协同级联网络和对抗网络的目标检测
2022-01-18李志欣陈圣嘉马慧芳
李志欣,陈圣嘉,周 韬,马慧芳
1.广西师范大学 广西多源信息挖掘与安全重点实验室,广西 桂林541004
2.西北师范大学 计算机科学与工程学院,兰州730070
目标检测是计算机视觉的基本问题之一,近年来由于深度学习的发展,这一问题在性能上取得了实质性的提高。众所周知,普遍的目标检测器是把检测问题转化为对候选框进行分类的问题。随着卷积神经网络(convolutional neural network,CNN)在图像识别任务上的广泛成功,越来越多基于CNN的目标检测方法被提出。这些结构多样的方法在一定程度上提高了目标检测的准确性,其中许多方法实现了在多个基准数据集上的实时性能。然而,图像通常包含遮挡目标和小目标,当前的目标检测方法对这些目标并不敏感,因此不可避免地限制了目标检测的性能。图1 通过实例展示了这种检测中存在的缺陷,检测缺陷已用红色箭头标注。在图1(a)中有几个可见的结果:(1)从图中左上角可以清楚看到,完整的公交车能准确检测出来,而旁边被遮挡的公交车没有被检测出;(2)图中一个人正在骑自行车,由于自行车被人遮挡,基线检测器只检测出人,完全忽略掉自行车;(3)一个距离较远穿着蓝色衣服的人,由于目标很小也被完全忽略。结果(1)和(2)说明检测器只关注目标的整体特征,而对不完整目标的局部特征不敏感,即对遮挡或变形目标的表征能力较弱,从而会影响检测器的性能。如果能结合遮挡或变形目标的特征,这些检测缺失就能避免。结果(3)说明检测器缺乏对小尺度目标特征的捕获能力,对小目标检测性能较弱。在图1(b)中,最右边的女人被小孩遮挡住了头部,而他们都是小尺度目标,检测器没能检测出,说明检测器没有捕获足够检测小尺度目标所需的细节特征。但是如果能通过多尺度深度特征融合来增强对小尺度目标特征的捕获,再提高对检测遮挡目标的敏感性,就可以在图像中检测更多的目标。

图1 一些典型的Faster R-CNN 检测缺陷Fig.1 Some typical detection defects of Faster R-CNN
综上所述,对遮挡目标和小目标的检测是提高目标检测性能必须要解决的关键问题。一般来说,小目标检测的相关问题实际上是检测涉及不同大小尺度目标的问题,这使小目标的检测变得更具挑战性。当前的目标检测方法通过生成不同尺度的特征表示来适应小目标检测。大量研究表明,多尺度特征图生成的特征表示能增强对小目标的检测能力,尤其是大尺度特征图。因此需要设计一种多尺度特征提取方法并将其集成到模型中,以提高检测器对小目标的敏感性。而针对增强遮挡目标检测敏感性的问题,通常是通过在大型数据集中学习覆盖大量视觉特征的变化来解决。然而,在数据集中捕获所有可能的遮挡样本是不可能的,即使在非常大的数据集中,低概率的遮挡目标也不会轻易得到。并且,通过收集更大的数据集来解决这个问题是非常低效的。因此考虑尝试使用对抗网络来生成所需要的遮挡目标样本。
在R-CNN(region-convolutional neural network)系列模型的基础上,本文提出一种协同级联网络和对抗网络的方法,称为Collaborative R-CNN。该方法对Faster R-CNN架构进行改进构造级联网络,从多标签数据中提取不同尺度目标的特征,并通过多尺度深度特征融合来增强检测小目标的能力。同时,设计了一种多尺度池化操作,通过添加多尺度池化来调整网络对不同大小目标的检测能力。此外,训练对抗空间失活网络(adversarial spatial dropout network,ASDN)生成包含遮挡目标的训练样本,可以显著影响模型的分类能力,提高模型对遮挡目标的鲁棒性。在PASCAL VOC 数据集上的实验结果表明,该方法相比其他几种先进的方法更有效准确。本文主要的贡献包括:
(1)对Faster R-CNN 进行改进,提出级联网络;
(2)提出多尺度RoIAlign(region of interest align)池化来调整对不同大小目标的检测能力;
(3)改进ASDN 对抗网络,生成带有硬遮挡的样本来提升模型对遮挡物体的识别能力;
(4)设计协同级联网络和对抗网络的总体架构进行目标检测。
1 相关工作
