DB-SMOTE及多层堆叠用于心律失常识别
2021-09-02王波,邓科
王 波,邓 科
(西安交通大学 智能网络与网络安全教育部重点实验室,陕西 西安 710049)
心电图用以记录心电活动,心电异常活动会引起心律失常。文中的心电图数据来自MITBIH数据集,选取了数据集中最多的5类作为心电图识别的对象,分别为正常节拍(N)、左束支传导阻滞(LBBB)、右束支传导阻滞(RBBB)、室性早搏(PVC)和房性早搏(APB)。
目前的心电图识别算法主要有3种,分别为基于波形形状的识别算法[1];基于波形特征的识别算法[2]以及基于深度学习的自动特征提取算法[3]。ZHU等利用波形形态学特征,并提取RR间期和QRS波时限等特征,利用支持向量机将心电图分为5类,最终的分类结果达到97.8%[4],该方法对心电图质量要求较高,抗干扰能力差,需对各波形准确定位,诊断准确率也较低。吕卫等人采用S变换提取心电图特征,然后利用支持向量机作为分类器的识别方法,将心电图分为8类,最终的识别效果达到96.4%[5],该方法训练时间较短,但高维心电图信号是复杂的,单一的分类器不能很好地完成识别任务。庞彦伟等人利用深度卷积神经网络的方法将心电图分为5类,准确率达到98%[6],该方法避免了人工提取特征,但训练时间较长,识别的准确率依赖于网络结构,不易设计出合适的卷积网络,对数据的要求较高。
基于上述总结,由于心电图数据失衡以及分类器单一对心电图信息利用不充分,传统的心律失常识别方法分类效果较差,因此笔者设计了一种新型的心律失常识别方法。
1 心律失常识别方法
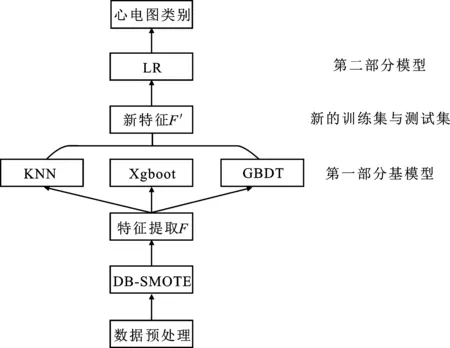
图1 心律失常识别方法
心律失常识别方法如图1所示,由下向上主要包括预处理、聚类插值过采样(Density-Based spatial clustering of applications with noise- Synthetic Minority Over-sampling TEchnique,DB-SMOTE)算法、特征提取及多层堆叠分类器4个部分。
由于信号采集受到干扰,首先对心电图信号进行滤波去噪。心电图信号中各类别数量存在严重的不平衡,分类效果受到极大影响,因此有必要构造少数类样本以增强数据集。传统合成少数类过采样技术(Synthetic Minority Over-sampling TEchnique,SMOTE)算法未考虑噪声样本的干扰以及少数类数据内部的不均衡,因此提出了聚类插值过采样算法来改善少数类样本分布状况。在特征提取阶段,通过小波变换对心电图信号压缩作为提取的特征F。在分类阶段,采用多层堆叠模型进行识别,第一层基模型为识别准确率高的K最近邻(K-NearestNeighbor,KNN)、极端梯度提升树(eXtreme gradient boosting,Xgboost)和梯度提升树(Gradient BoostingDecision Tree,GBDT)模型,将提取后的特征F映射为新特征F′,为防止过拟合,第二层使用简单的逻辑回归(Logistic Regression,LR)模型识别新特征F′。
1.1 数据预处理
数据来源为美国麻省理工学院提供的研究心律失常的数据库MITBIH。由于传感器采集到的心电信号受肌电干扰、工频干扰以及基线漂移等不同性质的噪声干扰,因此需滤去信号中的噪声,图2为滤波去噪效果图。然后根据Pan-Tompkins算法对处理后的心电图信号进行QRS波定位,主要有微分、平方、滑动积分和阈值运算4个步骤[7]。采用微分放大QRS波的斜率,便于检测QRS波群。对信号进行逐点平方,使得微分后的输出非线性放大,有助于限制T波引起的误差。接着利用滑动窗口积分,使得绝对振幅增大和波形进一步光滑,获得R波斜率和其他波形信息。最后采用自适应双阈值检测R峰,两个阈值中较高者用于信号的第一次分析,如果在特定的时间间隔内未检测R峰,则使用较低的阈值[8],双阈值的设计一定程度上就可以防漏检。图3为检测R峰示意图,红圈标注的位置为R峰,以R峰为基准点,向左取199个采样点,向右取100个采样点,合计300个采样点为一个心拍。

