基于投票人影响因子的投票预测模型
2022-03-11张新昀张绍武张益嘉林鸿飞
张新昀 张绍武 任 璐 杨 亮 徐 博 张益嘉 林鸿飞
计算政治学[1]又称计量政治学,是分析相关数据描述和研究政治现象的学科.议会作为某些国家的政治关键组成部分和立法机构,是计算政治学研究人员密切关注的对象,而在议会中作为投票人的议员,更是计算政治学中投票预测的研究重点.本文以人工智能相关理论方法为基础进行投票预测研究.
根据相关国家议会议事规则,议案分为4类:决议案(Simple Resolution)、共同决议案(Concurrent Resolution)、联合决议案(Joint Resolution)和法案(Bill).法案是最常见、使用最多的立法形式,占议案总数的85.2%以上.法案由一个或多个立法者提出,法案想法可以是原创的,也可来自选民、公职人员或利益集团.为了成为法律,该法案需要在被提出的议院经过一个审查程序,其中最关键的环节就是由全体议员投票表决.如果法案获得通过,会被送到另一个议院完成一个同样的程序.经两院通过并统一文本后提交总统签署成为国家法律,这样的过程也被称为立法过程.
每个法案对应一个或多个主题,拥有一份官方的标题和描述.在提出法案的议员当中,排名第一的议员称为发起者(Sponsor),其余议员称为共同发起者(Cosponsor).议员对于一个法案有三种投票选择:赞成、弃权、反对.对于三种投票选择的百分比在本文中称为法案的投票比率.对于每位议员,相应的信息主要包含姓名、国会唯一编号、地区、党派等.后文中,议员被称为投票人.
投票预测中最受欢迎的技术之一是Poole等[2]提出的理想点模型(Ideal Point Model),这是一种基于统计学的投票预测模型,假设投票人的意识形态和法案反映的意识形态都是单一维度,计算空间距离,得到投票人对于法案的倾向性.Simon[3]使用贝叶斯统计方法实现对理想点模型的模拟和简化.Clinton等[4]将理想点模型发展为投票人的多维意识形态立场估计.Gerrish等[5]在理想点模型中引入国会法案相关的文本信息,利用法案相关文本的主题推断法案在意识形态空间中的位置,根据历史投票记录得到投票人在意识形态空间中的位置,并依照立法主题进行调整,然后对比投票人与法案的空间距离,预测投票人支持法案的可能性,预测准确率得到一定提升.Yano等[6]研究从第103届到第111届国会的法案,发现利用法案处理问题的紧迫性和重要性的特征,以及从共同发起人中提取的一组特征,有助于模型预测.Nay[7]研究大量国会法案文本,确定最适合投票预测的文本结构,最终发现,模型中使用法案的全文可提高预测精度.Yang等[8]提出基于图卷积网络(Graph Convolutional Network, GCN)[9]的对投票人和法案联合表征学习的方法,利用GCN学习共同发起者之间的联系,能得到更好的法案和投票人的特征表示,再通过对比投票人和法案的空间距离,确定投票人对法案的偏好,提高预测精度.
尽管上述工作提升投票预测的精度,但都未考虑投票过程中投票人的相互影响,因此存在改进的可能性.在现实的投票过程中,不仅少数的共同发起者之间有联系,每位投票人之间都会因为党派不一、理念异同、关系远近、地位高低而产生或强或弱的投票选择的影响.也就是说确定其中一位投票人的投票选择,就可以高置信度地认定另一位投票人的投票选择.但是以往的模型都单方面注重投票人对于法案的倾向性,忽视投票过程中投票人之间的相互影响.
GCN是一种直接运行在图数据结构上的神经网络,能从图数据结构中抽取局部特征或全局特征.近年来,学者们尝试将GCN应用在不同的自然语言任务当中,并证实有效性.Bastings等[10]把GCN融入机器翻译模型之中.Nguyen等[11]使用GCN完成事件检测.Yao等[12]应用GCN到文本分类.Zhang等[13]在事件抽取任务中使用GCN.在自然语言处理(Natural Language Processing, NLP)任务当中,上述方法都恰当地应用GCN,取得当时最佳的表现.
