基于自适应鲸鱼优化算法和容错邻域粗糙集的特征选择算法
2022-03-11黄金旭徐久成马媛媛
孙 林 黄金旭 徐久成 马媛媛
特征选择作为数据预处理的关键步骤,目前已广泛应用于机器学习、模式识别、数据挖掘等领域[1-2].根据评价准则的不同,特征选择一般分为3类:包装法、过滤法和嵌入法[3].包装法使用已确定的学习算法,直接使用分类性能作为特征重要性程度的评价标准.过滤法是先对特征集进行筛选,再使用学习算法进行训练,特征选择的过程与学习算法无关.嵌入法是在使用学习算法进行训练的过程中,自动进行特征选择.过滤法的评价准则依赖学习算法,所选特征的准确率低于包装法,但是包装法的计算开销较大.
粗糙集模型在处理数值型数据时需要对数据进行离散化处理,然而离散化处理可能会导致数据出现信息损失[4-6].为此,刘艳等[7]运用K-S检验,提出基于邻域粗糙集的混合数据特征选择算法,直接处理含有数值型和符号型数据的邻域信息系统.Chen等[8]分析邻域粗糙集中上下边界域的模糊性和类的不均匀分布,提出基于差别矩阵的特征选择算法.Sun等[9]提出基于费雪评分算法(Fisher Score)和多标记邻域粗糙集的多标签分类特征选择方法.
但是,上述邻域粗糙集模型通常沿用经典粗糙集求解上下近似时的包含关系,导致邻域粗糙集理论缺乏一定的容错性[10].为了解决此问题,彭潇然等[10]利用决策粗糙集模型中的最小风险决策规则,在邻域空间中进行决策风险分析,提出基于容错改进的邻域粗糙集属性约简算法.但是,此研究是基于容错正域的约简算法,并未讨论邻域粗糙集中依赖度、精度、粗糙度和特征重要度.
当前,大部分邻域粗糙集模型通常仅是从代数观点或信息论观点研究特征选择方法.Hu等[11]基于矩阵的正域、负域和边界域,设计动态更新近似方法,提出基于矩阵的特征选择算法.Wang等[12]基于距离测度,研究模糊粗糙集理论,提出基于依赖度和特征重要度的特征约简算法.上述文献都是仅从代数角度进行特征选择,只能反映特征对确定分类子集的影响[13].
目前,基于信息论的特征选择已得到广泛研究.Sun等[14]研究联合信息熵,结合Fisher score设计特征选择算法.然而,如果仅从信息论单方面构造特征重要度,那么只能反映特征对不确定分类子集的影响,因此,结合代数和信息论观点成为新的研究课题.Wang[15]给出代数和信息论观点下的特征重要度概念,设计启发式约简算法.Sun等[16]结合ReliefF和邻域互信息,提出特征选择算法.Sun等[17]基于Lebesgue测度和熵,设计FSNTDJE(Fea-ture Selection Algorithm Based on the Neighborhood Tolerance De-pendency Joint Entropy).
群智能优化算法具有操作简单、全局寻优能力强等优点[18-20].学者们结合群智能优化算法与粗糙集理论,研究特征选择算法,已提出大量的群智能优化算法.例如:粒子群优化算法、蚁群优化算法、果蝇优化算法、蚱蜢算法、鲸鱼优化算法(Whale Opti-mization Algorithm, WOA)[20]等.相比传统的特征选择方法,结合群智能优化算法的特征选择方法性能更优.Wang等[21]提出PSORSFS(Particle Swarm Optimization for Rough Set-Based Feature Selection Algorithm).孙林等[22]提出基于邻域粗糙集和帝王蝶优化的特征选择算法.
鲸鱼优化算法(WOA)通过模拟鲸鱼的收缩包围、螺旋式更新位置和随机捕猎的觅食机制进行寻优,具有参数设置简单、收敛速度较快、寻优精度较高等特点,同时具有良好的寻优能力[20].但是,传统的WOA存在过早收敛和容易陷入局部最优的问题[23].因此,本文使用自适应惯性权重改进WOA,并与容错邻域粗糙集结合,提出基于自适应WOA和容错邻域粗糙集的特征选择算法(Feature Selection Based on Adaptive WOA and Fault-Tolerance Neighborhood Rough Sets, FSAWFN).首先,提出分段式的动态惯性权重,改进WOA的收缩包围和螺旋捕食阶段,设计自适应WOA(Adaptive WOA, A-WOA).再针对邻域粗糙集的零容错问题,引入邻域内相同决策特征比例,给出具有容错性的上下近似、精度、粗糙度的概念.然后,将容错粗糙度引入熵中,提出容错邻域近似条件熵的概念,实现代数观点和信息论观点的结合.最后,基于容错邻域粗糙集构造适应度函数,使用A-WOA,不断迭代以获取最优子群.针对高维数据集,采用Fisher Score进行初步降维,降低算法的时间复杂度.在8个低维UCI数据集和6个高维基因数据集上的实验表明,本文算法可有效选择特征个数较少且分类精度较高的特征子集.
1 基础知识
1.1 鲸鱼优化算法
鲸鱼优化算法(WOA)是模拟座头鲸捕食行为而提出的一种寻优算法,主要包括包围猎物、气泡网攻击和随机搜索3种行为[20].下面简要介绍3种行为的位置更新模型.
1)包围猎物.由于目标位置或最优个体位置未知,WOA需要假设目标位置.一般选择初始适应度值最大的个体位置为目标位置,鲸鱼群体就会游向目标位置,位置更新公式如下:
S(j+1)=S*(j)-AM.
其中:M=|ES*(j)-S(j)|,为鲸鱼个体位置到目标位置的距离,
E=2r2
(1)
为系数变量,r2为0~1之间的随机数,S*(j)为假设的目标位置,S(j)为当前鲸鱼个体的位置,j为迭代次数;
A=2kr1-k,
(2)
为系数变量,
为收敛因子,在2~0之间递减,r1为0~1之间的随机数.
2)气泡网攻击.WOA模拟鲸鱼的气泡网攻击行为模型主要有如下2种.
(1)收缩包围圈.通过减少A中k值实现,A的取值范围为(-k,k),随着k在2~0之间递减,A也在递减,鲸鱼个体越来越接近目标位置.
(2)螺旋更新位置.计算鲸鱼个体到目标位置的距离,利用螺旋线公式进行位置更新:
S(j+1)=M′ehlcos(2πl)+S*(j),
其中,
M′=|S*(j)-S(j)|,
为鲸鱼个体到目标位置的距离,h为螺旋线常数,l为(-1,1)内的随机数.
一般情况下,鲸鱼在捕猎时是边螺旋游向猎物,边收缩包围圈,以0.5为阈值描述气泡网攻击,则
其中,M为鲸鱼个体位置到目标位置的距离,p为0~1之间的随机数.
3)随机搜索.鲸鱼还可利用|A|的变化进行随机搜索.为了增强WOA的全局寻优能力,当|A| > 1时,强制鲸鱼群体根据随机选择的个体进行位置更新:
S(j+1)=Srand(j)-AM,
(3)
其中,
M=|ESrand(j)-S(j)|,
Srand(j)为当前群体中随机一个鲸鱼的位置.
