大规模物联网恶意样本分析与分类方法
2022-03-08何清林王丽宏罗冰杨黎斌
何清林,王丽宏,罗冰,杨黎斌
(1.国家计算机网络应急技术处理协调中心,北京 100029; 2.北京航空航天大学 计算机学院,北京 100083;3.西北工业大学 网络空间安全学院,西安 710072)
据世界经济论坛(WEF)发布的《2020年全球风险报告》[1],网络攻击将成为继气候灾难、极端天气、核危机等之后人类面临的第七大威胁,另据统计机构Statista的预测报告[2],物联网设备将成为网络中的主流设备,2025年将超过750亿台,各类物联网设备已经成为网络攻击的重要目标。2016年9月,第一个出现的大型物联网僵尸网络Mirai,其恶意样本的功能和结构相对简单,之后各种各样的物联网恶意样本不断涌现,它们的功能越来越多,攻击手法越来越复杂,感染各类物联网设备的能力也越来越强,已经成为网络空间中的重要威胁。物联网恶意样本含有攻击模块等漏洞利用相关的代码,以及C&C服务器地址、代码编写风格等体现作者属性的信息,对样本进行分析、分类,可以获得关键线索,支撑未知威胁发现、攻击组织溯源等工作。
传统恶意样本一般使用家族标签对其进行分类,但是对物联网恶意样本来说,家族标签并不适用。首先,物联网恶意程序现有的家族标签信息并不准确,目前已知的2个最大物联网恶意样本家族是Mirai和Gafgyt,但是这两者都开放了源代码,后续的大部分物联网恶意样本都混合使用了其开源代码,无法实际区分两者。其次,物联网恶意样本的家族标签信息不够,无法精确刻画恶意样本的类别,以Mirai和Gafgyt为基础延伸出多个分支的恶意样本,仅使用家族标签无法对其进行精确刻画和分类。例如,广泛传播的Mozi系列样本,就是一个融合了P2P、Mirai、Gafgyt等多种技术的系列样本,但是并没有明显的家族标签与之对应。因此,需要一种更精确的物联网恶意样本分类方法,对样本的各个家族分支进行追踪和分析。
为了解决该问题,本文开发了一套物联网恶意样本捕获与分析系统,在2019年5月至2020年5月在某运营商的网络出入口节点上共捕获到了157 911个在野传播的物联网恶意样本。通过对样本进行静态逆向和多种维度的统计分析,结合分析结果和关联的威胁情报数据,标注了一套物联网恶意样本数据集,并提出了一种新的物联网恶意样本分类方法。该分类方法能够实现跨平台架构和高效的物联网恶意样本分类任务,并且在标记数据集上取得了优异的分类效果,平均召回率达88.1%。
本文的主要贡献如下:
1)对在野传播的157 911个物联网恶意程序进行了分类和梳理,对其CPU架构分布、加壳方式、样本传播方式等进行了分析,给出了物联网恶意样本的最新流行趋势。
2)结合多维度情报数据,对部分物联网恶意样本进行了标注,形成了一套物联网恶意样本数据集。该数据集包括 9 个家族分支,共计12 278个样本,覆盖X86、MIPS、ARM等3种CPU架构。
3)提出了一种新的物联网恶意样本的分类方法。该方法通过静态逆向分析提取属性函数调用图(attributed functions call graph,AFCG)和字符文本等样本信息,进一步使用图表示学习和文本表示学习的无监督学习算法,提取高维的向量特征,实现对跨CPU架构物联网恶意样本的统一表示。
4)对学习到的高维向量特征进行了分类实验验证,使用有监督学习分类支持向量机(SVM)算法进行分类,在标注数据集上达到平均88.1%的召回率。实验表明,从样本提取出能表征样本特征的信息越多,越能够明显提高分类的准确率。