当前目标检测模型通常基于两种方法:(1)基于候选区域的方法将目标检测任务划分为两个阶段,也即两阶段目标检测方法。在第一阶段,将候选区域生成网络(region proposal network,RPN)连接到一个CNN 上,从候选区域中提取特征,生成高质量的候选框;在第二阶段,设计一个区域子网络对候选框进行分类和边界框回归。(2)基于回归的方法则将目标检测任务视为一个阶段,称为一阶段目标检测方法,直接对目标进行分类和回归。
随着CNN 的兴起,两阶段方法如R-CNN、Fast R-CNN、Faster R-CNN等成为目标检测的主流。R-CNN 采用选择性搜索方法提取候选区域,采用线性支持向量机作为候选区域的分类器。然而对于R-CNN 来说,生成候选区域的过程在计算上是缓慢的。为了提高候选区域生成过程的计算速度,Fast RCNN 提出了RoIPooling(region of interest pooling),得到固定大小的相应特征图,方便进行后续操作,极大提高了处理速度。Faster R-CNN 用候选区域网络代替选择性搜索方法,进一步提高了候选区域生成的计算速度。同时,卷积层与框架其他部分共享参数,实现了整个网络的端到端训练。Faster R-CNN 在PASCAL VOC 2007 数据集上获得了69.9%的性能,成为当时最具代表性的方法。一阶段目标检测方法如SSD(single shot multibox detector)、YOLO(you only look once)和RON(reverse connection with objectness prior networks)等也得到了很大发展。这些方法直接计算候选目标,不依赖于候选区域,因此计算速度比两阶段方法快。这些方法对显著的、常规的目标具有较好的检测性能,但对小目标和遮挡目标的识别准确率不高。此外,一些新的方法也使目标检测的性能上了新的台阶。
当前目标检测的效果与大规模数据集的应用密切相关。但对检测遮挡目标问题,即使在大规模数据集中,一些罕见的遮挡样本也并不容易找到。然而,通过添加罕见的遮挡目标样本来扩充数据集的方法低效且成本昂贵。本文方法不是试图收集罕见的遮挡目标样本来扩充数据集,而是自主生成罕见的遮挡目标样本。生成对抗网络将生成问题视作判别器和生成器这两个网络的对抗和博弈:生成器从给定噪声中生成合成数据,判别器分辨生成器的输出和真实数据。前者试图生成更接近真实的数据,相应地,后者试图更完美地分辨真实数据与生成数据。两个网络在对抗中进步,在进步后继续对抗,由生成对抗网络得到的数据也就趋于完美,逼近真实数据,从而可以生成想得到的数据,如图片、序列、视频等。A-Fast-RCNN(adversary fast R-CNN)提出通过训练对抗网络的方法来生成低概率的对抗性样本,以避免依赖大规模数据集来捕捉所有可能的视觉概念变化,得到了良好的性能。这也启发了使用对抗网络的方法来提高模型识别遮挡目标的能力。此外,还有其他方法提出使用级联网络来识别遮挡或不可见的关键点,采用1×1 卷积层来减少网络参数的数量,从而加快计算速度。尽管这些方法使目标检测有了很大进步,但是都不能在识别小目标和遮挡目标的同时,取得良好的性能和速度。
相比之下,本文方法结合了高效的网络结构、深度特征融合、多尺度池化和更有效的训练策略,充分利用CNN 进行目标检测,能在不大幅度降低计算速度的前提下提取不同尺度特征。该方法与对抗网络相结合,能够适应多标签图像中目标特征的广泛变化,泛化能力更好,鲁棒性更强,从而增强了目标检测的性能。
2 级联网络
2.1 改进的Faster R-CNN 模型
一般来说,CNN 中不同深度的特征对应着不同层次的语义信息。深层网络提取的特征包含更多的高级语义信息,而浅层网络提取的特征则包含更多的细节特征。随着网络深度的增加,特征图变得越来越抽象,细节信息所占的比例越小,对小目标的识别效果就越差。目前几乎所有图像分类和目标检测性能较好的方法都采用特征金字塔的方法来解决这一问题。然而,这种方法是计算密集型的,会严重影响模型的计算速度,因此需要通过修改网络结构来提高对多尺度目标的识别能力。
