基于自注意力机制的多特征融合槽抽取模型
2022-03-17牛迪
牛 迪
(浙江大学 经济学院,浙江 杭州 310027)
在自然语言处理(Natural language processing,NLP)中,任务型人机对话系统的研究一直都备受关注,对它的研究投入也越来越多[1,2]。如今,在各个领域都可以见到任务型对话系统的实际应用场景,如金融[3]、智能家居[4]、汽车等。在任务型人机对话系统中,口语语言理解(Spoken language understanding,SLU)是至关重要的环节,需要识别用户的意图,以及相关的语义成分,也称之为槽。为此,SLU的任务常划分成两个子任务:意图识别、槽抽取。意图识别可视为文本分类类型的问题,预测用户话术的意图类型。而槽抽取则常被视作序列标注类型的问题,预测用户话术中的每一个字或者词的标注类别。以金融领域的智能问答机器人为例,用户会咨询股票涨跌类的问题,如:“今天A股的涨幅是多少”,其意图类别及序列标注类别如图1所示。

图1 SLU的子任务示例:意图识别、槽抽取
传统的槽抽取模型多采用规则模版和句法分析相结合的方法[5,6],先利用句法分析获取句法树结构,然后在句法树的基础上编写相应的规则,从中抽取出相应的槽值。随着深度学习的兴起,槽抽取逐渐采用了序列标注的方案,实现实体识别,进而抽取出相应的槽值。由于意图和槽之间的强相关性,研究人员现多采用联合学习模型[4,7-14](Joint learning models)来同时实现意图识别和槽提取,通过卷积神经网络(Convolutional neural network,CNN)或双向长短期记忆模型(Bi-directional long short-term memory,Bi-LSTM)提取句子特征,用作意图识别模型和槽抽取模型的共享特征。同时利用意图和槽之间的强相关性,将意图作为槽抽取模型的一个输入特征,构建联合损失函数。
当前的联合学习模型多采用门控机制将意图特征关联到槽提取模型中,但是在门控机制下,槽抽取模型获得的意图信息是隐向量,这并不能充分的保留意图信息[15,16],同时降低了模型的可解释性。为此,Qin等[15]采用了堆栈传播(Stack-propagation)架构,将意图直接编码,输入槽提取模型。除了门控机制外,当前的槽抽取模型在输入表征层还只是单纯依靠词嵌入(Word embedding),并没有用到其它语言领域的先验知识。而阻碍先验知识应用的很大原因是深度学习的模型结构很难和先验知识做融合。Luo等[17]采用了规则系统和神经网络相结合的方法,将正则表达式识别出的结果编码成词的一个特征,和词嵌入拼接成词向量,输入神经网络的输入表征层。但是,通过规则系统来引入先验知识的弊端是需要编写大量的正则表达式才能识别出词特征,以及规则之间的相互冲突会加大先验知识的融入难度。
