基于fastText算法的行业分类技术
2022-03-08吴震冉晓燕苗权刘纯艳张栋魏娜
吴震,冉晓燕,苗权,2,*,刘纯艳,张栋,魏娜
(1.国家计算机网络应急技术处理协调中心,北京 100029;2.国家计算机网络应急技术处理协调中心北京分中心,北京 100055; 3.长城计算机软件与系统有限公司,北京 100190)
中国的企业数量众多,行业类别广泛。对于广大企业进行行业分类是十分必要的,能够进一步解释特定行业所处的发展阶段及其在国民经济中的地位。以《国民经济行业分类》[1](GB/T 4754—2017)为例,将行业分为了97个大类、473个中类、1 380个小类。近年来,网信企业规模快速增加,随着基于深度学习的文本分类技术[2-4]的提升,如何利用企业数据信息进行行业智能判别和分类具有重要意义,同时对于全国企业的智能分类具有借鉴和参考作用。
据不完全统计,中国网信行业企业数量不低于200万家,既分布于互联网、信息设备制造、信息传输、信息技术服务等国民经济行业范围,又同时存在于电商、金融、教育、医疗甚至是大数据、人工智能等新兴和前沿领域。如何对网信行业进行行业分类,是做好网信企业统计分析工作的前提和基础,进而整体掌握当前中国网信行业及重点网信企业发展情况,及时发现运行过程中表现出的苗头性、倾向性、潜在性问题,并提出相对应的政策建议。
目前,进行行业分类的过程中,往往存在覆盖面积小、方式单一、时效性不足等问题,仅依靠传统的人工识别方式无法满足需求,亟须一种精确、高效的识别方式。随着人工智能技术的不断发展和进步,针对文本分类问题的研究也出现多元化的发展。文本分类一般包括3个步骤:①文本向量化;②根据算法提取文本特征向量;③使用分类器对特征向量进行分类判断。因此,词表示的好坏将直接影响分类器的结果,如何合理而有效地向量化文本通常是文本分类的关键技术。
词向量最初的表示形式是one-hot,该方法的缺点是:①词与词间的语义视为相互独立,无法表达词之间的语义信息。②每种表达每次只有1个位于高位,其余均位于低位,可能导致维度爆炸,这造成了one-hot表示具有高稀疏的特性。TFIDF算法解决了以上部分问题,其用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。算法主要思想是:字词在文件中出现的次数增多,其重要性也相应增加,但会与语料库中出现的频率反比例下降。
2013年,Mikolov等[5]提出了word2vec模型,相对于以上方法,该模型能够产生稠密的向量,避免维度爆炸,在语法和语义的相似性方面有很大的提高。
传统文本分类算法有Bayes、支持向量机(SVM)、KNN、Logistic回 归 等。徐 军 等[6]使 用Naïve Bayes等机器学习方法进行新闻的情感自动分类,但是Naïve Bayes对缺失数据不敏感,需要假设先验模型,从而导致预测效果不佳。2014年,Kim[7]提出了TextCNN网络,验证了使用预训练的词向量比使用随机初始化的词向量能获得更好的效果,而使用预训练的词向量初始化,并在具体任务中进行词向量的fine-tuning可能会得到更好的效果,但是由于卷积神经网络(CNN)更关注局部特征,并且大的卷积核会导致计算量暴增,不利于模型深度的增加,计算性能也会降低。2017年,Vaswani等[8]完全抛弃了循环神经网络(RNN)和CNN等网络结构,首次提出将注意力机制应用在NLP领域,注意力机制也成为了大家近期的研究热点。2019年,Devlin等[9]提出了一种新的语言表征模型BERT,这是一种基于Transformer的双向编码器。
本文提出了一种融合多元数据的fastText算法[10],用于网信行业文本分类。该方法在fast-Text算法基础上,对n元语法模型(n-gram)处理后的输入词序列进行权重计算。同时,融合网信企业信息不同维度的短文本数据,并进行加权计算,实现快速进行网信企业分类的目标。在网信企业数据集上进行实验,分类精确率达到83.1%。
1 相关工作
1.1 数据收集
本文实验通过获取企业经营范围进行企业识别分类。主要获取方式包括:通过政府数据公开平台中提供的公开API接口获取(如北京市政务数据资源网、广东省政府数据统一开放平台、上海市政府数据服务网)企业名称、企业法人、经营范围等信息;通过互联网采集的方式获取企业名称及相关信息。
1.2 文本预处理
文本预处理[11]是对非结构化企业经营范围、舆论等文本信息进行分析,经过过滤、提炼、选定等一系列自然语言处理操作[12]后,通过深度神经网络方法快速自动识别、划分文本中的经营范围词,并对智能分词结果文本进行展示。在网信企业分类的工程应用中,通过数据洗清、分词、词性标注、去停用词4个方面来完成语料的预处理工作。
2 网信企业分类
2.1 分类原则
以《国 民 经 济 行 业 分 类》[1](GB/T 4754—2017)和《电子信息产业行业分类目录》为基础,对国民经济行业分类中符合“网信”范畴的相关活动进行再归类。分类结果考虑中国宏观经济发展、网信事业发展进程的现实情况,以体现阶段性发展特征。
2.2 分类结果
共分为四大类:信息设备制造、信息传输服务、软件和信息技术服务业、互联网和相关服务,一级、二级、三级目录分类如表1所示。

