代码分发协议中最优分块冗余长度的研究
2022-05-10王宇波施伟斌和梦琪乐燕芬
王宇波,施伟斌,和梦琪,乐燕芬
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
无线传感器网络(WSN,Wireless Sensor Network)是物联网(IoT,Internet of Things)的重要组成部分,近年来得到了广泛的应用[1-3].对于大规模部署的WSN,通过分发协议更新软件能够显著减少系统维护的工作量[4].由于大量WSN节点以电池供电,如何提高通信效率是代码分发协议设计面临的挑战[5,6],不合理的冗余分组设置、环境干扰导致的非必要冗余数据传输和数据重传,是影响分发协议效率的主要因素.
自动重传请求[7](ARQ,Automatic Repeat reQuest)和前向纠错编码[8](FEC,Forward Error Correction)是分发协议中实现可靠传输的两种常用技术.TinyOS中的Deluge协议[9]是典型的使用ARQ的代码分发协议,由于存在较高的控制消息开销,当节点数量增加或链路质量下降时,分发效率较低.喷泉码[10]属于前向纠错编码,该编码具有无码率的特点,控制消息的开销较低,且拥有轻量化编解码算法[11].通信双方可以完全忽视信道删除带来的影响,因此基于喷泉码的代码分发协议通常有较高的鲁棒性.FRP协议[12]和SYNAPSE协议[13]均使用喷泉码作为编码方案,在分块传输结束后SYNAPSE协议设计了错误恢复阶段,利用增量冗余分组使节点从错误中恢复过来.SYNAPSE++协议[14]对于传输每个分块使用固定数量的编码分组,即引入固定分块冗余长度,在典型分组丢失率(PLR,Packet Loss Rate)条件(10%)下,某分块经过一次传输后,接收节点可获得80%以上的解码成功率.但SYNAPSE++协议中固定分块冗余长度的方案在链路质量较差的条件下会导致大量增量传输,从而使分发效率下降.
为了减少分发数据量,一些协议采用差异分发的方法,即仅分发新旧代码镜像文件之间的区别部分,如Incremental协议[15]和TinyCubus协议[16].文献[17]提出了一种新的差异编译技术,通过在重编译时将差异代码打包为增量脚本,以获得区别更小的差异镜像.但通常由于旧指令存储地址连续,为了避免覆盖,插入新指令将引入大量Flash读写操作,从而导致开销急剧增加.利用网络编码可以有效提高网络吞吐量,提高分发效率[18],中继节点可以无代价地将分组转发至下一跳节点.但当缺少中继节点间的协调机制时,可能导致过量冗余数据传输,进而造成分发效率降低.王开云等人[19]对可靠广播/多播理论中概率分布函数进行了近似化处理,得到求解单组数据期望重传次数的高精度近似公式,有助于广播/多播系统精确控制单组数据播发次数,提高系统效率.祝峰等人[20]基于3种可靠多播方案,在考虑分组头开销的条件下,提出确定满足最少传输时间的最佳有效负载长度的方法.其中基于LT喷泉码的多播方案因其可以有效抵抗分组丢失产生的影响而具有最优性能.
本文主要研究基于喷泉码的代码分发协议中最优分块冗余长度的选取方法,理论分析和实验验证结果显示,满足最小通信量条件的分块冗余长度δm应根据分组丢失率大小合理选取.在典型室内干扰条件下,δm与分组丢失率呈正相关,当分组丢失率上升时,增大分块冗余长度能减小分发过程的数据通信量.在此基础上,将自适应调整分块冗余长度的机制引入现有的代码分发协议,实验结果表明,通过动态调整分块冗余长度能明显提高分发效率.
2 最优分块冗余长度的研究
SYNAPSE++协议是唯一源代码公开的、完整实现并可以在实际WSN中运行的基于喷泉码的代码分发协议.实验结果显示,该协议在不同信道条件下,数据通信量变化范围较大,不同规模的网络在运行SYNAPSE++协议时的通信量变化情况如图1所示.
