基于变分推理的网络舆情传播模式分类
2022-03-08唐红梅唐文忠李瑞晨王衍洋王丽宏
唐红梅,唐文忠,李瑞晨,王衍洋,王丽宏
(1.北京航空航天大学 计算机学院,北京 100083; 2.新疆维吾尔自治区科技项目服务中心,乌鲁木齐 830000;3.北京航空航天大学 航空科学与工程学院,北京 100083; 4.北航江西研究院,南昌 330096;5.国家计算机网络应急技术处理协调中心,北京 100029)
当前,随着网络信息量的激增,信息生态环境受到污染,公众获取、辨别和消化信息的能力较弱,容易受到不实信息的影响,产生错误的情感导向[1]。传统的舆情传播模式分析,主要集中在数学建模与历史数据挖掘,且多数基于统计学原理,缺少完整的舆情分析功能。随着知识图谱的发展,很多领域均引入知识图谱[2]。
图模型对舆情的传播过程进行建模,将舆情信息的扩散以节点和边的形式进行表示,能完整建模舆情事件在用户间的传播扩散过程,并根据需要动态添加用户间关注关系、舆情信息引用关系等信息,提升分析的效果。王晰巍等[3]基于社会网络分析法对舆情的传播过程进行建模,基于建立好的社会网络图,分析节点的入度与出度和节点的聚类情况,可以识别出传播过程中的关键用户。崔树娟等[4]基于多子网复合复杂网络模型构建多关系社交网络,将复杂系统中个体间的多种相互关系映射为向量空间的多维向量,并将复杂网络复合及分解转化为向量空间的基变换,从而为具有多种关系的复杂网络研究提供了新的解决方法。王兰成和娄国哲[5]在2018年基于知识图谱对涉军舆情进行了分析,提出了网络舆情知识图谱的舆情事件表达和处理引擎设计。马哲坤和涂艳[6]在2019年基于知识图谱进行了突发话题监测研究,发现基于知识图谱的话题监测相比于传统方法在准确率与召回率指标上有较大提升。基于知识图谱的舆情分析过程,就是舆情知识图谱的推理过程。Chen等[7]在2018年针对知识图谱链接预测提出的DIVA推理模型可以应用在舆情传播模式分类上,通过变分推理框架,综合之前基于路径推理与基于特征推理的优点,达到了更优的性能。受变分自编码器(VAE)[8](提出于2013年)的启发,DIVA模型在设计中使用变分自编码器结构完成了路径搜索与路径推理的结合。
通过对已有模型进行研究对比,发现在舆情事件传播模式分类任务中,由于数据规模庞大,生成的舆情事件图谱包含上百万的实体,且实体间关系非常复杂,对推理模型有极高的要求。
