基于传感器网络与高斯过程回归的楼宇负荷预测
2021-12-20黄银燕于超黄文新覃智君毕乐明杨琳
黄银燕,于超,黄文新,覃智君,毕乐明,杨琳
(1. 广西大学电气工程学院,广西壮族自治区 南宁市 530004;2.广西万云科技有限公司,广西壮族自治区 南宁市 530022)
0 引言
我国建筑能耗快速上升,目前已占到总能耗的29%[1],因而楼宇节能问题已经引起工业界和学术界的广泛关注。针对该问题的主要解决思路是利用楼宇负荷预测促进楼宇节能方案的制定,实现建筑能耗的降低[2]。例如:通过楼宇负荷预测可以了解楼宇用电的高低峰,合理分配设备在用电峰谷时段的用电需求[3]。
楼宇负荷受多方面因素影响,预测精度难以大幅提高。因此,本文将进一步挖掘影响负荷波动的因素,提升楼宇负荷预测模型的准确度。在建筑研究领域中,一般采用建筑占有率表示人员在建筑中的存在情况[4]。2019 年发表在Nature 杂志上的文献[5]提出建筑占有率是影响建筑能耗的特征之一,准确的建筑占有率对建筑能耗预测至关重要。该文献提出了一种检测移动手机信号得出楼宇中建筑占有率数据的方法。但该方法存在操作繁杂、泄露隐私等缺点。
在负荷预测领域,常用的预测算法有时间序列法、灰色预测法、回归分析法等[6-7]。时间序列法的运算速度比较快,但没有考虑影响负荷波动的因素,负荷预测误差较大[8];灰色预测法虽然预测精度较高,但其最佳参数难以确定[9]。高斯过程(Gaussian process,GP)回归是基于贝叶斯框架下的机器学习方法[10-11],对高维度、小样本的数据具有较强的处理能力,并具有容易实现、收敛性好、超参数自适应性等特点[12]。传统高斯过程回归是通过求取极大似然估计值获得模型最优超参数,模型容易产生过拟合现象,降低预测准确度。
针对传统高斯过程回归出现的过拟合问题,本文将通过求取超参数的最大后验估计值来解决。基于最大后验估计的高斯过程回归模型是对先验分布和似然函数的乘积求取最大值以获得最优超参数,可以降低模型的复杂程度,减少训练过程中过拟合情况的发生,且不会对样本集造成浪费[13-14]。但是最大后验估计无法获得一个封闭的解析解,为了求出最大后验估计值并确定唯一的高斯过程回归模型,本文采用基于采样的近似推断算法求取最大后验估计的数值解[15]。
高斯过程回归模型中的协方差函数反映了不同样本集之间的相似性和相关性,对高斯过程回归模型的预测性能起到关键作用[16],且不同协方差函数对相同数据集有不同的学习效果[17]。因此本文研究了常见的几种协方差函数的预测效果,并甄别出最优的协方差函数。
