基于知识图谱卷积网络的双端推荐算法
2022-01-18杨兴耀钱育蓉
李 想,杨兴耀,于 炯,钱育蓉,郑 捷
新疆大学 软件学院,乌鲁木齐830008
随着互联网的快速发展,数据量呈爆炸式增长,导致信息过载,用户很难在数据的海洋中挑选出自己感兴趣的内容。为了提高用户体验,推荐系统已经应用于音乐、电影、广告等推荐场景。推荐系统主要分为基于协同过滤(collaborative filtering,CF)的推荐系统、基于内容的推荐系统和混合推荐系统。基于CF 的推荐系统由于能够有效地捕捉用户偏好,并且易于在多种场景下实现,而无需在基于内容的推荐系统中进行特征提取,因此得到广泛的应用。然而,基于CF 的推荐存在数据稀疏性和冷启动问题。为解决这些问题,混合推荐系统被提出来,其利用多种推荐技术来克服单一推荐方法的局限性,在此过程中会探索多种类型的辅助信息,比如物品属性、物品评论和用户的社交网络。
近年来,在推荐系统中引入知识图谱(knowledge graph,KG)作为辅助信息受到关注。KG 是一个有向异构图,其中节点作为实体,边表示实体之间的关系。可以将物品及其属性映射到KG 中,以理解物品之间的相互关系。此外,还可以将用户信息集成到KG 中,从而更准确地捕捉用户和物品之间的关系以及用户的偏好。最近提出多种KG,如Freebase、DBpedia、YAGO、谷歌的Knowledge Graph、微软的Satori,方便了构建用于推荐的知识图谱。可以发现知识图谱在多种推荐场景中都作为辅助信息,包括书籍、新闻、音乐、社交平台。
在以往的研究中,对知识图谱中用户属性信息的考虑少于对物品属性的考虑,这可能导致推荐结果存在一定的局限性。不同的人有不同的兴趣,这可能会受到用户的性别、年龄、职业等的影响。以电影推荐为例,不同性别和年龄的人可能会喜欢不同类型的电影。属于同一类别的人可能有相似的兴趣,而如果他们有不同的属性,他们可能有不同的兴趣。如图1 所示,大部分男性青年喜欢看科幻和动漫类型的电影,大部分中年男性喜欢看战争、犯罪和纪录片类型的电影,大部分女性青年喜欢看偶像和情感类型的电影,大部分中年女性喜欢看喜剧和情感类型的电影。
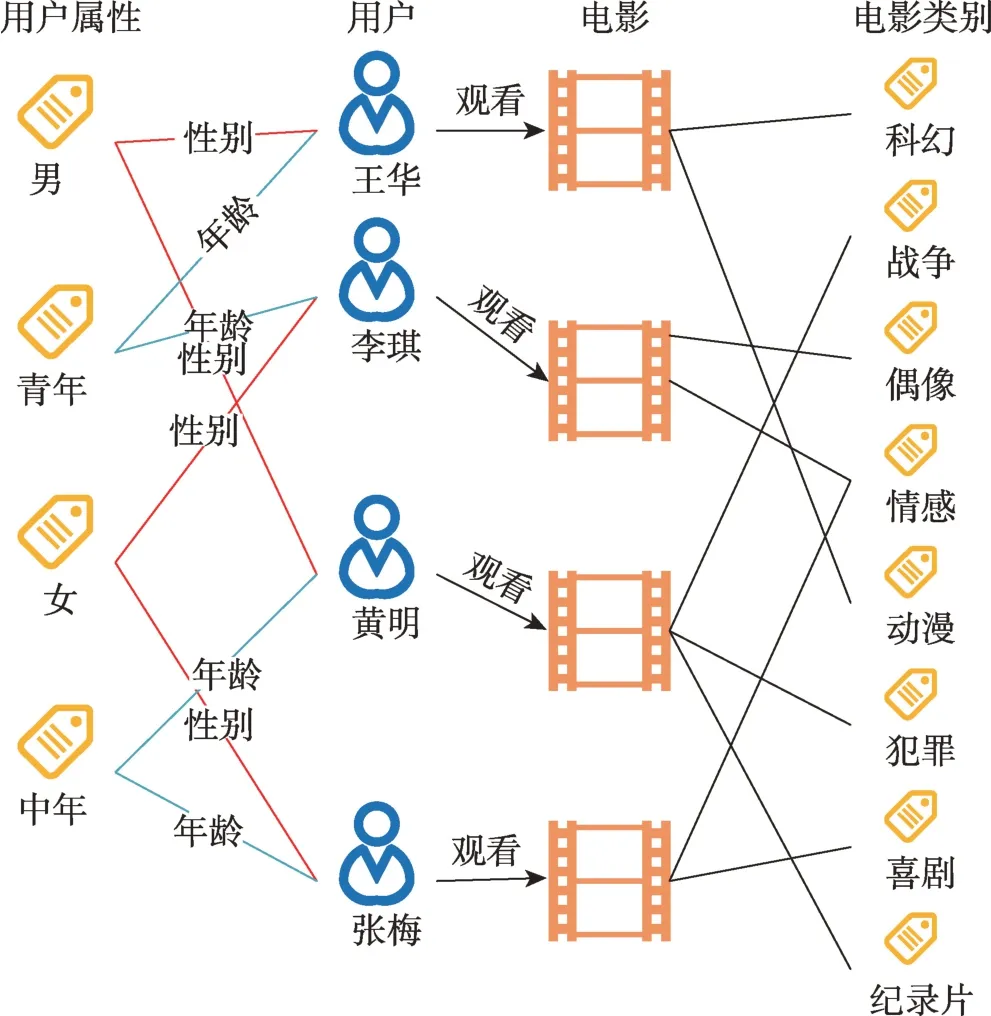
图1 不同属性的用户偏好不同类别的电影Fig.1 Users with different attributes prefer different categories of movies
KGCN(knowledge graph convolutional networks)在推荐方面具有优越的性能,其利用知识图谱的异构信息在物品端聚合物品的属性和其他额外的辅助信息,丰富了物品端的表示;但其在用户端没有考虑用户的属性信息,导致推荐模型存在一定的缺陷。为此本文对KGCN 模型进行改进,在用户端添加辅助信息,提出DEKGCN(double end knowledge graph convolutional networks),这是一个在知识图谱上探索用户偏好的端到端的推荐系统。它采用KGCN 作为项目推荐任务的基础模型,使得用户端和物品端都含有丰富的语义表示。
本文的主要贡献如下:(1)推荐模型利用知识图谱丰富的异构信息,以图卷积网络的方式在物品端聚合来自外部知识图谱丰富的物品信息和在用户端聚合来自数据集中用户的属性信息来学习各自的表示,提高了推荐系统的可解释性。(2)推荐系统数据集中的用户信息被提取出来构建三元组,拓宽了信息来源,丰富了知识图谱。(3)在公共电影数据集进行了大量的实验来评估DEKGCN 的有效性,与其他新近的模型相比,在共同的评价指标(例如、、和Top-)上,结果显示推荐性能有显著提升。
1 相关工作
1.1 推荐算法