在公开数据集的测试中,DIVA模型针对较为简单的单一关系分类任务,只能对给定的2个实体在知识图谱中判断两者是否属于一种关系,并分别对属于与不属于2种情况给出概率。由于单独的路径搜索过程无法有效区分不同路径的质量高低,导致在复杂网络中难以找到高质量的连接路径,影响最终的识别正确率。因此,如何通过二分类模式由一个模型直接输出2种分类各自的概率,提升分类任务的正确率是本文的研究重点。
本文采用GraphDIVA模型进行舆情传播模式分类研究,从而降低了训练次数,提升了分类任务的准确性。
1 舆情传播知识图谱
1.1 G raphDIVA模型
GraphDIVA模型以变分推理DIVA模型为基础,从网络模型结构和计算过程2个维度进行分析,在路径推理模块中引入GraphSAGE算法,用于解决原模型缺少对于图结构特征的感知能力导致正确率下滑这一问题。GraphDIVA模型在生成路径特征矩阵时,引入GraphSAGE算法,对路径所在的子图结构进行采样并聚合,过程如图1所示。
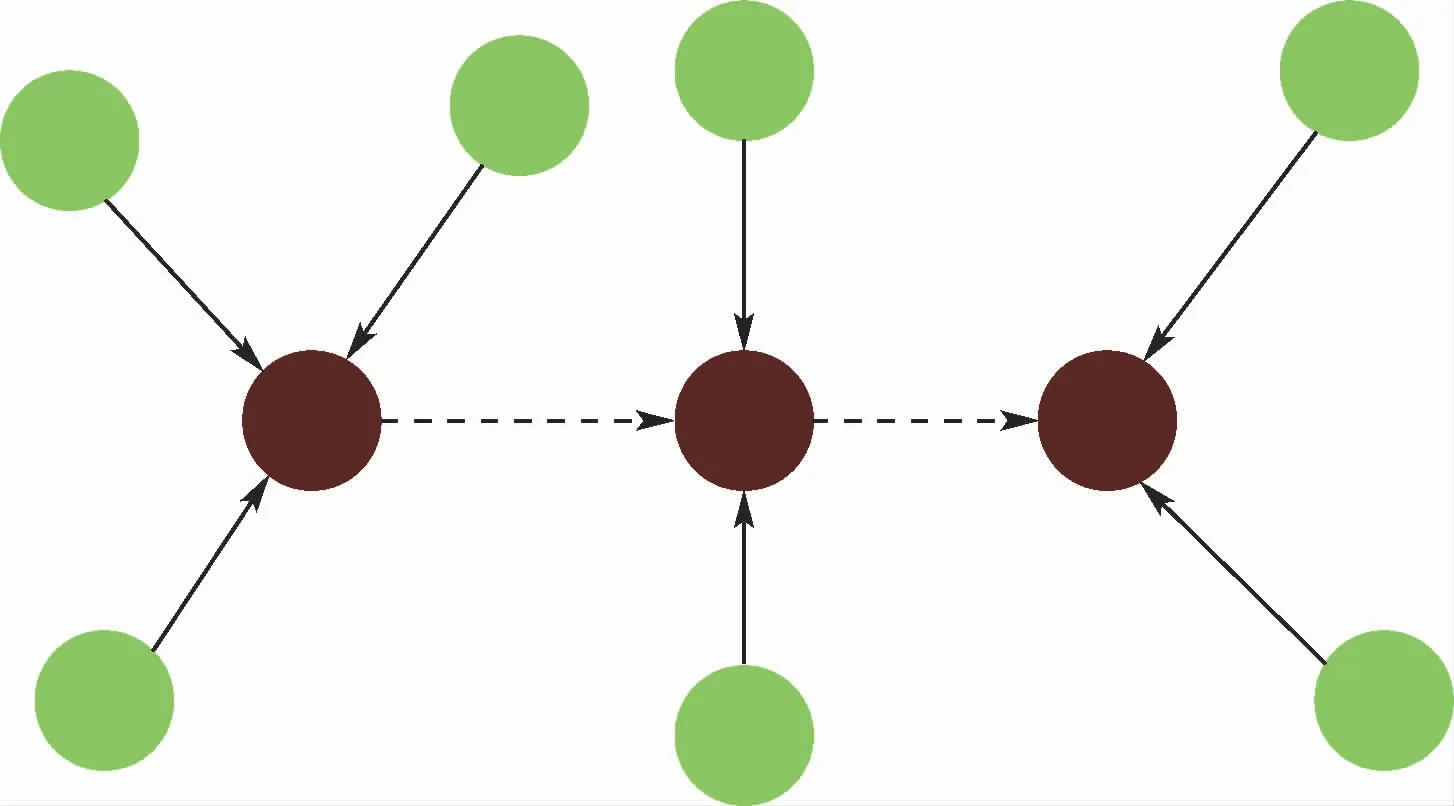
图1 GraphDIVA路径特征生成过程Fig.1 GraphDIVA path feature generation process
GraphSAGE算法是Ham ilton等[9]在2017年提出的对于图结构特征进行感知的算法,对于动态图结构拥有非常好的适应性。GraphSAGE算法认为一个节点的特征决定于周围节点,通过多轮采样聚合后便能得到最终的节点特征。同时,将特征的聚合操作定义为先从中心节点逐层向外扩散采样,再从最外层逐层向内聚合的递归过程,该方式可以解决图卷积神经网络(GCN)[10]弹性不足的问题。在使用卷积神经网络(CNN)窗口提取特征之前,先使用GraphSAGE算法对路径中的每个实体随机采样固定数据的数目与连接关系,再使用MaxPooling策略对采样到的嵌入向量进行聚合,得到路径实体与关系的特征表示。详细计算过程如下:
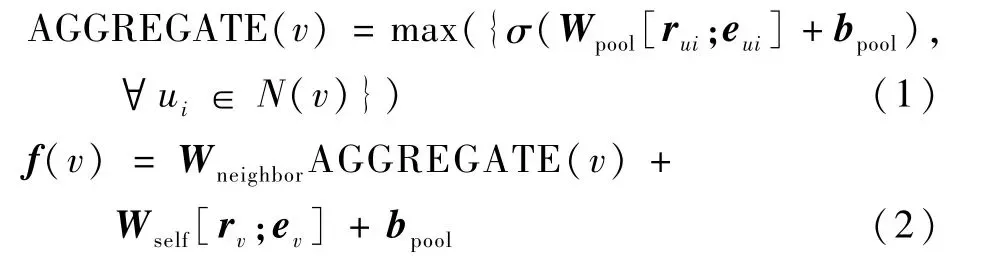
式中:[rv;ev]表示路径中某一步的关系嵌入向量与实体嵌入向量;N(v)为从路径实体出发随机选择多个邻接实体;[rui;eui]表示与路径实体邻接的实体与连接关系嵌入向量;f(v)为最终输出的针对路径中某一步的特征向量。
最终产生的路径特征矩阵由路径中的多步特征向量构成。
GraphDIVA路径推理模块结构如图2所示。
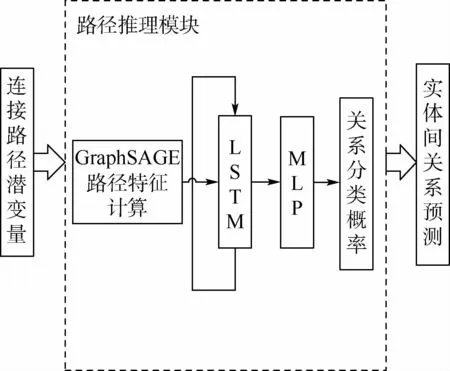
图2 GraphDIVA路径推理模块结构Fig.2 GraphDIVA path reasoning module structure
