《骆越演义》知识关系可视化系统设计与实现*
2022-05-09黄容鑫黄伟刚孙竞丹
李 航,黄容鑫,黄伟刚,孙竞丹,覃 晓
(南宁师范大学 计算机与信息工程学院;八桂学者创新团队实验室,广西 南宁 530100 )
0 引言
《骆越演义》[1]是一部以世界文化遗产——左江花山岩画为背景创作,描写岭南上古时期王朝兴废、朝代更替,揭开珠江文明和千古花山之谜的大型长篇历史小说。该书以回合制撰写,共一百二十五回,整书对上古时期骆越先民的生存状态和百越文明的历史渊源进行了生动描述,展现了上古时期岭南的政治、军事、经济、文化的发展史,以小说的形式全景式呈现上古珠江流域文明变蛮夷为金戈铁马般的灿烂史诗。
知识图谱[2]是以图的形式表现客观世界中的实体(概念)及其之间关系的知识库。知识是认知,图谱是载体,数据库是实现,知识图谱就是在数据库系统上利用图谱这种抽象载体表示知识这种认识内容。具体地说,知识图谱以结构化三元组的形式存储现实世界中的实体以及实体之间的关系,与通过关键字搜索的方法[3]相比基于知识图谱的方法能够更快速的匹配准确答案。陈蕾等[4]提出的《红楼梦》中社会权势关系的提取及网络构建中利用最小树形图算法生成了涵盖192个《红楼梦》主要人物的单向联通的树状社会关系图,通过这种方法生成的社会关系图能有效反映人际交往亲密度与社会影响力。这种关系图与知识图谱极为相似,说明了用知识图谱来表示人物关系能直观地展现人与人之间的联系。
《骆越演义》是以数个主要人物为中心,辐射大量的战争故事串联而成的小说,其内容人物关系和战争事件关系错综复杂,用知识图谱将这些复杂的关系处理成能够结构化表示的知识,再通过可视化图形展现出来,这样既能高效地查询人物关系,又能宏观地发现事件之间的关联性,更好的帮助理解小说内容。
本研究在自然语言处理的基础上,对小说中人物关系和事件关系进行定义[5],构建三元组,并将这些知识关系可视化[6-9],最后成功搭建一个《骆越演义》知识关系可视化系统,通过可视化的方法对文学作品提出了新的表现形式,使读者可以高效精确地学习和理解小说内容,了解骆越文化,同时促进了我国的优秀民族文化发展。
1 系统的总体设计
基于B/S架构,采用Python语言处理数据和程序的编写,前端由Django应用框架+ECharts[10]图表工具组合,后端使用图形数据库Neo4j,系统的总体架构如图1、图2所示。
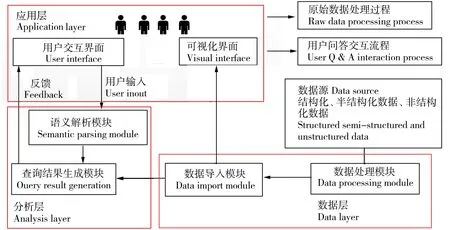
图1 知识可视化系统架构图
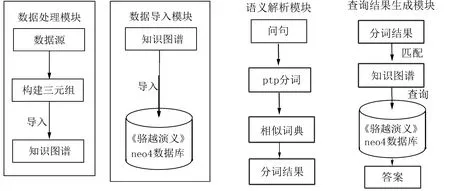
图2 知识可视化系统各模块结构
主要分为数据层、分析层和应用层共3层。数据层负责知识图谱构建和导入数据库,将自然语言文本处理为知识图谱构建所需要的三元组,主要包括2个模块:数据处理模块和数据导入模块;分析层用于对用户的问句进行语义解析,了解用户真实意图并提取答案,主要包括两个功能模块:语义解析模块和查询结果生成模块;应用层包含用户交互界面和可视化界面,用户交互界面实现对人物关系进行查询,并返回查询结果的知识关系图和人物属性,可视化界面展示知识关系全貌图和查询结果。
2 系统详细设计和关键技术
2.1 数据层
2.1.1 数据处理模块
构建知识图谱,本质上是要定义各种实体和实体关系,并建立各个实体关系的联系。对自然语言的文本而言,寻找实体关系,需要分析文档内容,抽取文字或标题的核心概念、关键内容,找到两个实体间可能存在的关系。
本系统主要处理对象是《骆越演义》电子文档。文档是非结构化数据,难以让计算机直接处理。因此在系统数据的预处理阶段,要对非结构化的数据进行结构化转化,即要确定电子文档中的实体和实体关系。
书中大部分章节描写的是战争场景,其中涉及大量的战争场地、战争场景、战争人物、战争爆发的原因、过程和结局等描写。通过仔细研究小说中的战争内容,本研究将关于战争的描写定义为“战争事件”,在战争事件中先定义人物、地点、原因、结果等实体概念,再定义“人物关系”“地点关系”“战争因果关系(简称因果关系)”等关系概念。《骆越演义》小说知识概念性定义描述(表1)。