用户属性相当于用户身上的标签,如年龄、性别、职业、收入等,把用户属性添加到推荐系统中可以极大地反映用户的本质特征,因而可以很大程度上促进更精准的个性化推荐。基于混合模型推荐算法的优化在修正余弦相似性和物品属性相似性结合的基础上,用SVDFeature 计算用户属性权重因子来获取用户相似度。基于用户属性和评分的协同过滤推荐算法以用户间属性相同个数来衡量用户的相似性,实现了与用户评分相似度融合的平滑过渡。基于用户聚类与项目划分的优化推荐算法使用means 算法对用户属性进行聚类,再通过增加物品类别相似度和评分相似度得到最近邻。文献[14]用优化的-means 算法对具有高活跃度的用户属性进行聚类来获得用户属性相似度,并综合考虑了用户偏好相似性。然而,现有的考虑用户属性的推荐算法只是把用户属性作为一种计算相似度的因素,并未把它用来丰富用户的表示,也没有学习高层次的抽象特征。
为了解决稀疏性和冷启动问题,把知识图谱应用到推荐系统越来越受到人们的关注。按照利用知识图谱的方式,将基于知识图谱的推荐系统划分为三种:基于嵌入的方法、基于路径的方法和统一的方法。基于嵌入的方法通常直接使用来自知识图谱的信息来丰富物品或用户的表示,将实体和关系嵌入到低维的向量空间。例如,在CKE(collaborative knowledge base embedding for recommender systems)
中,从知识图谱学习到的项目结构嵌入、项目文本嵌入和可视化嵌入集中在一个统一的贝叶斯框架中结合起来,共同表示物品。基于路径的方法利用知识图谱中用户或项目的连通性相似度来进行推荐。例如,PER(personalized entity recommendation)通过手动设计元路径,提取基于元路径的潜在特征来表示用户和物品之间沿着不同类型的关系路径的连通性。统一的方法结合基于嵌入的方法和基于路径的方法的优点,利用嵌入传播的思想来细化在知识图谱中具有多跳邻居的项目或用户的表示。例如在RippleNet中,通过沿着知识图谱中的关系,传播用户历史上交互过的项目来挖掘用户潜在兴趣,从而丰富用户的表示,提高推荐性能。本文提出的DEKGCN 是基于统一的方法,同时还考虑了用户属性对推荐的影响。
1.2 知识图谱嵌入
知识图谱嵌入(knowledge graph embedding,KGE)将实体和关系嵌入到连续向量空间中,同时保持其固有结构。KGE 算法可以分为两类:基于翻译的模型,如TransE、TransH、TransR、TransD等;语义匹配模型,如RESCAL、DistMult、ComplEx等。基于翻译的模型利用基于距离的评分函数,把衡量一个元组的可信性作为两个实体之间的距离,通常经过翻译关系进行。TransE 是最具代表性的基于翻译的方法,它将实体和关系以向量的形式表示在同一空间中,当三元组(,,)成立时,即+≈,则得分函数f(,)=||+-||2 的得分低,否则高。语义匹配模型利用基于相似性的评分函数,通过匹配在向量空间中实体和关系表示的潜在语义来衡量事实的可信性。例如,RESCAL将每个关系表示为矩阵,以捕获实体之间的组合语义,并使用双线性函数作为相似性度量。然而这些方法只适合在知识图谱内部完成特定任务,例如连接预测和三元组分类,而不适合应用在推荐领域。
2 DEKGCN 模型
本章将介绍所提出的DEKGCN 模型:首先描述知识图谱感知的推荐问题,然后展示一个单层的物品端和用户端的卷积表示学习过程以及两端的聚合方式,最后介绍完整的DEKGCN 学习算法。
2.1 问题描述
知识图谱感知推荐问题的表述如下:在一个典型的推荐场景中,通常有一组个用户={,,…,u}集合和一组个物品={,,…,v}集合。根据用户隐式反馈,定义用户-项目交互矩阵∈R:

其中,y=1 表示用户和物品之间存在隐式交互,如点击、观看、浏览、购买等行为;否则,y=0。
2.1.1 知识图谱
除了交互矩阵,物品还有一些附加信息,即物品的属性和额外扩展信息。例如,一部电影可以通过导演、演员和类别等来描述。这些辅助信息可以通过外部知识图谱获取,它由{(,,)|∈,∈,∈}三元组组成,即(头,关系,尾),和分别表示知识图谱中的实体集和关系集。例如,三元组(流浪地球2,电影导演,郭帆)表示,郭帆是电影《流浪地球2》的导演。在许多推荐场景中,物品∈可以与中的一个或多个实体关联。例如,在电影推荐中,电影《无间道》也作为实体出现在知识图谱中。在本文中,只考虑一个物品恰好对应知识图谱中一个实体的情况,即{(,)|∈,∈}。在本文的后面,可以互换使用符号和来表示某一项。此外,用()表示实体直接连接到的实体集,即()={|(,,)∈}。
2.1.2 用户属性图G
除了与物品相关的实体,还必须获取和用户相关的实体,即用户的人口统计学信息。由于这部分信息不包含在知识图谱中,只能从数据集中提取,来构造用户属性三元组,形成用户属性图G。对于用户属性三元组,把用户作为头实体,用户属性名作为关系,用户属性值作为尾实体,即{(,,)|∈,∈,∈},这里、分别表示用户属性图G中的关系集(属性名集)和实体集(属性值集)。例如,在图1 中,用户属性三元组(王华,性别,男)表示用户王华的性别为男。此外,用()表示用户的属性集,即()={|(,,)∈G},比如王华属性集合{性别:男,年龄:20 岁,职业:学生}。
在外部的知识图谱中,()的大小在所有实体上都有显著差异,在最坏的情况下可能会非常大(尤其是当跳数很大的时候)。为了保持每批的计算模式固定且更高效,对每个实体统一采样一个固定大小的近邻集,而不是使用它的完整近邻()。也就是说,将实体的采样近邻集定义为(),其中()={|∼()},|()|=,其中是一个可配置常数。在本文中,把()称为实体的(一阶)接受域,的最终表示受到接受域中不同实体的影响。在真实用户属性图G中,()有固定大小,即()=,且一般都很小,不需要对其采样,的接受域就是()且只有一阶。
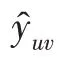