1 基于超宽频雷达的人员存在检测传感器
为了将准确的建筑占有率特征用于预测模型中,本文利用挪威Novelda 公司开发的人员存在检测传感器XeThru X4M300 构建检测系统,对室内人员实时计数。本文选用人员存在检测传感器获取建筑占有率的主要原因有以下3 点:1)该雷达传感器的检测范围广、测量精度高、穿透力强、适用于建筑占有率的测量;2)雷达传感器不同于其它直观的智能监控系统,可以保护室内人员的隐私,适用于私密性比较强的场合;3)雷达传感器不会受到温度、光照、恶劣天气等外部因素的影响。
本文所构建的实验平台如图1 所示,雷达传感器安装在房间天花板中。雷达传感器反射信号,形成点云,后台显示出3D 点云。比如,当室内有3 个人时,点云如图2 所示,通过点云聚类,可以判断人数为3。本文将传感器平台得到的建筑占有率数据,对数据集进行补充。

图1 雷达传感器网络Fig. 1 Radar sensor network
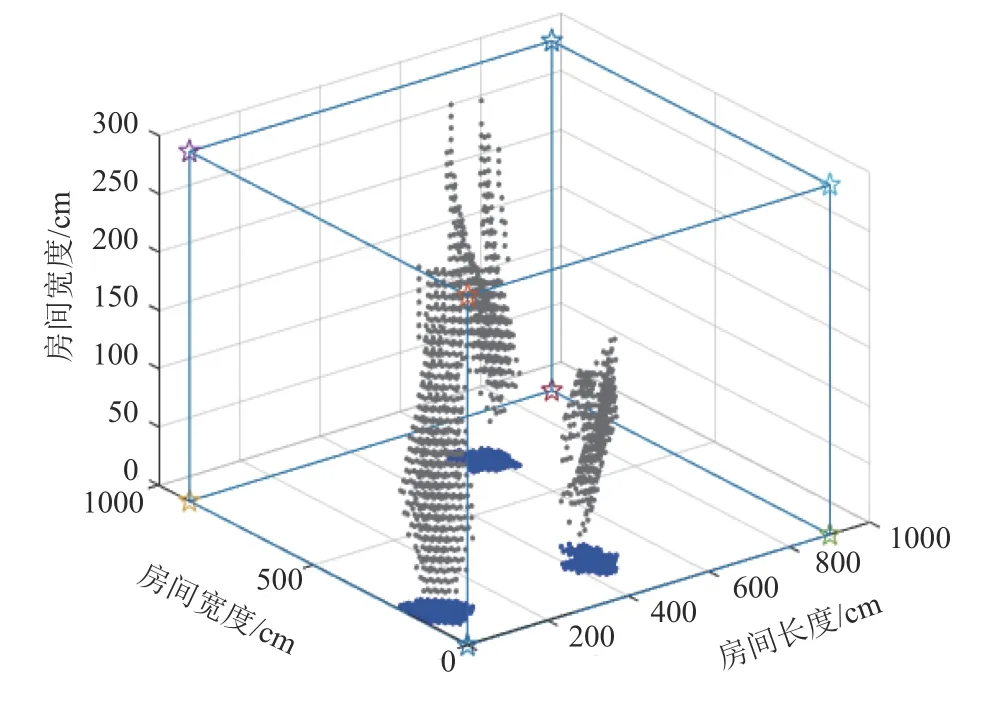
图2 传感器检测结果Fig. 2 Sensor detection results
2 高斯过程原理与预测模型构建
2.1 高斯过程
高斯过程回归模型可以从权重空间角度或函数空间角度来表示[18]。本文从函数空间的角度出发,定义一个高斯过程模型来描述函数分布。高斯过程实际上是一个无限元的随机变量的高斯分布,由无限维分布的均值函数m(x)和协方差函数K(x,x′)共同表示[19],对于任意的x和x′,高斯过程模型可以表示为
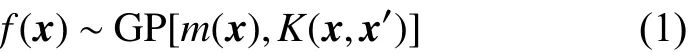
由公式(1)可知,空间中的每一个点都有一个与之对应的正态分布变量,高斯过程就是这无限多个随机变量的联合概率分布。
2.2 基于高斯过程回归的负荷预测模型
负荷预测过程中,可以定义函数空间f(x),f(x(1)),f(x(2)),···,f(x(n))构成随机变量的一个集合,服从联合高斯分布。假设观测负荷y有白噪声ε,即y=f(x)+ε。 ε是一个均值为0,方差为 σ2的服从高斯分布的独立随机变量,可表示为ε∼N(0,σ2)。因为噪声ε是完全独立于负荷函数f(x)的高斯白噪声,当f(x)服从高斯分布时,则负荷观测值y的联合分布的集合也是一个高斯过程。
本文构建高斯过程回归模型预测负荷时[20-25],训练集可由式(2)表示:
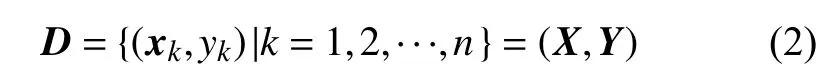