1 相关研究
2016年,Mirai事件的爆发让物联网恶意样本进入人们的视野,Antonakakis[3]、de Donno[4]等对Mirai事件过程及样本的机理进行了详细描述。Mirai初期主要使用内置密码的密码表,对大量具有弱口令的物联网设备进行了密码爆破攻击,在高峰时期控制了多达60万台的物联网设备。
物联网恶意样本主要是Linux平台下的ELF文件,Cozzi等[5]对10 548个ELF恶意文件进行了系统性分析,结合使用静态分析和动态分析的方法,分析了恶意样本的ELF文件头、持久化、加壳、信息收集、隐藏手法等9类行为特征,并指出同一家族的恶意代码会具有明显不同的行为特征。
Herwig等[6]分析了一个新的物联网恶意程序家族Hajime,使用人工样本逆向分析和流量分析的方法获知Hajime的样本行为,并估算僵尸网络的规模,该僵尸网络是披露的第一个大规模P2P物联网僵尸网络。文献[7]分析了另外一个2020年新出现的大规模P2P僵尸网络Mozi,病毒检测引擎VirusTotal[8]目前把Mozi样本识别为Mirai和Gafgyt,还没有新的家族标签。
文献[9-10]提出了基于卷积神经网络(CNN)深度学习的恶意程序判定和分类方法,其中文献[9]将物联网样本文件直接切割和转换,变成灰度图片后用CNN的模型进行恶意性判定,文献[10]根据样本文件构造熵灰度图后使用CNN深度学习模型进行分类。这类方法都没有对样本文件本身进行深入的分析,没有还原样本的结构特征和语义特征,可解释性不足。
物联网恶意样本是编译链接好的二进制文件,与传统的Windows PE样本及Android APK样本相比,有很多相似之处,其结构特征一般包括逆向还原的函数调用图(functions call graph,FCG)、控制流图(control flow graph,CFG)等,语义特征一般包括函数的反汇编代码片段等。恶意样本文件特征提取是一项繁杂的工作,涉及复杂的静态逆向分析,IDA Pro是最常用的静态分析工具,文献[11]对如何用IDA Pro分析物联网恶意样本给出了总结。其他常用的逆向分析工具还有Angr[12]、Radare2[13]等。
文献[14-15]提出使用FCG作为恶意样本相似性比较的主要参数,其中文献[14]使用优化的图编辑距离算法计算2个FCG图之间的距离,文献[15]则使用更多维度的函数属性值来作为FCG的节点属性,并采用学习优化的方法来计算FCG的距离矩阵。
可以看出,提取样本文件本身的复杂结构特征和语义特征,并对其进行表征和学习,是恶意样本研究的主流方向。物联网恶意样本出现时间不长,与传统Window样本和Android样本相比又有很多新的特性,如支持的CPU架构平台多样等,目前专门针对物联网恶意样本的分类研究还较少。本文借鉴传统的样本特征提取方法,同时考虑到物联网样本多平台问题,提出一种结合图和文本特征,以及结合无监督学习和有监督学习的样本分类方法。
2 物联网恶意样本分析
2019年5月至2020年5月,在某运营商网络中一共捕获到157 911个传播的物联网恶意样本。通过对这些恶意样本进行大规模静态逆向分析,包括其支持的CPU架构、加壳方式、漏洞利用传播方式等,形成了一套物联网恶意程序标注数据集。分析流程如图1所示。
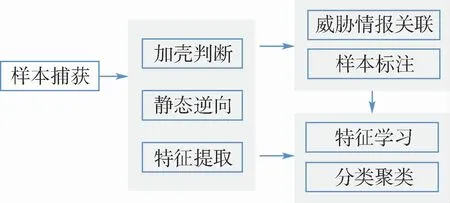
图1 样本分析处理示意图Fig.1 Schematic diagram of sample analysis and processing
