Android恶意软件检测低冗余特征选择方法
2022-03-08郝靖伟潘丽敏李蕊杨鹏罗森林
郝靖伟,潘丽敏,李蕊,杨鹏,罗森林
(1.北京理工大学 信息与电子学院,北京 100081; 2.国家计算机网络应急技术处理协调中心,北京 100029)
中国互联网络信息中心在2019年发布的《第44次中国互联网络发展现状统计报告》[1]显示,中国移动互联网用户数已达7.88亿,手机互联网用户比例高达98.3%。国际数据中心发布的报告[2]显示,2019年Android系统的市场份额为87%,占据了智能手机操作系统市场的主导地位。该系统具备的灵活性和开放性给开发者和用户带来了极大的便利,如开发者能够自由开发并上传应用程序到应用市场,用户可以从应用市场中随意下载应用程序,但同时也使Android系统和用户容易遭受恶意软件的攻击,因此,研究Android恶意软件检测方法是移动端操作系统安全防护领域的重要内容之一。
机器学习涉及概率论、统计学等多门学科,是近年来兴起的最热门的多领域交叉学科之一,现已被广泛应用到Android恶意软件检测领域。基于机器学习的Android恶意软件检测方法不需要过多人工干预,并且可随着恶意软件数据量的增加实现方法的自我改进,具有自动化和高精度的特点。特征选择是基于机器学习的Android恶意软件检测方法的重要组成部分。通过特征选择能够从高维特征空间中挖掘出用于检测恶意软件的关键特征。
针对Android恶意软件检测的特征选择方法,主要分为基于过滤评价策略的特征选择方法和基于包装评价策略的特征选择方法。
1)基于过滤评价策略的恶意软件检测特征选择方法。主要包含信息增益、卡方检验、频率统计等方法。其中,卡方检验、信息增益等方法计算特征与检测结果的相关度,再对特征进行排序,选择相关度高的特征。例如,Yerima等[3]提出利用信息增益对恶意软件原始权限特征集进行特征选择,选择出信息增益最大的20个特征作为特征集训练朴素贝叶斯恶意软件检测器,检测准确率达92%。Pehlivan等[4]提出通过卡方检验算法从97个权限特征中选择出25个特征,利用该特征集训练随机森林(RF)模型,检测准确率达到94.9%。Wang等[5]先通过互信息、相关系数和T-test检验方法分别对权限特征进行排序,再使用顺序正向选择算法和主成分分析(PCA)算法识别有风险的权限子集,使用支持向量机(SVM)和随机森林等评估选择出的权限特征的检测效果,实验结果显示,该方法能够达到94.62%的检测率及0.6%的误报率。频率统计的方法通过计算特征在软件中出现的频率,选择频率高的特征。但是,Cen等[6]在利用该方法进行Android软件特征选择时研究发现,有些低频率出现的特征(如SMS相关的权限)对检测效果贡献较高不被选择,有些高频率出现的特征(如toString()在恶意软件和良性软件中同时出现)对检测效果贡献度较低被选择,即该特征选择方法忽略了特征在类间的频率分布,容易选择出冗余特征。
2)基于包装评价策略的恶意软件检测特征选择方法。Pehlivan等[4]提出一种基于权限特征的恶意软件检测方法,利用随机森林进行特征选择,选择出25维特征,达到了89.32%的准确率。Fest[7]利用Freqensel算法对权限、API等特征进行特征选择,得到92%的准确率和召回率。2018年,Tao等[8]提出一种基于与权限相关的API特征的恶意软件检测方法,使用随机森林进行特征选择,选择出50个高度敏感的API,得到了98.24%的F1值。Li等[9]经过多层特征选择,从135维权限特征中选择出22维特征,利用该特征集构建基于支持向量机的检测模型,实现对Android恶意软件的检测。特征选择能够从高维特征空间中挖掘出Android恶意软件检测的关键特征,提高检测准确率。现有的Android恶意软件特征选择方法忽略特征在类间的频率分布,有些高频率出现的特征(如用户界面设计“android.view.ViewGroup.addView”在恶意软件和良性软件中同时出现)对检测效果贡献度较低,却被过度估计重要性,成为检测Android恶意软件的特征,导致特征子集冗余性较高,影响检测效果。
针对现有特征选择方法中对类间相同频率分布的特征过度关注导致特征冗余性较强的问题,本文提出一种Android恶意软件检测低冗余特征选择方法。首先,分离类间存在频率分布偏差的特征,然后,量化偏差程度和频率以剔除低偏差和低频特征,并结合分类器实际分类效果选择出特征子集,降低恶意软件检测特征集的冗余性。
1 算法原理
1.1 原理框架
Android恶意软件检测低冗余特征选择方法的核心思想是:通过分离类间存在频率分布偏差的特征,量化偏差程度和特征出现频率以剔除低偏差和低频特征,并结合分类器实际分类效果选择出特征子集。其基本原理框架如图1所示。