1.2 邻域粗糙集
给定邻域决策系统NDS=〈U,C,D,δ〉,U为论域,C为条件特征集,D为决策特征集,δ∈[0,1]为邻域半径参数.对于∀xi∈U,条件特征子集B⊆C,ΔB为距离函数,则xi关于B的邻域类[7]表示为:
给定邻域决策系统NDS=〈U,C,D,δ〉,对于任意特征子集B⊆C,论域U上任意2个样本点xi和yi,i=1,2,…,|U|之间的欧氏距离[8-9]为:
给定邻域决策系统NDS=〈U,C,D,δ〉,对于任意条件特征子集B⊆C,样本子集X⊆U,∀xi∈U,i=1,2, …,|U|,则X关于B的邻域上/下近似集[8]表示为:
给定邻域决策系统NDS=〈U,C,D,δ〉,对于任意条件特征子集B⊆C,样本子集X⊆U,则X关于B的邻域近似精度和邻域近似粗糙度[22]为:
给定邻域决策系统NDS=〈U,C,D,δ〉,对于任意条件特征子集B⊆C,决策特征D导出的划分U/D={D1,D2,…,Dl},则D关于B的正域和依赖度[22]为:
其中,Dt∈U/D,t=1,2,…,l.
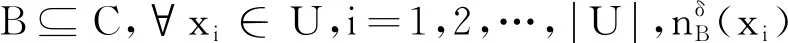
2 基于自适应鲸鱼优化算法和容错邻域粗糙集的特征选择算法
2.1 自适应鲸鱼优化算法
褚鼎立等[23]强调:惯性权重的取值对算法的寻优能力和收敛能力具有至关重要的影响.在传统的WOA中,惯性权重取较大的固定值,虽然保证WOA的全局寻优能力,但不利于WOA后期的局部寻优.因此,本文将WOA的收缩包围和螺旋捕食行为都分为前期、中期和后期3个阶段,根据迭代周期对惯性权重的取值进行动态调整.
定义1基于迭代周期的分段式动态惯性权重为:
(4)
其中,rand表示0~1之间的随机数,j为迭代次数,Maxiter表示最大迭代次数.
在WOA前期,ω仍保持较大的固定值,使鲸鱼具有较大的搜索步长;在WOA中后期,随着迭代的进行,ω的取值非线性递减,使鲸鱼向全局最优解靠近,加快WOA收敛.
根据式(4)计算惯性权重ω的值.式(4)保证ω的取值在[0,1]内,同时,随着WOA的执行,ω的取值呈现非线性递减,有利于避免WOA后期陷入局部最优、无法跳出的现象.
定义2依据动态惯性权重ω,自适应WOA的收缩包围和螺旋捕食行为表示为:
S(j+1)=ωS*(j)-AM,
(5)
S(j+1)=M′ehlcos(2πl)+ωS*(j),
(6)
其中,ω为动态惯性权重,A为系数变量,S*(j)为假设的目标位置,M′表示鲸鱼个体到目标位置的距离,h为螺旋线常数,l为(-1,1)内的随机数.
A-WOA的具体步骤如下.首先,设置最优位置或目标位置;再根据迭代次数计算动态惯性权重ω;然后,根据A和E的值,进行包围猎物、气泡网攻击和随机搜索3种位置更新;最后,确定最优解和最优位置.
2.2 容错邻域粗糙集
邻域粗糙集继承传统粗糙集在构造上下近似时的包含关系,导致邻域粗糙集缺乏一定的容错性[10].为了解决这一问题,本文将容错性分析推广到邻域粗糙集模型中,构建容错邻域粗糙集模型,并定义基于容错的邻域近似精度、粗糙度和依赖度.
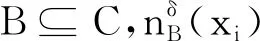
其中Di表示xi对应的等价类.同时,需要说明的是:

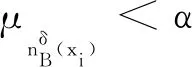

在传统的邻域粗糙集中,有正域
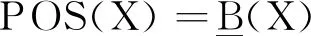
和边界域
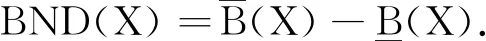
定义4给定邻域决策系统NDS=〈U,C,D,δ〉,对于任意条件特征子集B⊆C,样本子集X⊆U,则X关于B的容错邻域上/下近似集为:
定义5给定邻域决策系统NDS=〈U,C,D,δ〉,对于任意条件特征子集B⊆C,样本子集X⊆U,则X关于B的容错邻域近似精度和近似粗糙度为:
定义6给定邻域决策系统NDS=〈U,C,D,δ〉,对于任意条件特征子集B⊆C,则决策特征D关于B的容错依赖度为:
粗糙度反映知识的不确定性程度,邻域条件熵反映信息粒度引起的知识不确定性[14,17].于是,将基于容错的粗糙度引入邻域条件熵中,得到基于容错的邻域近似条件熵.
定义7给定邻域决策系统NDS=〈U,C,D,δ〉,对于任意条件特征子集B⊆C,∀xi∈U,i=1,2,…,|U|,U/D={D1,D2,…,Dl},αB(Dt)为容错邻域近似精度,ρB(Dt)为近似粗糙度,那么决策特征D相对于B的容错近似条件熵为:
(7)
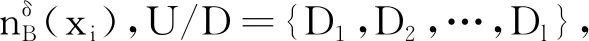
2)当且仅当所有对象都是正域中的元素时,H(D|B)取最小值0.

ρB(Dt)=1, log2(1+ρB(Dt))=1,
又因为
因此,H(D|B)取最大值|U|log2(|U|).
再证明2).∀xi∈U,xi都是正域中的元素时,有
αB(Dt)=1,ρB(Dt)=1-αB(Dt)=0,
所以
log2(1+ρB(Dt))=0,
H(D|B)取最小值0.
定理2给定邻域决策系统NDS=〈U,C,D,δ〉,对于任意2个条件特征子集P⊆C,Q⊆C,如果Q⊆P,那么
H(D|P) ≤H(D|Q).
证明对于任意条件特征子集Q⊆P⊆C,样本xi∈U,
U/D={D1,D2,…,Dl},
于是可得,
另外
所以
H(D|P)≤H(D|Q).
因此,随着条件特征的增加,H(D|B)是单调递减的.
定义8给定邻域决策系统NDS=〈U,C,D,δ〉,对于∀B⊆C,当且仅当
1)H(D|B) =H(D|C),
2)对于∀a∈B,有
H(D|B-{a})>H(D|C),
则称B是C相对于D的约简.
定义9给定邻域决策系统NDS=〈U,C,D,δ〉,对于任意条件特征子集B⊆C,∀a∈B相对于D的内部特征重要度为:
Siginner(a,B,D)=H(D|B-{a})-H(D|B).(8)
定义10给定邻域决策系统NDS=〈U,C,D,δ〉,对于∀a∈C,如果
H(D|C-{a})>H(D|C),
即
Siginner(a,C,D)>0,
称特征a为C相对于D的核特征.
定义11给定邻域决策系统NDS=〈U,C,D,δ〉,对于任意条件特征子集B⊆C,则对于任意条件特征a∈C-B,关于决策特征D的外部特征重要度为:
Sigouter(a,B,D)=H(D|B)-H(D|B∪{a}).
Sigouter(a,B,D)的值越大,说明在已知B的条件下,特征a对于决策特征D越重要.
2.3 适应度函数
目前,适应度函数中的特征依赖度只针对已选取的特征进行计算,而缺少对特征空间中其它特征的分析和评价[18,24].如果加入一个特征后不改变论域中确定分类的实例,但是不确定性却有所变化,则该特征的重要度在代数观点下为0,在信息论观点下重要度却不为0.因此,本文引入基于容错邻域近似条件熵的特征重要度,结合特征依赖度构造适应度函数.
定义12给定邻域决策系统NDS=〈U,C,D,δ〉,对于任意条件特征子集B⊆C,任意条件特征a∈C-B,基于容错邻域粗糙集的新的适应度函数为:
其中,λ1为特征依赖度参数,λ2为特征重要度参数,λ3为特征子集长度参数,λ1+λ2+λ3=1,γ′B(D)为决策特征D关于B的依赖度,Sigouter(a,B,D)为决策特征D的外部特征重要度,|B|为选择特征子集的个数,|C|为所有条件特征的个数.该适应度函数能对所有特征进行评价,并选择依赖度较大、剩余特征重要度较小、长度较短的特征子集.