由图1可以看出随着网络中节点数量的增加,分发数据量的均值变化幅度比较平缓.然而对于特定规模的网络,重复进行的实验在通信量方面差别却可能非常显著,例如节点数量为6(不包括Sink节点)的网络,最大数据通信量比最小数据通信量增加了约44%.通信量的增加是由编码分组的增量传输引起的,在分发过程中,编码分组会因存在干扰而丢失,导致不同程度的解码成功率降低,从而引起相应的增量传输,最终造成数据通信量大幅度波动.下面首先对解码成功率与分组丢失率的关系进行分析,然后给出确定最优分块冗余长度的方法.
2.1 分组丢失率对解码成功率的影响分析
设某分块划分为K个源数据分组,对接收节点而言,经过一次分发能正确解码的概率为[14]:
(1)
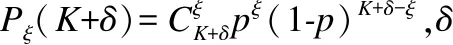
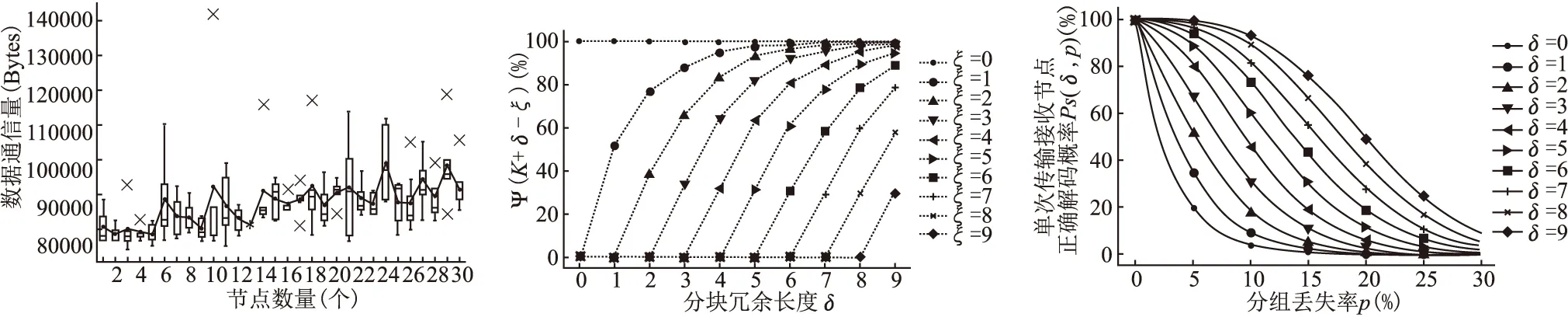
为了得到ψ(K+δ-ξ)近似值,按照SYNAPSE++协议的编解码算法,使用不同δ取值进行了一系列仿真计算,求得每个ψ(K+δ-ξ)所进行的计算次数为10000次(使用更大计算次数得到的结果与图2中结果之间的误差可忽略不计).为了便于将上述仿真结果与实际中SYNAPSE++协议的实验结果进行对比验证,取K=32.图2所示为部分ψ(K+δ-ξ)的计算结果.
从图2可以看出在ξ=5时,分块冗余长度δ从5增大到8,ψ(K+δ-ξ)将从31.7%提高到89.6%.而在ξ=1时,分块冗余长度δ从5减小为2,ψ(K+δ-ξ)由97.9%减少为76.7%.因此,存在少量编码分组丢失时,使用较小的分块冗余长度δ即可获得较大的解码成功率;当编码分组丢失数量增大时,相应增大δ能消除编码分组丢失导致的解码成功率下降.
将ψ(K+δ-ξ)的计算结果带入到公式(1)中,可以得出在任意给定分组丢失率条件下,一个分块单次分发可被接收节点正确解码的概率.图3所示为通过公式(1)计算出的单次传输时接收节点正确解码的概率与分组丢失率的关系,可以看出在相同分组丢失率情况下,增大δ能够使单次传输接收节点正确解码的概率具有较显著地提升.
