动态模糊匹配下的多元相似度定位算法
2021-09-02秦宁宁吴忆松
秦宁宁,吴忆松,杨 乐
(1.江南大学 轻工过程先进控制教育部重点实验室,江苏 无锡 214122;2.南京航空航天大学 电磁频谱空间认知动态系统工信部重点实验室,江苏 南京 211106;3.坎特伯雷大学 电气与计算机工程系,新西兰 克赖斯特彻奇 8011)
目前,大部分室内定位方法是利用无线信号的相关特征来进行定位的,常用的技术有WiFi[1]、射频识别[2]、超宽带[3]和蓝牙[4]等。室内环境的复杂性导致无线信号在传播时容易引发多径效应,很难对不同场景下的信号变换给出精准的数学模型。由于指纹匹配方法侧重于接收信号强度(Received Signal Strength,RSS)的指纹特征,而非遍历所有信号,因此可以通过匹配待定位点与指纹点的接收信号强度分布来获取待定位点的位置。
基于近邻点求平均位置的算法是最常见的指纹定位方法之一,微软公司的雷达系统[5]中提出的信号空间中K最近邻算法(K-Nearest Neighbors,KNN),选取待定位点与指纹库中匹配度最高的K个指纹点,以平均位置作为待定位点的位置。针对K最近邻算法因平等对待近邻点导致定位误差较大的问题,文献[6-7]引用了加权KNN算法(Weighted KNN,WKNN),增加指纹点的欧氏信息作为权重,用体现位置相似度的加权平均替代均衡平均,提高了定位精度。但固定的K值依然无法避免选择虚假的近似指纹点参与位置估计[8]。为了解决这个问题,文献[9]引入动态K值概念,把欧氏相似度大于阈值的指纹点去除后,再求加权平均位置。
上述基于最近邻指纹点的定位算法都具有简单易行的优势,但定位精度有限。近年来,为了提高定位精度,人们开始倾向于将复杂的机器学习方法引入到定位算法中,从而挖掘更深层次的信号特征。物理位置与信号强度的关联度越高,则定位越容易[10]。因此,姚彪英等[11]提出一种基于改进支持向量回归的室内定位方法,在训练阶段增加一个校正坐标z,提高二维位置信息与接收信号强度之间的关联性。基于机器学习算法的定位方法虽然在定位精度方面表现优异,却也带来了计算复杂度高和定位时间长、效率低的问题。为减少匹配计算量的同时保证系统的实时性,田增山等[12]基于主成分分析法(Principle Component Analysis,PCA)给出在子空间内的匹配算法,基于在线信号从离线指纹库中提取子指纹库,利用主成分分析法对在线数据及子指纹库进行降维和构建子空间。