图2 DEKGCN 模型框架图Fig.2 Overall framework of DEKGCN
2.2 知识图谱卷积网络
DEKGCN 被提出来捕获知识图谱中实体之间的高阶结构接近性,在该节中,只对实体的一阶卷积进行描述。对于一对候选用户和物品,先在知识图谱上用图卷积的方法计算物品(实体)的一阶向量表示,再在用户属性图G上用图卷积的方法计算用户的最终向量表示。
2.2.1 物品(实体) 的一阶向量表示
在知识图谱上,r表示实体e和实体e之间的关系。用一个函数:R×R→R(例如内积)来计算用户和关系之间的分数:

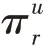
为刻画物品的拓扑接近结构,需要计算物品邻域的线性组合,即的一阶邻域表示:

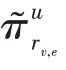

∈R是实体的向量表示。当计算一个实体的邻域表示时,用户关系评分作为个性化的过滤器,根据特定用户关系的评分带有权重地聚合近邻。
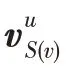

其中,和分别为变换的权值和偏置,为非线性函数,例如ReLU。
2.2.2 用户 的最终向量表示
用户的最终向量计算过程和物品的一阶向量表示计算过程一样,在这里只简单叙述。
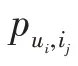

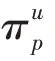
用户属性的线性组合,即的邻域表示:



∈R是属性的向量表示。
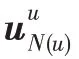

2.3 学习算法
通过单一的DEKGCN 层,实体的最终表示依赖于它自己以及它的近邻,称之为一阶实体表示。将KGCN 从一层扩展到多层,以更广更深的方式合理挖掘用户的潜在兴趣。该技术可以直观地描述为:将每个实体的初始表示(0 阶表示)传播给它的邻居,得到一阶实体表示,然后可以重复这个过程,即进一步传播和聚合一阶表示,以获得二阶表示。一般来说,一个实体的阶表示是它自身及其相邻实体的-1表示的混合。最终DEKGCN模型形式化描述在算法1中给出。
DEKGCN 的算法
输入:交互矩阵,知识图谱。
输出:预测函数F(,;,,)。
初始化所有参数

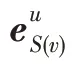

注意,算法1 遍历所有可能的用户-项目对(第2行)。为提高计算效率,在训练过程中采用负采样策略。损失函数如下:
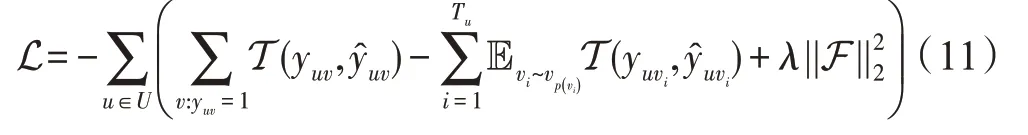
其中,T 为交叉熵损失函数;T为用户的负样本数,并且T=|{:y=1}|;为负抽样分布且服从均匀分布;最后一项是L2 正则化。
3 实验
3.1 数据集
为更好地评估本文提出的模型,一个包含交互信息和用户辅助信息的数据集是必要的。本文提出的模型是在MovieLens-1M 上评估的,这是一个广泛用于评估电影推荐系统的数据集,它包括由6 040 个用户对大约3 900 部电影产生的1 000 209 条匿名评分(值范围从1 到5),其用户属性信息包含年龄层次、性别、邮政编码和职业。