通过投票人影响因子,可得到近似真实博弈结果.为了模拟现实中投票人之间的联系,本文提出基于投票人影响因子的投票预测模型.结合投票人影响因子图与投票人的特征信息,输入GCN,学习投票过程中投票人的相互影响及投票人的影响范围和影响特征.此外,考虑到法案文本中上下文信息的关联性,利用双层长短期记忆网络(Bi-directional Long Short-Term Memory, BiLSTM)替代单层长短期记忆网络(Long Short-Term Memory, LSTM)理解法案文本描述的语义信息,获得法案特征向量.鉴于法案文本的规范性导致的术语频繁、用词重复,使用引入TF-IDF(Term-Frequency-Inverse Document Frequency)因子的TextRank替代朴素TextRank,得到法案的关键词.实验表明,本文模型的精确度和F1值都有所提升.
1 基于投票人影响因子的投票预测模型
1.1 模型基本结构
基于投票人影响因子的投票预测模型的基本结构如图1所示.将投票人的唯一编号、地区、党派等基本信息作为输入,得到投票人初始特征向量.使用历史法案投票结果计算投票人之间的影响因子,并利用优化器优化影响因子,得到投票人影响因子图.把投票人的特征向量和投票人影响因子图共同输入GCN中,获得投票人的最终特征向量.利用BiLSTM得到法案的特征向量,计算各位投票人对法案的投票偏好并排序,得到投票人序列.

图1 本文模型基本结构
投票偏好是以投票人最终特征向量和法案特征向量之间的相似度衡量的.再利用投票比率的感知模型得到投票比率,综合投票人序列和投票比率可得到最终投票结果.本文模型的基本结构优点在于能学到投票人之间的相互影响,较好地在向量空间中映射每位投票人的位置.投票比率感知模型的优点在于能充分学到投票过程中的背景信息,得到投票比率.相比直接得到投票人投票选择的模型结构,投票人序列和投票比率分别学习后再结合的模型结构预测精度更高.
1.2 投票人序列
1.2.1 投票人初始特征向量矩阵
本文每位投票人的信息由唯一编号、出身州和党派类别组成.唯一编号由国会制定.
将投票人i对应的唯一编号、出身州和党派类别分别输入预训练模型msmarco-MiniLM-L-6-v3,嵌入得到特征向量VID(i)、VState(i)、VParty(i),依次拼接,得到投票人i的初始特征向量:
Vlgt(i)=VID(i)+VState(i)+VParty(i).
组合所有投票人的初始特征向量,得到投票人初始特征向量矩阵Vlgt.
1.2.2投票人影响因子图
如果完全模拟投票过程中的真实博弈过程,除了需要考虑投票人的党派、出身、经历、理念、地位等因素,还需要考虑该投票人与其他投票人的关系,该投票人与各个利益集团之间的来往及该投票人对自身信念的坚定程度等因素.所以真实博弈过程的模型构建过于困难,权重关系复杂,同时涉及许多难以获得的非公开信息.上述分析说明在客观上难以完全模拟投票过程中的真实博弈过程.
针对上述问题,本文采用“唯结果论”的“逆推”方法,计算两两投票人的历史投票行为的拟合程度,即投票人影响因子,模拟近期未来两两投票人之间的真实博弈过程的结果.
本文具体统计分析2014~2018年度投票人投票选择相似度分布,具体如表1所示.

表1 2014~2018年投票人投票选择相似度分布
由表1可发现,有40.37%的两两投票人的投票选择相似度在80%以上,而仅有6.08%的两两投票人的投票相似度在40%以下.这是因为议会中有大量符合社会共识的法案,如教育、民生等领域的法案.对于这些法案,投票人会舍弃派别等方面的对立而共同致力于法案的通过,导致投票人之间的对立分歧不是非常明显.此外通过实验发现,因为数量过少,加入负影响的投票人影响因子对本文实验结果几乎无影响.所以本文仅考虑在模型中加入正影响的投票人影响因子.
投票人影响因子矩阵S中的元素si,j表示投票人i与投票人j之间的影响因子:

历史投票选择存在高拟合度的投票人在未来的投票中也会大概率拥有同样的投票选择,所以模型在预测投票结果时要充分注意到高拟合度投票人之间的联系,忽视弱拟合度投票人生成的噪音信息.本文使用优化器优化投票人影响因子矩阵S,增强高拟合度投票人之间的联系,削弱拟合度投票人之间的相互联系,得到新的投票人影响因子矩阵S′.优化器函数
(1)
通过此优化器优化后,投票人之间的联系被赋予马太效应,高相似度投票人之间的联系变得更强,低相似度投票人之间的联系变得更弱.忽视历史投票选择拟合度小于等于60%的投票人之间的联系,这些投票人的历史行为不会对彼此的投票预测结果产生影响.
