联合深度图聚类与目标检测的像素级分割算法
2022-03-11方宝富
方宝富 张 旭 王 浩
近年来,随着人工智能与机器人技术的深入发展,自主移动机器人受到越来越多研究人员的关注,而同时定位与建图(Simultaneous Localization and Mapping, SLAM)[1]是这一领域的重要技术,主要研究机器人在未知环境中自主探索、确定自己位置并对周围的环境建立地图.早期的SLAM技术大多采用声呐及激光雷达等传感器实现,经过多年发展,已得到深入研究并形成稳定的框架,能精确测量机器人周围的环境,但由于其成本高昂和应用场景不足的局限性,很难大规模地使用,于是基于单目、双目及RGB-D等相机作为传感器的视觉SLAM[2]开始成为研究的主要方向.随着学者们提出越来越多的视觉方法,视觉SLAM技术在室内静态环境下在自身的定位和建图精度方面已取得不错成果.
视觉SLAM按照视觉里程计的具体实现算法可分为基于特征点法和基于直接法.Mur-Artal等[3]提出ORB-SLAM2,匹配当前帧和前一帧中的ORB特征点以估计相机运动,能适应单眼、双眼及RGB-D相机三种设备,在广泛多样的环境中都能保证实时性.在ORB-SLAM2的基础上,Campos等[4]提出ORB-SLAM3,完全依赖于最大后验估计的基于特征、紧耦合的视觉惯性SLAM,及基于路标识别方法的多地图系统.相比特征点法,徐浩楠等[5]提出半直接法系统,采用增量式光束法平差进行相机位姿优化,为跟踪线程提供精确信息,同时将各个图像像素反投影到三维空间中,得到高精度的稠密三维地图.
上述视觉SLAM算法在静态的室内环境中具有较优性能,但是:1)由于真实世界的复杂性,动态物体的存在在很大程度上干扰SLAM系统的位姿估计与建图效果;2)越来越高级的任务被提出,获取周围环境中的语义信息也成为SLAM技术的热门话题.降低环境中动态物体的影响和增强机器人对世界信息的理解正逐渐成为SLAM技术研究的重点.因此,学者们提出语义SLAM[6].
目前语义SLAM系统主要采取在传统视觉SLAM系统的基础上添加深度学习算法检测物体的方式以获取语义信息,得益于近年来深度学习在计算机视觉领域的发展,各种基于RGB-D相机结合深度学习的语义SLAM相继出现.Yu等[7]提出DS-SLAM(A Complete Semantic SLAM System in Dyna-mic Environments),结合SegNet(Deep Fully Convolu-tional Neural Network Architecture for Semantic Pixel-Wise Segmentation)[8]和运动一致性检测方法,降低动态目标的影响,并建立语义八叉树地图.Bescos等[9]提出DynaSLAM(Tracking, Mapping and Inpain-ting in Dynamic Scenes),同样基于ORB-SLAM2,添加Mask R-CNN(Mask Region-Based Convolutional Neu-ral Network)和背景修复功能,在单眼、双眼和RGB-D的动态序列上具有较好的鲁棒性.该团队发布DynaSLAM II(Tightly-Coupled Multi-object Tracking and SLAM in Dynamic Scenes)[10],在原来的基础上加入多目标跟踪功能,但只对刚性物体有效.Zhong等[11]提出Detect-SLAM(Making Object Detection and SLAM Mutually Beneficial),将单帧多边界框检测方法(Single Shot MultiBox Detector, SSD)[12]融入传统视觉SLAM系统,实现SLAM技术与目标检测之间的相互促进.付豪等[13]提出基于语义和光流约束的动态环境下的SLAM,采用DeepLab v3语义分割网络获取语义信息,结合光流信息,提出动态特征点过滤算法,并提出动态环境下的静态语义地图构建方法,大幅降低存储空间的需求.Fan等[14]采用BlizNet(A Real-Time Deep Network for Scene Understanding)[15]获取图像中动态物体的语义分割结果,提出可在高度动态的环境下建立具有更高精度的点云地图的语义SLAM.Qi等[16]基于图方法,将3D点云分割为多个集群,同时将YOLO V3(You Only Look Once: Unified, Real-Time Object Detection)[17]目标检测方法添加到传统ORB-SLAM2系统中,并把语义信息投影到相应三维点,建立带有语义标签的3D稠密点云地图.
在上述语义SLAM系统常用的网络中,语义分割或实例分割网络可获得像素级别的分割结果,在剔除动态物体和添加地图语义信息时具有较高精度,但一般运算量较大,难以保证SLAM系统对实时性的要求.基于目标检测的方法运算速度较快,却只能得到物体所在的矩形边界框,限制分割结果的精度.
