课程概念依赖关系挖掘方法研究
2022-05-10王泽松
王泽松,曾 诚,肖 奎
(湖北大学 计算机与信息工程学院,武汉 430062)
1 引 言
在大学的课程体系中,课程与课程之间有着相对固定的学习顺序,后续课程通常必须安排在前导课程后面的学期开设.这种课程顺序是由每门课程中主要概念间的依赖关系所决定的.课程概念是一个课程中的专业词汇,对于一对课程概念(A,B),当学习者在学习概念B之前,需要首先理解概念A,那么就说明A与B之间存在依赖关系,即B依赖于A.同样,在一本教材的各个章节之间也有着相对固定的学习顺序,而章节学习顺序也是由各章节中包含的概念的依赖关系所决定的.
近年来,课程概念依赖关系挖掘逐渐成为研究人员关注的焦点,这种课程概念依赖关系已经在智慧教育的多个应用领域发挥了重要作用,比如概念图构建[1,2],文档阅读列表生成[3],学生知识状态追踪[4],学生学习情况评估[5],知识导航[6]等等.
本研究提出一种课程概念依赖关系挖掘方法,通过分析概念所属的课程的属性,以及概念对应的维基百科词条的属性,构建一对概念的课程特征和维基百科特征,并利用这些特征分析概念对之间是否存在依赖关系.同时,本文也利用课程概念依赖关系建立了概念图,通过对比不同大学相同专业的概念图,来分析不同大学在专业课程设置方面的差异.
本文的贡献主要有以下两个方面:
1)提出一种课程概念依赖关系挖掘方法,从大学的课程简介中抽取课程相关概念并分析这些概念间是否存在依赖关系,同时在公共数据集上对本文提出的课程概念依赖关系挖掘方法进行验证.
2)利用课程概念依赖关系建立了两个概念图示例,通过对比不同大学相同专业的概念图,分析不同大学在专业课程设置方面的差异.
2 相关研究
概念依赖关系挖掘是近年来研究人员关注的一个焦点.文献[7]首先对维基百科概念依赖关系挖掘进行了研究,作者认为如果概念B的维基百科词条中包含了一个链接指向概念A,那么A中可能包含了一些阅读B的词条所需要的背景知识,即B可能依赖于A.针对这些有链接关系的概念对,作者利用它们两个概念间的链接信息、编辑信息、内容信息设计特征,然后使用MaxEnt分类器预测概念间的依赖关系.文献[8]提出一种基于概念引用距离(RefD)的方法预测两个维基百科概念间的依赖关系.具体而言,维基百科中每个概念都可以由它的“相关概念集合”来代替,如果概念B的“相关概念集合”中的大部分概念中都包含了一个链接指向概念A,反之概念A的“相关概念集合”则很少引用概念B,那么概念B有可能依赖于概念A.文献[9,10]利用机器学习方法对维基百科概念依赖关系进行预测,文献[9]中作者建立了4组概念对的特征,包括基于链接、基于分类、基于文本内容以及基于时间关系的特征,并采用6种不同的分类器进行概念依赖关系预测实验.Sayyadiharikandeh等人[11]提出一种基于维基百科点击流数据来推断概念间依赖关系的方法.点击流就是用户在维基百科平台上的操作日志,这是研究人员首次利用用户交互行为预测概念对间的依赖关系.
上述方法都是根据概念对应的维基百科词条的内容进行概念依赖关系预测,也有一些研究人员开展了基于学习资源进行课程概念依赖关系识别的研究,有的是分析MOOC视频中课程概念间的依赖关系[12,13],有的是分析教材中课程概念间的依赖关系[14,15].文献[16]分析了大学课程简介中的内容,抽取出其中的主要的课程概念并推测课程概念间的依赖关系,与本文的研究内容比较接近.但是,作者只考虑了课程属性对概念依赖关系的影响,而本文同时使用了课程属性与维基百科属性对课程概念间的依赖关系进行识别.
3 方 法
本文的研究目标是从大学公开的课程简介信息中抽取出每门课程的主要知识概念,并利用课程学习顺序、维基百科词条内容等信息,对课程概念间的依赖关系进行预测.本文从课程简介中抽取的课程概念必须都是维基百科中存在的概念,即每个课程概念对应一个维基词条,这个概念就是词条的标题.这样做一方面是因为维基百科覆盖的知识范围较广,可满足不同学科的需要;另一方面是因为在利用维基百科进行概念依赖关系挖掘方面,当前已经有了一些较好的研究基础可供参考.