对于MovieLens-1M 数据集中的每个电影,都需要在知识图谱中有对应的实体。本实验使用MKR中在Microsoft Satori 上为数据集MovieLens-1M 构建好的知识图谱sub-KG 作为,其中数据集中的电影已经映射到相应的Microsoft Satori 实体。此外,利用MovieLens-1M 中用户的ID、性别、年龄,邮政编码和职业信息以三元组的形式来构建关于用户属性的知识图谱G。例如,ID 为3 的用户属性三元组为(3,性别,男性)。数据集和知识图谱的基本统计数据如表1所示。注意,用户、项目和交互的数量比原始数据集要小,因为过滤掉了知识图谱中没有对应实体的项。

表1 数据集和知识图谱的基本统计数据Table 1 Basic statistics for dataset and knowledge graph
3.2 对比模型
将提出的DEKGCN 与以下新近的基于知识图谱的推荐模型进行比较,对比模型的超参数设置除特别指出的以外,其他的与其原文中的设置相同。
MKR:通过一个交叉压缩单元学习物品和知识图谱中实体的共同潜在语义表示来进行推荐,丰富物品端的表示。在实验中,迭代次数设为10。
KGCN:用图卷积网络的方法在知识图谱中聚合物品的辅助信息,丰富物品端的表示,得到用户对物品的偏好概率。在实验中,批处理大小设为4 096。
KGNN-LS:在知识图谱上用图神经网络聚合邻域信息,并把标签平滑正则化添加到损失函数中进行推荐学习。在实验中,批处理大小设为4 096。
DEKGCN:本文提出的在用户端和物品端同时融合各自辅助信息的推荐模型。
3.3 实验设置
函数设置和基础模型KGCN 一样,和设置为内积函数。对于,设置ReLU 函数作为非最后一层的聚合器,tanh 函数作为最后一层的聚合器。超参数是通过优化验证集的AUC 来确定的,迭代次数为20,实体嵌入向量的维数=16,接受域的深度=2,L2 正则化器权重=e,学习率=0.01,批处理大小为4 096。在知识图谱中,实体邻域采样大小=4;在用户属性图G上,由于MovieLens-1M只提供了4 个用户属性,因此=4。通过Adam 对可训练参数进行优化。DEKGCN 的代码是在Python 3.6、TensorFlow 1.12.0 和NumPy 1.14.3 下实现的。
训练集、验证集和测试集的比例为6∶2∶2,每个实验重复3 次,取平均性能值。
在两个实验场景中评估模型:(1)在点击率(click through rate,CTR)预测中,使用训练好的模型来预测测试集中的每个交互,接着用、和1 来评估点击率预测。(2)在Top@推荐中,使用训练好的模型为测试集中的每个用户选择预测点击概率最高的个项目,然后选择@、@和1@对推荐集进行评估,其中=1,2,5,10,20,50,100。
3.4 结果及其分析
本节将介绍不同模型和DEKGCN 的比较结果。表2 为模型的CTR 的预测结果,图3、图4 和图5 分别为Top@推荐的准确率、召回率和1 折线图。

图3 Top@K 推荐的准确率Fig.3 Precision in Top@K recommendation
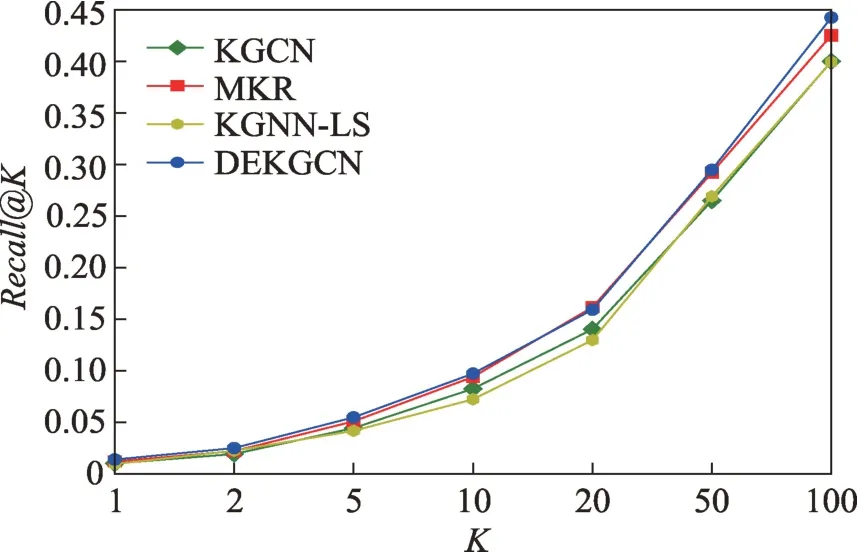
图4 Top@K 推荐的召回率Fig.4 Recall in Top@K recommendation