基于主成分分析法的子空间匹配方法能有效提升定位效率,但无法保证局部匹配的正确率,尤其当室内空间中的障碍物、人流量等干扰因素增加时,会严重拉低子空间匹配的正确率,可见一般的子空间匹配方法难以适应环境因素的波动而进行动态调整。
针对定位精度与定位时间的矛盾,论文提出了模糊匹配K近邻定位算法(Fuzzy Matching KNN,FMKNN)。作为一种动态的局部指纹库匹配方法,FMKNN通过可调的子空间匹配阈值,平衡匹配精度与计算复杂度之间的增益双赢,结合多维相似度系数,引入权重调整参数进行位置估计,优化近邻点集合的结构,突出邻近点的作用。实验验证该方法在降低匹配时间的同时,依然能为待定位点提供较为精准的匹配指纹信息,所构建的位置估计算法,确实进一步提高了定位的精度。
1 系统模型
1.1 网络空间模型
平面空间的场景内,部署N个基站:PA1,PA2,…,PAi,…,PAN,其中i=1,2,…,N。场景内布置K个指纹点作为采集指纹信息的位置。离线阶段,在指纹点处采集来自N个基站的RSS与其物理位置共同组成指纹点信息,记第k个指纹点PFk的指纹信息为PFk=[(xk,yk),(Rk1,Rk2,…,RkN)],其中k=1,2,…,K。在线阶段,在待定位点PT处采集来自N个基站的接收信号强度组成待定位点信号向量,记待定位点的信号向量为PT=[R1,R2,…,RN],PT的物理位置坐标为(x,y)。PFk,PT以及PAi共同构成了论文的网络空间模型。
1.2 基于泰森多边形的子指纹库聚类方法
为提高定位速度,以基站作为基点,利用泰森多边形[13-14]对PFk进行聚类,生成若干个以接收信号强度为参考量的子指纹库,用以简化定位阶段的搜寻过程。PFk聚类的过程如下:
步骤1 区域分割。以N个基站为基点,对场景生成关于基站的泰森多边形,包含N个子区域Ωi。
步骤2 指纹点数据录入。记录定位场景中K个指纹点的指纹信息PF1,PF2,…,PFK。
步骤3 指纹点聚类。以子区域为依据对指纹点进行聚类,若PFk位于PAi对应的子区域Ωi内部,则将PFk聚类到子指纹库DSi中,即
PFk∈DSi, if(xk,yk)∈Ωi,
(1)
其中,DSi内记录属于子区域Ωi的所有指纹PFk。