针对上述问题,同时为了提高对深度图像的利用率,本文提出联合深度图聚类与目标检测的像素级分割算法,在保证实时性的前提下,提高当前语义SLAM系统的定位精度.首先,采用均值滤波算法对深度图的无效点进行修复,使深度信息更真实可靠.然后,分别对RGB图像和对应的深度图像进行目标检测和K-means聚类处理,结合两者结果得出像素级的物体分割结果.最后,利用上述过程的结果剔除周围环境中的动态点,建立完整、不含动态物体的语义地图.为了验证算法的可行性,以TUM数据集和真实家居场景作为实验环境,分别进行深度图修复、像素级分割、估计相机轨迹与真实相机轨迹对比的实验.整个实验表明,本文算法在公开数据集和真实环境上均具有较好的实时性与鲁棒性.
1 联合深度图聚类与目标检测的像素级分割算法
ORB特征点作为SLAM中的经典方法,采用FAST(Features from Accelerated Segment Test)检测特征点,同时采用BRIEF(Binary Robust Independent Elementary Features)计算描述子,具有稳定的旋转不变性和光照不变性,结合BA(Bundle Adjustment)优化等算法,本文基于ORB-SLAM2,设计联合深度图聚类与目标检测的像素级分割算法.在ORB-SLAM2系统的跟踪线程、局部建图、回环检测及建图等基础线程上加入语义分割线程,用于获取环境中的语义信息和剔除动态特征点,并在最终的地图中加入语义标签,建立三维语义点云地图.具体系统布局如图1所示.
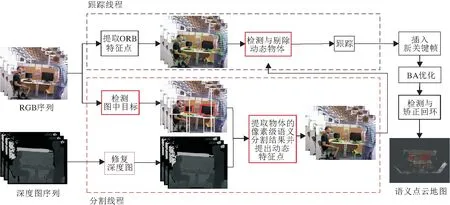
图1 系统结构图
在语义分割线程中,首先将深度图像进行均值滤波修复.然后采用目标检测算法处理RGB图像,将得到的目标边界框结果融入深度图中进行聚类,得到物体的语义分割结果.结合DS-SLAM中提到的运动一致性检测方法剔除动态点,减少其对视觉里程计的干扰.最后将静态物体的语义信息映射到点云地图中,得到语义地图并存储.
1.1 深度图修复
深度图像是构建地图的前提,在语义SLAM系统中,读取深度图像的信息获取像素点和相机之间的距离,进而得出其在世界坐标系中的坐标,同时由于本文算法对深度图依赖性较高,因此深度图像质量的优劣是决定性能好坏的重要因素.
在实际应用的Kinect V2相机中采用TOF(Time of Flight)[18]计算深度,开始时深度相机向外发射红外线束,在接触到障碍物时这些红外线会被反射回相机接收器,通过从发出到被接收之间飞行的时间即可计算像素点和相机之间的距离.这种方法对于结果测量较精确,但受限于环境和设备的局限性,在某些特殊情况下测量精度会急剧下降甚至失效.
在公开数据集与真实场景中,出现无效黑洞值的原因主要有如下3种.1)物体材质.某些物体的材质较光滑以至于红外线发生镜面反射,这时只有当发射器和接收器在镜面的中垂线上时才能接收到发出的红外线并计算深度值,同时由于深色物体(尤其是黑色物体)对红外光吸收能力较强,在对黑色物体的测量中有时会因为光线无法被反射接收而出现无效点.2)发射器和接收器存在一定距离,由于视差原因在某些物体的轮廓边缘会出现视觉盲区,根据光学理论,这种影响在较近的物体边缘较明显,距离越远的轮廓误差越小.3)深度相机自身磨损与老化情况严重,红外线发射器或接收器存在部分故障,如TUM数据集的某些序列上在深度图像四周总存在黑边.
