基于AdaBelief的Heavy-Ball动量方法
2022-03-11张泽东
张泽东 陇 盛 鲍 蕾 陶 卿
随机梯度下降法[1]是解决优化问题的经典算法之一,在其基础上添加动量和自适应步长技巧是机器学习领域用于提升优化算法性能常用的两种方式.动量方法利用梯度的历史累积信息调整解向量的更新方向,而自适应步长技巧利用梯度的历史信息调整梯度在不同维度上的步长.从理论分析的角度上说:动量方法能加速梯度下降方法的收敛速率,避开非凸优化中的局部极小点和鞍点[2-3];自适应步长方法能降低对人为指定步长的依赖,在处理稀疏学习问题时具有更紧的收敛界[4-5].
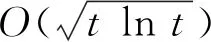
为了进一步提升Adam性能,学者们开始试图对自适应步长方法进行更精细的改进[10].特别是Zhuang等[11]提出AdaBelief,在Adam的基础上将动量的EMA形式看成是下一次迭代的预估方向,根据当前位置梯度方向是否与动量的EMA形式方向一致而灵活地调整步长.当梯度方向与动量的EMA形式方向一致时,选择相信,采用较大的步长;当两者方向相反时,选择怀疑,采用较小的步长.AdaBelief的这种步长策略更好地适应问题自身的特征,同时具有Adam快速收敛特性和随机梯度下降法的泛化性能.实验表明,AdaBelief在训练和测试精度方面均取得较优的实际效果,但由于其使用与Adam一样的EMA策略,仍无法避免收敛性方面存在的Reddi问题,导致未能较好体现动量的加速性能.
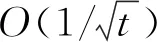
1 相关知识
本节介绍动量方法和自适应算法,以及它们的收敛性.
考虑约束优化问题:

其中,f(w)为目标函数,一般为凸函数,Q⊆Rn为有界闭凸集.投影次梯度方法的迭代步骤[1]为
wt+1=wt-αtgt.
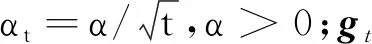
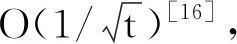
为了简单起见,与文献[8]和文献[13]一样,在算法的更新公式中省略偏差修正步骤.Adam更新公式如下[6]:
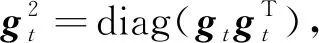
可以看出,Adam与投影次梯度算法的不同主要体现在使用动量的EMA形式mt调整参数更新方向,并采用自适应矩阵Vt调整参数更新的每维步长.
AMSGrad具体形式如下:
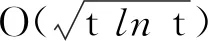
AdaBelief更新公式如下:
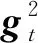
Heavy-Ball动量方法的迭代公式为
wt+1=wt-αtgt+βt(wt-wt-1),
其中,αt为设置的衰减学习率,βt∈[0,1)为动量系数[2],wt-wt-1为动量项.当动量系数为常数时,分别将Heavy-Ball动量和EMA动量展开为梯度累加和的形式,可得
可以看出,Heavy-Ball动量在参数更新时利用αi(i=1,2,…,t)的信息,而动量的EMA形式仅利用αt的信息,另外当动量系数β趋近于1时,(1-β)→0,使用动量的EMA形式时,wt+1≈wt, 而使用Heavy-Ball动量却不会出现这样的问题[12].
AdaHB迭代公式为
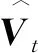
2 基于AdaBelief的Heavy-Ball动量方法
本节提出基于AdaBelief的Heavy-Ball动量方法(AdaBHB),给出在目标函数为非光滑一般凸情况下算法的最优个体收敛性证明.
将AdaBelief策略下的自适应步长技巧与AdaHB结合,提出AdaBHB,迭代形式为
不同于AdaHB,AdaBHB中自适应矩阵St的更新借鉴AdaBelief的思想,即对当前梯度与动量项差值的外积矩阵对角阵进行EMA平均,与之不同的是动量项不再采用EMA形式的动量mt,而是借鉴AdaHB的思想,采用Heavy-Ball动量wt-wt-1.
在进行最优个体收敛性的证明时,参考Tao等[13]提出的仅采用EMA策略调整步长的Heavy-Ball动量方法的收敛性分析思路,引入加权动量项
pt=t(wt-wt-1),
巧妙选取时变步长αt和动量因子β1t,从而将AdaBHB的迭代方式转化为类似于投影次梯度法的形式[13]:
借鉴此方法处理迭代,得到如下引理1.为了证明的简洁性,这里的证明采用无约束情况下的证明方式,有约束情况下的证明只需在此基础上利用投影的非扩张性即可.
引理1令
pt=t(wt-wt-1),
假设wt由式(1)产生,取
则有
(2)
证明根据迭代式(1),并令
pt=t(wt-wt-1),
有
wt+1+pt+1=wt+1+(t+1)(wt+1-wt)=
(t+2)wt+1-(t+1)wt=
代入
可得
证毕
基于式(2)可证明定理1,但为了解决变步长和动量系数导致的递归问题,先提出引理2.