图2 ECG信号预处理效果图

图3 QRS波R峰检测
1.2 DB-SMOTE算法
按照机器学习数据不平衡原则,数据比例超过2∶1就属于数据失衡。根据数据预处理后的心拍划分,正常、左束支传导阻滞、右束支传导阻滞、室性早搏和房性早搏的心拍数量分别为74 962、8 068、7 254、7 034和2 545,明显可看出各类样本数量分布不均衡,尤其是房性早搏的心拍数量只有正常的4%。
现有大部分分类模型都是建立在数据分布均匀的基础上,当数据不平衡时,会压缩少数类的分类空间,造成严重的分类误差。不过在现实条件中,采集和标注心电图数据的代价是昂贵的,因此生成少数类样本来缓解数据失衡是一种较好的替代选择。CHAWLA等在2002年提出经典的合成少数类过采样技术[9]。合成少数类过采样技术主要流程如下所示:
(1) 少数类中的每一个样本a,以欧式距离为度量,计算该样本到少数类中其他样本K近邻;
(2) 根据少数类的不平衡情况设置采样倍率N,对于每一个少数类样本a,从其K近邻中随机选出若干个样本,假设随机选择的近邻为b;
(3) 随机选择的近邻b与样本a以如下的公式生成新样本:
c=a+rand(0,1)*(a-b) 。
(1)
传统的合成少数类过采样技术忽略了少数类数据内部的不平衡和噪声样本干扰的影响,同时可能会入侵多数类样本分类空间。针对合成少数类过采样技术存在的问题,提出了DB-SMOTE算法。DB-SMOTE算法的主要思想是将少数类数据通过有噪空间的密度聚类(Density-Based Spatial Clustering of Applications with Noise,DBSCAN)算法[10]分为m个簇,过滤噪声样本集合,以各个簇的边界数据作为主体,插值合成新的样本。
有噪空间的密度聚类算法将少数类样本点分为3种,为核心点、边界点和噪声点,具体含义为:在半径Eps内含有超过MinPts数目的点为核心点;在半径Eps内没有超过MinPts数目的点为边界点;在半径Eps内没有相邻点为噪声点。

图4 DB-SMOTE生成结果可视化
DB-SMOTE算法具体步骤如下:
(1) 对少数类样本集Xb进行有噪空间的密度聚类,过滤不属于任意簇的噪声点集合Xn,根据样本点的局部密度将簇划分为{C1,C2,…,Cm},并获取边界点集合Cb;
(2) 将边界点集合Cb中的点按边界点在各簇{C1,C2,…,Cm}分布划分为边界样本簇{Cb1,Cb2,…,Cbm};
(3) 以各簇边界样本的簇密度{ωb1,ωb2,…,ωbm}为比例,对各簇的边界数据{Cb1,Cb2,…,Cbm}使用合成少数类过采样技术构造新数据。
有噪空间的密度聚类算法设置参数半径Eps为3.5、MinPts设为40、距离度量设置为minkowski。算法将少数类样本分类3个簇,样本个数分别为882、449和51,滤除的噪声样本个数为118,边界点为367。根据少数类样本失衡情况,DB-SMOTE算法生成少数类样本1 101个。为便于直观分析和理解,在文中利用流形学习算法t分布随机近邻嵌入(t-distributed stochastic neighbor embedding,tSNE)[11]实现心电图信号的降维可视化。DB-SMOTE算法的生成结果见图4,其中点表示原始心电图数据,加号表示生成的数据。可以清晰看到生成的心电图心拍主要集中在原始数据的边界,既扩充了少数类样本,也减少了生成样本入侵到多数类样本空间的风险。
在疾病类数据识别任务中,疾病被分为正常的代价比正常被认为疾病的代价大得多。正常被分为疾病可通过后期的复诊纠正,而疾病被分为正常很有可能错过最佳的治疗时间,所以DB-SMOTE算法生成少数类样本以提升少数类的识别效果很有意义。
在文中,DB-SMOTE算法生成房性早搏类1 101组心拍,每次试验随机划分训练集和测试集,有力地避免模型针对固定测试集调参。具体的训练集和测试集划分如下:

表1 训练集和测试集划分
1.3 特征提取
因心电图信号维度较高,为克服维度灾难并获取本质特征,特征提取在心律失常识别方法中起着重要作用。小波变换是分析非平稳信号的有力工具,它能同时提供时间和频率信息[12-13],文中采用小波变换对心电图信号进行压缩。小波压缩心电图信号利用了信号的小波域表示相对稀缺性,心电图信号可以使用少量近似系数和一些细节系数来精确表示。小波压缩主要有3个步骤:
(1) 分解过程:选定一种小波,对信号进行N层小波分解;
(2) 细节系数阈值选择:对于从1到N的每个级别,选择一个阈值,并将硬阈值应用于细节系数;
(3) 重构信号:利用N级的原始近似系数和1~N级的修正细节系数计算小波重构。
由于心电图信号的连续性和光滑性都较好,而sym 5小波函数具有紧支撑性、良好的连续性和对称性,因此适合对心电信号分解;小波分解层数设置为4层。利用基于Birgé-Massart策略的小波系数选择规则确定阈值,计算公式为
(2)
其中,M和α为经验系数,一般情况下M为第一层小波系数的长度,α取1.5,i和j分别为当前分解层数和总的分解层数。
文中使用压缩率(Number of zeros,Nz)和保留能量作为衡量压缩效果指标,压缩率是指压缩后不为零系数(L1)占原系数长度(L)的比率:
(3)
保留能量率(Retained energy,Re)是指压缩后信号保留的能量(Compress energy,Ce)与原始信号能量(Original energy,Oe)的比率:
(4)
通过图5原始信号和重建恢复的信号对比,可以发现无论是从压缩后的能量保留角度,还是恢复后的视觉感知,效果都是不错的,重建原始信号仅仅使用了14%的系数,最终心电信号的维度从300降到了47。

图5 原始信号和重建恢复信号对比

图6 多层堆叠分类模型结构图
1.4 多层堆叠分类器模型
由于计算能力的提高和没有完美的模型,多种模型融合的堆叠算法是当前分类模型中最有前途的方向之一。与bagging和boosting集成模型不同,多层堆叠模型是一种融合多个不同模型的方法。和相互独立的单一识别模型相比,堆叠模型具有更强的非线性,能够降低泛化误差,识别过程如图6所示。
为达到最优的识别效果,多层堆叠模型的基模型选取了识别准确率高和差异化的分类器,分别为K近邻、极端梯度提升树、梯度提升树。为了减少过拟合,在第一层模型训练利用5折交叉验证找到使模型泛化的最优超参数,最终K近邻参数K设为1,距离参数为曼哈顿距离,极端梯度提升树的学习率为0.05,树的个数为600,树深为15,梯度提升树的学习率为0.1,树的个数为800,树深为15。
多层堆叠模型的第二层是将各分类器的输出概率作为特征F′识别,由于第一层采用了多个复杂的非线性分类器,为了降低过拟合的风险,第二层分类器选取了较为简单的逻辑回归模型,正则化参数设置为l2,优化算法为sag。
2 结果分析
2.1 DB-SMOTE对识别方法的影响
DB-SMOTE算法过滤了少数类房性早搏心拍中的噪声,生成的样本增强了少数类样本集,也减少了入侵多数类样本空间的风险。以堆叠模型中的极端梯度提升树为例,结合合成少数类过采样技术的极端梯度提升树识别准确率为99.26%,结合DB-SMOTE算法的极端梯度提升树识别准确率达99.42%。由极端梯度提升树的对比实验可以看出,DB-SMOTE算法滤去了噪声样本,生成的少数类样本改善了样本的空间分布,提升了最终的识别效果。
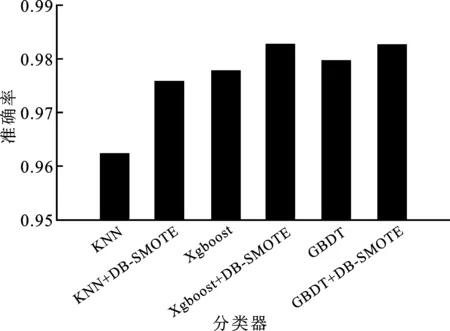
图7 使用DB-SMOTE识别房性早搏
在5类心电图数据中,房性早搏的心拍数量是最少的,也是识别效果最差的。DB-SMOTE算法能够有效改善数据分布状况。采用DB-SMOTE算法生成少数类房性早搏心拍,并结合K近邻、极端梯度提升树和梯度提升树进行识别,与未使用DB-SMOTE算法进行比较,各分类器识别表现见图7。
从图7中可以看出:对于K近邻、极端梯度提升树和梯度提升树3种分类器,使用DB-SMOTE算法均提高了房性早搏类的分类准确率。针对房性早搏类的识别情况,K近邻的分类效果最差,结合DB-SMOTE算法后准确率提高了1.35%,较大地提高了K近邻的分类效果;对于分类效果较好的极端梯度提升树和梯度提升树,结合DB-SMOTE算法后识别准确率未有较大的提升。DB-SMOTE算法对于效果较差的分类器,准确率提升较为明显,对于分类效果较好的分类器,准确率略有提高。
2.2 多层堆叠模型对识别方法的影响
单一的分类器识别结果并未令人满意,因此构造多层堆叠分类器来提升模型性能。实验中为提升效果,选取单一分类器中性能较好的3个分类器K近邻、极端梯度提升树和梯度提升树。基分类器类型不同,各有优点和缺点,可通过分类器之间的互补达到提升性能的作用。
多层堆叠模型的基模型融合不是简单使用投票机制,而是通过第二层的逻辑回归分类器将基模型的结果作为新的特征向量,再一轮训练和预测,最后输出识别结果。经过投票法与逻辑回归模型融合的对比实验,投票法的识别准确率达99.46%,而逻辑回归模型融合的识别准确率为99.66%,明显优于投票法的结果。从图8的实验结果可看出,多层堆叠模型与单独使用一种分类器进行分类相比,在模型性能上都优于对比的单一分类器,尤其是少数类房性早搏的效果提升最为明显。分类器的堆叠显然会造成模型收敛时间变长;不过,实际应用多为离线学习,训练的复杂度对模型应用影响不大。

