基于典型窃电用户相似性检索的窃电行为检测方法
2022-03-23覃华勤郭思佳马先芹郭崇慧
覃华勤,梁 叶,钱 奇,郭思佳,马先芹,郭崇慧
(1. 北京科东电力控制系统有限责任公司,北京市 100089;2. 大连理工大学系统工程研究所,辽宁省 大连市 116024)
0 引言
全社会的用电量不断增加,社会中违约用电、窃电等现象屡禁不止,给企业经营管理以及供电秩序的规范化带来严重的威胁[1-2]。分析用户用电特征以识别潜在的窃电用户,提高专业人员现场稽查窃电用户效率,是目前窃电检测的研究重点[3-4]。
时间序列相似性量度是时间序列数据挖掘的重要工作之一[5],对窃电模式分析和窃电用户检测有着重要的作用[6]。文献[7]发现线损电量序列和窃电用户用电量序列有正相关关系,曲线形态有一定的相似性。文献[8]利用3 种量度距离来计算负荷时间序列和异常馈线线损曲线之间的时域相似性,锁定窃电用户。文献[9]提出一种改进分段线性表示日负荷曲线,并结合动态时间弯曲(dynamic time warping,DTW)距离来量度相似度,提升电力数据聚类质量。尽管当前研究对电力时间序列数据的相似性量度进行了分析和探讨,但对用户的多指标、不等长的用电数据的相似性量度研究仍然比较少。因此,如何计算多指标、不等长的用电时间序列数据的相似性,是当前窃电用户识别研究的关键问题。
聚类分析是电力数据挖掘领域的重要手段,目前,聚类方法在窃电分析中得到了充分的研究和应用[10],对电力用户的划分越细致,越有助于窃电用户的聚焦和定位[11-13]。文献[14]对用电信息系统采用离群点算法达到检测窃电行为的目的。文献[15]通过基于网格的聚类方法得到排序的用电异常度,具有一定窃电检测效果。文献[16]提出基于密度的聚类和局部离群的方法,综合分析用户的异常用电得分。文献[17]对负荷数据进行降维,利用高斯混合模型进行聚类,不仅可以多维度分析楼宇的负荷数据,还为窃电分析提供一定依据。文献[18]利用近邻传播(AP)聚类对窃电检测出的工商业用户的负荷特征数据进行聚类,对其经营状态进行二次分析,以降低误报率。在窃电检测的工程实践中,因用户规模较大且用电特性较多,直接通过聚类方法对用户进行分类检测窃电行为的实用效果存在较大局限性。
从实际场景和工程应用出发,利用多指标、不等长的用电数据来挖掘与窃电用户用电曲线形态相似的用户,并通过DTW 来量度多指标的时间序列相似性;为了缩小窃电排查范围以提高检测准确度,本文利用基于DTW 的聚类分析来挖掘典型窃电用户,结合典型窃电用户特征来进一步检索待排查疑似窃电用户。
1 窃电行为检测方法框架