VGG16 模型已证实增加网络的深度能对网络产生积极影响。VGG16 模型的卷积层通过采用多个小3×3 卷积核来增加网络的深度,并同时减少参数的数量,从而减少了模型的计算复杂度。此外,与采用大卷积核的模型AlexNet相比,使用更小的卷积核有利于使用更多的滤波器,进而促进了更多激活函数的使用,进一步增强模型对更复杂的模式和概念的学习能力。然而,针对小目标和数据比较稀疏的情况下,小卷积核只有较小的感受野,只能提供较少的关于目标的尺寸、形状和位置的信息。并且,在深度网络的计算过程中,对特征图填充的边缘特征进行多次卷积,导致最后的特征图损失了很多细节特征,从而增加了错误的概率。相比之下,较大的卷积核拥有更大的感受野可以捕获更多的细节特征和空间上下文信息,有助于识别具有更多空间上下文关系的目标和具有不同尺度的目标。虽然增加卷积核数量对提高网络针对复杂概念特征表示有积极作用,但是卷积核数量的增加会导致网络参数数量增加。大卷积核拥有大的感受野,也意味着更多的参数,如果卷积层给网络带来大量参数,这无疑会限制系统性能。在级联网络中,卷积核的数量主要由参数的数量决定,因此在提高性能同时必须控制参数的数量,需要在网络特征表示的质量和计算性能之间进行最优权衡。
为解决这一问题,设计了基于Faster R-CNN 模型的级联网络结构,如图2 所示。该级联网络结构在原有的VGG16 模型基础上增加了两个浅层网络,其中一层包含5 个5×5 卷积核,另一层包含3 个7×7卷积核。此外,在原始VGG16 模型基础上增加了两个浅层网络,使得最终的输出特征图大小与VGG16模型相同,但分辨率更高,使得目标的特征信息更加详细。由于高分辨率的特征图具有更多的特征信息,使得特征深度融合后的级联网络包含更多的目标特征信息,即网络既包含深度语义信息又包含目标的细节特征信息,而这些细节特征正是检测小目标所最需要的。每个级联网络具有相同数量的池化层,确保用于融合的特征映射在大小上是一致的。拼接层用于拼接特征图并保持融合后特征图的大小不变,同时使得模型有更多的特征表示。此外,将批量归一化添加到每个卷积层后,可以提高训练速度和分类的效果。综合级联网络和多尺度RoIAlign的改进模型称为Improved R-CNN 模型。

图2 Improved R-CNN 模型的网络结构Fig.2 Network structure of Improved R-CNN model
如图3 所示,将Faster R-CNN 预训练模型的参数直接迁移到Improved R-CNN 模型中,可以减少训练时间。将Faster R-CNN 的参数迁移到Improved RCNN,实际上是对Faster R-CNN 的骨干网络VGG16模型的参数迁移。在预训练模型的基础上进行迁移学习,可以提高系统的精度。这个过程称为微调,将改善最终结果。具体的,通过调用预训练模型VGG16 的参数,把VGG16 的参数作为级联网络的部分固定参数,采用参数冻结不进行训练,以加快网络收敛速度。最后,训练级联网络的活动参数,微调全连接层来实现迁移学习。由于在Improved R-CNN模型中使用多尺度RoIAlign 改变了全连接层第6 层FC6 层的维度,Faster R-CNN 预训练的参数不对FC6层进行传递。参数传递之后,对Improved R-CNN 模型进行额外训练,对参数进行微调。Zhang 等人研究了全连接层在视觉表示迁移中的作用。通过对预训练模型进行微调,全连接层在实现目标域的高精度方面起着重要作用。全连接层在CNN 中起到将学到的具有高语义信息的特征表示映射到样本标记空间的作用。不含全连接层的网络微调后的结果不如含全连接层的网络,全连接层可以保证网络表示能力迁移的效果。因此,迁移的FC7 层可以看作保证迁移模型参数表示能力的一种方法。
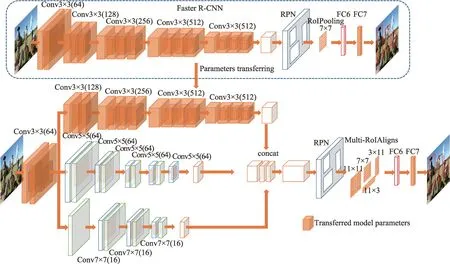
图3 Faster R-CNN 参数迁移到Improved R-CNNFig.3 Faster R-CNN parameters transferred to Improved R-CNN
2.2 多尺度RoIAlign
RoIPooling 操作是从RoI中提取小特征图(例如,7×7 尺寸)的标准操作。首先,RoIPooling 将一个浮点数字的RoI 量化到特征图的离散粒度,然后将这个量化的RoI 划分为多个区间,这些区间本身也进行了量化,最后将每个区间的特征值进行聚合(通常通过最大池化操作)。例如,输入图像在VGG16 最后一层得到的特征图的尺寸为/32,RoIPooling 进行第一次量化,使特征图变为round(/32),round(·)函数表示取整。第二次量化是在池化过程中进行取整。因此,RoIPooling 操作还打破了像素到像素的平移同变性,并且像素间偏移产生的误差会对小目标的识别能力造成极大的限制。这些量化使特征图在池化过程中损失掉很多细节特征,并导致了RoI 和提取的特征之间的不匹配问题。