新疆两种亚麻籽转录组分析及籽油香气差异基因挖掘
2022-02-16杨佳玮李欢康林雨霏刘文玉魏长庆
杨佳玮,李欢康,林雨霏,刘文玉,魏长庆
(石河子大学食品学院,新疆植物药资源利用教育部重点实验室,新疆 石河子 832000)
亚麻(Linum usitatissimumL.)是我国重要的经济农作物[1]。亚麻籽是亚麻的种子,富含不饱和脂肪酸、木酚素、酚酸、植物甾醇、生育酚、类黄酮等多种营养成分[2-4],对心血管疾病[5-6]、糖尿病[7]、高血压[8]、高血脂[9]、抑制癌症[10-12]等均具有有益作用。亚麻全籽含油量约达40%[13],其籽油因其特殊浓郁的香气和丰富的营养成分,备受消费者青睐。
转录组学是一门研究细胞中基因转录情况以及转录调控规律的学科,细胞中的转录组因其细胞的生长发育、细胞所处的环境而异[14-15]。转录组测序技术是基于Illumina HiSeq等测序平台对特定组织或细胞某个时期转录出来的所有mRNA进行测序[16],具有通量大、低成本、高分辨率、高灵敏度、检测范围广、不需克隆且操作简单等优点[17],是研究生物过程与分子机制的重要手段。近年来,转录组测序技术在农作物基因挖掘方面的运用很广泛,以Illumina HiSeq 2000测序平台为例,此项技术已在辣椒[18]、核桃[19]、花生籽仁[20]、大豆[21-22]、火龙果[23]中成功应用,为研究农作物基因功能提供大量的转录本信息,成为模式和非模式植物功能基因挖掘[24-26]的有效工具。
新疆作为中国亚麻的六大产区之一,培育出了很多品种,包括伊亚-1号、伊亚-3号(YY-3)、伊亚-4号、陇亚-7号、陇亚-8号、天亚-6号(TY-6)等系列品种,各个品种亚麻籽油香气具有明显差异。课题组前期对YY-3和TY-6品种的亚麻籽油挥发性香气进行定性定量测定,发现2个品种挥发性香气差异较大,其中醛类挥发性化合物含量及种类差异明显,且TY-6亚麻籽油的醛含量(66.15%)显著高于YY-3样品(52.27%)[27]。基于此,本研究以亚麻籽为研究对象,选取新疆2个特色亚麻籽品种YY-3和TY-6进行转录组测序和分析,旨在从分子角度挖掘亚麻籽油香气差异形成关键基因,并为新疆亚麻品种育种及籽油的香气改良提供理论依据和技术支撑。
1 材料与方法
1.1 材料与试剂
2个新疆亚麻籽品种YY-3、TY-6均来源于新疆伊犁雅琪娜公司。于亚麻籽成熟之际采集,用冰袋冷藏运回石河子大学食品学院,经液氮速冻后存于-80 ℃冰箱,用于RNA提取。
1.2 仪器与设备
