基于深度神经网络的文本语义相似性度量
2022-03-17左玉生
左玉生,张 礼
(东南大学 1. 实验室与设备管理处;2.成贤学院,江苏 南京 210096)
语义相似性度量[1]是自然语言处理领域用于判定词、句子或文本相似性的关键技术之一,在信息检索领域有着广泛的应用,正得到持续的研究关注。
传统的语义相似性度量通常采用基于词匹配的相似度计算方法或基于潜在语义分析的概率主题语义相似度计算方法来评价文本或句子在语义级别上的相似性或相关性。基于词匹配的相似度计算方法主要通过比较两个文本中词语的重复和相似程度以及词序相似度等信息来衡量句子相似度[2],比较典型的有基于最长公共子序列(Longest common subsequence,LCS)[3],词频-逆文档频率(Term frequency-inverse document frequency,TF-IDF)[4]、向量空间模型(Vector space model,VSM)[5]的语义相似度计算方法。其中基于VSM计算专利相似度的模型是目前最为成熟和常用的基于词匹配的方法。这类方法的优点是计算速度快、工作量小,缺点是这些模型建立在词与词之间无联系相互独立,忽略文本隐藏的语义信息。针对上述不足,研究人员提出了基于潜在语义分析的概率主题语义相似度计算方法,该方法的主要思想是利用词语中的共同信息对文本进行主题建模,挖掘专利文本中潜在的语义信息,从而计算文本之间的语义相似度。潜在语义分析模型(Latent semantic analysis,LSA)和潜在狄利克雷分配模型(Latent dirichlet allocation,LDA)是两种比较经典的基于潜在语义分析的概率主题模型[6]。这类方法考虑了深层语义信息,在结果上优于基于词匹配的方法,但仍存在没有考虑到词与词之间的位置关系等缺陷。随着深度学习方法在诸多领域取得成功,各类深度神经网络也被引入到语义相似性度量中用于捕获各种语义特征和训练语义相似性度量模型。在文本分布式表示方面,深度学习网络被用于将词、句子等表示学习,获取词向量[7],如word2vec、Glove和BERT等,进而获取句子向量和文本向量。在语义相似性度量模型方面,根据任务类型和数据特点,各种类型的深度神经网络,如自组织神经网络(Self-organization map,SOM)、卷积神经网络(Convolutional neural network,CNN)、循环神经网络(Recurrent neural network,RNN)等,在网络深度、宽度等方面被定制用于获得优良的相似性度量效果[8],代表性的工作DSSM[9]和ARC-II[10]。
为了提高文本相似性度量的准确性,从深度学习的角度出发,本文提出了一种新的文本语义相似性度量方法,旨在利用深度学习技术实现词级别、句子级别、文本级别的表示学习,使得学习到的表示向量能刻画上下文感知的语义信息。提出的方法由词嵌入、文本表示学习和相似性度量等模块构成。在词嵌入层,通过BERT获取词级别的分布式表示,在表示学习层,通过BIGRU将上下文信息融入词级别的语义向量中形成句子级别、文本级别的分布式表示,而在相似性度量层,通过CNN为两个输入的句子或文本计算相似性值,上述方法命名为BERT-BIGRU-CNN。为了评价提出的相似性度量方法的准确性,在两个基准数据集上进行了试验。
1 文本语义相似性度量方法
1.1 框架
为了提高文本相似性度量的准确性,本文从深度学习的角度出发提出了一种新的文本语义相似性度量框架,如图1所示。该框架的核心思想是利用深度学习技术实现词级别、句子级别、文本级别的表示学习,使得学习到的表示向量能提供上下文感知的语义信息,进而实现文本语义相似性度量。整个框架由三层构成,包括词嵌入层、文本表示学习层和相似性度量层,其中词嵌入层旨在获取词级别的分布式表示,文本表示层旨在将上下文信息融入词级别的语义向量中形成句子级别、文本级别的分布式表示,而相似性度量层旨在为两个输入的句子或文本计算相似性值。

图1 基于深度神经网络的文本相似性度量框架
1.2 词嵌入层
鉴于BERT模型可以捕获字符级、词级、句子级的上下文信息来消除词的多义性,因此本文使用BERT模型作为词嵌入层的解决方案。给定文本,采用BERT的标准输入格式构建输入张量,而后通过多层编码器,每一层编码器通过加权方式融合其它层的特征为输入生成一个新的特征,最后得到的输出张量由每个词对应的词向量,段向量和位置向量相加构成。因为BERT的最大输入长度为512个字符,故采用滑动窗口策略以固定的窗口大小进行划分,将文本分割成长短一致的句子集[S1,S2,…,Sn],再采用BERT进行编码。
1.3 句子表示学习层
在词嵌入基础上,句子表示学习层将上下文信息进一步融入词级别的语义向量中形成句子级别的分布式表示。本文采用双向循环神经网络的变体门控反馈单元网络(Gated recurrent unit,GRU)将输入词嵌入到上下文中以生成句子级的分布式表示,选取GRU的原因在于它不仅能获得包含上下文信息的句子中词嵌入表示,而且能兼顾上下文中词出现顺序对词表达的影响。设模型的输入为词向量X[t]和隐藏状态h[t-1],X[t]为句子中位置t处出现的词由词嵌入层编码得到的词向量,h[t-1]为文档中位置t-1处包含的表示上下文信息的隐藏状态。模型的输出为当前隐藏节点的输出y[t]和传递给下一个节点的隐藏状态h[t]。
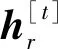
(1)