虽然这些量化对检测较大目标的鲁棒性影响不大,但严重影响了检测小目标需要达到的像素级精度目标框。因此,本文方法采用了Mask R-CNN中提出的池化操作RoIAlign,消除了RoIPooling 的苛刻的量化,并正确地将提取的特征与输入对齐。RoIPooling 和RoIAlign 的操作过程如图4 所示,图中虚线网格表示特征图,有色区域表示RoI,池化尺寸为(2×2),4 个点表示每个区间中的采样点。RoIAlign 根据特征图上邻近的网格点,通过双线性插值计算每个采样点的值,没有对RoI 或采样点中涉及的任何坐标进行量化。RoIAlign 避免了RoI边界或细分区间的任何量化(例如,它应用/32 而不是round(/32)),采用双线性插值方法计算每个RoI中4 个规则采样点的输入特征值,并利用最大池化操作对特征图进行聚合。

图4 RoIPooling 和RoIAlign 的操作过程Fig.4 Operation process of RoIPooling and RoIAlign
Faster R-CNN 在生成特征图的过程中容易丢失大量的目标局部信息,严重影响其小目标检测的性能。例如,最初64×64 像素大小的目标在卷积层的最后一层只剩下2×2 像素大小。这一问题可通过在候选区域生成网络中放大特征图和使用较小尺度的锚(anchor)来解决。Faster R-CNN 框架对RPN 生成的每个RoI 的特征图应用了池化大小为7×7 的RoIPooling 操作。然而,在使用单一尺度池化时,捕获不同大小尺度的目标特征非常困难。本文提出的多尺度RoIAlign 相比单尺度RoIPooling 在捕获不同大小尺度目标特征方法具有较大优势。多尺度池化可以更好捕获数据集中多尺度目标的特征信息,更符合客观世界目标的实际尺度,以及为RPN 获取复杂的候选区域特征提供更好的辅助作用。池化大小是依据目标在数据集中可能存在的尺度种类以及常规物体的高宽比来进行设置。设置高宽比大于1 的池化大小可隐式地捕获特征图中垂直的空间特征信息,高宽比小于1 的池化大小可隐式地捕获水平的空间特征信息。通过实验验证,发现设置池化大小为11×3、3×11 和11×11 模型性能达到最佳。本文方法通过应用11×3 和3×11 这两种尺度的池化来解决捕获不同尺度的目标特征困难的问题。11×3 大小的池化旨在捕获更多的水平特征,即有助于检测宽度远远大于高度的目标。相反,3×11 大小的池化可以捕获更多的垂直特征,即有助于检测高度远远大于宽度的目标。此外,还增加了一个11×11 大小的池化,以增强所提出模型检测小尺度目标的鲁棒性。
提出的多尺度RoIAlign 操作可以在尺度多变目标的情况下提取特征,从而提高目标检测的精度。此外,还采用了更小尺度的锚来增强检测小目标的能力。Faster R-CNN 的RPN 用特征图进行预测,锚为3种尺度(128,256,512)和3种比例(1∶1,1∶2,2∶1),即特征图上每个位置设置9 种参考锚,这些大约能覆盖边长70~768尺度的目标。但对于更小的目标,现有尺度的锚无法准确定位,虽然极小的目标在PASCAL VOC 数据集中的占比较少,但这也不可避免地限制了模型的性能。在大型数据集中,极小的目标也有较多的数量。因此,本文方法增加了更小尺度的锚来适应小尺度目标,使得每个锚点产生12 种候选区域,覆盖了更多小尺度的目标。在原有锚的尺度(128,256,512)基础上增加了更小尺度的锚,使提出的模型使用了(64,128,256,512)的锚尺度,每种尺度3 种比例(1∶1,1∶2,2∶1),在RPN 中每个锚点产生12 个候选区域,用来适应小尺度目标。
2.3 特征过滤
特征过滤的整个过程如图5 所示。由于使用多尺度RoIAlign 操作导致后续的全连接层获得了更大的维度,必然增加了目标检测相关计算的时间消耗。为此,Improved R-CNN 模型也使用卷积层和池化层来减少全连接层的参数冗余。
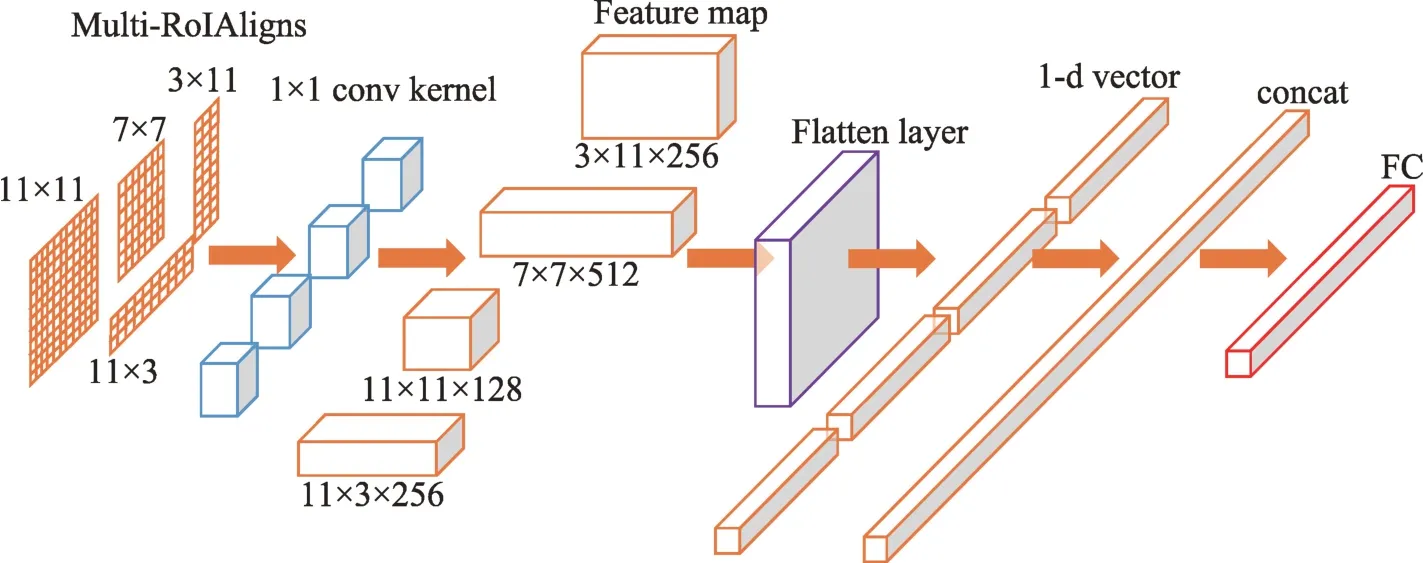
图5 特征过滤结构Fig.5 Feature filtering structure
