改进YOLOv5 的交通灯实时检测鲁棒算法
2022-01-18王国中李国平
钱 伍,王国中,李国平
上海工程技术大学 电子电气工程学院,上海201620
交通灯检测是指对交通灯定位和识别,作为自动驾驶和辅助驾驶中的核心算法之一,直接关系到智能汽车的行驶决策。对交通灯准确定位和类别检测能够为行驶中的车辆提供交通信号信息,保障车辆行驶安全。显然,实时和鲁棒的交通灯检测算法可以帮助智能汽车提前获取交通信号信息,避免交通事故的发生,提高汽车的安全性能。
随着计算机视觉和深度学习的快速发展,从视觉方面对交通灯检测取得重大突破。但是,基于计算机视觉的交通灯检测算法也面临诸多困难,总结为以下几个方面:(1)交通灯在图像中具有较小的尺度,算法定位困难;(2)行驶中的车辆抖动,采集到的图像模糊,交通灯的边缘信息难以确定;(3)交通灯的颜色和几何特征易与环境中其他物体混淆,算法产生误检测;(4)交通灯处于复杂多变的户外,算法难以泛化,鲁棒性差;(5)检测信息需要及时回传到汽车的控制系统,算法要有可靠的实时性。
传统的交通灯检测算法往往只考虑单一环境,关注交通灯的颜色和几何特征,使用特征提取、模板匹配和分类算法对交通灯进行识别。其中Sobel 边缘检测、Hough 变换和支持向量机(support vector machine,SVM)等算法被组合应用到交通灯的检测中。Omachi等人在交通灯颜色特征下,提出归一化输入图像的RGB 空间的方法提取候选区域,在候选区域上使用Hough 变换检测交通灯。Li 等人将形态学滤波和统计方法结合在一起,首先使用Top-Hat 变换将输入图像变换为二值图像,再使用阈值分割法提取明亮区域,结合形态学处理该区域,最后使用统计分析方法识别交通灯。这些算法不可避免地使用了大量人工提取的特征,鲁棒性差,只能在特定的场景中实现,实时性难以达到要求。
近年来,以卷积神经网络为核心的目标检测算法取得了发展。这些算法可分为一阶段和二阶段算法,一阶段的代表算法包括:OverFeat、SSD(single shot multibox detector)系列、YOLO(you only look once)家族和EfficientDet等。二阶段的代表算法有R-CNN(region-based convolutional neural networks)家族和SPPNet等。
Manana 等人使用一种提前预处理的Faster RCNN对车道线进行检测,相比没有预处理,缩短了训练的时间。Wang 等人使用HSV(hue saturation value)空间提取交通灯的候选区域,结合6 层卷积神经网络对这些区域进行分类,实现了较高的速度和精度。Liu 等人在自建的交通数据集上,提出改进YOLOv3 模型,模型检测速度达到了59 frame/s,精度高达91.12%。Thipsanthia 等人在泰国交通数据集下使用YOLOv3 和YOLOv3-tiny 对50 类路标进行检测,检测精度分别达到了88.10%和80.84%。Choi 等人基于YOLOv3,设计了高斯损失函数,增加了模型对交通灯的召回率,在BDD100K数据集上,最好获得了20.8%的mAP。
基于深度学习的目标检测算法弥补了传统算法中人工提取特征的不足,但是在特征提取过程中对原始图像进行多次下采样,对小目标检测能力差。并且,这些算法不仅网络结构复杂,而且模型规模大,训练代价高。
1 相关介绍
YOLO 算法将目标检测问题转化为回归问题,有着快速检测的能力。YOLOv5 延续网格检测方法,每个网格预测3 个bboxes(bounding box),每个bbox 包含4 个坐标、1 个置信度和个条件类别概率。
如图1,为了增加感受野且不影响模型推理速度,YOLOv5 在骨干网络增加Focus 层,将图像的宽度和高度信息转化为通道信息。为了减少冗余信息,YOLOv5借鉴了CSPNet,设计两种不同的BottleneckCSP 结构,分别记作CSP1 和CSP2。其中CSP1 用特征提取部分,CSP2 用于特征融合部分。YOLOv5 有着四种不同规模的模型,分别记为YOLOv5s、YOLOv5m、YOLOv5l 和YOLOv5x,模型参数依次增加,目标检测能力逐渐提升。尽管YOLOv5 有着快速识别和自适应锚框等优点,但是对目标特征提取能力不足,并且特征融合网络仅仅关注高级语义信息。因此,在此基础上提出改进方法,增加模型对类似交通灯这样小且环境复杂目标的检测能力。