本文提出典型窃电用户发现与窃电用户相似性检索方法,利用多指标窃电数据来挖掘企业积累的典型窃电用户,并在海量数据中进行典型窃电用户相似性检索,综合考量不同指标下数据的波动形态,结合人工经验查找出与典型窃电用户用电行为相似的疑似窃电用户,方法总体框架如图1 所示。
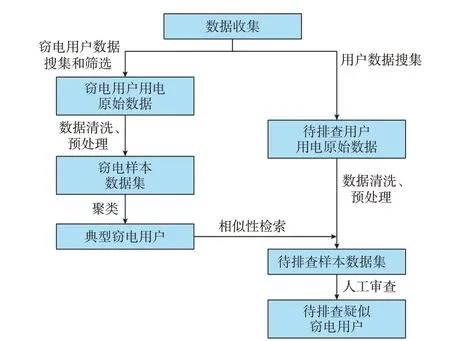
图1 窃电行为检测方法总体框架Fig.1 Overall framework of detection method for electricity theft behavior
在数据搜集环节,对历史窃电用户的数据进行搜集和筛选,包括对数据进行准确标记、窃电手法的判断等。待排查用户数据则收集其用户群的用电数据,并对收集到的数据进行清洗和预处理,提升数据质量。对窃电样本数据集进行聚类分析,得到典型窃电用户,利用典型窃电用户在待排查样本数据集中进行检索,再利用先验知识对嫌疑用户进一步分析审查,得到最终的待排查嫌疑用户。
在现实情况中,经过现场窃电排查人员的实际排查[19]后,一旦确认窃电行为,则在系统中标注该用户为窃电用户;反之,未经过标注的用户则视为待检查的“正常用户”。窃电用户的标注获取难、数据集类别不平衡、样本干扰等问题,给企业人员的分析排查工作带来一定的困难,若分析人员事先得到典型窃电用户,可以利用典型窃电用户做后续的分析。
2 典型窃电用户发现方法
2.1 DTW
受用户采集数据频度及质量影响,用户数据长度和时效性存在较大差异。实际情况造成的数据缺失及不等长,为用户的相似性量度带来了一定困难。DTW[20]是时间序列相似性量度中的常用方法,对时间序列的不等长、偏移、振幅变化等情况具有较强的鲁棒性[21]。欧氏距离与DTW 量度时间序列的效果如附录A 图A1 所示。由图A1 可知,DTW 可以很好地匹配不等长时间序列的形态,因此本研究采用DTW 来量度2 个用户的电力时间序列相似性。


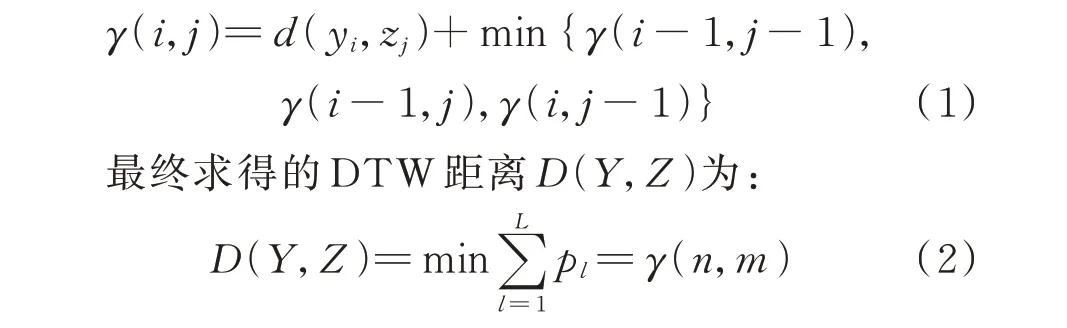
针对专变用户之间的DTW 距离计算方法如下。
因电压和电流数据存在A、B、C 这3 个相序,本文提出量度2 个专变用户之间的DTW 距离为电量、电流和电压的加权平均值。给定专变用户的电量数据集Q={q1,q2,…,qN}、电流数据集I={i1,h,i2,h,…,iN,h}、电压数据集U={u1,h,u2,h,…,uN,h}(N为样本个数,h={A,B,C}),则利用式(2)计算电量距 离DQ=D(qs,qt)、 电 流 距 离DI=∑D(is,h,it,h) 3,h={A,B,C} 和电压距离DU=∑D(us,h,ut,h) 3,h={A,B,C},其中s≠t。计算总距离Dtotal为:
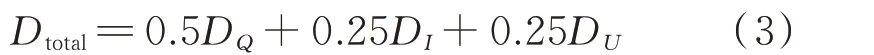
2.2 AP 聚类
AP 聚类具有事先不需要指定聚类中心及其数目、聚类速度快、错误率低的特点[22]。所有的数据点作为潜在聚类中心,通过迭代相互传递的数据点之间的代表度和有效度信息来选择代表点直至得到稳定的聚类结果。AP 聚类已广泛应用于电力、基因数据检测等多种领域[23]。代表度r(i,j)和有效度a(i,j)的初始值均设为0,经过以下公式进行迭代更新。
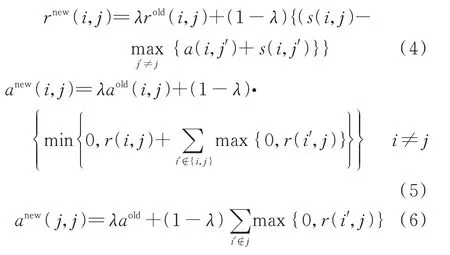
式中:上标new 和old 分别表示迭代前和迭代后对应的变量;r(i,j)表示点xj对点xi的代表度;a(i,j)表示点xj对点xi进行代表的有效程度;s(i,j)为点xi与xj之间的距离;λ为阻尼因子,为了避免在聚类过程中发生振荡,一般λ取值在(0.5,1)时可以增强聚类算法的稳定性[24]。
最后,选择代表度和有效度之和最大时对应的值作为簇中心ci,即
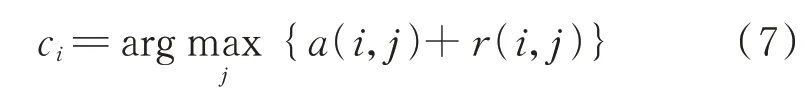
传统的K-means 聚类方法需要指定聚类数目且以簇成员的均值作为簇中心,簇中心是“虚拟的”点。AP 聚类是通过不断进行消息传递来自动确定稳定的簇,簇中心则是具体的样本点,具体如附录A图A2 所示。
2.3 基于DTW 的窃电用户AP 聚类
数据清洗和预处理之后,进行以DTW 为相似性量度方法的聚类分析,方法如下。
算法为基于DTW 的窃电用户AP 聚类。输入窃电用户电量数据集Q={q1,q2,…,qN}、电流数据集I={i1,h,i2,h,…,iN,h}、电 压 数 据 集U={u1,h,u2,h,…,uN,h}。输出聚类结果{C1,C2,…,CK}及其簇中心{c1,c2,…,cK}(ck∈Ck;k=1,2,…,K)。
步骤1:对窃电用户样本数据集Q、I、U进行数据清洗、预处理。
步骤2:对于居民用户,利用式(2)计算电量距离DQ=D(qs,qt),其中s≠t,且s≤N,t≤N。对于专变用户,利用式(3)计算总距离。得到最终的相似度矩阵S。
步骤3:利用相似度矩阵进行AP 聚类,得到K个簇{C1,C2,…,CK} 及其簇中心{c1,c2,…,cK}(ck∈Ck;k=1,2,…,K),簇中心即为典型窃电用户。
3 窃电用户相似性检索
时间序列数据挖掘中,时间序列相似性检索是一项基本操作,也是研究的热点问题之一[25]。传统的反窃电分析方法已经逐渐不能满足处理海量、复杂的用电数据。因此,本文研究提出根据典型窃电用户进行相似性检索,具体方法如下。