图1 Android恶意软件检测低冗余特征选择方法原理框架Fig.1 Framework of low redundancy feature selection method for Android malware detection
该方法包括2个主要的功能模块:预处理模块和特征选择模块。预处理模块对输入的Apk文件进行解压缩和反编译得到Smali源代码和Android Manifest.xml文件,再从中提取出3种类型的特征集,并对提取出的特征集进行缺失值清理、重复值清理、格式清洗和异常值处理等处理;特征选择模块对处理后的特征集进行Mann-Whitney检验,提取出存在频率分布偏差的特征集,再利用外观比率间隔算法对特征的偏差程度和出现频率进行量化并选择,最终通过粒子群优化算法结合分类器实际检测效果得到最优特征子集。
1.2 预 处 理
首先,使用Androguard工具[10]对Android应用程序的Apk文件进行解压缩。其次,反编译解压缩后的文件,得到Smali源代码及AndroidManifest.xml文件。然后,解析Smali源代码中的invoke-virtual、invoke-direct、invoke-static和invokesuper四个指令的汇编代码,得到API特征SApi={p1,p2,…,pm}。其中,m为应用程序包的数量。当pm出现在Apk Smali源代码中时,其值为1,否则为0。最后,解析AndroidManifest.xml文件,从文件中获取访问控制机制的特征和组间通信的特征,如权限、系统组件包含的Intent元素等。分别从AndroidManifest.xml文件和Smali源代码中提取出24个权限特征、45个系统Intent特征及620个敏感API作为原始特征集。初始特征的具体信息如表1所示。