众所周知,在多尺度RoIAlign 中得到的不同维度的特征不可能直接拼接。然而,正如R2CNN中使用的方法,可以通过过滤层来将池化得到的特征图(即多维矩阵)转化为一维向量。本文在使用过滤层之前,通过使用卷积核大小为1×1、步长大小为1 的卷积层来降低模型参数的数量,从而避免了在使用过滤层之前的参数冗余。使用1×1 卷积核的卷积操作能起到降维的作用,降维是指图像通道的数量(厚度)降低,而图像的宽度和高度没有改变。接下来分别减少了4 种池化得到的特征图维度,7×7 尺寸的池化得到的特征图维度降低到512,11×11 尺寸的池化得到的特征图维度降低到128,3×11 和11×3 池化的特征图维度降低到256。然后利用过滤层将汇聚的特征图转化为4 个一维向量,再利用拼接层将4 个向量进行拼接,最后把拼接后的向量传递到全连接层。
3 对抗网络
为训练对各种情况(如遮挡、变形目标)都具有很高鲁棒性的目标检测器,需要多样化的样本。但即使在大规模数据集中,也不可能覆盖所有潜在的含有遮挡和变形目标的样本。因此,这里采用了一种替代方法,不是依赖于数据集或筛选数据来寻找识别困难的样本,而是积极地生成目标检测器难以识别的样本。
首先对一个目标检测器网络()和对抗网络()的损失函数进行分析比较,其中是输入的一组特征矩阵,采用F()和F()来表示类别和预测的边界框位置输出。因此,()的损失函数E可以定义如下:

其中,和分别表示的真实类别和边界框位置。第一项是Softmax 损失,第二项是基于F()和的损失,即边界框的损失。对抗网络的目的是学习如何预测那些()无法准确分类的。因此,()为给定的生成新的对抗示例,然后将其添加到训练样本中。对抗网络()的损失函数定义如下:

对于容易被()分类的()生成的例子,会得到一个较低的E损失值,但会得到一个较高的E损失值。相反,对于()生成的例子,如果()很难对()生成的例子进行分类,则会获得较高的E值和较低的E值,因此这两个网络的任务完全相反。
3.1 ASDN
ASDN 用于对前景目标的深度特征进行遮挡。在标准的Faster R-CNN 中,可以在RoIPooing 层之后获得每个前景候选目标的卷积特征,因此可以使用这些基于区域的特征作为对抗网络的输入。给定目标的特征,ASDN 将生成一个掩膜,指示特征的哪些部分要失活,使检测器无法识别该目标。
本文将分级训练应用于ASDN,该训练方法已经在以前的工作中得到了应用。首先在一个多标签图像数据集上对ASDN 进行预训练,以获得适合ASDN 与Improved R-CNN 对联合训练时使用的数据集的初步感知。然后,通过修正所有网络层来训练ASDN,其框架如图6 所示。

图6 与Improved R-CNN 相结合的ASDN 框架Fig.6 Framework of ASDN combined with Improved R-CNN
ASDN 用于生成难以分类的包含遮挡目标的训练样本。ASDN 在卷积层、多尺度RoIAlign 池化层和全连接层上的结构与Improved R-CNN 框架相同。将RoIAlign 池化层之后的每个特征图的卷积特征作为ASDN 的输入。给定×大小的特征图,ASDN通过赋值0 来生成一个掩膜,代表需要遮挡的特征映射部分,这将使Improved R-CNN 获得更高的E损失值,引入更难分类的被遮挡目标的特征。这是通过应用一个/3×/3 滑动窗口来实现的,该滑动窗口删除所有通道中遮挡特征对应位置的值,从而生成一组新的特征向量。将以这种方式得到的所有新特征向量都传递到Softmax 损失层,计算损失函数,并选择损失值最大的特征向量。然后,在特征图中创建一个单一的×掩膜,其中央位置像素为1,其他像素为0。窗口滑动是将窗口映射回图像通过筛选来选择硬遮挡样本,并把其作为训练ASDN 的真实样本,如图7(a)所示。这样,ASDN 为个特征图生成空间掩膜,得到个使目标检测器损失值很大的训练样本。ASDN 的训练利用下面的二元交叉熵损失函数:

图7 ASDN 训练中选择和生成样本的实例Fig.7 Instances of selecting and generating samples in ASDN training
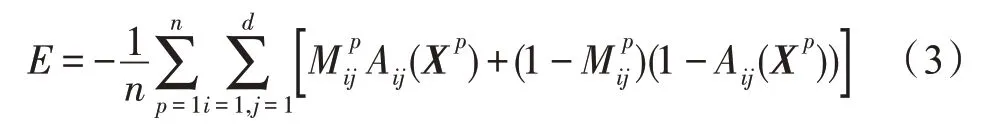
其中,对抗网络表示为(),它得到在图像上计算出的特征,并生成一个新的对抗样本。为个正样本候选区域生成空间掩膜,并为对抗失活网络获得对训练样本{(,),(,),…,(X,M}。A(X表示ASDN 给定的输入特征图X在位置(,)处的输出。M表示掩膜第行第列的值。如果M=1,则删除特征图对应空间位置中所有通道的值。