图2中:GraphSAGE路径特征计算过程与LSTM网络[11]为相对于原DIVA模型结构的变化。相比于原模型中使用的3个CNN 窗口,GraphSAGE算法使用LSTM 计算路径的次序特征,最终将LSTM 的输出向量作为路径的特征向量,如下所示:
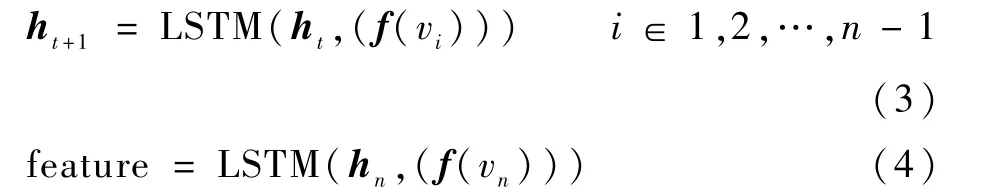
式中:h为LSTM 计算路径的每个时间步特征;v为图中的一个节点。
相比于原DIVA模型直接将输入路径中实体与关系的嵌入向量作为路径特征矩阵的做法,调整后的GraphDIVA模型先通过GraphSAGE算法识别路径中实体所在子图的结构特征,再利用LSTM提取路径的次序特征,大大提升了模型对图的感知范围与能力,从而解决了原模型中存在的正确率下滑等问题。
1.2 舆情图谱结构
与通俗意义上只注重建模领域概念的知识图谱不同,舆情知识图谱需要额外添加舆情的传播过程信息。娄国哲和王兰成[12]对基于知识图谱的网络舆情建模方法进行了研究,认为面向网络舆情的知识图谱中实体分为事件标签、事件主体、事件客体与事件传播方4类。事件标签为对事件本身的定性描述与分类;事件主体为事件内容涉及到的单位与个人,如机构、企业、明星等;事件相关客体描述事件的客观信息,如发生的地点、涉及到的时间等;事件传播方为舆情在传播过程中涉及到的用户、站点等。同时,知识图谱中的关系分为事件发起方与事件的关系、事件间的关系与事件传播关系。其中事件发起方与事件的关系包括发起、关注、参与等;事件间关系包括引发、有关、相似等;事件传播关系包括发表、评论、转发、点赞等。
本文主要研究舆情在微博用户间的传播过程,不关注舆情事件的概念、涉及到的主体与时间地理因素,因此本文定义的舆情传播知识图谱的实体与关系在上述模型的基础上进行了大幅精简与调整。实体包含关键词、博文、评论、用户与话题5类,关系分为包含关键词、转发、评论、用户创建、提及话题5类。
对于用户的转发行为,舆情传播知识图谱的建模三元组如下所示:
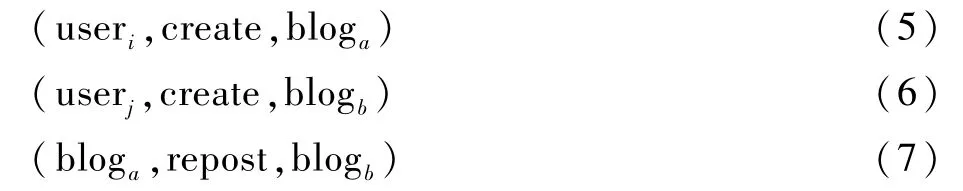
式中:user表示用户;blog表示博文。
首先,需要建立2个由用户指向各自创建的博文的三元组,然后,建立由被转发博文指向转发博文的三元组。
对于用户的评论行为,舆情传播知识图谱的建模三元组如下所示:
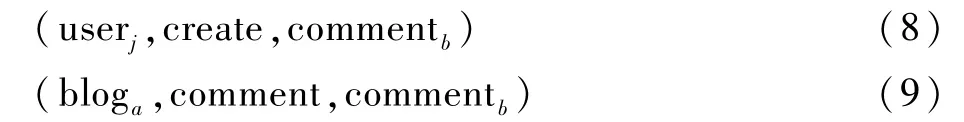
式中:comment表示用户评论。
与转发行为类似,首先,需要建立从用户指向创建的评论的三元组,然后,建立由被评论博文指向评论的三元组。
对于博文与关键词的对应关系,舆情传播知识图谱的建模三元组如下所示:
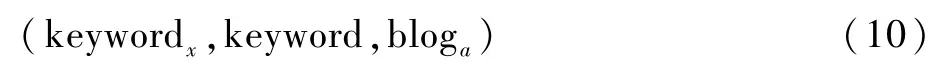
