基于CNN和超声传感的手势识别及辅助身份认证
2022-05-18张梦欢王亚刚
张梦欢, 王亚刚
(西安邮电大学 计算机学院,陕西 西安 710061)
0 引 言
手势是人机交互的重要方式,手势识别是许多移动应用的基础,并且正在成为新应用领域的重要技术。手势密码被广泛应用于公共设施,公寓楼和智能家居的访问控制。但是,由于目前的认证方法(例如,PIN和密码)存在被非法用户泄漏和盗取,因此这种认证方法提供的认证功能较差。围绕摄像机或基于指纹的技术构建的替代身份验证解决方案也不理想,不仅部署和维护昂贵,容易遭受各种攻击[1]。目前,用于活动识别的无线技术最新突破[2]使现在的工作成为可能。在无线传感技术中,它只需使用麦克风和扬声器即可轻松部署声音感应,而且无需用户佩戴其他硬件设备,与其他基于基础架构的解决方案(例如,视频监控[3])相比,它对隐私的干扰较小。经典的用户身份验证方法包括基于文本[4]和基于图形的密码[5]。但是,由于任何人都将身份验证密码视为密码的合法用户,因此,这些方法容易遭受身份验证密码的泄漏。目前还有一些身份验证方法包括访问智能卡[6]、指纹[7]和面部识别[8]等,这些认证方法效果虽然比较好,但还存在一些问题,它们部署相对比较昂贵,并且获得用户生物信息还遭受各种攻击。
近年来,WiFi已经成为感知信息的强大媒介,通过测量无线信道如何受人类活动的影响,可完成诸如步态识别[9]、手势识别[10]等。目前,WiFi技术也开始支持捕获用户输入。例如,通过测量了手指触摸导致的物理振动[11]如何变化,捕获不同表面上的用户输入,这些方法涉及昂贵的成本。还有其他方法可以对用户进行身份验证[12],多数情况下是根据生物特征信息来检查用户的合法性。基于生物信息的用户身份验证和识别方案包括指纹[7]、面部[8]和步态识别[9],已被广泛使用并受到关注,但生物特征识别认证涉及用户隐私问题。
针对上述问题,本文提出了一种新的用户密钥访问技术,利用声音频率的选择性衰减进行活动识别,提供一种验证用户是否为认证密钥所有者的方法,不需要采集用户的生物信息,是一种低成本的辅助身份验证系统。其中,包括了手势检测和目标识别的算法。手势检测算法基于动态能量阈值,当检测到手势时,通过能量阈值分割出手势动作。对于目标识别,利用声音信号的频率选择性衰减和多径效应捕获不同用户手指运动的独特属性,然后使用卷积神经网络(convolutional neural network,CNN)提取信号来完成这项工作,并进一步使用支持向量机(support vector machine,SVM)模型将信号特征映射到已知的用户手势输入动作,准确地判断用户的输入并能够验证不同的用户,提高了用户手势识别的准确率。
1 背 景
类似于信号在无线传输的过程中,超声波信号穿过介质时,由于两者相互作用,当在无线设备的发送端和接收端(扬声器和麦克风)之间产生手势动作,会导致传播信号发生反射/衍射。其中,部分声音信号反射,部分信号则经过多径效应进行传播,到达接收端。此外,在多径效应下,信号传播的时间沿着不同的路径变化。因此,麦克风接收的声音信号是通过多个延迟信号组成的。
信号通过信道传输后,信号的每个频率分量的变化不一致,当手指在信号发送和接收端间运动时,动态手势改变了信道的传输函数,引起声音信号的频率选择性衰减,使信道频域上的能量发生改变。用户静止时,信道频域上的能量基本保持不变,当用户的手在发送端和接收端的信号传输区域内运动时,信号传输路径发生变化,信号进行反射/衍射,使得信道频域上的能量产生变化。
2 系统概述
2.1 系统操作流程
移动设备的内置扬声器发出调制的高频声信号,然后由内置麦克风捕获并记录其回声信号。然后,对麦克风记录的原始声音信号进行预处理,提取特征信号,然后使用提取的信号特征值来进行手势识别。系统基本流程图如图1所示。