分块冗余长度的大小与分发过程数据通信量密切相关,减小分块冗余长度能减少传输数据量,但在链路质量较差时容易引起较多的增量传输;增大分块冗余长度能提高单次传输解码成功率,但过量的冗余数据传输可能导致分发效率下降.下面通过分析给出计算数据通信量的方法.
2.2 数据通信量的分析及验证
由公式(1)可得到某分块解码失败概率为:
(2)
由于节点存储资源有限,在实现代码分发协议时通常会设置缓存编码分组的数量上限J,如SYNAPSE++协议中J=50.当对一个分块首次解码失败后,在接收该分块后续编码分组的过程中,如果接收数量达到J,则后续收到的分组将覆盖已接收到的分组.当分组丢失率处于一定范围内(例如≤20%),每次增量传输后,接收到的编码分组总数都能达到J.假定所有接收节点相互独立,对于某分块,经过g轮分发可以成功解码的概率为:
(3)
其中qr(δr,p)为分发次数大于1时某分块解码失败的概率,δr为分发次数大于1时对应的分块冗余长度,δr=J-K,N为接收节点数量.
为便于计算,同时利用喷泉码无码率的特点,取qr(δr,p)≈qs(δr,p),则公式(3)成为:
PR′(g)=(1-qs(δ,p)×qs(δr,p)(g-1))N
(4)
该分块在第g轮解码成功的概率为:
P{G=g}=PR′(g)-PR′(g-1)
(5)
则为了保证可靠传输,该分块被传输次数T的期望可表示为:
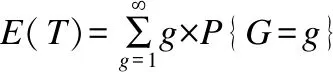
(6)
设代码镜像文件大小为F,分块大小为M,分组长度为L.在整个分发过程中,传输数据量C的期望值为:
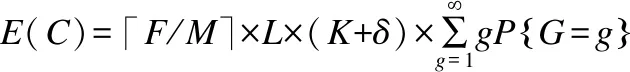
(7)
则可定义最优分块冗余长度为:
(8)
由于ψ(K+δ-ξ)与度分布函数相关,且无法得到其确切表达式,因此由公式(7)得出最优分块冗余长度δm的解析式较困难,可以通过仿真计算的方法确定最优分块冗余长度的取值.图4(a)、图4(b)两图显示了由公式(7)得到的在不同分块冗余长度条件下分发过程传输数据量期望值E(C)与分组丢失率的关系,其中图4(a)为K=32时公式(7)的计算结果,图4(b)为K=48时公式(7)的计算结果.在计算中取PR′(g)≥0.999,近似代替可靠分发,由此计算出保证可靠分发所需的最小轮数并带入公式(7)中得出最终结果.仿真计算参数如表1所示(表中所有参数设置可在实际应用中调整).
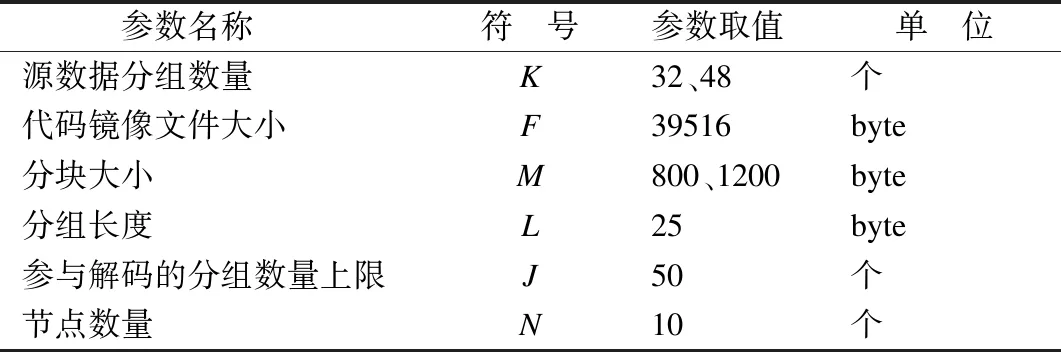
表1 仿真计算使用的参数Table 1 Parameters used in simulation calculation
从图4(a)、图4(b)所示的仿真结果可知,不同分组丢失率条件下,满足最小数据通信量的最优分块冗余长度δm取值不同.例如,对于K=32的情况(如图4(a)所示),当分组丢失率为15%时δm=9,而当分组丢失率为5%时δm=6.在分组丢失率为10%时,选用最优分块冗余长度δm=9分别比选用δ=1和δ=4减少了31.2%和21.5%的数据通信量.因此利用仿真计算方法,对于任意分组丢失率,总能找到满足最小数据通信量的最优分块冗余长度δm.