TG16-WS台式高速离心机 湘仪离心机仪器有限公司;2100生物分析仪 美国安捷伦公司;NanoDrop 2000超微量分光光度计 美国热电公司。
1.3 方法
1.3.1 RNA的提取与样本检测
将采集的样品使用植物总RNA提取试剂盒提取亚麻籽总RNA,并通过NanoDrop 2000超微量分光光度计检测RNA的浓度和纯度,采用琼脂糖凝胶电泳分析RNA质量,采用2100生物分析仪检测RNA的完整性,以保证后续实验结果的可靠性。
1.3.2 序列测序组装
将质检合格后的RNA利用高通量测序平台(Illumina HiSeq 2000)进行测序。将下机原始数据(raw reads)进行碱基质量、碱基错误率和碱基含量统计评估后,进一步进行质量控制,去掉reads中的接头序列、低质量的reads,得到clean reads进行后续分析[28],统计其数量使用Q30等指标对数据进行质量评估。用Trinity软件对所有clean reads进行从头组装得到大量转录本,取每条基因中最完整的转录本作为unigene,并对其进行优化过滤,且对组装结果进行质量评估。
1.3.3 unigene的注释、功能分类和生物学通路分析
将2个亚麻籽品种转录组测序获得的所有unigene利用BLAST软件将基因注释到非冗余蛋白(Non-Redundant Protein,NR)、直系同源群集(Cluster of Orthologous Group,COG)、基因本体(Gene Ontology,GO)和京都基因与基因组百科全书(Kyoto Encyclopedia of Genes and Genomes,KEGG)数据库,并对获得的注释情况及功能信息进行统计。
1.3.4 差异表达基因(differentially expressed genes,DEGs)的筛选及分析
使用TPM(transcripts per million)法估算基因表达水平,然后根据模型进行假设检验概率(P值)计算,最后进行多重假设检验校正。按照|log2(YY-3/TY-6)|>1(YY-3/TY-6表示差异倍数,下同)且错误发现率(false discovery rate,FDR)<0.05的原则筛选DEGs。利用比对软件将筛选出的DEGs进行GO分类以及KEGG通路分析。
1.4 数据处理
两个品种均进行3 次独立生物学重复实验。利用Excel 2007、Origin 8、SPSS 16.0等软件对实验数据进行统计分析及图像处理。FastQC软件进行测序数据质量控制,CutadaptVersion 1.2.1去除3’端的接头序列,Trinity软件进行转录组de novo组装,DEGSeq分析表达差异unigene。
