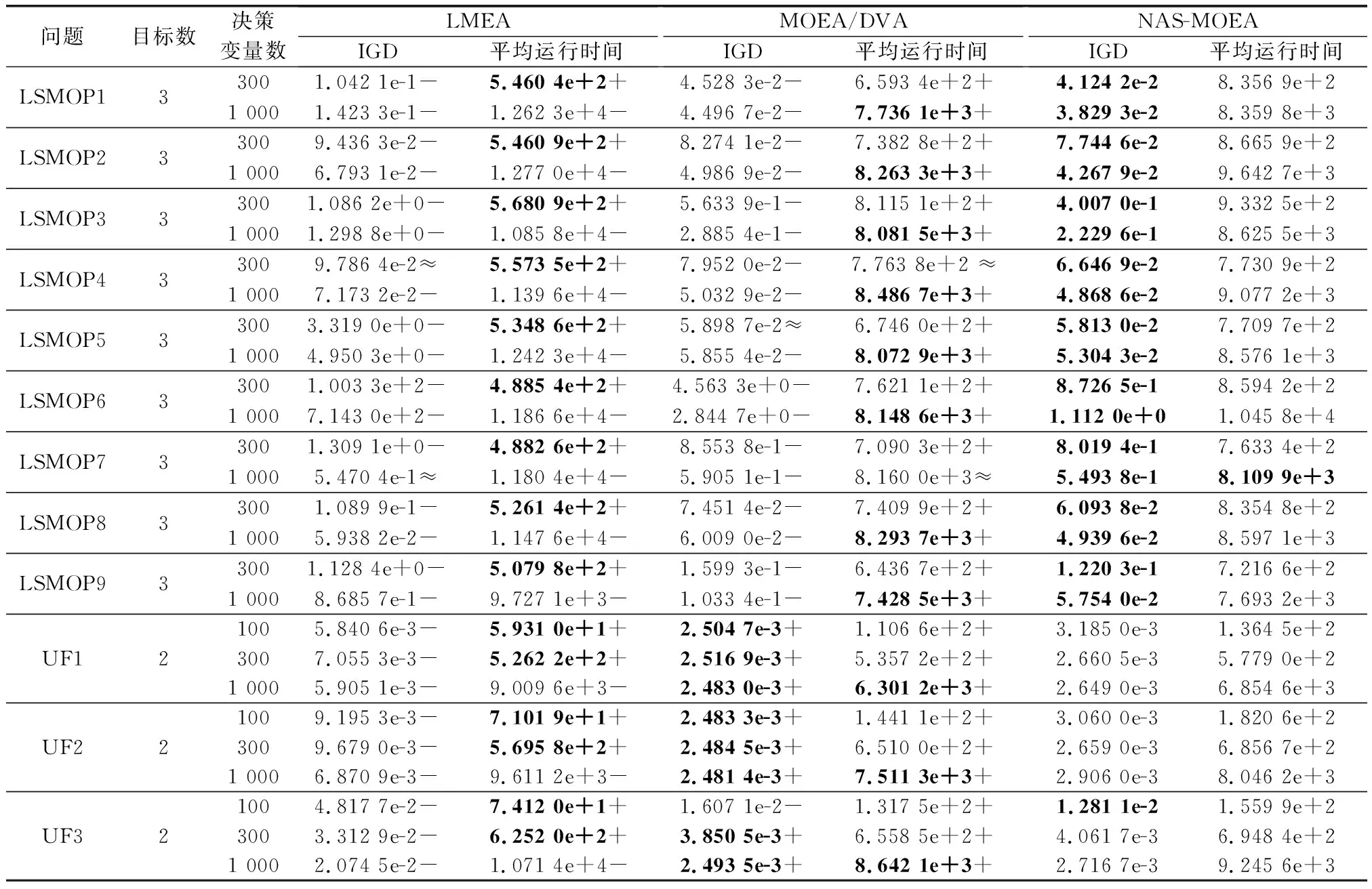