2.1 样本CPU架构分布
虽然物联网设备的硬件形态及CPU架构多种多样,但是恶意程序的主要攻击目标是操作系统基于Linux内核的设备,因此物联网恶意样本的形态主要为Linux下的ELF可执行文件。黑客在制造恶意程序时,一般都会交叉编译成多个版本的ELF文件同时发布,以支持不同的CPU架构。根据所有样本的统计,其支持架构分布如表1所示。
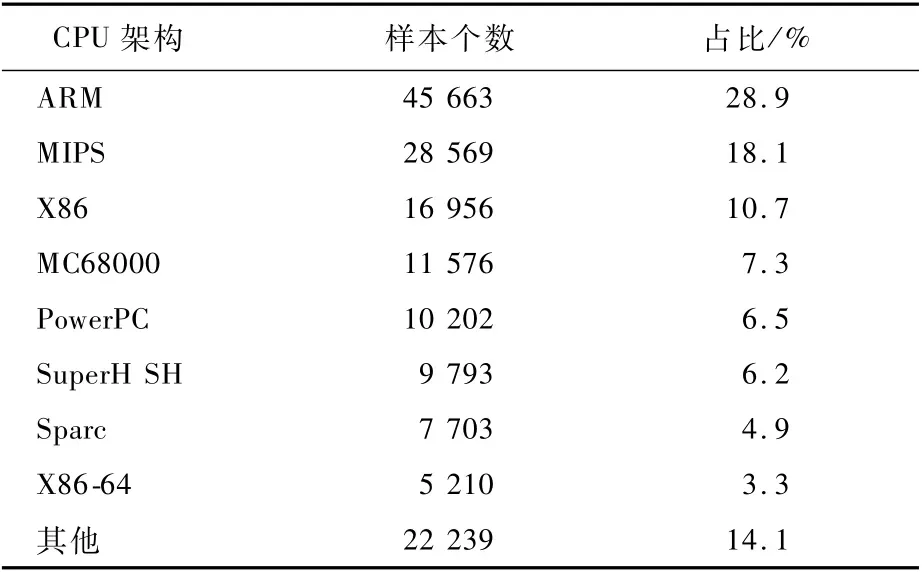
表1 157 911个恶意样本CPU架构分布Table 1 Distribution of CPU framework of 157 911 malwares
统计数据显示,物联网恶意样本攻击最多的为ARM和MIPS设备。可能因为在互联网中暴露且经常会出现漏洞的物联网设备主要是路由器和摄像头两大类,其CPU架构主要也是这2种,容易被黑客所青睐。另外统计数据还显示,大部分支持Sparc、PowerPC等架构的样本,同时也有支持ARM、MIPS和X86等架构的样本存在。这说明很多的物联网恶意程序会同时发布7~8个版本。发现某个CPU架构的恶意样本后,在恶意样本库中快速找到跨平台的其他同源恶意程序,也是大规模样本分析的一个基本目标。
2.2 样本加壳
通过对恶意样本加壳进而隐藏相关信息,防止被安全人员逆向分析,是黑客常用的一种对抗手段。大规模样本分析特别是静态分析,需先解决样本加壳问题,然而对恶意程序进行脱壳从来就不是一项容易的工作。Windows平台下的PE样本和Android平台下的APK样本,由于发展时间较长,存在各种各样的加壳方式,脱壳对抗难度非常复杂。物联网平台下的ELF样本,由于大规模出现的时间相对较晚,情况稍有不同,目前主要采用相对单一的UPX方式进行加壳。
UPX本身是一种开源的文件压缩方式,恶意程序编写者们会通过改写UPX文件头的各种参数来防止解压。文献[5]中对2017—2018年捕获的10 548个ELF样本进行统计,发现只有3.8%的恶意程序使用了UPX 加壳。本文对2019年5月至2020年5月捕获的157 911个恶意样本进行分析发现,其中有超过37%的恶意样本采用了UPX加壳,详情如表2所示。
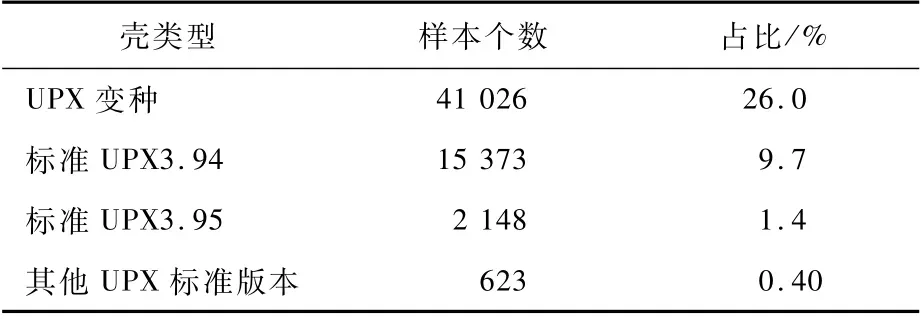
表2 物联网恶意样本加壳方式Table 2 Packers of IoT malware
因此从长期来看,黑客会采用更多样、更复杂的方式对ELF文件加壳,这将是安全人员长期面临的一项对抗与挑战。
2.3 传播方式
早期的物联网恶意样本,如2016年在美国爆发的Mirai,主要采用SSH密码爆破的方式进行植入和传播。随着黑客技术的演进和攻防对抗的升级,越来越多的物联网恶意程序开始利用设备的漏洞进行植入和传播。2019年5月披露的Echobot系列样本[16]使用了多达70个已知的漏洞利用进行传播。2020年3月,笔者团队发现有Fbot的恶意样本开始利用0-day漏洞进行传播。
针对所有捕获的样本进行漏洞利用分析,在其中的68 648个样本中发现有已知漏洞利用行为,共计发现超过200种物联网漏洞利用行为,其中最常用的物联网漏洞有CVE-2017-17215等。统计前10个利用最多的漏洞,详情如表3所示。
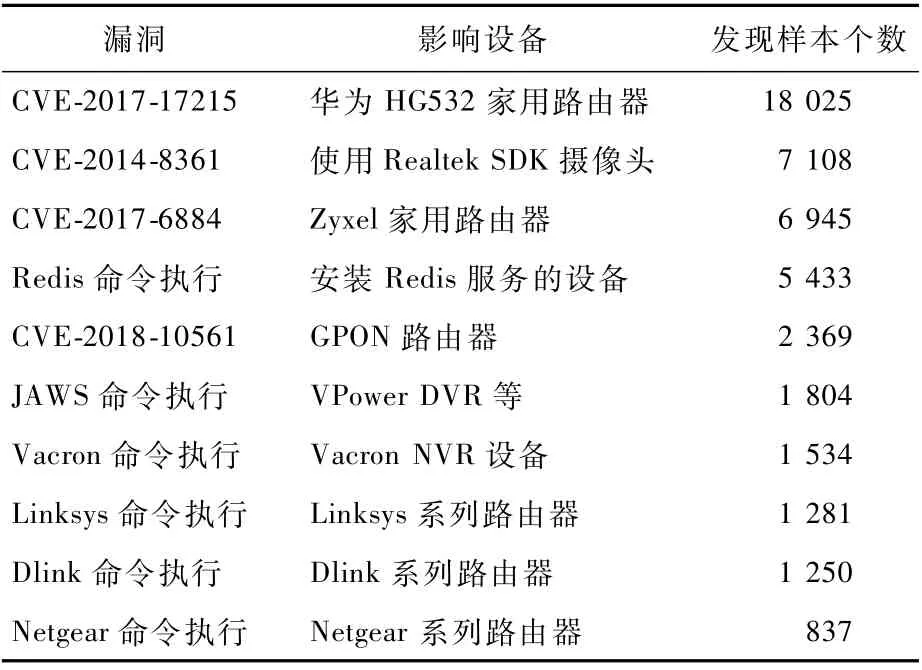
表3 样本10大漏洞利用统计Table 3 Statistics of top 10 vulnerability exploited in malware