算法为典型窃电用户相似性检索方法。输入待检索的正常用户样本电量数据集Q={q1,q2,…,qN}、电流数据集I={i1,h,i2,h,…,iN,h}、电压数据集U={u1,h,u2,h,…,uN,h}、典型窃电用户{c1,c2,…,cK},检索相似用户的个数为H(H<N)。输出相似性检索结果S={s1,s2,…,sKH},(sg∈Q,g=1,2,…,KH)。
步骤1:对于居民用户,选择典型窃电用户ck,利用式(2)计算ck与待检查正常样本用户的DTW 距离,得到N个距离值;对于专变用户,选择典型窃电用户ck,利用式(3)计算ck与待检查正常样本用户的总距离,得到N个距离值。
步骤2:对N个距离值从小到大进行排序,选择前H个用户作为待排查的嫌疑窃电用户。
步骤3:重复步骤1 至步骤2,直至所有典型窃电用户在电力系统中检索完毕,最终得到KH个待排查嫌疑窃电户。
为更好地理解DTW 在窃电检测中的效果,从大型专变窃电用户群中选择其中一户(该用户为某省供暖企业),利用DTW 在窃电样本中检索的大型专变窃电用户来初步检验是否能够检索出形态相似的用户,结果如附录A 图A3 所示。从图A3 可以发现,利用DTW 可以发现具有用电相似形态的用户。经核实历史窃电工单可知,检索出来的前2 位窃电用户也为供暖单位。这说明DTW 适用于根据指定用户用电行为曲线检索出更多待排查的用电曲线相似且可能异常用电的用户。
DTW 可以量度不等长时间序列,但DTW 在窃电检测的工程应用中有一定的适用条件:1)DTW具有较高的时间复杂度,用户用电曲线越长,则相似性检索所消耗的时间越多,因此需要人工控制检索数据的范围;2)DTW 量度用户用电曲线的整体形态有一定的优势,但较难准确捕捉细节特征,因此某些场景下需要对数据进行二次加工,构建不同粒度的时间序列来进行检索,而不是仅仅使用原始数据;3)DTW 无法充分考虑曲线的时效性,一般需要人工选定排查的时间段;4)DTW 是相似性量度方法,无法直接对量度结果进行解释,结果的分析和解释仍然需要人员参与。
4 实验及分析
为验证本文方法的可行性和有效性,本研究基于某省用电信息采集系统中的大型专变用户、居民用户的真实用电数据进行实验。样本数据集中,大型专变的窃电用户数与正常用户数分别为44 和134,居民的窃电用户数与正常用户数分别为283 和694。本文研究将数据集按下述方式进行划分,并进行相应的实验与方法评估。
1)按70%的比例随机抽取窃电用户,即30 个大型专变窃电用户和200 个居民窃电用户来进行典型用户发现。