投票人影响因子图由构建好的投票人影响因子邻接矩阵S′表示.在投票人影响因子图中,把代表某投票人的节点作为中心节点,而该中心节点的一阶邻域的节点集合叫作某投票人在投票人影响因子图中的周边空间分布.在投票人影响因子图中,除了最直接的投票人影响因子,投票人在投票人影响因子图中的周边空间分布也值得注意.原因是不同投票人的周边空间分布表示不同投票人各自的影响范围和影响特征,这也是模拟真实博弈过程的重要信息.所以如何让模型精确学习到每位投票人的周边空间分布状态也是提升模型性能的关键.
1.2.3法案特征向量
法案的文本冗长,上下文联系密切.普通循环神经网络(Recurrent Neural Network, RNN)能容纳的上下文信息有限,在处理较长序列时,容易出现梯度消失现象.所以本文引入BiLSTM,由两层的前向LSTM和后向LSTM组合拼接而成,能更好地学习文本上下文语义信息,抽取文本的语义特征.
使用BiLSTM获得法案k的信息特征向量:
Vlgn(k)=BiLSTM(lk(t)),
其中,
lk(t)=lk(title)+lk(des)
表示法案k的文本信息,lk(title)表示法案k的标题,lk(des)表示法案k的描述.
1.2.4投票人最终特征向量矩阵
基于谱域卷积实现GCN,由输入信号x∈RN和过滤器gθ=diag(θ)共同定义如下:
gθ*x=UgθUTx.
其中:*为卷积运算,U为标准化图拉普拉斯矩阵L的特征矩阵,
Λ为L的特征值对角矩阵,UTx为输入x的图傅里叶变换;gθ可理解为L的特征值函数,即gθ(Λ).为了减小计算开销,Hammond等[14]提出gθ(Λ)可通过切比雪夫多项式近似为Tk(x),得
(2)
其中,
为拉普拉斯算子的一个K阶多项式.本文将分层卷积限制为K=1,即关于L是线性的,因此在拉普拉斯谱上有线性函数.进一步近似λmax≈2,可将式(2)简化为
其中,θ′0、θ′1为自定义系数,过滤器参数被整个图共享.通过连续堆叠这种形式的过滤器,可有效卷积节点的K阶邻域,进一步简化为
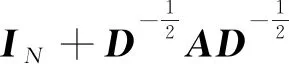
其中,
W为可学习的参数矩阵.
通过上述分析可发现,GCN的实现是基于邻域聚合.首先聚合某节点的一阶邻域特征,再合并邻域聚合的特征与当前节点特征,以更新当前节点特征.所以结合投票人影响因子图,GCN不仅可直接学习投票人对其他投票人的影响力大小,还能学到投票人周边空间分布,即产生相互影响的投票人的数量.
在本文模型中,使用双层GCN结构,双层GCN结构之间使用SeLU激活函数连接.相比ReLU等激活函数,SeLU激活函数的自归一化能力在解决梯度消失和梯度爆炸问题的同时,可使网络更快地收敛.
把投票人的初始向量矩阵Vlgt和投票人影响因子图S′作为输入,得到投票人的最终特征向量矩阵:
Zlgt=F(SeLU(F(Vlgt,S′)),S),
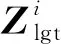
1.2.5投票人排序
投票人序列依照各位投票人对被预测法案的偏好程度的高低进行排序.各位投票人对被预测法案的偏好程度由投票人的最终特征向量与法案特征向量的相似度决定,即
根据数值大小从高到低排序的相似度序列为:
list=sort(sim1,sim2,…,simn),
simi的排名就是对应投票人对法案偏好的排名,即投票人序列.
1.3 投票结果的预测
根据图1可知,投票人序列和投票比率对于投票结果预测缺一不可.为了得到投票比率,本文应用投票比率的感知模型,如图2所示.

图2 投票比率的感知模型结构框图
为了得到法案的相似度矩阵,需要得到每个法案文本的嵌入表示:
其中:kw表示使用TextRank得到法案文本中的关键词,每篇法律文本选择前n个关键字;kwglove表示关键词kw在预训练词向量GloVe-6B-100d中的嵌入表示.考虑到法案文本中有很多专业辞令,虽然出现频率较高,但不能较好地作为关键字使用,所以本文模型引入TF-IDF因子,kwTF-IDF表示关键词的TF-IDF值.