2 结果与分析
2.1 测序数据及比对结果统计
对YY-3、TY-6亚麻籽进行转录组测序共得到68 221 320 条raw reads,对其进一步过滤得到61 995 756 条高质量的clean reads(表1)。其中Q20分别为98.80%和98.79%,Q30分别为96.73%和96.68%,Q20和Q30值越高说明测序错误越小,GC含量占总碱基数的52%和53%,说明这两种新疆特色亚麻籽转录组的测序质量较高,可用于de novo组装和后续分析。

表1 两种亚麻籽转录组测序数据统计Table 1 Data statistics of transcriptome sequencing of two flaxseed cultivars
将测序reads与参考数列进行比对得到各个样品的匹配率(表2)。两种亚麻籽比对到的reads占比均在90%以上,说明参考基因组选择较为合适,且数据结果适用于后续基因的功能注释和基因挖掘。

表2 两种亚麻籽序列比对统计Table 2 Statistics of sequence alignment of two flaxseed cultivars%
2.2 基因注释结果分析
利用String Tie软件结合de novo进行转录本重构,将组装好的转录片段与参考基因进行比较合并,将2个亚麻籽品种转录组测序获得的所有unigene通过BLAST软件与NR、COG、GO、KEGG数据库进行比对,对所有注释上的unigene进行分析。由表3可知,获得注释的unigene共有33 218 条。其中GO数据库注释比例最高,共注释了17 542 条(52.81%)unigene;COG和NR数据库其次,分别占unigene总数的51.99%和47.63%,KEGG数据可注释比例最低,仅有10 713 条(32.25%)unigene被注释。

表3 亚麻籽转录组功能注释Table 3 Functional annotation of flaxseed transcriptome
2.3 unigene的NR注释
将33 218个unigene注释到NR数据库,共有15 821个unigene注释到NR数据库,占总unigene的47.63%。