另外,笔者团队发现物联网恶意样本在网络中传播时会使用特定的文件名,如Hajime家族[6]主要采用“.i”的文件名进行传播,最新的Mozi系列样本[7]使用了“Mozi.a”和“Mozi.m”的文件名。图2显示了2个典型Mozi样本的逻辑结构,分别是“Mozi.a”和“Mozi.m”,具有不同的CPU架构,但是具有相似的逻辑结构。
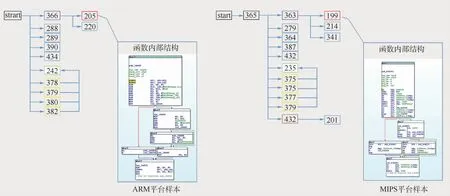
图2 两个Mozi样本的FCG示意图Fig.2 Schematic diagram of FCG of two Mozi samples
样本传播方式包括传播文件名和漏洞利用手法,是标注数据集时参考的一项主要参数。
2.4 标注数据集
在恶意样本识别和分类研究中,目前使用最多的数据集是2015微软恶意样本分类挑战赛数据集[17],其中的恶意程序主要是Windows平台下的PE文件,包含9类共21 704个恶意程序。而针对物联网恶意样本的研究,目前并没有一个公认的数据集。
根据捕获到的恶意样本文件,以及相关的传播地址、C2地址等威胁情报信息,同时参考病毒检测引擎平台VirusTotal[8]的样本检测结果和部分人工分析结果,标注了一套物联网恶意样本数据集,作为后续进行大规模样本分类研究的基础。如此规模的数据集标注,无法依赖人工分析手动完成,须通过自动识别和关联,因此数据集的标注要求至少满足以下2个条件:①样本能够通过程序自动脱壳并成功提取到静态编译信息,以满足后续的特征处理要求;②样本有相关的关联威胁情报信息,如样本使用的传播文件名和传播地址、样本在VirusTotal[8]上有检索结果等信息,用来确定该样本是哪个具体的家族或者分支。但是在捕获的所有样本中,其中有大部分样本或是无法进行自动脱壳,或是无法关联到相关信息,因此无法对其进行标注并纳入到标注数据集中。最终从157 911个物联网恶意样本中成功标注了12 278个样本,作为标注数据集进行分类实验。包括9个类别,覆盖ARM、MIPS、X86三种CPU架构,如表4所示。数据集中的样本都是已脱壳并能通过反编译工具提取出静态特征信息。
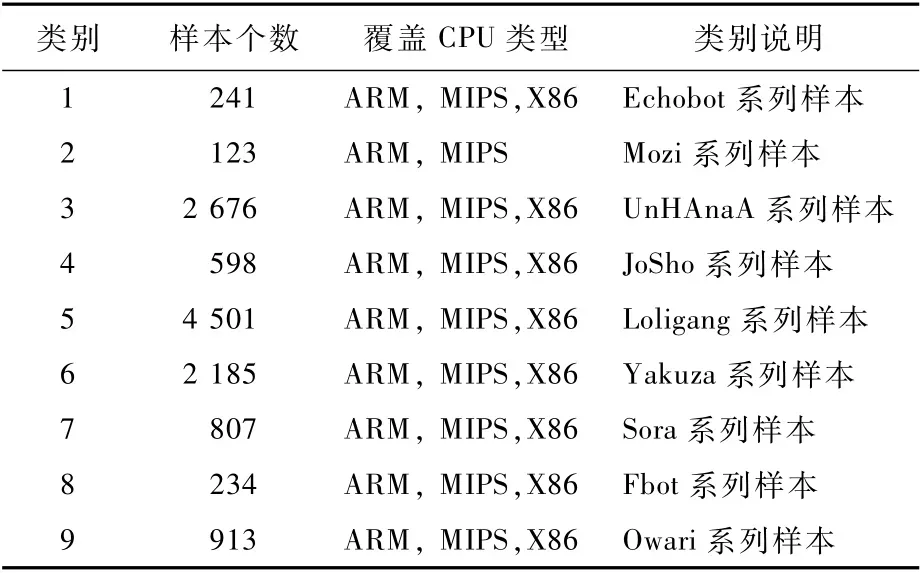
表4 物联网恶意程序标注数据集Table 4 Labeled IoT malware dataset
数据集中的类别与恶意样本的家族并不是一一对应关系,而是某一家族样本的某类具体分支。即使同一个样本,在VirusTotal上不同引擎也会给出不同的家族标签,而目前物联网恶意代码的家族判定并没有统一的标准。本文目标不是研究样本的恶意性判定或者家族判定,而是研究如何对已发现的大量IoT恶意样本进行更详细的分类,找出具有同类行为的分支,并对其进行更深入的追踪,从而溯源攻击组织、发现具有高级威胁的未知样本等。
3 样本特征提取
恶意样本分析,一般来说有静态分析和动态分析2种方法。静态分析主要通过反汇编反编译,提取二进制文件的语义和语法信息;动态分析则是通过在虚拟环境下运行可执行程序,获得各类运行状态行为信息。目前,物联网恶意程序支持的设备种类众多,缺乏成熟的动态执行环境。本文主要采用静态分析的方法提取函数调用关系图、函数反汇编代码、字符文本等特征,主要分析流程如图3所示。
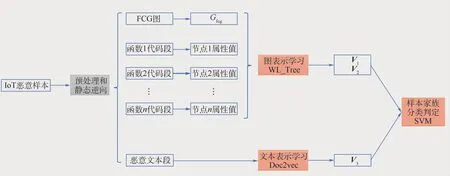
图3 样本特征提取与分类方法示意图Fig.3 Schematic diagram of sample feature extraction and classification method