式中:xk∈Rd是d维特征矩阵;yk∈R是xk通过函数运算后的输出负荷值;n表示负荷训练集样本的数量;X={x1,x2,···,xn}表示训练输入矩阵;Y为训练输出变量。
n∗组测试集数据如式(3)所示:
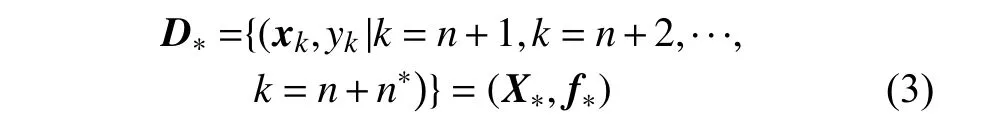
式中:X∗为包含多个特征的测试集数据;f∗为X∗经过函数输出的预测负荷。

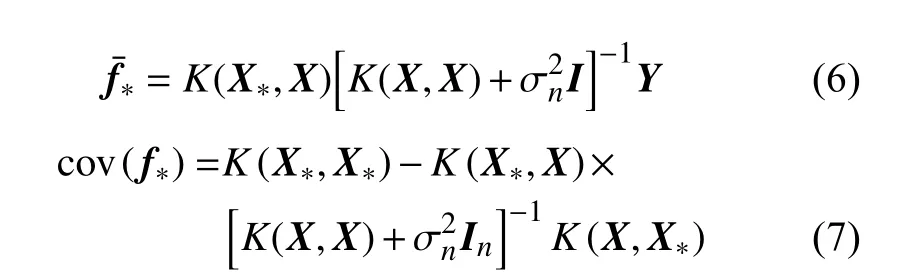
式中:f¯∗为测试集数据X∗经过高斯过程回归预测模型的均值向量;cov(f∗)为预测值对应的方差。
2.3 基于采样的超参数后验估计
本文基于PyMC3[15,26]提供的马尔科夫链蒙特卡洛(Markov Chain Monte Carlo,MCMC)方法对高斯过程回归模型的超参数进行采样,并获得其后验估计值。PyMC3 是一个概率图推断编程框架,允许用户利用贝叶斯机器学习方法构建模型并估计模型参数,具有很强的灵活性和适应性[27]。
2.3.1 协方差函数的选择
本文使用历史负荷数据对高斯过程回归模型进行训练,均值m=0,先验协方差函数选择Mateen类协方差函数、有理二次协方差函数和平方指数协方差函数,各协方差函数的具体描述如下文。
Matern 类协方差函数中不同的贝塞尔函数参数ν影响函数的光滑性,根据文献[28],ν=3/2和ν=5/2的Matern 类协方差函数分别由式(8)和式(9)表示:
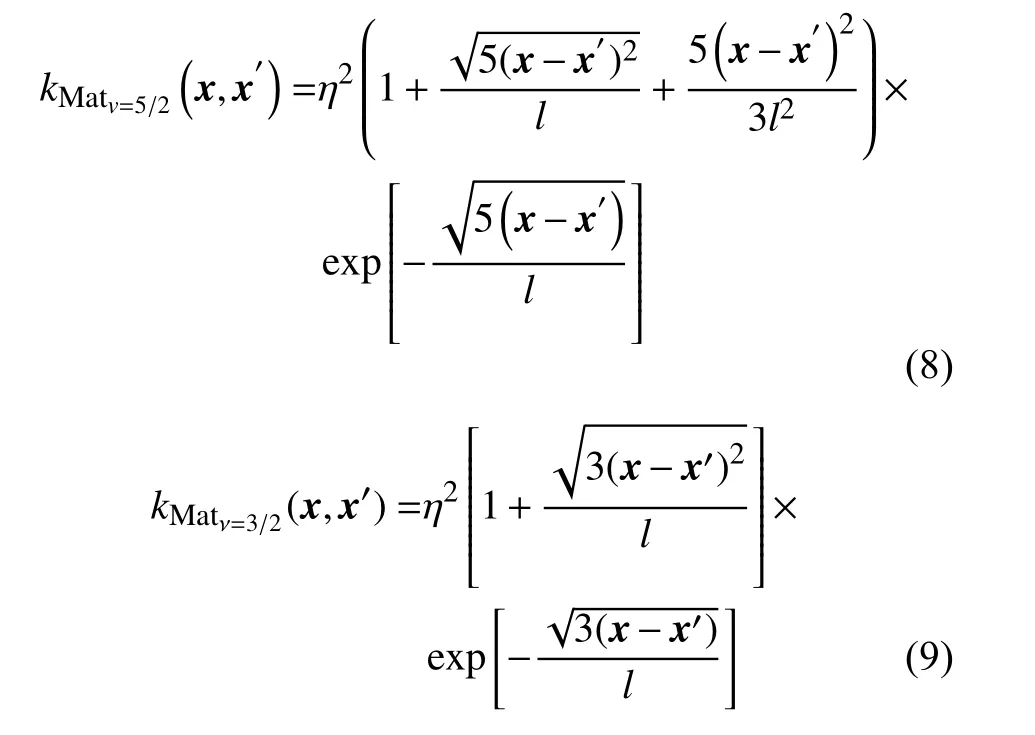
式中:超参数η为垂直尺度因子,有调节协方差函数变化的作用;超参数l为水平因子,起到对输入变量间的距离相对加权的作用。
有理二次(rational quadratic,RQ)协方差函数,根据文献[28],可由式(10)表示:
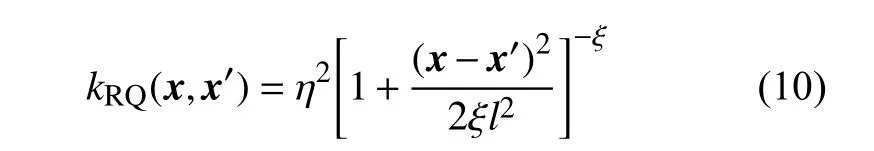
式中超参数ξ为调节协方差函数的衰减率因子。
平方指数(exponentiated quadratic,EQ)协方差函数,根据文献[29],可由式(11)表示:
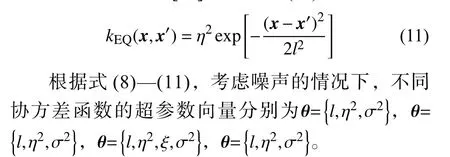
2.3.2 超参数优化
上文确定好了核函数的形式,下一步是对模型进行训练。根据文献[30],可知贝叶斯原理的公式如下:
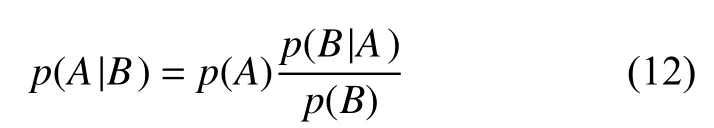
根据上式和文献[16]可知超参数的后验分布,如式(13)所示:

本文利用MCMC 方法获取超参数的最大后验估计值,主要思路是通过不掉向采样(no-u-turn sampler,NUTS)[31]得到参数的推断值。该做法的采样效率高,不必手动调整参数。
3 算例分析
本文为了验证以上模型以及实现负荷预测,获取了数据集1[32]和公开数据集2[33]进行实验。
3.1 数据准备
3.1.1 数据集1
本文对数据集1 进行预处理与分析,选用温度、风速、降雨量、当天为星期几、当天的第几个小时、是否假期等与负荷波动有关的因素作为训练特征。
本文数据的训练特征与负荷的分辨率均为1个小时,选取4 组训练集和对应的测试集,训练集为测试集前30 天的负荷数据,4 个测试集的时长均为2 天,样本数量为48。4 组训练集与测试集的起始时间划分情况见表1。
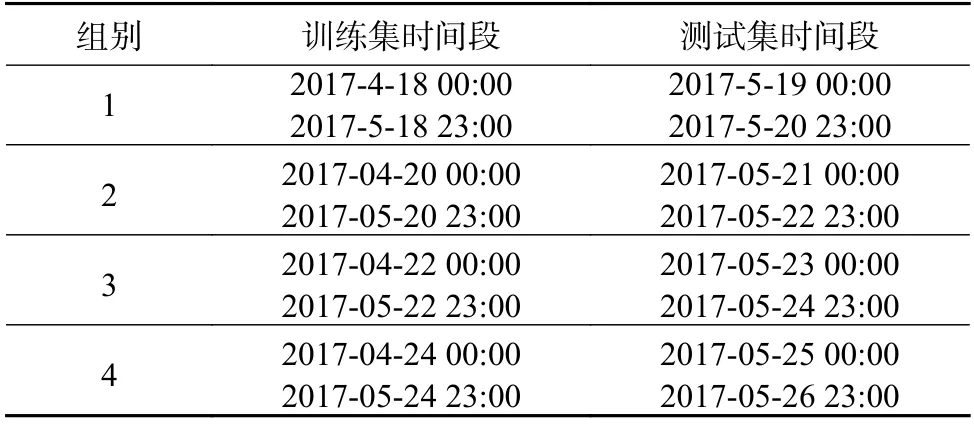
表1 训练集与测试集的划分Table 1 Division of train ing set and test ing set
3.1.2 数据集2
本文取得的数据集2 为美国哈佛大学某栋实验大楼的负荷数据,数据中包含历史负荷和天气状况等信息。根据用电日期和时间段来生成时间特征,比如:一年中的第几周、当天为星期几、一年当中的第几天、当天的第几个小时。实验数据中的历史负荷、天气特征、时间特征的分辨率都为1 h。本文的人员存在检测传感器平台搭建在国内某公司所在的大楼,该公司的作息时间与原数据的实验大楼基本一致,具有一定的参考性。平台每小时生成一次3D 点云,因此分辨率为1 h。本文将检测得到的建筑占有率信息归一化成0~1的数值,加入到原有的数据集中,作为楼宇负荷预测模型的新特征,并在后面的实验中分析增加该特征后预测效果的变化。
通过数据分析,训练集特征包括以下几个:建筑占有率、当天为周几、一年当中的第几天、一年中的第几周、当天的第几个小时和当地的风速。
本文对数据集2 预处理后,划分训练集,时间段从2013 年03 月20 日00:00 至2013 年04 月20 日23:00,训练集数据的分辨率为1 h。在数据存在缺失的情况下,训练集样本数量为768 个,即768 组实测数据。本文选取4 组测试集数据,第1 组是从2014 年04 月01 日00:00 至2014 年04 月02 日23:00,测试集样本数量为48 个。以时间类推,4 组测试集数据的划分见表2。
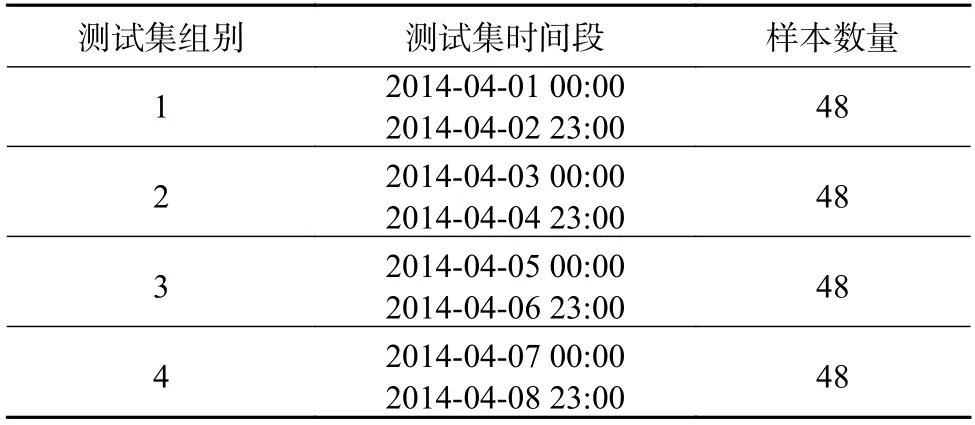