表1 知识实体及实体关系定义表
完成知识实体及实体关系定义表的建立,下一步基于依存句法分析模型[12.13]对实体和实体关系进行定义。为方便说明构建方法,先对相关概念进行定义和描述。
设小说文本的词汇实体集Entity为E={E1,E2,…,Ek},根据给定的语法体系,确定句子中词汇之间的依存关系,依存关系的集合表示为ERT,定义如下:
定义1句法依存关系对偶表,表示两个实体间的依存关系,记为ERT。
ERT={(Ei,Ej)|i,j=1,2,…,n,Ei,Ej∈E}
基于依存句法分析的小说文本实体关系抽取并构建成知识图谱(Entity relation extraction based on dependency parsing,ER_dp)的方法流程(算法1)。
算法1:ER_dp
输入:小说文本数据Text_data,实体关系定义表R
输出:小说实体关系集S
Step1: 对Text_data进行分词处理得到词汇实体集E;
Step2: 对E进行词性标注;
Step3: 依据词性特征,对Text_data进行依存句法分析,并依据句法依存关系得到句法依存关系对偶表ERT;
Step4: 根据实体关系定义表中的关系ri∈R,在ERT中找到实体的关系链,并合并为三元组;
Step5:S←(Ei,ri,Ej) //关系ri的三元组存放于实体关系集S中;
Step6: 重复step4、step5,直到实体关系定义表中的关系全部处理完;
step7: 返回小说实体关系集S。
对语句“金的长子燮邕跟随獞部落南下逃亡”的依存结构表示,如图3表示。通过依存句法分析得到依存关系ATT(金,长子);DBL(金,的);ATT(长子,燮邕);SBV(燮邕,跟随);VOB(跟随,獞部落);DBL(南下,獞部落);ATT(南下,逃亡)等,其中ATT(金,长子)和ATT(长子,燮邕)存在人物关系“长子”,合并关系链得到一个三元组(金;长子;燮邕)。以三元组的形式可以更好地存储小说中的实体关系。
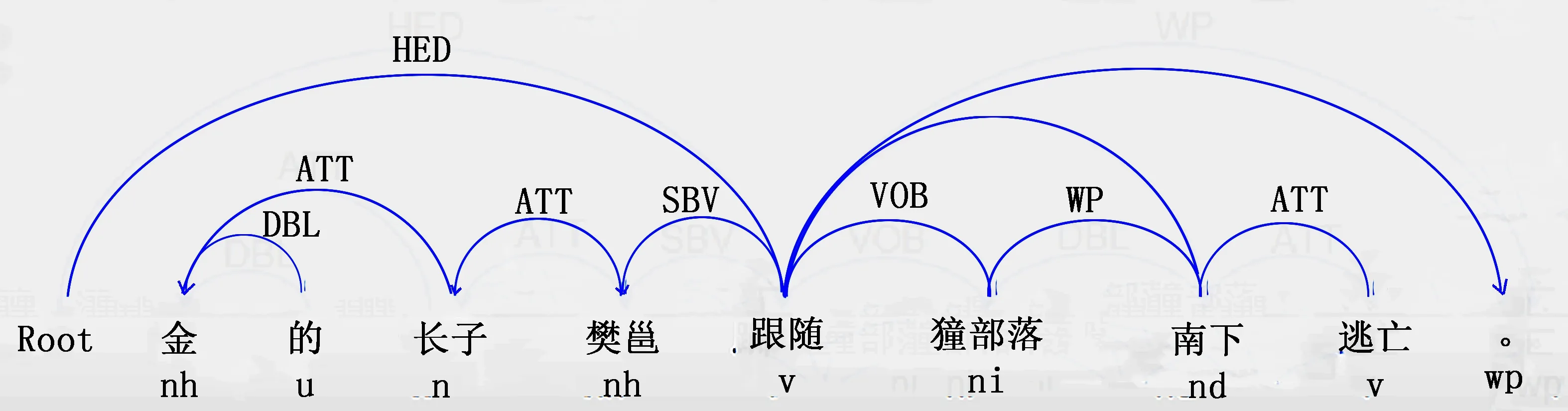
图3 依存树
2.1.2 数据导入模块
本模块完成对系统数据库的设计,主要采用neo4j存储所构建的《骆越演义》知识图谱。neo4j是以图形结构的形式存储数据的数据库,它采用node和relation来存储实体和关系。文中的节点(node)指的是诸如人物、地点、原因或结果等实体,关系(relation)指的是诸如“人物关系”、“战争关系”等。节点(node)和关系(relation)中包含属性(properties),如“燮邕”是一个实体,它具有名字(燮邕),性别(男),职位(护卫队队长)等属性。图3展示了本研究的数据存储模型,其中节点(node)和节点的属性(properties)存储于一个链表中,而节点和关系(relation)则使用一个双向链表来存放。从图4中可以看出,通过关系可以方便的查看跟这个关系关联的两个实体(node1和node2),并且从一个节点node1开始,可以直接遍历以该节点为起点的图。图5展示了在neo4j中存储的部分节点(node)和关系(relation)的链表表示。

图4 neo4j的数据存储模型 图5 部分人物关系链
本研究的neo4j存储数据的方法(算法2)。
算法2:DataToNeo4j
input df_data //df_data 是存储三元组的数组
output node and symbolic link relationship
Step1: create_node(e1,e2) //创建节点node
Step2: for name ine1,e2
Step3: create_relation(df_data) //创建边/关系
Step4: for m in range(0,len(df_data)) //遍历数组
Step6: match a,b where a=e1and b=e2//匹配关系的两节点
Step7: create a → b
Step8: end for
Step9: end for.