为了更好的探究课程概念间的依赖关系,本文将分别从课程属性和维基百科属性两个方面进行概念对的特征设计,实现课程概念依赖关系的预测.接下来将分别介绍“基于课程属性”的特征和“基于维基百科属性”的特征.
3.1 “基于课程属性”的特征
一个专业中课程学习的先后顺序通常是由它们本身的内容决定,对于两门课程Ca与Cb,如果课程Ca中包含了一些学习课程Cb所需要的背景知识,那么学习者必须先学习课程Ca再学习课程Cb.每门课程中通常介绍了一些重要的课程概念,如果学习课程Cb之前必须先学习课程Ca,那么说明在理解Cb中的一些主要课程概念之前,必须先理解Ca中的一些课程概念,而Ca中的这些课程概念就是学习Cb所需要掌握的背景知识.表1标注了课程属性的相关术语.

表1 课程属性的相关术语Table 1 Terms related to course attributes
在本文中,每门课程都有一段与之对应的课程简介,一门课程Ci可以在概念空间(w1,w2,…,wm)上用向量进行表示.向量中的值是不同概念在Ci课程简介中的tf-idf值.例如:
C1={0,0.23,0.014,0,0.56,0,…,0.13,0}
C2={0.15,0.03,0,0,0,0.11,…,0.03,0.02}
给定一对课程概念(wa,wb),本文设计了如下一些“基于课程属性”的概念对特征,用以进行概念依赖关系的识别.
·Crf(wa,wb).
假设概念wa出现在Ci的课程简介中,概念wb出现在Cj的课程简介中,且在学习课程Ci前需要学习课程Cj,那么这种课程顺序可能意味着概念wa依赖于wb.对于两个概念,遍历所有课程对组合,如果它们在多对有固定先后顺序的前导课程与后续课程中出现,那么这两个概念的关系如式(1)所示:
(1)
其中,r(Ci,wa)表示概念wa是否为课程Ci的重要概念,其中概念wa是Ci课程简介中的一个词汇,当概念wa的tf-idf值大于一个指定的阈值时,那么它就是课程Ci的一个重要概念,r(Ci,wa)取值为1,否则取值为0.本文将这个阈值定义为tf-idf的平均值,即对于概念wa和课程Ci,若概念wa在课程Ci中的tf-idf值大于课程Ci所包含概念的平均tf-idf值,则可认为概念wa是课程Ci的重要概念,即:
(2)
Z(Ci,Cj)表示课程Ci对课程Cj的依赖程度,取值为1或0,其中1表示学习课程Ci之前需要先学习课程Cj,0表示学习Ci之前不需要先学习Cj.在此基础上,定义第一个“基于课程属性”的特征如式(3)所示:
Crf(wa,wb)=Cr(wa,wb)-Cr(wb,wa)
(3)
另一方面,由于课程简介的内容往往篇幅有限,这就导致了有些课程概念虽然与课程有着密切的联系,但是无法出现在课程简介中.比如,“背包问题”、“旅行商问题”,这些都是《算法设计与分析》课程中经常会讲解的内容,但是在课程简介中可能只会包含“动态规划法”、“分支限界法”这些粒度更粗的概念.而“背包问题”通常是“动态规划法”中的一个重要范例,“旅行商问题”通常也是“分支限界法”中的一个重要范例.因此,本文将利用“动态规划法”这样的中间概念,建立课程与那些不在其中的概念之间的联系.
·Ctf(wa,wb).
对于一门课程Ci和一个概念wa,wa并未出现在课程Ci的简介中,但是可能与课程Ci的简介中的某些概念有着重要的联系,那么它们的相关性如式(4)所示:
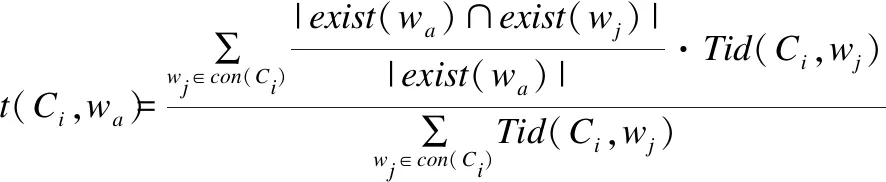
(4)
其中,exist(wa)表示简介内容中包含有概念wa的所有课程.wj是从Ci的课程简介中抽取的概念.概念wa和Ci中已有的概念同时出现的频率越高,wa和Ci的相关程度越高,就像概念“背包问题”和课程《算法设计与分析》一样.t(Ci,wa)描述了课程Ci和概念wa之间的一种文本相关性.