法案相似度图M中的结点mk,j表示法案k与法案j的相似度值:
mk,j=cos(ed(k),ed(j)).
使用BiLSTM获得所有法案的信息特征向量,组成法案特征向量矩阵Vlgn.将法案相似度图M与法案特征向量矩阵Vlgn一起输入GCN中,法案的最终特征向量矩阵为:
Zlgn=F(SeLU(F(Vlgn,M)),M),
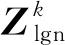
R=MLP(Zlgn+Vlgn),
其中,Rk为投票比率矩阵R中的第k行,表示第k个法案的投票比率,即该法案中赞成、弃权及反对这三种投票选择的比例.结合投票比率和投票人序列,得到最终的投票结果.
2 实验及结果分析
2.1 实验环境
实验数据来自于Yang等[8]在2020年公开的国外议会网站数据集,包含1993年至2018年的立法信息和投票结果,共有215 857项立法,2 234 082项投票记录,2 347位投票人.
考虑到实验数据的时间跨度较大,本文依次抽取1993年至2018年内连续五年的数据,构建22个单独的数据块.第1个数据块包含1993年至1997年的数据,第2个数据块包含1994年至1998年的数据.依此类推,一共有22个数据块.在每个数据块中,随机抽取前四年的数据作为训练集和验证集,比例为4∶1,使用最后一年的数据作为测试集.
本文选择准确率(Accuracy)和F1值作为主要评价指标,具体公式如下:
其中:TP表示实际为正样本且被判定为正样本的数量;TN表示实际为负样本且被判定为负样本的数量;FP表示实际为负样本但被判定为正样本的数量;FN表示实际为正样本但被判定为负样本的数量.文中准确率取在22个数据块上的平均结果.
本文模型中GCN深度为两层,隐藏层维度为32.BiLSTM深度为双层,输出维度为32.投票人特征向量的维度是32(ID维度16,党派维度8,地区维度8).模型的学习率设置为0.000 1,采用自适应矩估计(Adaptive Moment Estimation, Adam)优化器.为了防止过拟合,采用提前终止策略.损失函数为三元组损失函数(Triplet Loss).
2.2 实验结果对比
本文选择如下基准模型进行对比实验.
1)文献[4]模型(A Statistical Model for Roll Call Analysis).利用理想点模型计算投票人和法案的空间位置,投票人和法案的空间距离用于表征投票行为.
2)文献[5]模型(Text and Ideal Point Models).利用立法文本信息扩展理想点模型,使用文本回归嵌入立法立场.
3)Bert.使用Bert[15]的CLS位作为法案的特征向量,对比法案之间的相似度,进行迁移学习.
4)LSTM+MLP(Multi-layer Perception).使用LSTM获得投票人和法案的特征向量.结合两种特征向量,使用双层感知机模型预测投票结果.
5)LSTM+DeepWalk[8].使用DeepWalk[16],基于共同发起者之间的关系建模,获得投票人的特征向量,LSTM获得法案的特征向量.结合两种特征向量,使用双层感知机模型预测投票结果.
6)LSTM+GCN[8].使用GCN,基于共同发起者之间的关系建模,获得投票人的特征向量,LSTM获得法案的特征向量.结合两种特征向量,使用双层感知机模型,预测投票结果.
7)文献[8]模型(Joint Representation Learning of Legislation and Legislators).基于GCN,对共同发起者之间的关系建模,获得投票人的特征向量.利用LSTM获得法案的特征向量.结合两种特征向量,获得投票人序列.使用基于TextRank的投票比率感知模型获得投票比率,结合投票人序列和投票比率,预测投票结果.
各模型的指标值结果如表2所示.由表可发现,文献[4]模型表现最差,表明忽略法案文本信息的理想点模型的预测能力有限.加入文本信息后,相比文献[4]模型,文献[5]模型可大幅提高预测能力.
