多模态公文的结构知识抽取与组织研究
2022-06-25徐瑞麟耿伯英刘树衎
徐瑞麟, 耿伯英, 刘树衎
(1. 海军工程大学电子工程学院, 湖北 武汉 430033; 2. 中国人民解放军91001部队, 北京 100036;3. 东南大学计算机科学与工程学院, 江苏 南京 211189)
0 引 言
目前,以司法机器人等为代表的面向规范性文本的智能问答应用实践中,最普遍使用的方式是针对常见问题(frequently asked questions, FAQ)构建问答对,但所构建的问答对难以涵盖所有的问题。同时,基于知识库问答(knowledge based question answering, KBQA)的方法也存在解答效率低的问题。由于法律法规和政策文件等文档数据条目清晰,法理逻辑和思想路线等内涵蕴藏于文档结构中,因此针对文档的结构知识抽取和组织研究成为了一个值得探索的方向。然而,此类文档数据一般通过网页、电子文档、扫描件等非结构化的形式被获取到,如何将此类非结构化文档转换成为结构化的、层次逻辑清晰的文档,成为了一个重要的研究课题。
以知识图谱为代表的知识网络是最通用的知识结构化表示形式,例如FreeBase、DBpedia和YAGO等。这些大规模知识库一般通过实体识别和关系抽取等技术,从文本中大量抽取“实体,关系,实体”的三元组知识而构建。然而,此类知识图谱往往存在关系稀疏、结构上缺乏层次性等特点,难以形成与人类知识组织相似的知识体系,无法针对智能问答等下游任务提供技术支撑。为解决三元组知识结构逻辑性不强的问题,本文对文档的结构知识抽取与组织展开研究,将文档各级标题、摘要、作者、成文时间、文档编号等要素称为文档的知识结构要素。通过将上述文档知识结构要素按照文档的结构逻辑组织起来,更有利于厘清文档知识的层次逻辑,并建立知识体系。
在文档的结构信息抽取任务中,传统方法大多面向文本单一模态,采用基于规则的方法或基于自然语言处理(natural language processing, NLP)的方法实现。文献[8]利用正则表达式实现对金融公告文档中章节标题的抽取。文献[9]针对法律裁判文书构建规则,将非结构化的裁判文书转换成结构化的XML格式文档。文献[10]提出了一种基于双向长短记忆(bidirectional long short-term memory, BiLSTM)网络和条件随机域(conditional random field, CRF)模型的端到端模型,以从庭审笔录中抽取证据信息。文献[11]研究了利用命名实体识别和关系抽取方法从病历中抽取结构信息的方法。文献[12]设计了一种结合规则和NLP模型的文档结构信息抽取方法。文献[13]提出了一种基于隐马尔可夫模型方法和深度神经网络的文档版面分析方法。然而,这些文本模态的方法没有考虑文档的视觉特征,无法有效利用文档标题等视觉特征明显的关键要素。
视觉丰富文档分析(visually-rich document analysis, VRDA)任务旨在对文档页面图像或PDF文档进行分析,以识别文档中的标题、插图、表格、公式等各类结构要素。该任务与文档的知识结构抽取具有相似性。为了实现对视觉丰富文档(visually-rich documents, VRDs)的结构信息抽取,文献[14]针对银行文档页面提出了一种先进行光学字符识别(optical character recognition, OCR),再通过NLP模型抽取文档结构信息的方法;文献[15]提出了一种从VRDs中提取信息的通用方法,将文档页面分割为不同语义区域进行信息抽取;文献[16]提出了一种端到端的多模态全卷积网络;文献[17]提出了结合文档中文本与视觉信息的图卷积模型;文献[18]提出了大规模预训练语言模型与图神经网络相结合的抽取方法。LayoutLM及其改进模型则将文本模态和图像模态结合起来,以更好地抽取文档结构信息。