引理2令
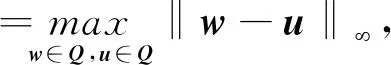
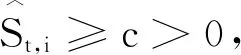
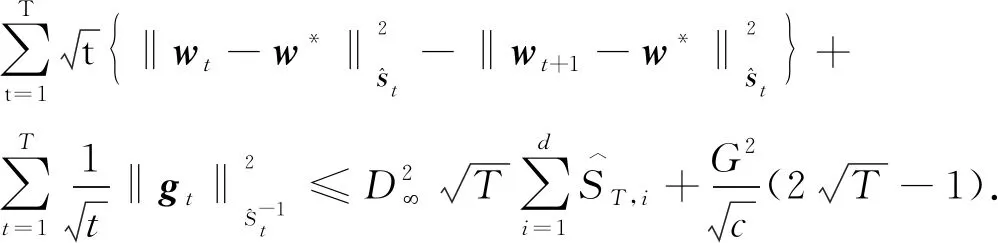
证明使用Zhuang等[11]证明在线AdaBelief的regret界时采用的迭代技巧,进行如下整理:
证毕
定理1设f(w)为一般凸函数,取
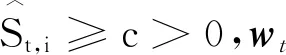
证明由引理1及投影的非扩张性可得
将上式从t=1,2,…,T累加,得
根据引理2,可得
证毕
推论1设f(w)为一般凸函数,取
wt由式(1)产生,则
推论1也表明个体收敛速率比平均收敛速率更难以获得.综上所述,获得AdaBHB在非光滑一般凸条件下的个体收敛速率.然而上述证明都是在批处理条件下完成的,所以这种操作并不适用于大规模数据集.为了使AdaBHB适合处理大规模机器学习问题,接下来将算法推广至随机形式.
考虑较简单的二分类问题,训练样本集:
S={(xi,yi)|i=1,2,…,m}⊆Rn×{1,-1},
其中,xi为样本特征,yi为样本的标签值,假设(xi,yi)是独立同分布的.
假设非光滑学习问题的损失函数为hinge损失,即
fi(w)=max{0,1-yi〈w,xi〉},
则优化目标函数为:
由于hinge损失函数的次梯度有多种计算方式,这里采用文献[18]的方式进行计算,即

(3)
其中,
实验中设定|At|=1,i是算法迭代到第t步时为计算当前梯度而随机抽取的样本序号.当样本满足独立同分布条件时,经过随机抽取方式计算得到的随机次梯度∇fi(wt)就是梯度在wt处的无偏估计.
约束条件下随机形式的AdaBHB的迭代公式如下:
(4)
相比批处理形式下次梯度gt的每次计算都需遍历样本集,随机次梯度∇fi(wt)只需选取一个样本即可.
AdaBHB的执行步骤如下所示.
算法AdaBHB
输入循环次数T
输出wT
初始化向量w1∈Q
Fort=1 toT
等可能地选取i=1,2,…,m
根据式(3)计算次梯度∇fi(wt)
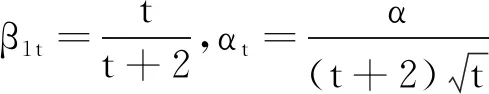
通过式(4)计算wt+1
End for
从算法中可看出,随机形式的算法只是将批处理形式下目标函数的梯度替换为无偏估计.Rakhlin等[19]给出将批处理算法的regret界转换为随机算法regret界的技巧,该技巧对于定理1同样成立.与文献[14]和文献[15]类似,本文可将定理1推广至随机形式,得到定理2.
定理2设f(w)为一般凸函数,取
wt由式(4)产生,则
E(f(wT)-f(w*))≤
3 实验及结果分析
凸优化实验中的问题模型为支持向量机中常见的hinge损失.本文采用Astro、A9a、Covtype、Ijcnn1、Rcv1、W8a标准数据集,均来源于LIBSVM网站.
在深度学习实验中,按照Wang等[20]和Tao等[13]的思路,模型为典型的ResNet-18网络及构造的一般4层卷积神经网络(Convolutional Neural Net-work, CNN),采用CIFAR10、CIFAR100和MNIST常用标准数据集.CIFAR10数据集包含50 000个训练样本,10 000个测试样本.CIFAR100数据集包含50 000个训练样本,10 000个测试样本.MNIST数据集包含60 000个训练样本,10 000个测试样本.
为了验证AdaBHB既在理论上具有最优收敛性,又在实验上具有良好效果,对比算法选取理论上收敛性最优的Heavy-Ball(HB)算法、AdaHB,以及在实验上表现良好的随机梯度下降(Stochastic Gradient Descent, SGD)、Adam、Ada-Belief.