表1 初始特征信息Table 1 Initial feature information
得到原始特征集后,对数据进行清理缺失值、清理重复值、清洗格式及处理异常值的操作。清理缺失值主要是将数据集中有属性值缺失的数据删除,如若某个权限的数据值不存在,则直接删除该应用程序的所有数据;清理重复值主要是以应用程序的ID作为标准,删除所有具有相同ID的数据,使得数据集中每个ID仅有一条数据;清洗格式主要是删除数据集中的不合法字符,如“-”等,修改不正确的数据格式,或将权限数量值由“科学计数”格式修改为“文本”格式等;处理异常值主要是识别数据集中的离群点及异常点并删除该条数据,如某个ID中权限特征值为10 000的数据。
经过数据预处理后,得到一个无空缺属性值、无重复应用程序、无异常属性值及数据格式正确统一的Android恶意软件特征集,以便后续步骤使用。
1.3 特征选择
1.3.1 Mann-Whitney检验
经过预处理后得到包含系统权限、API和组间通信Intent特征的原始特征集。接下来使用Mann-Whitney检验[11]来分析这些原始特征集中的特征在恶意和良性软件中的频率分布是否有显著不同。
Mann-Whitney检验方法是一种非参数秩和假设检验,对独立样本进行的一种不要求正态分布的T-test检验方法,能够对来自除了总体均值以外完全相同的总体,检验是否具有显著差异。首先,假设2个独立样本之间没有差异,成立则H0,不成立则H1。该方法的具体步骤如下:
步骤1 检验的2组独立样本n1、n2先进行混合,并根据数据大小升序排列并编排等级(秩rank),遇到相同的数据时,等级值相等,为编排等级前的平均值。
步骤2 分别求出2个样本的等级和R1、R2。
步骤3 Mann-Whitney检验统计量U1、U2的计算公式如下:
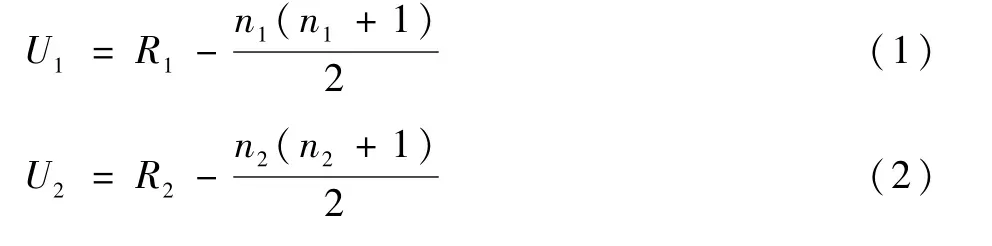
式中:U1、U2中的最小值用于与显著检验阈值Uα(查Mann-Whitney Table可得具体值)相比较,如果Umin<Uα时则拒绝H0,接受H1,表明两样本之间存在差异。
分别假设在恶意软件和良性软件中第i个特征集没有显著不同(不存在分布偏差),拒绝零假设的阈值a为0.05。再将恶意和良性的软件分为2组,输入矩阵如表2所示。如果一个应用软件(恶意或者良性)包含某个特征,则该样本的值Bf或Mf为1,反之为0。在一个检验中,2组样本集代表1个特定权限是否被恶意或者良性软件使用。Mann-Whitney检验的输出为拒绝假设或接受假设。当Mann-Whitney检验的p值大于阈值时则拒绝假设,当Mann-Whitney检验的p值小于阈值时则接受假设。

表2 Mann-Whitney检验输入矩阵Table 2 Mann-Whitney test input matrix
1.3.2 外观比率间隔算法
通过Mann-Whitney检验得到存在分布偏差的特征集F,接下来利用外观比率间隔算法量化特征在恶意软件和良性软件中的分布偏差程度,以及特征在良性软件和恶意软件中的出现频率,本文目标是:选择出在整体软件中高频出现且在恶意软件和良性软件中分布偏差程度大的特征。假设比例越小,一个特征在良性应用和恶意软件之间的外观比例差距越大。因此,显示小比例的特征对于检测恶意软件是有用的。外观比率间隔算法主要步骤如下:
步骤1 分别计算特征集F中的特征f在良性软件和恶意软件中的外观比率E(f)。特征在良性软件的外观比率E(f)benign和恶意软件的外观比率E(f)malicious计算公式如下:

步骤3 特征选择。若特征f的外观比率比例E(f)proportion不为0,则判断外观比率比例E(f)proportion是否小于阈值Tproportion,若小于阈值,则该特征为只在良性或恶意软件中频繁出现的特征,该特征被选择进入特征子集,若大于阈值,则该特征为只在良性或恶意软件中较少出现的特征,不被选择进入特征子集。若外观比率比例E(f)proportion为0,则 判 断 外 观 比 率 比 例 差 异E(f)difference是否小于阈值Tdifference。若小于阈值,则该特征为只在良性或恶意软件中频繁出现的特征,该特征被选择进入特征子集F′,若大于阈值,则该特征为只在良性或恶意软件中较少出现的特征,不被选择进入特征子集F′。外观比率间隔算法伪代码如下。
算法1 外观比率间隔算法。