2.4 算法步骤
FSAWFN首先初始化鲸鱼群体.然后根据更新策略更新位置,选择适应度最佳的个体.最后利用信息熵进行特征选择.具体伪代码如算法1所示.
算法1FSAWFN
输入邻域决策系统NDS=〈U,C,D,δ〉,
鲸鱼群体N,最大迭代次数Maxiter,
依赖度限制因子α、β,权重系数λ
输出特征子集R
1.随机产生大小为N、维度为|C|的鲸鱼群体
POP={S1,S2,…,SN},Si={s1,s2,…,s|C |},
si∈[0,1],R=Ø;
2.Foriter=1,2,…,Maxiter
3.将鲸鱼群体POP转化为二进制POP′;
4.根据式(4)计算惯性权重ω;
5.根据式(1)和式(2)计算A、E;
6.If |A|<1
7.Ifp>0.5.
8.根据式(5)更新鲸鱼个体的位置si;
9.Else
根据式(6)更新鲸鱼个体的位置si;
10.End if
11.Else
根据式(3)更新鲸鱼个体的位置si;
12.End if
13.End for
14.计算适应度值,选择适应度值最佳的个体ai;
15.根据式(7)和式(8)计算容错邻域近似条件熵H(D|ai)和特征重要度Siginner(ai,C,D);
16.IfSiginner(ai,C,D)>0,
则R=R∪{ai};
17.IfH(D|ai)=H(D|C)
18.令S=C-R,对于∀a∈S,计算
Sigouter(a,C,D);
19.选出ai,满足
Sigouter(ai,C,D)=
max{a|Sigouter(a,C,D),a∈S};
20.令S=S-ai,R=R∪{ai},计算H(D|R);
21.IfH(D|R)=H(D|C),
转入26;
22.Else
返回1;
23. End if
24. End if
25.End if
26.输出特征子集R.
设群体大小为n,维度为m,初始化种群的时间复杂度为O(nm),计算惯性权重的时间复杂度为O(n).步骤6~步骤12更新位置的时间复杂度为O(nm).在最坏情况下,步骤17计算H(D|B)的时间复杂度为O(n2m),需要计算m次,为O(n2m2).步骤16~步骤25计算每个特征重要度的时间复杂度为O(n2m),在最坏的情况下需要计算m次,时间复杂度为O(n2m2).因此,FSAWFN总的时间复杂度为
O(2n2m2+n2m+ 2nm+n),
约为O(n2m2).
3 实验及结果分析
3.1 自适应鲸鱼优化算法性能分析
为了验证动态惯性权重在WOA搜索后期局部寻优的能力,对本文提出的自适应WOA(A-WOA)进行寻优能力测试,选择文献[25]中6个基准函数,如表1所示.表中单峰函数f1~f3主要测试算法的寻优精度和收敛能力,多峰函数f4~f6检测算法的全局寻优能力和避免局部收敛的能力.

表1 基准函数信息
对比算法选择如下:海洋捕食者算法(Marine Predators Algorithm, MPA)[26]、水循环算法(Water Cycle Algorithm, WCA)[27]、WOA[20].
为了保证实验的公平性,4种算法参数保持一致,即种群规模N=30,空间维度dim=30,50,最大迭代次数Maxiter=300,每种算法分别独立运行30次.实验环境设置为Windows 10 、Intel(R) CPU 3.40 GHz、8.00 GB内存,MATLAB R2016a.
4种优化算法在6个基准函数上的最优值、最差值和平均值对比如表2所示,表中黑体数字表示最优值.
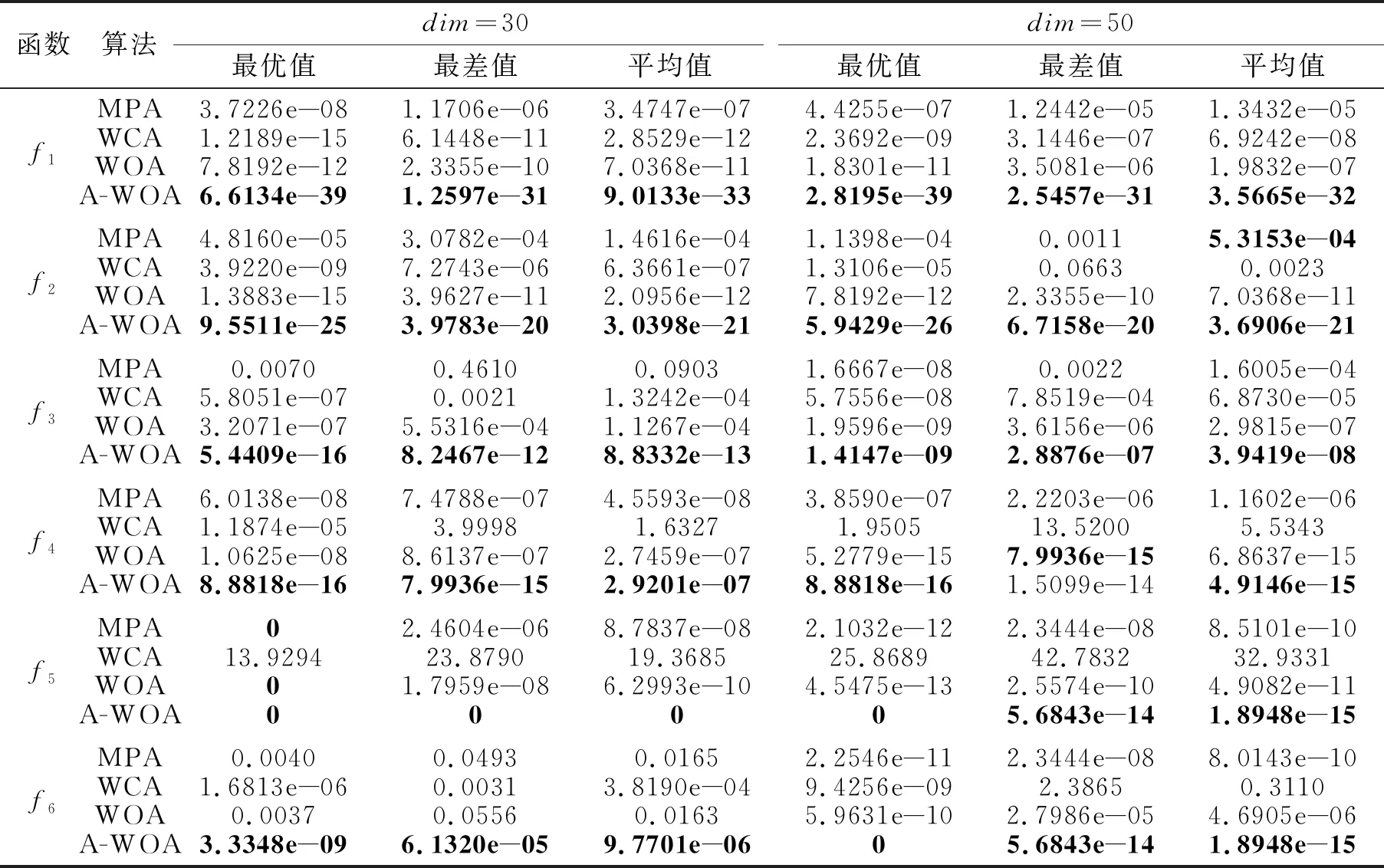
表2 各算法在6个基准函数上的性能对比
由表2可看出,A-WOA在6个基准函数上性能最优,尤其是在函数f1~f4、f6上,A-WOA的性能具有较大幅度提升.当维度为30时,在函数f5上,MPA、WOA和A-WOA最优值均为0,另外,A-WOA的最差值和平均值也达到0.当维度为50时,在函数f3上,4种算法在最优值上相差不大,但是,A-WOA在最差值和平均值上大幅优于其它3种算法.在函数f4上,WOA和A-WOA结果相差无几且明显优于MPA和WCA,但是,A-WOA取得的最优值和平均值都优于WOA.
