面向不均衡数据集的过抽样数学模型构建
2021-11-17杨思狄王亚玲
杨思狄,王亚玲
(内蒙古大学满洲里学院,内蒙古 呼伦贝尔 021400)
1 引言
机器学习技术发展迅速,不均衡数据集分类问题已成为机器学习领域的研究热点,不均衡数据集分类问题可完善机器学习体系,具有重要的应用价值[1]。不均衡数据集指数据集内部分类样本明显高于其它类样本,样本较多的类以及样本较少的类分别为多数类与少数类。
文本分类、信息检索在众多实际应用领域中均存在大量不均衡数据集情况。目前,通常采用数据层方法以及算法层方法解决不均衡数据集分类问题[2],算法层方法是通过调节概率密度、成本函数等方式提升少数类样本分类效果;数据层方法又称为重抽样方法,主要方式是操作训练集,利用完成操作的样本训练分类器,提升少数类样本分类效果[3]。重抽样方法主要包括过抽样以及欠抽样两部分,欠抽样仅可降低训练集的非平衡度,容易出现忽略多数类内有用信息的情况;过抽样可利用已有少数类信息以及复制少数类样本生成人工样本[4,5],提升少数类样本规模,令少数类样本具有较高的分类效果。除此之外,宋玲玲等人研究改进的XGBoost在不平衡数据处理中的应用[6];段化娟等人研究一种面向不平衡分类的改进多决策树算法[7],采用传统方法进行过抽样容易导致过学习情况,识别多数类样本识别率较高,对少数类识别率较低,对于少数类样本的分类精度并不理想。因此,需要采用高效方法优化传统过抽样算法,提升过抽样算法的分类精度。
为提升不均衡数据集少数类样本的分类性能,构建面向不均衡数据集的过抽样数学模型,利用ISMOTE过抽样算法处理训练集,并将完成处理的训练集输入优化后的混合核ε-SVM分类器中,实现不均衡数据集少数类的精准分类。
2 面向不均衡数据集的过抽样数学模型
2.1 ISMOTE算法
过抽样容易出现过拟合情况,少数类过抽样算法(Synthetic Minority Over-sampling TEchnique,SMOTE)是目前常应用于不均衡数据集的过抽样算法,通过加入“人造”样本于相距较近的少数类中,提升少数类样本,令数据集中数据具有较高的分布均衡性[8]。线性插值所获取的少数类样本仅在少数类与少数类线段间分布,形成少数类样本的分布范围有所限制。数据分布不均衡条件下的少数类过抽样算法(ISMOTE)可推广生成少数类样本范围至n维球体,该算法可降低不均衡数据集内众多数据的不均衡程度,提升不均衡数据集内少数类样本的分类精准度。
