使用蚁群算法和深度强化学习的工业异常入侵检测
2022-05-10陈铁明
陈铁明,董 航
(浙江工业大学 计算机科学与技术学院,网络空间安全中心,杭州 310023)
1 引 言
工业控制系统(ICS)包括监控和数据采集(SCADA)系统,分布式控制系统(DCS)等,常用于电力、水利、石油、铁路等基础领域,通过远程获取数据并推送监控命令到控制设备.
近年来,ICS和外部网络连接更加紧密,受到的网络攻击也日益增加.这将会对国家的基础设施造成破坏,带来重大的经济损失[1].2010年,针对微软件系统以及西门子工业系统的“网震”蠕虫病毒攻击了伊朗布什尔核电站,利用操作系统漏洞造成多台离心机感染;2012年,“火焰”病毒在中东地区大范围传播,通过盗取重要信息来执行间谍活动;“Havex”病毒,俄罗斯输气管道爆炸、德国钢厂事故等都显示出ICS面临越来越多的复杂攻击[2].除了这些著名的工业安全事件之外,每年还会发生数百起针对ICS的攻击.尽管对工业系统的攻击少于对Internet的攻击,但是由网络物理攻击造成的破坏却不容忽视.这些攻击活动表明,传统的方案如防火墙、基于签名的入侵检测系统(IDS)等已经不适合现有的情况.
入侵检测方法有两种.一种称为基于签名的入侵检测方法,第2种称为基于异常的入侵检测方法[3].基于签名的入侵检测方法也称为基于滥用的检测方法,用于在符合恶意软件[4]的数据中查找模式或签名,通过一个包含各种攻击签名的数据库对恶意软件进行筛选,检测结果阳性率较高.基于签名的技术的问题在于它无法检测到新颖的攻击,因为对于新颖的攻击尚不存在签名[5].基于反常异常的检测方法通过查找不符合的系统或者异常行为可以发现新颖的攻击,但是这种方法的假阳性率高,因为很难定义系统或网络的正常行为[6].机器学习基于数据驱动,更多的被用于基于异常的入侵检测.然而,机器学习依赖输入的数据,容易受到冗余特征、噪音等影响,在检测新型攻击时误报率较高.
基于现有方法的缺陷,本文尝试使用蚁群优化算法和深度强化学习用于SCADA异常监测和攻击分类.蚁群优化算法是一种高效的特征选择算法,通过对数据特征进行分类,选择冗余度最小的特征子集来达到提高分类速度的目的.强化学习是一种基于马尔可夫决策过程的机器学习范式,通过学习策略以达成回报最大化或实现特定目标的问题,强化学习算法在信息论、博弈论、自动控制等领域有一定应用[7].深度强化学习结合强化学习和深度学习的特点,能够更好地解决问题.
本文的其余部分安排如下.第2节讨论相关工作.第3节提供了本文提出方法的理论基础.第4节介绍本研究中使用的数据集并显示了相关的实验结果.最后,第5节总结结论.
2 相关工作
在工业互联网入侵检测领域,机器学习被广泛应用.郭建龙等人[8]通过制定入侵检测专家系统规则集进行入侵检测.Simon Duque Anton等人[9]使用传统的机器学习方法进行异常检测.作者通过原始数据呈现的特征提取出基础特征,并利用基础特征合成衍生特征.通过计算基尼系数减少特征值,使用SVM、Random Forrest和k-nearest neighbour对提取到的特征进行分类.胡臻伟等人[10]将贝叶斯网、ID3 决策树、感知机、KNN 和 AdaBoost 算法用于实际的网络流量数据,并对比不同分类器算法的有效性.
和传统的机器学习方法相比,深度学习最大的优势就是可以从原始数据中自动学习特征,并取得优异的性能[11].B.Yan[12]等人使用自动编码器提取特征,降低维度,然后使用分类器(SVM、KNN、RF)对数据进行分类.为了提高模型的泛化能力,作者向编码器中添加了稀疏项,并使用多层编码器堆叠.同时,为了更好地训练SSAE模型,在训练时使用不同的学习率,作者使用 Adam算法来实现不同参数的动态自适应调整.作者使用该方法对KDD99和NSL-KDD数据集进行检测,证明降维提取特征能在不损失准确率的情况下减少训练和预测时间.Wei Wang等人[13]使用长期短期记忆递归神经网络(LSTM-RNN)检测时序数据,通过欧几里得检测器验证预测数据和观测数据之间的偏离程度,对数据进行分类.作者通过TE模型生成数据集,使用正常数据进行训练,设置阈值,计算预测值和观测值的欧几里得距离,超过阈值的被认定为恶意攻击,实验取得较好的结果.Mikel Canizo等[14]结合卷积神经网络和循环神经网络的特点,构建模型对多时间序列数据进行异常检测,在数据样本不均衡的情况下也有较好的性能.Karimipour等人[15]提出一种为ICS设计的基于广义集成深度学习的攻击检测方法.该方法将原始的不平衡数据集构造成新的平衡展示,并基于DNN和DT分类器检测攻击.Hu Yibo等人[16]分析传统IT网络数据和ICS网络数据的特性,通过设计卷积神经网络将传统IT网络的异常检测知识转移到ICS网络中,判别异常行为.Chang Chunpi等人[17]提出了一种基于半监督技术的工业控制系统异常检测方法,结合k-means和卷积自动编码器两种模型对数据进行检测.