上述模型和方法大多聚焦于商业领域文档,对公文这一具有规范成文规则且应用广泛的文档类型鲜有研究。并且,目前的研究和应用局限于抽取知识结构要素,而没有将知识结构要素按照文档的结构逻辑组织起来。因此,为了解决知识结构要素的抽取和组织中存在的问题,本文以公文为研究对象,构建文本和图像多模态公文文档数据集,在文本模态通过构建规则抽取知识结构要素,在图像模态利用目标检测和OCR抽取知识结构要素;并提出多模态知识结构要素抽取模型,将文本和图像两个模态的抽取结果综合考虑,得到最终的抽取结果。本文利用所抽取出知识结构要素的层次结构特征,将非结构化的公文文档按结构逻辑组织形成文档结构树并构建结构化的文档网络。实验验证了对多模态文档知识结构要素抽取和组织的有效性。
本文的主要贡献如下:① 针对目前鲜有研究的公文结构知识要素抽取问题,提出一个多模态公文结构知识要素抽取模型;② 设计文档结构树(document structure tree, DST)模型,将抽取的知识结构要素组织形成结构化图网络;③ 构建多模态公文文档数据集,填补了多模态公文文档的数据空白。
1 多模态公文知识结构要素抽取
本文以公文为例(本文所称公文,是指依据文献[21-22]中的规定所拟制的机关公文),从文本和图像两个模态分析抽取公文知识结构要素的方法。由于书籍、论文、技术报告和法律法规文档中的知识结构要素同样具备与公文类似的规律性特征,因此也可以采用相同方法实现抽取。
1.1 文本模态的知识结构要素抽取
文本模态的公文文档知识结构要素抽取,即从无结构的公文文本中抽取“正文标题、一级标题、二级标题、三级标题、密级、紧急程度、发文机关标志、发文字号、主送机关、抄送机关”等要素。由于公文文档具有严格的成文标准,因此可以通过建立规则实现知识结构要素的抽取。
1.1.1 公文知识结构要素的规则分析
文献[21-22](以下简称“《标准》”)对公文的各级标题进行了规定,这些标题具备典型的上下级层次关系,且按照“数词+特殊符号”的方式进行编号。因此,通过分析这些编号模式并建立词典(见表1),可以实现对一级、二级、三级标题的识别。

表1 公文各级标题的编号方法
此外,依据机关公文的行文和用语习惯,可以得到表2所示的公文常用的其他形式的各级标题编号方法。

表2 公文各级标题的其他编号方法
类似地,对于密级、紧急程度、发文字号、主送机关等其他各类结构要素,从文本的角度看,可以分析和归纳为表3所示的识别规则。

表3 公文知识结构要素的抽取规则
1.1.2 公文知识结构要素的抽取流程
(1) 数据预处理
数据预处理包括文本清洗和文本分句两个部分。文本清洗,即清除不符合格式规范的换行符、空符、缩进和英文标点等字符的过程。文本分句,首先以换行符为标志,将文本所成自然段进行分割并赋予标签,随后在分段的基础上,以中文常用句终标点(如句号、感叹号、省略号等)为标志对段落进行语句分割并赋予标签。数据预处理算法如算法1所示。

