基于多源辅助信息的推荐算法研究*
2022-05-09庞健婵闭应洲武文霖王志远邓超文
庞健婵,闭应洲,杨 辉,武文霖,王志远,邓超文
(南宁师范大学 计算机与信息工程学院,广西 南宁 530199)
0 引言
随着互联网时代的到来,网络上各个服务平台的信息呈现爆炸式的增长。用户在网上选购商品时需要花费大量的时间来寻找自己喜欢的物品,这往往会导致用户的体验较差。为了解决这个问题,科技人员们不断研究更有效的推荐算法,在用户需求不明确的情况下,推荐算法可以为用户挑选他可能喜欢的物品,相当于模拟一个销售帮助客人完成购买的过程。判断一个推荐算法好坏的关键,就是看它能否为用户提供个性化的推荐,为用户推荐感兴趣的物品,提升用户体验。
协同过滤推荐算法是目前应用广泛,也是最经典的推荐算法,这种算法又分为基于用户的协同过滤[2]、基于物品的协同过滤和基于模型的协同过滤。基于用户的协同过滤推荐算法是找到有相似喜好的用户来做推荐,基于物品的协同过滤推荐算法是找到相似的物品进行推荐;基于模型的协同过滤是用机器学习的方法来建模,根据用户的历史记录来做出预测和推荐。矩阵分解算法[3](Matrix Factorization)基于矩阵补全的方法来做评分预测,它在2007年的Netflix发起的Netflix Prize百万美金竞赛中取得很好的表现,自此受到人们的关注,但是矩阵分解仍然存在数据稀疏和冷启动问题[2]。为此,多源异构数据随之被[1]被引入到推荐系统中,比如相关的标签、文本、图片等数据;另外,将多源异构数据进行混合引入也引起了科研人员的关注。在多源异构信息难以融合的时候,又引入了知识图谱(Knowledge Graph,KG)[4],它以图的形式将人类知识进行了表示。在推荐算法中引入知识图谱,可以获得更多的语义关系和结构关系,从而可以深层次地挖掘用户潜在的喜好,还可以获取更多种类的关联,这有助于避免推荐结果的单一性;同时可以将用户的历史记录和推荐结果联系起来,为推荐提供可解释性,提高用户的使用体验。
KGCN是Hongwei Wang[5]在2019年提出的推荐系统模型,该模型通过知识图谱来捕获邻居实体,将邻居实体与项目本身实体结合起来,这样获得的向量可以捕获物品端的高阶结构信息和语义信息,这些丰富的物品信息可以有效表示用户潜在的兴趣。KGCN在预测点击率方面获得了很好的效果,但它仅使用了物品端的信息,忽略了用户端信息。本研究将用户的相关信息添加到模型当中,将特征组合后作为用户信息的高阶接受域,最后用这些信息与用户实体结合起来作为用户的向量表示,以此来提升推荐系统的性能。
将用户的额外信息引入并进行组合,如“中年(年龄)男性(性别)”“销售(职业)中国(地址)”等这样组合特征来表示用户,建立起来用户和物品之间的非线性联系。性别为男性的中年人喜欢看科幻类型的电影,还有性别为女性的青年喜欢看恋爱题材的电影。通过观察大量的样本数据可以发现,某些特征经过关联之后,与推荐结果之间的相关性就会提高。
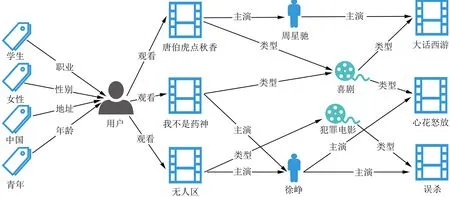
图1 用户属性和用户偏好电影图
1 相关工作
1.1 基于知识图谱的推荐算法
近年来,在推荐系统中引入知识图谱作为辅助的信息取得了很好的成效。在电影推荐中,如将电影的导演、类型、演员、产地等物品的属性添加到模型中丰富物品的表示,可以更加准确地反应出物品的本质特征,因此模型可以更加准确地为用户做推荐。知识图谱是一个有向的异构图,在知识图谱中物品作为实体,实体之间用边来连接,边表示的是物品之间的关系,这样物品与物品之间的关系就能在知识图谱中得到表示。在推荐算法中引入知识图谱后丰富了物品信息和表示,可以更好捕捉用户的偏好,提高推荐的效率。基于知识图谱的推荐系统[8]包括基于路径的方法、基于Embeddig的方法[9-11]和混合的方法3种。