如果两个概念wa和wb分别对应一些这样相关的课程,并且它们所对应的课程之间也存在着前导课程与后续课程这样固定的顺序关系,那么这种课程顺序可能是由wa和wb的依赖关系引起,因此有式(5):
(5)
在此基础上,定义第2个“基于课程属性”的特征如式(6)所示:
Ctf(wa,wb)=Ct(wa,wb)-Ct(wb,wa)
(6)
·Clf(wa,wb).
如果概念wa与课程Ci相关且未出现在课程Ci的简介中,但是wa与Ci的课程简介中包含的概念wj在维基百科中存在着链接关系,即wa的词条中有一个链接指向wj,或者wj的词条包含了一个链接指向wa.那么,就可利用这种关系探究课程Ci和概念wa之间的链接相关性.本文设置link(wa,wj)表示这种链接关系,即如果概念wa的词条包含了一个链接指向概念wj,或者wj的词条包含了一个链接指向wa,则link(wa,wj)取值为1,否则取值为0.进而可定义课程Ci和概念wa之间的链接相关性见式(7):
(7)
如果两个概念wa和wb分别有这样一些和它们链接相关的课程,并且它们的这些课程之间也存在着前导课程与后续课程这样固定的顺序关系,那么这种课程顺序可能是由wa和wb的依赖关系引起,因此有式(8):
(8)
在此基础上,定义第3个“基于课程属性”的特征如式(9)所示:
Clf(wa,wb)=Cl(wa,wb)-Cl(wb,wa)
(9)
·Ckf(wa,wb).
维基百科官方通常会公布最近30个月中用户的点击流数据日志(1)https://dumps.wikimedia.org/other/clickstream/.点击流是指用户浏览了一个维基百科词条后立即浏览另一个词条的动作,用户通常是点击一个词条中的链接跳转到另一个词条中继续浏览,而这样被连续浏览的两个词条往往是密切相关的[11].点击流数据记录了在在过去一段时间里,所有用户从一个词条跳转到另一个词条的次数.图1显示了在过去30个月中,维基百科用户从concept A到concept B的跳转次数.
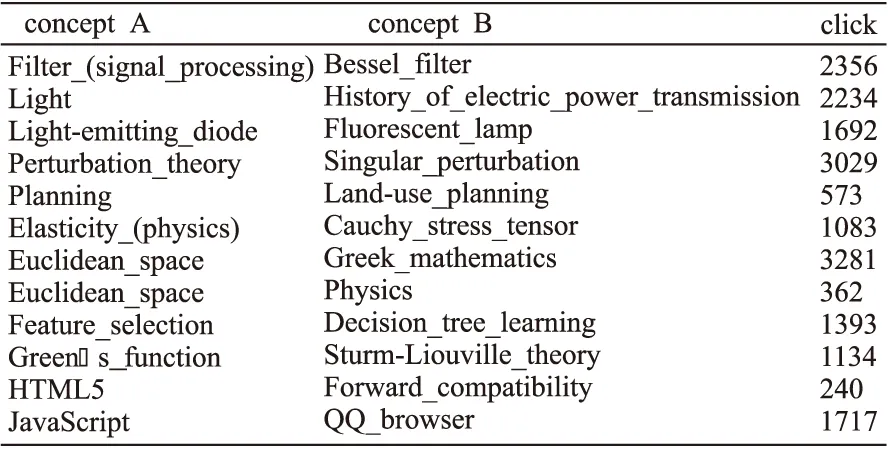
图1 维基百科点击流数据Fig.1 Wikipedia clickstream data
如果概念wa与课程Ci相关且未出现在课程Ci中,但是概念wa与课程Ci中包含的概念wj间存在这样一种点击流关系,即用户浏览了wa以后立即浏览wj,或者浏览了wj以后立即浏览wa,那么概念wa可能与wj是相关的.据此,可以定义概念wa与课程Ci间的点击流相关性如式(10)所示:
(10)
其中,click(wa,wj)表示两个概念wa与wj是否相关,相关取值为1,否则取值为0.