从匹配序列的相似度分布(图1a)可见,有28.61%序列的相似度大于80%,26.43%序列的相似度在70%~80%之间,有41.79%序列相似度在40%~70%之间,仅有3.17%的相似度在40%以下。从E-value分布(图1b)可见,有62.01%的E-value分布在0~10-100之间;有9.12%的E-value分布在10-80~10-60之间。其中E-value越小说明匹配结果的可靠性越高。从注释匹配的物种分布(图1c)可见,排在前5 位的物种分别为麻风树(Jatropha curcas,27.97%)、蓖麻(Ricinuscommunis,13.67%)、毛果杨(Populustrichocarpa,11.20%)、胡杨(Populuseuphratica,10.85%)和可可树(Theobroma cacao,4.23%)。其中注释到麻风树的基因数量最多,说明亚麻籽转录组测序组装的unigene与麻风树的相似性最高。由于亚麻籽的全部基因组信息尚未被报道,所以本研究中部分unigene在NR数据库中无法和已知基因匹配,这些unigene可能包含了亚麻籽与其他物种不同的、自身所特有的基因序列。
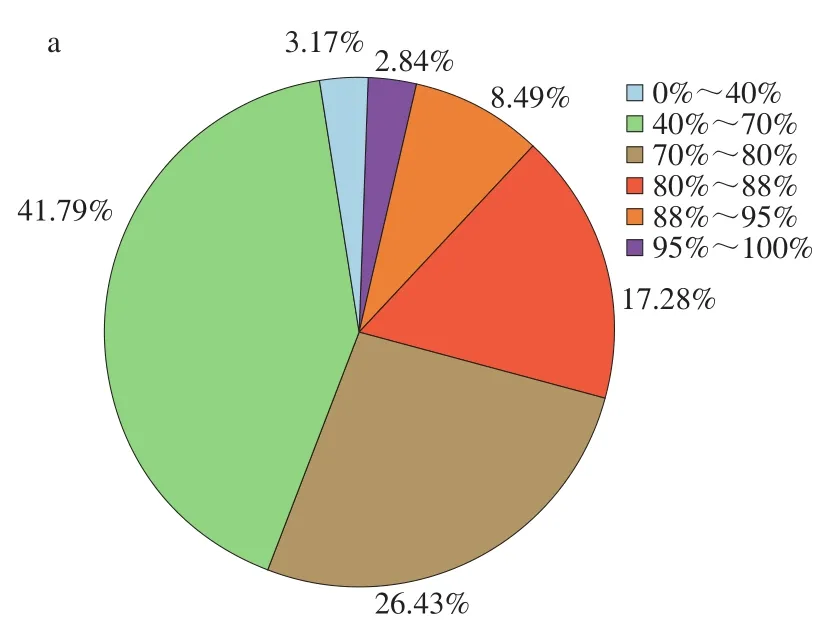
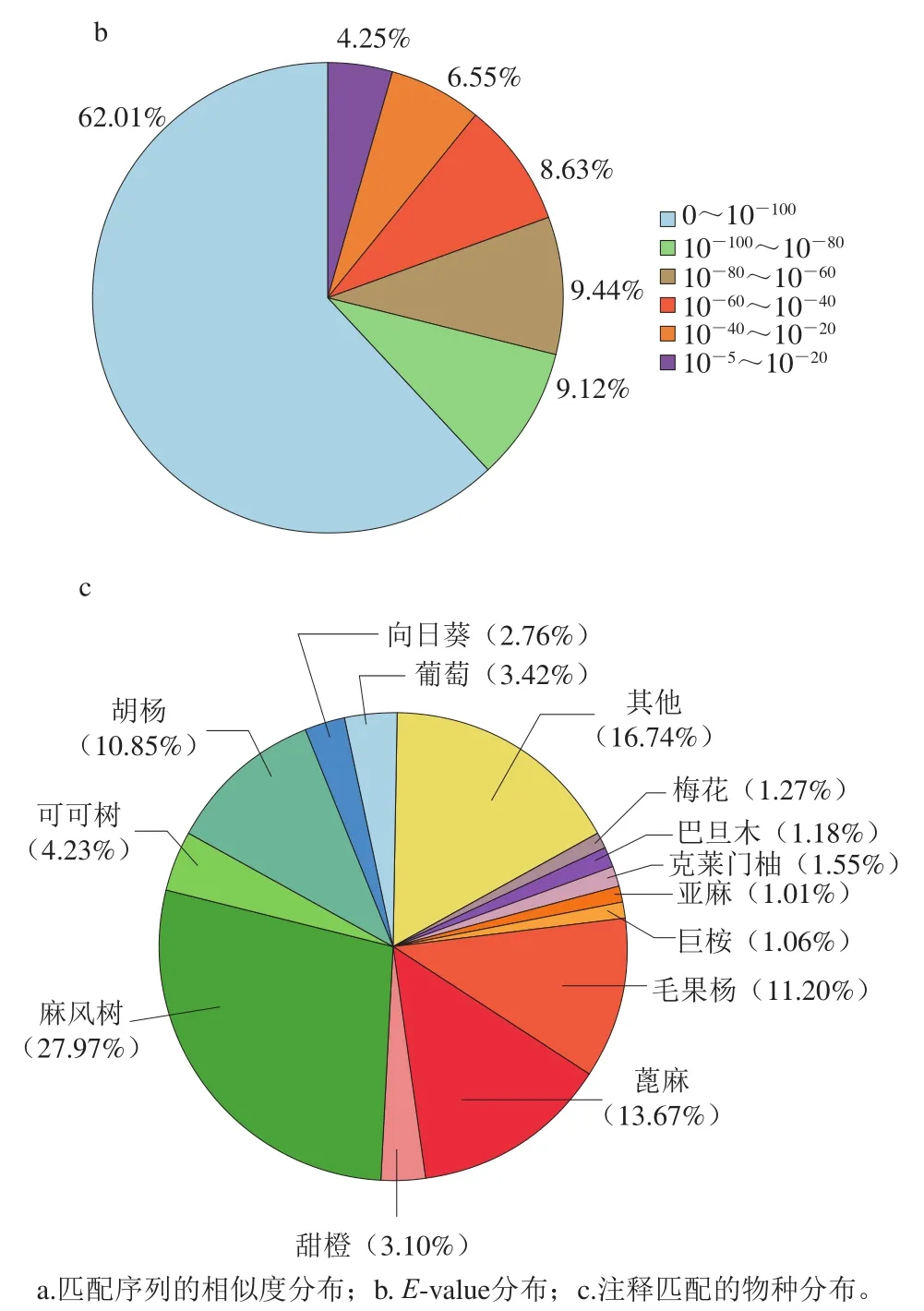
图1 亚麻籽unigene的NR注释分类Fig. 1 Annotation classification of flaxseed unigene via NR
2.4 unigene的COG注释
将unigene注释到COG数据库,根据结果对unigene的功能进行分类并统计注释unigene数目(图2)。结果表明,有17 269 个unigene注释到COG数据库,占总注释到unigene的51.99%,此数据库将基因注释到3 大类,包括细胞过程和信号、信息存储与处理、代谢。22个各功能类的基因注释数目有明显差异,其中翻译后修饰、蛋白质折叠和分子伴侣最多,占15.48%;其次是转录占10.90%,细胞内运输、分泌和囊泡运输占比为9.91%,信号转导机制占比8.87%,翻译、核糖体结构和生物合成占比8.74%,复制、重组和修复占比6.77%,其余均在5%以下。细胞运动和核结构类别中注释基因最少,均为0.14%。
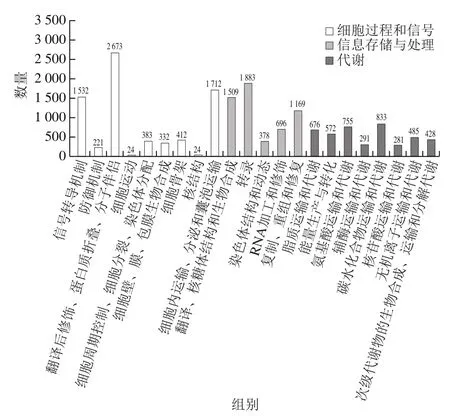
图2 亚麻籽unigene的COG注释分类Fig. 2 Annotation classification of flaxseed unigene via COG
2.5 DEGs分析
2.5.1 基因表达水平对比

图3TPM盒形图Fig. 3 TPM box chart
为进一步分析基因表达差异情况,本研究引入TPM计算基因表达量。图3为2个样品的TPM盒形图,可以看出两组亚麻籽品种基因表达之间的差异。两组数据分散程度基本相同,YY-3的中值较大,说明相较TY-6,它的整体表达量较高。