综上所述,无论是单峰函数还是多峰函数,A-WOA表现出优越的局部寻优性能,充分说明基于动态惯性权重改进的A-WOA较好地解决WOA容易陷入局部最优和局部寻优性能不稳定的问题.
3.2 算法性能分析
为了说明FSAWFN的分类性能,在14个数据集上进行仿真实验,具体信息如表3所示,其中:前8个数据集为低维UCI数据集,选自UCI Machine Lear-ning Repository(http://archive.ics.uci.edu/ml/index.php);后面6个为高维基因数据集,选自Cancer Program Datasets(http://portals.broadinstitute.Org/cgi-bin/cancer/datasets.cgi).
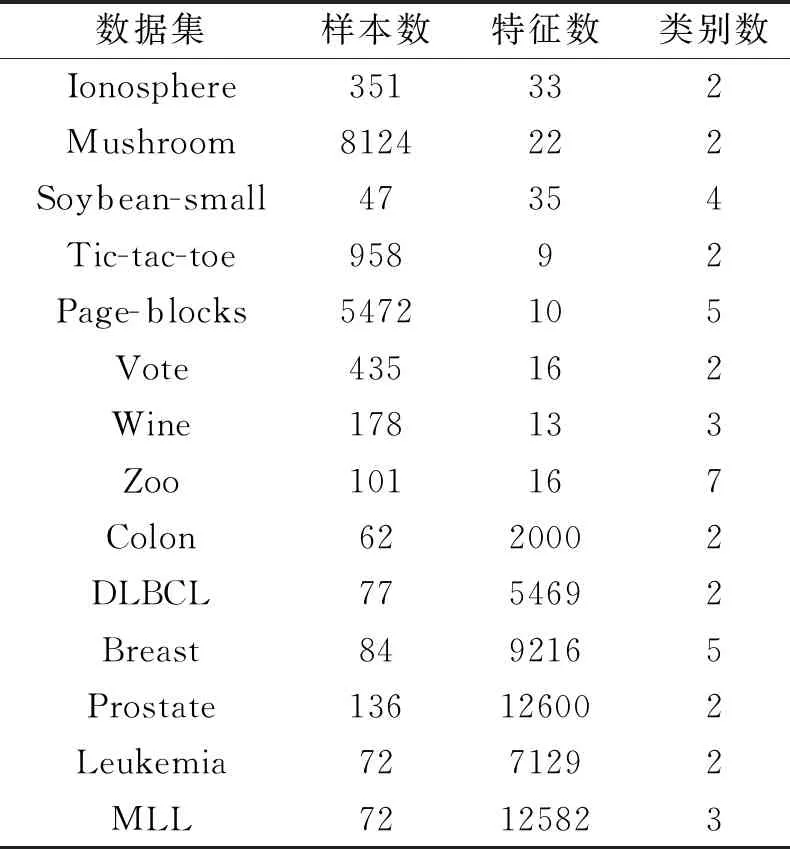
表3 实验数据集
在WEKA软件中选择J48、Naive Bayes(NB)、K近邻(KNext Neighbor, KNN)(k=10)、CART这4种分类器,验证算法的分类性能.
所有实验都通过10折交叉验证实现[28-29].依据文献[10]、文献[20]、文献[30]的参数设置方法,分别设置容错分析阈值α= 0.8,适应度函数参数λ1=0.6,λ2=0.3,λ3=0.1.
3.2.1种群个数和迭代次数的影响
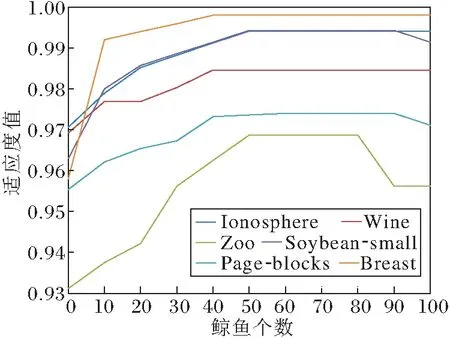
为了验证鲸鱼个数和迭代次数对实验的影响,选取Ionosphere、Wine、Zoo、Soybean-small、Page-blocks、Breast数据集进行实验,鲸鱼个数和迭代次数对适应度值的影响如图1所示.
(a)鲸鱼个数
由图1(a)可看出:当鲸鱼个数由0增至50时,适应度值也增加;当鲸鱼个数由50增至100时,适应度值趋于稳定.这说明当鲸鱼个数达到一定程度时,FSAWFN趋于稳定,对鲸鱼数量不敏感.由(b)可看出,适应度值随着迭代次数的增加而增加,当迭代次数增加到一定程度时,适应度值趋于稳定,说明FSAWFN经过迭代可收敛.因此,本文选取种群个数为50,迭代次数为50,进行后续的特征选择实验.
3.2.2邻域半径的选择
由于邻域半径的不同,特征选择得到的约简子集和分类精度也不同,直接影响实验结果,于是通过研究不同邻域参数对特征子集的约简率[1]和分类精度的影响,为每个数据集选择最优的邻域半径.对于6个高维基因数据集,为了有效降低算法的时空复杂度,采用Fisher score[9,14]初步降维,在WEKA上获取7种不同维度下的分类精度如表4所示,表中黑体数字表示最优结果.由表可见,当分类精度最优时,Colon数据集上选择合适的维度是500维,DLBCL、Leukemia数据集上选择合适的维度是300维,Breast数据集上选择合适的维度是50维,Prostate数据集上选择合适的维度是100维,MLL数据集上选择合适的维度是200维.
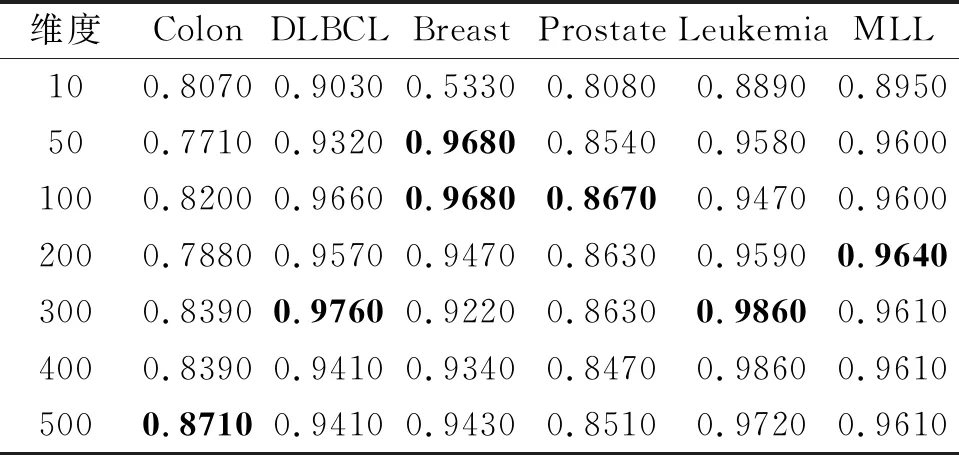
表4 6个高维基因数据集在7种不同维度下的分类精度
在14个数据集上,使用WEKA中的J48和NB分类器计算分类精度,参照文献[1]、文献[17]最大限度地平衡分类精度和约简率的方法,通过实验选择最优邻域半径,设置邻域半径δ∈[0.05, 0.95],以0.1为步长.于是,FSAWFN在不同的邻域半径下进行特征选择,平衡分类精度和约简率,为每个数据集选择最优的邻域半径,具体如表5所示.