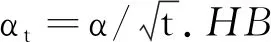
为了降低随机因素产生的影响,各算法在每个数据集上均运行5次,取平均值作为最后输出.
在凸优化实验中,调用有效投影稀疏学习(Spares Learning with Efficient Projections, SLEP)工具箱的函数,实现投影的计算,PQ为l1范数球
{w∶‖w≤z‖1}
上的投影算子.根据数据集的不同,z对应选取不同的值,并且各算法均取相同的约束参数.从理论分析的角度出发,AdaBHB应具有最优的收敛速率.
各算法在6个数据集上的收敛速率对比如图1所示,图中纵坐标表示当前目标函数值与最优目标函数值之差.由图可见,在100步迭代之后,各算法在6个标准数据集上都达到10-4的精度,收敛趋势基本相同,AdaBHB收敛最快,这与理论分析是吻合的.

(a)Astro (b)A9a (c)Covtype
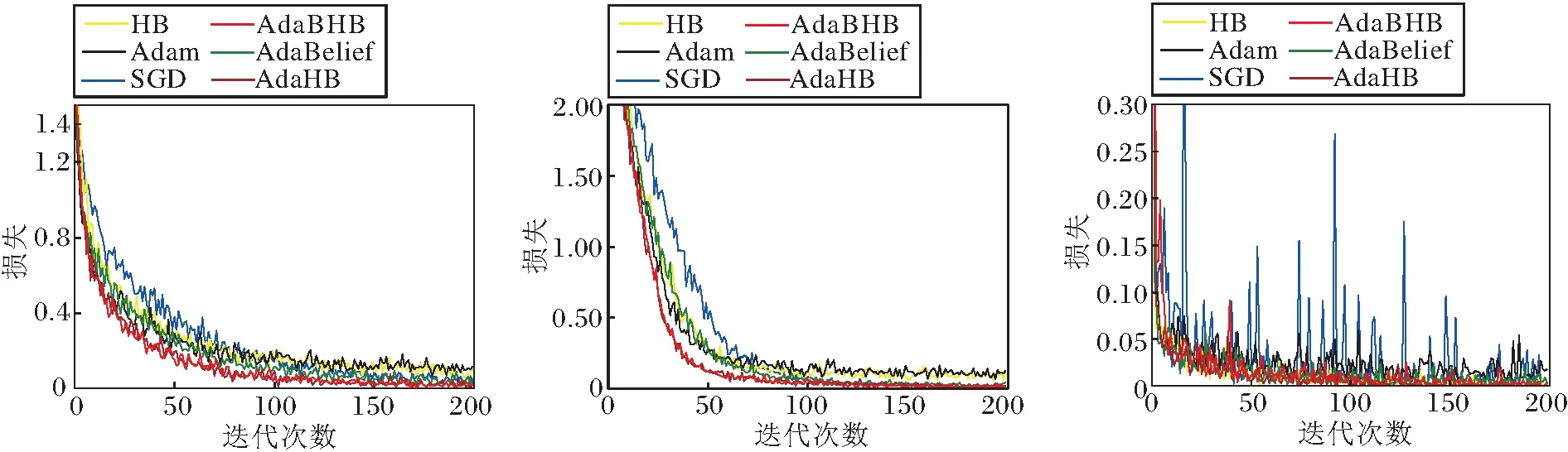
在深度学习实验中,采用参数权重衰减和批量归一化策略以减少过拟合,所用的损失为交叉熵.图2为各算法在2个网络上的损失对比,图3为各算法在2个网络上的测试精度对比.
(a1)CIFAR10 (a2)CIFAR100 (a3)MNIST

(a1)CIFAR10 (a2)CIFAR100 (a3)MNIST
由图2和图3可见,AdaBHB在损失降低速率上明显占优,这也促进其在测试精度上效果良好.在其它深度学习网络上的实验也验证AdaBHB取得较优的实验效果,因此具有普遍性.由于论文篇幅限制,本文仅展示较典型的残差网络Res-Net18和CNN4上的结果.
实验表明, AdaBHB不仅在非光滑凸条件下理论上可获得最优的个体收敛速率,并且在深度学习实验中也取得性能的提升.这也说明AdaBelief 的步长调整技巧可作为一般性的减少震荡、提升算法泛化性能的方法.AdaBHB结合传统动量方法的优点,可发展出更多性能良好的优化算法.
4 结 束 语
本文结合AdaBelief的步长调整技巧和Heavy-Ball型动量项,提出基于AdaBelief的Heavy-Ball动量方法(AdaBHB),证明算法具有最优的个体收敛速率,并在深度学习实验中得到验证.今后将研究强凸情况下AdaBHB的个体收敛速率,以及将Nesterov加速梯度(Nesterov Accelerated Gradient, NAG)型动量与AdaBelief的步长调整技巧结合的优化算法的收敛速率等问题.