输入:F,n(B0f),n(M0f),n(B f),n(M f)。输出:F′。

For i to F.size()do计 算 E(f)benign,E(f)malicious,E(f)proportion,E(f)difference If E(f)proportion不为0 then If E(f)proportion小于阈值T proportion then F←fi Else: F←/fi Else:If E(f)difference是否小于阈值T difference then F←fi Else: F←/fi
1.3.3 粒子群优化算法
通过外观比率间隔算法提出低频和低偏差的特征后,接下来利用粒子群优化算法选择出用于Android恶意软件检测的特征子集。
首先,将粒子群随机初始化即随机选择特征子集。粒子的位置即特征子集Xi={x1,x2,…,xN},xi∈{0,1},i=1,2,…,N。每个粒子的位置代表一个特征子集。其中,N为特征的总数,xi=1代表i位置的特征被选择,xi=0代表对应位置的特征不被选择。初始化时,每个粒子位置在[0,1]之间。
然后,计算适应度(Fitness),公式如下:

式中:r为属于(0,1)区间的一个随机数;vi为粒子的速度大小。
最后,设置停止条件。当选择出的特征子集在分类器中的检测准确率达到阈值时则停止,否则继续进行特征选择。
2 实验分析
2.1 实验环境和条件
实验所用软件资源如表3所示,包括Python和Anaconda,分别用来提供脚本语言环境和搭建虚拟环境。实验所用硬件资源如表4所示,使用Mac计算机来编写代码和运行程序。

表3 实验所用软件资源Table 3 Software resources used in experiment

表4 实验所用硬件资源Table 4 Har dware resources used in exper iment
2.2 评价方法
将准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1值作为实验评价指标,计算公式如下:

式中:tp为恶意软件被正确检测的样本数量;tn为良性软件被正确检测的样本数量;fp为良性软件被检测为恶意软件的样本数量;fn为恶意软件被检测为良性软件的样本数量。
2.3 检测能力评估实验
2.3.1 实验目的和数据源
本节实验旨在评估本文方法在不同算法上使用前后的检测性能表现。AMD和DREBIN公开数据集为实验数据源,数据集概况如表5所示。

表5 数据集概况Table 5 Description of dataset
表5中,AMD数据集包含了2010—2016年间的24 650个恶意软件样本及24 650个良性样本,恶意软件包含了135个恶意软件类型和71个恶意软件家族。DREBIN数据集包含了2010年8月至2012年10月的5 560个恶意软件和5 560个良性软件。由于广告软件处于恶意软件和良性功能之间的模糊地带,该数据集中不含有广告软件样本。
2.3.2 实验过程和参数
首先,将DREBIN数据集中的80%数据作为训练集,20%的数据作为测试集。
然后,利用训练集选择出模型中合适的参数。其中,Mann-Whitney检验拒绝零假设的阈值a为0.05,外观比率比例的阈值Tproportion取值为0.2,外观比率比例差异的阈值Tdifference取值为0.5,粒子群优化算法中α取值为0.8,β取值为0.2,加速因子c1为0.5,c2为0.5。
其次,在训练集下,分别利用原始特征集和最优特征集训练梯度提升树算法(GBDT)[12]、自适应提升算法(AdaBoost)[13]、多层神经网络算法(MLP)[14]、逻辑回归算法(LR)[15]、贝叶斯算法(NB)[16]和随机森林[17]算法。其中,随机森林算法中树的数量为100,每个决策树随机选择的特征数目为241。
最后,在测试集下,分别利用原始特征集和最优特征子集计算上述算法的准确率、精确率、召回率和F1值,最终得到Android恶意软件检测外观比率间隔特征选择方法的实验结果。
AMD数据集重复以上过程。
2.3.3 实验结果
以AMD数据集为例,使用提出的外观比率间隔特征选择方法选择出维度为294的最优特征子集,如表6所示。检测能力评估实验的结果如表7和表8所示。