在特征选择方面,Hadeel Alazzam等人[18]使用鸽群智能优化算法进行特征选择,并用于入侵检测;Jung-Hyok Kwon等人[19]提出了一种使用迭代特征选择的工业互联网故障预测模型,通过特征选择排除无关与故障的特征,结果表明,提出的故障模型具有较高的预测精度;Maryam SamadiBonab[20]等人提出了一种基于包装器的特征选择方法,混合多种算法对入侵检测系统中的特征进行最优选择,用于降低执行负载和存储方面的复杂性.
3 方 法
3.1 蚁群优化算法
在数据集预处理阶段,首先要进行特征选择.在没有先验知识的情况下,很难提前获知特征与目标、特征与特征之间的相关性以及每个特征的重要程度.在进行模型训练之前去除无关的特征和噪音有利于降低模型的学习难度,加快模型训练和测试的速度,使模型具有更好的解释性,还可以降低过拟合的风险,提高模型的泛化能力.常见的特征选择方法有:过滤法(Filter)、包装法(Wrapper)和嵌入法(Embedding).
蚁群算法是由Dorigo、Maniezzo等[21]在20世纪90年代提出,通过启发式搜索,利用蚂蚁的整体行为寻找到达食物源的最短路径.
SCADA数据集的指标较多,存在大量无关、冗余和嘈杂的特征,对分类器的准确性和分类速度都会造成很大的影响.由于数据集中多个特征之间存在关联,传统过滤器方法只考虑单个特征,无法挖掘不同特征之间的组合效应,因此并不适用.此外,相关数据集较大,传统的包装器方法收敛慢,对训练和测试的时间有很大影响.蚁群算法通过将过滤器方法与包装器方法相结合,能够解决组合优化问题,并且收敛较快,适用于数据量大,特征多的SCADA数据集.
首先,定义数据一个全连接无向图G={F,E},F={F1,F2,F3,…Fd}表示d个特征,E={(Fi,Fj):Fi,Fj∈F}表示边,边的权重为各个特征之间的相似度:
(1)
其次,初始化信息素,通过考虑特征和类标签之间的余弦相似度最大值来初始化信息素矩阵[22]:
(2)
在每一轮迭代中,设置一个阈值q0,当随机数大于q0时,根据公式(3)计算每个待选特征的概率,通过轮盘赌算法选择下一个特征;当随机数小于等于q0,选择使信息素与成本的比值最大的特征为下一个特征:
(3)
(4)
Fmi表示第m只蚂蚁在选择特征i后下一个可以选择的特征的集合;η(i,μ)表示两个特征i和μ之间的成本;τ表示特征的信息素;α为信息素因子,表示蚂蚁积累信息素的重要程度;β为启发因子,表示启发式因子在特征选择中的重要程度.
每一轮迭代完成后,使用SVM分类器对每只蚂蚁选择的特征集合进行分类,根据结果排名,选择前20%的蚂蚁更新信息素,如公式(5)所示:
(5)
信息素挥发因子ρ表示t+1时刻信息素挥发的比例,C(i)表示每轮迭代后特征i被选中的个数.
经过多轮迭代后,选择表现最好的蚂蚁的特征作为最后的结果.
具体算法如下:
算法1. 蚁群算法特征选择
输入:
D:n×d特征集,n条数据,特征数量为d;n×1标签集.
m:蚂蚁数量
cycle:迭代次数
n_feature:要选择的特征数
q0:阈值
α:信息素因子
β:启发因子
ρ:挥发因子
输出:
s:选中的特征集合
1. initialize:根据公式(1)、公式(2)初始化τ,η
2. for iteration = 1,2,…cycle do
3. C[i] = 0 i = 1,2,…d
4. for m = 1,2,…m do
5. fori = 1,2,…d do
6. 根据公式(3)、公式(4)选择特征,如果特征i被选
7. 中,C[i] = C[i]+1
8. endfor
9. endfor
10. 对每一轮迭代中所有蚂蚁选中的特征使用SVM分
11. 类,根据准确率选取前20%的蚂蚁,根据公式(5)
12. 更新信息素
13. endfor
14. 返回准确率最高的蚂蚁选中的特征集合
3.2 深度强化学习
由于SCADA遇到的攻击种类多变,因此有必要使用一种能够适应在线学习的模型.强化学习能够根据环境的变化通过奖励函数驱动制定合适的策略,适用于多种类型的问题,对入侵检测有很大的帮助.
强化学习基于马尔可夫决策过程(MDP)理论,由四元组(S,A,T,R)表示.S表示所有状态的集合,A表示有限的动作集合,T表示动作对状态转换的映射,R表示执行动作获得的奖励.通过MDP为每个状态提供最佳的策略,以获取奖励,得到最优解.