图1 YOLOv5 的网络结构Fig.1 YOLOv5 network structure
2 改进方法
本文分别从三方面改进YOLOv5:(1)改进模型的输入尺度,使其能够尽可能输入较多的目标特征;(2)设计了ACBlock(asymmetric convolution block)、SoftPool和DSConv(depthwise separable convolution),旨在增加主干网络的特征提取能力,减少模型参数;(3)设计记忆性特征融合网络,增加模型对底层特征的学习能力。改进YOLOv5 的网络结构如图2 所示。

图2 I-YOLOv5 的网络结构Fig.2 I-YOLOv5 network structure
为了与YOLOv5 的四种模型对应,改进后的模型分别记作I-YOLOv5s、I-YOLOv5m、I-YOLOv5l 和I-YOLOv5x。
2.1 模型输入改进——可见标签比
YOLOv5 以640×640 的尺度作为模型输入,特征提取过程对目标进行了8 倍、16 倍和32 倍下采样。此过程会使小目标丢失显著特征,因此本节探究模型输入,尽可能多地保留目标的显著特征。
本文定义可见标签的概念:标签的GT(ground truth)经过主干网络的特征提取后,尺度大于1×1,称这个标签为可见标签,其对应的特征图包含着目标的显著特征。不可见标签则会与周围环境融合,生成弱信息特征图,给检测带来了难度。由此,计算一个可见标签阈值,控制模型输入,使采样后的特征有更多的显著特征。以8 倍下采样作为模型最低的下采样值,推导模型输入与可见标签阈值之间的关系如下:

式中,是计算得到的模型输入大小;=max{,},、分别是原始图像的宽和高;是可见标签阈值。
可见标签比指的是尺度≥的标签个数与总标签数目的比值,可以确定可见标签阈值,控制模型输入。可见标签比越大,特征图中目标的显著特征越多。表1 以BDD100K 为数据集,给出了可见标签阈值、可见标签比、模型输入尺寸、模型检测能力、模型运行速度和模型训练占用显存之间的关系。如表1,随模型输入尺度的增加,模型的AP(average precision)也随之增加。但是,相应的计算量会随之增加。为了均衡AP 值和模型显存占用,使用手肘法确定=13。此时模型的效益最高,相应的模型输入为800×800。

表1 可见标签比与模型性能关系Table 1 Relationship between visible label ratio and model performance
2.2 主干网络的改进方法
为了提高主干网络对目标的特征提取能力,本文借鉴ACNet,设计了ACBlock作为CSP(cross stage partial)结构的基础卷积。
如图3,设计的ACBlock 由3 个卷积核3×3×、3×1×和1×3×组成。其中3×3×卷积核是一个正则卷积,可以提取图像的基础特征;3×1×和1×3×分别是竖形和横形卷积核,二者可以提取图像的纵向和横向特征,以及目标的位置和旋转特征。因此,ACBlock 比原卷积核能够提取到更多的特征信息,提高了主干网络的特征提取能力。

图3 ACBlock 结构Fig.3 ACBlock structure
因为卷积满足叠加原理(式(2)),所以ACBlock可以直接替换CSP 中的卷积核。ACBlock 提取特征后,依据式(2)进行特征叠加。
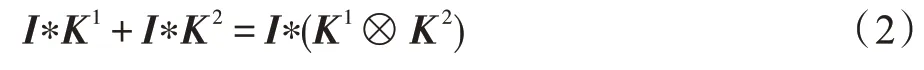
式中,是输入,和是两个兼容大小的卷积核,*是卷积运算。
在训练阶段,ACBlock 中的3 个卷积核被单独训练,叠加后再前向传播。在推理阶段,3个卷积核的权重被提前融合成一个正则卷积形式,再进行推理计算,因此不会增加额外的推理时间。融合公式如下:


ACBlock 可以直接替换原始卷积核,使主干网络获取到更多的特征信息。ACBlock 由三种卷积核实现,势必也会增加模型参数,又因为ACBlock 中的每个卷积核被单独训练,所以模型训练时间被延长。
池化是卷积神经网络中一种至关重要的方法,它降低了网络的计算,实现了空间不变性,更重要的是增加了后续卷积的感受野。YOLOv5 使用正则卷积实现模型下采样,这不仅增加了计算量,而且还产生了较多的采样损失。为此,本文提出在激活特征图的池化区域内使用Softmax 方式实现池化,对特征图进行2 倍下采样。
在池化区域内,使用Softmax 计算每个元素激活的权重,将指数加权累加激活作为池化邻域的激活输出,指数加权权重和邻域激活公式如下:

如图4,类似卷积核,本文使用一个3×3 步长为2 的掩膜来对特征图进行池化。在激活后的特征图中,较高激活(图中高亮块)包含特征图的主要特征信息,较低激活则包含次要信息。下采样时,掩膜会覆盖在特征图的3×3 区域上,在此区域内计算每一个激活的Softmax 权重,较高的激活会获得更高的权重。对此区域内的激活加权累加后,作为池化结果传递到下一个特征图。这个过程中,池化区域内的所有激活都参与累加,较高的激活携带主要特征占据池化结果的主导地位,较低的激活也能将自己的次要特征信息传递到池化结果中。

图4 SoftPool下采样过程Fig.4 SoftPool down sampling process
因此,SoftPool 以加权求和保留了激活信息,对不同激活的关注度不同,很大程度上保留输入的属性,实现下采样的同时能够减少信息损失。
分析模型规模时,发现ACBlock 的引入,将模型参数增加了约70%。因此本文设计了DSConv 卷积核代替主干网络中的部分正则卷积,旨在确保精度不变条件下减少模型参数。
如图5(a)所示,YOLOv5 的正则卷积是由一个3×3×的卷积核实现,DSConv 则是由3×3×1 和1×1×两个卷积核组成,卷积的过程也是两步进行。先由3×3×1 的卷积核对特征图进行逐通道卷积,得到结果;再由1×1×对进行逐点卷积,得到作为DSConv 结果输出。
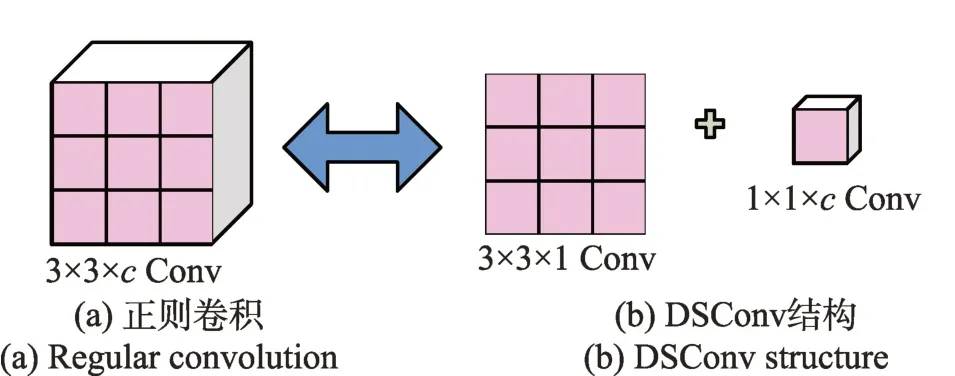
图5 正则卷积与DSConv 对比Fig.5 Regular convolution compared with DSConv

将主干网络中第二层卷积核(图1backbone 部分)替换成DSConv(图2backbone 部分),可以减少模型参数,对模型性能几乎没有任何影响。
2.3 记忆性特征融合网络
对小目标检测而言,底层特征比高级语义信息更重要。如图6(a),YOLOv5 借鉴了PANet,采用自上而下和自下而上的顺序融合方式生成三种高级语义信息,来计算损失。显然,用于计算损失的只有高级信息,底层特征没有被使用,丢失了较多小尺度信息,模型对目标边缘学习能力也被局限。
因此本文提出一种记忆性特征融合网络,旨在将高级语义信息和底层特征结合,让模型同时学习底层特征和高级语义信息,增加模型对小目标的学习能力,提高模型对目标的定位和回归能力。
如图6(b),设计的记忆性融合网络没有边缘融合节点,使用远跳链接将底层特征直接传递到语义生成节点。因此,网络末端可以将原始底层特征和高级语义信息再次融合。最终送入损失函数的特征既包含高级语义信息,又有底层特征。模型在学习高级语义信息的同时也能够学习到底层信息,有助于模型检测小尺度目标。