算法 1 数据预处理输入 公文文本数据Document输出 赋标签的句子集Sentences1 lines ← readlines(Docunment)2 for line in lines do3 Paragraph ← line.strip(‘tab’)4 end for5 for para in Paragraph do6 Sentences←Paragraph[para].cut(punctuation)7 end for8 return Sentences
通过数据预处理,使得整篇数据文本转化为以句子为单位、每个句子由标签索引的自由文本集合={(,),(,),…,(,)},其中(,)表示文中每一个句子所被赋予的唯一标签,也即该句位于文中第自然段的第句。
(2) 建立抽取规则
由于《标准》在文本层级上对各级标题的规定严格到了具体的字符级别,因此可以简单地认定,对文本中的每个语句,仅需遍历前文所构建的标题词典,若存在匹配的文本对象,则记录其所处级别和语句的坐标位置。各级标题识别算法如算法2所示。
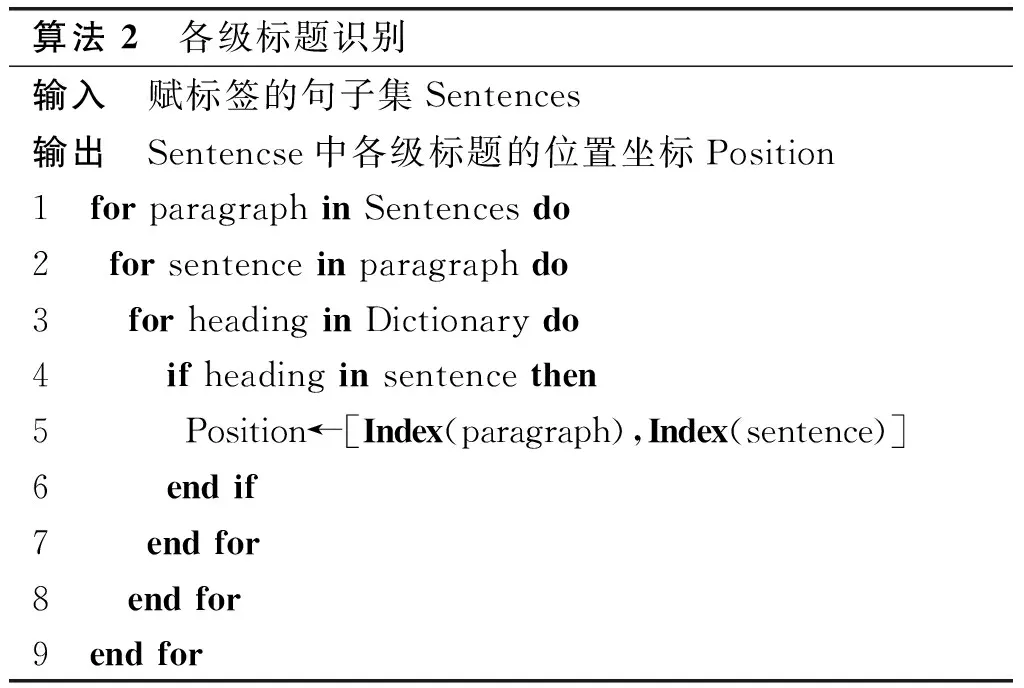
算法 2 各级标题识别输入 赋标签的句子集Sentences输出 Sentencse中各级标题的位置坐标Position1 for paragraph in Sentences do2 for sentence in paragraph do3 for heading in Dictionary do4 if heading in sentence then5 Position←[Index(paragraph),Index(sentence)]6 end if7 end for8 end for9 end for
算法2中Dictionary代表前述的5类标题词典;Index(·)函数的功能是返回当前对象所在列表的标号。
在上述过程中,将识别得到的各级标题整理得到两种基本类型:一是具有明显级别特征的一级、二级、三级和四级标题,分别记录于表Position_1,Position_2,Position_3,Position_4中;二是其他难以确定级别的标题,记录于表Position_0中。
通过分析《标准》的具体规定,以及给出的若干样例,分析考虑单署公文、联署公文、信函、通知、命令等各类格式的尽可能多的成文情形,以及可能出现的识别歧义情况。因此,从标点符号、缩进、句长、相对位置等方面入手,归纳建立文档描述要素的识别规则。知识结构要素的抽取算法如算法3所示。

算法 3 知识结构要素的抽取输入 赋标签的句子集Sentences输出 知识结构要素集合{密级、紧急程度、发文字号、主送机关、抄送机关、正文标题}1 for paragraph in Sentences do2 for sentence in paragraph do3 if “×密” in sentence then4 密级 ← sentence5 end if6 if “×急” in sentence then7 紧急程度 ← sentence8 end if9 if “〔 ” in sentence and “〔 ” in sentence do

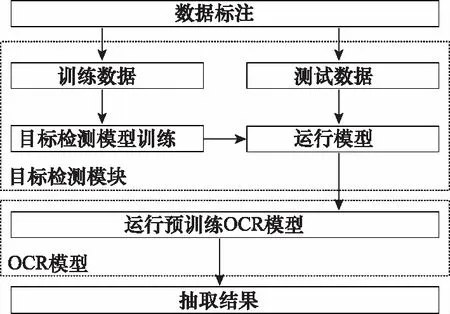
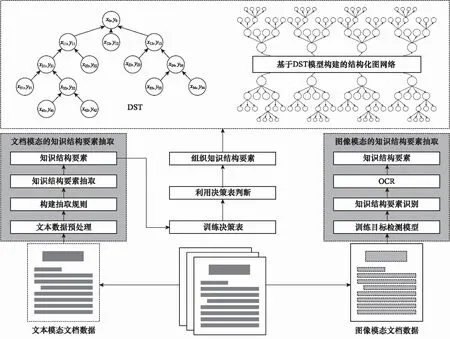
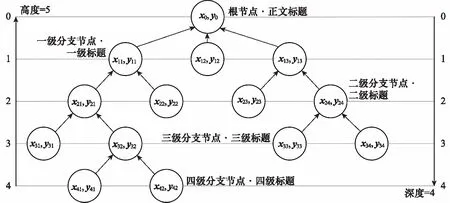