价值函数如公式(6)所示:
Q(s,a)=Q(s,a)+α[Rsa+γQ(s′,a′)-Q(s,a)]
(6)
由于本文实验中每条数据和其他数据不相关,所有样本独立同分布,因此γ设置为0,公式(6)转变为公式(7):
Q(s,a)=(1-α)Q(s,a)+αRsa
(7)
ε-greedy中ε设置为1/epoch,一开始ε值较大,使用随机的方式进行探索;随着多次迭代,ε值减小,开始使用模型进行动作选择.
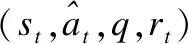

图1 深度强化学习流程图Fig.1 DQN flow chart
4 实验结果
4.1 数据集
本文使用密西西比州立大学设计和开发的天然气管道测试平台SCADA系统收集的真实数据[24].该数据集包括26个特征和8种类型标签,具体标签的分布、描述和数量如表1所示.

表1 实验数据表Table 1 Dataset
4.2 数据预处理
数据预处理包含两个部分:删除无效的特征和标准化.某些特征的标准差接近0,说明这个特征在样本上没有差异,对分类不起作用.剔除数据集中所有标准差为0的特征,并通过公式(8)标准化将特征缩放成均值为0、方差为1的数据集.
(8)
本实验使用五重折叠交叉验证,将原始数据集划分成5份,每份训练集和测试集比例为4:1.
4.3 评估指标
本文使用下列指标评估分类器的效果:
Accuracy:准确率,表示被分类器正确分类的比例:
Precision:精确率,表示预测为正例的真实正例样本占预测为正例的样本总数的比例:
Sensitivity:灵敏性(召回率),表示预测为正例的真实正例样本占真正例样本总数的比例:
Specificity:特异性,表示预测为负例的负例样本占真负例样本总数的比例:
G-mean:基于灵敏性和特异性,在数据不平衡时,有参考价值:
4.4 特征选择
本节使用4种特征选择方法,蚁群算法、随机森林(Random Forest)、Fisher Score和互信息度量(mutualinfo)进行特征选择,在不同特征维度下使用五重折叠交叉验证,最后使用支持向量机分类,根据准确率选择合适的特征子集,如图2所示.使用蚁群算法选择不同维度的特征子集,并用支持向量机分类,计算其灵敏性、特异性、G-mean和训练的花费时间.随着特征数量增加,训练时间也随之增加.当特征数量到达10以后,灵敏性、特异性和G-mean基本收敛,具体如图3所示.
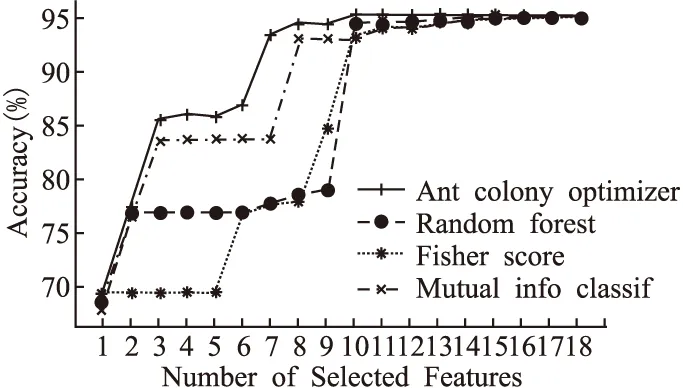
图2 4种特征选择方法不同维度特征子集准确率图Fig.2 Accuracy of feature subsets with different dimensions for the four feature selection methods
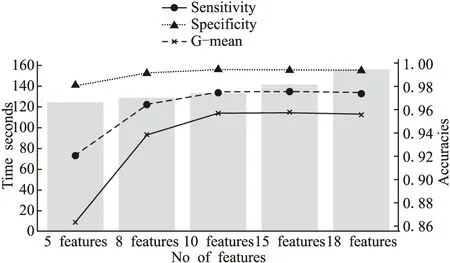
图3 蚁群算法特征选择各指标值图Fig.3 Ant colony algorithm feature selection of each index value
通过以上实验,最终选出了最佳的特征维度,选取的特征如表2所示.