表5 2个不同分类器在14个数据集上的最优邻域半径
3.2.3优化特征选择算法性能对比
为了有效体现WOA[20]在特征选择上的运用及其实验效果,本文构建基于WOA的特征选择算法(Feature Selection Based on WOA, WOAFS)和基于A-WOA的特征选择算法(Feature Selection Based on A-WOA, A-WOAFS),进一步分析WOAFS、A-WOAFS和FSAWFN的分类性能.从表3中选择10个数据集进行特征选择实验,分类精度如表6所示,表中黑体数字表示最优结果.

表6 3种基于WOA的优化特征选择算法的分类精度
由表6可知,A-WOAFS选择的特征个数均少于WOAFS,在分类精度方面,除了Wine、Tic-tac-toe数据集以外,A-WOAFS在J48和NB分类器上所得的分类精度高于WOAFS.在Wine数据集上,虽然A-WOAFS在J48和NB分类器上所得的分类精度略低于WOAFS,但特征个数少于WOAFS,获得的分类精度仅略低于WOAFS.在Tic-tac-toe数据集上,虽然A-WOAFS在NB分类器上的分类精度比WOAFS降低0.032,但A-WOAFS选择特征个数少于WOAFS,并且在J48分类器上的分类精度高于WOAFS,因此,A-WOAFS性能优于WOAFS. FSAWFN在10个数据集上选择特征个数少于A-WOAFS,并且分类精度高于A-WOAFS,由此可看出,将本文改进的A-WOA与容错邻域粗糙集结合能选择特征个数较少且分类精度较高的特征子集.
3.2.4在低维UCI数据集上的实验结果
根据由表5得到的邻域半径,从选择的特征数量和分类精度两方面对比分析FSAWFN在低维UCI数据集上的分类性能.对比算法如下:PSORSFS[21]、DQBGOA_MR(Dynamic Population Quantum Binary Grasshopper Optimization Algorithm Based on Mutual Information and Rough Set Theory)[30]、ARRSFA(Attribute Reduction Based on Rough Sets and Discrete Firefly Algorithm)[31]、FSARSR(Fin-ding Rough Set Reducts with Fish Swarm Algori-thm)[32]、QCSIA_FS(Cooperative Swarm Intelligence Algorithm for Feature Selection Based on Quan-tum-Inspired and Rough Sets)[33].对比算法实验结果均来自于文献[30].
各算法在8个低维UCI数据集上选择的特征个数如表7所示,表中黑体数字表示最优结果.由表可看出,FSAWFN在8个低维UCI数据集上选择的特征个数较少,优势较明显,选择的平均特征个数最少.在Soybean-small、Zoo数据集上,FSAWFN和DQ-BGOA_MR得到的平均特征个数相近,但都达到最小值,并且少于其它4种算法得到的平均特征个数.在Ionosphere、Mushroom、Tic-tac-toe、Vote数据集上,FSAWFN选择的平均特征个数均达到最小值,优势显著.在Wine数据集上,FSAWFN选择的平均特征个数较多.在Page-blocks数据集上,FSAWFN的平均特征个数与QCSIA_FS和DQBGOA_MR相同,但都是最小值.
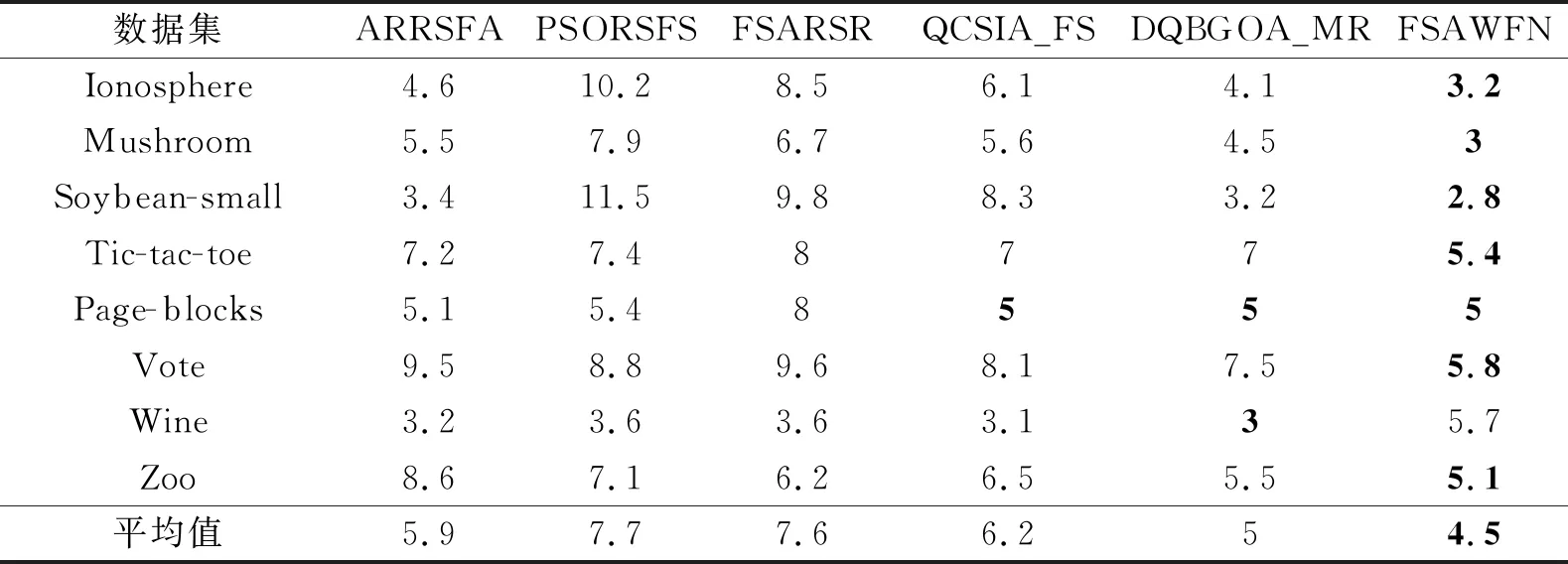
表7 各算法在8个低维UCI数据集上选择的特征个数对比
综上所述,FSAWFN在8个低维UCI数据集上能选择较小的特征子集.最终FSAWFN选择的最优特征子集如表8所示.
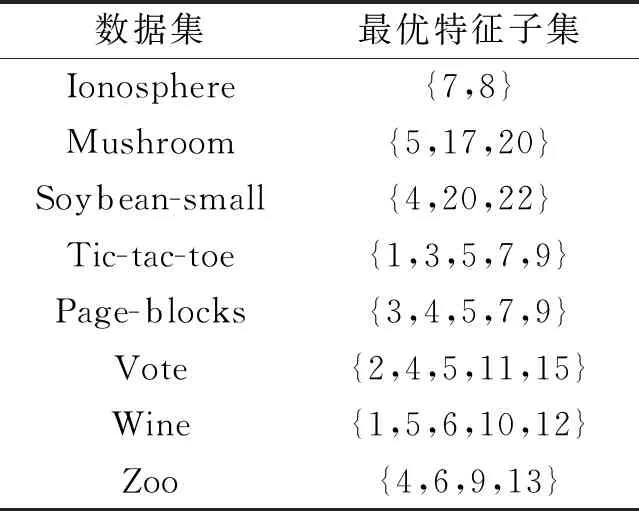
表8 FSAWFN在8个低维UCI数据集上选择的最优特征子集
各算法在J48和NB分类器上得到的分类精度和标准差如表9所示,表中黑体数字表示最优结果.由表可知,FSAWFN在J48和NB分类器上的分类精度多数能达到最大值,大于其它5种算法.在J48分类器上,除了Mushroom、Vote数据集以外,FSAWFN在其它6个数据集上均得到最大分类精度,并且在Mushroom、Vote数据集上仅比最大值分别降低0.21%和0.54%,同时FSAWFN在这2个数据集上也选择最小的特征子集.在NB分类器上,除了Ionosphere、Page-blocks数据集以外,FSAWFN在其它6个数据集上均得到最大分类精度,尤其在Tic-tac-toe、Vote、Wine、Zoo数据集上优势更显著.在Iono-sphere、Page-blocks数据集上,FSAWFN在NB分类器上的分类精度虽然略低于最大分类精度,但是,结合表7可知,FSAWFN选择的特征子集最小.结合表9给出的J48和NB分类器上的分类精度对应的标准差可看出,J48和NB分类器对应的标准差能达到较小值.