表2 测试集的划分Table 2 Division of test ing set
3.2 预测模型的评价指标
为了直观地判断负荷预测模型的准确度,本文引入几种常见的精度评价指标来评估模型的准确率,分别为均方根误差(root mean square error,RMSE)RMSE、平均绝对百分比误差(mean absolute percent error,MAPE)MAPE以及决定系数R2[34-37]。均方根误差和平均绝对百分比误差越低则预测准确度越高。决定系数R2是评价模型拟合程度的一个指标,越接近于1 则表明拟合程度越高[37]。各评价指标的计算公式如下:

3.3 实验结果
3.3.1 最大后验估计法与极大似然估计法的预测准确度对比
本次实验数据采用数据集1,高斯过程回归预测模型的协方差函数采用Matern32 函数,分别利用最大后验估计法与极大似然估计法求取模型的超参数。2 种方法的参数设置及实现过程如下文所述。
模型求取参数的最大后验估计值时,水平因子l和衰减率因子ξ的先验分布设置为Gamma 分布,噪声σ、垂直度因子η的先验分布设置为Half-Cauchy 分布。经过网格搜索确定各先验分布的设置如下:
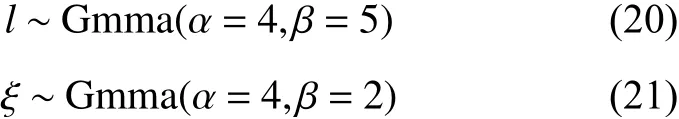
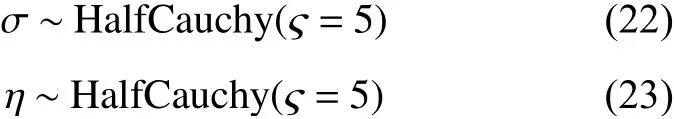
式中:α为Gamma 分布的形状参数;β为逆尺度参数; ς为Half-Cauchy 分布的尺度参数。
模型求取超参数的极大似然估计值时,接入Scikit-learn 库的高斯过程回归函数接口进行计算,采用拟牛顿 (Broyden-Fletcher-Goldfarb-Shanno,BFGS)[38]算法对参数进行优化。
本次实验采取同样的训练集训练上述2 个不同的模型,对同样4 个测试集的数据进行预测。经过模型训练与测试,得到的预测结果见表3。根据表3 中各项评估指标数据显示,测试集1—4中,最大后验估计法和极大似然估计法比较,MAPE值分别降低了5.12%、0.41%、9.46%、9.87%,R2分别提高了0.28、0.02、0.07、0.12,说明参数基于最大后验估计的预测模型比参数基于极大似然估计的预测模型准确度高。
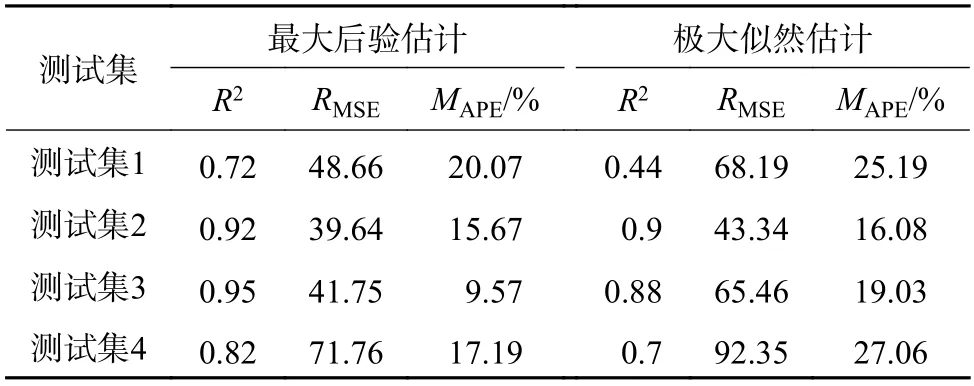
表3 2 种参数求取方法的预测结果(Matern32)Table 3 Prediction results of two parameter calculation methods (Matern32)