3.1 函数调用图
FCG是能够从整体上直接反应恶意样本逻辑结构的一种表示。它是一类典型的图结构G(node,edge),node表示恶意样本中的函数,edge表示函数之间的调用关系,edge是有向边。图2显示了2个同分支的样本,分属不同的CPU架构,但具有相似的FCG结构和函数结构。图中:节点编号代表了函数的排列序号,样本总计有400多个函数节点,为方便表示只标记了从起点函数开始的前3层调用节点。
能否成功从样本中还原出FCG图,取决于2个因素:①样本没有加壳或者能够成功解壳;②样本没有使用外部动态链接库。本文数据集都进行了脱壳处理,而且都仅使用静态链接的样本。另外,根据对物联网样本库的统计,目前仅有3.2%的样本使用了动态链接库。
对恶意样本直接进行静态逆向得到的FCG图,通常不是一个连通图。例如,很多物联网的恶意程序都有一个初始化函数init_func,其表示的节点在图中是个独立的节点。根据对样本库的统计数据显示,最大连通子图中的节点个数占整个图的节点个数比率的分布区间为93.2% ~99.1%,平均值为96.7%。选取G(node,edge)的最大连通子图作为恶意程序的函数调用图近似表示Gfcg,可以认为Gfcg就是恶意程序的逻辑结构表示。
本文针对数据集中的12 278个不同的恶意程序文件进行分析提取,得到1 323个不同的Gfcg文件。这表明很多恶意样本具有同样的Gfcg,样本的逻辑结构是完全一致的,恶意样本的编写者们只是进行了一点简单修改,如修改C2地址或对某个函数的功能进行升级等,再重新编译作为一个新的恶意程序发布。以数据集中的第4类Josho样本为例,有2个MD5值不同的样本,其样本MD5值分别为:“aeb9d28e524694e5ef5eb6275 ef53b05”和“90e2ab9037c9b18cb2ea83c5f3862ee6”(VirusTotal[8]上均可以检索到样本相关信息),文件大小分别为56 584 Byte和58 180 Byte。通过静态分析提取得到的这2个样本的函数调用关系Gfcg完全一样,而这样的情况在同一类样本中大量出现。由此可以看出,Gfcg图是一种能够快速识别和分类相似恶意样本的方法。
进一步,如果加上节点属性,也就是函数的属性,就可以得到恶意程序的逻辑结构及语义表示,形成属性函数调用图,用Gafcg表示。
3.2 函数属性
恶意样本是一类可执行的二进制文件,而函数是二进制文件的基本逻辑单元。针对二进制文件中的函数属性提取和学习是逆向静态分析的一个重要研究方向,尤其是漏洞挖掘样本关联分析等。很多安全分析人员直接根据函数的hash值进行分析[18];也有使用函数控制流图信息来进行大规模二进制分析[19],如漏洞挖掘固件组件分析等;文献[20]使用BERT深度学习框架学习函数的特征。
与以上方法不同,本文使用一种相对高效且跨平台的方式来学习函数的向量化表示。先对恶意程序进行静态逆向得到函数的一段反汇编码。在反汇编代码中,一般包含API调用(系统或外部调用)和本地汇编操作。一个典型的本地汇编操作包含操作指令和地址或变量。其中地址或变量是动态执行相关的,通过静态逆向分析得到的值参考意义有限,因此重点关注操作指令。把函数转换成一段包含操作指令和API调用的序列。