为了使深度图的可信度及所建地图比真实环境的还原度更高,本文算法结合RGB图像转换之后的灰度图,在分割线程中加入基于均值滤波的修复方法.首先综合对比均值滤波算法、双边滤波算法及中值滤波算法的原理与时间性能,并进行实验的对比分析.由于均值滤波本身原理较简单,在3种滤波算法中的时间复杂度最低.同时还对比3种算法的原理.双边滤波是一种非线性的滤波算法,修复值取决于两点之间的空间距离和灰度距离的权值,得到的修复值存在一定波动.中值滤波仅取一个点作为修补值,存在较大的偶然性.均值滤波是线性滤波算法,在修复过程中如果处理每个像素,可能会造成整体图像的模糊,破坏原有图像细节.因此本文在传统的均值滤波算法中添加谨慎的筛选策略进行深度图修复,策略设计如下所述:1)跳过存在深度值的有效点.如果某一像素点的深度值大于设置阈值θ1,认为此点深度值可信并跳过,保护原有像素点不被破坏.2)跳过独立于物体之外的点.如果某一像素点的对应灰度值与滑动窗口内所有有效点的灰度值之差均小于设置阈值θ2,认为此点为正常无效点并跳过,保护真实无效值不被破坏.经过两步筛选,仅对存在于物体上的无效点进行修复,有效保护图像细节.经过实验得出,上述策略中θ1=0,θ2=5较合适.
本文采用的修复算法如下:首先使用YOLO V3目标检测算法处理彩色图像,得到图像中物体的目标边界框集合
B={Box1,Box2,…,Boxn},
其中n表示算法检测到当前帧中的物体数量.对于每个Boxi∈B,有
Boxi={xi,yi,widthi,heighti},
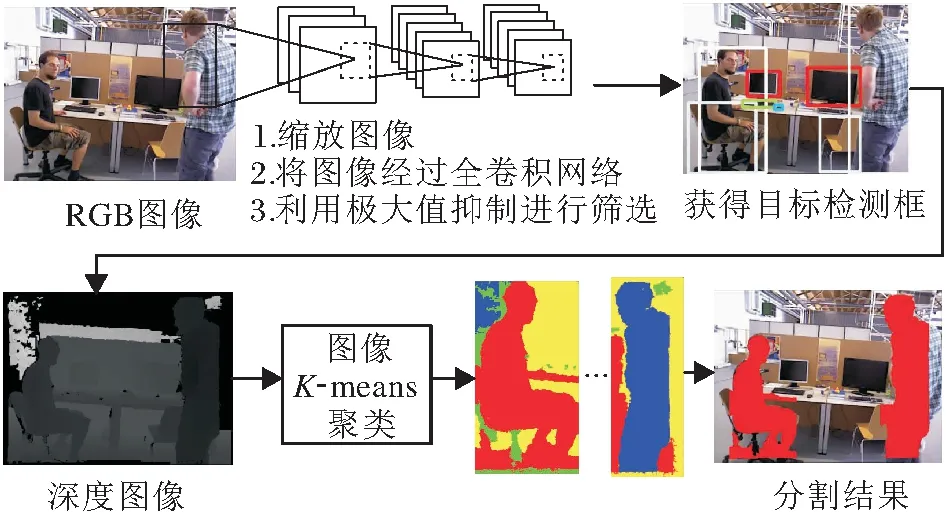
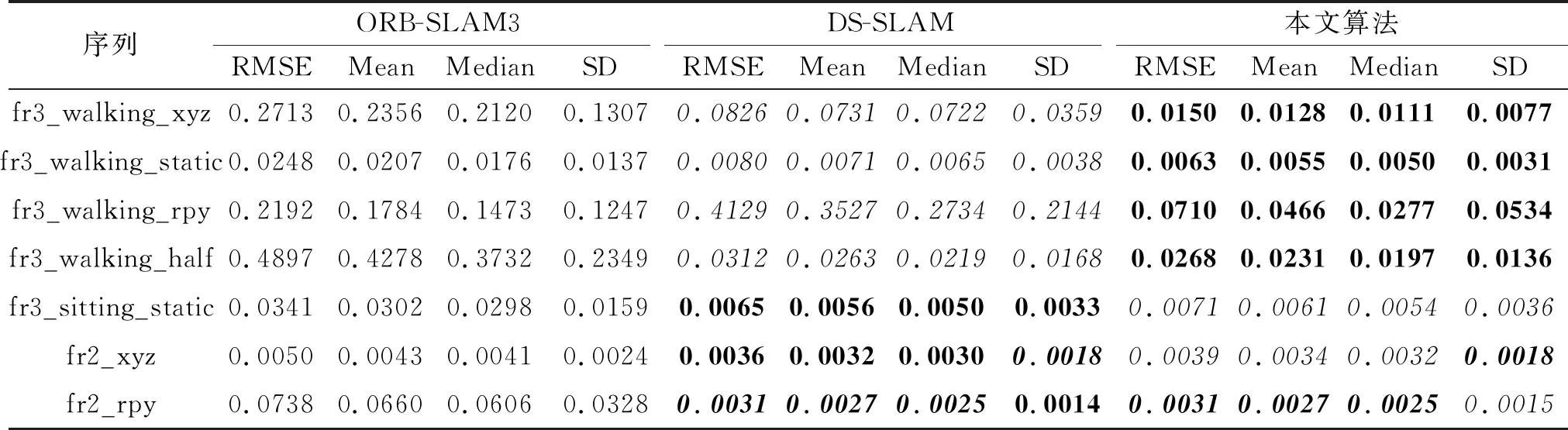
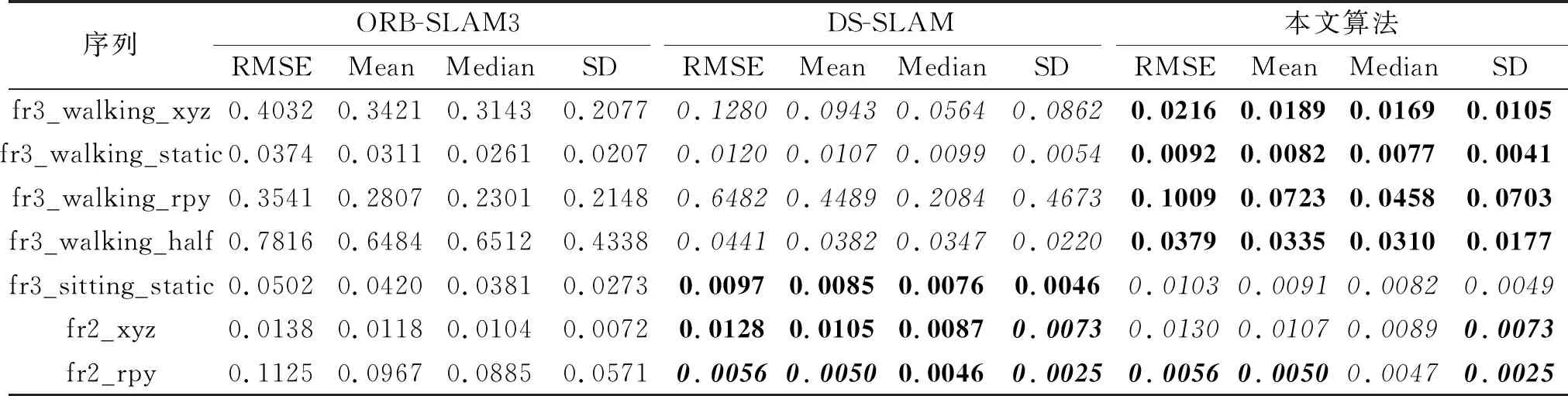
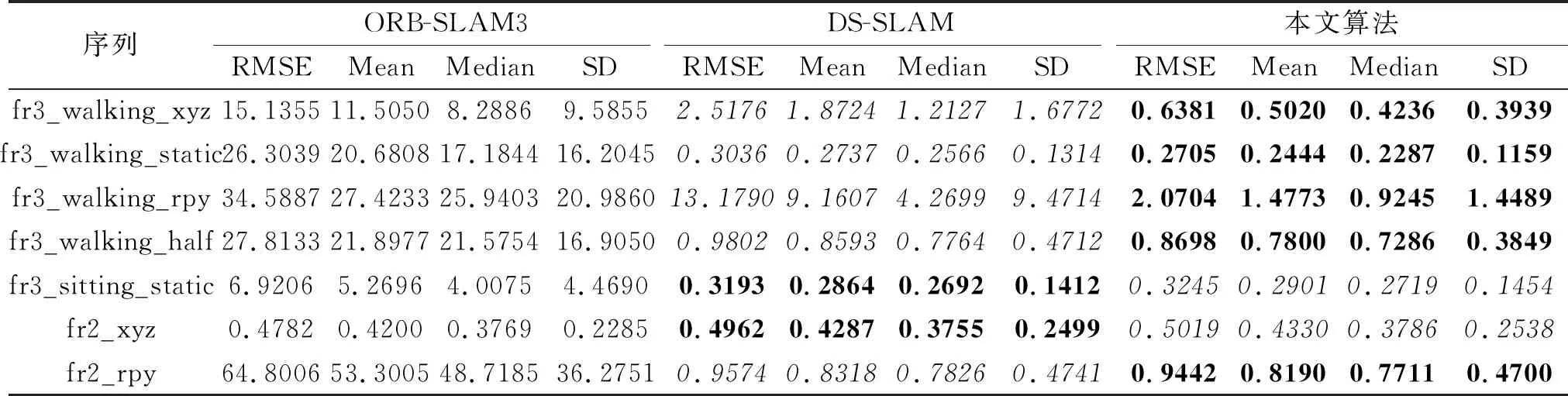
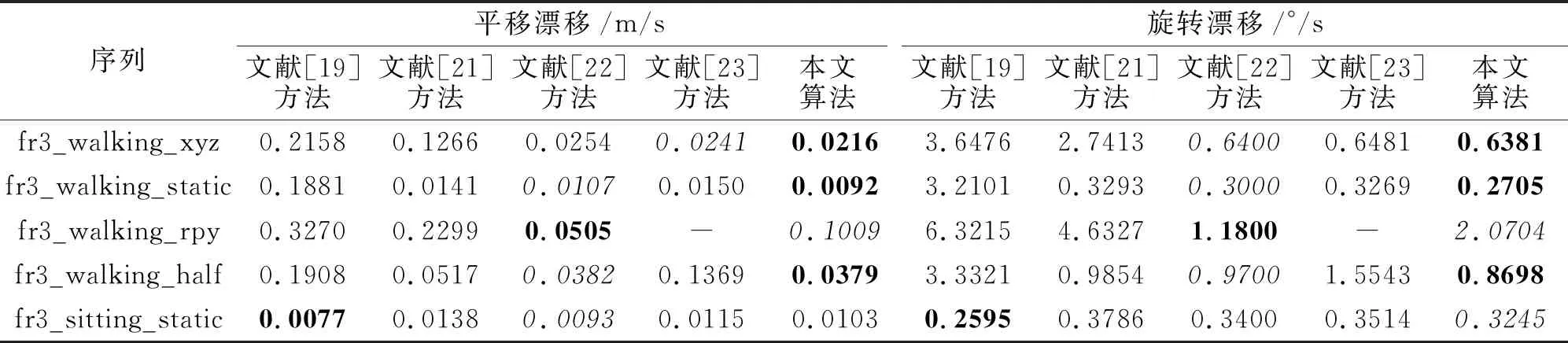
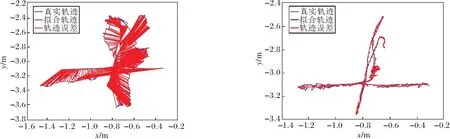
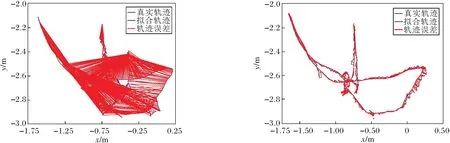
其中,(xi,yi)表示第i个物体目标边界框的中心坐标,widthi、heighti表示该目标边界框的宽度和高度.将B中所有边界框信息对应添加到深度图中,对于每个物体的深度信息,采用上述筛选策略进行处理.本文认为像素值不为0的点其信息是可信的,因此算法仅对无效黑洞点进行修复.对于第i个物体,从左上角点(xi-widthi/2,yi-heighti/2)开始,遍历目标边界框中每点Pij,0 遍历滑动窗口中的像素点:如果深度值为无效值或与要修复像素点之间的灰度值差别超过设置阈值,跳过;否则将其深度值累加,最终获得有效像素值总和depValSum及有效像素点个数count.如果count=0,认为该部分在真实环境下为无效点,不改变当前无效值;否则,将其值赋为depValSum/count,进行下一个像素点的处理,直至修复所有像素. 