表2 特征子集表Table 2 Feature subset
4.5 平衡样本
本实验采用的数据样本分布不均衡,大部分都是正常样本,MSCI、MFCI和NMRI 3个类别的样本数量较少.为了避免数据不平衡造成机器学习和深度学习引起的偏见,本文采用SMOTE算法进行过采样,对少数类样本进行分析并根据少数类样本人工合成新样本并添加到数据集中,如等式所示:
由于本数据集部分类别样本数量和正常样本差距过大,为避免过拟合,当某个类别样本数量不足正常样本5%时,增加该类别样本至正常样本的5%.最后训练集和测试集各样本数量如表3所示.

表3 数据集划分表Table 3 Dataset division
4.6 结果比较
本文使用五重折叠交叉验证,比较了4种不同方法的准确率:SVM、CNN、LSTM和DQN.表4显示了4种方法分类的准确率,SVM、CNN和LSTM的准确率分别为95.36%、96.05%和96.08%,本文提出的方法准确率有小幅度提升,为96.29%.表5和图4显示了4种分类器不同分类的准确率.

图4 4种分类器不同分类准确率图Fig.4 Different classification accuracy of four classifiers

表4 4种分类器准确率表Table 4 Accuracy of four classifiers

表5 4种分类器不同分类准确率表Table 5 Different classification accuracy table of four classifiers
图5和图6分别描述了4种不同方法的精确率和召回率.从召回率分析可以看出,本文提出的方法在4个类别(Normal、NMRI、CMRI、Recon)中得分最高.在NMRI分类中,由于该分类样本较少,4种分类器的召回率都较低.从精确率分析上看,本文提出的方法在4个分类(Normal,NMRI,CMRI,Recon)上得分最高,其他几个分类相差不大.从总体趋势看,本文提出的方法有更好的性能.

图5 4种分类器不同分类召回率图Fig.5 Different classification recall rates of four classifiers

图6 4种分类器不同分类精确率图Fig.6 Different classification precision rates of four classifiers
ROC曲线是预测模型的一种性能指标,它表示真实阳性率(TPR)和错误阳性率(FPR)之间的关系[25].ROC曲线和坐标轴围成的面积AUC用于评估检测方法的真实性.AUC的值越大,真实性越高.图7显示4种不同分类模型的ROC曲线和AUC值,SVM、CNN、LSTM和DQN的AUC值分别为0.963,0.970,0.971,0.976.

图7 4种分类器ROC曲线图Fig.7 ROC curve of four classifiers
混淆矩阵是一种评价精度的标准格式,用于比较分类结果和实际结果,从而判断分类器的性能.图8显示本文提出的模型的混淆矩阵,大部分分类结果都集中在对角线上,分类表现较好,NMRI类型的攻击在分类中表现不佳,召回率较低.
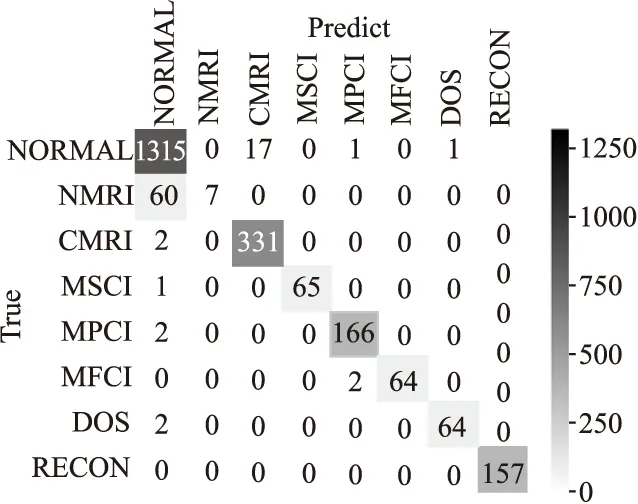
图8 DQN模型混淆矩阵图Fig.8 DQN model confusion matrix
5 结 论
本文提出了基于蚁群算法和深度强化学习的入侵检测模型.考虑到数据集特征中存在冗余,并有可能对分类造成影响,提出基于蚁群算法的特征选择方法,选取最佳的特征集合,将特征数量从26个减少到10个,降低了训练和测试的时间和内存.本文使用深度强化学习,借助其反馈调整学习策略的优势,实现了对恶意攻击的检测和分类.在未来的工作中,将使用更多更复杂的数据集来检验该模型的泛化能力.