(2)

得到门向量后,再通过一个激活函数tanh的全连接层来将数据放缩到(-1~1)范围内,对输入信息向量进行编码并最终获取用于更新隐藏状态的输入信息作为候选隐藏状态,其计算过程如式(3)所示
(3)
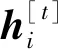
接着,一方面输入信息被更新门过滤,以获得用于更新隐藏状态的信息。另一方面在更新门上执行逐点操作以获得另一个遗忘门,并且前一时刻的隐藏状态被用于确定需保留的信息。两部分信息融合更新作为t位置的隐藏状态,计算过程如式(4)所示
(4)
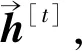
(5)
1.4 基于CNN的文本表示学习层
为了能够自动地挖掘文本特征,文档的最终表达是按文档的单词位置顺序排列的,并保留词语先后顺序关系。本文采用卷积神经网络进行特征提取,图2是基于CNN模型的文本编码过程。

图2 基于CNN的文本编码过程
(1)输入层。式(6)是文档的初始表示,其中w[t]是式中位置t处的词嵌入的最终表示,其维度为k,d′i为下标为i的文档的初始表示,维度为n×k,n是文档中的单词数。
(6)
(2)卷积层。卷积层中有3个不同窗口大小的卷积核,窗口大小分别是h1、h2和h3,每个卷积核的数量为m。选择不同高度卷积核的原因是要考虑文档中不同长度的文本之间的语义关系。以窗口大小hα(α=1,2,3)的第β(β∈(0,m])个卷积核Fαβ为例,得到特征序列cαβ如式(7)所示
(7)
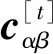
(8)
(3)池化层。提取出文本中最具有代表性的特征项,减少无用信息的影响。采用最大池化策略,如式(9)所示,并在hα窗口大小下的m个卷积核生成的特征图便会生成m个特征,如式(10)所示
(9)
(10)
(4)全连接层。输出文本的特征向量,最终文本表示结果是通过将3个卷积核的特征向量结果进行拼接而获得表示文本中间向量di,如式(11)所示
(11)
1.5 相似性度量层
两个待计算相似性的文本经过文本表示层后得到了相同维度的中间向量。相似性度量层需要计算两中间向量ds和dq之间的相似性值,采用如图3所示的计算模型。

图3 文本相似度计算模型
该模型先通过对两个中间向量进行逐点乘法和逐点减法运算,获得了两个文本的综合表示,并且由于关系是无向的,因此点后的向量逐点减法也经过逐点绝对值处理,如式(12)所示
(12)
然后,向量dp通过一个全连接隐层,假设神经网络中有i个隐藏层,通过式(13)获得输出yi
(13)
式中:wi是第i个隐藏层的权重向量,bi是第一隐藏层的偏移矢量,α(g)采用ReLU函数作为激活函数。

(14)
式中:θk表示第k个类别的权重向量,用于预测两个文本是否相似的可能性。
1.6 模型训练
为了在训练过程中优化模型需要合理构建模型的损失函数。本文选取了交叉熵损失函数,如式(15)所示,并采用小批量梯度下降法(Mini-batch)对网络中的参数进行训练。为防止可能出现的过拟合的问题,利用L2正则化来约束参数,同时采用dropout策略在迭代中在全连接层随机抛弃一部分训练好的参数。
(15)
2 试验
2.1 试验设定
为了评价提出的相似性度量准确性,在基准数据集上进行了试验评价。试验中使用了2个基准数据集,MPRC[11]和SNLI[12]。MPRC是由微软提供的用于同义句识别任务的基准数据集,每个句子对都进行了标注,标注值1表明是同义句,而标注值0表示语义不同,训练集有4 076个样本,测试集有1 718个样本。SNLI是斯坦福大学提供的用于自然语言推理任务的基准数据集,给定假设并依据该假设进行假设间关系推理,结果为蕴含、冲突和中立,详细的数据集样本分布情况如表1所示。