如果两个概念wa和wb分别对应这样一些点击流相关的课程,并且它们的课程之间也存在着前导课程与后续课程这样固定的顺序关系,那么这种课程顺序也可能是由wa和wb的依赖关系引起,因此有式(11):
(11)
在此基础上,定义第4个“基于课程属性”的特征如式(12)所示:
Ckf(wa,wb)=Ck(wa,wb)-Ck(wb,wa)
(12)
3.2 “基于维基百科属性”的特征
除了利用课程属性识别两个概念间的依赖关系,本文也利用两个概念对应的维基百科词条内容来识别它们间的依赖关系.并且,每个维基百科概念都可以由它的相关概念集合来表示.所以,对于一对概念(wa,wb),如果它们的相关概念集合间存在着依赖关系,那么说明它们两个概念间也存在着依赖关系[8].本文定义了两种类型的相关概念集合:基于链接的相关概念集合S*与基于点击流的相关概念集合S#.
3.2.1 基于链接的相关概念集合S*
首先,本文将那些与概念wa同属一个维基百科分类(Category)且与wa具有链接关系的概念视为wa的相关概念.如图2所示,概念Machine learning与Knowledge integration同属于分类Learning,且概念Machine learning的词条中包含了一个链接指向概念Knowledge integration,那么后者可以作为前者的相关概念.同理,概念Machine learning control也可以作为概念Machine learning的相关概念.
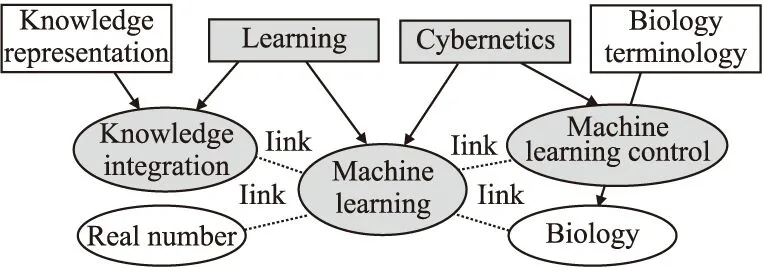
图2 相关概念集合S*Fig.2 Related concepts collection S*
3.2.2 基于点击流的相关概念集合S#
如前所述,用户在维基百科中连续浏览了两个词条,那么这两个词条可能是有关联的.为了减轻计算量,对于一个概念wa,本文将点击流次数大于平均出(入)度的概念作为相关概念.如图3所示,在过去30个月的点击流数据日志中,由概念Machine learning点击出去到达其它概念的平均次数为82.2;从其它概念点击进入概念Machine learning的平均次数为44.4.我们将点击出去大于82.2次的概念Algorithms、Training data、Mathematical optimization,以及点击进入Machine learning大于44.4次的概念Computer vision、Deep learning、Dimensionality reduction作为Machine learning的相关概念.
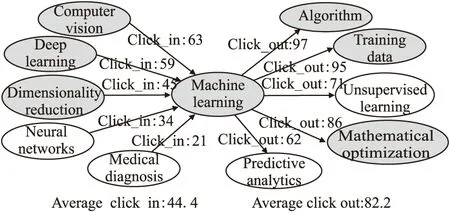
图3 相关概念集合S#Fig.3 Related concepts collection S#
本小节将使用的一些术语定义如下.
A.基于维基百科分类的特征
维基百科中的分类(Category)信息可以被用于识别概念间的依赖关系.在维基百科中,每个概念会隶属于一个或多个分类,如果一个分类的层次在另一个分类的层次之上,层次高的分类包含的概念通常更抽象,层次低的分类包含的概念通常更具体,而这些具体的概念往往依赖于抽象的概念[9,17].因此,本文设计了如下特征来识别概念间的依赖关系.
·Waf(wa,wb).
root代表维基百科体系中的根节点“Content”,len(root,wa)代表根节点到概念wa的最短路径长度,这也是概念wa在维基百科体系中的层次.如图4所示,len(root,wa)=2,len(root,wb)=2,len(root,wc)=3.
图4 概念在维基百科分类中的层次Fig.4 Level of concepts in Wikipedia classification
显然,len(root,wa)值越大,说明概念wa的层次越低,wa的内容越具体;len(root,wa)值越小,说明概念wa的层次越高,wa的内容越抽象.如果len(root,wb)的值比len(root,wa)小,说明概念wb的层次比wa高,wb的内容比wa抽象,那么概念wa可能会依赖于概念wb,因此本文设计了特征如式(13)所示:
Waf(wa,wb)=len(root,wa)-len(root,wb)
(13)
·Waf*(wa,wb)与Waf#(wa,wb).