式中:keyword表示博文的关键字。
对于博文与话题标签的对应关系,舆情传播知识图谱的建模三元组如下所示:

式中:tag表示博文的标签。
在进行舆情事件的划分时,直接使用关键词作为划分标准。如果从不同的实体出发,最终能到达相同的关键词实体,则认为这些实体都属于同一个舆情事件。
1.3 数据采集与处理
本文选择新浪微博官方热搜排行榜中热门的新闻类与娱乐类话题,提取核心关键词作为后续搜索内容的基础,每隔3~5天,根据热搜排行榜的变化,更换核心关键词,扩大舆情的搜索范围,获得最原始的舆情数据。
确定关键词后,以微博搜索作为入口,通过关键词对有关微博内容进行搜索,并按照热度提取排名前10的结果。对于每一篇微博,按热度获取热门评论与热门转发,再根据热门转发链接完成转发关系的递归获取操作。同时,在解析页面时,记录当前页面与上一个页面的链接,从而方便从结果中重建正确的微博转发关系。
本文研究数据来源于微博,时间段为2019年9月28日至2019年11月4日。数据结果类型包括数据数量、博文转发量、博文传播地位、博文话题标签、评论点赞量、话题标签数据、关键词出现次数和舆情传播深度等,详细数据结果如表1所示。博文数据的分布状况如表2~表4所示。

表1 数据数量统计Tab le 1 Data quan tity statistics
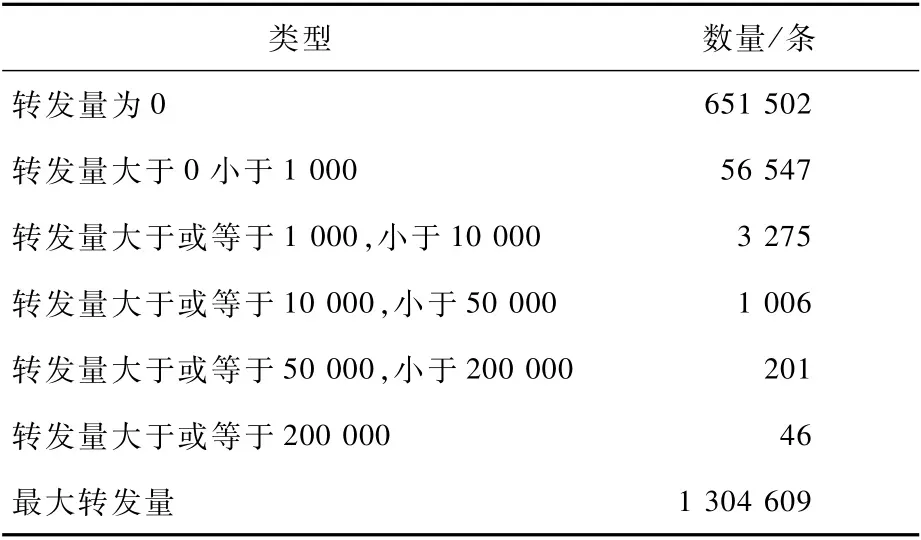
表2 博文转发量统计Tab le 2 Blog post forward ing quantity statistics

表3 博文传播地位统计Tab le 3 Statistics of propagation status of blog posts

表4 博文话题标签统计Tab le 4 B log post hashtag statistics
评论数据的分布状况如表5所示。话题标签数据的分布状况如表6所示。关键词数据的分布状况如表7所示。舆情传播深度与广度分布如表8所示。

表5 评论点赞量统计Tab le 5 Statistics of the am ount of likes

表6 话题标签数据统计Tab le 6 Hash tag data statistics

表7 关键词出现次数统计Tab le 7 Statistics of keyword occurrence tim es
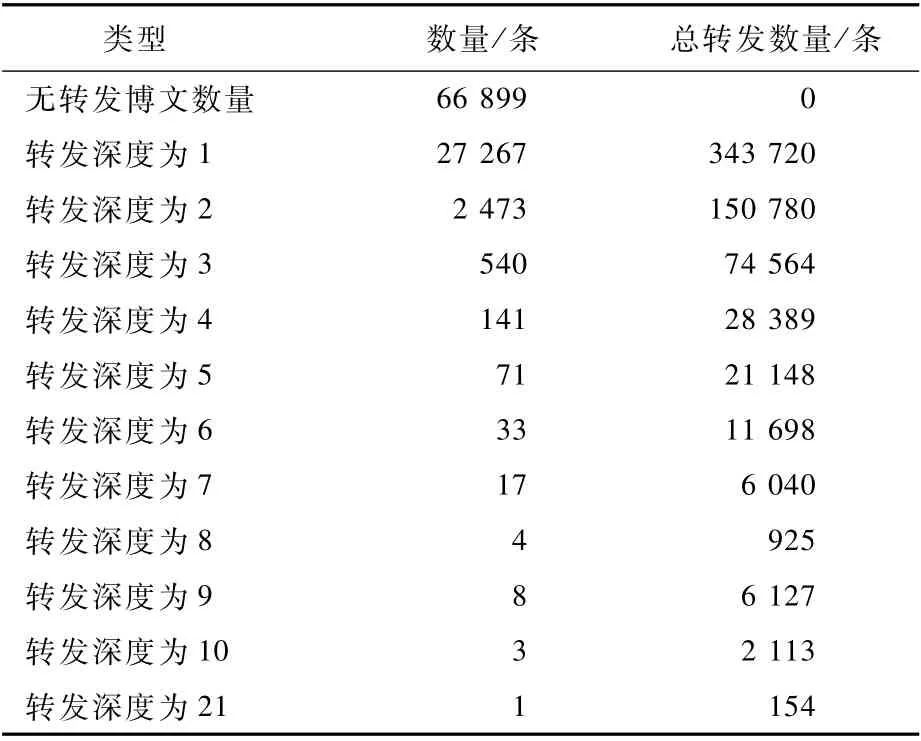
表8 舆情传播深度统计Tab le 8 Statistics of pub lic opinion p ropagation dep th