表1 行业分类结果Tab le 1 Industry classification resu lts

续表
2.3 企业分类技术方法
2.3.1 分类识别过程
本文实验采用自然语言预处理技术,主要针对网信行业企业的经营范围进行分段、分句,并对每一句进行分词,根据分词与关键词比对的结果,实现对网信行业统计分类和创新性分类的自动识别与发现。流程如图1所示。
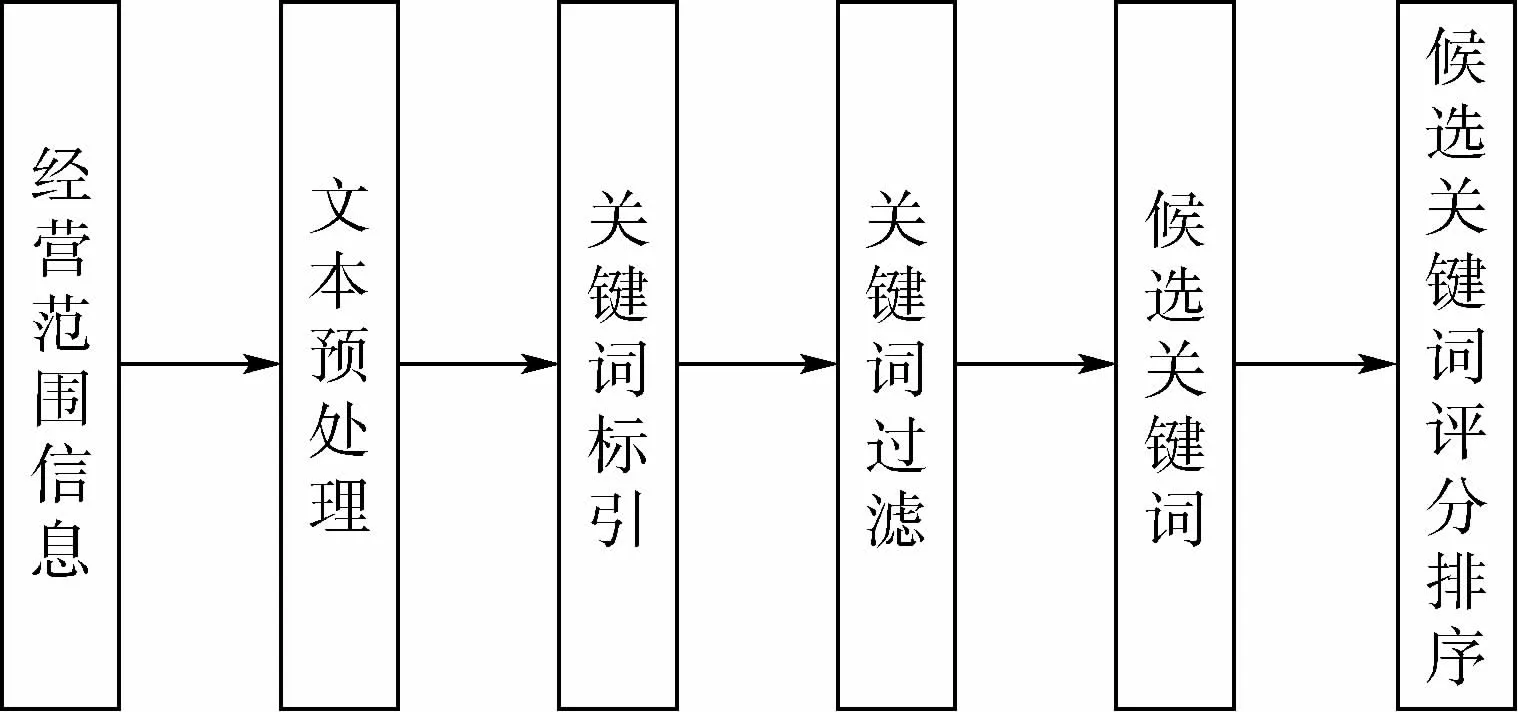
图1 分类识别流程Fig.1 Flowchart of classification and identification
2.3.2 基准分类算法
实验分别采取了Naïve Bayes、决策树、KNN、TextCNN等作为基准方法。
2.3.3 fastText算法
综合考虑经营范围数据的特征,本文基于fastText算法进行行业分类识别。fastText是facebook开源的一个词向量与文本分类工具[13-14],典型应用场景是“带监督的文本分类问题”,结合了自然语言处理和机器学习中最成功的理念。该算法只有隐层和输出层,模型简单,训练速度快,准确率较高。在普通的CPU上可以实现分钟级别的训练,比深度模型的训练要快几个数量级,同时,在多个标准的测试数据集上,fastText在文本分类的准确率上,与现有的一些深度学习的方法效果相当或接近。fastText使用词袋及n-gram袋表征语句,使用子词(subword)信息,并通过隐藏表征在类别间共享信息。另外,采用了一个Softmax层级(利用了类别不均衡分布的优势)来加速运算。
2.3.4 层次Softmax
对于有大量类别的数据集,fastText使用了一个分层分类器[15](而非扁平式架构)。不同的类别被整合进树形结构中。在某些文本分类任务中类别很多,计算线性分类器的复杂度高。fastText模型使用层次Softmax,对标签进行编码,能够极大地缩小模型预测目标的数量。
层次Softmax如图2所示。