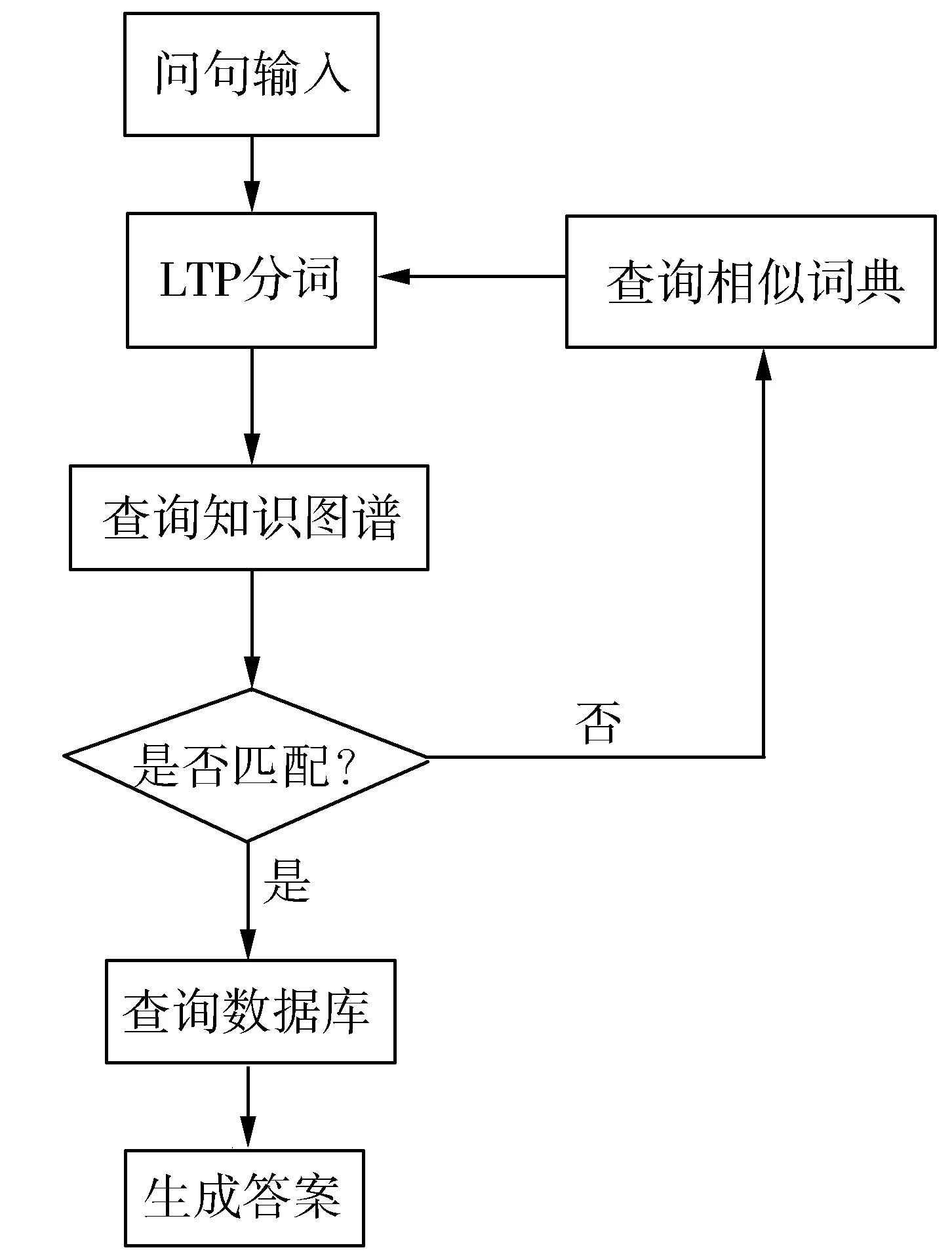
在算法2中,输入是前一节生成的三元组数组{(ei,rt,ej|i,j=1,2,…,n;t=1,2,…,m;m 分析层的关键作用是将用户输入的自然语言准确分词,这样才能提高反馈答案的正确率。本研究的人物知识查询的具体流程图如图6所示,当用户输入问句,经LTP分词模型后查询知识图谱,若能够匹配,则直接查询数据库,若不匹配则查询相似词典再重新经LTP分词,将新的分词结果映射到知识图谱中,并从数据库抽取答案。 图6 知识查询流程图 2.2.1 语义解析模块 本模块是人物知识查询的主要技术支撑,主要完成对用户输入的问句中单词的词性进行判断,功能的实现是借助哈工大开源LTP分词模型和本研究根据《骆越演义》构建的相似词典共同完成。 由于LTP模型只能处理一些日常的词语,而《骆越演义》是描述的是特定民族文化的语言文本,一些人名类的词语不一定能准确分词,而分词不准确,那么词性标注也会出错,例如,人名“黎修”,如果把它拆分成“黎”和“修”就不能标注成一个人名了,这样就必然会影响返回结果的正确率。所以,增加一个相似词典,将《骆越演义》中涉及所有的人名、所属部落都加入相似词典里。首先构建了m个数组X={x1,x2,…,xn},m表示相似词典中的实体数,n表示相似词的个数;然后将数组X中的词映射到同一个实体Z,得到集合S={Z1,Z2,…,Zm},S表示为相似词典;将S加入LTP的分词库中再对问句进行分词处理;就能增加分词查询的正确率了。 总之,学校的安全教育无小事,孩子们的安全更是牵动着千家万户。 因为学校不仅仅是学习知识的摇篮,更应该是学生健康平安成长的乐园。让我们用心与情来共织一张安全教育之网,让社会、学校和家长共建一道安全防护栏!让娇艳的生命之花越开越芳香灿烂! 2.2.2 查询结果生成模块 本模块负责将语义解析模块获得的分词结果映射到知识图谱中查找对应实体,然后匹配数据库生成答案并反馈到前端展示界面。 