不同CPU架构的指令集规模不一样,统计157 911个物联网恶意样本用到的指令,按照CPU架构类别统计,如表5所示。更进一步,为了解决函数属性跨平台统一表示的问题,参考文献[21-22]的方法,将操作指令统一为中间语言表示。定义20个不同的操作类型,根据指令类别和在样本中出现的频率,将不同CPU架构的指令映射到这20类中,将API调用映射为另外1类。目前,仅对物联网恶意样本中最常见的3种CPU架构,也是样本集中涉及到的3种CPU架构,即ARM、MIPS、X86做了映射和统一表示。

表5 恶意样本中常用的3种CPU架构指令集数量Table 5 Number of instruction set commonly used in malware with three CPU framewor ks
提取的函数属性值是一段有序的数值序列A,序列中的数值为1~21的数。通过对序列A学习的向量作为函数的属性值。进一步,将函数与Gafcg中的节点对应起来,并将函数属性值作为节点的属性值,得到样本的Gafcg表示。从样本中一共提取出了1 323个不同的Gafcg文件。
3.3 字符串信息
物联网恶意程序在编译连接生成ELF格式的可执行文件时,会将很多字符串一起打包到可执行文件中。这些字符串一般包括本地的操作命令、密码表、远程通信命令等信息。通过反汇编提取恶意程序可执行文件的字符信息,从而来判断恶意程序的行为,是逆向分析时的一个基本手段,如提取恶意程序外联的C2地址、恶意程序传播时利用的漏洞、使用的爆破密码表等。字符串包含了丰富的信息,对其内容进行表示学习和分类,可以更好地对恶意程序进行识别和分类。
从恶意程序提取出来的字符串是按行排列的,每一行代表一类操作或者一类命令,行与行之间是上下文无关的。对样本提取原始的字符串,再进一步重排序处理,得到8 590个不同的字符串文本文件malware_string。
样本集中的样本个数是12 278个,提取出来的不同的Gafcg文件是1 323个,不同的字符串文本文件是8 590个。字符串文本文件和Gafcg文件的数目并不一致,多个样本可能对应同一个Gafcg文件,却对应不同的字符串文本文件。因为同一个样本进行修改再编译发布时可能不改变函数逻辑结构FCG,却会修改字符串文本文件,所以样本分类时,将主要参考FCG图和AFCG图等逻辑结构信息,字符串文本特征作为辅助。进一步对字符串文本进行映射和处理后,从样本集中一共提取到1 323个不同的字符串文本文件。
4 特征学习及分类实验
从物联网恶意样本中提取出来的特征是包括图和文本等信息的复杂结构特征,无法直接使用这些特征来进行恶意样本的分类任务。因此,使用图表示学习和文本表示学习的方法,将恶意样本的特征转换成统一的向量表示。
针对实际场景设计了9组分类方法实验,验证从恶意样本中提取和学习到的特征的有效性。
4.1 图表示学习
文献[14-15]用恶意样本的FCG图进行分类判定,两两计算2个图之间的编辑距离,再以此为基础构建和优化相似性模型。本文做法与之前的方法不同,使用图表示学习的方法,将FCG图通过表示学习直接映射到一个向量空间中。
图表示学习,目前主要有基于核函数的方法和图神经网络方法两大类。图神经网络方法更适合学习节点的特征用于节点分类任务,而针对整个图的分类任务,则使用图核函数的方法更多。目前,常见的图核函数有基于随机游走的核函数、基于路径的核函数、基于子树结构的核函数等。
对图的整体结构捕获和表达能力最好的是基于子树结构的WL_Subtree核函数[23],其是一种快速计算的子树核,由多步迭代计算完成。