3.3.2 不同协方差函数的高斯过程回归预测模型准确度对比
本次实验采用数据集2,在模型参数进行最大后验估计时,分析不同协方差函数的负荷预测准确度。本文设置每种协方差函数的超参数先验分布和噪声均一致,可参考3.3.1 节的参数设置。不同协方差函数的4 组测试集的预测结果见表4。
从表4 的不同核函数模型的准确度评价指标值可以看出:对于评价指标R2,Matern32 相较于EQ 最高提升0.13,相较于RQ 最高提升了0.35,对于评价指标RMSE,Matern32 相较于Matern52最高降低了3.04,相较于EQ 最高降低了6.99,对于RQ 最高降低了16.7,对于评价指标MAPE,Matern32 相较于Matern52 最高降低了1.62%,相较于EQ 最高降低了3.76%,对于RQ 最高降低了7.49%。

表4 最大后验估计下不同协方差函数的预测结果Table 4 The prediction results of different covariance functions under the maximum posterior estimation
综上,选用Matern32 协方差函数的预测误差比其他3 种协方差函数低。因此,在高斯过程回归中,选取Mtern32 协方差函数可以得到更为准确的预测结果。
本次实验也对比了模型参数求取极大似然估计值时不同协方差函数的预测准确度,实验结果如表5 所示。由实验结果可知求取模型参数的极大似然估计值时,RQ 和Matern32 协方差函数的预测精度较高。

表5 极大似然估计下不同协方差函数的预测结果Table 5 The prediction results of different covariance functions under maximum likelihood estimation
进一步对比表4 和表5 可见,最大后验估计方法下,Matern32、Matern52、EQ 协方差函数的预测准确度相较于极大似然估计方法有明显提升。其中EQ 协方差函数提升最明显,4 个测试集中,决定系数R2最大提升了0.47,均方根误差最大降低了20.15,平方绝对百分比误差最大降低了6.54%。实验结果也进一步验证了3.3.1 节结论的有效性,即求取超参数的最大后验估计值时,模型的预测准确度较高,证明最大后验估计可以避免过拟合现象的发生,使得模型拟合程度高,进而提升了预测精度。
3.3.3 建筑占有率的影响