2.5.2 DEGs筛选及聚类分析
根据条件|log2(YY-3/TY-6)|>1且FDR<0.05,YY-3亚麻籽样品相比较TY-6亚麻籽样品共得到1 658个DEGs,其中上调基因825个,下调基因833个(图4)。红色点的纵坐标值均较大,说明这些上调基因的表达量变化差异较为显著。
图4 两种亚麻籽DEGs火山图Fig. 4 Volcano diagram of DEGs between two flaxseed cultivars
2.5.3 DEGs GO富集分析
对亚麻籽unigene采用interproscan-5.8-49进行注释。两个不同品种亚麻籽筛选出的DEGs进行GO富集分析,将其分为3 大类33个分支(图5)。第一层次的GO Term由细胞组分、生物过程和分子功能三大类构成。其中,归属生物过程的GO条目最多(13个)。生物过程中两组亚麻籽DEGs主要集中在代谢过程、细胞过程和单有机体过程。在细胞组分中,以细胞、细胞部分和膜3个亚类为主。在分子功能中注释信息最多的两个功能亚类是结合和催化活性。从图5可以看出,由于品种不同,导致催化活性等均不同,所以细胞和细胞部件、膜等具有差异,从而导致了两组亚麻籽代谢过程、细胞过程和单有机体过程的差异性。
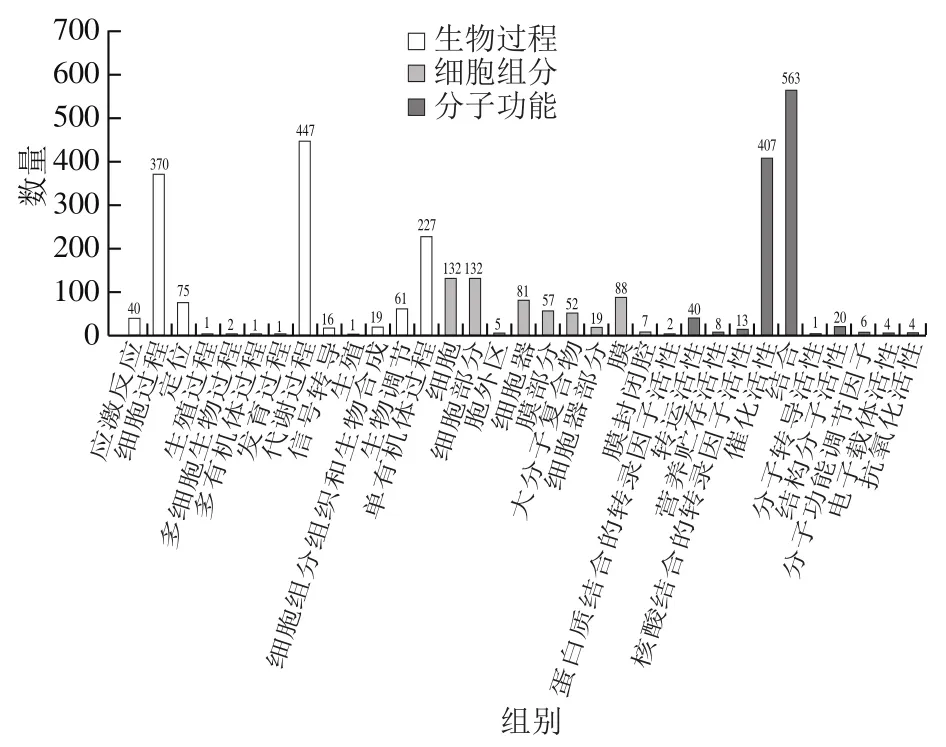
图5 DEGs的GO注释分类Fig. 5 Annotation classification of differentially expressed genes via GO
2.5.4 DEGs KEGG富集分析
KEGG是基于分子水平信息,特别是大型分子数据集合而生成的基因组测序数据库和其他高通量实验得出的数据库资源,是一个有关通路的主要公共数据库[29],可用于进一步研究基因的复杂行为。根据KEGG数据库对两个不同品种新疆亚麻籽进行功能分类和通路注释。380 个DEGs被注释到108 条代谢途径,对DEGs进行KEGG通路富集分析,获得两种亚麻籽DEGs富集的代谢途径(图6)。
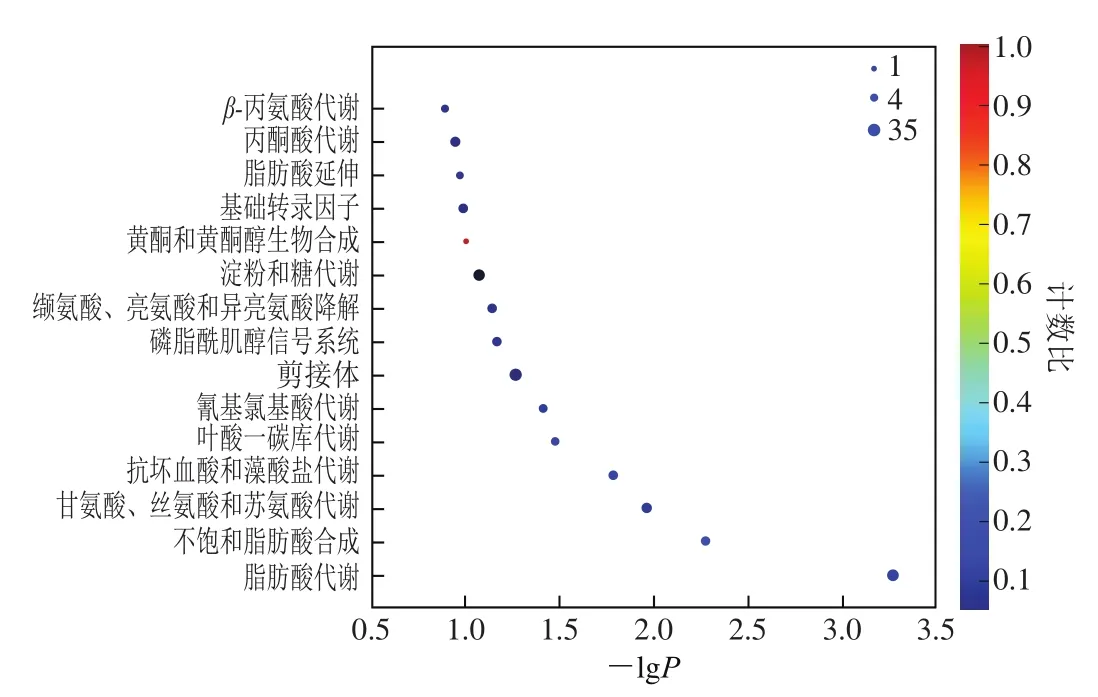
图6 DEGs KEGG富集散点图Fig. 6 KEGG enrichment scatter plot of DEGs
利用散点图形式表现KEGG富集程度,计数比为某功能类别中差异表达数与所有功能类别中注释到的DEGs数的比值,取值范围为(0,1)。结果表明,两种亚麻籽DEGs主要富集到脂肪酸代谢,不饱和脂肪酸合成,甘氨酸、丝氨酸和苏氨酸代谢,抗坏血酸和藻酸盐代谢,叶酸一碳库代谢等。