以如图1(a)中N=8个基站为例,生成以PAi(i=1,2,…,8)为基点的8个子区域。在场景中随机放置一定量的指纹点,依据泰森多边形单元格进行指纹聚类,得到相应的8个子指纹库DSi,如图1(b)所示。
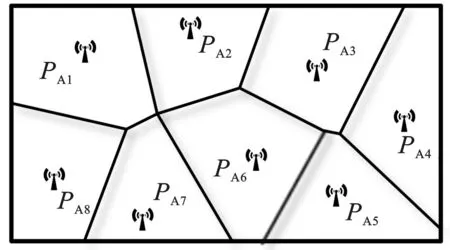
(a) 区域划分示意图
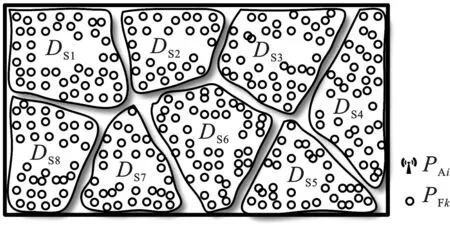
(b) 指纹点聚类示意图
1.3 相似度系数
通常借助评估指纹点与待定位点所接收到接收信号强度的相似程度,即相似度系数,来衡量指纹点与待定位点之间的相关性。已有研究将相似度系数分为以欧氏距离[15]为代表的整体相似度系数和以空间余弦量[16]为参考的局部相似度系数。
1.3.1 欧氏相似度
欧氏相似度以PT和PFk之间信号向量的空间距离作为参考量,定义系统整体相似程度,其欧氏相似度Ek计算式为
(2)
可见Ek越大,给定PT与PFk的接收信号强度在向量空间的距离越小。
1.3.2 余弦相似度
基于余弦的相似度系数以PT和PFk的信号向量空间方向为参考量,衡量两者的向量夹角建立局部相似度模型为Ck,即
(3)
可见Ck越大,给定PT与PFk的RSS向量在空间中的夹角越小。
2 指纹的概率特征提取
室内信号传播会受到同频、多径、障碍等多重因素的联合影响。若以经典的以时间段为统计单位的平均信号强度,直接作为某指纹点的指纹信号,则无法体现同一位置上接收信号强度的不确定性和随机波动特征。考虑到同一位置采样得到的接收信号强度信号值的频数分布近似符合高斯分布,则可以剔除出现概率较小的信号值,保留高概率信号的几何均值作为该指纹点的接收信号强度特征值,以此克服环境干扰的影响。
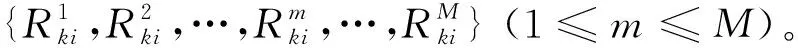
(4)
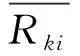
(5)
3 模糊匹配
3.1 匹配思想
在指纹定位的搜寻近邻点阶段,通常会选择遍历所有的PFk来与PT进行匹配,这种保证搜寻范围完整性的极度贪婪做法,极易导致计算量激增。可对大范围指纹区域采用泰森多边形方式切割,并将PFk聚类到相应的DSi中,以区块匹配的方法,把全局的遍历搜索转换为局部的快速检索过程,在保留全局搜索准确性的基础上可以提升定位的时效性。