图1 操作流程
接收超声信号,将动作对高频信号的影响作为输入。数据收集完成后对数据进行预处理,去掉声音信号首尾没有动作的数据,使用巴特沃斯滤波器进行去噪,然后通过阈值来截取部分动作,并对截取后的数据进行特征提取。基于短时傅里叶变换(short-time Fourier transform,STFT)的特性,利用傅立叶变换将时域信号转换为频域信号,并及时对快速傅里叶变换(fast Fourier transform,FFT)后的每一帧的频域信号(频谱图)进行叠加以获得声谱图,STFT功能可以很好表示随时间变化的信号频率。在认证部分中,使用提取的频谱图对模型进行训练,对于同一动作,经过训练后,训练后的结果将用作SVM分类器的输入,以识别和认证,确定输入动作是什么,并确定合法用户。
2.2 预测建模
信号调制过程中,选择序列调制,将指定的信号序列调制到固定的频率载波上形成带宽信号。为了避免出现其他频率的噪音,使用带通滤波器对调制信号进行带通滤波,留下需要带宽信号。
收集声音信号数据后,将原始声音信号数据进行读取,并用阈值方法截取声音信号,再用巴特沃斯低通滤波器进行滤波。然后直接提取高频特征,获得信号的STFT时频关系。STFT的窗大小为1 024,重叠大小为512,每1 024个点做一次FFT,可以得到信号的频谱图。同时进行灰度处理,将3通道的彩色图处理成单通道的灰度图,达到数据压缩的目的降低训练CNN模型的时间。
当手在移动的过程中,声音传输时的多径会随着手的移动产生变化,在每一个时间点获得超声波的频率衰减时,这些频率衰减就形成一个频率衰减曲线(FAP),FAP就可以看成是一个手势动作的图像。图2是写字母“A”,数字“8”和手势“手势3(逆时针圆圈)”时的STFT。不同字母,数字和动作的笔触不同,输入不同动作会对信号频率产生不同的影响,对应的提取STFT后,不同频率的信号有不同的影响效果,最终不同动作的频谱图也不同。

图2 不同动作的频谱图
预处理后的信号特征作为CNN的输入进行手势识别[13]。对于CNN模型[14],网络结构每层依次为Conv2D(作为输入层),Maxpooling2D,Conv2D,Maxpooling2D,Dropout,Conv2D,Conv2D,Conv2D,Maxpooling2D,Dropout,Flatten,Dense,Dropout,Dense,Dropout,Dense(class,activation=’softmax’),卷积层的卷积核大小依次是8×8,6×6,3×3,3×3,3×3,最大池化层的池化大小依次是5×5,4×4,4×4。其中,Dropout层是为了避免模型过度拟合。然后通过Flatten层将中间层的输出绘制为一维矢量,以便将其输入到全连接层,两个全连接层进一步调整网络中的权重。最后一个全连接层中,SoftMax激活函数用于输出分类标签,以便以后与其他分类器进行比较。此CNN模型中使用的激活函数为tanh,尽管ReLU激活功能当前在图像领域中更为常用,在测试数据后,tanh的激活功能可以更好地对目标任务进行处理。在模型训练过程中,当迭代次数设置为2 000时,结果是稳定的。
辅助认证过程中,不同类型的分类器效果不同。选择了8个不同的分类器来训练数据。8个分类器是逻辑回归(logistic regression,LR)、SVM、K最近邻(K nearest neighbour,KNN)、决策树高斯朴素贝叶斯(Gaussian naive Baye-sian,GNB)分类器、随机森林(random forest,RF)、梯度提升(gradient boosting,GB),并直接使用CNN识别。经过测试,最终选择了CNN+SVM进行辅助身份验证,此时SVM中采用线性核函数。
3 系统实施与评估
为了分析和评估系统的性能,邀请了33名志愿者参加实验数据的收集,使用魅蓝Note6手机进行系统性能测试。志愿者根据各自的行为习惯输入手势动作。
采集环境:1)安静环境:数据采集过程中,没有其他噪音干扰; 2)噪音环境:当志愿者执行手指手势输入时,播放高达80 dB的噪声。
收集的数据集:33名志愿者在安静的环境和受噪声干扰的环境中接收26个大写字母,0~9个数字,4个手势[11]以及连续的动作。以下通过不同动作,不同噪声环境和不同距离来分析系统识别和验证的准确性。
3.1 基本手势动作评估
3.1.1 评估单独的动作
志愿者书写26个大写字母(确保33名志愿者在同一场景下收集实验数据,方便后续的数据处理和实验结果的验证)。大多数动作的识别准确度均在96 %以上,部分动作识别准确度达到100 %。如图3所示,对于三种不同的动作,平均识别准确率达到96 %以上。