在TUM数据集上设备的限制会导致某些部分在相机测量范围之外的情况,这种情况在深度图中表现为四周的黑边,影响对动态点的剔除和静态物体的建图精度,因此本文对这部分无效值也进行修复.在物体的候选框超出检测范围的区域中,首先计算周围有效值点与无效点灰度值的差值,如果该差值小于设定的阈值,认为该有效值点与无效点属于同一物体,将其深度值累加,修复无效点,修复后的值可继续用于下一个点的修复结果.依据此步骤,对超出相机测量范围的物体部分进行修复,提升系统在建图方面的精度. 算法1深度图修复 输入深度图mImDepth,灰度图Gray, 边界框左上角坐标(xi,yi), 宽度widthi,高度heighti 输出修复图mImFixed ImFixed←mImdepth form←xitoxi+widthido forn←yitoyi+heightido 取当前像素深度值与对应灰度值 depth_val←mImDepth(m,n) g_val←Gray(m,n) ifdepth_val≠0 then 初始化滑动窗口内深度值总和与像素点个数 depValSum←0 无锡金利达生态科技有限公司是国内专业从事水生态修复工程技术研发及工程材料生产的高新技术企业,是水生态修复整体解决方案提供商。公司主营业务包括水生态修复、生态护岸工程的规划、设计、咨询;水生态修复工程技术及产品的研发、生产和销售;水生态修复工程施工技术的研究、推广和应用等。公司研发的“生态格网结构”系列产品销售额在国内市场遥遥领先,成为该行业领军企业。 count←0 自适应地设置滑动窗口宽高 wm,n←max(4,widthi/10) hm,n←max(4,heighti/10) forp←m-wm,n/2 tom+wm,n/2 do forq←n-hm,n/2 ton+hm,n/2 do 取当前像素深度值与对应灰度值 depth_tmp←mImDepth(p,q) ifdepth_tmp≠0 and abs(g-g_tmp)<5 then depValSum←depValSum+tmp count←count+1 end if ifcount≠0 then mImFixed(m,n)←depValSum/count end if end for end for end if end for end for returnmImFixed YOLO V3目标检测算法由于在检测准确度和实时性上的优越性,被广泛应用于各种对计算机视觉语义信息有需要的场景.但是,由于目标检测的局限性,算法仅能获得物体的边界框,其中不可避免地包含较多非目标区域信息,如果不做优化会影响视觉里程计和建图的精度.此外,当前大多数SLAM系统对深度图的利用率较低,仅在建图过程中离散地获取像素深度值,很少连续性地考虑其中蕴含的信息. 为了解决上述问题,基于每个物体其深度值应该连续、平稳且独立于其它物体的先验知识,本文提出联合深度图聚类及目标检测的像素级分割算法,结构如图2所示. 