图6 PANet与本文特征融合网络结构Fig.6 PANet and proposed feature fusion network structure
由于融合的信息中包含了较多的底层信息,模型对目标的定位将更加精确,同时回归框的精度也得到提高。如图7,从特征融合的热力图中可以分析网络对图像的关注点。相比于PANet,记忆性特征融合网络关注中心更集中在目标中心,给检测头提供了准确的位置中心,有助于模型的定位。因此,记忆性特征融合网络可以提高定位精度。

图7 特征融合后的热力图Fig.7 Heatmap of fused features
另外,热力图中目标边缘处较多的热点会增加模型对边缘信息的判别难度。通过计算预测框和真实框的IOU(intersection over union)可以评估预测框回归的精准度。表2 在BDD100K 验证集上计算了改进方法的预测框与真实框的平均IOU。YOLOv5 模型预测框与真实框之间的平均IOU 是0.528,使用记忆性特征融合网络后的平均IOU提高到了0.591,提高了0.063。记忆性特征融合网络能够克服目标边缘问题,回归精度增加了6.3 个百分点。

表2 预测框与真实框的平均IOUTable 2 Average IOU of predict and ground truth boxes
3 实验
3.1 实验步骤
本文在BDDTL(BDD100K traffic light)和Bosch数据集上训练模型,并测试改进方法的有效性。相比于Bosch,BDDTL 不仅有着更大的数据量,而且还具有更多的数据属性,能够充分测试模型的泛化能力。因此,本文在BDDTL 数据集上建立消融实验和测试模型泛化能力。模型的训练是在Nvidia Tesla V100 PCIE 32 GB GPU 上进行,测试是在Nvidia RTX2080 Super 8 GB GPU 上进行。
YOLOv5 的训练参数见文献[12],采用余弦退火的衰减方式。在参数一致的前提下,训练了I-YOLOv5,并对模型输入进行增强。
实验内容如下:
(1)在BDDTL 数据集上建立改进方法的消融实验来分析改进方法的可行性和必要性;
(2)在BDDTL 和Bosch 数据集上,通过对比多种算法、改进前后的算法,来测试改进的效果;
(3)在BDDTL 数据集上测试模型的鲁棒性,评估模型的泛化能力;
(4)在BDDTL 数据集上建立模型鲁棒性消融实验,验证改进方法对鲁棒性的影响。
3.2 评估指标
本文采用AP.50 作为评估模型性能的指标,因此需要计算模型的和,具体公式如下:

式中,是准确预测标签的个数;是不存在目标的误检测,或已存在目标的误检测;是目标的漏检测。
3.3 模型训练
如图8(a),在训练过程中,YOLOv5 收敛速度慢,其 中YOLOv5s 和YOLOv5m 在 第250 个epoch 附 近开始收敛。I-YOLOv5 在第50 个epoch 附近开始收敛,有着更快的收敛速度。从图8(b)可以看出:YOLOv5 在验证集上的AP 先增后降,出现了严重的过拟合;随着模型收敛,I-YOLOv5 的验证AP 稳定上升,没有出现过拟合现象。

图8 模型训练过程Fig.8 Model training process
3.4 消融实验
为了充分验证改进方法行之有效,通过构建消融实验(见表3),逐步探究改进方法对YOLOv5 影响。消融实验以YOLOv5l为基础模型,输入大小统一为640×640,评估指标为AP和模型计算量(FLPOS)。