通过对以上统计数据进行分析可以看出,本文建立的舆情传播图谱覆盖范围广泛,不仅包含丰富的热门话题种类,而且还有效保留了舆情的原始传播过程,可以充分支撑舆情传播模式分类研究工作。
2 基于变分推理的传播模式分析
2.1 传播模式
对于舆情在用户间的传播特性,领域中已有大量的研究成果。刘继和李磊[13]在2013年就针对微博的舆情传播过程对用户间的传播模式特点进行了分析。本文中将舆情的传播关系网划分为单关键点型、多关键点型与链式型3种基本模式,结构示例如图3所示。
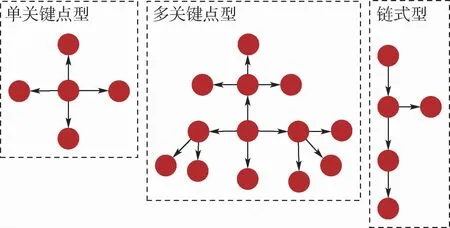
图3 微博舆情信息传播基本模式示例Fig.3 Example of basic pattern of Weibo public opinion information propagation
单关键点由一个中心用户与大量粉丝用户组成。中心用户往往在小范围社区内有非常高的人气,多为某一特定领域的“大V”;粉丝用户对于中心用户有极高的信任与热情,大多会在第一时间转发相关舆情内容。在这种模式中,中心用户对于舆情事件的爆发有较强的控制力,能把握住舆情的走向节奏,但是最终的传播规模也往往只局限在某个小圈子里,缺少大规模传播的潜力。
多关键点由交换用户、多个中心用户与大量不同领域的普通用户组成,相当于多个单关键点的复合结构。交换用户为多关键点型的核心节点,类似于沟通不同领域的中央交换机,拥有与大量不同领域中心用户的紧密关系,能够发动多个“大V”传播自己的观点;与此同时,多个中心用户可以通过交换用户实现信息互动,增强对不同领域的传播能力。由于交换用户的存在,多关键点在传播时相比于单关键点型的覆盖范围大大延伸,往往能形成影响非常巨大的舆情事件。
链式与单关键点及多关键点在构成上有较大的差别。单关键点与多关键点总体上属于中央式结构,能将节点分为主从2种;而链式则更类似分布式结构,各个节点的地位大体是均等的。链式结构往往出现在有较强针对性的舆情传播过程中,波及到的用户也常常属于相近的社交圈。由于链式传播的路径与生命周期较长,容易造成舆情的演化与扭转,并引发新的舆情传播热点。
实际舆情事件中,以上3种传播模式不会以单独的形式存在,而是产生大量的混合型结构。一种常见的情况是先由普通网民发起链式传播,之后被“大V”发现后转变为多关键点模式。
2.2 任务定义