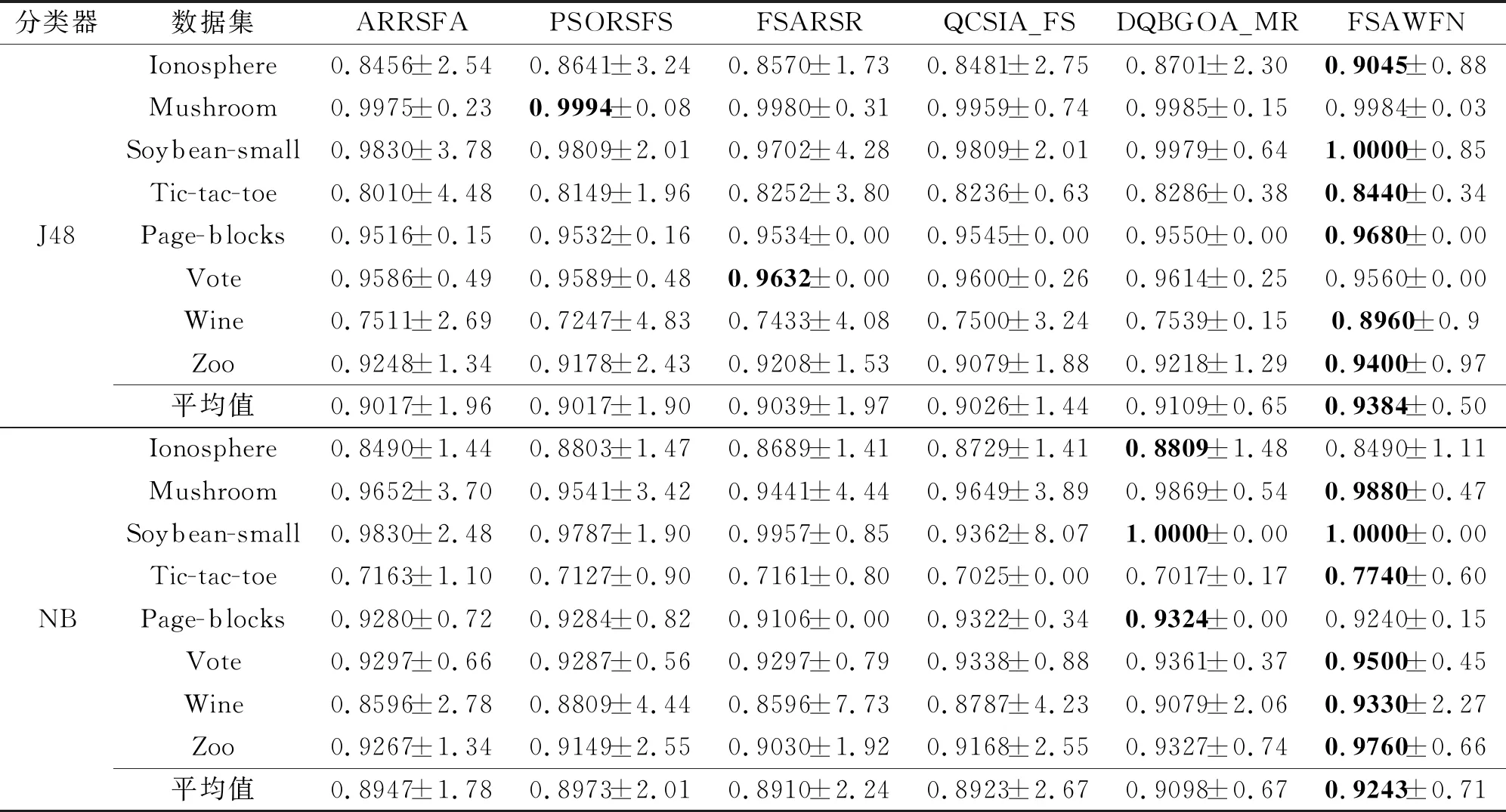
表9 J48和NB分类器上6种算法的分类精度
综上所述,FSAWFN在J48和NB分类器上能得到较小的特征子集、较大的分类精度和较小的标准差,因此具有较好的分类性能.
3.2.5在高维基因数据集上的实验结果
为了验证FSAWFN在高维基因数据集上的分类性能,选择如下对比算法:FSNTDJE[17]、CFS(Co-rrelation Feature Selection)[29]、FCBF(Fast Correla-tion-Based Filter Algorithm)[34]、INT(Interacting Fea-tures Selection Algorithm)[34]、IG(Information Gain Based Feature Selection Algorithm)[35].
为了方便验证和实验对比,根据文献[17]和文献[32]的实验设计,选择Colon、DLBCL、Breast、Prostate高维基因数据集,在J48和NB分类器上进行对比实验.
通过10折交叉验证,各算法选择的基因个数如表10所示,表中黑体数字表示最优结果.FSAWFN选择的最优基因子集如表11所示.

表11 FSAWFN在2个分类器上选择的最优基因子集
由表10可看出,除了DLBCL数据集以外,FSAWFN优势明显,均选择最小的基因子集.在DLBCL数据集上,尽管FSAWFN选择的特征个数多于IG,但优于CFS、FCBF、INT和FSNTDJE.在NB分类器上,FSAWFN在Colon数据集上优势显著,选择最小的基因子集;在J48分类器上,FSAWFN在Prostate数据集上优势显著.总之,FSAWFN能选择较小基因子集,并获得较少平均基因个数.
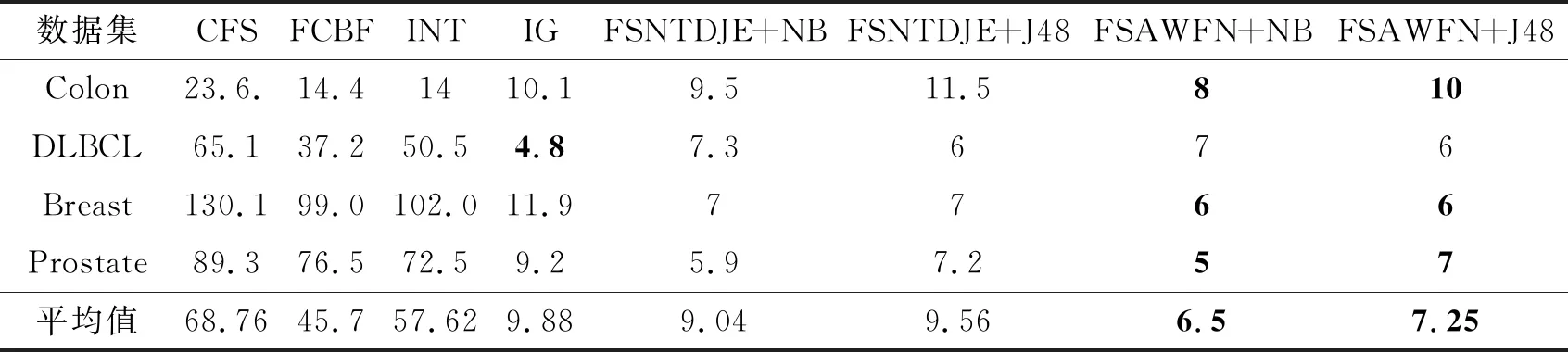
表10 各算法在4个高维基因数据集上选择的基因个数
下面依据文献[17]和文献[25]中3个评价指标,即精度(Accuracy, Acc)、真正例率(True Posi-tive Rate, TPR)、假正例率(False Positive Rate, FPR),评价FSAWFN在Colon、DLBCL、Breast、Pros-tate数据集上的分类结果.通常TPR越大,FPR越小,算法性能越优.NB和J48分类器上各算法在4个数据集上的指标值如表12和表13所示,表中ODP表示原始数据处理算法,黑体数字表示最优值.