为此,本文将自注意力[18-22]机制(Self-attention)引入到槽抽取模型中,用于融合多维度的先验知识信息,同时采用Qin等[15]对意图信息的处理方式,抛弃门控机制,利用自注意力机制来融合意图信息和先验知识。为后续陈述方便,将意图信息、先验知识等统称为多维度特征。在图像处理领域,研究人员也有采用自注意力机制[22]和多特征融合[23]来提升图像识别的能力。Zechao[22]等利用自注意力机制抽取同品类物体的像素信息,以提升语义分割的性能,且实验结果验证了该方案的有效性。除此之外,Zechao[23]等还采用了深度协同嵌入(Deep collaborative embedding,DCE)框架融合社交网络图片的多标签特征,在社交网络图片理解上取得了很好的实验结果。
本文具体从以下三个方面对槽抽取模型的研究进行了扩充。
(1)设计了独立的槽抽取模型,在不依赖联合模型的前提下,依然能够充分利用意图识别的信息。同时,解耦意图识别模型和槽抽取模型,好处在于方便意图识别任务采用集成学习来提升性能;
(2)本文采用自注意力机制,能够融合了更多的字词表征信息,实现了意图特征、上下文特征、字符特征、词特征等多维度特征融合,实验结果也验证了该方法的有效性;
(3)在系统中增加了新词词特征的处理方案,通过词典和本体共同处理新词现象,使得垂直领域的新词解决能力大大提升。可以不用在文本语料上标注数据,只需简单的将新词添加到对应的词典即可。
本文在公开数据集ATIS(Airline travel information system)的基础上,通过对比传统的联合模型或者独立的槽抽取模型,本文的槽抽取模型对新词的识别能力更强,整体槽抽取的F1值能达到97.99%。
1 模型结构
区别于常见的自注意力机制的使用方法,本文使用自注意力机制来融合字、词,以及意图的多维度特征,而不是用于句子的编码。本文的模型结构如图2所示。
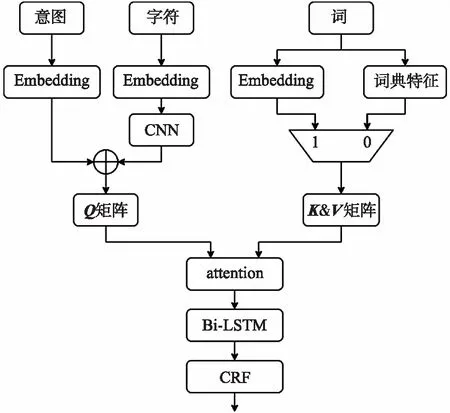
图2 模型结构
1.1 多维度特征融合
本文所采用的多维度特征指:意图特征、词特征、词典特征,以及字符特征。假设一个句子的字符长度为m,字符嵌入向量长度为dc;词的个数为n,词嵌入向量长度和词典特征的向量长度都为dw。意图特征来源于意图识别的结果,对识别出的意图字段做随机初始化编码,生成长度为di的向量。整个特征融合的过程如下:
步骤1对于字符,通过CNN对句子字符做一维卷积,卷积核(Kernel)个数为k,每个kernel是w×dc矩阵,经过填充(Padding)卷积操作,生成m×k的矩阵Mc;
步骤2对意图特征向量做扩充,生成m×di矩阵,并与字符矩阵Mc做拼接,生成Q矩阵,尺寸为m×(di+k)。为保证后续的注意力运算正确,Q矩阵的尺寸需要满足di+k=dw,即Q为m×dw的矩阵;
步骤3对于词,由于存在生词没有对应预训练词嵌入的现象,需要通过词典特征和词嵌入两种做复合查询。预先会根据应用场景创建一系列词典,如股票名词典、家居设备词典。当出现没有对应的词嵌入时,系统会查询该词所在的词典,并将词典特征视为该词的向量;
步骤4在获得句子中每个词的向量后,生成K、V矩阵,尺寸为n×dw,且K=V。至此,自注意力机制中的所需要的Q、K、V举证全部构建完成;
步骤5本文采用了变换网络(Transformer)[15]模型的点积注意力(Scaled dot-product attention)机制,将构建的Q、K、V矩阵输入自注意力模块,经方程