图8 使用多层堆叠集成分类对比
2.3 评价指标

表2 混淆矩阵
在分类任务中一般以分类的准确率来衡量任务的成功程度,但在数据不平衡的情况下,仅以准确率作为衡量指标不够全面。在机器学习领域,常利用混淆矩阵客观评价分类性能,它是精度评价的一种标准格式,混淆矩阵具体见表2。
其中,TP表示正确分类的正类样本数量,TN表示正确分类的错误样本数量,FP表示错误分类的负类样本数量,FN表示为被错误分类的正类样本数量。基于混淆矩阵,目前有一些评估指标专门用于评价不平衡的数据集。选择F-value(Fvalue)以及G-mean(Gmean)作为评估分类器性能的指标,平均方法为宏平均(macro-average)。
(5)
(6)
(7)
Gmean=(PR)1/2,
(8)
其中,P表示查准率,R表示查全率,β为查全率对查准率的相对重要性。文中将β设置为1,代表查准率和查全率的重要性相同。

表3 各分类器F-value和G-mean实验对比
在相同的数据集下,13层的卷积神经网络VGG13的准确率达到98.7%,其中,学习率设为0.01,批尺寸设为256,epoch设为300;单层的LSTM网络准确率达到99.08%,其中,学习率取为0.01,批尺寸取为64,epoch取为300,这两种深度网络都不如文中识别方法效果好。和传统机器学习相比,深度学习的训练需要更多的数据以及复杂的深度网络,在较浅的卷积神经网络或数据较少的情况下,传统机器学习的表现更为突出。同样针对MITBIH数据集,与表4总结的参考文献给出的实验结果对比,文中提出的算法性能更优。

表4 文中的识别方法与相关研究算法对比
3 结束语
针对心电图信号识别性能不理想尤其是少数类房性早搏的心拍识别效果差的问题,笔者提出了一种识别心律失常的方法。其中主要包括DB-SMOTE算法滤去少数类噪声样本,通过构造数据缓解样本的类别间失衡和类内失衡,以小波变换压缩心电图信号以及多层堆叠模型组合分类器互补提升识别性能。该方法能够充分利用心电图信号中的信息,整体的分类准确率达到99.66%,F-value的准确率为99.43%,G-mean的准确率为99.44%。心律失常识别方法提高了准确率、F-value和G-mean,尤其是在少数类疾病的识别上有较大提升,也优于VGG13和LSTM等深度学习网络,对未来应用于临床试验具有一定意义。
