基于PCA及Elamn神经网络的财务困境预警
2022-05-30康亮河林雨蔚朱莉莉王雲慧袁敏
康亮河 林雨蔚 朱莉莉 王雲慧 袁敏


摘要:企业是市场的重要参与主体之一,而财务是各个企业的重要运营支撑,在新冠肺炎疫情所带来的压力下,市场风险逐渐扩大,随时出现的财务困境成为企业所面临的最大挑战。该研究选取2020年157家被特别处理的上市公司(Special Treatment, ST) 和157家非ST上市公司的19个指标为研究对象,对公司的财务状况进行预测和分析构建了Elman神经网络预测模型。实验结果表明: RBF、BP及SVM模型的准确率具体数值为14.28%、9.52%、7.93%,而Elamn模型预测的分类准确率是85.71%,说明研究提出的Elman预测模型在财务困境的预测中具有较强的预测能力,可以为企业机构做出正确的决策提供指导意义。
关键词:Elamn神经网络;均值插补法;PCA算法;财务困境
中图分类号:TP391.1 文献标识码:A
文章编号:1009-3044(2022)31-0011-03
1 引言
财务困境是指公司在经营过程中财务状况严重恶化、债务违约甚至面临破产风险的状况[1]。随着经济生活国际化发展,中小企业在推动我国经济增长和社会进步中发挥着愈来愈重要的作用,但自2020年以来,新冠肺炎疫情下的中小企业在经营状况远不如前,停工停业,物流受限,原料成本上升供应不足等种种原因导致亏损运营[2],因此,寻找合适的财务困境预警模型,使公司能够及时应对或者规避可能发生的财务风险,对企业自身、公司股东及利益相关者具有重要意义。
2008年6月以来,国际金融危机对市场的巨大冲击使得人们愈发重视财务困境。Altman[3]提出构建Z-Score模型,利用多项指标来分析和预测企业的财务状况;1980年开始,随着机器学习的快速发展,决策树、随机森林及神经网络在财务困境预警领域得到了广泛的使用,李晓静[4]等人不仅逻辑回归模型在财务困境预测研究领域中的实际应用,同时利用Logistic模型对我国上市公司财务报表进行了分类和预测,据此取得了良好的预测;张春华[5]等人根据t-1年与t-2年的面板数据,构建了SVM多分类模型,将企业划分为财务健康公司、财务亚健康公司和财务困境公司三类;西凤茹[6]等人以制造业上市公司为研究对象,构建了基于遗传算法的BP神经网络,并与logistic、PCA及BP神经网络算法进行了对比,发现优化后的BP神经网络预测准确率明显提高。
2 主要算法介绍
2.1 均值插补法
对于缺失值最简单的处理方法便是删除,如果直接删除将会影响分析结果或者建模的准确率,所以对于特定的数据一般不直接删除,可采用插补法进行填补,其中均值插补法是最常用且插补精度较高的一种插补算法。均值插补是利用样本数据平均值或众数替换数据变量中的所有缺失值(NA) ,从而在含有缺失值的数据上集中形成一组完整的数据[7],均值插补的插补值的计算公式为:
[y=i=1nβiyini] (1)
其中,[βi]为是否回答的描述符号表示,[βi=1]表示“是”,[βi=0]表示“否”,[ni]是个数。
2.2 PCA算法
PCA即主成分分析是常用的特征属性分析、数据降维方法,PCA 算法利用数据的相关性,从线性相关到线性无关,从高维数据降到低维数据,实现数据降维的同时剔除数据相关性,称低维数据变量为主成分[8]。通过主成分分析算法对指标变量进一步地提取,筛选出重要财务指标作为建模属性,完成数据预处理阶段的工作,并为后续模型的建立提供可靠的数据集。本文利用 PCA 算法旨在选出比原始财务指标个数少,且能解释和代替原始财务指标的主成分,对原始财务指标进行替代作为建模特征。主成分分析的计算步骤如下:
1) 设原始变量[x1],[x2]…,[xp]的n次数据矩阵[X]为:
[X=x11x12...x1px21x22...x2p........xn1xn2...xnp] (2)
2) 将该矩阵按列中心标准化。标准化的矩阵定义为[rij]:
[rij=k=1nxki-xixkj-xjk=1nxki-xi2k=1nxkj-xj2] (3)
其中[rij]=[rji],[rii]=1,r为实对称矩阵。
3) R为相关系数矩阵,[R=(rij)p*p],求出R的特征方程[detR-λE=0]的特征根[λ1≥λ2≥λp>0](特征根越大说明该指标越重要)。
4) 确定主成分个数m,累计方差贡献率[?]依据实际情况而定,一般情况下(≥80%或≥85%) 取值80%。
[i=1mλii=1pλi≥?] (i=1,2,…,p) (4)
5) 计算[m]各相应的单位特征向量:
[β1=β11β21..βp1, β2=β12β22..βp2,... β3=β1mβ2m..βpm] (5)
6) 计算主成分,上市公司的综合值(特征值大于1为标准提取主成分),并对其进行降序排列:
[Zi=β1iX1+β2iX2+...+βpiXp] (6)
2.3 Elman神经网络
Elman 神经网络属于动态递归神经网络,通过存储内部状态使其具备映射动态特征功能,系统因此具有适应时变的特性,增强了网络的全局稳定性,Elman神经网络为4层结构,包括输入层、隐含层、承接层和输出层,其中承接层可以自动保存隐含层中的状态信息,所以网络層处理动态消息能力相对较为优越[9]。Elman 神经网络的输入层、隐含层和输出层表示形式分别如下式中:
[xit=xipmt=Ppmpm=ivi,mxit+mp?mtyjt=mvm,jpmt] (7)
[t]时刻第 [i] 个神经元的输出值为[xit],第 [m] 个神经元的输出值是[pmt];[P] 为激活函数;输入层第 [i]个元的输入值为 [xi],第 [m]个神经元输入值是[pm] ;[vi,m] 为输入层到隐含层的权值;[p?mt]为承接层输出值;输出层第 [j]个神经元的输出值为[yjt];[vm,j]为隐含层到输出层的权值。
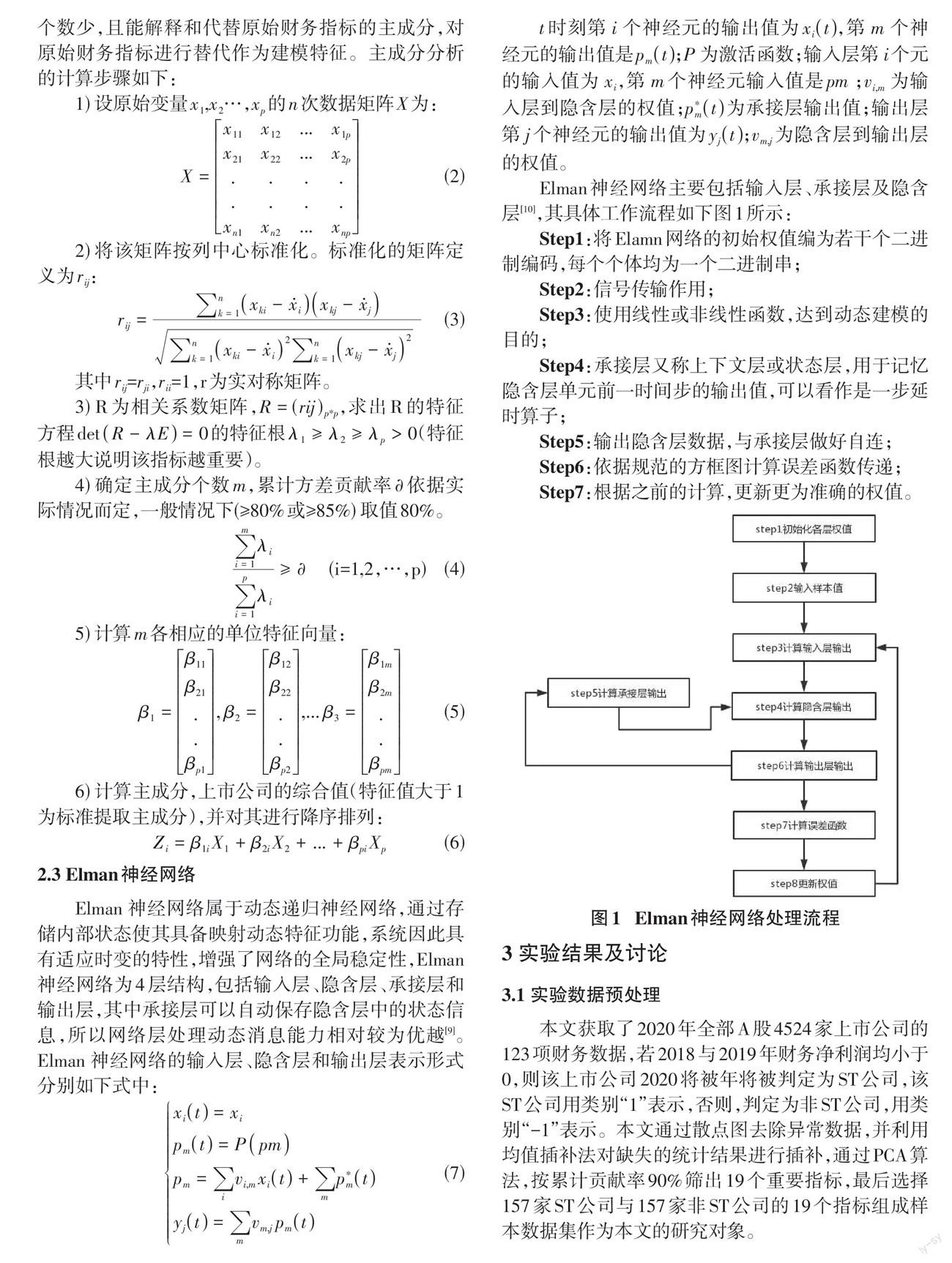
Elman神经网络主要包括输入层、承接层及隐含层[10],其具体工作流程如下图1所示:
Step1:将Elamn网络的初始权值编为若干个二进制编码,每个个体均为一个二进制串;
Step2:信号传输作用;
Step3:使用线性或非线性函数,达到动态建模的目的;
Step4:承接层又称上下文层或状态层,用于记忆隐含层单元前一时间步的输出值,可以看作是一步延时算子;
Step5:输出隐含层数据,与承接层做好自连;
Step6:依据规范的方框图计算误差函数传递;
Step7:根据之前的计算,更新更为准确的权值。
3 实验结果及讨论
3.1 实验数据预处理