本次实验的高斯过程回归模型采用Matern32协方差函数,采用的数据为数据集2 的测试集1,实验目的是对比有无建筑占有率特征的模型预测精度。图3(a)为考虑建筑占有率特征的预测值曲线图,图3(b)为未考虑建筑占有率特征的预测值曲线图。比较这2 个图可知,图3(a)的预测负荷曲线在2 个波谷时段的预测准确度比图3(b)高。
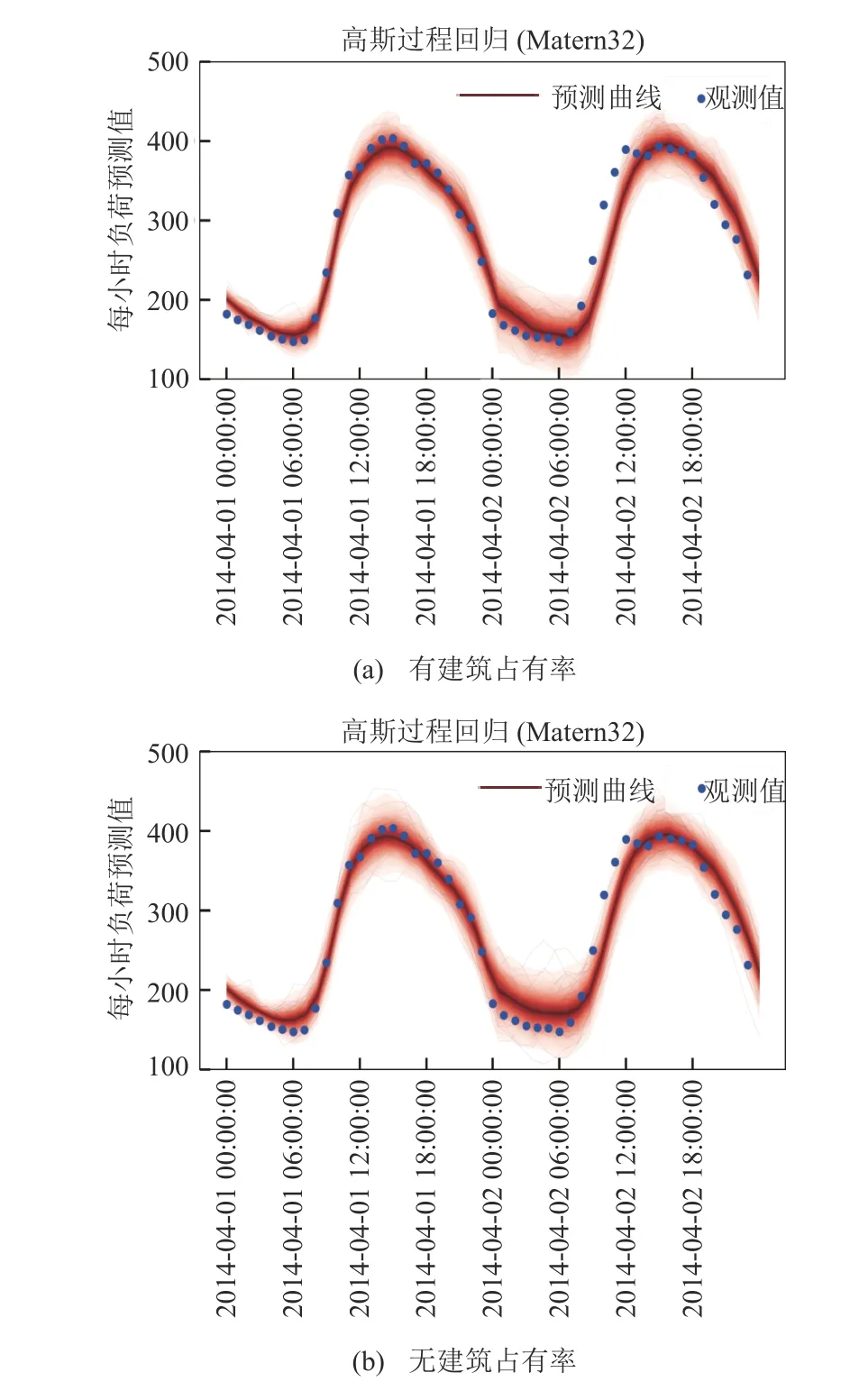
图3 负荷预测曲线Fig. 3 Load forecasting curve
表6 为模型参数进行最大后验估计且采用Matern32 协方差函数时,考虑有无建筑占有率的预测结果表。由表6 可知,考虑建筑占有率特征时4 个测试集的MAPE值都优于未考虑建筑占有率时,测试集1—4 中,考虑建筑占有率模型的MAPE值比未考虑时分别降低了0.88%、0.93%、1.86%、0.57%。考虑建筑占有率模型的RMSE 值比未考虑时分别降低了0.24、0.8、4.18、2.74。由此说明考虑建筑占有率特征可以提高预测的精确度。
表7 为模型参数进行极大似然估计且采用Matern32 协方差函数时,考虑有无建筑占有率的预测结果表。综合表6 和表7 分析得出:本文所提方法相较于未考虑建筑占有率的传统高斯过程回归方法,MAPE值分别降低了1.53%、3.35%、9.68%、2.16%,验证了本文方法的有效性和准确性。
此外,表6 和表7 中测试集3 的预测误差与另外3 个测试集相比较大,其主要原因是测试集3 处于非工作日,各时间段的负荷相较于工作日都有所下降,而训练集中非工作日的数据较少,造成模型对非工作日的参数训练不够精确,使得训练集3 的预测准确度明显低于其他训练集,因此可以通过增加训练集的数量降低预测误差。
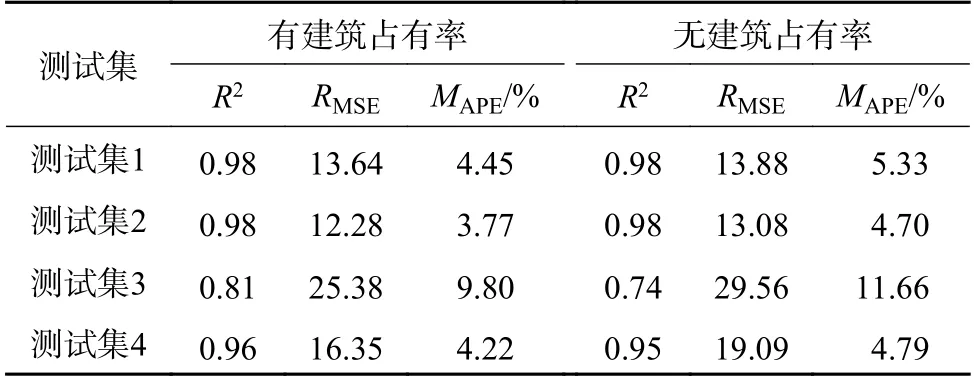
表6 最大后验估计法的预测结果Table 6 Prediction results of the maximum a posteriori estimate method
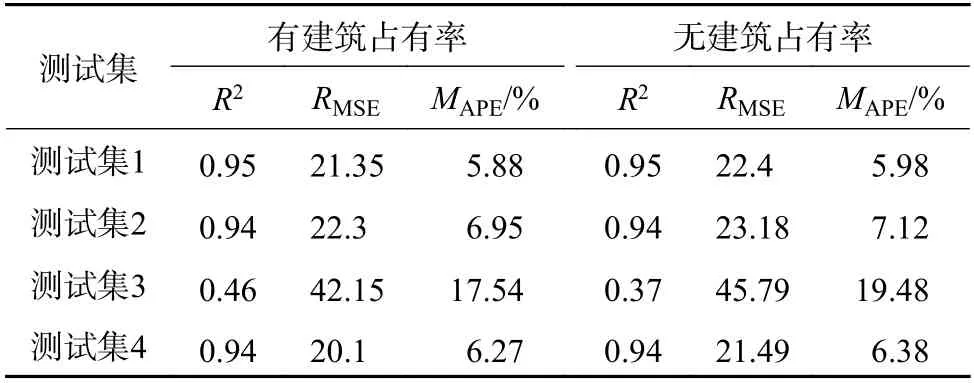
表7 极大似然估计法的预测结果Table 7 Prediction results of maximum likelihood estimation method
3.3.4 收敛性分析