2)在相似性检索评估阶段,对剩余14 个大型专变窃电用户和随机抽取的14 个大型专变正常用户进行相似性检索,共28 个用户,取前14 个相似用户来评估检索效果。另外,对剩余83 个居民窃电用户和随机抽取的83 个居民正常用户进行相似性检索,共166 个用户,取前60 个相似用户来评估检索效果。
3)在相似性检索实例分析阶段,分别对剩余120 个大型专变正常用户和剩余611 个正常居民用户进行相似性检索,实例分析检索效果。
4.1 典型窃电用户发现结果
对用户用电数据进行标准化,使其均值为0,方差为1。分别对大型专变用户和居民用户数据进行基于DTW 的窃电用户AP 聚类,参数阻尼因子λ设为常用默认值0.8,AP 聚类的最大迭代次数为500。
本实验对按70%的比例随机抽取的30 个大型专变用户以及随机抽取的200 个居民用户数据进行相似性量度和聚类分析,实验控制聚类数目最多为9 个。通过AP 聚类最终找到有效度和代表度之和最大的簇代表,作为该簇的典型窃电用户。居民用户和大型专变用户的典型窃电用户结果分别如图2和图3 所示。
图2 与图3 分别展示了9 个居民用户和6 个大型专变用户的典型窃电用户。典型窃电用户除了有电量骤降或逐渐下降趋势,也存在持续低电量甚至“零电量”的现象。“零电量”是用户用电异常的典型现象,发现“零电量”用户,须立即现场排查。
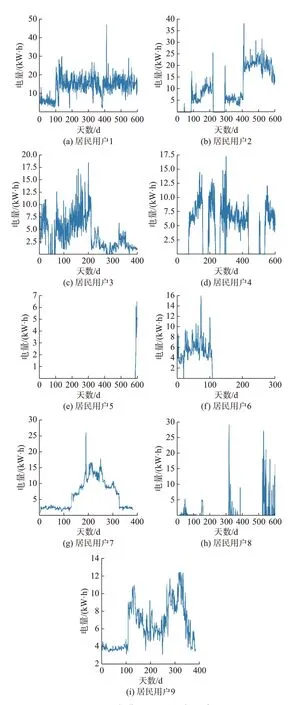
图2 9 个典型居民窃电用户Fig.2 Nine typical residential users with electricity theft behavior
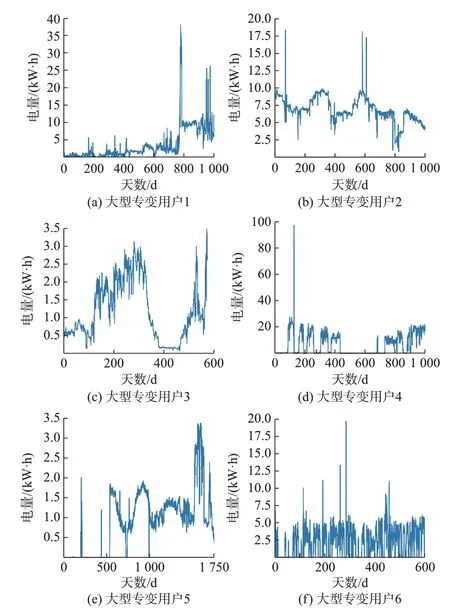
图3 6 个典型大型专变窃电用户Fig.3 Six typical large-scale dedicated transformer users with electricity theft behavior
4.2 典型窃电用户相似性检索结果
4.2.1 相似性检索方法评估
为了便于分析,利用典型大型专变窃电用户,在剩余14 个大型专变窃电用户和随机抽取的14 个正常的大型专变用户中进行单指标相似性检索,取前14 个相似用户来评估检索准确度。以检索出窃电用户的占比作为检索精确度,以误判正常用户的占比作为检索误判率。基于6 个典型大型专变窃电用户进行6 次相似性检索实验,其检索的平均精确度与平均误判率作为典型大型专变窃电用户相似性检索的最终评估指标。同理,针对居民典型窃电用户,进行9 次相似性检索实验,取前60 个相似用户来评估检索准确度,最终检索的平均精确度和平均误判率作为最终的评估结果,如表1 和表2 所示。