表1 SNLI数据集的标签分布
试验中采用了accuracy和F1-score来评价相似性度量结果准确性,并与其它类似的先进工作进行了对比分析,选取的对比算法同样都采用了基于深度学习的思路,其中深度语义结构模型(Deep semantic structured model,DSSM)[9]是最早用于度量文本相似性的深度学习模型之一。该模型采用典型的Siamese网络结构,由五层的网络单独进行向量化,计算文本间的余弦相似度得到文本相似性得分;卷积网络深度匹配模型ARC-II[10]采用交互学习方式,分别对查询中的词进行n-gram卷积提取和文档中的词进行卷积提取,而后得到的成对词向量进行相似性计算得到一个相似性度矩阵。
2.2 消融试验
本节从词嵌入方式、句子表示学习方法和文本表示学习方法等三个方面评估它们对于语义相似性度量模型的影响。在词嵌入层,采用常用的word2vec词嵌入方式取代BERT,生成名为Word2vec-BGRU-CNN的方法,在句子表示学习层去除双向GRU结构得到模型BERT-CNN,在文本表示学习层用AVG取代CNN后得到模型BERT-BGRU-AVG。表2给出了消融后得到的模型与本文提出的BERT-BGRU-CNN在两个基准数据集上的试验结果。
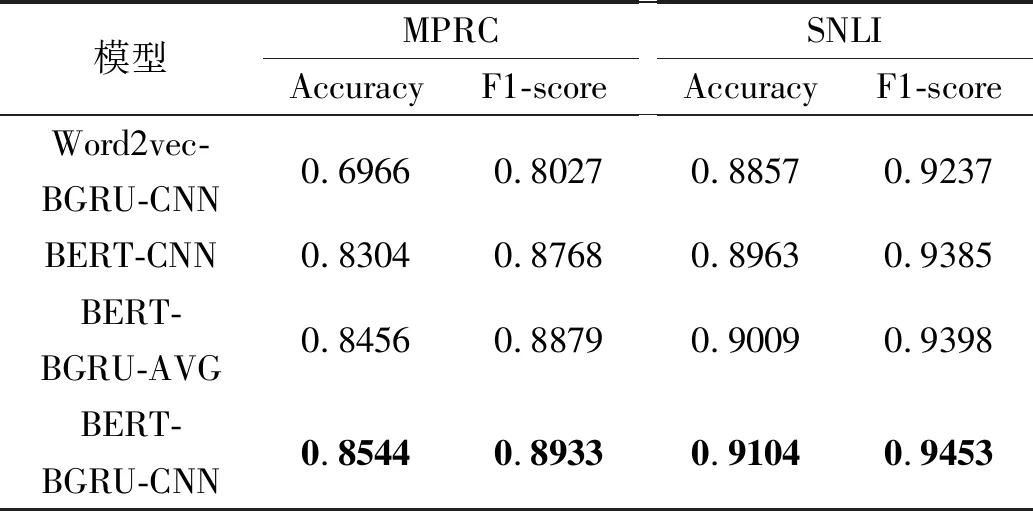
表2 不同模型在基准数据集上试验结果
从表2中可以看出,基于BERT的词向量的模型在性能上优于基于word2vec的模型,具体表现在采用BERT词向量的模型较word2vec的在MPRC数据集上Accuracy和F1-score都有显著的提升,分别提高了22.6%和11.2%。在句子表示学习层,采用BRGU编码句子后在两个数据集上指标都有一定的提升,Accuracy和F1-score分别提高了约1.8%和1.3%,表明双向GRU可以获得了距离相距较远的词特征与基于BERT的上下文词特征相结合,能更好地掌握文本上下文相关的信息。在文本表示层,采用CNN后的模型在两个数据集上指标同样都有一定的提升。
2.3 对比试验
本节将提出的模型与现有的先进模型进行了对比试验,试验结果如表3所示。从表中可以看出,本文提出的模型在两个基准数据集上accuracy和F1-score值都优于现有的模型,尤其是在MPRC基准数据集上有明显的性能提升,这表明融合BERT,双向GRU和CNN构建的文本相似性度量模型能有效的度量句子级别、文档级别的相似性。
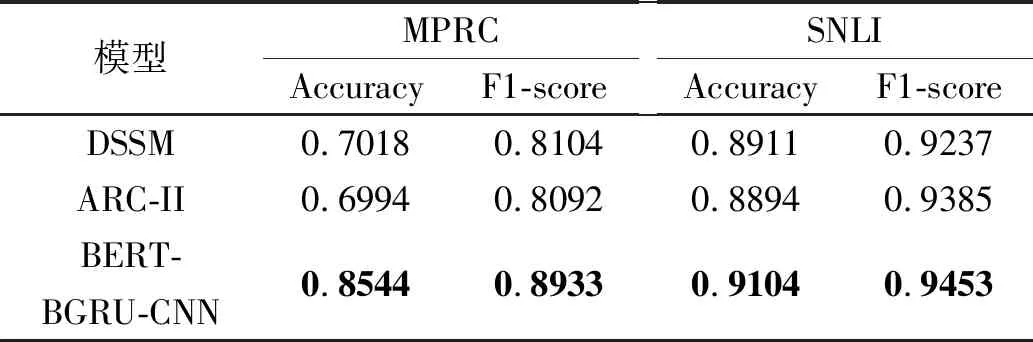
表3 本文提出的模型与对比模型在两个基准
3 结束语
出于提高文本相似性度量准确性的目的,本文提出了一种新的文本相似性度量,借助深度神经网络来捕获文本中词级别、句子级别和文本级别的丰富语义信息,从而提高文本相似性度量准确性。通过在两个基准数据集上的试验和对比验证了提出的文本语义相似性度量的有效性。