ASDN 使用重要性抽样法来选择热力图中1/3 的像素,并把这些像素赋值为1,其余的2/3 像素赋值为0。ASDN 网络的输出不是一个二值掩膜而是连续的热力图。因此,要生成二值掩膜,不是直接阈值化热力图,而是通过重要性抽样法选取阈值来生成二值掩膜。在训练过程中,抽样过程结合了样本的随机性和多样性。ASDN 网络输出的热力图,使对整张图像越重要的像素热力区域越突出,例如目标通常会成为图像中最重要的像素热力区域。因此,在使用重要性抽样法来选择图像中重要的像素来生成遮挡掩膜的过程中需要控制阈值的大小。如果阈值过大,生成的二值掩膜会覆盖一部分目标的非重要像素区域;如果阈值过小,目标的一些最重要的像素区域会覆盖不完全。因此,本文通过实验验证和参考ASDN 网络对重要性抽样法阈值的设置,来确定阈值的选取。结果显示当阈值选取1/3 时,得到的二值掩膜效果最好。
图7(b)展示了ASDN 生成的遮挡掩膜实例,其中黑色区域表示被遮挡的部分,表示对分类最重要的像素。硬遮挡样本的应用在ASDN 学习过程中产生高的损失值,可以识别出对分类来说最重要的目标的像素部分。在本例中,使用掩膜来遮挡这些部分的像素,使分类更加困难。
3.2 联合训练
在联合模型中,ASDN 与Improved R-CNN 模型共享卷积层和池化层,但各自使用自己独立的全连接层。当然,这两个网络的参数必须根据所面临的任务进行独立优化。为了训练Improved R-CNN 模型,首先在正向传播训练阶段使用预训练的ASDN 生成掩膜,在池化层之后生成修改后的特征图,然后将修改后的特征传递给Improved R-CNN 模型,计算损失并进行模型训练。虽然修改了特征,但是它们的标签没有改变。通过这种方式,确保在训练Improved R-CNN 模型时引入更困难的和更多样化的样本,并在对有遮挡的目标进行分类时获得更高的鲁棒性。对于ASDN 的训练,使用采样策略将热力图转换为二值掩膜,使得分类损失的计算不可微,因此训练过程中无法利用分类损失的梯度进行反向传播。与AFast-RCNN 相同,只有硬示例掩膜被用作真实样本来训练对抗网络,方法是使用与式(3)中描述的相同的损失来计算那些导致检测器分类分数显著下降的二值掩膜。
4 实验
4.1 数据集和评估指标
实验中使用的PASCAL VOC 2007 和PASCAL VOC 2012 数据集分别包含9 963 幅和22 531 幅图像,并划分为训练集、验证集和测试集。实验把PASCAL VOC 2007 数据集划分为5 011 幅图像的训练验证集和4 952 幅图像的测试集,把PASCAL VOC 2012 数据集划分为11 540 幅图像的训练验证集和10 991 幅图像的测试集。以平均精度(average precision,AP)和平均精度均值(mean average precision,mAP)作为评价指标,符合PASCAL 挑战赛规定。测试速度和模型收敛速度也是评估模型性能的重要指标,实验将Collaborative R-CNN 的速度与几种先进方法进行了比较,包括Faster R-CNN、A-Fast-RCNN、SSD和RON。所有实验结果都在一台配置了Intel Core i7 4.20 GHz时钟频率的处理器,GTX 1080 Ti GPU 和16 GB 内存的电脑上运行得到。
4.2 模型收敛和联合模型训练
本文首先通过PASCAL VOC 2007 训练集将Collaborative R-CNN 参数初始化并训练Faster R-CNN。为了适应Collaborative R-CNN 模型中全连接层FC6尺寸的变化,该层由0 均值高斯分布初始化,标准差为0.01,学习率设为0.01,基于0.9 的动量和0.000 5 的权重衰减值,并设置每20 个epoch 学习率降低至当前的10%,共60 个epoch。对于Faster R-CNN 模型和Collaborative R-CNN 模型的训练包括一系列迭代,设置为60 个epoch,其中每个epoch 包含2 000 次迭代。mAP分数是在模型的迭代过程中计算得到的,训练模型的mAP分数在40个epoch之前,70 000迭代次数之后开始收敛。在这70 000 迭代次数后,Collaborative R-CNN 模型的mAP 得分为77.5%,而Faster R-CNN训练模型的mAP 得分为73.2%。这些结果表明,Collaborative R-CNN模型比Faster R-CNN模型具有更快的收敛速度。ASDN 经过12 000 次迭代的预训练,然后联合模型进行120 000 次迭代训练。再次采用了变化的学习率,采用了前一部分使用的动量和权重衰减值,初始学习率为0.001,迭代60 000 后下降到0.000 1。