对于两个概念(wa,wb),本文也分析了概念wa的相关概念集合如表2中S*(wa)与概念wb的相关概念集合S*(wb)中的概念间的层次关系,利用相关概念的平均层次识别两个概念间的依赖关系,具体特征如式(14)所示:

表2 维基百科属性的相关术语Table 2 Terms related to Wikipedia attributes
(14)
同理,将相关集合替换成S#,又定义了下面一个特征如式(15)所示:
(15)
B.基于维基百科点击流的特征
·Wkf(wa,wb).
由于人们在浏览一个概念的维基百科词条以后往往会继续浏览其它相关词条,查看背景知识内容.如果在点击流数据中存在从概念wa到概念wb的情况,但不存在从wb到wa的情况,则概念wa可能依赖于概念wb.因此定义了如式(16)所示的特征用于识别概念间的依赖关系:
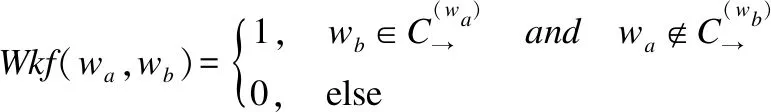
(16)
·Wkf*(wa,wb)与Wkf#(wa,wb).
另一方面从相关概念集合的角度考虑,本文用Out*(wa,wb)表示wa的相关概念集合S*(wa)中所有概念的点击流的指出概念集合与wb的相关概念集合S*(wb)的交集;In*(wa,wb)表示wa的相关概念集合S*(wa)中所有概念的点击流的指入概念集合与概念wb的相关概念集合S*(wb)的交集.
(17)
(18)
如果Out*(wa,wb)值较大,而In*(wa,wb)值较小,那么说明用户浏览时常常在浏览了wa的相关概念以后继续浏览wb的相关概念,而很少从在浏览了wb的相关概念以后继续浏览wa的相关概念,这说明概念wa有可能依赖于概念wb.因此定义了如式(19)所示的特征用于识别概念间的依赖关系:
Wkf*(wa,wb)=Out*(wa,wb)-In*(wa,wb)
(19)
同理,当使用S#作为相关集合时,则可定义出另一个特征Wkf#(wa,wb),如式(22)所示:
(20)
(21)
Wkf#(wa,wb)=Out#(wa,wb)-In#(wa,wb)
(22)
C.基于维基百科链接的特征
文献[8]利用概念的维基百科词条中的链接识别概念间的依赖关系,本文借鉴了相关做法定义了如下概念对的特征.
·Wlf(wa,wb).
对于一对概念(wa,wb),如果wa的维基百科词条中包含了一个链接指向概念wb,说明wa引用了wb,那么wa有可能依赖于wb.因此定义了如式(23)所示的特征用于识别概念间的依赖关系:
(23)
·Wlf*(wa,wb)与Wlf#(wa,wb).
从相关概念集合的角度考虑,对于概念wa和wb,如果wa的相关概念集合中的大多数概念都包含有指向wb的链接,而概念wb的相关概念集合中很少有概念包含指向wa的链接,那么概念wa有可能依赖于概念wb.基于这样的假设,定义了如式(24)所示的特征:
(24)
同理,将相关集合替换成S#,可定义出另一个类似的特征,如式(25)所示:
(25)
4 实 验
4.1 数据集
Liang等人[16]从11所美国大学的计算机科学专业的网站上爬取了654门课程的数据,其中包含了每门课程的课程简介、以及前导课程与后续课程的顺序关系等信息.在这些课程中有861对课程间存在着前导课程与后续课程的顺序关系,本文将在此数据集上对提出的方法进行验证.
我们首先从全部课程的课程简介中抽取维基百科概念,由于都是计算机专业的课程,所以从不同大学抽取的概念存在大量重复的现象,最后实际得到不同的概念2699个.然后,通过人工筛选出其中的计算机科学领域的概念569个,并组织3位计算机专业的研究生对这些概念对的依赖关系进行投票,以确定这些概念对之间是否存在依赖关系.对于一对概念(wa,wb),通常有3个选项:1)wa依赖于wb;2)wa不依赖于wb;3)不确定.删除包含不确定选项的概念对以后,最终得到有依赖关系的概念对共1312对,没有依赖关系的概念对2448对.表3展示了数据集的相关信息.