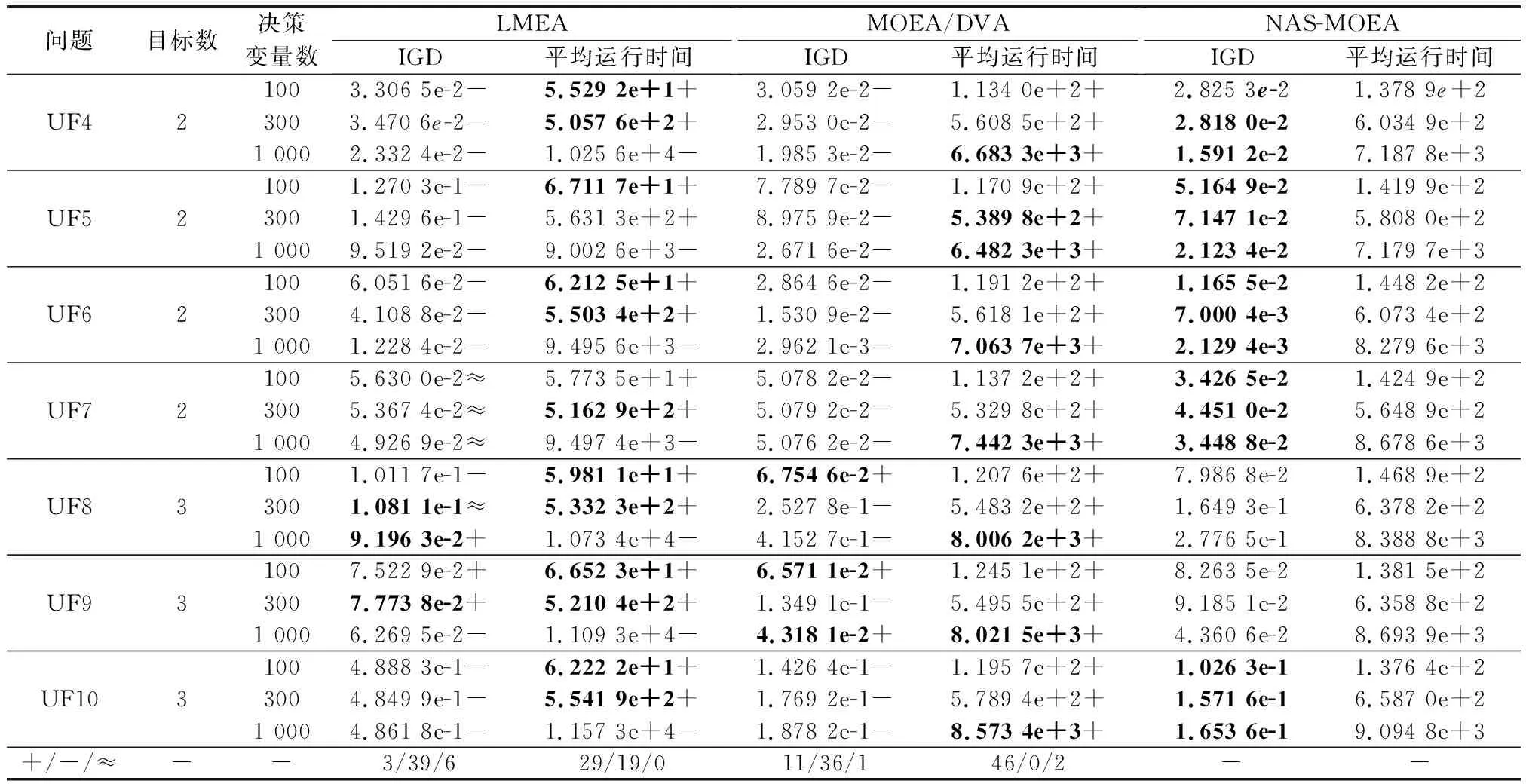
3.4 实验结果与分析








4 结 论