然而,对指纹库进行“一刀切”式的划分在简单易行的同时,势必会带来匹配阶段准确性不高的问题。对于一些受到信号波动影响较大的指纹点,简单的局部匹配方式极有可能为其匹配到错误的子库。论文提出由多个子库组成局部指纹库DP,在PT匹配阶段对子区域进行模糊匹配,得到其对应的局部指纹库,有条件地扩大PT的匹配范围,牺牲有限的定位速度来弥补传统局部匹配算法误差概率大的缺陷。
3.2 模糊匹配
为了兼顾局部指纹库的匹配速度和准确率,需要根据场景特性调整匹配的模糊程度。为此,论文引入模糊参数f,在判断PT与子区块相关性时灵活地调整匹配包容度,找到具有场景独特性的模糊参数值。
在线定位阶段,待定位点匹配对应的局部指纹库,匹配步骤如下:
步骤1 分割线标签。根据泰森多边形的特性可知,区块分割线处于相邻两个基站连线的垂直平分线上。因此比较来自分割线两侧基站的接收信号强度大小,即可获得以分割线为区分粒度的标签。若泰森多边形子区域Ωi由J条分割线切割而成,赋予每条分割线一个标签,记第j条分割线(j=1,2,…,J)的标签为
(6)
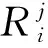
步骤2 子指纹库标签。当一块区域的分割线标签都已确定,该区域对应的DSi是否与PT匹配成功由J条分割线共同决定,则判断子指纹库标签可表示为
(7)
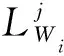
步骤3 匹配局部指纹库。前文已经提到,局部指纹库由所有匹配成功的子指纹库共同构成。因此,PT的局部指纹库由标签为1的子指纹库组成,可表示为
(8)
多区块的匹配结果既保证了PT不会被误分类,又防止了全局匹配的低效性,是匹配速度和质量的一个折中办法,同时削弱了两种极端方法的缺陷。
3.3 模糊参数分析
模糊参数f的引入使得匹配过程中的模糊程度可调,因而保证了不同的定位空间及定位时间下都能做到模糊匹配的准确率与匹配量动态平衡。为了比较f的取值对算法匹配指纹点数量的影响,如图2所示,将不同f取值下的DP匹配结果进行对比。由图2(a)可见,当f=0即不采用模糊匹配时,DP是由单个DSi构成,且容易匹配到错误的结果;图2(b)和图2(c)中,当f>0,待定位点处的DP由多个子指纹库组成,并且随着f增大,匹配结果的区块数量增加。
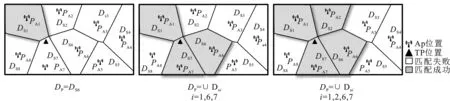