本文获取了2020年全部A股4524家上市公司的123项财务数据,若2018与2019年财务净利润均小于0,则该上市公司2020将被年将被判定为ST公司,该ST公司用类别“1”表示,否则,判定为非ST公司,用类别“-1”表示。本文通过散点图去除异常数据,并利用均值插补法对缺失的统计结果进行插补,通过PCA算法,按累计贡献率90%筛出19个重要指标,最后选择157家ST公司与157家非ST公司的19个指标组成样本数据集作为本文的研究对象。
本文采用分类准确率、第I类错误率及第Ⅱ类错误率指标来评估分类模型[11],对其定义如下:
[Accuracy=TP+TNTP+TN+FP+FN×100%] (8)
[Type Ⅰ error=FPFP+TN×100%] (9)
[Type Ⅱ error=FNTP+FN×100%] (10)
其中,TP、TN、FP及FN分别表示真正例、真负例、假正例及假负例,即表示正常公司被正确分类的数量、ST被正确分类的数量、ST公司被分为正常公司的数量及正常公司被分为ST公司的数量。
3.2 参数设计
在Elman算法中,利用激活函数[tansig(x)=2/(1+exp(-2x))-1] 计算隐藏层 ,[purelin(x)=x]计算输出层,隐藏层个数用经验公式 [m=n+l+?]计算,其中用 [n]、[l]、[?] 分别表示输入层个数、输出层个数和[1~10] 之间的常数,经测试,预测误差最小时 [m=21],最大训练次数为100,误差目标为0.0001,学习率为0.1。
3.3 实验结果及讨论
1) 预测结果
本课题采用314家A股上市公司作为研究对象,以251家公司的财务数据为训练集,以剩余63家公司作为测试集。Elman神经网络预测模型以通过PCA算法所获得的19个指标数据作为基础数据构建,对预测结果进行统计分析,得到结果如图2所示。
图2表示,在被选择用来预测的63家公司中有33家公司因财务困境而被特殊处理变为ST股,剩余30家公司显示财务正常,在Elman预测模型对63家公司财务状况进行预测的研究结果中,30家公司面临财务困境,财务正常的公司有33家,其中Elman预测正确了54家公司的财务状况与实际数据对比分析得出,Elman神经网络预测模型的预测准确率为85.71%。
2) 预测结果分析
为进一步分析Elman神经网络预测模型,本文将 SVM、BP和 RBF神经网络算法模型的各项指标值进行了比较。各模型的预测结果如表1所示。
从上表中可以看出,采用Elman算法进行建模预测的63个结果值中,共有54家公司分类正确,有6家ST公司被分为了正常公司,有3家正常公司被分为了ST公司,即第Ⅰ类误差数量是4,第Ⅱ类误差数量是3;依次分析得:RBF模型预测结果中,有45家公司分类正确,第Ⅰ类误差数量为3,第Ⅱ类误差数量为15;BP模型预测结果中,48家公司分类正确,第Ⅰ类误差数量为8,第Ⅱ类误差数量为7;SVM模型预测结果中,有49家公司分类正确,第Ⅰ类误差数量为7,第Ⅱ类误差数量为7。
从以上的分析对比中可得出:Elman算法在财务困境的预测中,准确率最高,第Ⅰ类及第Ⅱ类错误数最少,因此,本文所构建的Elman神经网络预测模型对公司应对或规避财务风险更具有合理性和可靠性。
3) 预测误差分析
笔者对各模型分别进行了10次运算,并对预测结果取均值,计算出Elman算法与各对比算法的准确率、第Ⅰ类及第Ⅱ类错误率,结果如表2所示。