用Xj与X′分别表示少数类样本以及Xj的k个少数类近邻中的随机样本,利用SMOTE算法形成“人造”少数类样本Xnew公式如下
Xnew=Xj+random(0,1)·(X′-Xj)
(1)
式中,Xnew表示分布于X′与Xj间的人造样本,该人造样本的分布范围可扩大至n维球体。人造样本分布范围越广表示样本分布越均匀,此时样本与实际数据更为接近,算法可行。
ISMOTE算法的中心为少数类样本,将少数类样本至最近邻少数类样本的欧式距离作为n维球体半径,利用所形成虚拟的少数类样本改善不平衡数据集内数据不均匀分布情况。
用N表示样本属性数量,样本Xj的数量为N的属性值,用xj1,xj2,…,xjN表示,此时X′=(x′1,x′2,…,x′N),Xnew=(xnew1,xnew2,…,xnewN)。
ISMOTE算法的虚拟样本Xnewi通过X′与Xj形成。令所形成虚拟样本Xnewi分布于n维球体内,该球体半径为|Xj-X′|,需符合公式如下
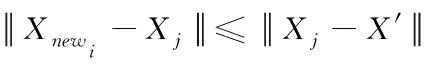
(2)
xnewi=xji+random(0,1)·(bi-ai)1≤i≤N
(3)
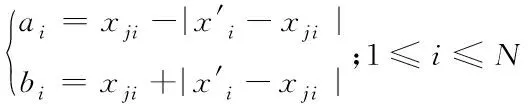
(4)
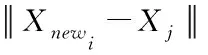
少数类样本的最近邻可能为多数类样本以及少数类样本,最近邻为少数类样本时,依据最近邻思想可知,所形成虚拟样本属于少数类的概率较高[9],限制少数类样本最近邻可提升所形成虚拟少数类样本的质量。
2.2 混合核ε-SVM优化的过抽样数学模型
2.2.1 ε-SVM
支持向量机包括非线性可分、线性可分以及核函数映射三种情况。用S=(xi,yi)表示训练样本,i=1,2,…,l。xi与yi分别表示支持向量机的输入特征与类别标签,l表示训练样本数量。
非线性划分的分类利用二分类目标核函数支持向量机实现,在支持向量机分类器中加入不敏感损失函数ε,即ε-SVM算法,其公式如下
T(y,f(x,a))=T(|y-f(x,a)|ε)
(5)
设给定待分类数据集为S={(x1,y1),(x2,y2),…,(xl,yl)},则估计回归函数的线性函数集合公式如下
f(xi)=μ·φ(xi)+b
(6)
式中,μ与b分别表示回归系数与阈值;φ(xi)表示输入空间至特征空间的映射函数。
2.2.2 混合核函数