(a) f=0 (b) f=5 (c) f=10
4 位置计算
欧氏相似度表示空间中两点的直线距离,作为一种最基本的相似性度量方法,由于算法简单,其成为KNN的核心方法。在室内指纹定位技术中,待定位点PT与指纹点PFk的物理距离越近,得到的Ek就越大。而在实际中,由于接收设备的型号不同或环境差异,会造成在线阶段对PT接收到的信号强度存在偏差;在这种情况下,采用欧氏距离进行近邻点权重计算,会造成不同接收设备针对同一近邻点权重不一致,进而产生较大的定位误差。因此,论文引入多个层面的相似度考量方式,以此弥补单一相似度系数带来的衡量偏差。
4.1 基于多元相似度的近邻点集合
经研究发现,不同设备接收基站的接收信号强度向量存在差异性,终端差异会使得基于欧氏距离的定位精度降低,甚至会出现定位失败的情况。终端差异虽然会引起接收信号强度向量在空间距离上的大幅浮动,但这些浮动的方向性改变较小,因此引入余弦相似度来衡量PT与PFk的相似性。利用欧氏相似度和余弦相似度对空间距离与角度不同的敏感性,定义基于空间距离和向量方向联合作用下的多元相似度系数为
(9)
其中,Gk表示PT与PFk的多元相似度,Gk值越大,认为PT与PFk的物理距离越小。附加项ε>0且存在ε→0,避免了分母为0。
在位置计算阶段采纳多元相似度最高的S个指纹点,其中1≤S≤K,并以此生成具有多元性和时效性的近邻点集合U={PFU1,PFU2,…,PFUs,…,PFUS},s=1,2,…,S。由多元相似度确定的近邻点集合综合了整体与局部的特征,更加真实地反映出待定位点的物理位置特征。
4.2 近邻点权重配置
考虑到环境因素对定位的影响较大,仅以Gk作为近邻点权重的依据无法突出定位场景的个体特征,不同环境下的权值应进行适当调整。引入环境参量v,调节近邻点对PT位置(x,y)计算的权重占比WFUs,确定具有场景特性的新权重量纲。WFUs可表示为
(10)
参量v与环境相关,需要确定定位场景的最佳环境变量。可针对离线阶段得到的指纹库,取场景中坐标均匀分散的位置,通过与指纹库的计算匹配,进行离线获取使定位误差最小的v作为环境参量取值。
4.3 位置匹配
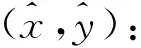
(11)
其中,WFU表示U中的近邻点序列的权重,xU和yU分别表示PFU的物理横坐标和纵坐标。
5 FMKNN流程