Yu X,Ren X等[12]在2014年提出的HeteRec模型和Zhao H,Yao Q等[13]在2017年提出的FMG模型都是基于路径的方法。随着信息技术的发展更多信息被挖掘和使用,因算法数据的稀疏和推荐算法效果受限等原因,研究人员将多源异构信息引入到推荐系统中。Fuzheng Zhang等2016年提出了CKE模型,该模型将文本信息、图片信息和知识图谱等多种异构信息融合到知识表示当中来丰富物品的表示,学习出用户表示和物品表示以此计算出用户点击物品的概率。CKE模型是一个基于Embeddig的知识图谱推荐方法,类似的还有Hongwei Wang在2018年提出的DKN推荐模型等。
混合的推荐方法有Hongwei Wang等[14-16]在2018年提出的RippleNet模型,该模型是Wang提出的基于知识图谱的神经网络模型,类似的模型还有Hongwei Wang在2019年提出的KGCN模型等。
1.2 特征交叉推荐模型
在早期的CTR算法是使用广义线性模型来计算用户的点击率,但没有将特征进行交叉组合和筛选,这样有可能造成信息丢失。POLY2模型将所有的特征进行两两交叉组合,且给特征组合赋予了相应的权重,POLY2模型特征组合的方式考虑了特征和特征之间相互作用的问题。POLY2模型的本质还是逻辑回归模型,也就是线性模型,针对POLY2模型存在的问题,又推出了FM(因子分解机)模型。FM模型使用的梯度下降学习方法,它对特征进行交叉组合后的特征赋予单一的权重,这就解决了POLY2模型直接交叉带来的数据稀疏的问题,使每个特征更容易被学习。FM模型具有较高的泛化能力,在处理较小数据和稀疏数据时会较高的利用价值。在特征交叉模型中的两个特征交叉组合如矩阵所示,这样的特征组合起来建立与推荐结果的联系就是特征交叉模型的重要思想。

属性性别职业年龄地址性别性别×性别性别×职业 性别×年龄 性别×地址职业职业×性别职业×职业 职业×年龄 职业×地址年龄年龄×性别年龄×职业 年龄×年龄 年龄×地址地址地址×性别地址×职业 地址×年龄 地址×地址
2 FMKGCN模型
2.1 FMKGCN问题定义
为了方便描述,给出如下定义,在推荐系统中存在着用户u和项目v,用户集用U={u1,u2,…,un}来表示,项目集用V={v1,v2,…vn}来表示。用户和项目的交互矩阵定义为Y∈RM×N,如果用户u对项目v有点击、购买或者评分行为等隐性反馈行为则yuv=1,反之那么yuv=0。
除了有用户和项目的交互矩阵,在这个模型中还包括了知识图谱G,知识图谱是为了描述实体与实体之间的关系,一般实体通过这样
模型的最终目标是预测一个用户u对没有过交互的物品v是否有兴趣。设置了一个函数yuv来预测用户u点击物品v的概率,函数定义为yuv=F(u,v|Θ,Y,G),其中Y表示的是用户和项目的交互矩阵,G表示的是知识图谱,Θ表示模型参数。
2.2 模型描述
FMKGCN模型结构如图2所示,右边的物品端模块输入的是知识图谱和物品的实体,经过KGCN卷积层来捕获物品相近的邻居实体将这些实体作为高阶接收域,计算出物品和邻居实体之间关系的分数,最终把这些信息结合起来并作为物品端的属性显示出来。

图2 FMKGCN模型框架
在图2的左侧是用户端模块,该模块输入的是用户和用户额外的信息,将这些特征交叉组合学习出这些信息之间隐藏的关系,将信息组合起来作为用户的向量表示(图2的中间模块)。输入用户向量、物品向量和评分矩阵,最终从预测评分的函数Y=F(u,v)中得到模型的预测结果。