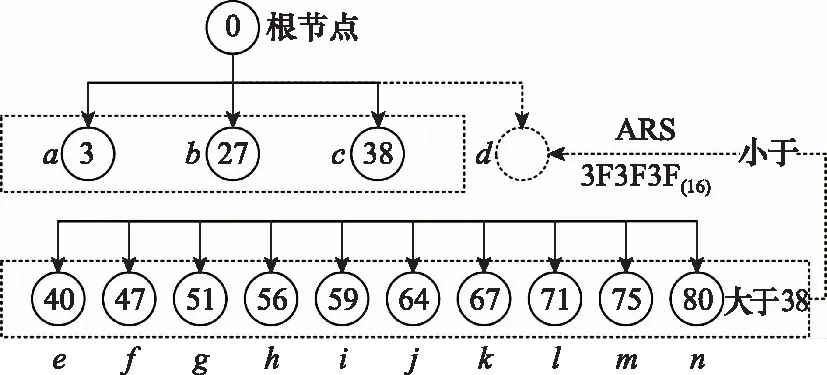
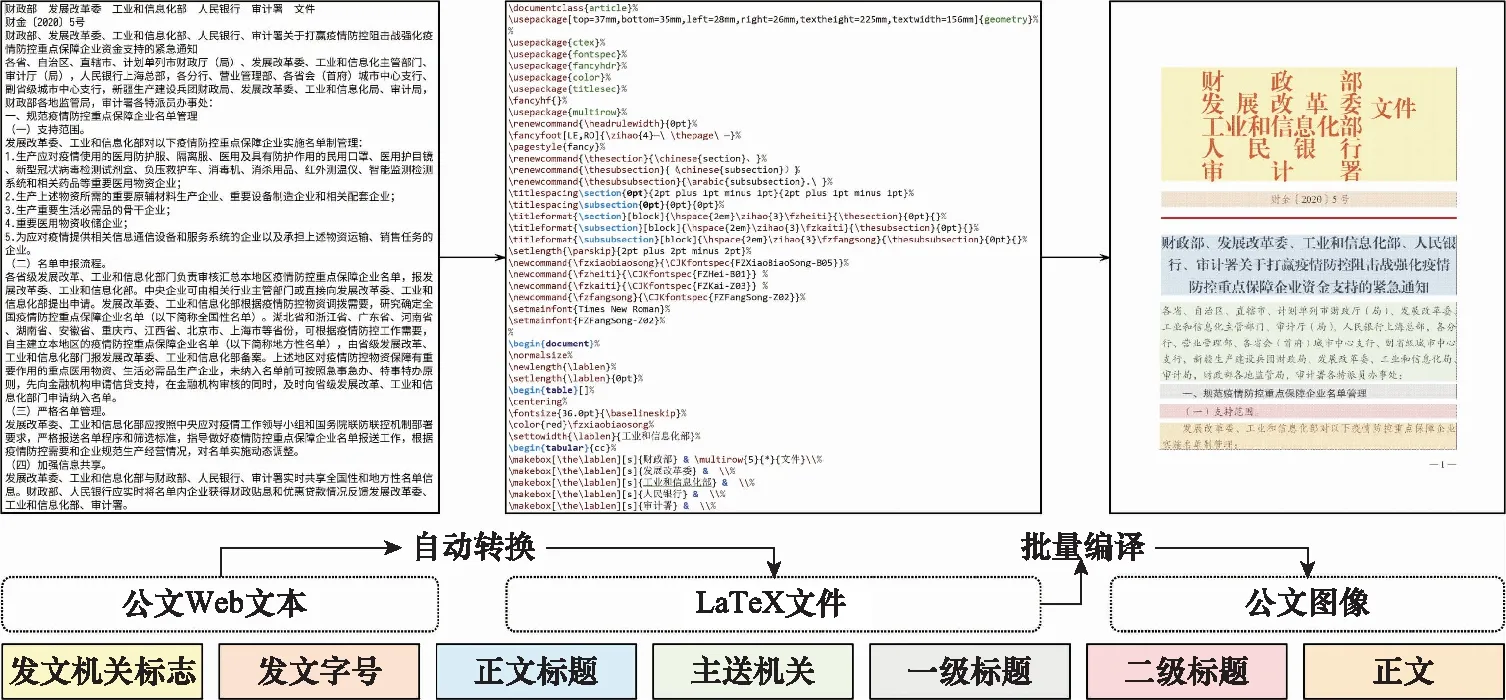
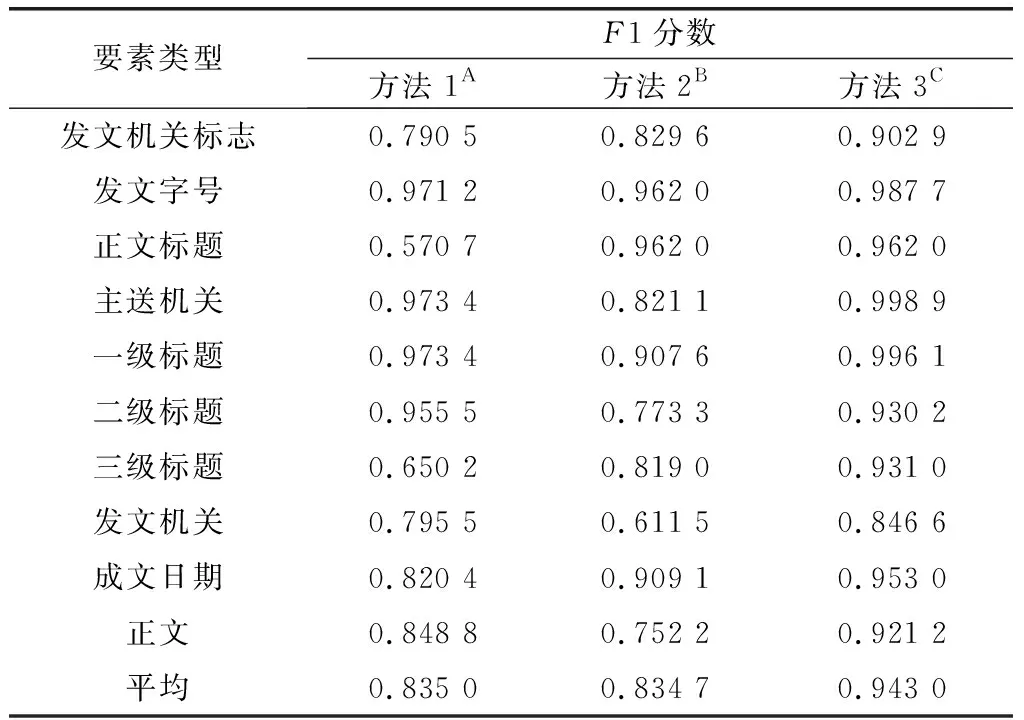
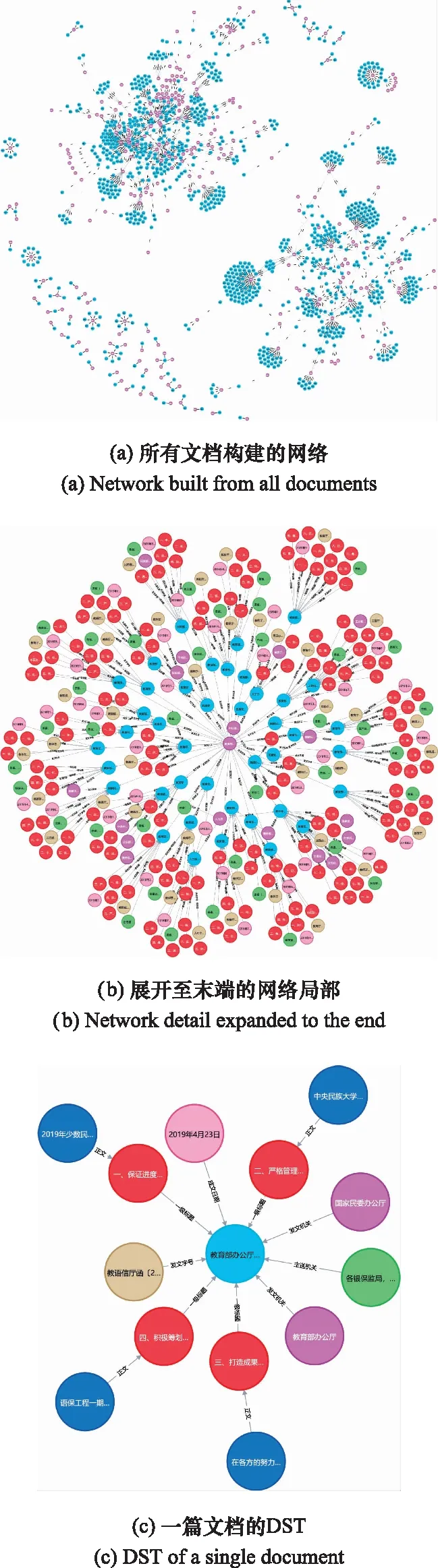
10 if “签发人:” in sentence do11 发文字号 ← sentence[: sentence.find(“号”)]12 elif sentence.endswith(“号”) do13 发文字号 ←sentence[sentence.rfind(“”)+1:]14 elif “” in sentence:15 发文字号 ← sentence[: sentence.find(“”)]16 else 发文字号 ← sentence17 end if18 end if19if (sentence.endswith(“:”) and Index(paragraph)<=8) or (“主送:” in sentence) do20 主送机关 ← sentence21 end if22 if “抄送:” in sentence do23 抄送机关← sentence24 if 发文字号 and 主送机关 do # 判断是否存在25 ifIndex(paragraph[Index(发文字号)]) 算法3中find(·)函数的功能是返回左起第一个与对象字符匹配字符的标号,endswith(·)函数的功能是判断字符串是否以对象字符结尾,rfind(·)函数的功能是返回右起第一个与对象字符匹配字符的标号,“”表示空格符。 通过前述算法构建的规则,对以句子为单位的公文字符串进行操作,即可实现对符合《标准》规定的文档知识结构要素的抽取。 人在判断所阅读的文本属于何种类别时,除了从语义上分析外,人的视觉也在文本阅读中起到了直接作用。计算机在模拟人的阅读过程时,也可以模拟人的视觉角度对文档进行分析。 在文本模态,基于规则的抽取方法依赖于规范性的文本数据,容错性能有限,尤其对于识别规则复杂的文档描述要素,在文本数据存在不规范性的情况下,所构建的规则无法保证知识结构要素抽取的准确性。同时,文档的字体、字号、文字颜色和相对位置特征无法通过文本表现出来,也就需要考虑在语义分析之外,加入视觉分析手段,以提升知识结构要素抽取的容错能力。 基于计算机视觉(computer visualization, CV)的知识结构要素抽取,是OCR与目标检测两类计算机视觉任务的组合应用。具体而言,就是先通过目标检测,判断找到要素所在区域并判断要素的类别,再从这些区域中识别出文档要素所对应的文本内容。 图1是图像模态的知识结构要素抽取模型的基本结构,该模型由目标检测模块和OCR模块两部分构成。对于图像模态的文档数据,例如文档的扫描件或PDF格式的文档,将其转化为图像处理。目标检测模块使用目标检测算法YOLO v4网络模型。YOLO v4充分借鉴了深度残差网络(deep residual network, ResNet)、稠密卷积网络(dense convolutional network, DenseNet)和特征金字塔(featur pyramid networks, FPN)的思想,在识别准确性和识别速度上都达到了目前目标检测领域的领先水平。