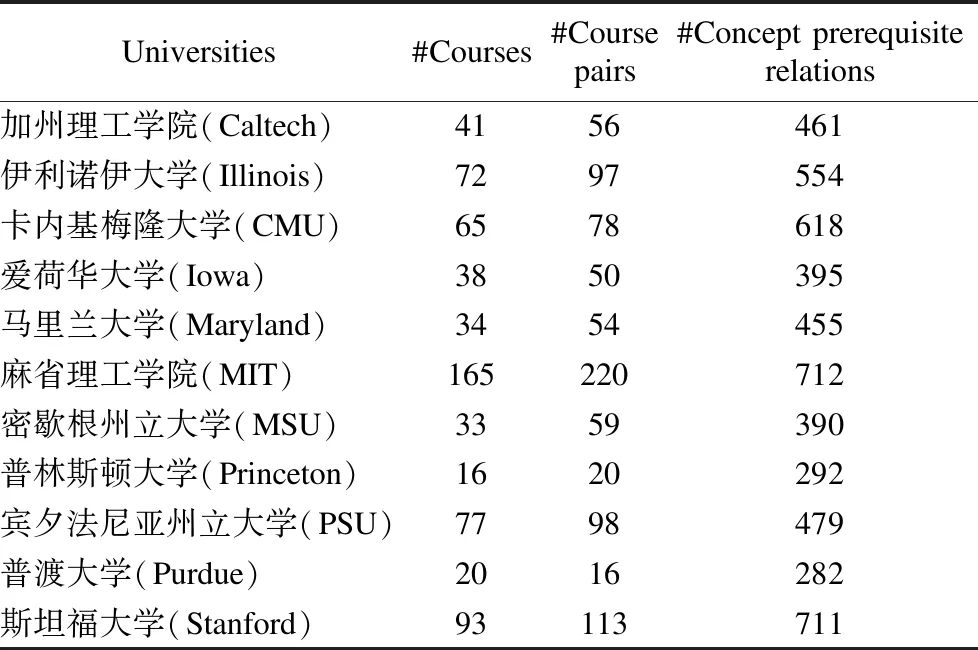
表3 大学计算机专业课程数据集Table 3 University computer professional course data set
4.2 结果评估
本文采用五则交叉验证对提出的方法进行实验评估.在本文的实验中,使用了6种常用的机器学习分类器对课程概念依赖关系进行预测,分别是随机森林(RF)、朴素贝叶斯(NB)、多层感知器(MLP)、支持向量机(SVM)、逻辑回归(LR)和AdaBoost,所有分类器都是采用python程序和sklearn库实现,参数均为默认参数.具体实验结果如表4所示.
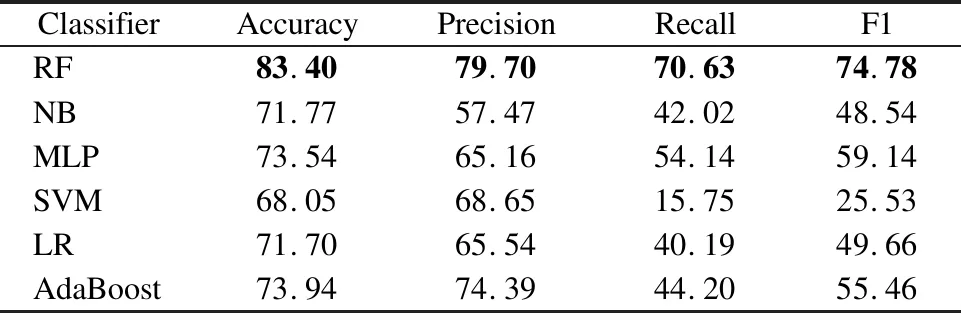
表4 本文提出方法的分类结果(%)Table 4 Classification results of the method we proposed(%)
从表4可以看出,不同的分类器的预测结果有着较大的差异.对比各指标值可以发现,随机森林分类器性能最好,在Accuracy、Precision、Recall、F1等度量指标上均优于其它分类器,分别达到83.40%、79.70%、70.63%、74.78%.这与其它相关研究[9,12]的结论类似,随机森林相较于其它分类器在概念依赖关系预测中表现更为出色.