表6 AMD数据集的最优特征子集Table 6 Optimal feature subset of AMD dataset

表7 特征选择实验结果(AMD数据集)Table 7 Experimental results of feature selection(AMD dataset)
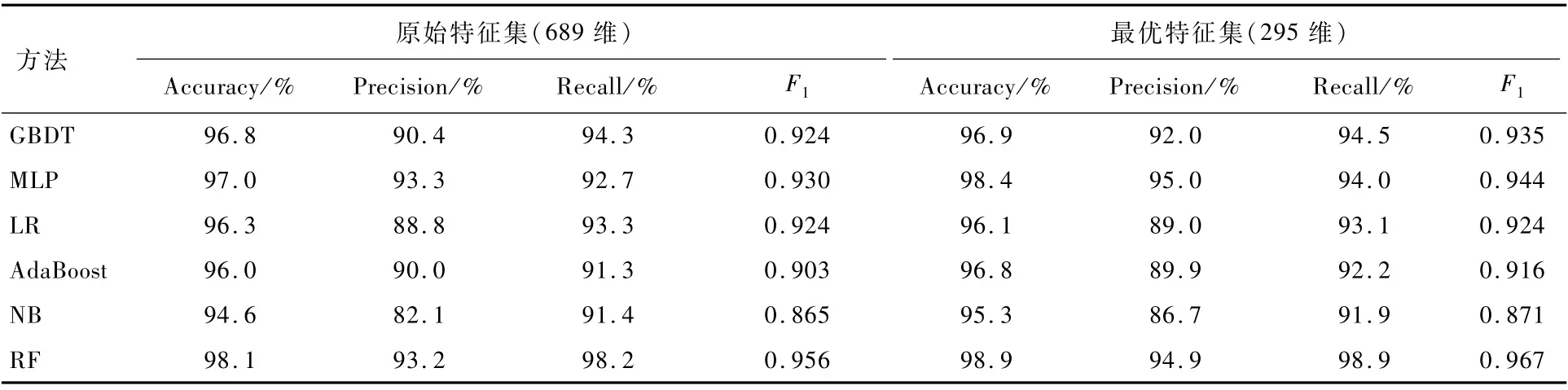
表8 特征选择实验结果(DREBIN数据集)Table 8 Experimental results of feature selection(DREBIN dataset)
2.4 对比分析实验
2.4.1 实验目的和数据源
本节实验旨在对比分析提出的外观比率间隔特征选择方法与其他特征选择方法在Android恶意软件检测准确率上的性能差异。DREBIN公开数据集为实验数据源,其详细介绍如表5所示。
2.4.2 实验过程和参数
首先,将DREBIN数据集中的80%数据作为训练集,20%的数据作为测试集。
然后,利用训练集选择出模型中合适的参数。其中,Mann-Whitney检验拒绝零假设的阈值a为0.05,外观比率比例的阈值Tproportion取值为0.5,外观比率比例差异的阈值Tdifference取值为0.5,粒子群优化算法中α取值为0.8,β取值为0.2,加速因子c1为0.5,c2为0.5。
其次,在训练集下,分别利用文献[18-22]中提到的卡方检验、方差选择、递归特征消除、遗传算法和关联规则特征选择方法,与本文方法对原始特征集进行特征选择并训练随机森林分类器。其中,随机森林算法中树的数量为100,每个决策树随机选择的特征数目为241。
最后,在测试集下,分别利用文献[18-22]中的方法,与本文方法选择出特征并测试随机森林分类器的准确率、精确率、召回率和F1值,最终得到Android恶意软件检测外观比率间隔特征选择方法对比实验结果。
2.4.3 实验结果
对比分析实验结果如表9所示。
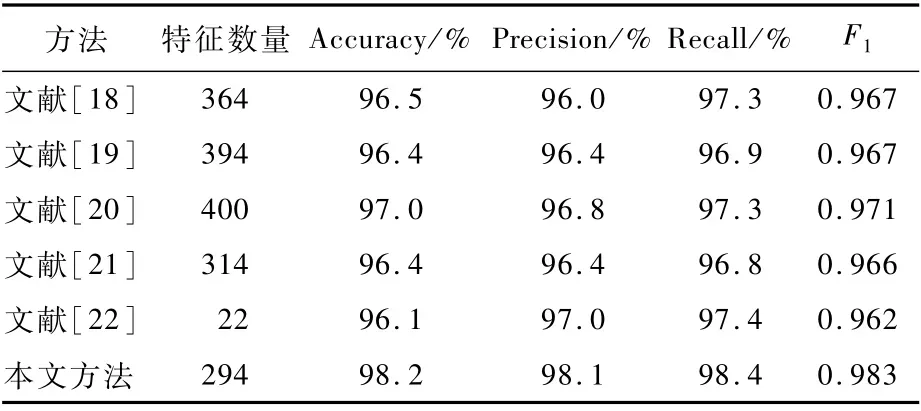
表9 特征选择方法实验结果对比Table 9 Comparison of experimental results among feature selection methods
3 实验结果讨论
在生成最优特征子集时,外观比率间隔特征选择方法可以挑选出低频和低偏差的特征,同时将不相关特征及冗余特征从备选特征集中剔除。从表6可以看出,Android恶意软件更倾向于使用与SMS短信相关的特征,这类特征在正常应用中所使用的频率较低,同时Dex Class Loader等在Android正常应用中所使用的频率远高于在恶意软件中所使用的频率。这一现象表明,Android开发人员有意识地通过动态加载这一技术对自己的核心代码进行保护,同时开发人员还可以通过该技术对自己的软件进行动态拓展。