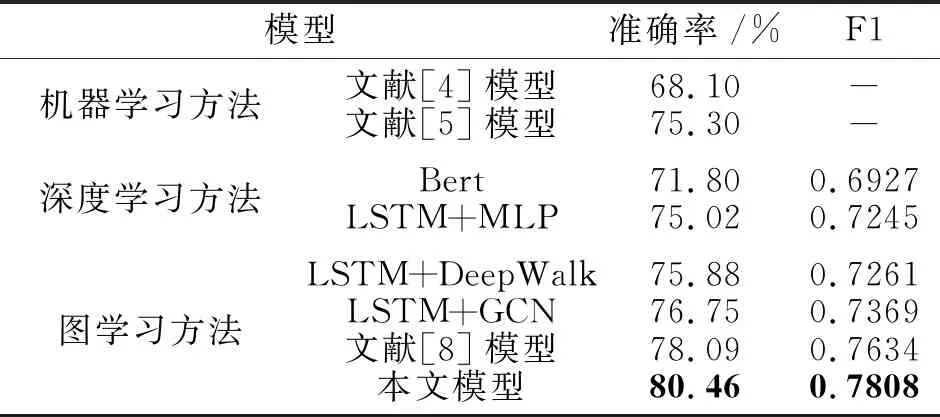
表2 各模型的指标值对比
Bert的表现只强于文献[4]模型,这可能是Bert在预训练时未学习到足够的法案相关的语料,注意力机制缺乏对法案关键信息的敏感性,不能较好地捕捉立法过程中的特征.
对比LSTM+MLP、LSTM+DeepWalk、LSTM+GCN和文献[8]模型可发现,基于共同发起者之间的关系使用GCN建模是有效的.虽然DeepWalk和GCN都把共同发起者视为节点,但是相比Deep-Walk,GCN表现更优,这是因为GCN不仅学习每个节点及其邻域的结构关系,同时可将每个节点自身的特征融入其中进行更全面的学习.
相比LSTM+GCN,文献[8]模型加入投票比率感知模型,由于能更准确地划分不同的投票群体及比例,进一步提高模型准确率.
相比文献[8]模型,本文模型引入投票人影响因子,通过GCN学习投票人之间的相互影响及投票人影响范围和影响特征,在某种程度上实现投票的动态过程.同时由于改进为BiLSTM和融入TF-IDF因子的TextRank,本文模型能容纳立法过程中更多的背景信息,更好地捕捉投票人和法案的特征,取得更佳结果.
2.3 改进验证实验
为了验证本文模型中多项改进的有效性,进行验证实验,选用如下模型.
1)文献[8]模型-BiLSTM.使用双层BiLSTM替代文献[8]模型中单层LSTM.
2)文献[8]模型-factor.在文献[8]模型中引入投票人之间的影响因子.
3)文献[8]模型-TR-with-TI.在文献[8]模型中使用融入TF-IDF因子的TextRank.
各模型的验证结果如表3所示.由表可发现,相比文献[8]模型,文献[8]模型-BiLSTM提升0.32%的准确率,0.006 8的F1值,这是由于BiLSTM能学习更多的立法文本上下文关联的语义信息,更好地抽取立法文本的语义特征.在基准模型中融入投票人之间的影响因子之后,文献[8]模型-factor在预测过程中开始捕捉投票人之间的相互影响及投票人影响范围和影响特征,注意到某些投票人大概率具有相似的投票选择,因此准确率提升1.94%,F1值提升0.011 3,是提升最大的一项改进.将基准模型使用的TextRank改为融入TF-IDF因子的TextRank之后,文献[8]模型-TR-with-TI的准确率提升0.40%,F1值提升0.007 2,效果的提升是因为投票比率感知模型更好地对比法案之间的相似度,使下游的GCN和MLP得到高质量的输入,输出更准确的投票比率.

表3 各模型的验证实验结果
2.4 超参数和预训练词向量验证实验
优化器函数(式(1))中的n,k为超参数,对预测准确度的影响如表4所示.
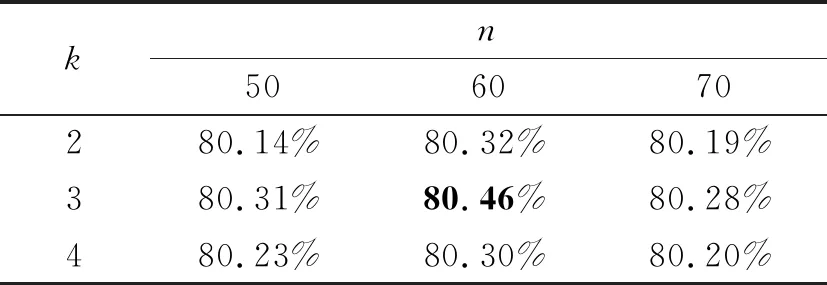
表4 超参数n,k对预测准确度的影响
由表4可知,n=60,k=3时效果较优,这也符合表1中投票人投票选择相似度分布.