知识图谱推理任务是指基于三元组进行推理的模型。对于任意一个知识图谱,包含实体集合ε与关系集合R。知识图谱的结构则可以(es,r,ed)的三元组进行表示。以舆情传播知识图谱为例,用户A与用户B表示为实体euser_a和euser_b,用户B转发用户A消息的操作表示为关系rrepost,舆情 的 扩 散 则 可 用 三 元 组 描 述 为(euser_a,rrepost,euser_b)。推理任务基于部分残缺的三元组,推测可能的答案。推理任务的三元组可能缺少关系(es,?,ed),也可能缺少实体(es,r,?),对应了链接预测与实体预测2种子任务。本文基于舆情传播模式分析的场景,更关注于链接预测[14],也就是推测用户A与用户B间可能存在的联系,作为舆情传播模式的划分依据。原始的DIVA模型针对较为简单的单一关系分类任务,只能对给定的2个实体在知识图谱中判断两者是否属于一种关系,并分别对属于或不属于2种情况给出概率。本文研究的重点是:基于对原模型改进后的GraphDIVA模型,在进行推理任务分析时,通过二分类模式由一个模型直接输出2种分类各自的概率,提升分类任务的准确性。GraphDIVA模型的路径搜索过程对应了传播模式分析中舆情的核心传播过程路径的构建,而路径推理过程则对应了以核心传播路径为主干的传播关系子网的传播模式特征识别。
2.3 训练过程
原始的舆情传播知识图谱中只包含单向的传播关系,因此,在进行传播路径搜索与特征聚合时也只能单向进行,无法进行传播溯源、邻居特征聚合等操作。因此,训练与测试数据集的搭建参考了文献[15]中建立NELL995数据的过程。

建立数据集时,本文在原始知识图谱的基础上为每个三元组都创建了对应的反向关系三元组。
原始的DIVA模型与GraphDIVA模型只能对关系进行分类判断,因此,需要将传播模式对应为舆情事件中起点微博与端点微博之间的关系。本文定义的新闻类与娱乐类2种舆情传播模式分别建立了political与entertainment两类传播模式关系,并在始发舆情与转发舆情间建立对应的关系三元组作为训练与测试数据。
由于在搜集舆情时是通过关键词获取信息的,可以直接以关键词作为样本划分的依据。之后,对每类关键词中转发深度大于1的始发博文搜索位于最深转发位置的转发博文并保存传播路径。如果转发深度大于5,则只搜索深度为5的博文,尽量减小深度差别带来的数据偏差。最终,本文构建了包含18 633个样本的数据集。样本的详细分布状况如表9所示。

表9 样本分布状况Table 9 Sam p le distribution status