应用层向用户提供交互式的知识查询功能,允许用户以问句的方式向系统进行条件查询和知识浏览功能。 2.3.1 知识概览查询 知识概览查询是指向系统提出浏览知识图谱的请求,系统将展示《骆越演义》小说内容的全部知识结构。实现方法是在《骆越演义》知识图谱中,调用Cypher查询语句‘MATCH (n) return (n)’,n表示知识图谱中的实体,该语句可以返回所有数据,即《骆越演义》知识关系的全貌图。如图7展示了其中7个部落的知识关系全貌图。 图7 部分知识关系可视化全貌图 2.3.2 条件查询 条件查询是指用户在系统界面输入查询语句,系统调用分析层的语义解析模块,理解查询语句的语义,并从数据库中查找与查询语义匹配的知识结构,返回到系统前端ECharts可视化图表工具中。实现方法是对用户输入问句进行LTP分词并对结果调用语句: ′MATCH(n:el)-[re:r]->(s)returnn,re,r′,其中n表示问句的实体,el表示实体名称,re是实体间的关系,关系名称为r,通过查询和实体el具有关系r的实体并返回结果。如图8中展示了当用户问“金的长子是谁?”,本系统通过匹配知识图谱找到答案“燮邕”并展示“燮邕”的部落、性别、人物关系、职位和“燮邕”与“金”的人物关系图。 知识图谱是以图的形式表现客观世界中的实体(概念)及其之间关系的知识库。利用知识图谱来表示人物关系能直观地展现人与人之间的联系。《骆越演义》是一部人物关系和战争事件关系错综复杂的大型小说,为了更充分地展示小说中人物和事件关系,设计并实现了对《骆越演义》的知识关系可视化系统。本研究的工作包括:提出了一种基于依存句法分析的小说文本实体关系抽取并构建成知识图谱的方法;对战争历史类小说构建了一套实体关系定义表。在LTP中加入相似词典提高分词准确率;应用ECharts对人物和事件关系可视化。本研究不足之处在于构建的实体关系定义表方法效率比较低,如何提高方法效率,高效地抽取数据是下一步的研究方向。2.2 分析层
2.3 应用层

3 结 语