图2 本文算法框图 首先基于YOLO V3获取当前RGB图像帧中的语义信息,在对应的深度图中分割所有目标边界框.然后对每个边界框采用K-means进行聚类处理,得到多个聚类簇.根据目标检测算法的原理,在一个物体的边界框中,物体应该作为前景且与背景元素相比占据边界框大部分像素,因此取深度值较小、像素值较多的聚类簇作为物体的分割结果. 本文算法步骤如下. 1)通过YOLO V3获得目标的边界框,在深度图中取相应的边界框位置,进行聚类,获得k个聚类簇: C={cluster1,cluster2,…,clusterk}, (1) 每个clusteri∈C中存储这类中所有像素点的深度值和像素点个数, clusteri={d1,d2,…,dcounti,counti}, 1≤i≤k, (2) 其中,dj∈cluster,j=1,2,…,counti表示每个像素点的深度值,counti表示类中所有像素点的个数. 2)结合式(1)和式(2),计算每个cluster的平均深度值: (3) 3)为了同时考虑深度值与像素个数指标,将通过式(3)计算得到的所有聚类簇的平均深度值Di和式(2)中像素个数counti进行归一化处理: (4) 其中,1≤i≤k,Dmax表示所有cluster中最大平均深度值,Dmin表示所有cluster中最小平均深度值,countmax表示所有cluster中最大像素个数,countmin表示所有cluster中最少像素个数. 4)由式(4)中归一化的平均深度值和像素个数决定每个聚类簇的评分结果,设计函数使最终得到的结果满足深度值较小且像素个数较多,即 scorei=θ1count_normali+θ2D_normali. (5) 实验中分别取θ1=0.5,θ2=-0.5. 5)对比式(5)中得到的所有聚类簇分数,取分数最高的cluster作为物体的分割结果: clusterobject=max{score1,score2,…,scorek}. 由上述步骤获得物体的像素级分割结果后,针对室内场景,剔除位于语义信息为“人类”区域上面的特征点,同时结合运动一致性检测算法计算其它动态特征点,降低动态物体对视觉里程计的影响. 本文采用TUM数据集上5个动态序列进行深度图修复、像素级分割、SLAM系统性能对比及语义建图实验,在真实家居环境中进行动态点检测与剔除实验. 实验所用计算机的配置为Intel i7-10750 12核心2.60 GHz CPU,16 GB内存,NVIDIA GeForce RTX 2070独立显卡,ubuntu18.04操作系统,拍摄设备为Kinect V2 RGB-D相机. 本文在TUM数据集的fr3_walking_xyz序列上进行滤波算法时间性能分析,分别采用均值滤波算法、双边滤波算法及中值滤波算法对序列中的深度图进行修复.针对一帧图像修复所消耗的平均时间如下:均值滤波算法为2.35 ms,双边滤波算法为3.36 ms,中值滤波算法为4.15 ms.