OCR模块使用经汉字符和拉丁字符预训练的Tesseract-OCR开源识别引擎。 图1 图像模态的知识结构要素抽取模型Fig.1 Structural elements of knowledge extraction in image modal 当图像模态的文档数据输入后,目标检测模块进行多目标识别,输出图像中各目标(文档要素)的视觉特征向量=(,,,,,),其中表示目标的要素类型标签,表示目标属于该类要素的概率,,,,是目标所在位置的边界框坐标,分别表示中心点(,),宽度和高度。随后,OCR模块将根据向量中的边界框坐标分割图像区域,并按区域进行OCR识别,读出各要素的具体内容。通过上述两个模块的操作,即得到了图像模态的文档数据中知识结构要素的类型和文本内容。 由于单一模态的抽取在面对不同类知识结构要素时的效果表现存在优劣差异,因此需要从两个模态出发,同时考虑两个模态的抽取结果,补足单一模态抽取的容错性问题,以改善知识结构要素的抽取质量。 图2是基于跨模态分析的知识结构要素抽取模型的总体结构,其中两类知识结构要素抽取模型分别对两个模态的文档数据进行抽取,随后综合两类模型对不同文档要素的抽取能力,对两类模型的抽取结果进行综合考量,通过训练得到决策表,利用决策表在不同情况下择优采纳,优化知识结构要素抽取结果。 图2 多模态的知识结构要素抽取模型Fig.2 Multi-modal document knowledge structural elements extraction model 对于知识结构要素,设文本模态的抽取结果为One-Hot表示的向量_text,图像模态的抽取结果为One-Hot表示的向量_image,若文档知识结构要素的总数为,要素类别总数为,则两个模态抽取结果的所有可能组合共种。若设×2矩阵为决策矩阵,=[1,2]×2,其中每行表示一种抽取结果组合。设中第行表示“文本模态对要素的抽取结果为第类,图像模态对同一要素的抽取结果为第类”的情况,其中=×。若文本模态的抽取结果正确而图像模态的抽取结果不正确,则令1=1,2=0,反之则令1=0,2=1,若两个模态的抽取结果均正确,则令1=2=05这样,对于要素,两个模态最终的抽取结果为=1_text+2_image。经过一定样本训练后得到后,对于输入的两个模态的抽取结果(第类和第类),只需查矩阵的第×行,加权求和即得最终的抽取结果。 前文构建的知识结构要素抽取模型实现了对文档知识结构要素类别的识别,但是并没有明确要素之间,尤其是各级标题之间的并列关系和包含关系,没有形成层次性的文档结构。 从人的行文和阅读习惯出发,要解决各级标题之间的相互关系问题,仅需考虑各级标题在全文中的出现顺序。在属于“包含”关系的各级标题间,先出现的标题级别一定高于后出现的标题级别;在属于“并列”关系的同级标题间,在文中出现的先后顺序亦可反映其关系。概括地说,就是通过各级标题在文中出现的先后顺序,解决属于“包含”关系的各级标题间的分级问题和属于“并列”关系的各级标题间的排序问题。 算法1实现了将自由文本集合转换成为具有“段落标号+段内分句标号”标签结构的句子集合。段落标号越小,说明该句所在段落在前;段内分句标号越小,说明该句在段内的顺序在前。这种分句方式体现着明显的先后关系,也就为解决文本结构化问题提供了参考和依据。 树是不包含简单回路的无向或有向连通图。有根树是一个顶点被指定为根,每一条边都指向远离或趋近根的方向的树。