通过组合单个核函数建立新的核函数即为混合核函数,建立混合核函数时需充分考虑全局核函数以及局部核函数特性,充分发挥全局核函数以及局部核函数特性的优势。RBF核函数以及Polynomial核函数分别具有较强的局部性以及全局性质[10],组合以上两种核函数,令所获取混合核函数具有较强的推广性能与学习能力,混合核函数组合过程如下:
Polynomial核函数公式如下
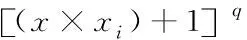
(7)
RBF核函数公式如下
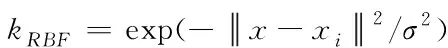
(8)
根据式(7)和式(8)可得混合核函数公式如下
k(x,x′)=δkPoly(x,x′)+(1-δ)kRBF(x,x′)
(9)
式中,δ表示混合核函数中单个核函数所占比例,0<δ<1。
Mercer函数约束条件公式如下
(10)
将k(x,x′)代入式(10)中,当计算结果满足Mercer核函数约束条件时,表示所构造混合核函数成立。
将所构建混合核函数应用于ε-SVM中,获取具有较强泛化能力与学习能力的混合核ε-SVM分类器。
2.2.3 构建数学模型
利用ISMOTE算法生成新样本的方式可均衡化处理不均衡数据集,通过新增样本扩充样本集合时,原样本分布的外围轮廓特征无法改变,分类问题对分类边界的影响程度较小。
面向不均衡数据集的混合核ε-SVM优化的过抽样数学模型结构图如图1所示。
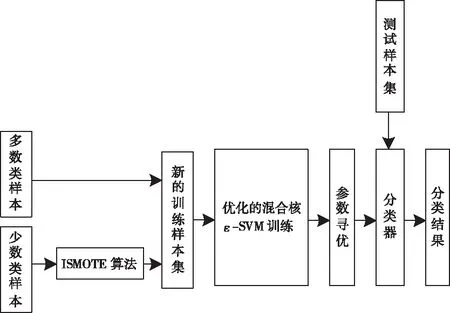
图1 过抽样数学模型
采用混合核ε-SVM分类器训练样本时,所建立的超平面过于偏向少数类,将影响不均衡数据集分类效果[11]。混合核ε-SVM分类器训练样本过程中,添加正惩罚系数C+与负惩罚系数C-,并利用熵值法优化混合核ε-SVM分类器,提升不均衡数据集过抽样的均衡性。
通过赋予不同惩罚系数于多数类样本以及少数类样本中,实现误差代价的良好调节,获取理想分类效果。
加入惩罚函数后混合核ε-SVM的约束化问题公式如下:
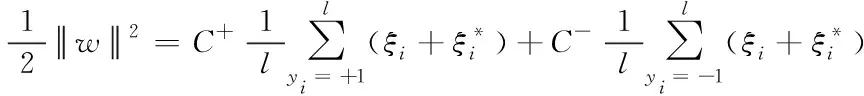
(11)
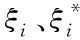
采用熵值法确定ε-SVM分类器的正负惩罚系数,该方法充分考虑少数类样本以及多数类样本的离散程度,通过离散程度确定惩罚系数,是较为有效的赋值方法,该方法可有效避免主观人为因素干扰[12],令所获取惩罚系数具有更高价值。
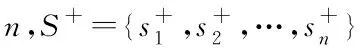