的处理,最终实现了各维度特征的融合。其中,Q、K、V矩阵分别为自注意力模型中的查询矩阵(Query matrix)、键矩阵(Key matrix),以及值矩阵(Value matrix),如图3所示。经过以上的特征融合操作,最终输出m×dw尺寸的矩阵,可等效为m个字符的特征矩阵。
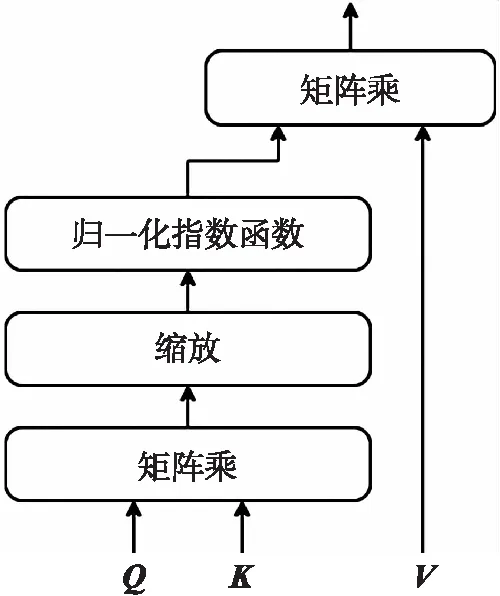
图3 点积自注意力模块
在整个模型结构中,关键性的计算单元是CNN、自注意力模块,以及Bi-LSTM模块。CNN的计算复杂度是O(k×n×d2),自注意力的计算复杂度是O(d×n2),Bi-LSTM的计算复杂度是O(n×d2)。其中,k为卷积核的尺寸,n是句子长度,d为各计算模块的输入向量维度。考虑到实际应用中,向量维度d会远大于句子长度n,而卷积核的尺寸较小,因此整个模型的计算复杂度为O(n×d2)。同时,CNN和自注意力的顺序操作(Sequential operations)步数为O(1),Bi-LSTM的顺序操作步数为O(n),因此整个模型的顺序操作步数为O(n)。
1.2 Bi-LSTM和CRF
虽然整个模型结构中利用到了词特征和词典特征,但是在经过注意力机制的特征融合后,实际输出的m×dw矩阵可等效成字符特征。因此,模型中的Bi-LSTM需要基于字符来做训练和预测。Bi-LSTM利用长短期记忆模型(Long short-term memory,LSTM)单元对输入的字符特征做编码,前向LSTM和反向LSTM分别输出各自的隐向量,然后由拼接单元将其拼接,最终得到Bi-LSTM的输出隐向量。
CRF层采用线性CRF[24](linear CRF),在Bi-LSTM和线性CRF融合的模型结构中,由Bi-LSTM输出发射概率矩阵,CRF结合发射概率矩阵和标签转移矩阵,预测每个字符的序列标签。其模型结构如图4所示。
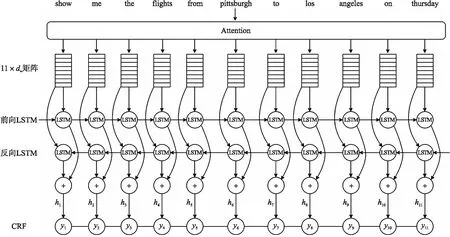
图4 Bi-LSTM和CRF网络结构
2 模型及训练参数
其中,参数w可归纳为CNN网络参数、Bi-LSTM网络参数、CRF的转移矩阵参数。除了网络参数外,本文模型的超参数值如表1所示。
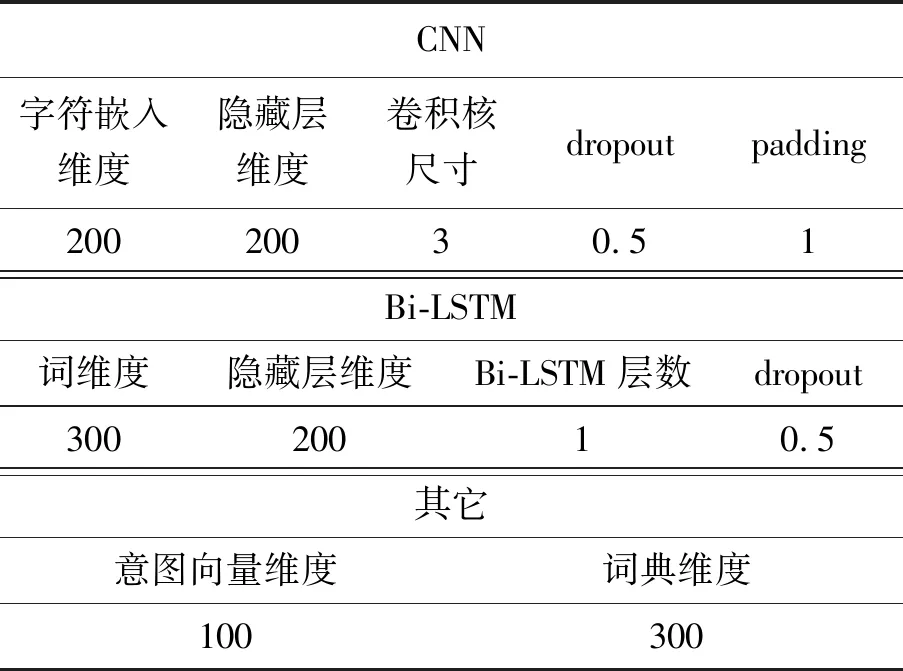
表1 模型超参数
3 实验结果及分析
为验证模型的性能,本文搭建的实验环境为4核CPU、2080Ti GPU,以及8G内存。实验数据为公开数据集ATIS,同时创建了城市名词典、日期词典等,训练耗时约为48 min。为方便与文献中有代表性的模型结果进行对比,本文方案命名为Attention multi-feature,实验结果如表2所示。

表2 ATIS实验对比数据
3.1 模型对比