排序有根树是每个分支节点的所有子节点按照从左至右排序的有根树。 精确子图枚举树(exact subgraph enumeration tree, ESU-Tree)是为解决网络模体识别问题所设计的结构模型。该模型用于搜索网络中指定规模的子图。由于ESU-Tree的结构设计能够较好地反映层次和结构关系,因此在ESU-Tree的基础上,本文针对文档的层次化表示问题设计了一种树形结构,该结构在本文中称为DST,如图3所示。 图3 DST模型Fig.3 DST model DST是一颗有向有根树,其特点如下: (1) 每个子代节点都指向各自的亲代节点; (2) 根节点位于第0层,全树层数为4,深度为4,高度为5; (3) 第4层全为叶子结点; (4) 节点具有权重而边没有权重,且节点权重由(前权,后权)两部分组成,比较权重时优先比较前权,前权相等时比较后权; (5) 左节点权重小于右节点,亲代节点权重小于子代节点。 将一个节点的亲代节点的同层右节点定义为该节点的右亲节点。类似地,将一个节点的亲代节点的同层左节点定义为该节点的左亲节点。 用表示亲节点,表示子节点,LP标志左亲节点,RP表示右亲节点,ST表示子树,DST表示整颗DST,RST表示相对于ST的右子树,表示标题级别,用“←”表示“赋值为”weight(·)表示节点权重。显然,分析DST的特点,可以归纳出以下3条基本性质。 在DST的任意一颗子树内,存在如下的权重关系: weight() 对DST中的任意节点node,存在∀node∈DST,∃ST⊆DST,←Root(ST),RP←Root(RST)。若weight() 对DST中的任意节点node,其层级归属满足∀node∈DST,∃,,且=+1;若min weight() DST的建立顺序和遍历顺序与中文阅读顺序一致,基本按照“根节点→相对左节点→相对右节点”的顺序进行。其建立问题可以抽象为下述的表示形式。 已知:① 部分节点(各级标题的节点)所属层;② 各节点权重。 求解:① 各节点的亲子关系;② 部分节点(其他标题的节点)归属。 根据性质1和性质2所述规则,通过比较节点权重的大小关系,可以完成各级节点之间并列和归属关系的确定。需要注意的是,在比较权重时,应当按照定义,优先比较节点的前权,也即节点标签的第一个坐标值,当前权相同时,再比较第二个坐标值。 实际上,一个DST就是结构化知识网络的一个子网,或是知识结构要素图谱(网络)中的一个子图。在大量文档数据支持的情况下,结合主题识别和关键词抽取,通过DST(文档子图)的聚类,就具备了构建大规模文档知识网络的基础。 使计算机实现对文档知识结构要素的组织,需要考虑对前述DST模型的数据结构进行设计。而进行设计的主要问题是要在计算机中实现“亲节点<子节点<右亲节点”的关系判定。要完成这一任务,需要从左至右、自顶向下地访问每个节点,判断左右级、上下级节点(子树)之间的并列和包含关系。 对于不等式“亲节点<子节点<右亲节点”,考虑条件不完备的情况,由于采用自顶向下遍历,因而亲节点一定在子节点之前得到访问,即不等式左端一定成立,故仅需考虑右端条件不完备的情况,即右亲节点(右子树)不存在的情况。 显然,若采用分类讨论方法,单独为右亲节点不存在的情况追加补充规则的成本较高,因此,考虑构造使得不等式右端恒成立的条件以适应原规则,而非建立新规则。为此引入绝对右子树(absolute right subtree, ARS)的概念。 ARS是根节点权重为充分大数,子节点为空的DST。