支持向量机表现较差,其Recall、F1等指标值分别只有15.75%和25.53%.估计是由于当前使用的特征值都是具体的数值,并且这些数值的范围差异较大,较难在两类样本中形成一个较好的超平面来对样本进行分类,所以分类效果不是很好.本文将采用随机森林进行后续的实验.
4.3 与基准方法对比
本文选取了3个基准方法(baselines)进行对比,第1个是文献[8]提出的计算概念引用距离(RefD)识别概念依赖关系的方法,作者在其中运用了两种方式定义维基百科词条中每个相关概念的权值,分别是equal(所有相关概念权值均为1)和tf-idf(所有相关概念权值为它们的tf-idf值).第2个对比的方法是文献[16]提出的一种基于优化技术的概念依赖关系识别方法(CPR),这也是首次运用课程间依赖关系计算课程概念依赖关系的方法.第3个对比的方法是文献[9]中提出的利用链接、分类、文本、创建时间等特征进行概念依赖关系预测的方法(EPR).具体实验结果如表5所示.

表5 与基准方法对比(%)Table 5 Comparison with baseline method(%)
可以看出本文提出的方法在各度量指标上表现均优于其它方法.需要说明的是,RefD与CPR方法均未在分类任务中采用机器学习分类器,前者是根据计算得到的RefD值直接进行分类,后者是利用优化技术计算课程概念间的依赖关系值然后进行排序和分类.而EPR方法与本文一样采用常规分类器进行分类,它们的性能要明显优于RefD和CPR方法,这说明人工建立的特征确实能够为概念间的依赖关系识别提供有效的帮助.
4.4 特征贡献度分析
为了了解各个特征在课程概念依赖关系分类任务中的效果,本文也对每个特征的贡献度进行了分析.表6展示了依次去掉每个特征后,总体分类准确率(Accuracy)的变化情况.从整体来看,“基于维基百科属性”的特征贡献度大于“基于课程属性”.当“基于维基百科属性”的特征被去掉后整体分类准确率下降了11.13%,当“基于课程属性”的特征被去掉后整体分类准确率下降了3.60%.当然,“基于维基百科属性”中的特征数量也多于“基于课程属性”中的特征.

表6 特征贡献度分析(%)Table 6 Feature contribution analysis(%)
进一步分析“基于课程属性”的特征可以看出,Ckf(wa,wb)特征去掉后影响最大,分类准确率下降了1.86%.Crf(wa,wb)特征影响最小,去掉后分类准确率下降了1.62%,可能是因为这个特征仅分析课程简介中包含的概念,涉及的概念数量较少,所以影响也相对来说较小.
而“基于维基百科属性”的特征中,“基于维基百科分类”的系列特征(Waf)影响较大,去掉此类特征后整体分类准确率下降了5.30%.就单个特征而言,Wkf#(wa,wb)特征影响最大,该特征去掉后整体分类准确率下降了2.77%.另一方面,与相关概念集合有关的特征作用也较为明显,说明使用大量相关概念做辅助以后能够更准确的预测两个课程概念间的依赖关系.
4.5 概念图分析
为了观察不同大学的计算机科学专业课程体系的差异,本文利用课程概念间的依赖关系构建了概念图.图5与图6分别展示了麻省理工学院(MIT)和斯坦福大学(Stanford)的概念图.其中,概念“Computer Science”,“Computer Programming”和 “Mathematics”是被依赖程度较高的几个概念.这也印证了利用维基百科分类层次信息定义特征的合理性,概念越抽象越容易被其它概念所依赖.