图表示学习对象为:无节点属性的FCG图和包含节点属性的AFCG图。从样本数据集中一共提取出1 323个不同的图,图的节点规模分布区间为212~3 226,均值为372。对FCG图Gfcg和AFCG图Gafcg分别进行图表示学习,得到2组特征向量V1和特征向量V2,如式(1)、式(2)所示,其中kWL_SubTree表示WL_Subtree核函数:

4.2 文本表示学习
目前,文本学习方法主要有轻量级的TF-IDF、Word2vec[24]等简单模型,也包括像BERT[20]深度学习框架等较为复杂的模型。TF-IDF实现相对简单,较为容易理解,不足在于没有考虑特征在样本间分布情况,难以适用于恶意样本分类场景。BERT深度学习框架能够梳理出连续文本的内在联系和语言结构,但对数据规模及模型大小要求非常苛刻,一般适用于大规模海量的数据场景中。
学习对象为恶意样本提取出来的字符串形式的文本标记为malware_string,其大小分布一般在5 KByte至50 KByte之间,样本中需要用来进行下游分类任务的文本malware_string的数量为1 323个。综合性能和效率考虑,同时能够更好地利用隐藏在样本序列中的语义和语法信息,引入Doc2vec[25]方法进行向量特征提取。Doc2vec方法是一种无监督算法,可从变长的恶意样本字符文本中学习得到固定长度的特征表示,既可克服词袋模型中没有语义的缺点,又能接受不同长度的恶意样本做训练,并表征为向量。利用Doc2vec方法进行向量特征学习过程,主要包括去噪、训练及推断等3个步骤,如图4所示。在Doc2vec方法中,首先在去噪过程中通过预处理剔除了一些恶意文本中噪声数据,将恶意文本库的格式修剪统一;其次在训练过程中,主要期望在已知的恶意文本训练数据中得到恶意字符串的词向量、softmax的参数、恶意文本段落向量或句向量以进行后续推断操作;最后在推断过程中,主要利用已有信息,推断后续新的段落向量表达形式,得到恶意文本的向量表达形式。最终通过Doc2vec方法学习到的恶意文本向量表达记为特征向量V3,如下:

图4 基于文本表示学习的向量特征学习Fig.4 Vector characteristic learning based on text representation learning
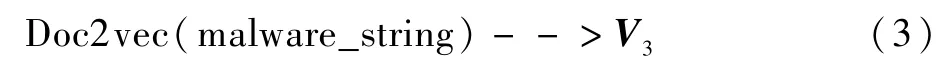
4.3 二分类学习
设计的分类实验是二分类学习,对应的实际场景是:如果已知某一物联网恶意样本家族分支的系列样本后,能否通过学习的方法,快速地从样本库中或者新发现的样本找出同类的样本。将样本集中的每一类样本分别标记为正例样本,样本集中的其他样本标记为负例样本,做二分类学习和判定。分类算法使用SVM。
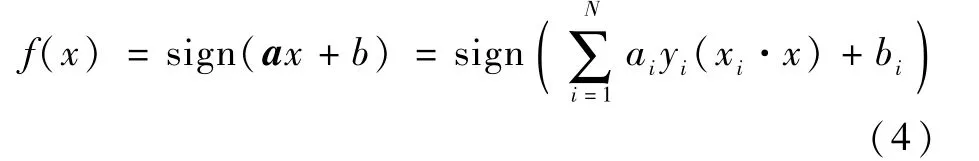
SVM是基于超平面分类线性可分的假设,通过学习和优化得到一个超平面分类器。假设有N个训练集{(x1,y1),(x2,y2),…,(xN,yN)},xi∈Rd,yi∈{-1,1}。假设空间为超平面(a,b),a为权重向量,b为偏差,对一个新输入的数据x可以用如下分类:该分类问题是个不平衡分类问题,正例样本的个数远小于负例样本的个数,实际场景中也是如此。因此,更关注正例样本是否被正确标记,把召回率R作为主要参考的评价指标,同时参考F1值,指标如式(5)和式(6)所示。其中TP表示被正确标记正例样本,FP表示被错误标记的正例样本,FN表示被错误标记的负例样本。