其实际上是所在层最右端的一个权重充分大的叶子节点,只参与权重比较,但不会被访问。 由于第4层属于四级标题项,均为叶子结点,子树为空,因此仅需在第1、2、3层建立ARS。并且,通过设置遍历条件,可以使得ARS参加权重比较而不被访问,这就解决了右亲节点不存在的情况。 例如,图4所示的节点权重是2019年政府工作报告的文档结构要素所建立的DST的一部分。显然,对于节点的所有子节点到,都没有右亲节点,而使得性质1不再成立。为了确保性质1恒成立,则weight(ARS)应当是一个充分大数。本文将16进制数0×3F3F3F3F设置为该充分大数,该数值既避免了数据溢出,又与32位整型数据最大值0×7FFFFFFF同处于10量级。由于ARS的引入,使得子节点到的右亲节点成为了,权重为充分大数0×3F3F3F3F;而其左亲节点的权重为38;进而使不等式38 图4 ARSFig.4 ARS 因此,DST的最小数据单元就是一个包含根节点属性和所有子节点属性的结构体,并通过递归定义,即可实现DST的构建。 在VRDA任务中,目前已经公开的单模态和多模态数据集主要集中在商业文档和科学文献数据上。文献[29]构建了一个图像模态的大规模文档数据集PubLayNet,文献[30]构建了一个多模态的科学文献数据集DocBank。文献[31]和文献[32]中分别使用了各自获得的图像模态公文文档,但并没有将数据公开。因此,目前针对公文的公开多模态文档数据集仍是一个空白。 为了填补多模态公文文档分析任务中的数据空白,并验证本文提出模型的有效性,本文从国务院政策文件库以网页文本格式获取公文文档,经数据清洗后,设计符合《标准》规定的LaTeX模板并将无格式的网页文本批量排版编译为PDF文档,随后转换为图像模态的文档数据。本文将构建的多模态公文文档数据集命名为GovDoc-CN,并将该数据集开源发布。流程如图5所示。 图5 GovDoc-CN数据集的数据处理流程Fig.5 Data processing flow of GovDoc-CN 本文共标注了6 816个文档页面,“发文机关标志、发文字号、正文标题、主送机关、一级标题、二级标题、三级标题、发文机关、成文日期和正文”10类共29 942个文档知识结构要素。数据集统计信息如表4所示。 表4 数据集统计信息 本文中基于计算机视觉的文档要素实体抽取,将YOLO v4模型的学习率设置为2e-5,Batchsize设置为64,迭代次数26 000,训练集包括4 090个文档页面,验证集包括2 045个文档页面,测试集包括690个文档页面。 为评价模型的抽取效果,用TP表示“实际为正例,预测为正例”的数量;用FP表示“实际为负例,预测为正例”的数量;用FN表示“实际为正例,预测为负例”的数量;用TN表示“实际为负例,预测为负例”的数量。 于是,定义模型的精确率为 Precision=TP/(TP+FP) (1) 定义模型的召回率为 Recall=TP/(TP+FN) (2) 模型的精确率反映了模型预测结果的准确性,因此也称查准率。模型的召回率反映了模型预测全面性,因此也称查全率。 为了使用一个综合考虑“查准”与“查全”的指标,本文使用1分数评估抽取模型的效果,其计算方法为 (3) 在同一测试集下,基于规则的知识结构要素抽取方法和基于计算机视觉的知识结构要素抽取方法取得的结果如表5所示。 