2.2.1 KGCN层聚合物品向量
通过自动捕获知识图谱中的高阶结构和语义信息来挖掘用户潜在的兴趣爱好。在知识图谱中找到项目v对应的实体,捕获并存储每个实体的局部邻接结构,根据用户u对关系r的得分对邻居进行加权。为了方便描述,对一些符号进行定义,N(v)表示的是和v连接的实体集合,rei,ej表示的实体ei和ej的关系,函数g∈Rd×Rd→R用来计算用户u对关系v的分数,表示为:
(1)
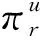
得到用户u对关系r的评分后,计算近邻e对项目v的重要性的算式为:
(2)
将用户u-项目v的近邻评分进行归一化:
(3)
根据每个用户对关系的评分不同,计算出项目v的近邻e对特定用户的分数。
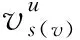
(4)
式(4)中,w表示的是权重,b表示的是偏置项,σ表示的非线性函数,如ReLU。
2.2.2 特征交叉方法学习用户向量
用户的向量表示用特征交叉的方法来学习,借鉴FM(因子分解机)算法的思想,将特征两两组合进行学习,与FM算法不同的是将式(4)进行变形,去除了特征的权重得到新的算式为:
(5)
aggFM(e)表示在节点e处的向量聚合,n就代表节点e的邻居数量,xi与xj分别代表节点e的第i与第j个邻居节点向量,假设该向量的向量维度为dim。本研究采取的是两两邻居向量全元素相乘计算方法,而不是点乘。因为要让输出的向量维度限定在dim,这样直接可与节点向量同维度。
将用户u向量聚合以后,还有通过一个线性变换才能获得最终的向量表示,算式如下:
(6)
2.3 算法步骤
算法 FMKGCN算法
输入:交互矩阵Y,知识图谱G
输出:预测函数F(u,v,Θ,Y,G)
1.初始化所有参数
2.For 训练迭代次数 do
4.eu[0]←e,∀e∈W[0]
5.for h=1,...,H do
6.for e∈W[h] do
9.vu←eu[H]
12.梯度下降更新参数
13.return F
14.捕获项目v的邻域实体
15.W[H]←v
16.for h=H-1,…,0 do
17.W[h]←W[h+1]
18.for e∈W[h+1] do
19.W[h]←W[h]∪S(e)
3 实验及分析
为了验证FMKGCN模型的推荐效果,实验所需平台搭建的硬件条件如下,CPU型号 i5-5200U 2.20GHz,内存12.0GB,显卡使用的是AMD R5M230。软件环境如下,操作系统使用的是Win10 64位操作系统,实验平台使用的是TensorFlow,Python 3.6版本。
3.1 数据集
为了评估模型的推荐效果,在MovieLens-1M的数据集上进行实验,这个数据集包含有6036个用户对2347部电影的75多万条评分,也包含有电影元数信息和用户的属性信息,用户的属性信息有用户的性别、年龄、职业和邮编。这个数据集真实存在且已被用于推荐系统。
本研究的知识图谱采用了MKR模型论文[16]所构建的知识图谱。图谱中的每个实体对应代表的是MovieLens-1M数据集中每部电影。KG的三元组数为20195组,KG实体数是7008个,KG关系数是7种。
在MovieLens-1M数据集中,每个用户都会有超过20条评分,评分为1~5分。由于模型的目的是探索用户潜在的偏好,所以,当设置用户给电影的评分≥4分时,视为用户对该电影喜爱;反之,评分<4分则视为用户对该电影没有兴趣。为了更好地运算和记录,创建一个用户-物品的评分矩阵。矩阵把用户对一部电影感兴趣标记为1,不感兴趣标记为0。
3.2 对比模型