从表1 和表2 中发现,针对典型窃电居民用户,其相似性检索的最高精确度达到73.33%。但由于大型专变用户的经营状态不同,容易造成误报。由于数据集的特性,有必要对用户进行二次分析来降低误判率。
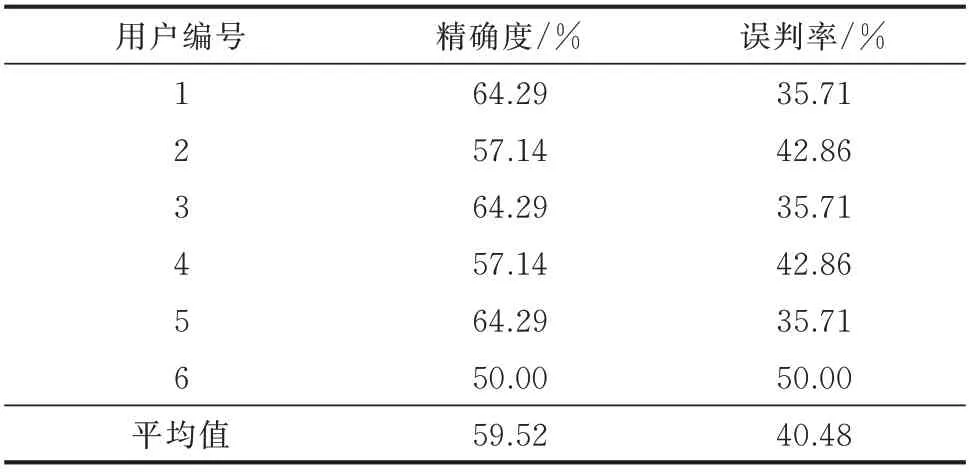
表1 典型大型专变窃电用户检索结果Table 1 Retrieval results of typical large-scale dedicated transformer users of electricity theft
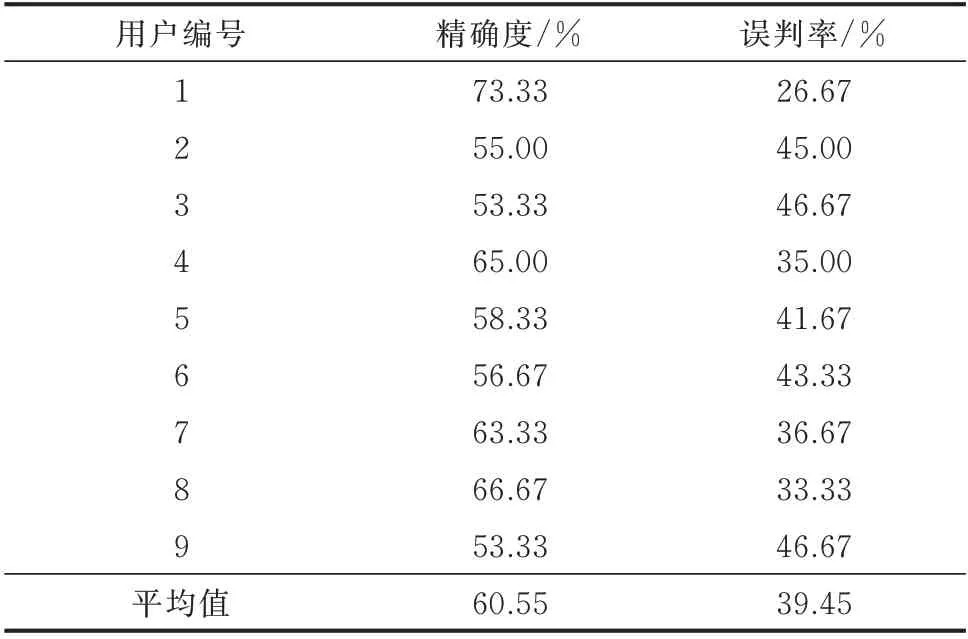
表2 典型居民窃电用户检索结果Table 2 Retrieval results of typical residential users with electricity theft behavior
4.2.2 不同方法判别结果对比
本文利用常用的分类方法来进行窃电检测对比。由于数据标签以用户为粒度,因此构建指标的统计量作为用户的用电特征,即均值、方差、偏度、峰度、峰谷差。实验设计及评估如下:
1)针对居民用户,计算用户电量数据的均值、标准差、偏度、峰度、峰谷差数据,共5 个特征。
2)针对大型专变用户,首先,每个时刻分别计算三相电流均值、三相电压均值,得到电流均值曲线数据和电压均值曲线数据。其次,分别计算用户的电量、电流、电压均值曲线数据的均值、标准差、偏度、峰度和峰谷差数据,将时间序列数据聚合成以用户为粒度的数据,共15 个特征。
3)针对每种类型用户数据,按7∶3 的比例划分训练集和测试集。训练集用以训练模型,得到训练好的模型后对测试集进行预测,每个用户得到相应的预测概率。
4)利用测试集来计算模型对窃电用户判别的准确率和误判率。为了公平起见,将预测概率从大到小进行排序,分别提取排在前60 的居民用户和前14的大型专变用户,并计算提取的用户对应的模型判别精确度和误判率。
选择随机森林[26]、决策树[27]、神经网络[28]以及卷积神经网络[29]作为对比方法。其中,随机森林的中树的数目为100;神经网络采用2 层隐藏层,神经元个数分别为5 和2;卷积神经网络的卷积核大小为1×3,步长为1,滤波器数目为64,激活函数为ReLU,池化层大小为2,全连接层含50 个神经元,优化器采用Adam。实验结果如表3 和表4 所示。
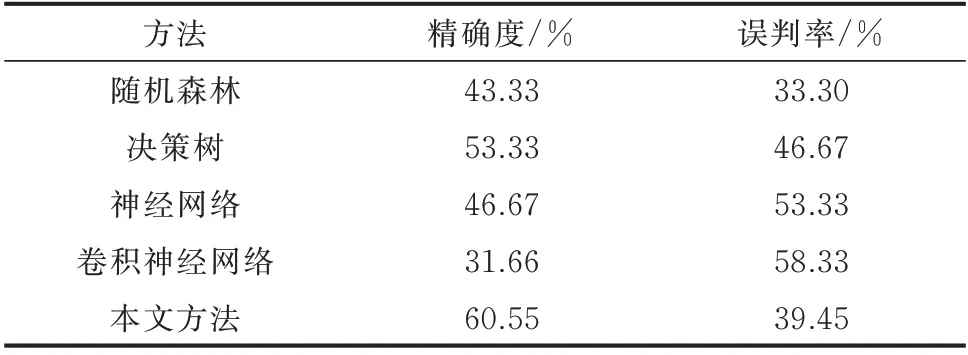