2.5.5 脂质代谢途径相关DEGs分析
由KEGG富集程度分布图可知,富集程度最高的前2个KEGG条目为脂肪酸代谢和不饱和脂肪酸合成。其中在脂肪酸代谢中注释到17个DEGs,在不饱和脂肪酸代谢中注释到了8个DEGs,对其分别进行聚类分析(图7、8)。

图7 脂肪酸代谢相关DEGs热图Fig. 7 Heatmap of DEGs related to fatty acid metabolism
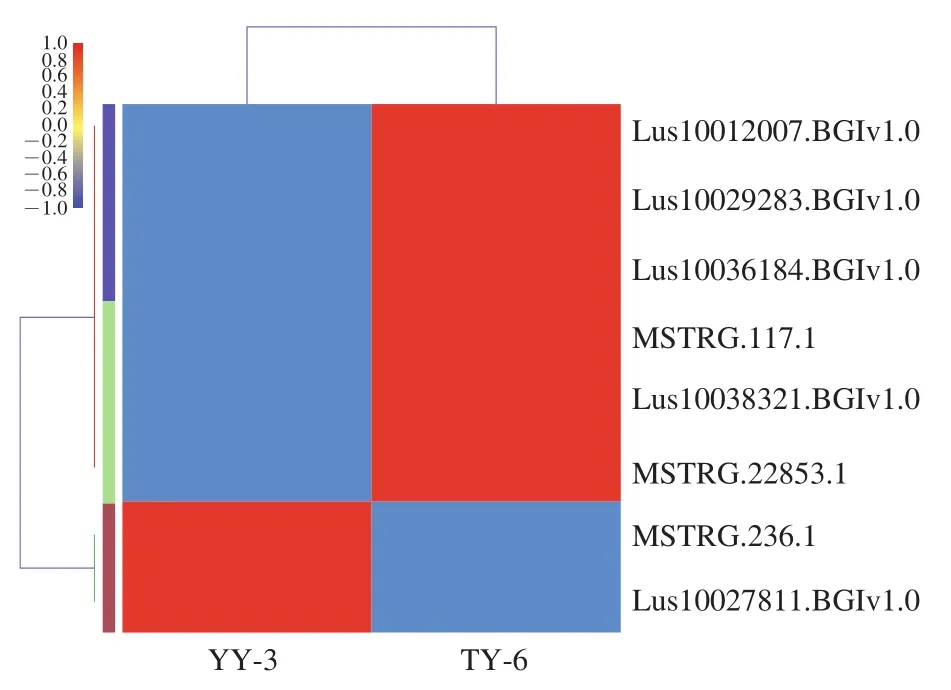
图8 不饱和脂肪酸代谢相关DEGs热图Fig. 8 Heatmap of DEGs related to unsaturated fatty acid metabolism
由图7、8可知,两个品种在脂肪酸代谢通路上注释到的17个DEGs中,有12个基因在TY-6中显著表达,分别为:MSTRG.8561.1、Lus10040173.BGIv1.0、Lus10036184.BGIv1.0、Lus10012007.BGIv1.0、Lus10029283.BGIv1.0、Lus10006502.BGIv1.0、MSTRG.12234.3、Lus10020160.BGIv1.0、MSTRG.3862.1、Lus10038321.BGIv1.0、MSTRG.117.1和MSTRG.22853.1。这12个基因中有6个基因同时注释到了不饱和脂肪酸通路上,分别是:Lus10012007.BGIv1.0、Lus10029283.BGIv1.0、Lus10036184.BGIv1.0、MSTRG.117.1、Lus10038321.BGIv1.0和MSTRG.22853.1。由图7可知,5个基因在YY-3中显著表达,分别为Lus10020908.BGIv1.0、MSTRG.236.1、Lus10033072.BGIv1.0、Lus10027811.BGIv1.0和Lus10004186.BGIv1.0,其中MSTRG.236.1和Lus10027811.BGIv1.0这2个基因同时注释到了不饱和脂肪酸通路上,参与调解不饱和脂肪酸的生物合成。