4.3 消融实验
消融实验的目的是评估不同尺度的锚和不同尺度池化等改进方法对训练模型在PASCAL VOC 2007数据集上目标检测性能的影响。实验包括了Faster R-CNN 基线模型和改变了锚尺度的Faster R-CNN;级联网络是一个与Improved R-CNN 等效的网络结构,但采用RoIPooling 操作,而Improved R-CNN 采用的是多尺度RoIAlign 操作;以及综合所有方法的Collaborative R-CNN。虽然RoIPooling 也能捕捉到目标的不同尺度特征,但与RoIAlign 相比,其模型的准确率较低。RoIAlign 消除了对RoIPooling 的严格量化,因而能正确地将提取的特征与感兴趣区域对齐。RoIPooling 的量化导致了感兴趣区域和提取特征之间产生了不匹配问题。这些量化打破了像素到像素的平移同变性,同时会导致一些特征信息的丢失。虽然这不会对大目标的检测精度产生较大影响,但对于小目标,量化问题会降低检测准确率。
消融实验结果如表1 所示。结果表明,本文增加了更小尺度锚使得性能得到了略微提高,也隐含地说明了本文方法能捕获更小尺度的目标,提升了模型检测小目标能力,使得最终的mAP 得到了提升。消融实验是在PASCAL VOC 2007 数据集上进行的,测试集中极小目标数量较少,在这种情况下也能提升性能说明了本文方法的优越性,也表明了采用更小尺度锚的方法具有很大潜力。此外,更多尺度的锚也意味着更多的候选区域特征信息,为后续操作提供更有意义的目标信息,在整个网络中起到了承上启下的作用。采用4 个尺度(3×11,11×3,7×7,11×11)池化的级联网络比采用单尺度(7×7)的池化的Faster R-CNN 性能更好,也比采用单尺度(7×7)的池化和3 个尺寸(3×11,11×3,7×7)的池化的级联网络性能更好。首先,这些结果证明了所提出的多尺度RoIAlign 操作相对于标准RoIPooling 操作的优势,因为多尺度RoIAlign 操作增强了提取多变尺度目标特征的能力。其次,这些结果表明,提出的级联网络对模型性能的增加有积极影响,并且级联网络可以捕获更多尺度的特征信息,从而能够检测更多不同大小目标,即多尺度的目标。随着网络深度的增加,特征图越来越抽象,一些特征信息在通过卷积和池化后逐渐被忽略,特别对于小目标将损失很多特征信息。并且较深的网络产生的低分辨率特征图不利于小目标的识别。而提出的级联网络结构深度融合多尺度特征信息,提供了小目标检测所需要的更多的细节特征信息,从而增强了小目标检测的性能。最后,这些结果证明了使用水平尺度(11×3)池化和垂直尺度(3×11)池化的优势,说明添加11×11 尺度的池化可以提高级联网络的目标检测性能,也证明了多尺度池化的有效性。表中FT(fine-tuning)表示微调,通过固定部分参数进行训练,对提高模型性能也有很大贡献。表中的结果清楚地表明,与Improved R-CNN 模型的结果相比,包含ASDN 的Collaborative R-CNN 增加了2.3 个百分点的性能,反映了ASDN 对抗网络生成的遮挡样本对性能提高有显著影响。

表1 在PASCAL VOC 2007 数据集上的消融实验结果Table 1 Results of ablation experiments on PASCAL VOC 2007 dataset
4.4 结果分析
表2 和表3 分别列出了在PASCAL VOC 2007 和PASCAL VOC 2012 数据集中Collaborative R-CNN 和各种先进方法获得的各种图像种类的AP 值和综合的mAP 值。实验结果表明,所提出方法的检测性能明显优于Faster R-CNN,且对鸟类(bird)和植物(plant)等小目标的检测性能有了显著提高。虽然在PASCAL VOC 2007 数据集上RON 方法得到的mAP值略大于提出的Collaborative R-CNN 方法,但也相当接近。以上实验结果证明了本文方法的有效性。

表2 在PASCAL VOC 2007 数据集上的目标检测实验结果Table 2 Experimental results of object detection on PASCAL VOC 2007 dataset