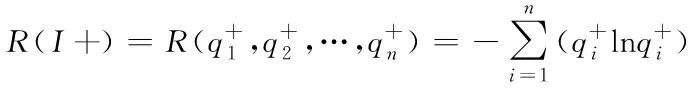
(12)
包含m个子类的多数类负类样本S-的熵值公式如下
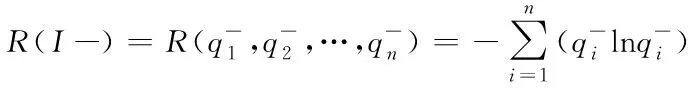
(13)
可得正类样本S+的差异性系数公式如下
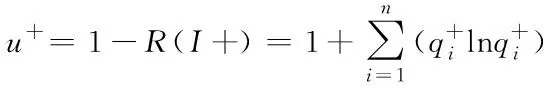
(14)
可得负类样本S-的差异性系数公式如下:
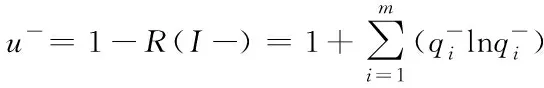
(15)
设C+=C,可得公式如下:
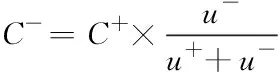
(16)
通过以上优化过程有效提升过抽样算法面向不均衡数据集的分类性能,令完成优化的混合核ε-SVM分类器与ISMOTE算法良好结合,实现最终过抽样数学模型的良好分类。
3 模型测试
为验证所构建面向不均衡数据集的过抽样数学模型对于不均衡数据集内样本的分类性能,选取UCI数据集进行模型测试,测试数据集具体描述如表1所示。
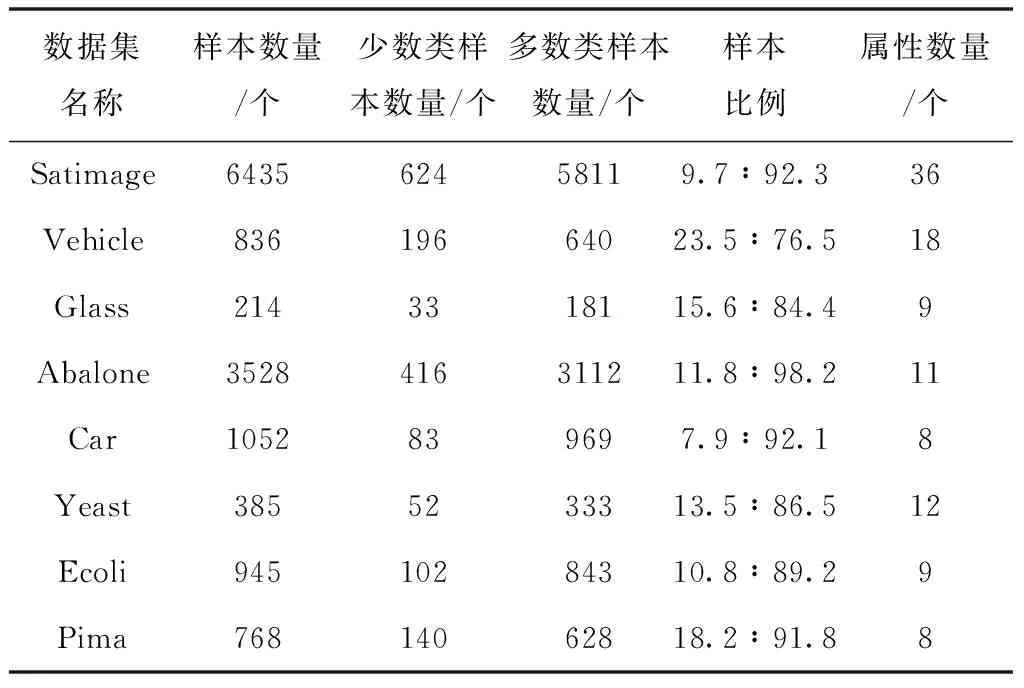
表1 测试数据集描述
选取XGBoost模型(参考文献[6])以及多决策树模型(参考文献[7])作为对比模型,将本文模型与另两种模型对比,验证本文所构建数学模型的分类性能。
所构建数学模型的主要目的是提升不均衡数据集内少数类样本的分类性能。为验证所构建数学模型的分类性能,将多数类以及少数类样本分别称为负类以及正类,建立多数类与少数类两类数据集的混合矩阵如表2所示。

表2 分类问题混合矩阵
不均衡数据集样本分类结果的查全率与查准率公式如下:
Re call=TP/(TP+FN)
(17)
Pr ecision=TP/(TP+FP)
(18)
统计采用三种模型对于不同数据集分类的查全率以及查准率,统计结果如图2以及图3所示。
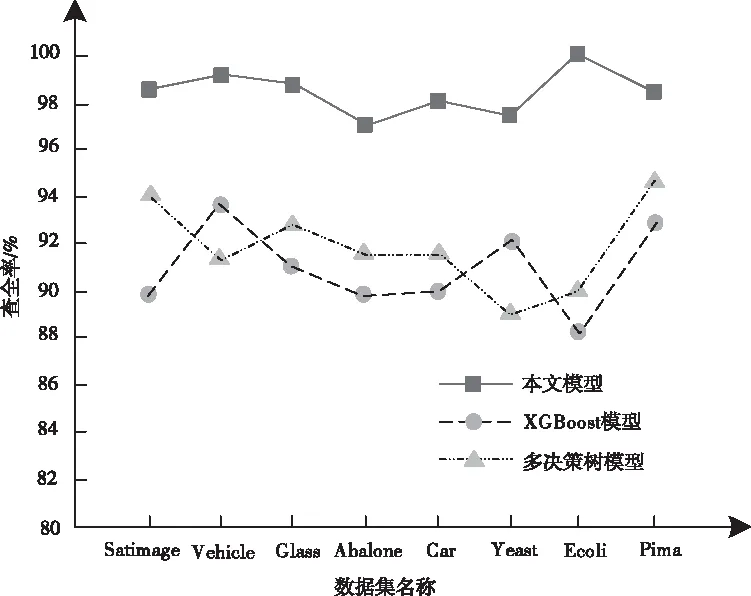
图2 查全率对比结果
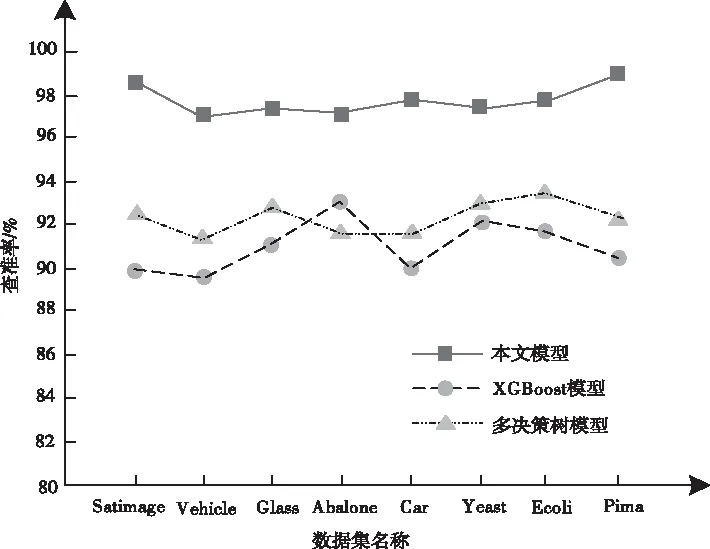
图3 查准率对比结果
从图2与图3中的实验结果可以看出,本文模型对于不同数据集均具有较高的查全率以及查准率。本文模型分类不同数据集的查全率以及查准率均高于96%,说明本文模型可有效提升不均衡数据集内少数类样本的分类性能,分类性能较高。