经过计算Elman算法的准确率85.71%,第Ⅰ类错误率为9.68%,第Ⅱ类错误率为16.67%;RBF算法准确率、第Ⅰ类及第Ⅱ类错误率分别为71.43%、14.29%、35.71%;BP算法准确率、第Ⅰ类及第Ⅱ类错误率分别为76.19%、22.86%、25%;SVM算法准确率、第Ⅰ类及第Ⅱ类错误率分别为77.78%、27.78%、26.92%。
对比分析可得,Elamn算法的各项指标都明显优于其他模型且优势显著,最終从中选择最优算法Elamn算法预测模型,可有效地发现并预警企业的财务问题,尽早地甄别问题、解决问题。
4 结论
本文以2020年A股上市公司的财务数据为研究对象,通过散点图及均值插补法对数据集中的异常值及缺失值进行处理,利用PCA算法筛选出重要属性以降低属性集的复杂度,构建Elman神经网络预测模型,对公司的财务状况进行预测和分析,以251家上市公司的财务数据为训练集,通过RBF、BP、SVM等多个预测模型对63家公司的财务状况进行了测试对比与分析,进一步证明了该模型的可靠性和有效性,于是得出最终结论:基于PCA算法的Elman神经网络模型对公司的财务困境预测具有较高的准确率,可作为企业应对或规避风险的有效方法。
参考文献:
[1] 陈辉远,姜慜喆,冯家兴.基于集成算法的上市公司财务困境预警模型[J].武汉理工大学学报(信息与管理工程版),2022,44(3):468-477.
[2] 梁创维.基于财务状况多分类的财务困境预警研究[J].现代商业,2021(30):169-171.
[3] Altman E I.Financial ratios,discriminant analysis and the prediction of corporate bankruptcy[J].The Journal of Finance,1968,23(4):589-609.
[4] 李晓静,聂广礼,曾婧.Logistic方法在财务困境预测中的应用[J].中国管理信息化,2009,12(15):124-126.
[5] 张春华,卢永艳.基于SVM多分类模型的上市公司财务困境预测[J].中国管理信息化,2014,17(4):2-5.
[6] 西凤茹,时文超.基于遗传算法和神经网络的上市公司财务困境预测[J].辽宁科技大学学报,2013,36(2):166-171.
[7] 周青,张青松.基于Elman神经网络的客流量预测方法应用[J].数字技术与应用,2022,40(8):19-21.
[8] 郝婧,劉强.基于改进ELman神经网络的台风风暴潮损失测度[J].中国海洋大学学报(自然科学版),2022,52(8):71-76.
[9] 徐鸿艳,孙云山,秦琦琳,等.缺失数据插补方法性能比较分析[J].软件工程,2021,24(11):11-14,10.
[10] 高楠,刘晶,郑培.基于PCA-Elman-PSO算法的动力电池低温充电优化[J].汽车文摘,2022(1):24-30.
[11] 朱昶胜,田慧星,冯文芳.基于Adaboost算法结合DEGWO-SVM的财务困境预测[J].兰州理工大学学报,2021,47(6):100-107.
【通联编辑:李雅琪】
收稿日期:2022-04-11
基金项目:甘肃省农业大学盛彤笙科技创新基金(GSAU-STS-2021-15) 2022年甘肃农业大学研究生教育研究项目(2020-19) ;甘肃农业大学大学生创新创业训练计划项目(项目编号:202216041)
作者简介:康亮河(1987—) ,女,甘肃会宁人,助教,研究方向为人工智能算法;林雨蔚,本科生,研究方向为数据科学与数据管理。