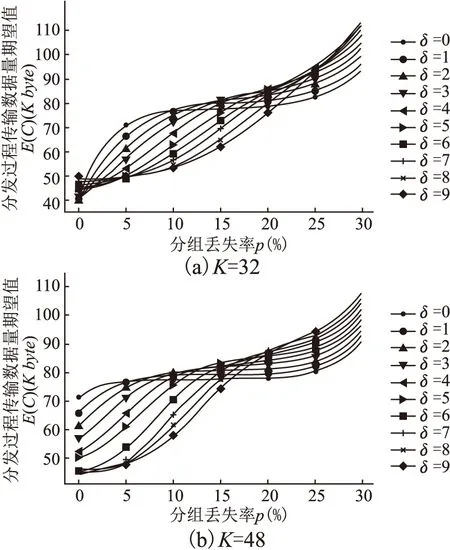
图4 K=32和K=48时E(C)与p的关系Fig.4 Relationship between E(C) and p when K=32 and K=48
为了验证了上述对δm取值计算的正确性,使用真实的节点运行SYNAPSE++协议,在实验室中进行了实验.通过改变代码分发协议中分块冗余长度,在室内干扰环境中进行测试,统计分发过程中的数据通信量.实验中使用无线局域网(WLAN,Wireless Local Area Network)数据传输对WSN进行干扰,设置WSN分组丢失率约为5%(±2%).图5所示为实际环境中实验结果与仿真结果对比,可以看出不同分块冗余长度δ情况下的测量值与理论值基本相符,证明了上述理论分析结果的正确性.

图5 验证实验结果与仿真结果对比Fig.5 Comparison of verification experiment results and simulation results
2.3 基于喷泉码的分发协议的改进
现有的基于喷泉码的代码分发协议在分发过程使用ADV-REQ-DATA范式,即首先由发送节点广播ADV消息,告知邻居节点当前代码镜像文件的分块信息,然后接收节点发送REQ消息请求分发.最后发送节点传输该块镜像.为实现分块冗余长度的自适应调整,对现有系统进行如下修改.
首先,在每个DATA分组(编码分组)中加入序号,该序号在DATA分组成功发送后递增1.接收节点根据收到DATA分组中序号计算实时分组丢失率.该分组丢失率将作为接收节点选取δm的参数.
由图4(a)、图4(b)所示的计算结果可得到在特定分组丢失率范围内满足最小通信量的δm取值.接收节点在求出分组丢失率后,利用查表法得到对应的δm值,并将δm附加到REQ消息中,请求发送节点按照更新的冗余长度分发后续分块.在分发开始前,由于接收节点无法得知当前环境的分组丢失率信息,因此δm的初值设为0.在分发过程中,发送节点可能收到来自不同接收节点的多个包含δm的REQ消息,此时发送节点取所有REQ消息中δm的最大值以保证处于较差链路上的节点的分发效率.
节点解码失败时,将暂存此次解码结果,并且请求该分块的增量传输以便接收到足够数量的编码分组后再次尝试解码.由于存储空间的限制,当接收到的编码分组数量超过上限时,后续收到的分组会覆盖已接收的冗余分组,导致分发效率降低,因此在接收节点请求增量传输前,应根据分组丢失率和缓存空间计算出所需的分块冗余长度δ,然后通过REQ消息向发送节点请求.自适应选取最优分块冗余长度的算法伪代码如算法1所示,其中δR表示接收节点存入REQ消息的分块冗余长度.