在近期的应用中,预训练词向量表现出良好的通用性,在很多任务中取得较好效果.常见的预训练词向量有GloVe(GlobalVectorsforWordRepresen-tation)[17]和FastText[18].进行英文词向量预训练的语料库一般采用CommonCrawl、Twitter、Wikipedia.预训练词向量的维度分为50维、100维、300维等.不同类型的预训练词向量和维度可根据任务特点进行灵活选择.
在本文模型中,投票比率感知模型使用基于Wikipedia语料库的GloVe预训练词向量.相比CommonCrawl和Twitter语料库,Wikipedia语料库的行文更正式,内容更专业,与法案文本内容较契合.为了确定GloVe预训练词向量维度对预测准确率的影响,选择3种GloVe预训练词向量:GloVe-6B-50d、GloVe-6B-100d、GloVe-6B-300d.它们都是在60亿词元上训练的,维度分别为50维、100维和300维.在本文模型上进行对比实验,结果如表5所示.
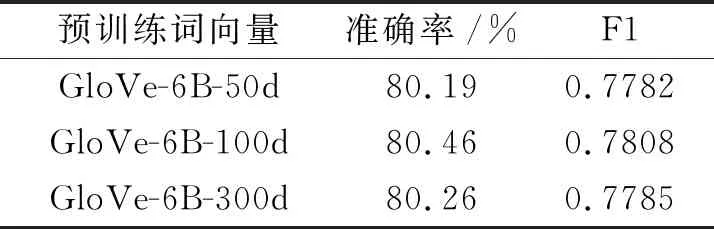
表5 预训练词向量维度对指标值的影响
由表5可看出,GloVe预训练词向量维度对预测准确率有一定的影响.从50维增加到100维时,模型准确率提升0.27%,F1值提升0.002 6.从100维增加到300维时,模型的准确率下降0.20%,F1值下降0.002 3.预训练词向量维度在100维时取得最高准确率.因此本文模型最终应用基于Wikipedia语料库的GloVe-6B-100d预训练词向量.
2.5 正确案例与错误案例分析
为了更好地理解本文模型的工作方式,进行正确案例与错误案例分析.以2018年的数据为例,深入探究后发现意识形态排名、党内偏离度排名和相互影响投票人数对投票人投票预测的准确率产生明显影响,具体结果如表6所示.
表6中一共列举10位投票人,前5位投票人是投票预测准确率最高的5位投票人,后5位投票人是投票预测准确率最低的5位投票人.意识形态排名数据来自于GovTrack,一共435位投票人,排名越高意识形态越保守,排名越低意识形态越自由.将投票人在投票中没有跟随党内多数人投票的行为称作偏离行为,党内偏离度排名越高,偏离行为越严重.相互影响投票人数是指与该投票人产生相互影响的投票人数量.

表6 正确案例与错误案例分析结果
通过观察发现,在意识形态方面,前5位投票人的意识形态都较保守,相比之下,后5位投票人的意识形态较中立.在党内偏离度方面,前5位投票人的党内偏离程度较低,而后5位投票人的偏离程度较高.在相互影响投票人数方面,前5位投票人与大量的投票人产生相互影响,相比之下,后5位投票人几乎不与其他投票人产生相互影响.
据此可得到结论:投票人的意识形态越鲜明,党内偏离程度越低,相互影响投票人数越高,模型的投票预测准确率越高;否则越低.而且相互影响投票人数因素的作用最清晰.
3 结 束 语
投票预测就是尽可能地模拟真实的投票过程,而投票人之间的相互影响不可或缺.因此本文提出投票人影响因子,并在相应数据集上进行研究.加入投票人影响因子图到GCN中,使本文模型模拟真实投票过程中投票人之间相互影响的博弈过程.同时,考虑到法案文本语义的严谨性和用词的规范性,使用BiLSTM和引入TF-IDF因子的TextRank,得以充分理解法案文本语义信息,并挖掘法案的细粒度文本特征,使投票过程的模拟更贴近现实.实验表明,本文模型能取得较好结果.今后将考虑建立并引入投票人辩论文本集或外部知识库等,进一步提升模型性能.