本文对超参数的采样过程和结果进行分析以判断收敛性。图4 为高斯过程回归模型采用Matern32 协方差函数时,其参数(l,η,σ)进行1000次采样的采样图,本次实验设置同一参数有4 条并行的采样轨迹,采用的训练集特征维度为6,由公式(9)可知参数l的维度也为6,采样过程会对参数l各维度进行采样。图4(a)是各参数1000个采样值的分布图,可看出各参数的最大后验估计值分布趋近于高斯分布;图4(b)是各参数每步采样得到的采样值,可以看出每个参数的采样轨迹相对稳定,围绕某个值附近振荡。
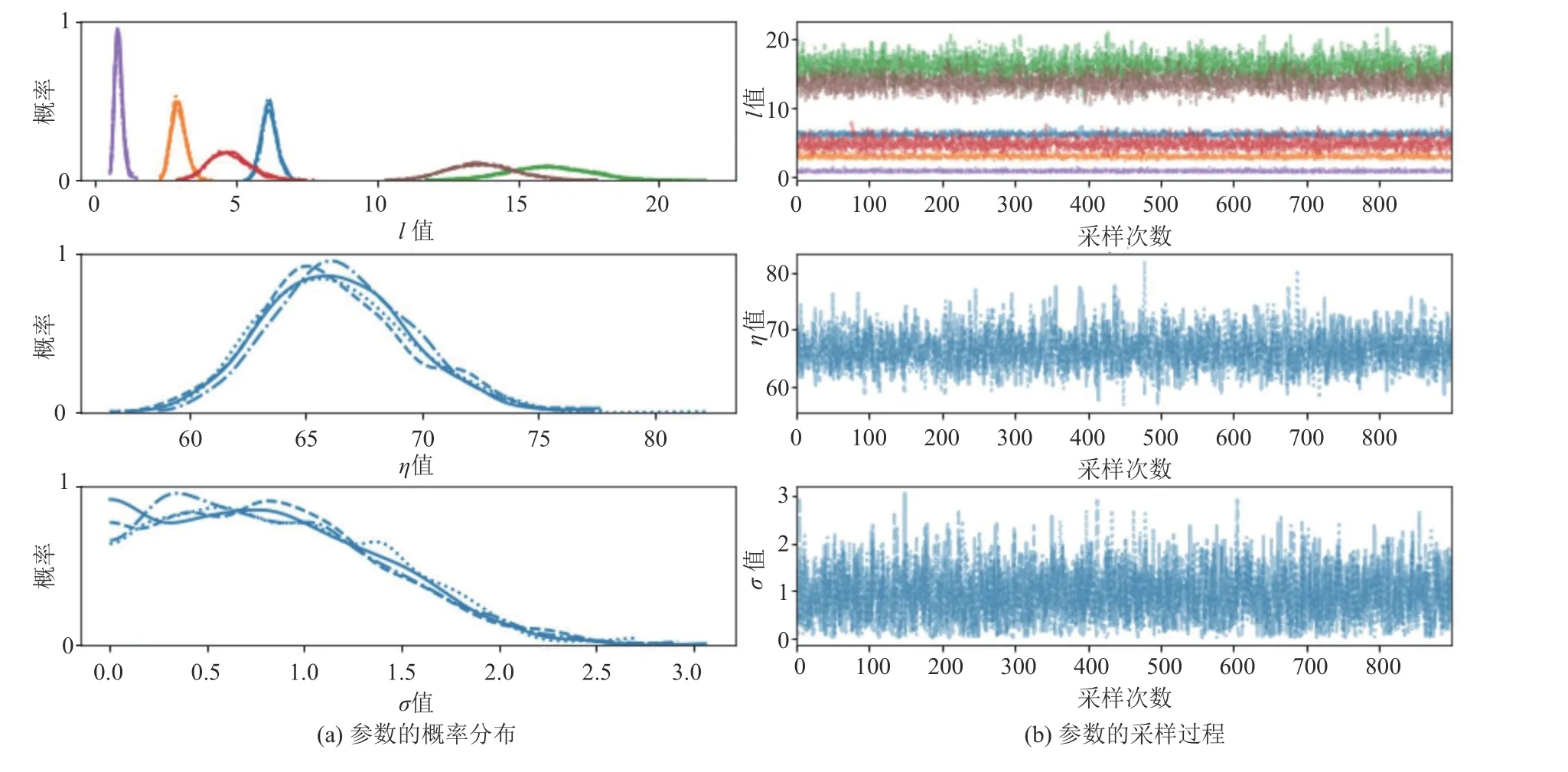
图4 参数采样图Fig. 4 Diagram of parameter sampling
表8 为各参数采样结果的可视化表,表8 中列出了各参数后验的均值、标准差、置信区间以及Rˆ值。表中l1至l6分别是参数l的6 个维度。Gelman-Rubin 法可以定量地检验收敛性,Rˆ值为Gelman-Rubin 检验法的检验指标,理想状态下Rˆ=1,由表8 可知各参数的采样过程均收敛。
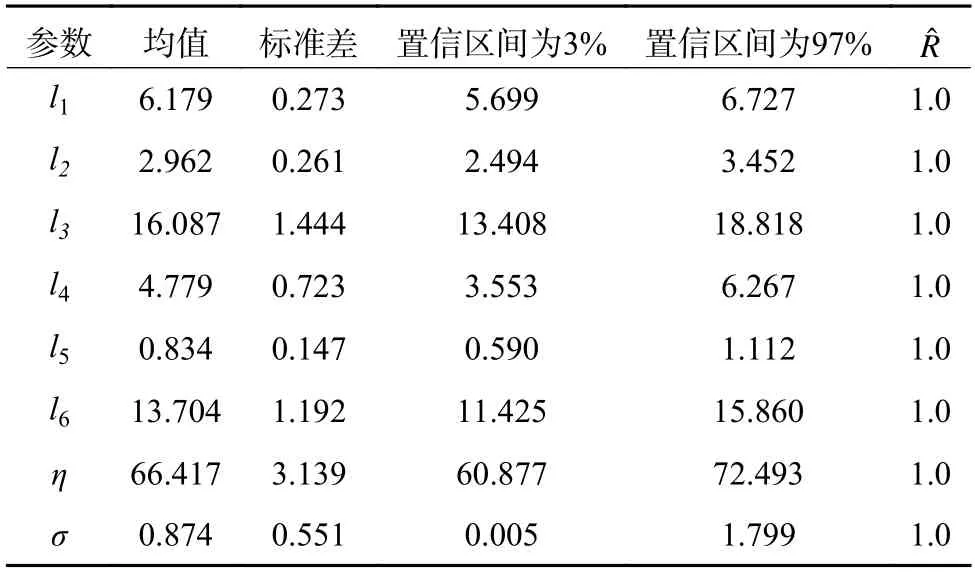
表8 参数采样结果可视化表Table 8 Visual table of parameter sampling results
4 结论
本文利用人员存在检测传感器获取的建筑占有率数据,结合原始数据的时间特征和天气特征,建立多维高斯过程回归预测模型并对楼宇负荷进行预测,实验结果表明:
1)建筑占有率特征可以有效提升楼宇负荷预测准确度,因此本文提出的通过传感器网络获取建筑占有率的方法,适用于人员流动性强的楼宇进行负荷预测;
2)超参数最大后验估计法与极大似然估计法相比较,可以有效防止模型训练过程中过拟合现象的发生,并提高了楼宇负荷预测准确度;
3) 本文对Matern32、 Matern52、 Rational Quadratic、Exponentiated Quadratic 这4 种协方差函数的预测效果进行对比,实验数据分析表明Matern 类协方差函数拟合能力较强。
本文所提对参数进行最大后验估计的方法能够有效降低过拟合现象的发生和数据噪声的影响。基于传感器采集建筑占有率数据的方法,适用于人员流动性强且隐私性要求较高的楼宇,可为楼宇的负荷预测提供新的特征。本文模型用于短期负荷预测时有较高的预测精度,适用于楼宇的负荷预测,可给楼宇节能方案的制定提供强有力的数据基础,促进楼宇能耗的降低以及节能建筑的良好发展。
本文方法预测精度高,但通过采样获得参数最大后验估计的方法存在计算时间较长的缺点,后续研究将通过并行计算进一步提高计算效率。