表3 在PASCAL VOC 2012 数据集上的目标检测实验结果Table 3 Experimental results of object detection on PASCAL VOC 2012 dataset %
Collaborative R-CNN 在PASCAL VOC 2007 和PASCAL VOC 2012 数据集的目标检测定性实验结果如图8 所示。这些例子定性地证明了Collaborative R-CNN 能够检测具有不同大小和宽高比的物体,并且能够很好地定位它们的位置,特别是对于飞机、鸟类和人这样的目标能够准确检测出来。实验结果也证明了提出的方法对遮挡目标的鲁棒性,例如图像中的汽车、植物和人能够准确检测。图9比较了Collaborative RCNN和Faster R-CNN在PASCAL VOC 2007和PASCAL VOC 2012 数据集上的一些目标检测定性实验结果。这些例子展示了两种方法对小目标和被遮挡目标的检测性能。在每对检测结果中(顶部与底部),顶部是Faster R-CNN 的检测结果,底部是Collaborative R-CNN 的检测结果。

图8 在PASCAL VOC 2007 和PASCAL VOC 2012 数据集上的实验结果Fig.8 Experimental results on PASCAL VOC 2007 and PASCAL VOC 2012 datasets
图9(a)中,被遮挡的公交车、自行车和人被Faster R-CNN 忽略了,而Collaborative R-CNN 正确地把这些模糊的目标进行了标注。图9(b)中,最右边的妇女怀里抱着一个小孩,并且小孩遮挡住了妇女上半部分身体,这既是小目标也是被遮挡目标。在这种情况下,Faster R-CNN 在图像中这个位置没有检测出任何目标,而使用提出的方法将这个目标标注为一个人。这些检测结果使Faster R-CNN 和所提出的方法之间形成鲜明对比。图9(c)中,一把被遮挡的椅子被Faster R-CNN 忽略了,而提出的方法正确地将这个目标标注为椅子。这些例子说明了Collaborative R-CNN 与Faster R-CNN 相比,在检测小目标和被遮挡的目标时具有明显的优势。

图9 Faster R-CNN 和Collaborative R-CNN 的实验结果Fig.9 Experimental results of Faster R-CNN and Collaborative R-CNN
最后,表4 展示了两阶段方法和一阶段方法在PASCAL VOC 2012 数据集上的检测性能和计算时间,比较方法包括Faster R-CNN 和Collaborative RCNN以及SSD和RON。在这个实验中,获取每个图像目标检测的时间,并平均所有的检测时间(ms/image)。实验结果表明,两阶段法的计算准确度较高,但计算速度较低。可以看到,Collaborative R-CNN 的计算速度低于Faster R-CNN,这是因为多尺度RoIAlign 操作比RoIPooling 操作要消耗更多的计算时间。由于两者之间的计算时间差异较小,Collaborative R-CNN 仍然满足实时目标检测的要求。综合来看,Collaborative R-CNN 与Faster R-CNN 相比,只略微降低了计算速度,但显著提高了检测性能。

表4 在PASCAL VOC 2012 数据集上的实验结果Table 4 Experimental results on PASCAL VOC 2012 dataset
5 结束语
本文提出了Collaborative R-CNN,通过增强对小目标和遮挡目标的检测能力提升目标检测性能。利用级联网络和多尺度RoIAlign 操作深度融合了多尺度特征,并获得了语义多尺度特征表示,使模型能适应不同尺寸和宽高比的目标,如人、车和飞机等,显著提高了对小目标的检测性能。将ASDN 与提出的级联网络相结合,生成能够明显提高模型分类能力的被遮挡训练样本,提高了模型对遮挡目标的鲁棒性。在PASCAL VOC 2007 和PASCAL VOC 2012 数据集上将本文方法与各种先进方法进行了对比,实验结果表明Collaborative R-CNN 与Faster R-CNN 相比具有更高的检测准确率,并对小目标和遮挡目标的检测性能显著提升,但检测速度降低不明显。