另一个与传统知识推理任务的差异,是舆情传播模式分析任务只关心从某个始发微博诞生的传播关系网属于哪种传播类型,而不关注于始发微博与某个中间转发微博之间属于哪种传播类型。因此,模型只在预训练阶段关注传播路径,保证路径搜索模块的基本搜索能力。之后的训练与测试过程不再对路径的终点进行检查,直接进入路径分类模块计算分类概率。实际上,路径搜索模块在本任务中的作用更类似核心传播路径的分析与生成,而路径推理模块则对应了图数据的结构分类功能。
3 实验结果及分析
本节针对舆情传播分类任务,完成了Graph-DIVA模型和DIVA模型在不同训练样本中的传播模式分类正确率的对比实验。通过实验表明,本文方法针对小样本进行分类时,用较少的训练次数达到了较高的正确率。
3.1 实验参数
本文在生成传播图谱的嵌入向量时,使用了Fast-TransX[16]项目中的TransE实现。项目的代码由C++编写,同时,从算法层面针对多线程运行进行优化,运行时只占用极少的内存。Fast-TransE编码器编码参数如表10所示。表中:embedding_size表示最终生成的嵌入向量宽度;nbatches表示每轮迭代的批数量;threads表示生成时使用的线程数;epochs表示迭代次数;alpha表示生成时的学习速率。

表10 Fast-TransE参数Tab le 10 Fast-T ransE param eters
DIVA模型与GraphDIVA模型在进行传播模式分析任务训练时的规模与参数如表11和表12所示。

表11 传播模式分析网络参数Tab le 11 Propagation pattern analysis network param eters
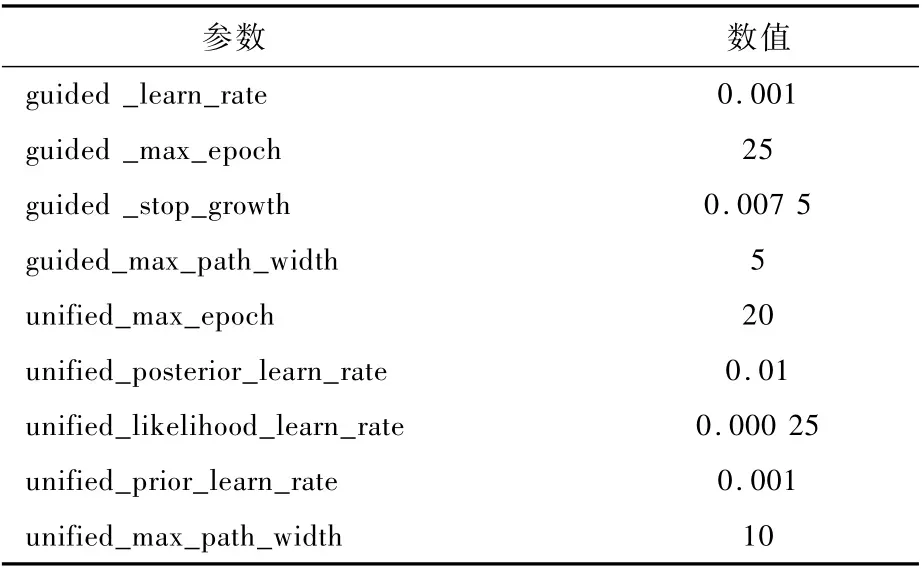
表12 传播模式分析训练参数Tab le 12 Propagation pattern analysis training param eters
为了加快训练与测试速度,在训练时,先对训练样本进行随机排序,再选择前100个样本作为训练集;测试时,进行同样的随机排序操作,并选择前500个样本作为测试集。另外,为了突出GraphDIVA模型相比于原模型的性能提升,实验中额外测试了2个模型在前25个样本中进行训练后的性能表现。
3.2 实验结果
本文使用DIVA模型与GraphDIVA模型运行相同的数据并对比最终效果。100个训练样本的实验结果如图4所示。结果显示,利用知识图谱与变分推理模型进行舆情传播模式分析是非常有效的一种技术方案,2种模型使用100个训练样本在经过4轮训练后即可达到90%的分类正确率。GraphDIVA模型相比于原始DIVA模型分类正确率从93%提升到95%,并且在训练10轮后就达到了最高正确率;相比之下,DIVA模型则需要20轮训练才能达到最佳效果。