表5 知识结构要素抽取结果 在表5中,A表示方法1为基于规则的抽取方法;B表示方法2为基于计算机视觉的抽取方法;C表示方法3为方法1与方法2的组合运用。 通过表5可知,基于规则的抽取方法(文本模态)和基于计算机视觉的抽取方法(图像模态)在知识结构要素抽取上的效果表现互为补充。在1分数表现上,多模态抽取方法相比文本或图像单一模态的抽取方法分别提升了10.80%和10.83%,各类要素的抽取效果也为最优,证明了本文所提出的多模态文档知识结构要素抽取方法的有效性,与单一模态的抽取方法相比具有明显的效果提升。 本文从GovDoc-CN数据集中随机选择了1 000篇公文文档,利用第2节提出的知识结构要素组织方法,将每篇文档抽取的知识结构要素组织形成DST,再将DST利用“发文机关”建立文档关联,最后存储至Neo4j数据库中,得到了如图6所示的结构化文档知识网络。该网络共包含22 377个节点(要素实体), 22 621条边(要素实体间关系)。 利用图数据库管理系统,可以对构建的结构化知识网络进行管理。例如,用户使用Cypher语句: MATCH (:发文机关{name:“科技部”}) RETURN 其中,为“发文机关”。即可查询到图7所示的共33篇科技部发文。类似地,利用Neo4j等图数据库管理系统,可以通过创建、删除、合并实体和关系等操作,实现对结构化知识网络中结构要素实体以及它们之间关系的管理。 图6 大规模DSTs构建的文档网络Fig.6 Document network built from large scale DSTs 图7 以“科技部”为关键词检索到的文档Fig.7 Documents retrieved with the keyword “Ministry of Science and Technology” 综上所述,本文通过对文档知识结构要素的抽取、组织和管理设计并进行实验,证明了本文提出的多模态抽取方法的有效性;通过构建公文文档的结构化知识网络,分析了本文提出的DST模型在知识组织和管理方面进行应用的可行性和有效性。 本文以公文为例,提出了从多模态文档中抽取知识结构要素并组织生成结构化知识图的方法。在文本模态,本文针对公文文档的拟制标准和行文特点,提出了公文知识结构要素的抽取规则,实现了对公文文档中知识结构要素的抽取。在图像模态,本文利用目标检测和OCR方法,对基于规则抽取方法的短板弱项进行补足。同时,本文提出了一个多模态文档知识要素抽取框架,利用决策表实现多模态知识结构要素抽取结果的择优。经实验验证,多模态抽取方法在1分数上从单一模态的0.835 0和0.834 7提升到了0.943 0。同时,本文提出了DST模型,按照文档的结构逻辑实现了对知识结构要素的组织,并将得到的结构化文档输入图数据库进行管理。实验结果证明,本文提出的知识结构要素抽取与组织方法具有良好的效果表现,在解决目前基于三元组知识构建的知识网络结构逻辑性弱的问题,以及文档智能问答、公文自动化管理等方面具有重要的研究和应用价值。1.2 图像模态的知识结构要素抽取
1.3 多模态知识结构要素抽取
2 公文知识结构要素的组织
2.1 公文知识结构要素组织问题分析
2.2 公文知识结构要素组织的数学模型
2.3 公文知识结构要素组织的数据结构
3 多模态公文数据集构建

4 实验与分析
4.1 公文知识结构要素抽取
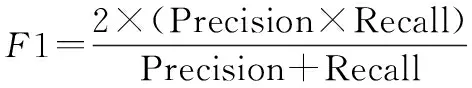
4.2 公文知识结构要素的组织与管理

5 结 论