论文提出的FMKNN定位算法的步骤流程如图3所示。离线阶段,相比于一般的指纹定位步骤,FMKNN在生成离线指纹库后增加指纹点聚类过程,建立N个子指纹库,为在线阶段的局部指纹库模糊匹配做好准备。在线阶段设置二次权重分配,是为了进一步加强近邻点权重,新的权重WFUs使权重配置更符合环境特征。
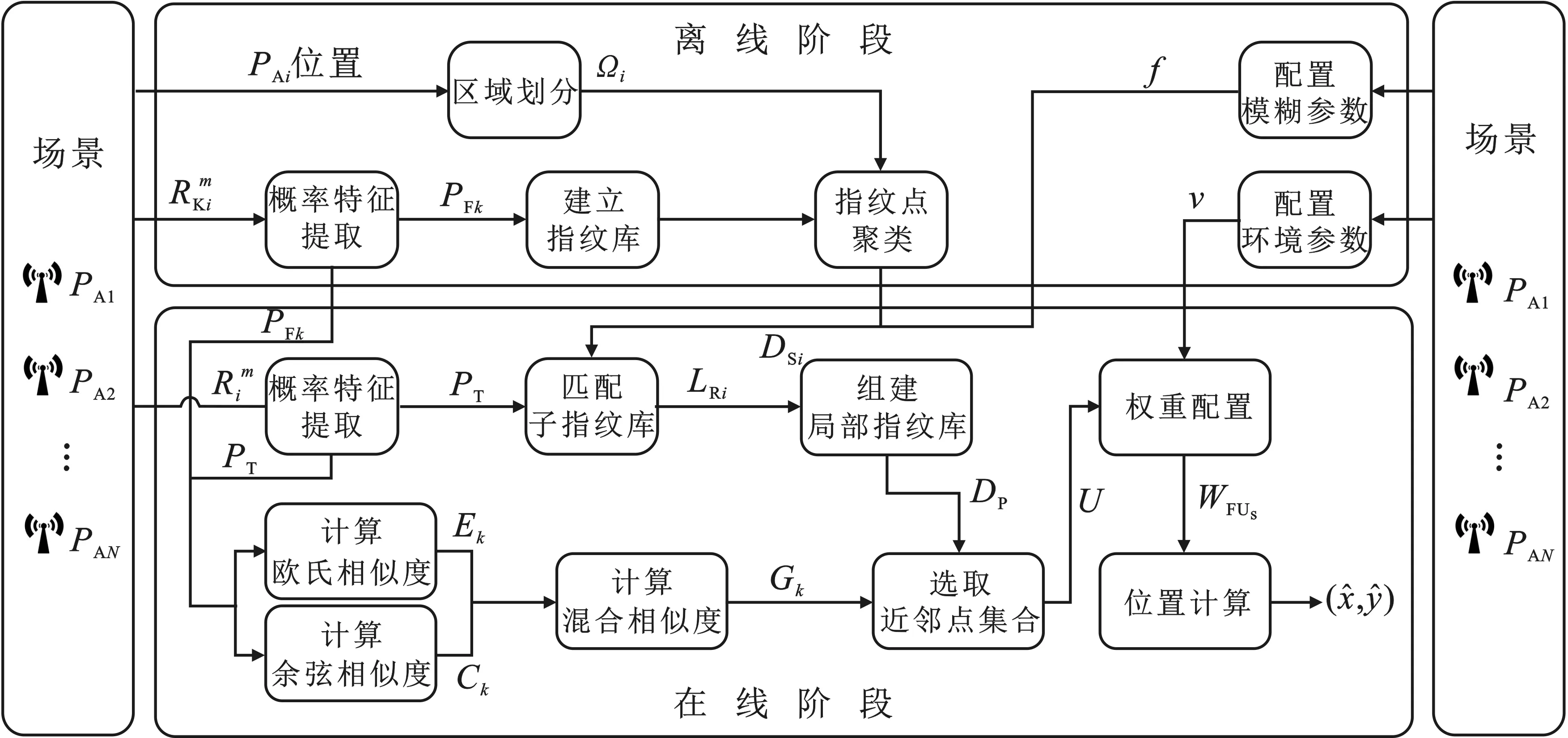
图3 FMKNN算法流程图
6 实验与结果分析
6.1 测试场景与数据处理
为了评估所提算法的性能,以江南大学物联网工程学院某会议室为实景测试场地,场地俯视图为11.5 m×5.5 m的矩形。图4(a)给出该场地的环境布置以及基站信号源位置与指纹点排布平面图。场景中布置低功耗蓝牙节点作为无线基站 (N=4),且位置随机。指纹信息采用网格取点的方式,将矩形定位区域均匀划分成0.5 m×0.5 m的网格,取网格中心点为指纹点位置,共计生成K=160个指纹点。为了保证待定位点数据兼顾均匀性与随机性,待定位点的选取是在基于0.8 m×0.8m的网格内随机选取,共获得78个备选待定位点。
在待定位点与指纹点数据的采集过程中,为体现算法对设备差异的透明性,对离线与在线阶段分别选用平板电脑和智能手机作为数据采集工具。信号采集以2 s为间隔时间,连续采集2 min,构建生成包含60组数据。将采集的接收信号强度以信号热图的形式呈现,如图4(b)所示。
(a) 场景示意图

(b) 场景信号热图
为了验证实验场景的接收信号强度数据符合高斯分布,不失一般性,随机选取k=34时PFk的信号情况进行分析。由图5所示的PF34处各个基站的采样信号概率分布图可见,样本数据总体趋于高斯分布,符合文中算法的应用条件。面对概率优先的数据处理方法,本实验场景取p0=7%,可达到滤除偏差数据的目的。经特征提取后得到指纹点接收信号强度向量,与其物理位置共同构建指纹数据库。

(a) 接收信号强度PA1 (b) 接收信号强度PA2 (c) 接收信号强度PA3 (d) 接收信号强度PA4
6.2 实验参数配置
6.2.1 模糊参数
模糊参数f影响着局部指纹库匹配的包容程度,f越大,局部指纹库匹配的正确率越高;但同时,f增大会提升匹配结果为多子块的概率,增加计算负担。因此具体的定位场景可通过实验确定最佳模糊参数f,在提高DP匹配正确率的同时,尽可能削弱多子库匹配带来的指纹点匹配量增大的弊端。