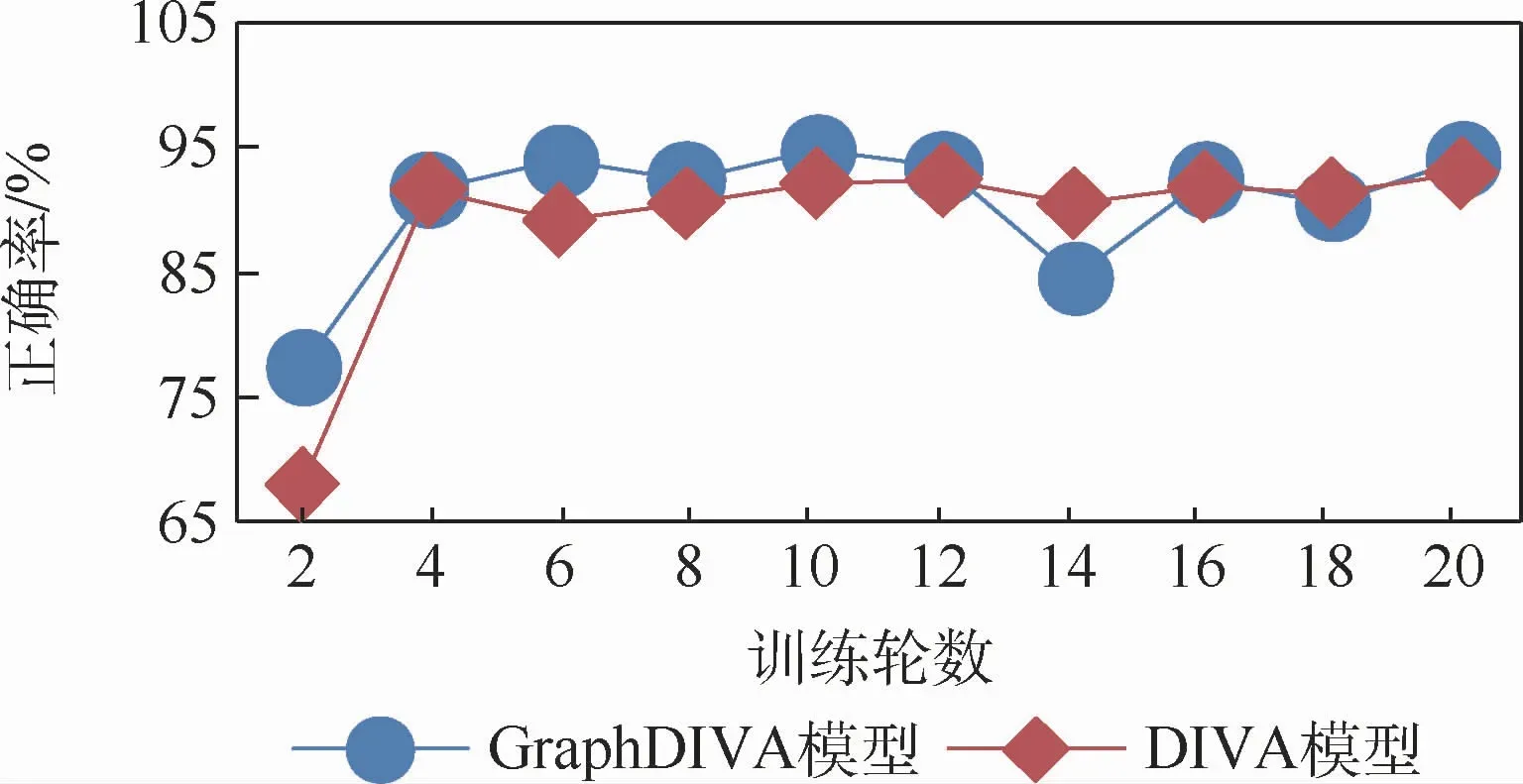
图4 舆情传播模式分类100样本测试结果Fig.4 100 sample test results of public opinion propagation pattern classification
25个训练样本的测试结果如图5所示。结果显示,GraphDIVA模型在经过20轮训练后就能达到89.4%的正确率,而DIVA模型只有76%,实验表明GraphDIVA模型在减少训练次数、提升分类正确率方面具有更优的效果。
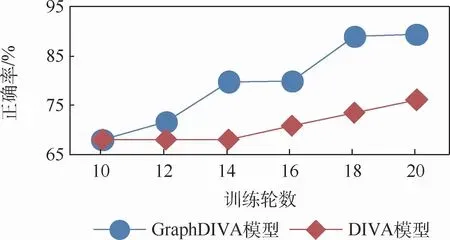
图5 舆情传播模式分类25样本测试结果Fig.5 25 sample test results of public opinion propagation pattern classification
为了展示舆情分析模型的分析过程与效果,实验选取了“无锡高架桥坍塌”与“永不消逝的电波”2个舆情事件作为新闻类与娱乐类传播模式的案例,分析后的结果分别对应图6与图7,图中加粗的连接线表示模型识别出的核心传播路径。可以看出,虽然转发深度都是9层,模型从“无锡高架桥坍塌”的传播图谱中识别到的核心传播路径多样性强于“永不消逝的电波”,且核心传播路径周边的传播子图结构特征有很大的差别,在路径末端仍能找出多关键点模式的结构,该实验体现了变分推理模型先构建核心传播路径,再对传播子网特征进行识别的分析流程的有效性。
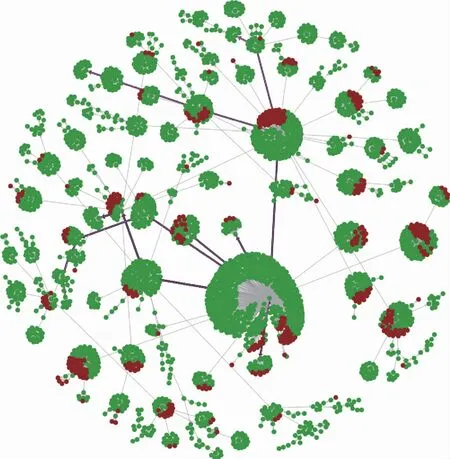
图6 新闻类案例分析结果Fig.6 News case analysis results
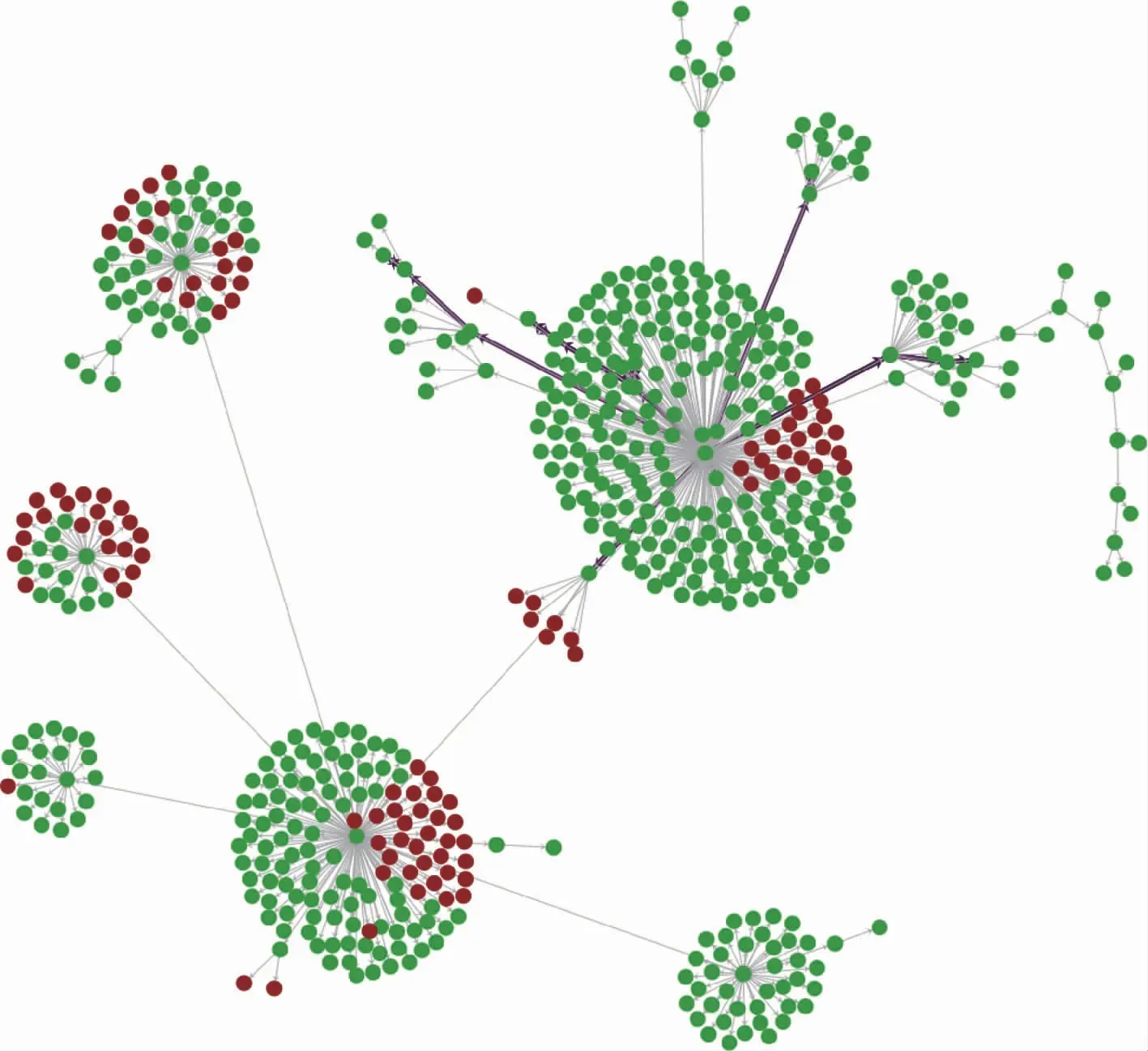
图7 娱乐类案例分析结果Fig.7 Entertainment case analysis results
4 结 论
1)针对舆情传播分析任务场景,提出了舆情传播领域知识图谱结构定义,使用微博数据搭建了舆情传播知识图谱与舆情传播分析任务数据集。
2)使用GraphDIVA模型进行舆情传播模式分类,围绕分析任务设计训练过程,并在自建数据集中完成了GraphDIVA模型和DIVA模型模式分类100样本和25样本测试的对比实验。Graph-DIVA模型能有效降低训练次数,提升分类的正确率,特别是在25样本测试中,模型在经过20轮训练后,分类正确率从76%提升到89.4%。
综上所述,使用GraphDIVA模型进行传播模式小样本分类时,在减少训练次数、提升分类正确率方面具有更优的效果。