表3 居民窃电用户判别结果Table 3 Identification results of residential users with electricity theft behavior
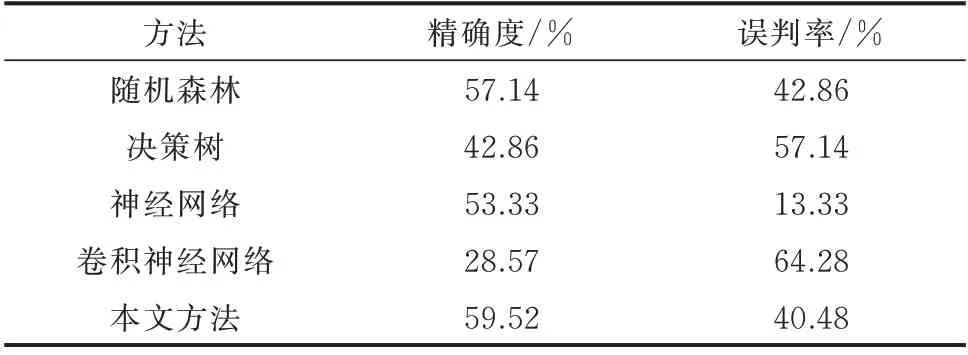
表4 大型专变窃电用户判别结果Table 4 Identification results of large-scale dedicated transformer users with electricity theft behavior
从表3 和表4 中可以发现,对比方法的分类模型预测的精确度较低而误判率较高。本实验中采用神经网络判别大型专变窃电用户,尽管其误判率较低,但精确度并没有相似性检索判别的效果好。分类模型的预测效果依赖于特征的有效性和参数设置。将数据聚合成一个统计指标,容易忽略数据中的窃电细节;不恰当的参数设置将影响模型的性能,造成低精确、高误判的现象。另外,深度学习相关方法的训练模型耗时较长,其可解释性较差,不利于窃电检测的工程应用。
4.2.3 相似性检索实例分析
对于典型居民窃电用户进行单指标相似性检索;对于大型专变用户则采用多指标相似性检索。
1)典型居民窃电用户检索实例分析
为了便于分析,针对图2(e)中的典型居民窃电用户5 在正常样本数据集中进行相似性检索,其电量曲线和在正常样本数据集中的检索结果如附录A图A4 所示。
由附录A 图A4 可以发现,典型居民窃电用户5在正常居民用户样本数据集中检索到的5 个居民用户中,该典型窃电用户5 与待排查正常居民用户1、2、3 的电量曲线形态相似,这些检索出来的正常居民用户可能存在一定的窃电嫌疑。例如正常居民用户1 到3 存在“零电量”现象,需要现场排查用户是否存在窃电行为。待排查正常居民用户4 在一段时间低电量后电量的突变幅度较大,用电异常。待排查正常居民用户5 的电量曲线在前段有“零电量”现象,其“骤升骤降”的波动特点值得用电检查人员关注。
2)典型大型专变窃电用户检索实例分析
针对图3(a)中的典型大型专变窃电用户1,在大型专变正常用户样本数据集中进行多指标相似性检索,具体操作如下。
(1)利用式(3)计算典型窃电用户与其他用户的电量时间序列总距离。
(2)将总距离从小到大排序,选择前M个距离值小的用户作为相似嫌疑窃电户。
以典型大型专变窃电用户1 为例,其多指标相似性检索的结果如附录A 图A5 所示。
利用窃电样本用户先验知识,有利于进一步判定用户窃电行为。对历史窃电用户按照行业进行窃电次数占比统计,结果如图4 所示。
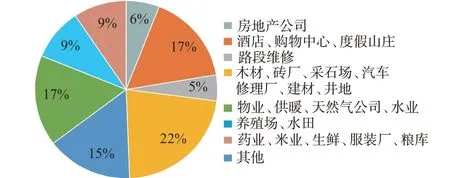