在检测能力评估实验中,本文方法能够提升分类方法的检测效果。将本文方法应用到分类方法后显示(见表7),在AMD数据集中部分基础分类方法的检测效果有所提升,如使用GBDT方法进行恶意软件检测,其精确率从94.9%提升至96.2%,LR 方法的精确率从90.2% 提升至95.2%,MLP方法的召回率和F1值均提升了0.01,AdaBoost方法、NB方法等准确率、精确率都有不同程度的提升。表8显示,在DREBIN数据集中,部分基础分类方法的检测效果有所提升,如使用RF方法进行Android恶意软件检测,其精确率从93.2%提升至94.9%,其他方法的准确率、精确率等评价指标在进行特征选择后都有不同程度的提升。本文方法能够拉近同类特征在特征空间中的距离,不易过拟合,能够准确检测Android恶意软件。因此,本文方法能够提升分类算法的检测效果。
在对比分析实验中,本文方法优于其他对比方法。结果显示,该方法选择出的特征数量为294,准确率为98.2%,召回率即检测率为98.4%,精确率为98.1%,F1值为0.983,特征数量少于4种(共5种)对比方法,准确率、精确率、召回率和F1值均优于其他5种对比方法。该方法通过分离类间存在频率分布偏差的特征,量化偏差程度和特征出现频率以剔除低偏差和低频特征,并结合分类器实际分类效果选择出特征子集,相比于其他利用特征与检测结果相关关系的对比方法(卡方检验、方差选择、递归特征消除、遗传算法和关联规则),具有更好的特征选择效果。因此,本文方法优于其他对比方法。
4 结 论
本文针对现有的Android恶意软件检测特征选择方法忽略特征在类间的频率分布情况,对同时出现在恶意软件和良性软件的特征过度关注,导致特征冗余性较强的问题,提出一种Android恶意软件检测外观比率间隔特征选择方法。
1)该方法利用Mann-Whitney检验方法选择出在恶意软件和良性软件中存在频率分布偏差的特征,通过外观比率间隔算法量化偏差程度和特征出现频率剔除低偏差和整体软件中低频使用的特征,利用粒子群优化算法根据实际检测效果得到最优特征子集,降低了Android恶意软件特征集的冗余性。
2)使用DREBIN公开数据集和AMD公开数据集进行特征选择能力评估实验和对比实验,实验结果显示,在AMD数据集上选择出了294维特征,进行特征选择后6种分类器的检测准确率提高了1% ~5%,最佳检测准确率为98.2%;在DREBIN数据集上选择出了295维特征,进行特征选择后将随机森林分类器的检测精确率提高了1.7%。与5种特征选择方法对比,具有较少的特征数量,具有较高的准确率、精确率、召回率(检测率)和F1值。这是因为本文方法可以通过确定阈值保存其他方法丢弃的有用特征,同时去除其他方法的冗余特征,降低了特征的冗余性,提高了恶意软件检测特征选择方法的检测效果。
研究工作还可以进一步增加从Apk文件中提取出的初始特征类型和数量,从而提升Android恶意软件检测能力,实现对Android系统和用户进行全面的安全防护。