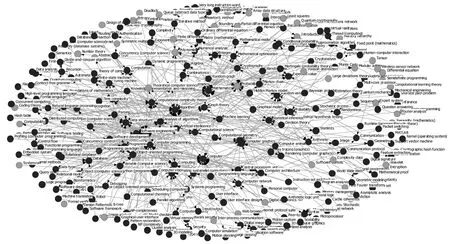
图5 麻省理工学院(MIT)课程中涉及的概念及其依赖关系Fig.5 Concepts and dependencies involved in MIT courses
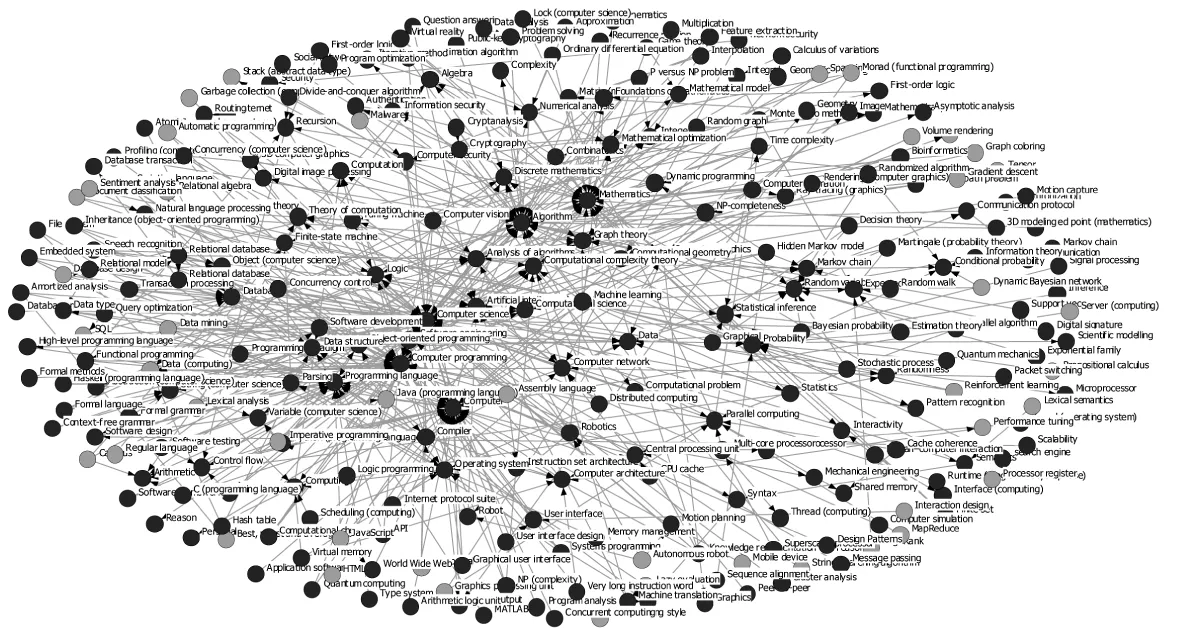
图6 斯坦福大学(Stanford)课程中涉及的概念及其依赖关系Fig.6 Concepts and dependencies involved in Stanford
图5和图6中深色的结点为两所大学的课程中共有的概念,浅色的结点为两所大学的课程中不同的概念.例如“Least squares”、“Finite difference”、“Polynomial”等概念为麻省理工学院课程中独有的概念,“Graph coloring”、“First-order logic”、“Lazy evaluation”等概念为斯坦福大学课程中独有的概念.
仔细分析这些不同的概念,我们发现造成这些不同概念的原因有两方面.一方面是两所学校开设的课程有所区别,例如“Least squares”为麻省理工学院的“Dynamic Systems and Control”这门课程简介中包含的概念,而斯坦福大学的课程集合中并没有这门课程.另一方面,当两所学校的课程的名称相近时,它们的课程简介内容的侧重点会有所不同,例如“Polynomial”为麻省理工学院中“Design and Analysis of Algorithms”这门课程简介中涉及的概念,而斯坦福大学也有一门“Algorithms”课程,但是课程简介中并没有包含这一概念.所以,通过对比不同大学的概念图,可以进一步了解这些学校在课程设置方面的相同之处和不同之处.
5 结束语
本文提出了一种新的课程概念依赖关系挖掘方法,分别利用概念的课程属性与维基百科属性设计特征,实现对课程概念依赖关系的分类预测.课程间固定的学习顺序通常是由它们所包含的课程概念相互依赖引起的,所以课程属性的这些特征有助于识别课程概念间的依赖关系.同样,维基百科中分类层次、用户浏览词条的次序、词条间的链接关系,也都从不同的方面帮助识别概念间的依赖关系.实验结果表明,本文提出的方法相较于现有的其它方法分类准确率更高.除此之外,本文也使用课程概念依赖关系建立了概念图,并举例分析了不同大学在课程体系设置上的差异.
当前,本文使用的公用数据集的数据量较小,未来我们将为更多不同学科专业、不同语言的课程创建可用的概念对数据集,对本文提出的方法进行进一步的验证.此外,我们也将尝试对MOOC、教材等各种类型的学习资源进行分析,抽取其中的主要概念并分析这些概念间的依赖关系.