实验对比了FMKNN在不同f值下,局部指纹库匹配正确率的变化情况,同时对比了指纹点匹配数量在全局匹配的占比变化。实验结果如图6所示,可以看到,当f取9及以上时,局部指纹库匹配正确率已经可以达到100%,同时需要匹配的指纹点数量仅为全局匹配的38.8%,计算复杂度也有明显降低。因此,不失一般性,设置本实验场景的模糊参数f=9。
6.2.2 环境参量
定义平均定位误差Δ来衡量定位精度:
(12)
其中,Q为测试的待定位点数量。为验证v对定位精度的正向作用,实验对比了不同的v取值对Δ的影响。如图7所示,根据实验数据拟合,确定v和Δ的函数关系G,从而得出定位场景的最佳环境参量,即
v=G-1[(Δ)min] 。
(13)
由G的曲线变化可以发现,当v>0时,平均定位误差相比不引入v大幅降低。另一方面,v过大会引发过度调参,导致定位误差反弹。考虑到v过大或过小都无法达到有效调节权重的目的,以Δ=0.8 m为上限,得到v的经验取值范围[2.1,6.4],同时确定本场景最佳的v=3.2。
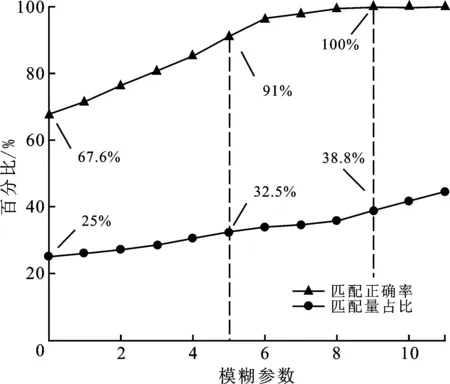
图6 局部指纹库匹配结果对比
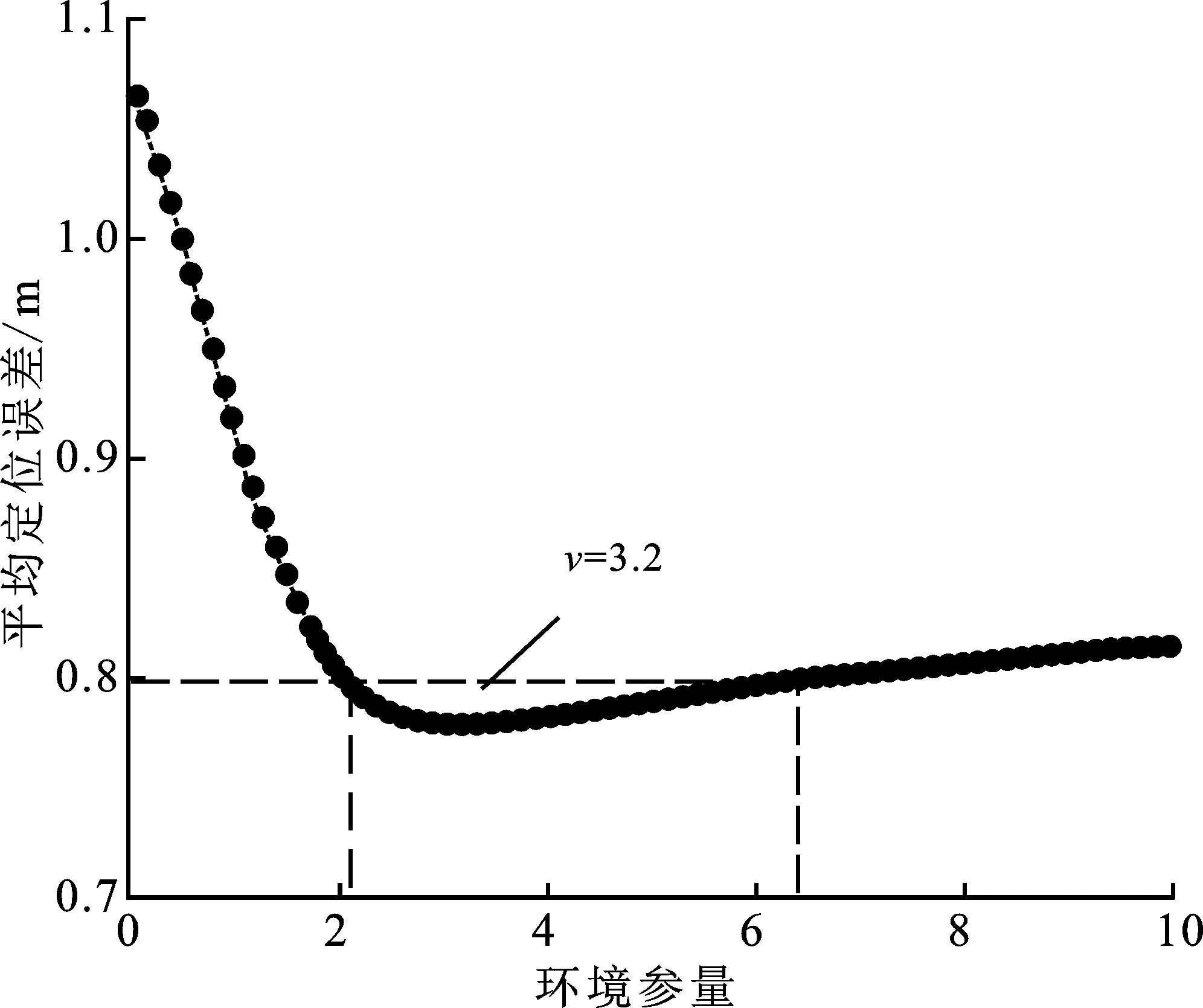
图7 环境参量与平均定位误差的关系曲线
6.3 定位误差的对比分析
考虑到论文提出的FMKNN算法以提升匹配速率为目标,选用同样具有快速易行的传统WKNN[6]、增强加权K最近邻算法(Enhanced Weighted K-Nearest Neighbors,EWKNN)[17]、改进的支持向量回归算法(Improved Support Vector Regression,ISVR)[11]作为对比,用以测试FMKNN算法的工作性能。图8显示了近邻点数量S对4种算法定位误差的影响。可以看到总体上随着近邻点个数的增加,4种算法的Δ都呈下降趋势,其中EWKNN和ISVR下降速率较慢,而FMKNN最快。