均值滤波算法在对深度图像的修复时间上低于另外两种算法,表明均值滤波算法在时间性能上的优越性.该算法能更好地满足SLAM系统对于实时性的要求. 在TUM数据集的fr3_walking_xyz、fr3_walking_static序列上进行深度图修复实验,场景中显示器的材质较光滑且呈现黑色,因此获取的深度图在显示器区域中存在较多无效值,同时在一些物体轮廓边缘也存在相应的黑边.本次实验采用均值滤波算法,对YOLO V3检测的物体区域进行无效值修复,效果如图3所示,图中使用红色椭圆框标注主要修复部分.由图3可看出,在左边第1列的2幅图中,本文算法修复图像中由于视差原因在人的轮廓边缘产生的轮廓黑边,在右侧的黑边中也修复本来未检测到的一部分显示器,而从第2列和第3列图像中可看出,本文算法在存在大量无效值的图像帧中也能获得较优效果.(b)中依然存在一些零散的黑洞区域,这是因为为了增加系统的实时性,在修复时仅考虑识别语义信息的物体.算法由于修复广泛存在的无效值,因此为SLAM系统在后续像素级分割的算法提供基础. (a)修复前 本节在TUM数据集的fr3_walking_xyz序列上进行实验,验证本文算法的有效性.以ORB-SLAM2系统为基础,加入本文算法,得到每帧的分割结果,用于SLAM系统的动态特征点剔除. 具体像素级分割结果如图4所示.(a)为数据集原图由FAST提取ORB特征点的结果,(b)为对应的图像经过本文算法处理后输出的分割结果.由于主要剔除人身上的特征点,因此在此实验中将序列中属于人这类的像素标为红色以区分其它部分.通过对比可看出,本文算法能精准根据物体的轮廓划分语义区域,获得像素级的分割结果,为动态特征点的剔除提供基础.(c)为经过本文算法和运动一致性检测对特征点进行剔除之后的结果,可看到已剔除位于动态物体(人)上面的特征点,对视觉里程计的性能起到提升作用. (a)剔除动态点前 本文在TUM数据集上选取5个高动态序列(fr3_walking_xyz、 fr3_walking_static、 fr3_walking_rpy、fr3_walking_half、 fr3_sitting_static), 验证系统剔除动态物体性能的鲁棒性. 同时选取2个静态手持序列(fr2_xyz、fr2_rpy)验证本文算法在一般场景下定位与建图的精确性. 以ORB-SLAM3和DS-SLAM作为基线方法进行对比,实验中采用均方根误差(Root Mean Square Error, RMSE)、平均值(Mean)、中值(Median)、标准差(Standard Deviation, SD)4种衡量标准,每种方法在每个序列上进行10次实验,取10次实验的各项指标的平均值进行对比分析. 绝对轨迹误差(Absolute Trajectory Error, ATE)指算法估计的相机位姿和真实位姿之间的差值,直观反映算法对全局相机轨迹的计算效果. 相对位姿误差(Relative Pose Error, RPE)指相邻两帧之间估计值与真实值之间差异的差值,衡量SLAM系统的漂移误差,包括平移漂移误差和旋转漂移误差. 