为了验证FMKGCN模型的推荐效果,模型进行如下对比:
KGCN:一种由wang提出的基于知识图谱的图卷积网络模型,将物品的邻居作为高阶接受域,聚合和物品和物品的高阶信息,探索用户潜在的偏好,从而为用户做出推荐。实验中模型的参数设置与模型设置相同。
KGNN-LS:这是一个基于KGCN模型的增加正则项的模型,模型在学习的过程中对边缘进行正则化,实现了更好的优化效果。Ls_weight的值等于1,其他值与本模型设置的值相同。
CKE:一种融合了知识库的结构化内容、文本内容和图片内容的模型,使用了embedding来提取语义特征的推荐算法。实验参数设置与原论文参数一致,本研究的实验数据引用MKR论文的CKE模型实验结果。
FMKGCN:在物品端使用特征交叉方法来进行特征组合并聚合信息得到物品端向量表示,在用户端用KGCN图卷积层来聚合信息得到用户端向量表示的推荐算法。
3.3 实验评估指标及实验设置
实验将数据以6∶2∶2的比例分为训练集、验证集和测试集。实验的所有结果经过每个实验运行5次取平均值。用来评估模型点击率(CTR)使用的指标是AUC和F1,用来评估模型模型在Top-K中的推荐性能使用的是Precision@K和Recall@K两个指标,其中K的取值分别有2,5,10,20,50。
在实验中,CKE取值与原论文取值相同,其他模型的参数设置为:维度dim设置为32维,迭代次数n_epochs设置为10次,集合层数n_iter设置为2层,数据集batch_size设置为1024,正则化系数l2_weight设置为0.000001,学习率lr设置为0.02,近邻数neighbor_sample_size设置为4。
3.4 实验结果分析
3.4.1 CTR预测对比
为了验证模型,将模型与其他模型在相同的实验环境下运算,CKE使用了原来的参数,运算结果见表1。FMKGCN模型较KGCN模型在AUC指标有了1.3%的提升,在F1指标上提升1.7%。FMKGCN算法在AUC和F1的结果都优于其他基准算法,由此可见,FMKGCN算法推荐性能的优越性。

表1 CTR预测实验结果
3.4.2 Top-K推荐对比
FMKGCN模型与各基准算法的Precision和Recall指标对比,K分别取2,5,10,50时各个模型的实验结果,如图3、图4所示。

图3 TOP@K推荐的精确率 图4 TOP@K推荐的召回率
从图3、图4可以看出,FMKGCN在MovieLens-1M数据上的表现是最优的;在Precision的指标里,当K=5时本模型较KGCN算法提升了2.36%,较KGNN_LS算法提升了2.1%。在Recall指标中,当K=5时,FMKGCN模型较KGCN算法提升了1.76%,较KGNN_LS算法提升了1.8%。实验结果表明,FMKGCN模型相较于其他模型有更优的结果。
4 结 语
实验表明,FMKGCN模型在MovieLen-1M数据集上取得了良好的推荐效果,这说明模型的优越性。本研究的贡献主要有:(1)引入用户的额外的辅助信息,将这些信息进行特征的交叉组合并结合用户自身信息来获得用户向量的表示,用KGCN卷积层来学习物品向量的表示;(2)提出了一个新的混合模型框架;(3)在真实数据集MovieLens-1M上应用,推荐效果有所提升。
本研究利用知识图谱的中物品端的异构信息进行聚合,丰富物品端的表示,用特征交叉的方法聚合用户端信息,通过模型的训练和学习,将物品表示和用户表示带入得分函数来计算用户对物品评分,预测出用户的点击率。在未来的研究中,推荐系统可以使用特征交叉模型来做更多的信息聚合,还可以加入知识图谱等异构信息来丰富用户或者物品的向量表示,构建更加准确和有效的推荐系统。