从最优近邻点数量下的平均误差来看,FMKNN相较于其余算法具有最低的误差值。其中WKNN定位误差最高,比FMKNN高出0.27 m;同时FMKNN的Δ也比EWKNN和ISVR分别降低0.15 m和 0.13 m,占比20.21%和17.74%,可见FMKNN定位效果良好。但另一方面,也发现当S≤3时,FMKNN的平均定位误差相对较高,且降低速率较小,原因是近邻点个数过少,环境参量v的调节作用不大。近邻点个数较少时,存在权重误调节的情况,反而使物理距离较远的近邻点分配到更大的权重。当S≥9时,过多的权重被分配到离待定位点物理距离较远的近邻点上,从而导致4种基于KNN的算法定位误差开始反弹增长。
6.4 误差累计概率分析
在应用给定的定位误差容忍范围内,通过实验可确定各定位算法的估算结果满足该容忍范围的概率,记为误差累计概率pΔ。本实验中给出了在不同的误差容忍范围下,WKNN、EWKNN、ISVR和FMKNN定位结果的pΔ对比情况。从图9可以看出,4种算法的pΔ均随误差容忍范围扩大而升高,最终达到100%。当给定Δ≤0.5 m时,由于允许误差小于一个单位的指纹点间隔距离,因而4种算法的pΔ相差不大且都较低,此时的误差水平受到指纹点设定影响。而误差容忍范围继续扩大后,FMKNN的pΔ曲线表现出最快的上升速率。当Δ≤1 m,FMKNN的pΔ已经达到95.4%,可见该场景下FMKNN的平均定位误差基本能够控制在2倍指纹点间隔距离以内,具备良好的定位稳定性。而相对上升趋势最慢的WKNN在Δ≤1 m条件下,pΔ为54.4%,比FMKNN低43%,EWKNN和ISVR的pΔ曲线则始终介于前两者之间。
通过以上对比得知FMKNN的平均定位误差集中于小范围的误差区间,可见其定位稳定性优于另外三者。此实验证明FMKNN在处理由环境变化和设备差异带来的信号波动时具有明显的优势,主要原因是多元的相似度计算模型可以更全面地衡量待定位点与指纹点的物理距离,从而更好地抵抗环境噪声影响。
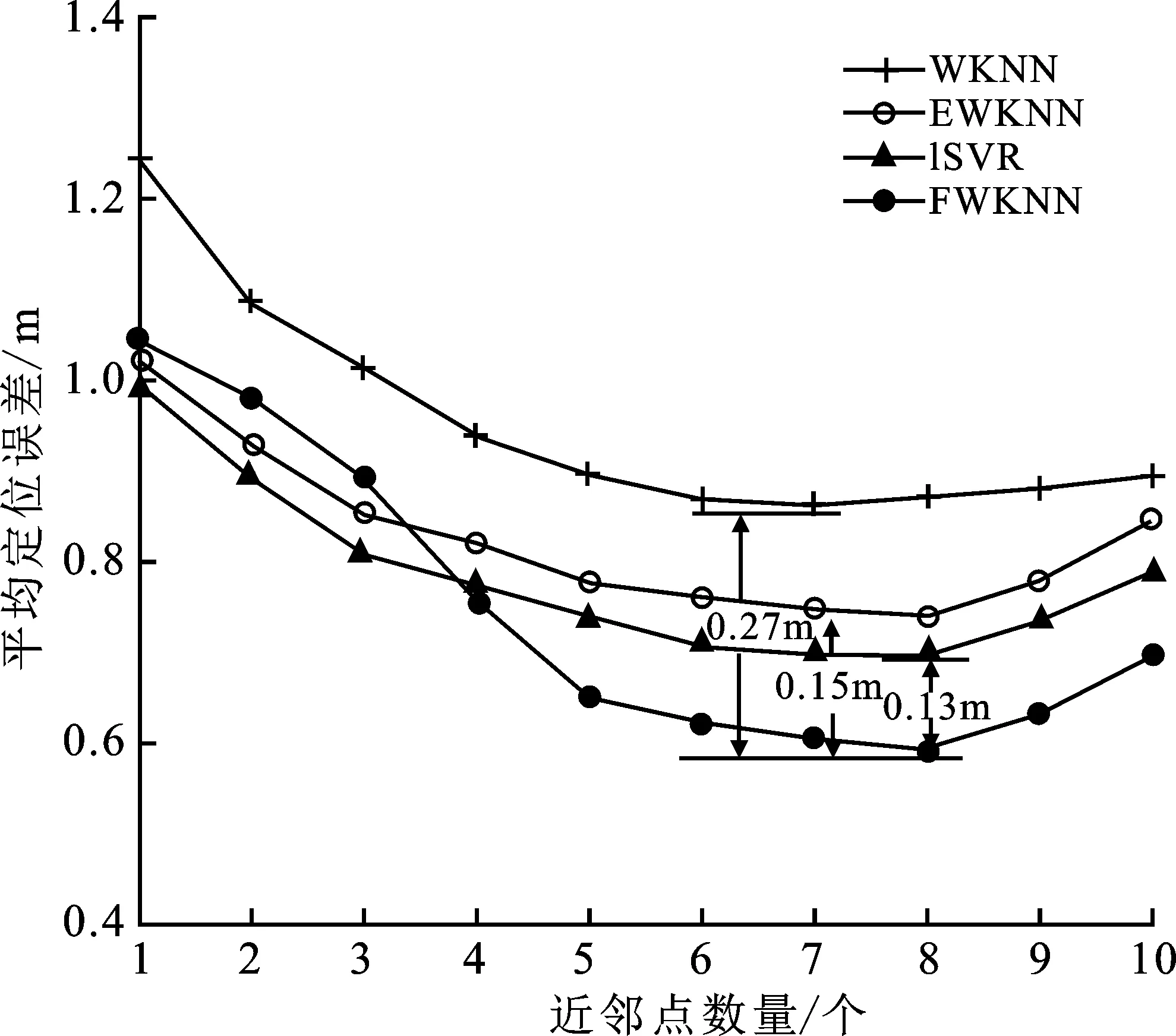
图8 近邻点个数S对平均定位误差的影响
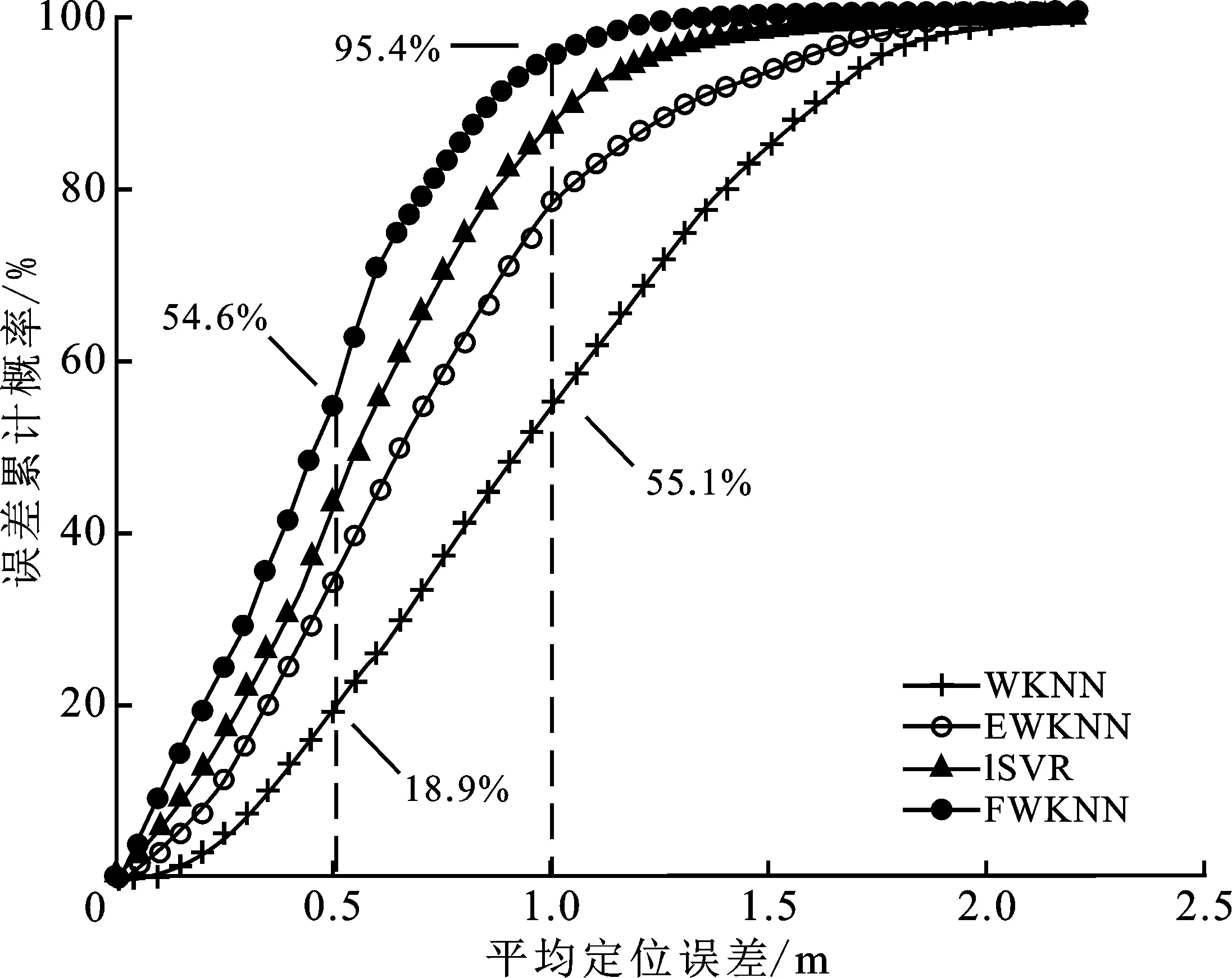
图9 目标定位误差的累计概率对比
7 结束语
论文针对基于K近邻的算法存在定位精度低,以及大多智能算法计算复杂度高的问题,对指纹定位的各个步骤提出了改善方法。基于模糊参数的局部指纹库匹配有效减少了定位过程中指纹点的匹配数量,加快了定位效率;新的相似度计算方式,弥补了近邻点匹配过程中指标单一的不足;最后经过权重再分配机制降低定位误差。实验表明,论文提出的算法在定位速度和定位精度两个方面都优于传统的全局K近邻定位算法。