图3 26个大写字母识别准确率
3.1.2 环境噪声的影响
具体的数据收集是志愿者在安静的环境和音乐噪音为80 dB的环境中收集数据。如图4显示单独动作和连续动作在两种环境下的身份验证准确率。
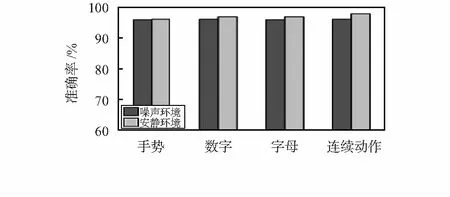
图4 不同环境识别准确率
3.1.3 不同距离的影响
用户收集实验数据时,评估用户手指手势与麦克风之间的距离。测试了4个距离段,分别在距麦克风0~5,5~10,10~15,15~20 cm书写26个大写字母,0~9个数字和4个手势[11],验证距离是否会影响系统的身份验证准确性。如图5所示,随着手离麦克风越来越远,识别准确率降低。因此,在随后的辅助认证数据收集中,要求志愿者手和麦克风的距离保持在15 cm以内,用户进行手势输入。

图5 不同距离识别准确率
3.2 用户身份辅助认证
为了更好地应用于现实生活中,实验环境位于日常工作办公室中。招募了15名志愿者进行合法的用户身份验证,在3个月内完成了实验数据的收集。收集实验数据之前,向每个志愿者详细解释了实验测试动作。
3.2.1 数据量统计
1)单独动作:对于15位志愿者,本文要求根据写作习惯书写26个大写字母,0~9个数字和:4个手势。每个动作重复30次,对志愿人员没有任何限制。写入过程中收集的数据总量为18 000(40×30×15)。
2)连续操作密码:上述40个动作中,随机选择4个密码组合,找到4组随机组合的密码进行数据收集,并且在书写过程中对志愿者的行动规模没有限制。收集的总数据为1 800(4×30×15)。
3)从一些志愿者处收集其他数据,包括不同的材料,不同分类器等,以测试系统的性能。
3.2.2 用户验证准确性结果
1)15名志愿者对26个大写字母,0~9位数字和4个简单手势进行用户身份验证和识别。如图6所示,不同的身份验证用户,不同动作的准确性存在差异,字母验证的准确性优于数字和手势,因为动作越复杂,用户在捕获过程中获得的特征信息越多。因此,识别和认证的效果也更好。

图6 不同动作的用户认证
2)不同材料的用户辅助认证,对于不同的材料表面,主要选择对硬材料(例如木材)和软材料(例如硅胶)执行用户身份验证。6名志愿者在两个材料表面上输入手势。如图7所示,软材料略低于硬材料的认证准确率,但两者都在96 %以上,并且可以有效地对用户进行身份验证。

图7 不同材质的用户辅助认证
3)系统通过CNN模型训练,并使用SVM进一步分类识别。比较了7种分类器的性能,包括LR,SVM,KNN,DT,GNB,RF和GB。图8显示了当用户输入26个大写字母,0~9个数字和手势时,不同分类器的识别精度,可以看出,使用SVM进行分类认证的准确性略高于其他分类器,SVM分类的准确性超过96 %。

图8 不同分类器的识别准确率
4 结 论
本文构建了一种智能用户访问模型,使用超声波检测来提高用户使用指纹和其他生物识别技术的安全性。基于频率选择性衰减和在空中传播的声音信号的多径效应,通过发送固定的高频信号,捕获动作以提取STFT特征;然后使用神经网络进行训练,可以对用户的手势进行识别。为用户提供3个不同的独立密码(4个简单手势,大写字母,数字)和一种连续密码,将保存的频谱图作为CNN的输入,CNN可以执行为每个用户建模训练,并使用SVM进行用户分类身份验证。在Android系统的手机上实施了该系统,结果表明:该系统对用户的手势识别及身份认证可以达到96 %以上的准确度。