选3种不同的样本特征作为分类学习的算法输入,分别使用从样本FCG 图学习到的向量V1(1)、从样本AFCG图向量学习到的向量V2(2)、V2和从样本的恶意文本学习到的向量V3(3)相结合。不同的特征选择,代表了不同的样本表征能力。实验中,将训练集和测试集划分为0.8和0.2,最终选取多次实验的平均值作为最终指标。实验结果如表6所示。
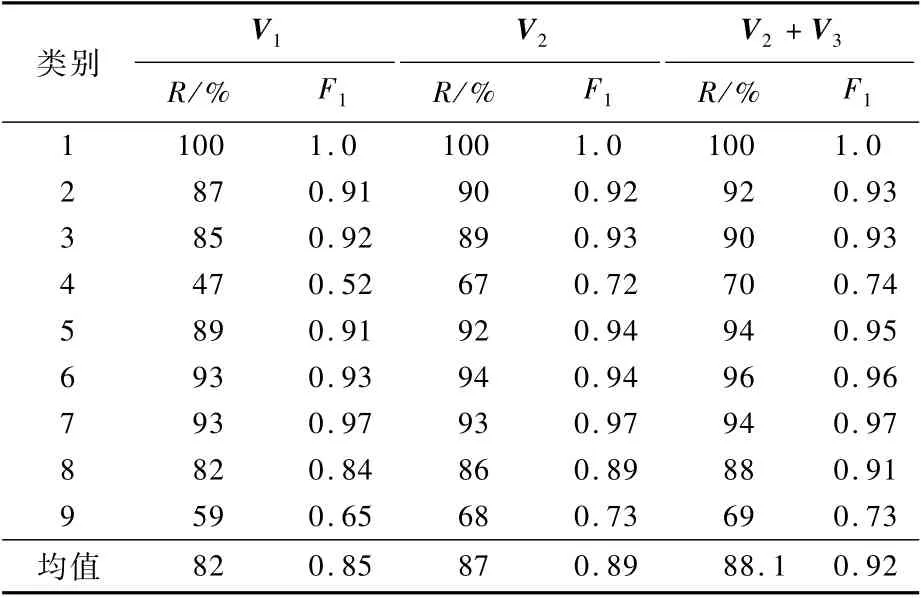
表6 不同特征和类别的分类召回率及F 1 值Table 6 Classification r ecall rate and F 1 value with different features and categories
4.4 实验结果分析
实验结果显示,样本分类平均召回率达到88.1%,说明从样本中提取的特征是有效的,通过表示学习得到的向量,可以很好地从整体上表征恶意样本。实验结果还显示,使用的特征越多,分类效果越好,说明如果能够从样本中提取出更多能表达样本逻辑结构和语义信息的特征,更有助于提高分类的效果。
实验中的9组分类实验,分别对应数据集中9个不同的样本家族分支类别。其中除了第2组Mozi分支以外,其他8个分支均由Mirai家族演化而来。其中第4组和第9组的样本分类召回率较低,分别是JoSho家族分支的74%和Owari家族分支的73%。对这2个家族分支的部分样本进行人工逆向分析,发现其样本中大量借鉴了Mirai的开源源码。例如,属于JoSho家族分支的MD5值为“aeb9d28e524694e5ef5eb6275ef53 b05”的样本,和属于Owari家族分支的MD5值为“46a4cea56dafbfecd0981a7d411508c9” 的 样 本(VirusTotal[8]上均可以检索到样本相关信息),通过对这2个样本进行人工逆向分析发现,其与Mirai源代码的差异性不到10%。而这2个样本在这2类家族分支具有典型性,在该家族分支中分别存在多个与这2个样本相似的样本。这说明这2个家族分支在样本中自己进行编码的部分并不多,也就是说没有很明显的样本分支特征,从而导致分类效果不是很理想。
实验结果显示,其余7组家族分支的样本检出率均超过了0.8,其中1组的检出率为1.0,说明本文样本分类方法能够对大部分的样本家族分支进行正确地分类,实现对不同家族分支的样本进行追踪分析的目标。
5 结 论
目前,针对物联网恶意样本的大规模分类研究属于刚刚起步阶段,本文根据实际工作中捕获到的物联网恶意样本,进行了大规模分析和分类的尝试:
1)对所有样本进行了分析和统计,并结合外部威胁情报特征和人工分析,标注了一套物联网恶意样本数据集。
2)通过静态逆向分析提取特征和学习特征,在标注的样本数据集上进行分类实现,效果表现优异,达到了平均88.1%的召回率。
3)该样本分类方法在实际工作中取得了较好的效果,能够持续地自动标注新的样本。
在实际工作中,笔者一直在持续跟踪Mozi系列的样本[7],即标注数据集中的第2类,通过数据集训练生成的分类器,从原来的样本库中识别出了数十个之前未曾被标记的Mozi系列样本,并通过后续进一步的人工分析一一确认,通过分类器自动标记的Mozi样本是有效的。进一步,该方法已经用在后续的日常样本分析中,将每天新发现的样本进行自动分类和标注。
恶意样本分析和分类与其他领域(如图像识别分类等)不同,其研究对象恶意样本是由黑客制造出来,对象的性质会由于黑客持续对抗而变化。对样本的特征提取会由于加壳等技术的升级而变得日益困难,特征的表达能力可能也会由于使用代码混淆等高级对抗手法而受到影响。笔者将深入挖掘样本多个维度的特征,并结合安全专家知识,对物联网恶意样本分类问题进行持续研究。