CNN-CRF[25]模型采用CNN对句子做编码,提取词特征信息,CRF层采用这些特征预测词的槽位标签。Attention Encoder-Decoder NN[11]模型采用了常规机器翻译模型的编码器解码器(Encoder-decoder)结构,编码器(Encoder)用于句子编码,提取词特征信息,将Bi-LSTM生成的隐向量作为特征用于解码器(Decoder)。除了隐向量,解码器还利用上下文向量(Context vector)作为特征用于预测词的槽位标签。与Attention Encoder-Decoder NN相似,Attention BiRNN[11]模型也是采用了Bi-LSTM对句子编码,同时借助加权平均的方式来生成context vector。Slot-Gated[10]模型依然是采用Bi-LSTM对句子做编码,提取词特征信息,但采用了门控机制来将意图信息融入到槽提取模型中。
区别于上述模型,本文的Attention multi-feature模型除了用到词特征信息外,还采用了词的字符特征信息、词典信息,同时采用了自注意力机制将意图信息融入到槽提取模型中。从实验结果中可以看出,相比以往文献的模型方案,本文所采用方案在性能上有优势,F1值优于常见方案,最大提升了约3%。
3.2 消融实验
为分析各特征对实验结果的影响程度,本文进行了消融实验,结果如表3所示。其中,“W/O词典”表示忽略词典特征;“W/O CNN”表示模型结构中删除CNN结构,即忽略字符特征;“W/O 词”表示模型结构中忽略词嵌入和词典特征。

表3 消融实验
从实验结果中可以看出,不同维度特征的缺失都会影响到识别的性能。其中,词典特征对性能的影响较小,词特征对性能的影响较大。由此可以说明,多维度的特征融合能够提升槽识别的性能。
由于忽略词嵌入和词典特征会带来自注意力模型的K矩阵和V矩阵的缺失,因此在“W/O词”的实验中,本文的模型结构也需要相应地删除自注意力机制,进而导致模型的性能大大降低。而无论是忽略词典特征的实验“W/O词典”,还是忽略字符特征的实验“W/O CNN”,其模型结构中都需要自注意力机制做特征融合,这两者的实验结果都优于“W/O词”,由此可以说明,自注意力机制在本文的模型结构设计中起到了十分重要的作用。
同时,对比忽略词典特征的实验“W/O词典”和忽略字符特征的实验“W/O CNN”,发现词典特征对模型的性能影响较弱。这是因为在本文的模型结构设计中,词嵌入和词典特征是复合查询,当没有对应词的词嵌入时,才会采用词典特征。
从中可以看出,本文所采用的方案在准确率和召回率方面均有优势,F1值能达到97.99%。
4 结束语
任务型人机对话系统的语言理解模块可以简单的划分为意图识别和槽抽取两个任务。本文将槽抽取任务视为序列标注类问题,采用了基于自注意力机制的多特征融合模型,简称Attention multi-feature。本文在现有的Bi-LSTM+CRF模型框架的基础上设计了新的特征提取模块,利用自注意力机制,将字符特征、词特征、词典信息、意图信息融合成一个矩阵。因为矩阵的尺寸和句子字符embedding的尺寸相同,因此可以认为字注意力机制将多维度特征融合成了一个新的字符特征,同时后续模块采用了传统的基于字符的Bi-LSTM+CRF模型。
为了验证模型方案的效果,本文构建了在ATIS数据集的基础上,对比分析了以往文献的模型方案。实验结果表明,本文的模型方案在性能上有优势,F1值最大提升了3%。