表3 以YOLOv5l为基础模型的消融实验Table 3 Ablation experiments based on YOLOv5l
从表3中可知,ACBlock、SoftPool 和Our FPN(feature pyramid network)对模型检测能力有较大的提升。ACBlock 使模型的AP 上升了5.4 个百分点,因此ACBlock 可以提取到更多的特征信息,但也增加了69.2%的计算量。
SoftPool 池化使模型的AP 增加了2.8 个百分点,参数量减少了1.7%,这种池化方式实现了下采样的同时可以减少信息丢失。
DSConv直接减少了4.3%的计算量,将模型的AP降低了0.2个百分点,对模型的精度几乎没有任何影响。
记忆性融合网络将模型的检测能力提高了5.6个百分点,模型参数减少了21.4%。因此,使用远跳连接使底层特征与高级语义信息重新再融合可以增加模型的特征学习能力。
在消融实验逐步进行的过程中可以发现:改进方法叠加,模型的性能并不是直接叠加,而是在上一个改进的基础上的小幅度提升。通过逐步改进YOLOv5 的主干网络和特征融合网络,模型的检测能力也随之逐步提升。
3.5 实验结果
模型在BDDTL 和Bosch 数据集上的测试结果列在表4 和表5 中。
如表4,在BDDTL数据集上,YOLOv5x作为YOLOv5 最优秀的模型,在55 frame/s 的检测速度下获得了63.30%的AP。EfficientDet-D2 的AP 只有45.50%,检测速度只有24 frame/s。I-YOLOv5s 的AP达到了72.30%,比YOLOv5x 提升了9 个百分点,推理速度也达到了111 frame/s。I-YOLOv5x 取得了所有实验中最优的结果,模型的AP高达74.30%,比YOLOv5x提高了11 个百分点,检测速度保持在40 frame/s。
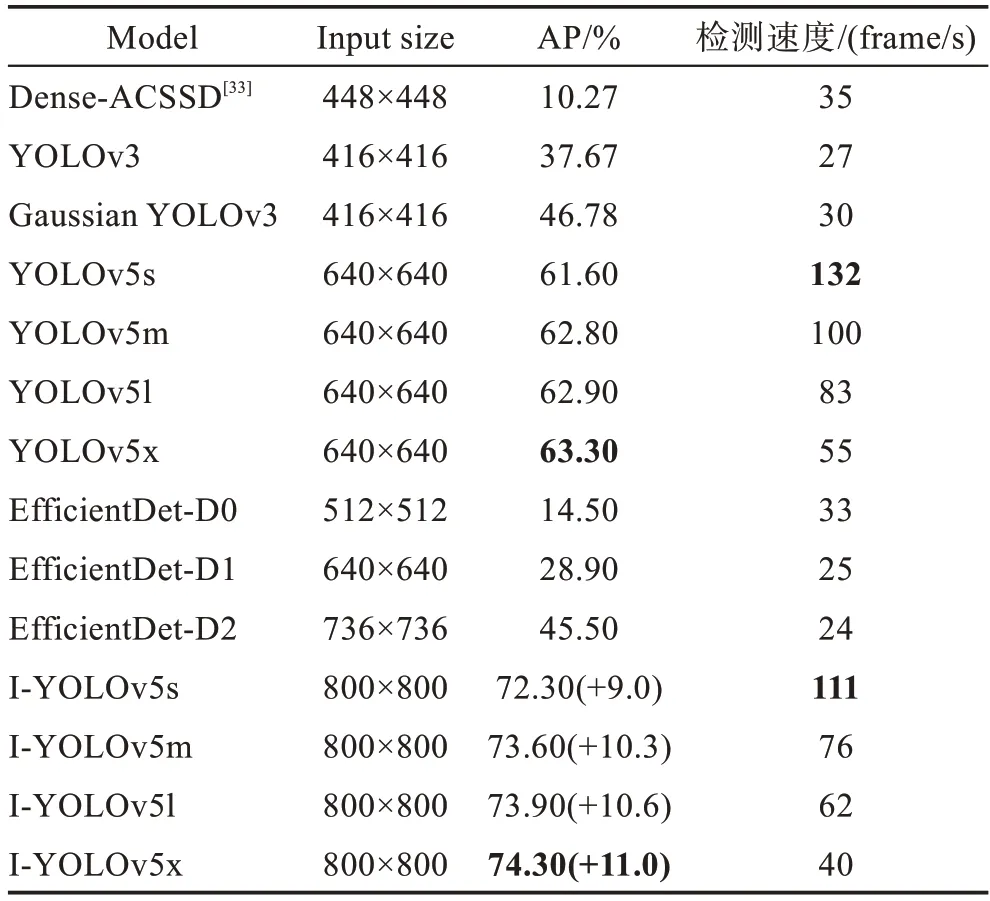
表4 不同模型在BDDTL 数据集上的测试结果Table 4 Test results of different models on BDDTL
如表5,在Bosch 数据集上,YOLOv5 的AP 达到了75.1%,检测速度最快达到130 frame/s。相比之下,I-YOLOv5 检测速度平均下降了约7 frame/s,但检测平均能力提高了12.03个百分点。其中,I-YOLOv5s在82.8%的AP 下检测速度达到了126 frame/s;IYOLOv5x在84.4%的AP下,检测速度也有46 frame/s。