图5 Top@K 推荐的F1Fig.5 F1 in Top@K recommendation
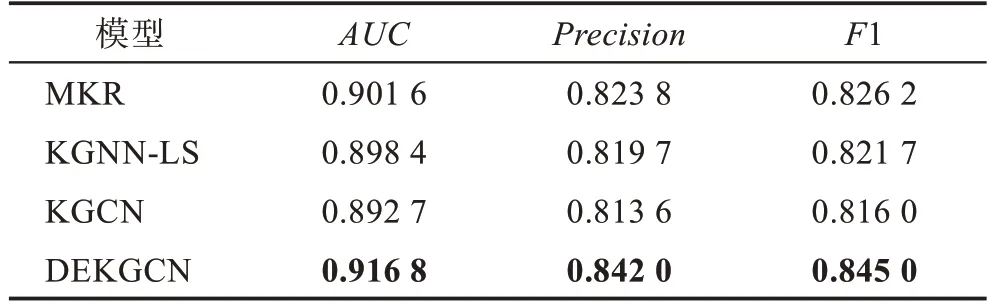
表2 CTR 预测的AUC、Precision 和F1 结果Table 2 Result of AUC,Precision and F1 in CTR prediction
从表2 中可以看出,模型DEKGCN 在CTR 的各项指标上均取得了较好的性能。与表现最好的基准模型MKR 相比,DEKGCN 在上提升了1.69%,在上提升了2.21%,在1 上提升了2.28%。与原模型KGCN 相比,改进后的模型DEKGCN 在上提升了2.70%,在上提升了3.50%,在1 上提升了3.55%。
从图3、图4和图5中可以看出,DEKGCN 在@、@和1@上也实现了较好的性能。=10 时,基准模型KGNN-LS 在准确率上表现最好,DEKGCN 与其相比提升了7.13%;基准模型MKR在召回率和1上表现最好,DEKGCN 与其相比在召回率上提升了2.67%,在1 上提升了12.89%。与原模型KGCN 相比,DEKGCN 在准确率上提升了18.62%,在召回率上提升了0.68%,在1 上提升了12.51%。
在CTR 预测和Top-推荐中,DEKGCN 在各项指标中均取得了较好的性能。在基准模型中,MKR在CTR 推荐场景中表现优秀,但在Top-的推荐场景中表现得不是很好。而DEKGCN 在这两个推荐场景中都表现出色。这是由于MKR、KGNN-LS、KGCN和DEKGCN 这几个推荐模型都结合了知识图谱中丰富的异构信息,但MKR、KGNN-LS、KGCN 只是融合了物品在知识图谱中的辅助信息及其关系,只有DEKGCN 同时在用户端和物品端结合各自的辅助信息及其关系。本文提出的DEKGCN 模型性能提升有两个潜在原因:第一个原因是使用了更多的信息源;第二个原因是使用结构化知识图谱来建模异构信息。DEKGCN 表明,在用户端融合用户的辅助信息,在物品端融合物品的辅助信息是可行的。推荐系统对异构信息的利用可以显著提高推荐性能,而用户属性信息的额外使用也可以提高推荐性能。
4 结束语
本文提出的DEKGCN 推荐模型,是一种利用用户和物品属性及其关系进行推荐的端到端模型,在MovieLens-1M 数据集上进行的大量实验,证明了该模型在提高推荐质量方面的有效性,且为用户提供了直观的推荐解释。在未来,会进一步地将知识图谱与其他辅助信息有效地结合到推荐系统中,如社交网络、用户评论信息等;也会在其他领域拓展本文提出的模型,比如音乐、电子商务、新闻、视频等。