由表12和表13可看出,除了J48分类器上的DLBCL数据集和NB分类器上的Prostate数据集以外,FSAWFN都能得到较好的分类精度.从整体上看,相比其它算法,FSAWFN能得到较高的Acc值和较低的FPR值.在NB分类器上,在DLBCL数据集上,虽然FSAWFN选择的基因个数多于IG,但3个指标值均优于IG,并且TPR达到最大值,FPR达到最小值.对于Acc指标,FSAWFN在Colon、Breast、Prostate数据集上表现较优.对于TPR指标,FSAWFN在DLBCL数据集上达到最大值1.对于FPR指标,FSAWFN在DLBCL、Prostate数据集上达到最小.
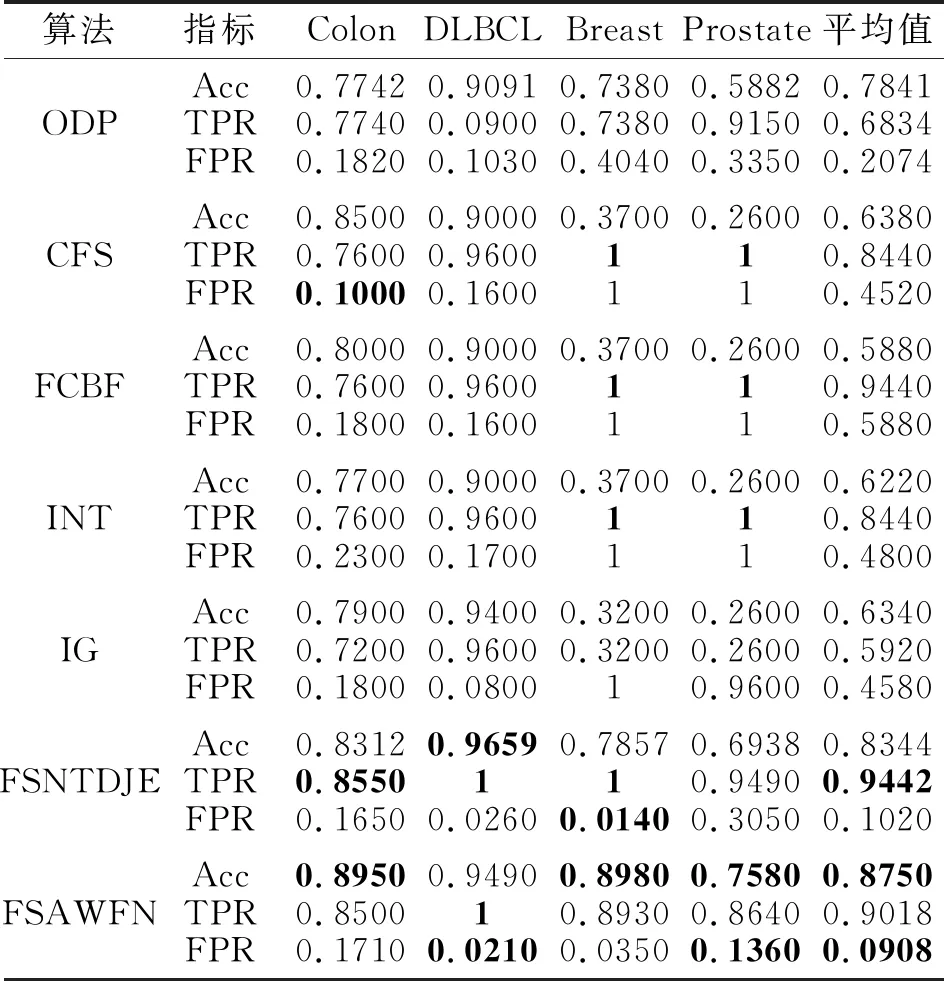
表12 各算法在NB分类器下的指标值
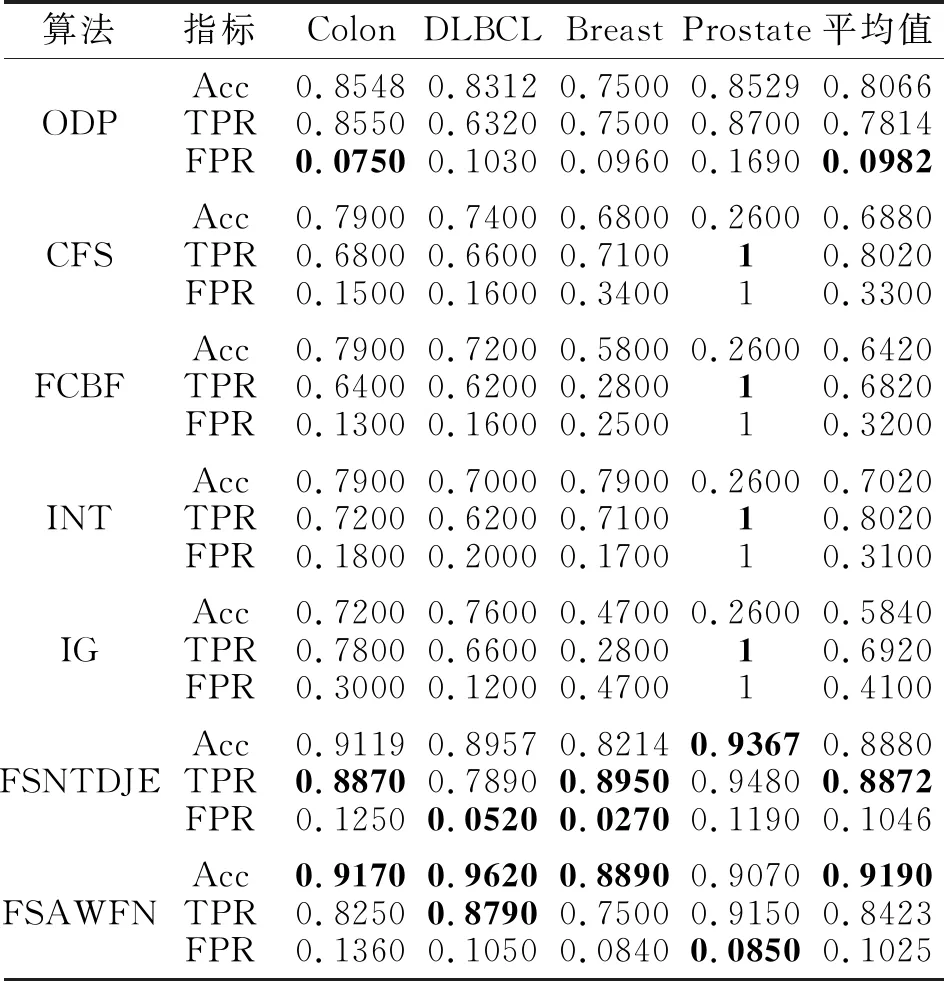
表13 各算法在J48分类器下的指标值
同样地,在J48分类器上,FSAWFN在Prostate数据集上获得的Acc、TPR值都略小于最优值,但是选择的基因个数最少,并且FPR也达到最小值.对于Acc指标,FSAWFN在Colon、DLBCL、Breast数据集上表现较优.对于TPR指标,FSAWFN在DLBCL数据集上达到最大值1.对于FPR指标,FSAWFN在Prostate数据集上达到最小.