图4 各行业类型的窃电用户占比Fig.4 Proportion of users with electricity theft behavior in various industries
从图4 可以看出,根据各行业类型的历史窃电情况可以重点关注木材加工、砖厂、汽车修理厂、建材、井地、物业、供暖、天然气公司、水业、酒店、购物中心、度假山庄、房地产公司这类型的专变用户的用电情况,提高窃电用户排查效率。典型大型专变窃电用户1 相似性检索的5 个用户中,大型专变用户4为砖厂,其他用户为电信、医院、普通企业等非工业用户。因此,本研究首先重点针对典型大型专变窃电用户1 相似性检索得到的大型专变正常用户4 来进行分析,分析效果见附录A 图A6。
由附录A 图A6(a)可知,大型专变正常用户4的用电量振荡下降,直至为0;计算以周为粒度的用电量周环比,如图A6(b)所示,发现该用户第3 周至第12 周的用电量环比下降。除用电量异常以外,图A6(c)中该用户三相电流不平衡度均大于0.4,该用户用电异常。2020 年5 月20 日至6 月25 日,三相电流不平衡度除5 d 未超过1 外,其余时间均大于1,此时间段内用户的三相电流出现负值,电流出现异常。图A6(d)中周功率因数反映第3 周到第7 周的功率因数最小值低于0.6,这个时间段的数据异常应引起关注。用户的功率因数自2020 年5 月20 日,即电流出现负值的时间开始下降,在此区间内,功率因数出现了小于0.6 的情况。2020 年7 月16 日至8 月6 日,该用户的电流不平衡度为0,说明该用户在对应日期的最大相电流和最小相电流均为0,即该用户可能发生“失流”问题,推断其可能的窃电方式为“欠流法窃电”。
5 结语
本文研究以中国国家电网某省电力公司提供的用户用电数据进行分析和处理,构建了一种基于典型窃电用户相似性检索的窃电行为检测方法。一方面,利用DTW 作为时间序列相似性量度方法和AP聚类方法,将窃电用户进行聚类分析,识别典型窃电用户;另一方面,利用典型窃电用户的单指标或多指标用电数据在系统中进行相似性检索,提取与典型窃电用户相似的用户,用电行为越相似的待检查用户越具有窃电嫌疑,实现从形态特征角度进行窃电用户结构化预判。由本文的实验结果可知,所提方法可以识别典型窃电用户,并可以利用典型窃电用户检索出形态相似的待排查用户,丰富了反窃电手段,提高了反窃电查处准确性。
本文在撰写过程中受到大连市科技创新基金重点学科重大课题(大连智慧城市建设中基于大数据的智能决策理论方法及支持技术研究,2019J11CY020)资助,特此感谢!
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