王欢欢等[30]在对番茄果实呈香组分及其代谢途径的研究中发现,番茄果实中的11 种香气组分分别来自于以脂肪酸、氨基酸和类胡萝卜素为前体物质的代谢途径。在脂肪酸代谢途径中,不饱和脂肪酸在脂肪氧合酶(lipoxygenase,LOX)催化下生成的氢过氧化物通过氢过氧化物酶(hydroperoxide lyase,HPL)的作用,可转化成己醛、顺-3-己烯醛等C6醛类化合物。Olias等[31]对初榨橄榄油中挥发性香气成分的研究表明,当植物受到创伤时,LOX变得活跃,导致不饱和脂肪酸形成以己醛为代表的C6醛类化合物。亚麻籽破碎过程中,细胞组织被破坏,亚油酸或亚麻酸在LOX的催化下会生成具有共轭二烯结构的氢过氧化物,进而HPL导致O—O键的断裂,通过进一步裂解迅速生成了大量醛类挥发性物质。杜乐[32]对冷榨亚麻籽油中不饱和脂肪酸氧化产物的研究表明,不饱和脂肪酸自动氧化形成醛类羰基化合物从而影响油的风味和质量,同样说明了不饱和脂肪酸是挥发性香气形成的重要前体物质。这些研究均揭示了亚麻籽品种中不饱和脂肪酸含量及种类的差异性与其籽油醛类特征香气的生成具有重要相关性。此研究中对两个新疆亚麻籽品种上游转录组差异代谢途径及相关基因的发掘,可对下游两个品种籽油的香气差异的进一步探究提供理论依据。
3 结 论
采用Illumina HiSeq测序平台对两种新疆特色亚麻籽进行转录组测序,两组数据共获得68 221 320 条raw reads,过滤得到61 995 756 条clean reads。采用生物信息学软件对测序结果组装得到33 218个unigene,将其与NR数据库进行比对发现,亚麻籽转录组测序组装的unigene与麻风树的相似性最高。利用COG数据库进行比对发现可将17 269 个unigene注释到细胞过程和信号、信息存储与处理、代谢3 大类22个分支,其中翻译后修饰、蛋白质折叠和分子伴侣是富集最多的条目,占比15.48%。
按照|log2(YY-3/TY-6)|>1且FDR<0.05的原则,共筛选出1 658个显著性DEGs,其中825个基因上调,833个基因下调表达。通过DEGs GO富集分析可知,可将其分为细胞组分、分子功能、生物过程3 大类33个分支,其中归属生物过程的GO条目最多(13个);380 个DEGs被注释KEGG数据库的108 条代谢途径中,两种亚麻籽DEGs KEGG代谢通路中显著富集的通路有脂肪酸代谢,不饱和脂肪酸合成,甘氨酸、丝氨酸和苏氨酸代谢,抗坏血酸和藻酸盐代谢,叶酸一碳库代谢等。通过KEGG数据库对脂质代谢途径相关DEGs分析可知,在脂肪酸代谢中注释到17个DEGs,其中有12个基因在TY-6中显著表达,5个基因在YY-3中显著表达。在不饱和脂肪酸代谢中注释到了8个DEGs,其中在TY-6显著表达的DEGs有6 条,2 条基因在YY-3中显著表达。研究结果为深入开展不同品种亚麻籽脂肪酸代谢过程研究及籽油香气改良提供科学依据。