表5 不同模型在Bosch 数据集上的测试结果Table 5 Test results of different models on Bosch
图9 展示了改进前后的检测效果,其中(a)、(c)、(e)和(g)是YOLOv5 检测效果,(b)、(d)、(f)和(h)是I-YOLOv5 检测效果。从(a)和(b)可知,改进后的算法缓解了YOLOv5 的漏检测问题,模型对小尺度交通灯的检测能力也得到提高;如(c)和(d),在夜晚场景下,改进后的模型修正了检测框的位置,提升了定位精度;从(e)和(f)可知,由于大尺度训练样本少,YOLOv5 对大尺度交通灯的检测能力也同样不足,而改进后的方法弥补了这个问题;由(g)和(h)可知,改进后的模型对小尺度交通灯的检测能力显著上升。

图9 模型检测效果Fig.9 Model detection effect
3.6 模型鲁棒性测试
如表6,测试不同的环境条件下的模型性能,可以评估改进前后模型的鲁棒性是否有所提高。

表6 改进YOLOv5 和YOLOv5 鲁棒性测试结果Table 6 Improved YOLOv5 and YOLOv5 robustness test results %
(1)在不同尺度检测能力的测试中,I-YOLOv5在small 尺度中取得了71.9%的AP,在large 尺度中提高了40%。可以发现,所有模型在large 尺度中的检测能力都小于small 尺度下。这是因为BDDTL 数据集中大尺度标签仅仅只有119个,小尺度标签有164 333个,样本不均衡,模型对大尺度目标学习能力不足。
(2)在不同时间条件下的测试结果表明,IYOLOv5 的AP 显著提高,在黎明和黄昏条件下,提升了20.7%的AP,在夜晚AP 也有8.3 个百分点的增加。
(3)通过在不同场景下测试,I-YOLOv5 几乎都有较高的提升,其中在parking lot 场景中,I-YOLOv5l将AP 值直接提高了21.1 个百分点。但是在tunnel场景,I-YOLOv5 表现出较差的检测性能。因为该场景中的测试图片只有3 张,共9 个目标,测试结果偏差大。
(4)在不同天气条件下,I-YOLOv5 对YOLOv5的AP 提升都在10 个百分点之上。在foggy 场景中,I-YOLOv5 提升了25.4 个百分点,达到了75.2%。
3.7 模型鲁棒性消融实验
为验证改进方法对模型泛化能力的影响,以YOLOv5l 模型为基础,在输入统一为640×640 的条件下,逐步引入提出的方法,通过测试不同场景下的mAP(mean average precision)来衡量模型性能,研究改进方法对模型鲁棒性能的影响。此外增加A mAP I(average mAP increase)指标,用于衡量mAP 的平均增加量。
模型鲁棒性消融实验结果见表7。设计的ACBlock 结构在size、time 和weather 场景下的mAP都增加了5.0 个百分点以上,在scene 场景下,mAP 仅增加了5.2%。SoftPool 对不同场景下模型的mAP 提升了2.5 个百分点~3.0 个百分点,其中在scene 场景下对模型的贡献最少。DSConv 的使用对模型检测能力的影响较小,在不同size 条件使模型的mAP 降低了1.0%。本文的特征融合网络的设计对模型的贡献最大,在weather 场景下提高模型5.9 个百分点,平均给模型性能增加5.0 个百分点。

表7 以YOLOv5l为基础模型的鲁棒性消融实验Table 7 Robust ablation experiment based on YOLOv5l
与3.4 节内容相似的是,改进方法对模型鲁棒性的提高不是具体到某一种方法的改进,而是模型整体特征提取能力的增加,特征融合的优化使模型的检测能力增加。
4 结论
针对目前基于视觉的交通灯检测算法存在的难点,本文以BDD100K 为数据集,以YOLOv5 为基础,使用可见标签比确定模型输入,引入ACBlock 增加主干网路的特征提取能力,设计SoftPool 减少模型采样损失,使用DSConv 减少模型参数,设计一种记忆性特征融合网络充分利用特征信息。
实验结果证明,改进后的方法在BDD100K 和Bosch 数据集上使AP 分别提高了11.0 个百分点和9.3个百分点,检测速度最慢也在40 frame/s。在不同的尺度、场景、天气和时间条件下,改进后的模型均有较大的提升,最多提升了25.4 个百分点,有效增加了模型的鲁棒性和小目标提取能力。本文通过改进YOLOv5 模型,增加了模型的检测能力,提高了模型的鲁棒性,做到了准确和实时的交通灯检测。