少数类样本的F-Value值是评价不均衡数据集分类性能的重要评价准则,该评价指标是查全率Recall与查准率Precision的重要组合,设置系数β值为1。不均衡数据集所分类少数类样本的查准率以及查全率均较高时,所获取少数类样本的F-Value值较高。将少数类样本的F-Value值应用于不均衡数据集内少数类分类性能评价中,具有较高应用价值,其公式如下:
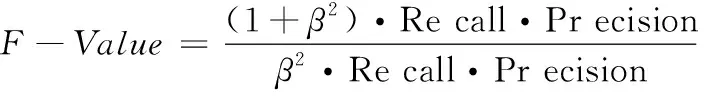
(19)
设置面向不均衡数据集情况下每次迭代过程中“过抽样种子”的扩充倍数作为横坐标,即原始数据集内少数类样本的扩充倍数。采用三种模型分类数据集在不同扩充倍数情况下少数类的F-Value值如图4所示。
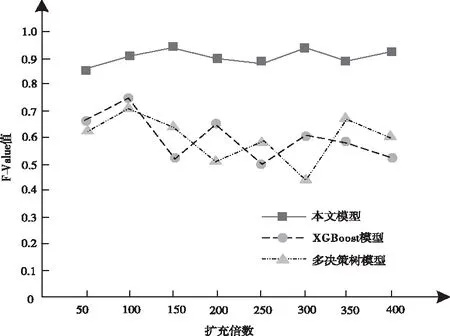
图4 F-Value值对比结果
图4实验结果可以看出,不同扩充倍数下本文模型的F-Value值明显高于另两种模型。本文模型在不同扩充倍数情况下对于少数类样本分类的F-Value值均高于0.8;另两种模型在不同扩充倍数下对于少数类样本分类的F-Value值均低于0.8,有效验证本文模型具有较好的少数类分类性能。
利用几何均值G-mean作为评价不均衡数据集分类的重要评价指标,其公式如下
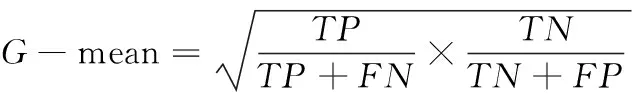
(20)
几何均值G-mean是多数类与少数类精确度乘积的平方根,可知几何均值G-mean与不均衡样本集内多数类与少数类样本分类精度存在直接关联,多数类样本与少数类样本分类精度同样较高时,所获取不均衡数据集的几何均值G-mean结果较高。统计不同模型在不同扩充倍数情况下的几何均值G-mean,对比结果如图5所示。
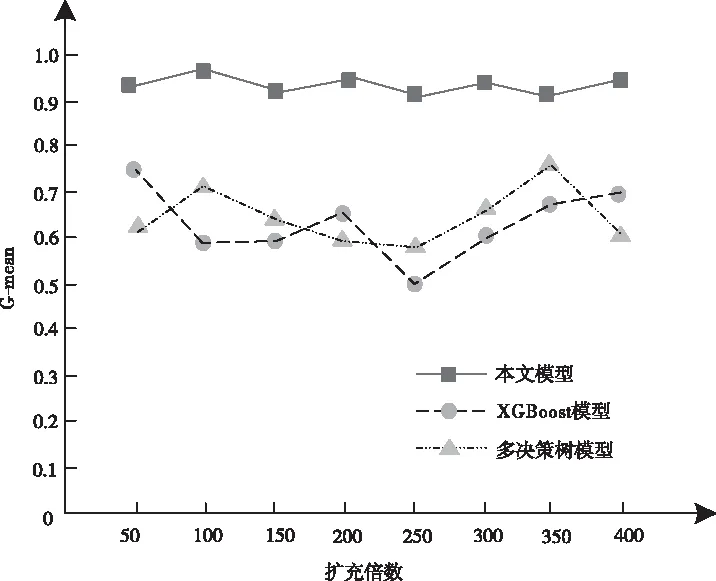
图5 几何均值G-mean对比
图5实验结果再次验证所构建模型对于少数类样本具有较高的分类有效性。本文模型在分类少数类样本下,面对过抽样情况,扩充倍数有所提升时,仍具有较高的少数类样本分类性能。本文模型可有效提升整体不均衡数据集的分类性能,不仅可提升不均衡数据集少数类样本的分类性能,对于整体样本的分类性能同样具有较高的分类性能。
4 结论
不均衡数据集少数类样本的分类问题是机器学习领域的重要研究方向。构建面向不均衡数据集的过抽样数学模型,有效提升少数类样本分类性能。通过实验验证,采用该模型可有效分类不均衡数据集中少数类样本信息,均衡训练样本间数据。不均衡数据集实际应用中,较容易收集多数类样本,将该模型应用于不均衡数据集少数类样本分类中具有较强的应用价值。