为了进一步验证FSAWFN在高维数据集上的分类性能,选取Colon、Leukemia、Breast、MLL数据集.对比算法选择ODP、FSNTDJE[17]、DMRA(Dis-cernibility Matrix-Based Reduction Algorithm)[36]、FPR(Fuzzy Positive Region Reduction)[37]、FRFS(Fuzzy-Rough Feature Selection Algorithm)[38]、IFPR(Intuitionistic Fuzzy Positive Region Based Gene Selection Algorithm)[39].通过10折交叉验证,获得KNN(k=10)和CART分类器上的分类精度如表14所示.
由表14可见,FSAWFN在4个高维数据集上均取得最大的分类精度.在KNN分类器上,FSAWFN在Leukemia、Breast数据集上优势明显.在Colon、MLL数据集上,FSAWFN分类精度略高于FSNTDJE,但优于ODP、DMRA、FPR、FRFS、IFPR.在CART分类器上, FSAWFN在Leukemia、Breast、MLL数据集上优势明显.在Colon数据集上,FSAWFN分类精度率略高于FSNTDJE,但优于ODP、DMRA、FPR、FRFS、IFPR.因此FSAWFN具有较好的分类效果.
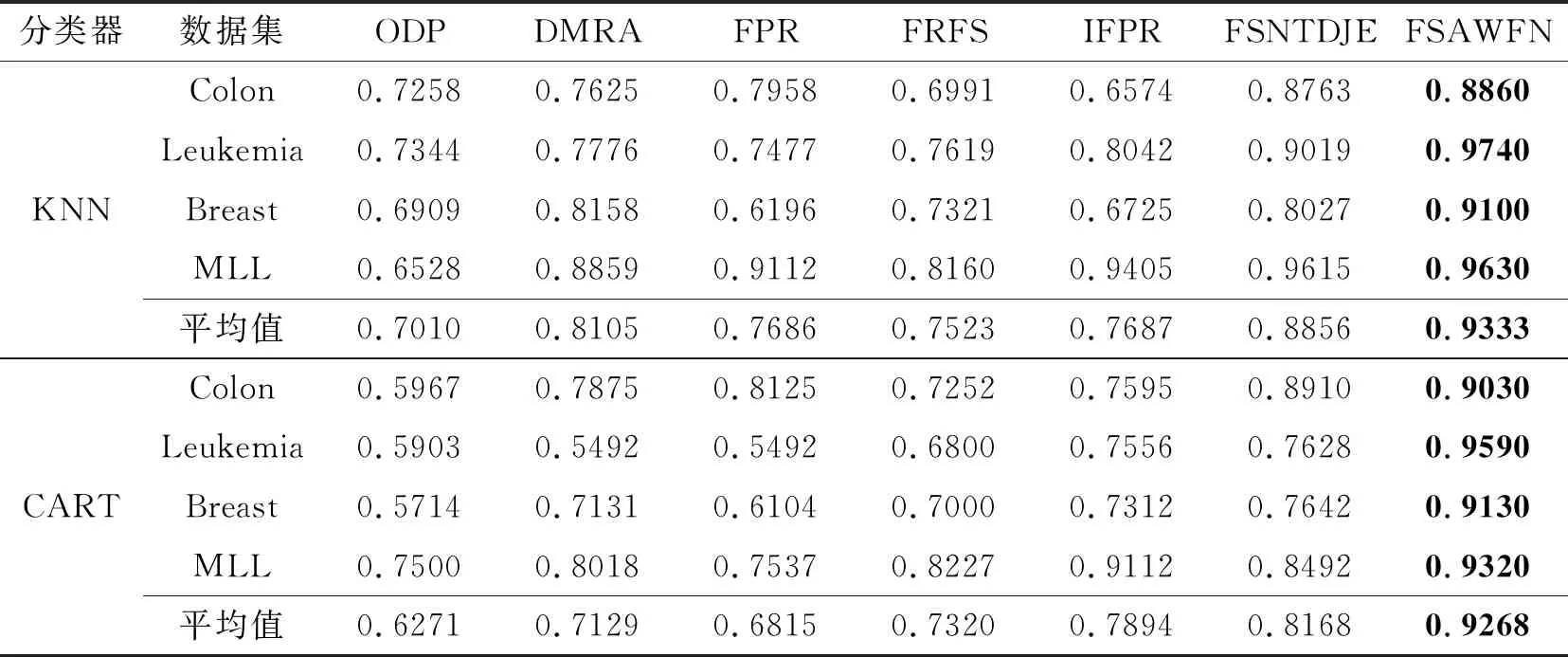
表14 KNN和CART分类器上7种算法的分类精度
3.3 统计分析
为了对FSAWFN的分类结果进行统计验证,选择Friedman检验和Bonferroni-Dunn检验,分别定义如下:
其中,s为算法数量,T为数据集数量,Ra(a=1,2,…,s)为第a种算法的平均排序.FF服从F分布,如果通过Friedman检验得到的所有算法性能明显不一样,需要post-hoc检验以对比各算法,常用的后续检验为Nemenyi检验,临界差值[40]为:
其中,α为显著性水平,这里选择α=0.1,qα为临界值.
根据表9中各算法在8个UCI数据集上的分类精度,进行Friedman检验,结果如表15所示.当α=0.1时,
由表15可知,在J48和NB分类器上各对比算法性能显著不同,于是进行post-hoc检验.

表15 J48和NB分类器上6种算法的统计结果
为了直观说明算法的差异,6种算法在J48和NB分类器上的Bonferroni-Dunn检验结果如图2所示.
由图2(a)可知,FSAWFN平均排序最小,与DQBG-OA_MR、FSARSR、PSORSFS无显著性差距,但明显优于ARRSFA和QCSIA_FS.由(b)可知,FSAWFN平均排序最小,明显优于FSARSR.总之,FSAWFN性能最优.

(a)J48 (b)NB
对表14中4个高维基因数据集的分类精度进行Friedman检验,结果如表16所示.当α=0.1时,
q0.1=2.326,CD=3.077,
根据表16可知,在KNN和CART分类器上各算法的性能显著不同,因此进行post-hoc检验.

表16 KNN和CART分类器上6种算法的统计结果
各算法在KNN和CART分类器上的Bon-ferroni-Dunn检验结果如图3所示.由(a)可看出,FSAWFN平均排序最小,与FSNTDJE、DMRA、IFPR无显著性差距,优于FRFS和FPR.由(b)可知,FSAWFN平均排序最小,优于FRFS、FPR、DMRA.总之,FSAWFN明显优于其它算法.

(a)KNN (b)CART
4 结 束 语
利用WOA操作简单、计算参数较少、全局寻优能力较强等优点,本文提出基于自适应WOA和容错邻域粗糙集的特征选择算法(FSAWFN).首先,提出动态惯性权重,设计自适应WOA.然后,解决邻域粗糙集缺乏容错性问题,提出容错上下近似集、容错近似精度、容错近似粗糙度、容错依赖度及容错近似条件熵.最后,使用自适应WOA进行预处理,获取最优子群,进而结合容错邻域粗糙集设计特征选择算法.在8个UCI数据集和6个高维基因数据集上的实验表明:本文算法是有效的,通过对WOA进行的自适应改进,能更容易收敛到最优或接近最优解;将自适应WOA与容错邻域粗糙集结合能使算法更快找到最小特征子集.但是,在运行时效上,本文算法的改善效果并不明显,这是下一步需要研究的内容.