算法1.分块冗余长度自适应选取算法
随着社会的发展变化,内部审计的办事方法也从传统的书面文字改成了会计电算化形式,这样一来企业的内部审计工作就更加方便、快捷了。当审计信息化进程逐渐加快之时,也正是计算机成为内部审计工作主流之势。一旦企业内部的审计工作可以逐渐被计算机审计功能替代,就会更加的节省时间,提高办事效率,也能更加方便、快捷地跟其他企业的竞争对手相互对比,找出优势、劣势从而更快地提高工作质量。更严谨地对企业资金及各种资产进行密切跟踪、监视,从而尽快地评估出企业风险的等级指数充分做好事前的准备工作,和事后的审计工作。
1.while dissemination is not over:
2. request a block;
3. receive encoded packets of the block and calculate PLR;
4. if successfully decode the block then
5. selectδmfor next block according to PLR;
6.δR=δm;
8. calculateδRfor incremental transmission;
9. end if
10. putδRinto REQ message;
11.end while
3 实验结果与分析
为了测试自适应分块冗余长度调整机制的性能,将SYNAPSE++协议及其改进版本和Deluge协议移植到以CC2430[21]为核心的平台上,在本校光电楼内的无线网络实验室和9楼办公区域分别进行了实验.实验中,使用相同大小的可执行代码镜像文件进行分发,文件大小38.6KB.所有实验以各节点均正确完成代码更新作为结束条件,并取5次实验的平均值作为实验结果.为便于叙述,将增加了分块冗余长度调整机制的分发协议简称为FDP-VRL(Fountain-code based Dissemination Protocol with Variable Redundancy Length).
3.1 实验室内的测试
为了测试SYNAPSE++协议及本文提出的FDP-VRL在不同信道条件下的性能,使用WLAN数据传输对WSN代码分发产生干扰.WLAN由两台PC机和一台路由器组成,设置WLAN信道与WSN信道相互重叠,并通过改变WLAN速率来产生不同强度干扰,WLAN的通信速率通过jperf软件控制.使用一个CC2531节点配合Sniffer软件[22]侦听WSN数据分组,并保存侦听结果用于后续分析.图6为实验环境示意图.
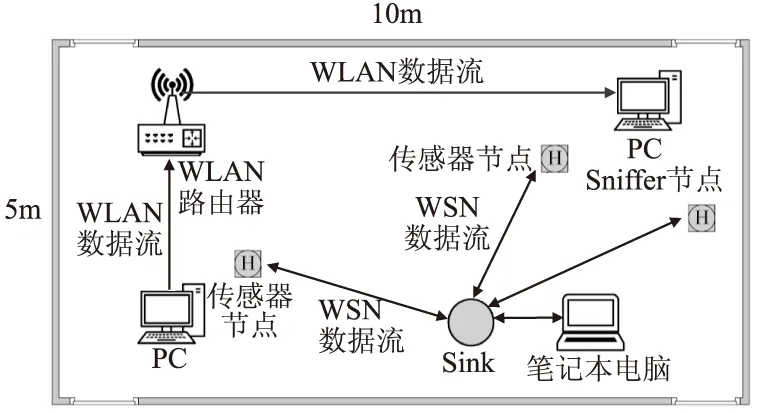
图6 在不同分组丢失率条件下实验环境示意图Fig.6 Experimental environment under different PLR
在实验室内共进行两组测试,分别将1个和2个代码接收节点布置在如图6的环境中.在配置1个接收节点的测试中,设置WSN节点分组丢失率分别为1%(±1%)、3%(±1%)、5%(±1%)、10%(±1%).图7显示了在不同分组丢失率条件下,SYNAPSE++与FDP-VRL在分发过程中传输的编码分组数量对比,可以看出通过加入分块冗余长度自适应选取机制,传输的编码分组数量在1%的分组丢失率条件下减少了约12.1%.值得注意的是,在环境干扰变得更强时,FDP-VRL性能表现更优,在分组丢失率为10%时传输数据分组数量比SYNAPSE++协议减少了14.8%.