本文方法、ORB-SLAM3、DS-SLAM的实验结果对比如表1~表3所示,表中黑体数字表示最优结果,斜体数字表示次优结果,黑斜体数字表示存在2种最佳方法. 由表1~表3可看出:在高动态序列上,本文算法能有效减少动态物体对视觉里程计的影响;针对静态手持序列,本文算法在更一般的场景下也能得到精确的定位结果. 表1 各算法在7个序列上的绝对轨迹误差对比 表2 各算法在7个序列上的平移漂移误差对比 表3 各算法在7个序列上的旋转漂移误差对比 在fr3_walking_xyz、fr3_walking_static、fr3_wal-king_rpy、fr3_walking_half序列上,相比ORB-SLAM3和DS-SLAM,本文算法能取得最优性能.在fr3_sitting_static、fr2_xyz、fr2_rpy序列上,由于人的动态性较低或场景中不含动态物体,本文算法性能优于ORB-SLAM3,与DS-SLAM在结果上相差不大,可认为性能相当. 另外,本文算法还与文献[19]方法~文献[23]方法进行对比,具体RMSE结果如表4和表5所示.在上述表中,黑体数字表示最优结果,斜体数字表示次优结果. 表4 各算法在5个序列上的绝对轨迹误差的RMSE对比 表5 各算法在5个序列上的相对位姿误差的RMSE对比 由表4和表5可看出,本文算法在与众多前沿的语义SLAM系统的对比中:ATE指标在5个序列中的2个序列上取得最优效果,在1个序列上取得次优效果;平移漂移指标在3个序列上取得最优效果,在1个序列上取得次优效果;旋转漂移指标在3个序列上取得最优效果,在剩余序列上取得次优效果.综合上述数据发现,本文算法在高动态环境中效果优于众多语义SLAM. 本文还根据TUM官方给出的评估工具绘制SLAM估计的相机轨迹图,并与真实轨迹进行对比.ORB-SLAM3与本文算法在fr3_walking_xyz、fr3_walking_static序列上的轨迹对比如图5和图6所示.图中黑线表示数据集上由运动捕捉设备获得的真实相机轨迹,蓝线表示估计相机轨迹,红线表示两者之间的差别. 由图5和图6可看到,本文算法所得在很大程度上降低动态物体对算法性能的影响,能更好地拟合真实轨迹. (a)ORB-SLAM3 (b)本文算法 (b)The proposed algorithm (a)ORB-SLAM3 (b)本文算法 (b)The proposed algorithm 实验中使用手持Kinect V2相机采集真实家居环境下的图像序列,输出大小为480×640,共计848帧图像.下面在此序列上验证本文算法. 本文算法在真实场景中对动态点的剔除效果如图7所示.由图可看出,本文算法在实际场景中也能剔除位于动态物体上的特征点,并保留位于静态物体上的特征点以用于位姿估计,并获得精准的目标语义分割结果. 在真实场景中,本文算法各模块的平均运行时间如下:ORB特征提取为10.22 ms,深度图像修复为2.35 ms,目标检测为24.91 ms,深度图像聚类为10.73 ms.