图2 层次SoftmaxFig.2 Hierarchical Softmax
2.3.5 n-gram子词特征
fastText在用于网信企业名称分类时,使用的特征是词袋模型,同时,加入了n-gram特征,用于解决词语之间顺序的分类问题。每个词被看做是n-gram字母串包。为了区分前后缀情况,“<”、“>”符号被加到了词的前后端。除了词的子串外,词本身也被包含进了n-gram 字母串包。以where为例,n=3的情况下,其子串分别为<wh,whe,her,ere,re>,以及其本身。
2.3.6 fastText算法模型
fastText模型架构[16]如图3所示。

图3 fastText模型架构Fig.3 Architecture of fastTextmodel
图3展示了单个隐层的简单模型[17]。第一个权重矩阵A可以被视作某个句子的词查找表。将词表示平均成一个文本表示。文本表示是一个隐藏变量,然后将其送入一个线性分类器。该模型将一系列单词作为输入并产生一个预定义类的概率分布。本文使用Softmax函数f来计算预定义类的概率分布,对于一组包含N个文档的文档集,fastText模型目标是使式(1)最小化。

式中:n为样本个数;xn为第n个文档特征的标准化包(第n个样本的归一化特征,每个特征是词向量的平均值);yn为第n个样本对应的类别;f为损失函数Softmax;A为权重矩阵(构建词,embedding);B为权重矩阵(隐层到输出层)。因预测语料更偏向词语的组合,本实验中融入TF-IDF的先验特征,经验证显著提升了分类效果。
3 实验与分析
3.1 评价方式
本文采用精确率P、召回率R、F1值进行评估,具体计算公式如下:


式中:A为预测正确的正样本数;B为测试数据集中各个类的数目;C为预测结果中各个类的数量;F1为预测错位的负样本数。
3.2 实验数据
本文实验数据来源于政府公开API接口及互联网爬取数据。其中,公共API(北京市政务数据资源网、广东省政府数据统一开放平台、上海市政府数据服务网)和互联网爬取结果获取企业信息(如企业名称、企业法人、企业经营地址等企业信息)。获取到的数据在经过清洗整合后,保存企业名称等结构化数据,通过企业基本信息分析,获取对应企业经营范围。共使用了10万条数据,包括计算机制造、通信设备制造、广播电视设备制造、雷达及配套设备制造、非专业视听设备制造、智能消费设备制造、电子器件制造、电子元件及电子专用材料制造、电子信息机电产品制造、专用仪器仪表制造、其他电子设备制造等31个企业分类。以上数据根据获取平台划分为5个数据集DS1~DS5,以及1个测试集Test1,如表2所示。

表2 文本数量数据集样本Tab le 2 Text quantity dataset sam p le
3.3 实验环境
实验机器配置:操作系统Ubuntu 18.04.1 LTS,Intel(R)Xeon(R)Gold 6130 CPU@2.10 GHz,fastText在gcc 7.3.0上编译。
3.4 实验结果分析
为了验证fastText对企业分类的效果,本文使用DS1做训练集,使用Test1做测试集,n-gram使用的默认值为1,维度使用默认值为200,分类的准确率的宏平均值及所用时间如表3所示。
依据表3,本文实验基于fastText算法在8 s内完成80 000条数据的企业分类,精准率平均值达到83.1%,召回率平均值达到了80.5%,F1值平均值达到了81.8%,在网信行业分类方面达到了良好的效果。

表3 数据集的分类结果Table 3 C lassification resu lt of dataset%
4 结束语
针对目前企业分类效率及准确率较低的问题,本文以网信行业为例,使用fastText文本分类算法,探讨其在行业分类的适用性,经实验表明,基于fastText的行业分类识别准确率高(可达到82%以上),分类速度快,能够满足现有的行业分类需求。