在第2组实验中,将两个传感器节点分别放置在两台PC机附近,使两个节点受到WLAN干扰尽可能相互独立(如图6所示),分别设置3%(±2%)、10%(±2%)、20%(±2%)共3种不同的分组丢失率.测试结果如图8所示.当分组丢失率较大时,SYNAPSE++协议完成单个分块分发可能需要较多轮传输,而FDP-VRL能在首轮传输尽可能请求到足够的编码包,即使首轮传输后未能正确完成解码,亦可在后续传输中按照自身接收情况选取合适的分块冗余长度进行增量传输.FDP-VRL在20%的分组丢失率时传输数据分组数量相比SYNAPSE++协议减少了21.7%.
3.2 在实际环境中的性能
图9为9楼办公区域的网络部署示意图,分别设置6个和10个节点进行两组分发实验,在相同条件下分别对Deluge、SYNAPSE++和FDP-VRL进行测试.办公区域的每个办公室中都设有WLAN路由器,与3.1 节中所述专门设置的WLAN干扰相比,实际环境中WLAN数据传输多具有突发性.实验中调整各个节点位置,使它们受干扰的情况尽可能相互独立.
图10为实际环境中数据通信量的测试结果.由于Deluge协议中数据分组负载长度与基于喷泉码的代码分发协议不同,因此将分发过程传输数据分组的字节数量作为评价参数.当使用10个节点时,FDP-VRL相对于SYNAPSE++减少了13.4%的数据通信量,相对于Deluge协议减少了36.6%的数据通信量.图11所示为整个分发过程的总通信量,其中包括控制消息开销.在使用10个节点的实验中,FDP-VRL与SYNAPSE++和Deluge协议相比,分别减少了约15.3%和60.9%的通信量.随着网络中节点数量的增加,FDP-VRL的总通信量增加了8.1%,而SYNAPSE++和Deluge则分别增加了14.8%和47.0%.随着网络中节点数量增多,各节点接收代码镜像进度不同的概率随之增大,同时由于存在突发性干扰,运行Deluge协议的网络控制消息的开销迅速增加,导致分发效率下降.运行 SYNAPSE++协议的网络采用固定的冗余长度,当分组丢失率较高时,解码成功率显著下降,需要更多的增量传输,导致通信量上升.运行FDP-VRL的网络通过实时计算分组丢失率,可以合理选择最优分块冗余长度,在发生突发干扰时使接收节点仍能获得较高的解码成功率,从而减少增量传输,保持较高的分发效率.


图10 传输数据量对比结果Fig.10 Comparison of the amount of data transmitted
图12所示为分发过程经历的总时间对比.将Sink节点发送第一条ADV消息作为分发开始,直至网络中最后一个节点完成代码更新结束,将该过程所经历的时间作为实验结果.从图12中可以看出,对于10个节点的测试结果,FDP-VRL比SYNAPSE++协议完成分发所用总时间减少了约24.0%,相比Deluge协议减少了约85.5%.网络规模由6个节点增大为10个节点,FDP-VRL完成分发的总时间增长了3.1%,SYNAPSE++协议和Deluge协议分别增长了3.9%和30.3%.
4 结 论
本文对基于喷泉码的代码分发协议的最优分块冗余长度进行了研究,理论分析与实验结果表明,最优分块冗余长度与干扰条件相关,在典型室内环境中,当链路质量较好时,较小的分块冗余长度可以得到较少的数据通信量;随着分组丢失率上升,应相应增大分块冗余长度.实验结果显示,通过在基于喷泉码的代码分发协议中加入自适应机制,根据干扰条件动态调整最优分块冗余长度,可以明显减少数据通信量,提高分发速度,从而有利于延长网络生存时间.