同时选取DS-SLAM与DynaSLAM进行系统整体运行帧率的对比,对比结果如下:DS-SLAM为49.81 ms,DynaSLAM为1 167.33 ms,本文算法为32.85 ms.由此可看出,得益于分割线程与跟踪主线程的高度并行设计,本文算法能满足SLAM对于实时性的要求,耗时最短,由此验证本文算法在实时性方面的可靠性. 结合图7中的分割结果发现,本文算法在真实场景中能在保证实时性的同时,获得RGB图像的像素级分割结果,提升SLAM系统在高动态环境下的定位精度,因此在真实场景中具有普适性与鲁棒性. (a)剔除动态点前 (b)像素级分割结果 (c)剔除动态点后 本节对比本文算法与ORB-SLAM3在TUM公开数据集fr3_walking_xyz、fr3_walking_half序列上的轨迹拟合效果.由图可看出,2个序列在真实轨迹中都存在位置上的回环,同时结合表1~表3中的定量分析数据可看出,本文算法在存在回环时有更好的表现,由此验证本文算法在回环检测中的优异性能. 在建图实验中对TUM公开数据集fr2_xyz、fr3_long_office_household静态序列及fr3_walking_xyz动态序列,共3组图像序列,进行处理并建立稠密语义点云地图,在此序列上验证本文算法在语义建图方面的有效性. 对3个不同的图像序列建立稠密语义点云地图,如图8所示.为了更直观地展示建图效果,在每个序列中挑选具有代表性的图像帧作为对比.在地图中使用不同颜色标注,区分不同物体的语义信息,而其它没有语义信息的部分采用现实世界中的颜色.由图可看出,本文算法能还原真实环境中的地图结构,可精准标注物体的语义信息,在fr3_walking_xyz动态序列上的实验结果中也能较好地剔除位于人身上的点,为更复杂的机器人导航、识别及抓取等任务提供保障. (a)原始图像 本文提出联合深度图聚类与目标检测的像素级分割算法.分割线程中首先基于均值滤波算法修复存在无效值的深度图,同时采用YOLO V3对每帧进行目标检测,获取图中的语义信息.然后基于已修复的深度图,对每个物体进行K-means聚类处理,得到像素级的语义分割结果,精确剔除位于动态物体上的特征点,减少动态环境下SLAM系统产生的误差.实验表明,本文算法在保证实时性的同时,提升分割精度. 本文对于动态物体的处理在于剔除人类身上的特征点及动态一致性检测,减少高动态物体对SLAM系统的影响,在室内场景中取得不错效果.就当前的语义SLAM研究领域而言,如果动态物体在一帧图像帧中面积占比过大,可能会干扰系统对一般物体的检测,影响回环检测的精度.今后考虑把抗动态物体的回环检测作为下一步的研究方向,综合对比不同的思路可行性,寻找这一问题的解决方案.1.2 算法步骤
2 实验及结果分析
2.1 深度图修复实验

2.2 语义分割实验

2.3 在TUM数据集上的对比实验

2.4 在真实场景中的实验

2.5 回环检测与语义建图实验

3 结 束 语
